






1754B Kevin and Permutation
题目描述:输入一个n,输出从1到n组成的序列中,两个相邻的数的差的最小值最大
解题思路:想要使最小值最大,把这个数组从中间分为两部分,例:对n=6,可以分为1 2 3和4 5 6两部分,按照3 6 2 4 1 5 的顺序输出,最小值就是3
代码:
#include<bits/stdc++.h>
using namespace std;
stack<int> q1,q2;
int main(){
int t;
cin>>t;
while (t--)
{
int n ;
cin>>n;
for(int i=0;i<(n+1)/2;i++){
q1.push(i+1);
}
for(int i=(n+1)/2;i<n;i++){
q2.push(i+1);
}
while (!q1.empty()||!q2.empty())
{
if(!q1.empty()){
cout<<q1.top()<<' ';
q1.pop();
}
if(!q2.empty()){
cout<<q2.top()<<' ';
q2.pop();
}
}
cout<<endl;
}
return 0;
}
这里使用了栈,总结栈的使用:
s.empty(); //如果栈为空则返回true, 否则返回false;
s.size(); //返回栈中元素的个数
s.top(); //返回栈顶元素, 但不删除该元素
s.pop(); //弹出栈顶元素, 但不返回其值
s.push(); //将元素压入栈顶
查找
1、P2249 【深基13.例1】查找
明显本题使用二分查找,看大佬解答
关于upper_bound和lower_bound的使用
这俩是基于二分查找的
lower_bound(begin,end,k):从begin地址开始到end-1位置,查找第一个大于等于k的值返回该值的地址,不存在返回end
upper_bound(begin,end,k):从begin地址开始到end-1位置,查找第一个大于k的值返回该值的地址
AC代码:
#include <bits/stdc++.h>
using namespace std;
const int MAXN=1e6+10;
int a[MAXN];
int main()
{
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++){
cin>>a[i];
}
while(m--){
int target;
cin>>target;
int ans = lower_bound(a+1,a+n+1,target)-a;
if(a[ans]==target){
cout<<ans<<" ";
}else{
cout<<-1<<" ";
}
}
return 0;
}
P1102 A-B 数对
解题思路:首先看到题后先想的是遍历A数组,由AC得到B=A+C然后在数组中查找B,这明显O(nm)的复杂度,必然过不了。然后查找的话,二分查找比较快,因此使用sort后,使用二分查找B,于是得到了下面的代码
#include<bits/stdc++.h>
using namespace std;
const int MAXN=2e+5;
int a[MAXN];
int main(){
int num=0;
int n,c;
cin>>n>>c;
for(int i=0;i<n;i++){
cin>>a[i];
}
sort(a,a+n);
for(int i=0;i<n;i++){
int b = a[i]+c;
int loc = lower_bound(a+i,a+n,b)-a;
if(b==a[loc]){
num++;
}
}
cout<<num;
return 0;
}
结果过不了
原因:在使用lower_bound时只能找到一个b的位置,但是在这个数组中可能有好多b,看了大佬们的解答,有两个思路
1、使用upper_bound的结果-lower_bound的结果,就是b的个数,当b不存在的时候两个值相等,结果就是0,当;两个值不等的时候,lower得到的结果是b的第一个位置,然后upper得到的是b后面的一个位置,然后两个位置相减,就可以得到b的个数
代码如下
#include<bits/stdc++.h>
using namespace std;
long long a[200000];
int main(){
long long num=0;
long long n,c;
cin>>n>>c;
for(int i=0;i<n;i++){
cin>>a[i];
}
sort(a,a+n);
for(int i=0;i<n;i++){
long long b = a[i]+c;
num += ((upper_bound(a+i,a+n,b)-a)-(lower_bound(a+i,a+n,b)-a));
}
cout<<num;
return 0;
}
注意记得开long long !!!!!没开long long 导致一个测试点过不了
2、使用map记录数组中每个值出现的次数
#include<bits/stdc++.h>
using namespace std;
long long a[200000];
map<long long ,long long> m;
int main(){
long long num=0;
long long n,c;
cin>>n>>c;
for(int i=0;i<n;i++){
cin>>a[i];
m[a[i]]++;
}
sort(a,a+n);
for(int i=0;i<n;i++){
long long b = a[i]+c;
int loc = lower_bound(a+i,a+n,b)-a;
if(a[loc]==b){
num+=m[b];
}
}
cout<<num;
return 0;
}
砍树
解题思路:想到先用sort排序,然后从高到低遍历逐个降低伐木机的高度,然后计算砍下来的高度,直到满足要求,比较暴力,复杂度为O(n^2),不合适。
解题思路(大佬的):使用二分思想,找到最大的树高和最小的树高,然后对这两个高度求中间值作为砍树机的高度,然后遍历求砍下来的长度,如果不够,就把最小树高变为中值+1,否则,最大树高变为中值-1,继续上述过程。
AC 代码
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
LL tree[1000000];
int main(){
LL N,M;
cin>>N>>M;
LL l=0,h=0;
for(int i=0;i<N;i++){
cin>>tree[i];
h = max(h,tree[i]);
}
sort(tree,tree+N);
int mid;
while(l<=h){
LL s=0;
mid = (l+h)/2;
for(int i=N-1;i>=0;i--){
if(tree[i]<=mid){
break;
}
s+=tree[i]-mid;
}
if(s<M){
h=mid-1;
}else{
l=mid+1;
}
}
cout<<l-1;
return 0;
}
开始的时候,我用自己的while判断条件里面是l<h,然后加了相等判断,最后mid作为结果,但是有4个数据过不去,改为大佬的代码,可以过(郁闷)
然后评论说二分的写法:
while(left<=right){
int mid=(left+right)/2;
if(check(mid)) left=mid+1;
else right=mid-1;
}
最后r+1做答案
前缀和与差分
参考:前缀和与差分
基础数学问题
进制转换
解题思路:1、首先使用map,将16机制的字符串对应到整数
map使用:map详解
2、输入的要转换的数字是一个字符串,先转为10进制:使用map[number[i]]*pow(n,length(number)-i-1)
3、使用栈,将十进制数除以要转换的m进制,将余数入栈,然后出栈
#include<bits/stdc++.h>
using namespace std;
map<char,int>map1{{'0',0},{'1',1},{'2',2},{'3',3},{'4',4},{'5',5},{'6',6},{'7',7},{'8',8},{'9',9},
{'A',10},{'B',11},{'C',12},{'D',13},{'E',14},{'F',15}};
stack<int> ss;
int main(){
int n,m;
string number;
cin>>n;
cin>>number;
cin>>m;
int len = number.length();
int tennumber=0;
for(int i=0;i<len;i++){
tennumber += map1[number[i]]*pow(n,len-i-1);
}
while(tennumber){
ss.push(tennumber%m);
tennumber /= m;
}
while(!ss.empty()){
int topn = ss.top();
if(topn<10){
cout<<topn;
}
else if(topn==10){
cout<<'A';
}else if(topn==11){
cout<<'B';
}
else if(topn==12){
cout<<'C';
}
else if(topn==13){
cout<<'D';
}else if(topn==14){
cout<<'E';
}else if(topn==15){
cout<<'F';
}
ss.pop();
}
return 0;
}
P1469 找筷子
解题思路:先声明一个map,里面存筷子长度到筷子数量的映射,最后,遍历这个map,找到单数长度输出就好了
啊…超内存了,看大佬思路:直接吧所有的数进行异或,为偶数的话,异或后就是0,最后异或结果是啥,啥就是单数个…嗯,技巧。下回看到这种单数偶数的题就用异或,代码如下:
#include<bits/stdc++.h>
using namespace std;
int n,ans,a;
int main(){
cin>>n;
for(int i=0;i<n;i++){
scanf("%d",&a);
ans^= a;
}
printf("%d",ans);
return 0;
}
P1100 高低位交换
很容易就想到了左移16位+右移16位,开始时,我用int定义,但是交的时候WA,看了别人的解答,int 类型有32位,其中在保存的时候,有一位作为符号位,因此int的范围是-2(31) ~231-1,而题目中是32位的数,而题目中的要求是正整数,这时候就可以用unsigned类型了,然后就AC的很顺利
P1017 [NOIP2000 提高组] 进制转换
拿到题后,感觉就是一个简单的进制转换(吧),然后用手算了一下给的例子,一直模,然后取余,嗯,果然没这么简单。然后问题就是在于负数的模,在计算机中,它算模是用a-a/bb,例如对于例题中的-25000mod(-16)商为1563,余数为-8,我想给他变成整数,用b去减这个余数,就是-25000 = -161563-8,我在后面给它+16,在前面给它减16,所以商+1。
总结:思路就是当遇到余数为负的情况,就用R+余数(因为余数为负,所以用加),商也+1。AC代码如下:
#include<bits/stdc++.h>
using namespace std;
int main(){
int n,R,absR;
cin>>n>>R;
absR = abs(R);
stack<int> ss;
int n1 = n;
while(n1){
int mod = n1%R;
if(mod<0){
mod = absR+mod;
n1 = n1/R +1;
}else{
n1 = n1/R;
}
ss.push(mod);
}
cout<<n<<"=";
while(!ss.empty()){
int m = ss.top();
if(m>=10){
cout<<char(m-10+'A');
}else{
cout<<m;
}
ss.pop();
}
cout<<"(base"<<R<<")";
return 0;
}
P3383 【模板】线性筛素数
这是一个模板,用欧拉筛。
算法思想:想要找到小于数n的所有素数:首先确定0,1非素数,先定义一个isprime[i],它表示i是否为素数,prime数组记录素数。从2开始遍历,如果i是素数,就给它放入到prime数组中,并把i的素数倍筛掉。一个重要的点,if(i%prime[j]0) break;例如对i=16,当看到prime[1]=2的时候发现16%20,就不要往后看后面的质数倍了,因为16能筛的已经被2筛掉了。
模板如下:
bool isPrime[n];
int prime[n];
int cnt=0;
void GetPrime(int n){
memset(isPrime,1,sizeof(isPrime)); //把isprime都置位true
isPrime[0]=isPrime[1]=0;
for(int i=2;i<n;i++){
if(isPrime[i]){
prime[++cnt]=i;
}
for(int j=1;j<=ctn&&i*prime[j]<=n;j++){
isPrime[i*prime[j]]=false;
if(i%prime[j]==0) break;
}
}
P1029 [NOIP2001 普及组] 最大公约数和最小公倍数问题
解题思路:第一个想的是暴力, 那肯定过不了哇。看了一下题解,整理思路:
首先,gcd:最大公约数数,lcm:最小公倍数,然后有数学知识,两个数的积等于他俩的gcdlcm(这确实不知道),然后可以通过遍历x,用PQ/x得到y,然后判断x和y的gcd,如果为P,那么他们的lcm也一定是Q,就找出了一组,x遍历到x*y的开放就行了,后面的重复,直接乘2,然后如果x==y满足,即P=Q,那么加一次就行。x,y最大1e5称完之后1e10,因用ll
解题:开始算y的时候直接让y=n/x,但是n不一定可以整除x啊,就过了四个点,然后改过之后就可以AC了,代码如下:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
ll P, Q;
ll gcd(ll x, ll y) {
if (y == 0) return x;
return gcd(y, x % y);
}
int main() {
cin >> P >> Q;
ll n = P * Q;
ll ans = 0;
for (ll x = 1; x <= sqrt(n); x++) {
if (n%x==0&&gcd(n/x,x)==P) {
ans++;
}
}
ans *= 2;
if (P == Q) {
ans--;
}
cout << ans << endl;
return 0;
}
总结,在这里首先是我不知道x*y=gcd(x,y)*lcm(x,y)然后就是求gcd 的一个函数模板:
这是辗转相除法
ll gcd(ll x, ll y) {
if (y == 0) return x;
return gcd(y, x % y);
}
还有一种辗转相减法:先把a和b除2变为奇数,a和b之中,用大的减小的,一直减,知道减数和结果相同,这个相同的就是最大公因数
P1572 计算分数
看到题后,第一反应就是处理字符串,读入字符串,然后遍历,当我读到/就标志前面的数是分子,放入分子数组,读到+or-就表示分母读入完成,,把它放入分母数组中,最后再求最小公倍数,再计算,对于负数,我可以用一个flag标志读入的是+还是-,嗯…写出来的程序又乱又长的。最后还没过,代码如下:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll gcd(int x, int y) {
if (y == 0) return x;
return gcd(y, x % y);
}
int main() {
int top[50];//保存分子
int bot[50];//保存分母
int gcnum = 1;//保存最大公因数
ll sum = 1;//保存的是分母的乘积,最后用来计算最大公倍数
int fflag = 1;//记录当前数的符号-1or1
int num = 0;//记录当前的数字的值
string s;
cin >> s;
int x=0, y=0;//分子分母的两个指针
for (int i = 0; i < s.length(); i++) {
if (s[i] == '-') {
if (i != 0) {
bot[y] = num;
y++;
gcnum = gcd(gcnum, num);
sum *= num;
}
fflag = -1;
num = 0;
}
else if (s[i] == '+') {
bot[y] = num;
y++;
gcnum = gcd(gcnum, num);
sum *= num;
fflag = 1;
num = 0;
}
else if (s[i] == '/') {
top[x] = fflag * num;
x++;
num = 0;
}
else {
num = num * 10 + s[i]-'0';
}
}
bot[y] = num;
gcnum = gcd(gcnum, num);
sum *= num;
ll lcm = sum / gcnum;//最大公倍数
ll re_top = 0;
for (int i = 0; i < x; i++) {
re_top += lcm / bot[i] * top[i];
}
int gcd2 = gcd(lcm, re_top);
re_top = re_top / gcd2;
lcm /= gcd2;
cout << re_top << "/" << lcm;
return 0;
}
看了dalao的题解,他们直接输入的时候就直接搞了。en…6666,确实我想不到。
解题思路:输入时,用abcd分别接受两个数的分子和分母,然后使用a/b+c/d=ad+cb/bd,最后对分子分母约分。(dalao就是dalao)
AC代码如下:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll gcd(ll x, ll y) {
if (y == 0) return x;
return gcd(y, x % y);
}
int main() {
ll a, b, fz, fm;
char op, f;
cin >> fz >> f >> fm;
while (cin >> a >> f >> b) {
fz = fz * b + a * fm;
fm = fm * b;
}
ll c = gcd(fz, fm);
fz /= c;
fm /= c;
if (fm < 0) {
fz = -fz;
fm = -fm;
}
if(fm==1){
cout << fz;
}
else {
cout << fz << '/' << fm;
}
return 0;
}
P3811 【模板】乘法逆元
①使用扩展欧几里得:
void Exgcd(ll a, ll b, ll &x, ll &y) {
if (!b) x = 1, y = 0;
else Exgcd(b, a % b, y, x), y -= a / b * x;
}
原理见基础数论
②费马小定理

然后用快速幂:快速幂模板:
ll fastPow(ll base, ll pow,int p) {
ll re = 1;
while (pow) {
if (pow & 1) { //pow为奇数
re = (re*base) %p;
}
pow /= 2;
base = (base * base) %p;
}
return re;
}
③线性算法
原理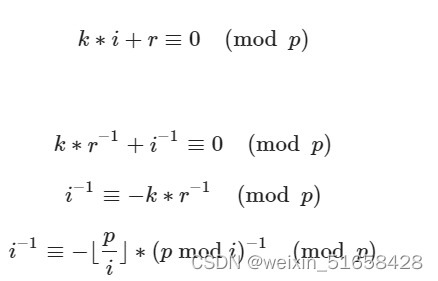
实现:
inv[1] = 1;
for(int i = 1; i < p; ++ i)
inv[i] = (p - p / i) * inv[p % i] % p;
很明显,这题适合用线性算法
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
ll inv[3000001] = {0,1};
int main() {
ll n, p;
cin >> n >> p;
cout << inv[1] << endl;
for (ll i = 2; i <= n; i++) {
inv[i] = (p - p / i) * inv[p % i] % p;
printf("%d\n",inv[i]);
}
return 0;
}
当我用cout的时候俩点超时,然后改成printf就AC了嘿嘿嘿
卢卡斯算法
模板
原理:
long long quickpow(long long base, long long power) {
long long ret = 1;
while (power) {
if (power % 2)
ret = ret * base % p;
base = base * base % p;
power /= 2;
}
return ret;
}
long long C(long long n, long long m) {
if (n < m) return 0;
if (m > n - m) m = n - m;
long long a = 1, b = 1;
for (int i = 0; i < m; i++) {
a = (a * (n - i)) % p;
b = (b * (i + 1)) % p;
}
return a * quickpow(b, p - 2) % p;
}
long long Lucas(long long n, long long m) {
if (m == 0) return 1;
return Lucas(n / p, m / p) * C(n % p, m % p) % p;
}
毕业季
添加链接描述
思路:首先想的就是使用辗转相除做,但是后来做着做着做到了o(n3),这必爆
另一个思路:对于每一个数,我们都可以分解因子,记录因子出现的次数,如果这个因子正好出现k次,那么这个这个因子,必然是这k个数的最大共约数。我的思路想到了这里,然后问题来了怎么分解,如果从1遍历到当前的数的话,那肯定很慢。g。看了大佬答案。总结一下:
首先因数的分解,可以从1-sqrt(m)遍历,如果m可以除i,那么m必然可以除m/i,因子分解的问题就解决了,下面就是记录每个因子出现的次数,使用c[i],表示的是i作为因子出现的次数,然后有一个巧妙地,就是我们可以找到最大的那个因子,那个因子必然是只有一个数的因子,然后就是找两个数的最大因子,这个因子肯定是比一个数的因子小的,因此,找两个数的因子的时候可以直接把i–,一直找到c[i]=当前的人数,代码如下:
#include<bits/stdc++.h>
using namespace std;
const int N = 10005;
const int INF = 1000006;
int c[INF];
int main() {
int n;
cin >> n;
int ma = 1;
for (int j = 0; j < n;j++) {
int m;
cin >> m;
if (ma < m) {
ma = m;
}
//下面对m进行分解
for (int i = 1; i <= sqrt(m); i++) {
if (m %i == 0) {
if (m != i * i) {
c[i]++;
c[m / i]++;
}
else {
c[i]++;
}
}
}
}
//下面找出现次数为k的因子
int i = ma;
for (int k = 1; k <= n; k++) {
while (c[i] < k) {
i--;
}
cout << i << endl;
}
return 0;
}
总结:因数分解可以找sqrrt(m)
P1835 素数密度
这个题涉及到了素数筛,再复习一下
1、埃氏筛
思想:通过将素数倍增,将倍增的数进行标记,未标记的就是素数,并对其进行一下优化:首先肯定是要排除偶数,只遍历奇数;其次就是在倍增的时候值需要从i的i倍开始就行了
int aishi(int n) { //找从1-n的所有素数
if (n < 2) {
return 0;
}
int k = 0;
isPrime[0] = isPrime[1] = 1;
isPrime[2] = 0;
for (int i = 4; i <= n; i += 2) {
isPrime[i] = 1;
}
for (int i = 3; i * i <= n; i += 2) {
if (isPrime[i] == 0) {
for (int j = i; i * j <= n; j++) {
isPrime[i * j] = 1;
}
}
}
prime[k++] = 2;
for (int i = 3; i <= n; i+=2) {
if (isPrime[i] == 0) {
prime[k++] = i;
}
}
return k;
}
2、欧拉筛
欧拉筛是对埃氏筛的改进,埃氏筛还是会重复筛选的,欧拉筛是改进在倍增的时候的操作,倍增的时候只倍增素数表,其次,要注意,如果当前的这个数是前面的素数的倍数,那么i的倍数一定被筛了,也停止
void Erlu(int n) {
isPrime[1] = 1;
isPrime[2] = 0;
int k = 0;
for (int i = 2; i <= n; i ++) {
if (isPrime[i] == 0)
prime[k++] = i;
for (int j = 0; j < k; j++) {
if (i * prime[j] > n)
break;
isPrime[i * prime[j]] = 1;
if (i % prime[j] == 0) {
break;
}
}
}
}
2022.11.3 2022桂林
今天感受一下真题吧题目连接
A.lily
居然一开始没看懂题,丢大人
题目描述:第一行输入一个字符串长度,然后第二行输入字符串,然后不让C挨着L,让C尽量的
解题思路:貌似直接吧不挨着L的.换成C就行了吧,开整
AC代码
#include <bits/stdc++.h>
using namespace std;
int main() {
int n;
string s;
cin >> n;
cin >> s;
int i = 0;
if (n == 1) {
if (s[0] == '.') cout << "C";
else cout << s;
}
else {
//先输出第一个
if (s[1] == 'L'||s[0]=='L') cout << s[i];
else cout << "C";
i++;
for (; i < n - 1; i++) {
if (s[i] == 'L' || s[i - 1] == 'L' || s[i + 1] == 'L') cout << s[i];
else cout << "C";
}
//处理最后一个
if (s[i] == 'L' || s[i - 1] == 'L') cout << s[i];
else cout << "C";
}
return 0;
}
在这里我直接输出了,感觉可以看一下字符串的操作
线段树
P3372 【模板】线段树 1
首先学习线段树的基本三个操作:构造,查询,修改
首先定义线段树结构体
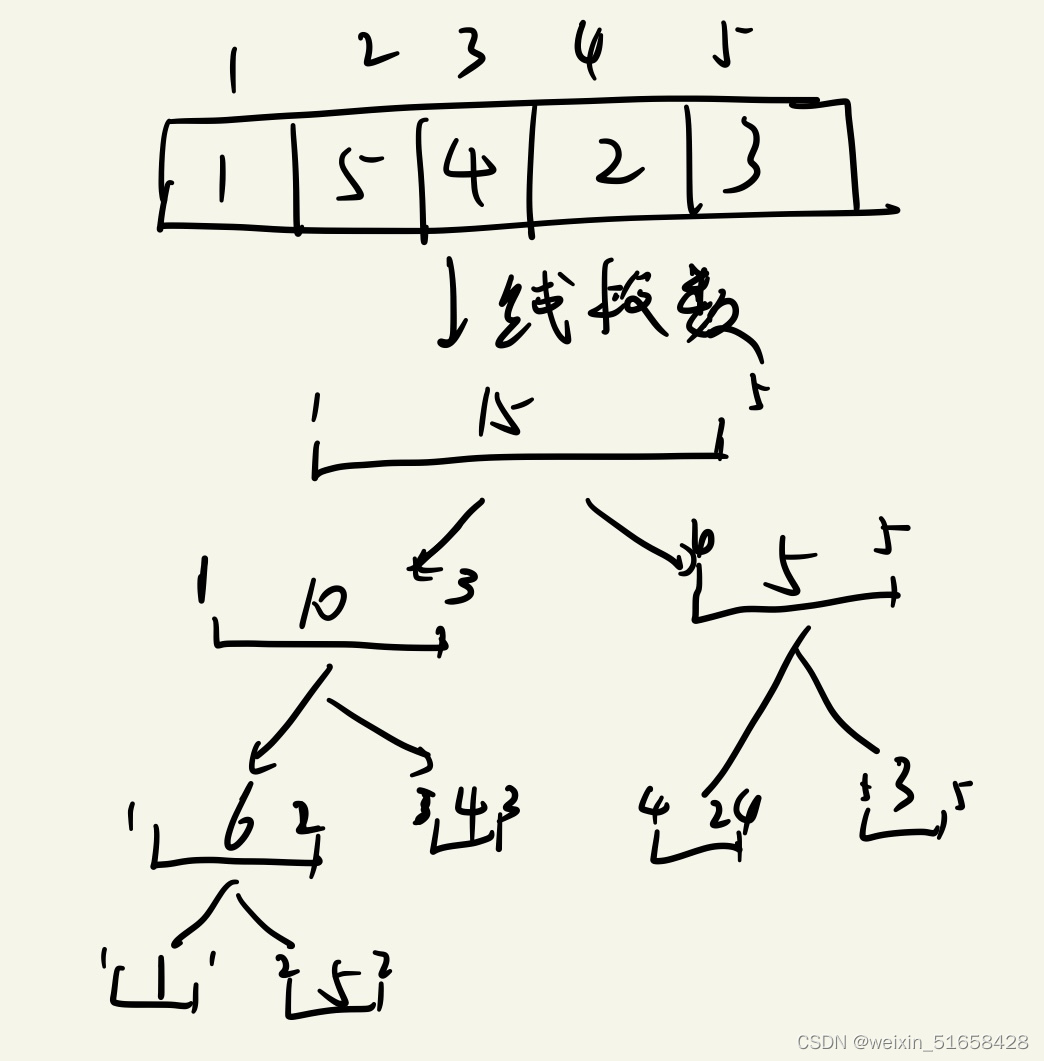
struct noded{
int l,r,sum,lazy;
//这里,l,r,表示的是该区间的左右断点
}tree[N];
sum表示这个区间的和,结构体中只需要存该去区间的左右段点,他们与左右孩子的关系通过2k去找左孩子,2k+1去找右孩子
构造线段树
思想:我们要把number数组中存的数放入到线段树数组中,就是把它们放到想线段树的叶子节点处,可以采用递归,递归到叶子节点的时候结束并放值,这个值我们可以看到叶子节点左右段点的值就是要放的值在number数组中的位置。,然后递归出来之后,我们就更新这个点,即该点的sum值=左孩子的sum+右孩子的sum。代码如下
void build(int k,int l,int r){//当期到数中的第k个点,然后他的左右段点分别是l和r
tree[k].l =l;tree[k].r =r;
if(tree[k].l==tree[k].r){//当前是叶子节点
tree[k].sum = number[l];
}
int mid (l+r)/2;
build(2*k,l,mid);
build(2*k+1,mid+1,r);
}
下面介绍懒惰标记,懒惰标记的意思是我已经对这个区间做了修改,但还没有对它的子区间进行修改,这个用于修改区间值的时候我们就不用去一个一个往下搜索改变了,只需要吧这个区间对应点的lazy加上我要加的值就行了。
一个困惑?为啥在修改的时候要去吧lazy下放,个人感觉不下放的话多个lazy相加,然后在最后查询的时候一起下放就好了啊,但是好像下放的话对效率影响不大,lazy下放是o(1)级别的
lazy下放代码:
给第k个节点的lazy下放,就是先把它左右子树区间的值变了,然后在给左右子树的lazy设置,并将自己的lazy置0,lazy表示自己这个区间已经变过了
void push(int k){//将树中的第k个节点的lazy下放
if(tree[k].lazy){//当这个点的lazy不为0的时候就下放
tree[2*k].sum += (tree[2*k].r-tree[2*k].l+1)*lazy;
tree[2*k+1].sum += (tree[2*k+1].r-tree[2*k+1].l+1)*lazy;
tree[2*k].lazy += tree[k].lazy;
tree[2*k+1].lazy += tree[k+1].lazy;
tree[k].lazy = 0;
}
}
区间修改代码:
典型的寻找区间+修改lazy
void changeSement(int k,int l,int r,int x){ //当前到达树的第k个节点,目标区间是l,r,吧该区间内的值+x
if(l<=tree[k].l && tree[k].r<=r){//当前的区间完全被目标区间覆盖,就找到了
tree[k].sum += (tree[k].r-tree[k].l+1)*x;
tree[k].lazy += x;
}
int mid = ( tree[k].l+tree[k].r)/2;
if(r<=mid) changeSegment(2*k,l,r,x);
if(l>mid) changeSegment(2*k+1,l,r,x);
update(k);//这个一定要有,不然的话不更新父节点
}
区间查询:查询l,r区间的和
int queryTemp(int k,int l,int r){//当前节点为k,目标区间是l,r
if(l<=tree[k].l && tree[k].r<=r){ //结束条件,当前区间是目标区间的子集
return tree[k].sum;
}
pushdown(k);
int re= 0;
int mid = (tree[k].l+tree[k].l)/2;
if(r<=mid) re+=queryTemp(2*k,l,r);
if(l>mid) re+=queryTemp(2*k+1,l,r);
return re;
}
洛谷AC代码:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll N = 100010;
ll number1[N+2];
struct node
{
ll l = 0, r = 0, lazy = 0;
ll sum = 0;
} tree1[4*N+2];
void update1(ll k) {
tree1[k].sum = tree1[k * 2].sum + tree1[k * 2 + 1].sum;
}
void build1(ll k, ll l, ll r) {
tree1[k].l = l;
tree1[k].r = r;
if (l == r) {
tree1[k].sum = number1[l];
return;
}
ll mid = (l + r) / 2;
build1(2 * k, l, mid);
build1(2*k+1,mid+1,r);
update1(k);
}
//懒惰标记下传
//这是当我要给某个区间加上某个值的时候,使用相对标记,
//直接修改这个区间的懒惰标记,在使用的时候再将每个节点的懒惰标记下传,并将自己的懒惰标记值为0
//当要吧某个区间的值修改为某个特定的值的时候就可以使用绝对懒惰标记
void pushdown(ll k) {
//将k的懒惰标记下传
if (tree1[k].lazy) {
tree1[2 * k].sum += (tree1[k * 2].r - tree1[k * 2].l + 1) * tree1[k].lazy;
tree1[2 * k + 1].sum += (tree1[k * 2 + 1].r - tree1[k * 2 + 1].l + 1) * tree1[k].lazy;
tree1[k * 2].lazy += tree1[k].lazy;
tree1[k * 2 + 1].lazy += tree1[k].lazy;
tree1[k].lazy = 0;
}
}
//区间修改,把[l,r]中所有的值修+x
//最后递归的出口就是完全覆盖我要的区间
void changeSegment(ll k, ll l, ll r, ll x) {
//当前到了tree的k号节点,目标区间是l,r,我要把l,r区间中的值+x
if (tree1[k].l >= l && tree1[k].r <= r) {//找到了想要的区间
tree1[k].sum += (tree1[k].r - tree1[k].l + 1) * x;//sum加上区间长度
tree1[k].lazy += x;
return;
}
pushdown(k);
ll mid = (tree1[k].l + tree1[k].r) / 2;
if (l <= mid) changeSegment(2 * k, l, r, x);
//全部落在左区间的情况
if (r > mid) changeSegment(2 * k+1, l, r, x);
//全部落在右区间的情况
update1(k);
}
ll queryTemp(ll k, ll l, ll r) { //查询,求区间和
//当前在k个节点,我要查询l,r区间的和
//当前区间是目标区间的一个子集的时候,返回当前区间的sum值
if (l <= tree1[k].l && r >= tree1[k].r) return tree1[k].sum;
pushdown(k);
int mid = (tree1[k].l + tree1[k].r) / 2;
ll re = 0;
if (l <= mid) re += queryTemp(2 * k, l, r);
if (r > mid) re += queryTemp(2 * k + 1, l, r);
return re;
}
int main() {
ll n, m;
cin >> n >> m;
for (ll i = 1; i <= n; i++) {
cin >> number1[i];
}
build1(1, 1, n);
while (m--) {
ll flag, x, y,k=0;
cin >> flag ;
if (flag == 1) {
cin >> x >> y >> k;
changeSegment(1, x, y,k);
}
else {
cin >> x >> y;
cout << queryTemp(1, x, y) << endl;
}
}
return 0;
}
树状数组
https://www.cnblogs.com/xenny/p/9739600.html
树状数组它存的是和、原数组中的几个数的和每个节点的父节点为i+lowbit(i)
其中的主要操作有
①单点修改,区间求和
单点查询
在数组的第i个位置上加上k
分析:在第i个数组上加上k,那么相应节点的父节点也要加上k,写个循环,遍历父节点
void update(int i,int k){
while(i<=n){
tree[i]+=k;
i+=lowbit(i);
}
}
区间求和:
可以通过lowbit向前遍历,就可以求出1-i的和
int getsum(int i){
int res = 0;
while(i>0){
res+=tree[i];
i-=lowbit(i);
}
}
②区间修改,单点查询
将区间[x,y]中的值+k,然后进行单点查询
这里用到了差分,构造差分数组d[i]=a[i]-a[i-1],这里简单回顾一哈。
对于上面那个式子,我们在还原的时候可以看出a[i] = d[i]+a[i-1],这样就可以得出a[i] = d[1]+d[2]+…+d[n],当想要修改[x,y]的值的时候,我们将d[x]+k,这样在还原的时候,从x往后的值都加上了k,然后给d[y+1]-k,这样从y+1开始后面的值又把k减掉了,这样就可以实现只修改区间中的值。
通过上面的分析,就可以很容易分析了吧,差分在进行区间修改的时有用
这个代码的update跟getsum与上面的一样。
③区间更新,区间查询
有个关系:∑ni = 1A[i] = n∑ni = 1D[i] - ∑ni = 1( D[i](i-1) );
在这里我们要维护两个数组:D跟(i-1)*D
update(int i,int k){
int x = i;//在进行维护的时候i-1它不变,对于一个i它是不变的
while(i<=n){
sum1[i]+=k;
sum2[i]+=k*(x-1);
i+=lowbit(i);
}
}
int getsum(int i){
int res = 0;
while(i>0){
res+=n*sum1[i]-sum2[i];
i-=lowbit(i);
}
return res;
}
洛谷模板题
1、单点修改,区间查询
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int sum[500010];
int n,m;
int lowbit(int i) {
return i & (-i);
}
void update(int i, int k) {//单点修改操作,给a中第i个数值加上k
while (i <= n) {
sum[i] += k;
i += lowbit(i);
}
}
int getSum(int i) { //返回1-i位置的和
int res = 0;
while (i > 0) {
res += sum[i];
i = i - lowbit(i);
}
return res;
}
int main() {
cin >> n >> m;
int a;
for (int i = 1; i <= n; i++) {
cin >> a;
update(i,a);
}
int tag, x, y;
for (int i = 1; i <= m; i++) {
cin >> tag >> x >> y;
if (tag == 1) {
update(x, y);
}
else {
cout << getSum(y) - getSum(x - 1)<<endl;
}
}
return 0;
}
2、区间修改,单点查询
#include<bits/stdc++.h>
using namespace std;
int d[500001];
int n, m;
int lowbit(int x) {
return x & -x;
}
void update(int x, int k) {
while (x <=n ) {
d[x] += k;
x += lowbit(x);
}
}
int getsum(int x) {
int res=0;
while (x > 0) {
res += d[x];
x -= lowbit(x);
}
return res;
}
int main() {
cin >> n >> m;
int a1;
cin >> a1;
update(1, a1);
int a2;
for (int i = 2; i <= n; i++) {
cin >> a2;
update(i, a2 - a1);
a1 = a2;
}
int flag, x, y, k;
while (m--) {
cin >> flag;
if (flag == 1) {
cin >> x >> y >> k;
update(x, k);
update(y + 1, -k);
}
else
{
cin >> x;
cout << getsum(x) << endl;
}
}
return 0;
}
堆
堆数据结构学过很熟了,就不多说原理了,下面写常用操作
1、向下调整
向下调整通常用于对根节点一下的都有序
对于i节点,首先找它的左右节点中较小的那个,然后判断i的值和子节点的值谁小,如果违背了小根堆的规则,就swap,swap之后还要进行一个递归,直到递归到i<=n的节点return退出
2、向上调整
通常用在对随机混乱的数列中
对于节点i找父节点(i/2),比较它跟父节点的值,违背规则交换,直到i=0为止
3、建堆
从n/2开始向上遍历直到i=1的节点
4、插入
在数组尾部插入,然后对最后一个元素进行shiftup
5、删除
删除的是第一个节点,把最后一个节点放到第一个,然后给第一个shiftdown
#include<bits/stdc++.h>
using namespace std;
int arr[12] = {0,8,3,4,15,16,4 ,3 ,7, 5, 20,0 };
int len = 10;
//这里都先以构造小根堆为例
void swap(int x, int y) {
int temp = arr[x];
arr[x] = arr[y];
arr[y] = temp;
}
void shiftdown(int arr[],int n,int i) { //向下调整
int child = i * 2;
if (child <= n) {
if (child+1 <= n && arr[child + 1] < arr[child]) { //如果右节点比左节点小
child++;
}
//现在child里保存的是左右节点中较小的
if (arr[i] > arr[child]) {
swap(i, child);
shiftdown(arr, n, child);
}
}
return;
}
void shiftup(int arr[], int n, int i) {
int parent = i / 2;
if (parent > 0) {
if (arr[parent] > arr[i]) {
swap(parent, i);
shiftup(arr, n, parent);
}
}
return;
}
void buildheap(int arr[],int n) {
int root = n / 2;
for (; root > 0; root--) {
cout << root << endl;
shiftdown(arr, n, root);
}
}
void insertheap(int arr[], int n, int k) {
arr[n + 1] = k;
n++;
shiftup(arr, n, n);
}
void delheap(int arr[]) {
arr[1] = arr[len];
len--;
shiftdown(arr, len, 1);
}
int main() {
buildheap(arr, len);
for (int i = 1; i <= len; i++) {
cout << arr[i] << " ";
}
cout << endl;
delheap(arr);
for (int i = 1; i <= len; i++) {
cout << arr[i] << " ";
}
return 0;
}
堆经常用在找第i小的数中,只要建一个长度为i 的大根堆,大根堆的根就是要找的
今天做题的时候发现STL自带堆,下面记录一下吧
在STL里面是优先队列priority_queue<Type, Container, Functional> type是数据类型,Container是容器类型一般是vector、queue,不能用list,Functional 就是比较的方式,当需要用自定义的数据类型时才需要传入这三个参数,使用基本数据类型时,只需要传入数据类型,默认是大顶堆
//升序队列
priority_queue <int,vector,greater > q;
//降序队列
priority_queue <int,vector,less >q;
具体例子如下
#include<iostream>
#include <queue>
using namespace std;
int main()
{
//对于基础类型 默认是大顶堆
priority_queue<int> a;
//等同于 priority_queue<int, vector<int>, less<int> > a;
priority_queue<int, vector<int>, greater<int> > c; //这样就是小顶堆
priority_queue<string> b;
for (int i = 0; i < 5; i++)
{
a.push(i);
c.push(i);
}
while (!a.empty())
{
cout << a.top() << ' ';
a.pop();
}
cout << endl;
while (!c.empty())
{
cout << c.top() << ' ';
c.pop();
}
cout << endl;
b.push("abc");
b.push("abcd");
b.push("cbd");
while (!b.empty())
{
cout << b.top() << ' ';
b.pop();
}
cout << endl;
return 0;
}
吼吼吼,一次性AC记录一下,P1168 中位数
P3865 【模板】ST 表
通过题目,可以看到这个题说是典型的静态区间最大值的题,然后看到标签有线段树,就想用线段树搞一搞,虽然我现在还不知道啥是ST表
线段树:传统的线段树一个节点记载了左右端点和这个区间内的和,在这里,我们记录[l,r]的最值,其他操作一样,我们只需要改一下update就行了
结构体:
typedef struct node{
int l,r,m;
}tree[2*N];
首先是build,建树
写出来的代码如下
#include<bits/stdc++.h>
using namespace std;
const int N = 100005;
struct node {
int l, r, m;
}tree[2*N];
int a[N];
inline int read()
{
int x = 0, f = 1; char ch = getchar();
while (ch < '0' || ch>'9') { if (ch == '-') f = -1; ch = getchar(); }
while (ch >= '0' && ch <= '9') { x = x * 10 + ch - 48; ch = getchar(); }
return x * f;
}
void build(int i, int l, int r) {
tree[i].l = l;
tree[i].r = r;
if (l == r) {
tree[i].m = a[l];
return;
}
int mid = (l + r) / 2;
build(2 * i, l, mid);
build(2 * i + 1, mid + 1, r);
tree[i].m = max(tree[2 * i].m, tree[2 * i + 1].m);
}
int getmax(int i, int l, int r) { //当前所在的节点为i,然后目标区间是l,r
//如果当前区间是目标区间的子集,就直接返回
if (l <= tree[i].l && r >= tree[i].r) {
return tree[i].m;
}
int ma = 0;
int mid = (tree[i].l + tree[i].r) / 2;
if (r <= mid) ma = max(ma, getmax(2 * i, l, r));
else if (l > mid) ma = max(ma, getmax(2 * i + 1, l, r));
else {
int m1 = getmax(2 * i, l, r);
int m2 = getmax(2 * i + 1, l, r);
if (m1 >= m2) {
ma = max(ma, m1);
}
else {
ma = max(ma, m2);
}
}
return ma;
}
int main() {
int n, m;
n = read();
m = read();
for (int i = 1; i <= n; i++) {
a[i] = read();
}
build(1, 1, n);
int l, r;
while (m--) {
l = read();
r = read();
cout << getmax(1, l, r) << endl;
}
return 0;
}
就AC仨点,其他的超时了,嗯,老老实实学ST表吧
ST用于静态询问,它预处理可以达到O(nlog2n)查询只需要O(1)空间需要O(nlogn)
d[i][j]代表的区间为左段点为i长度为2j,它管辖了[i,i+i^j-1]
#include <bits/stdc++.h>
using namespace std;
int d[100005][21];
int n,m;
int a[100005],lg[100005];
inline int read()
{
int x = 0, f = 1; char ch = getchar();
while (ch < '0' || ch>'9') { if (ch == '-') f = -1; ch = getchar(); }
while (ch >= '0' && ch <= '9') { x = x * 10 + ch - 48; ch = getchar(); }
return x * f;
}
int main() {
n = read();
m = read();
for (int i = 1; i <= n; i++) {
d[i][0] = read();
}
//下面初始化lg
lg[1] = 0;
for (int i = 2; i <= n; i++) {
lg[i] = lg[i >> 1] + 1;
}
//下面初始化d[i][j],d[i][j] = max(d[i][j-1],d[i+(i<<j-1)][j-1]
for (int j = 1; j <= lg[n]; j++) {
for (int i = 1; i + (1 << j) - 1 <= n; i++) {
d[i][j] = max(d[i][j - 1], d[i + (1 << (j - 1))][j - 1]);
}
}
int l, r;
while (m--) {
l = read();
r = read();
int k = lg[r - l + 1];
cout << max(d[l][k], d[r - (1 << k) + 1][k])<<endl;
}
return 0;
}
图
首先肯定是要说图的深搜和广搜啦
具体的算法过程不再赘述
直接上模板吧
其中的G[i]是表示值为i的节点的关系
const int N = 100006;
vector<int> G[N];
int visited[N] = { 0 };
int n, m;
queue<int> q;
void DFS(int x, int cur) { //x表示当前访问的节点,cur表示当前已经访问的节点数
visited[x] = 1;
cout << x << " ";
if (cur == n) {
return;
}
for (int i = 0; i < G[x].size(); i++) {
if (!visited[G[x][i]])
DFS(G[x][i], cur + 1);
}
}
/*
* 对于当前节点x,先把它入队,然后出队,并且把x的子节点都入队,然后出队往复知道队空
*/
void BFS(int x) {
q.push(x);
visited[x] = 1;
int curnode;
while (!q.empty()) {
curnode = q.front();
q.pop();
cout << curnode << " ";
visited[curnode] = 1;
for (int i = 0; i < G[curnode].size(); i++) {
if (visited[G[curnode][i]] == 0) {
q.push(G[curnode][i]);
visited[G[curnode][i]] = 1;
}
}
}
}
然后就是洛谷查找文献题
/*
这里写基本的DFS和BFS:
DFS基本过程:首先使用vector定义一个二维数组G[][],G[x][y]表示x和y点之间有路径
然后定义一个visited[],visited[i]=1,表示i已经被访问
对于DFS,任意选一个点开始,先输出,然后遍历G[x],如果G[x][i]没有被访问就使用递归访问
为了标记遍历完成,使用一个变量cur标记当前已经遍历的节点的个数
*/
#include<bits/stdc++.h>
using namespace std;
const int N = 100006;
vector<int> G[N];
int visited[N] = { 0 };
int n, m;
queue<int> q;
void DFS(int x, int cur) { //x表示当前访问的节点,cur表示当前已经访问的节点数
visited[x] = 1;
cout << x << " ";
if (cur == n) {
return;
}
for (int i = 0; i < G[x].size(); i++) {
if (!visited[G[x][i]])
DFS(G[x][i], cur + 1);
}
}
/*
* 对于当前节点x,先把它入队,然后出队,并且把x的子节点都入队,然后出队往复知道队空
*/
void BFS(int x) {
q.push(x);
visited[x] = 1;
int curnode;
while (!q.empty()) {
curnode = q.front();
q.pop();
cout << curnode << " ";
visited[curnode] = 1;
for (int i = 0; i < G[curnode].size(); i++) {
if (visited[G[curnode][i]] == 0) {
q.push(G[curnode][i]);
visited[G[curnode][i]] = 1;
}
}
}
}
int main() {
cin >> n >> m;
int a, b;
while (m--) {
cin >> a >> b;
G[a].push_back(b);
}
for (int i = 1; i <= n; i++) {
sort(G[i].begin(), G[i].end());
}
DFS(1, 0);
cout << endl;
memset(visited, 0, sizeof(visited));
BFS(1);
return 0;
}
P3916 图的遍历
开始想到的是用深搜,遍历每个点,然后有俩点超时
然后就想到了dp可以优化一下,优化失败,直接WA了好几个点,而且还超时,思路应该没问题,大概是代码问题
然后看了大佬的答案,用了反向数组,遍历的时候先从大的数开始,然后给大的数经过的地方都设置为这个大数。
不得不说,这思路确实牛,AC代码如下
#include<bits/stdc++.h>
using namespace std;
vector<int> G[100005];
int visited[100005];
int ma[100005];
int n,m;
void dfs(int x,int cur) {
visited[cur] = 1;
for (int i = 0; i < G[cur].size(); i++) {
if (visited[G[cur][i]] == 0 && ma[G[cur][i]]==0) {
visited[G[cur][i]] = 1;
ma[G[cur][i]] = x;
dfs(x, G[cur][i]);
}
}
return;
}
int main() {
cin >> n >> m;
int a, b;
while (m--) {
cin >> a >> b;
G[b].push_back(a);
}
for (int i = n; i >=1; i--) {
memset(visited, 0, sizeof(visited));
if (ma[i] == 0) {
ma[i] = i;
dfs(i, i);
}
}
for (int i = 1; i <= n; i++) {
cout << ma[i] << " ";
}
return 0;
}
最短路径
主要有floyed和dijistla
模板如下
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N = 100005;
const int MAX = pow(2,31)-1;
//int G[N][N];
int n, m;
int visited[N] = {0};
ll dis[N];
/*
* floyed算法时间复杂度在o(n3),可以用于求最A多每个点之间的最短路径
*/
//void floyed() {
// for (int k = 1; k <= n; k++) {
// for (int i = 1; i <= n; i++) {
// for (int j = 1; j <= n; j++) {
// if ((i != j) && (i != k) && (j != k) && (G[i][k] + G[k][j] < G[i][j])) {
// G[i][j] = G[i][k] + G[k][j];
// }
// }
// }
// }
//}
//这里下面是地杰斯特拉
struct Edge
{
int z;//这个边的子节点
int val;//这个边的权值
int nexty;//与它最近的同父节点的边的编号
}edge[N];
int head[N];
int cnt;
void addedge(int a, int b, int c) {
cnt++;
edge[cnt].z = b;
edge[cnt].val = c;
edge[cnt].nexty = head[a];
head[a] = cnt;
}
int main() {
//memset(dis, MAX, N);
int n,m,s;
cin >> n >> m >> s;
for (int i = 1; i <= n; i++) {
dis[i] = MAX;
}
int a, b, c;
for (int i = 0; i < m; i++) {
cin >> a >> b >> c;
addedge(a, b, c);
}
int cur = s;
dis[s] = 0;
int minn;
while (!visited[cur]) {
visited[cur] = 1;
for (int i = head[cur]; i != 0; i = edge[i].nexty) {
if (!visited[edge[i].z] && dis[edge[i].z] > dis[cur] + edge[i].val)
dis[edge[i].z] = dis[cur] + edge[i].val;
}
minn = MAX;
for (int i = 1; i <= n; i++) {
if (!visited[i] && minn > dis[i]) {
minn = dis[i];
cur = i;
}
}
}
for (int i = 1; i <= n; i++) cout << dis[i] << " ";
return 0;
}
迪杰斯特拉堆优化
#include<bits/stdc++.h>
using namespace std;
const int N = 500005;
int MAX = 0x7fffffff;
int dis[N];
int visited[N];
int head[N];
struct Edge
{
int son;
int wei;
int nexty;
}edge[N];
struct node {
long long int from, val;
bool operator <(const node& a) const {
return a.val < val;
}
};
int cnt;
void addedge(int u, int v, int w) {
cnt++;
edge[cnt].son = v;
edge[cnt].wei = w;
edge[cnt].nexty = head[u];
head[u] = cnt;
}
int main() {
int n, m,s;
cin >> n >> m >> s;
for (int i = 1; i <= n; i++) {
dis[i] = MAX;
}
int u, v, w;
while (m--) {
cin >> u >> v >> w;
addedge(u, v, w);
}
int cur = s;
dis[s] = 0;
priority_queue<node>q;
q.push({ s, 0 });
while (!q.empty()) {
node now = q.top();
q.pop();
if (visited[now.from]) continue;
visited[now.from] = 1;
for (int i = head[now.from]; i != 0; i = edge[i].nexty) {
int j = edge[i].son;
if (dis[j] > edge[i].wei + dis[now.from]) {
dis[j] = edge[i].wei + dis[now.from];
q.push({ j,dis[j] });
}
}
}
for (int i = 1; i <= n; i++) {
cout << dis[i] << " ";
}
return 0;
}
邮递员
这这个题归结起来就是求从1到其他点的最短路和其他点到1的最短路,1到其他点好说,其他点到1开始想floyed,o(n3),过分了,于是想到了反向图,于是就AC了
#include<bits/stdc++.h>
using namespace std;
int MAX = 0x7fffffff;
const int N = 100005;
int cnt;
int cnt2;
int head[N];
int head2[N];
int dis1[N];
int dis2[N];
int visited[N];
int n, m;
struct Edge
{
int son;
int wei;
int nexty;
}edge[N];
struct Edge2
{
int son;
int wei;
int nexty;
}edge2[N];
void addedge(int u, int v, int w) {
cnt++;
edge[cnt].son = v;
edge[cnt].wei = w;
edge[cnt].nexty = head[u];
head[u] = cnt;
}
void addedge2(int u, int v, int w) {
cnt2++;
edge2[cnt2].son = u;
edge2[cnt2].wei = w;
edge2[cnt2].nexty = head2[v];
head2[v] = cnt2;
}
int main() {
cin >> n >> m;
int u, v, w;
while (m--) {
cin >> u >> v >> w;
addedge(u, v, w);
addedge2(u, v, w);
}
for (int i = 0; i <= n; i++) {
dis1[i] = MAX;
dis2[i] = MAX;
}
memset(visited, 0, sizeof(visited));
int cur = 1;
dis1[cur] = 0;
while (!visited[cur]) {
visited[cur] = 1;
for (int i = head[cur]; i != 0; i = edge[i].nexty) {
if (!visited[edge[i].son] && dis1[edge[i].son] > dis1[cur] + edge[i].wei) {
dis1[edge[i].son] = dis1[cur] + edge[i].wei;
}
}
int minn = MAX;
for (int i = 1; i <= n; i++) {
if (!visited[i] && minn > dis1[i]) {
minn = dis1[i];
cur = i;
}
}
}
memset(visited, 0, sizeof(visited));
cur = 1;
dis2[cur] = 0;
while (!visited[cur]) {
visited[cur] = 1;
for (int i = head2[cur]; i != 0; i = edge2[i].nexty) {
if (!visited[edge2[i].son] && dis2[edge2[i].son] > dis2[cur] + edge2[i].wei) {
dis2[edge2[i].son] = dis2[cur] + edge2[i].wei;
}
}
int minn = MAX;
for (int i = 1; i <= n; i++) {
if (!visited[i] && minn > dis2[i]) {
minn = dis2[i];
cur = i;
}
}
}
int sum = 0;
for (int i = 1; i <= n; i++) {
sum += dis1[i] + dis2[i];
}
cout << sum << endl;
return 0;
}
最小生成树
克鲁斯卡尔思想:
首先将图中的边按权值由小到大排列,然后从列表中每次回帖一条边,并且要注意是否生成了环直到生成n-1条边
prime算法:
一个列表存储该点是否被选中,还有一个列表存储第i个顶点链接的边的最小值,一个数组存储选中了这个边的第i个节点的父节点
prime算法
#include<bits/stdc++.h>
using namespace std;
int read()
{
int x=0,f=1;char c=getchar();
while(c<'0'||c>'9'){if(c=='-') f=-1;c=getchar();}
while(c>='0'&&c<='9') x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*f;
}//快读,不理解的同学用cin代替即可
#define inf 123456789
#define maxn 5005
#define maxm 200005
struct edge
{
int v,w,next;
}e[maxm<<1];
//注意是无向图,开两倍数组
int head[maxn],dis[maxn],cnt,n,m,tot,now=1,ans;
//已经加入最小生成树的的点到没有加入的点的最短距离,比如说1和2号节点已经加入了最小生成树,那么dis[3]就等于min(1->3,2->3)
bool vis[maxn];
//链式前向星加边
void add(int u,int v,int w)
{
e[++cnt].v=v;
e[cnt].w=w;
e[cnt].next=head[u];
head[u]=cnt;
}
//读入数据
void init()
{
n=read(),m=read();
for(int i=1,u,v,w;i<=m;++i)
{
u=read(),v=read(),w=read();
add(u,v,w),add(v,u,w);
}
}
int prim()
{
//先把dis数组附为极大值
for(int i=2;i<=n;++i)
{
dis[i]=inf;
}
//这里要注意重边,所以要用到min
for(int i=head[1];i;i=e[i].next)
{
dis[e[i].v]=min(dis[e[i].v],e[i].w);
}
while(++tot<n)//最小生成树边数等于点数-1
{
int minn=inf;//把minn置为极大值
vis[now]=1;//标记点已经走过
//枚举每一个没有使用的点
//找出最小值作为新边
//注意这里不是枚举now点的所有连边,而是1~n
for(int i=1;i<=n;++i)
{
if(!vis[i]&&minn>dis[i])
{
minn=dis[i];
now=i;
}
}
ans+=minn;
//枚举now的所有连边,更新dis数组
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].v;
if(dis[v]>e[i].w&&!vis[v])
{
dis[v]=e[i].w;
}
}
}
return ans;
}
int main()
{
init();
printf("%d",prim());
return 0;
}
克鲁斯卡尔
#include<bits/stdc++.h>
using namespace std;
#define re register
#define il inline
il int read()
{
re int x=0,f=1;char c=getchar();
while(c<'0'||c>'9'){if(c=='-') f=-1;c=getchar();}
while(c>='0'&&c<='9') x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*f;
}
struct Edge
{
int u,v,w;
}edge[200005];
int fa[5005],n,m,ans,eu,ev,cnt;
il bool cmp(Edge a,Edge b)
{
return a.w<b.w;
}
//快排的依据(按边权排序)
il int find(int x)
{
while(x!=fa[x]) x=fa[x]=fa[fa[x]];
return x;
}
//并查集循环实现模板,及路径压缩,不懂并查集的同学可以戳一戳代码上方的“并查集详解”
il void kruskal()
{
sort(edge,edge+m,cmp);
//将边的权值排序
for(re int i=0;i<m;i++)
{
eu=find(edge[i].u), ev=find(edge[i].v);
if(eu==ev)
{
continue;
}
//若出现两个点已经联通了,则说明这一条边不需要了
ans+=edge[i].w;
//将此边权计入答案
fa[ev]=eu;
//将eu、ev合并
if(++cnt==n-1)
{
break;
}
//循环结束条件,及边数为点数减一时
}
}
int main()
{
n=read(),m=read();
for(re int i=1;i<=n;i++)
{
fa[i]=i;
}
//初始化并查集
for(re int i=0;i<m;i++)
{
edge[i].u=read(),edge[i].v=read(),edge[i].w=read();
}
kruskal();
printf("%d",ans);
return 0;
}
kruskal
#include<bits/stdc++.h>
using namespace std;
struct Edge
{
int u,v,w;
}edge[200005];
int fa[5005], n, m, ans, eu, ev, cnt;
bool cmp(Edge a, Edge b) {
return a.w < b.w;
}
int find(int x) {
while (x != fa[x])
x = fa[x] = fa[fa[x]];
return x;
}
void kruskal() {
sort(edge, edge + m, cmp);
for (int i = 0; i < m; i++) {
eu = find(edge[i].u);
ev = find(edge[i].v);
if (eu == ev) {
continue;
}
ans += edge[i].w;
fa[ev] = eu;
if (++cnt == n - 1) {
cout << ans;
return;
}
}
cout << "orz" << endl;
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; i++) {
fa[i] = i;
}
for (int i = 0; i < m; i++) {
cin >> edge[i].u;
cin >> edge[i].v;
cin >> edge[i].w;
}
kruskal();
return 0;
}
排序
P1177 【模板】排序
洛谷排序模板题
想都不想直接sort,sort还挺快
#include<bits/stdc++.h>
using namespace std;
int a[100005];
int main(){
int n;
cin>>n;
for(int i=0;i<n;i++){
cin>>a[i];
}
sort(a,a+n);
for(int i=0;i<n;i++){
cout<<a[i]<<" ";
}
return 0;
}
P1923 【深基9.例4】求第 k 小的数
这个第一反应就用sort,but第一次交的时候就过仨点,后俩点TLE。然后人家说用scanf和prinf。这就AC了,行吧,下次就用scanf和printf
#include<bits/stdc++.h>
using namespace std;
int a[5000005];
int main(){
int n,k;
scanf("%d%d",&n,&k);
// cin>>n>>k;
for(int i=0;i<n;i++){
// cin>>a[i];
scanf("%d",&a[i]);
}
sort(a,a+n);
// cout<<a[k];
printf("%d",a[k]);
return 0;
}
趁这个题把这俩函数的用法捡起来把
printf函数
printf("字符串");
printf("字符串占位符",a);
常用的格式符

看这个表,下次遇到进制转换类的问题,就可以直接使用printf完成了
格式控制
使用%nd控制输出的宽度
//控制输出的宽度为4,不够的在前面填空格
printf("%4d",1)
//控制输出宽度为4不够的向后面填空格,这个结果就是1跟后面的.相距4个字符宽
printf("%-4d".,1)
浮点数输出控制
printf("%f",179.96f);
当没有加限制的时候默认是6位小数
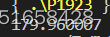
//这里保留1位小数(四舍五入)
printf("%.1f",179.96f);

//同时设置宽度和小数点位数
printf("%8.1f",179.96f);
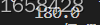
scanf用法
接收三个数用-隔开
scanf("%d-%d-%d",&a,&b,&c);
P1093 [NOIP2007 普及组] 奖学金
这个题也是是排序的,第一反应用sort但是这个使用结构体存储的,我们要对结构体进行排序,先学习一下sort:
它有三个参数sort(begin, end, cmp),其中begin为指向待sort()的数组的第一个元素的指针,end为指向待sort()的数组的最后一个元素的下一个位置的指针,cmp参数为排序准则,cmp参数可以不写,如果不写的话,默认从小到大进行排序。如果我们想从大到小排序可以将cmp参数写为greater()就是对int数组进行排序,当然<>中我们也可以写double、long、float等等。如果我们需要按照其他的排序准则,那么就需要我们自己定义一个bool类型的函数来传入。
原文链接:https://blog.csdn.net/qq_41575507/article/details/105936466
可以知道sort可以自定义排序规则,cmp函数可以写成cmp(a,b)return a>b这样就可以按从大到小排序:可以理解为a排在b前面返回true
bool cmp(stu a,stu b){ //比较a和b,如果a>b(a在b前面)返回ture
if(a.sum>b.sum) return true;
else if(a.sum==b.sum && a.ch>b.ch) return true;
else if(a.sum==b.sum && a.ch==b.ch && a.id<b.id) return true;
else return false;
}
暴力枚举
P2241 统计方形(数据加强版)
这个可以画图示意一下。对于正方形的个数,可以考虑当边长为1、2…min(m,n)可以知道当边长为i的时候正方形的个数为(m-i+1)(n-i+1)其中i从1到min(n,m)。对于长方形可以先不考虑排除正方形,以i,j为左上顶点的长方形的个数为(m-i+1)(n-j+1)这里i从1到m,j从1到n,然后算出所有长方形和正方形的个数之后减去正方形个数就可以得到长方形的个数
#include<bits/stdc++.h>
using namespace std;
int main(){
int m,n;
cin>>m>>n;
int zheng=0,chang=0;
int minn = min(m,n);
for(int i=1;i<=minn;i++){
zheng+=(m-i+1)*(n-i+1);
}
int sum1=0,sum2=0;
chang = sum1*sum2;
for(int i=1;i<=m;i++){
for(int j=1;j<=n;j++){
chang += (m-i+1)*(n-j+1);
}
}
chang = chang-zheng;
cout<<zheng<<" "<<chang<<endl;
return 0;
}
只有40,另外6个测试点WA,咋都卡不出错,感觉逻辑也没啥问题啊!!然后看人家的思路,跟我的差不了多少,然后自己写还是那6个wa,仔细一看,人家用的long long,数据范围是n和m<=5000,m*n<=25000000,2的8次方,int最大到2的9次方还要求和有点危险,要用longlong。注意数据范围
递归
P1044 [NOIP2003 普及组] 栈
这个题首先可以用深搜diamante与注释如下
#include<bits/stdc++.h>
using namespace std;
int ans [20][20]; //ans[i][j]表示当队列里面有i个数,栈里面有j个数的时候的种类数
//深搜思路:ans[i][j]表示当队列里面有i个数,栈里面有j个数的时候可能的数
//当队列里面0个数的时候,表示全部在栈里或者弹出,ans[0][i]=1
//向下继续思考,当队列里面有1个数栈里面有0个ans[1][0]只有一种情况ans[1][0]=1;当队列里面有1个数栈里面有1个数,ans[1][1]的可能情况
//ans[i][j]的可能个数等于队列里有i个数,栈里面有j+1个数
int dfs(int i,int j){
if(ans[i][j]>0)
return ans[i][j];
if(i==0)
return 1;
if(j>0) ans[i][j]+=dfs(i,j-1);
ans[i][j]+=dfs(i-1,j+1);
return ans[i][j];
}
int main(){
int n;
cin>>n;
cout<<dfs(n,0);
return 0;
}
看解析可以用卡特兰数,其基本思想是对于数组f[i]的意义是i个数的可能性,设x为当前出栈的最后一个,x有n种取值,可以将已经出栈的数分为两部分:比x大和比x小的在该题中,比x小的有x-1个,比x大的有n-x个,一个x的可能取值有f[x-1]*f[n-x]种,ans = f[0]*f[n-1]+f[1]*f[n-2]+…+f[n-1]*f[0]
LeeCode刷题
LeeCode解析做的是尊滴不错,但是没有输入输出,用的真难受!!!写一题就回到洛谷了
3、无重复字符的最长字串
该题用到了unordered_set容器,下面对该容器进行简单的了解http://c.biancheng.net/view/7250.html
unordered_set 容器具有以下几个特性:
不再以键值对的形式存储数据,而是直接存储数据的值;
容器内部存储的各个元素的值都互不相等,且不能被修改。
不会对内部存储的数据进行排序
创建容器
std::unordered_set<std::string> uset;
std::unordered_set<std::string> uset{ "http://c.biancheng.net/c/",
"http://c.biancheng.net/java/",
"http://c.biancheng.net/linux/" };
剩下的操作可以访问上面的链接
基本思想是使用滑动窗口方法,定义一个unordered_set容器,将其作为滑动窗口,使用左右只针的方法。首先左指针指向第一个元素,然后不断的移动右指针(使用向容器中添加元素的方法,首先判断要进入的元素在容器中有没有,如果没有的话,直接inert进去,如果有的话,就停止不加入,通过右指针和左指针的下标判断这个序列的长度),然后当以该字母为开头的最长不重复字符串找完之后,左指针右移进行相同的操作,最后返回最大的值














 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









