







654.最大二叉树 5min搞定,但我写的虽然逻辑比较清楚但不够优化(用了额外的vec而不是在上面直接操作),后来又优化一下。第一版:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
if(nums.size()==0) return nullptr;
int maxv=INT_MIN;
for(auto ele:nums){
maxv=ele>maxv?ele:maxv;
}
auto mid=std::find(nums.begin(),nums.end(),maxv);
vector<int> leftv(nums.begin(),mid);
vector<int> rightv(mid+1,nums.end());
auto leftc=constructMaximumBinaryTree(leftv);
auto rightc=constructMaximumBinaryTree(rightv);
TreeNode* root= new TreeNode(maxv,leftc, rightc);
return root;
}优化1:但其实不如直接找max value的index,我这样好麻烦。然后做的时候有个错误:
一开始写的是nums.size()==0,不对,应该是if(l_idx >= r_idx) return nullptr;
TreeNode* helper(vector<int>& nums, int l_idx, int r_idx){//left include, right exclude
if(l_idx >= r_idx) return nullptr;
int maxv = INT_MIN;
for(int i = l_idx; i < r_idx; i++){
maxv = max(maxv, nums[i]);
}
auto mid = std::find(nums.begin() + l_idx, nums.begin() + r_idx, maxv);
TreeNode* root = new TreeNode(maxv);
root->left = helper(nums, l_idx, mid - nums.begin());
root->right = helper(nums, mid - nums.begin() + 1, r_idx);
return root;
}
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return helper(nums, 0, nums.size());
}更好的,直接求max index的这样写:
TreeNode* helper(vector<int>& nums, int l_idx, int r_idx) {
if (l_idx >= r_idx) return nullptr;
int max_idx = l_idx;
for (int i = l_idx + 1; i < r_idx; ++i) {
if (nums[i] > nums[max_idx]) {
max_idx = i;
}
}
TreeNode* root = new TreeNode(nums[max_idx]);
root->left = helper(nums, l_idx, max_idx);
root->right = helper(nums, max_idx + 1, r_idx);
return root;
}
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
return helper(nums, 0, nums.size());
}617 合并二叉树 经典,第一次做感觉不简单
我一开始写了个这样的代码,问题很大(下面这个是错的)。我的反思是,既然是递归,就不要尝试在一层的逻辑里处理node,left,right三个,也不应该是在该层处理left和right的值,应该是处理node的,左右孩子留给下一层。另外这道题的helper用node做为return明显比用void好
//复杂的错误代码
void traverse(TreeNode* node1, TreeNode* node2){
//merge on tree1
if(node1->left!=nullptr && node2->left!=nullptr) node1->left->val+=node2->left->val;
if(node1->right && node2->right) node1->right->val+=node2->right->val;
if(node2->left) node1->left=node2->left;
if(node2->right) node1->right=node2->right;
//for traverse, not for merge
if(node1->left) node2->left=node1->left;
if(node1->right) node2->right=node1->right;
//till then, both left right child exist
traverse(node1->left,node2->left);
traverse(node1->right,node2->right);
}
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if(root1==nullptr) return root2;
if(root2==nullptr) return root1;
traverse(root1,root2);
return root1;
}改成这样就对了
TreeNode* merge(TreeNode* node1, TreeNode* node2) {
if (node1 == nullptr && node2 == nullptr) {
return nullptr;
} else if (node1 == nullptr) {
return node2;
} else if (node2 == nullptr) {
return node1;
} else {
node1->val+=node2->val;
node1->left=merge(node1->left, node2->left);
node1->right=merge(node1->right, node2->right);
return node1;
}
}
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
return merge(root1, root2);
}
更简洁更好的:前中后序都行
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if (root1 == nullptr) return root2;
if (root2 == nullptr) return root1;
root1->val += root2->val;
root1->left = mergeTrees(root1->left, root2->left);
root1->right = mergeTrees(root1->right, root2->right);
//注意这三句这里前中后序都行
return root1;
}用层序遍历的迭代也很好(随想录的代码),关键是两个tree的node都要同时加入queue进行比较和相加之类的:
TreeNode* mergeTrees(TreeNode* t1, TreeNode* t2) {
if (t1 == NULL) return t2;
if (t2 == NULL) return t1;
queue<TreeNode*> que;
que.push(t1);
que.push(t2);
while(!que.empty()) {
TreeNode* node1 = que.front(); que.pop();
TreeNode* node2 = que.front(); que.pop();
// 此时两个节点一定不为空,val相加
node1->val += node2->val;
// 如果两棵树左节点都不为空,加入队列
if (node1->left != NULL && node2->left != NULL) {
que.push(node1->left);
que.push(node2->left);
}
// 如果两棵树右节点都不为空,加入队列
if (node1->right != NULL && node2->right != NULL) {
que.push(node1->right);
que.push(node2->right);
}
// 当t1的左节点 为空 t2左节点不为空,就赋值过去
if (node1->left == NULL && node2->left != NULL) {
node1->left = node2->left;
}
// 当t1的右节点 为空 t2右节点不为空,就赋值过去
if (node1->right == NULL && node2->right != NULL) {
node1->right = node2->right;
}
}
return t1;
}
曾有困惑为什么把空的填上之后就不push了,因为push是为了放到queue再拿出来合并,这里把不空的赋值了,就已经完成了合并。而且既然那个原来都是空的了,把它变成不是空的之后,也不用接着遍历往下走了。
【随想录还有个办法是用**的指针操作,我这一遍暂时放过,不学了。】
700 搜索二叉树 递归2min出来
TreeNode* searchBST(TreeNode* root, int val) {
if(root==nullptr) return nullptr;
if(root->val==val) return root;
if(root->val>val) return searchBST(root->left, val);
if(root->val<val) return searchBST(root->right, val);
return nullptr;
}迭代也2min出来:
TreeNode* searchBST(TreeNode* root, int val) {
stack<TreeNode*> mys;
if(root) mys.push(root);
while(!mys.empty()){
auto node=mys.top();
mys.pop();
if(node==nullptr || node->val==val) return node;
if(node->val>val) mys.push(node->left);
if(node->val<val) mys.push(node->right);
}
return root;
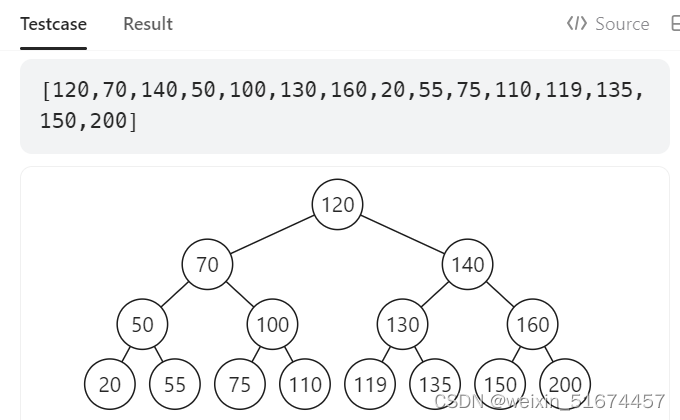
}98 Validate Binary Search Tree 这题弄了我一个多小时
本题最大的陷阱:不能单纯的比较左节点小于中间节点,右节点大于中间节点就完事了
这是一个错误做法,底下那个test case 120 和 119那里就不对,我最开始写的代码没考虑到那个情况
bool helper(TreeNode* root, int grand){
if(root==nullptr) return true;
if(root->left&&(root->left->val>root->val||root->left->val==root->val)) return false;
if(root->right&&(root->right->val<root->val||root->right->val==root->val)) return false;
if(root->val > grand &&root->left && (root->left->val<grand||root->left->val==grand)) return false;
if(root->val < grand &&root->right && (root->right->val>grand||root->right->val==grand)) return false;
grand=root->val;
return helper(root->left,grand) && helper(root->right,grand);
}
bool isValidBST(TreeNode* root) {
return helper(root, root->val);
}
然后和gpt一起理解分析我这个思路,给修改对了。下面是修改后的。但还是感觉我这个思路过于复杂,容易出错。
犯错了,修改了的地方:
1.那些max min初始化全都应该是 min max值而不是 root val。
2. 每轮求max min的时候是和root val比较,不是和 longmin之类的
3.这个根据testcase是可以找出来的,就是case里有int的最小值,所以不能用int_min那些,全改成long,对应的type也都要改成long
bool helper(TreeNode* root, long &max, long &min){
if(root == nullptr) return true;
long max_left = LONG_MIN, max_right = LONG_MIN;
long min_left = LONG_MAX, min_right = LONG_MAX;
bool left_yes = helper(root->left, max_left, min_left);
bool right_yes = helper(root->right, max_right, min_right);
max = std::max(max_right, (long)root->val);
min = std::min(min_left, (long)root->val);
if(max_left < root->val && root->val < min_right && left_yes && right_yes)
return true;
else
return false;
}
bool isValidBST(TreeNode* root) {
long max = LONG_MIN;
long min = LONG_MAX;
return helper(root, max, min);
}现在我们来看随想录的思路:
思路一:利用中序遍历的性质:输出的二叉搜索树节点的数值是有序序列。验证二叉搜索树,就相当于变成了判断一个序列是不是递增的了。直接中序的递归模板+检查order
vector<int> vec;
void traversal(TreeNode* root) {
if (root == NULL) return;
traversal(root->left);
vec.push_back(root->val); // 将二叉搜索树转换为有序数组
traversal(root->right);
}
bool isValidBST(TreeNode* root) {
vec.clear(); // 不加这句在leetcode上也可以过,但最好加上
traversal(root);
for (int i = 1; i < vec.size(); i++) {
// 注意要小于等于,搜索树里不能有相同元素
if (vec[i] <= vec[i - 1]) return false;
}
return true;
}思路二:类似1,但是不用放到vec里,边遍历边比较
TreeNode* pre = NULL; // 用来记录前一个节点
bool isValidBST(TreeNode* root) {
if (root == NULL) return true;
bool left = isValidBST(root->left);
if (pre != NULL && pre->val >= root->val) return false;
pre = root; // 记录前一个节点
bool right = isValidBST(root->right);
return left && right;
}思路三:也是中序,检查顺序,套dfs迭代模板
bool isValidBST(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
TreeNode* pre = NULL; // 记录前一个节点
while (cur != NULL || !st.empty()) {
if (cur != NULL) {
st.push(cur);
cur = cur->left; // 左
} else {
cur = st.top(); // 中
st.pop();
if (pre != NULL && cur->val <= pre->val)
return false;
pre = cur; //保存前一个访问的结点
cur = cur->right; // 右
}
}
return true;
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









