






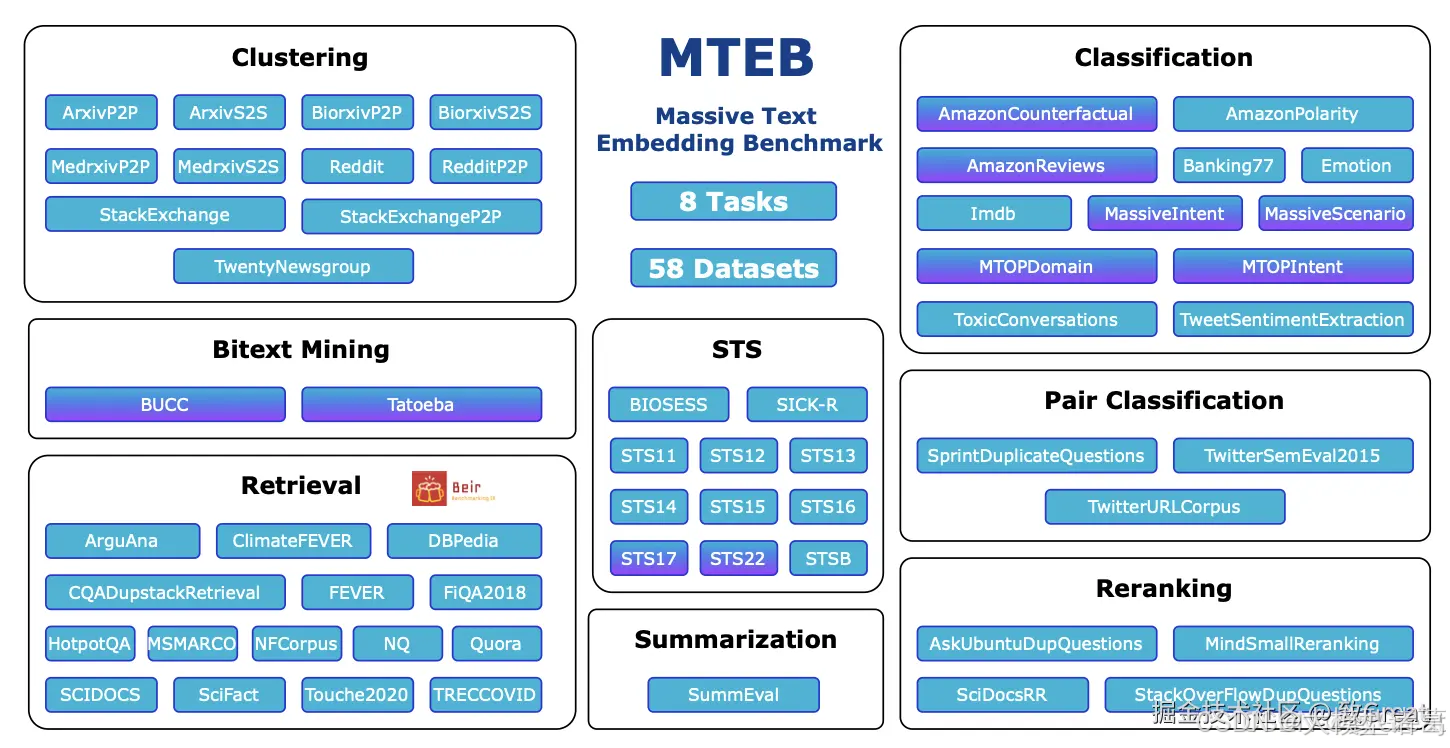
MTEB 是一个包含广泛文本嵌入(Text Embedding)的基准测试,它提供了多种语言的数十个数据集,用于各种 NLP 任务,例如文本分类、聚类、检索和文本相似性。MTEB 提供了一个公共排行榜,允许研究人员提交他们的结果并跟踪他们的进展。MTEB 还提供了一个简单的 API,允许研究人员轻松地将他们的模型与基准测试进行比较。
MTEB 包含以下 8 种任务类型:
- Bitext Mining :寻找两种语言句子集之间的最佳匹配。输入是来自两种不同语言的两个句子集,对于来自第一个句子集的句子,找到在第二个子集中最匹配的句子。模型将句子编码成向量后用余弦相似度来寻找最相似的句子对。F1是主要的评估指标、Accuracy、precision、recall也一并计算了。
- Classification :使用嵌入模型训练逻辑回归分类器。训练集和测试集通过给定模型编码,测试集向量被用来训练一个LR分类器(最多100次迭代),然后使用测试集来打分,主要评估指标是accuracy with average precision,同时包括F1。
- Clustering :将句子或段落分组为有意义的簇。给定句子集或段落集,将其分组为有意义的簇。在编码后的文档上训练一个 mini-batch k-means 模型(batch size为32, k是不同标签的个数),然后使用v-meature为模型打分。
- Pair Classification :为一对文本输入分配标签,通常是二元变量,表示重复或释义对。输入是一对带标签的文本,两个文本被编码后计算多种距离:cosine similarity, dot product, euclidean distance, manhattan distance。接着使用最佳阈值来计算accuracy, average precision, f1, precision, recall。基于余弦相似度的平均精度是主要指标。
- Reranking :根据与查询的相关性对结果进行重新排序。输入是一个查询语句以及一个包含相关和不相关文本的列表。模型编码文本后比较与查询语句的余弦相似性。每个查询语句的分数都被计算并平均所有查询语句的分数。指标有平均 M R R @ k MRR@kMRR@k和MAP(主要指标)
- Retrieval :找到相关文档。每个数据集包括一个语料集,查询语句及其与语料中的相关文档的映射。模型编码所有查询语句和语料文档之后计算余弦相似度,对每一个查询语句的结果排序后计算k的多个取值所对应的nDCG@k, MRR@k, MAP@k, precision@k , recall@k。使用BEIR相同的设置,nDCG@10是主要指标。
- Semantic Textual Similarity (STS) :确定句子对的相似性。给定句子对计算它们的相似度,标签是连续得分(越大相似度越高)。模型编码句子后计算使用不同的距离指标计算它们的相似性,计算好的距离与标签相似度基准比较Pearson和Spearman相关性。主要指标是基于余弦相似度的Spearma
- Summarization :评估机器生成的摘要。包括一个手写摘要和机器生成摘要数据集,目标是给机器生成摘要打分。模型编码所有摘要,然后对于每一个机器生成摘要向量,计算其与所有手写摘要向量的距离,将相似度最大的分数作为单个机器生成摘要的分数,接下来与基准比较计算Pearson和Spearman相关性。主要指标是基于余弦相似度的Spearman相关性。
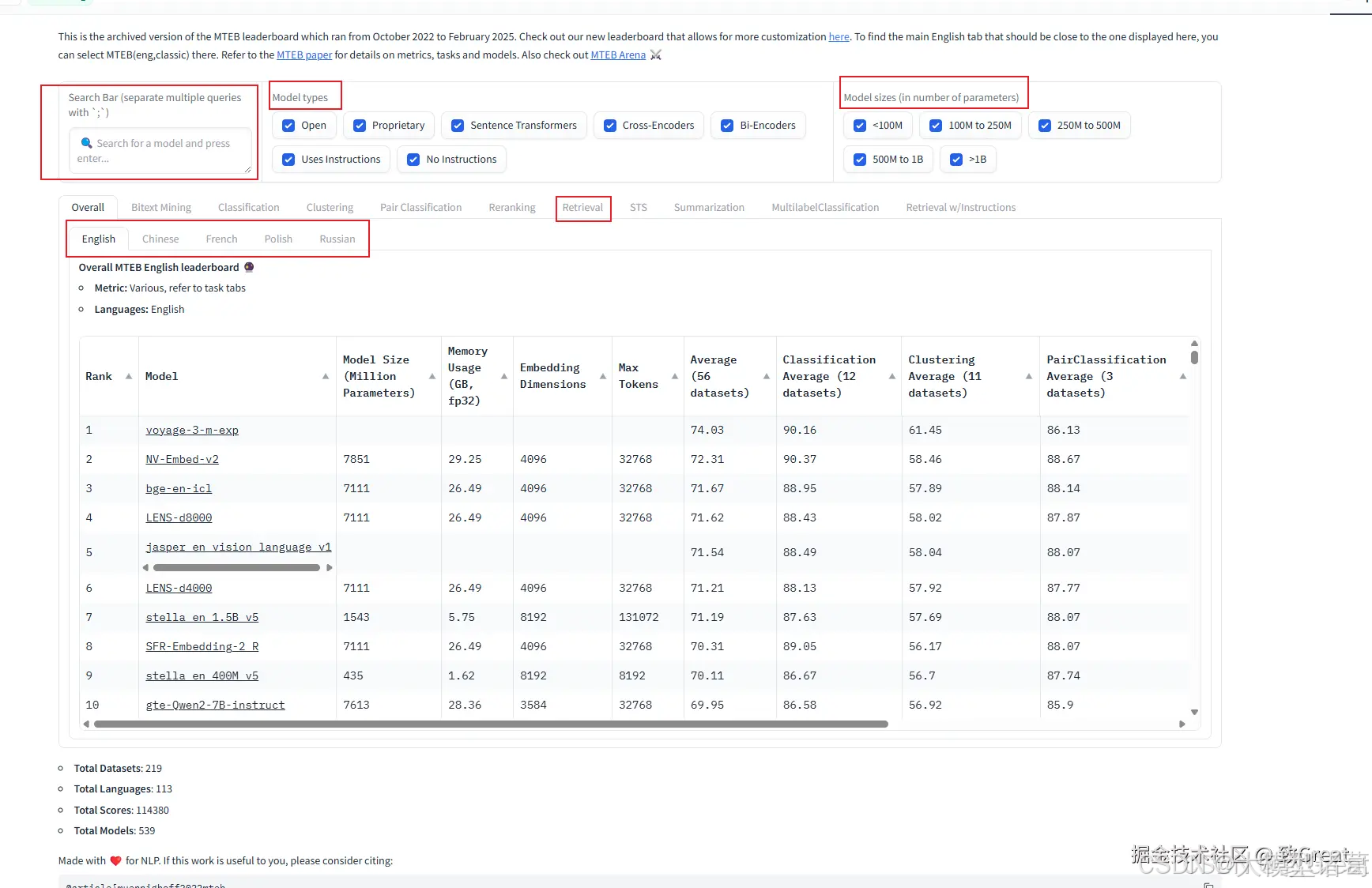
下面我们以旧版本为例(其中有中文等语言的筛选),看下榜单怎么快速筛序我们想要的模型
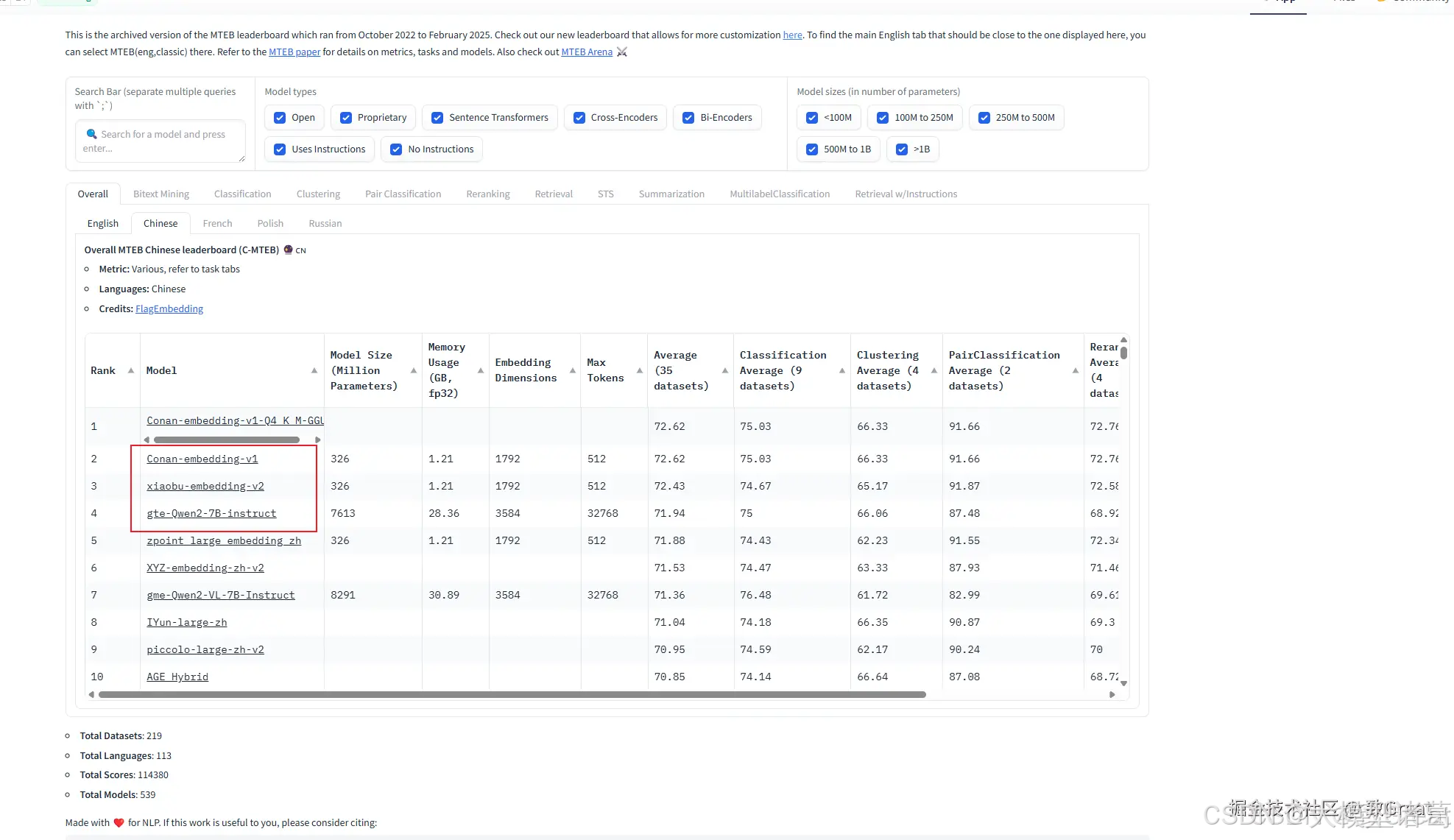
我们可以在搜索框里面输入模型名字以及关键词进行快速筛选,同时可以结合模型类型以及模型大小进行过滤,下面一栏是可以筛切换语言种类和具体任务榜单,下面是中文模型的模型排行:
考虑因素
有同学也有反应MTEB榜单可能存在过拟合的现象,我们可以尽量选取前面的模型,结合使用或者下载量来选择比较靠谱的模型。
除了排行榜,模型的以下特性也需考虑:
-
模型大小: 影响计算资源需求和延迟。例如,较大的模型如 gte-Qwen2-7B-instruct(7 亿参数)可能更适合复杂任务,但计算成本更高。
-
嵌入维度: 维度较低的模型(如 384 维的 all-MiniLM-L6-v2)存储和比较更快,但可能牺牲语义捕捉能力。
-
语言支持: 多语言模型如 multilingal-e5-large 适合跨语言应用,而单语言模型可能在特定语言上表现更好。
-
预训练与微调: 预训练模型如 intfloat/e5-large-v2 适合通用场景,领域特定模型如 PubMedBERT(医学领域)则需微调以适应特定数据。
-
存储和内存等资源需求: 高维向量需要更多的存储空间,这可能会带来长期成本。例如,较高维度的模型如 text-embedding-ada-002 需要更多的存储资源。另外,较大的模型可能会占用更多内存,因此不适合内存有限的设备。
-
推理时间: 如果你的应用场景对响应时间有高要求,需要选择在推理时速度较快的模型。
-
模型在特定领域的表现: 通用 Embedding 模型在特定垂直领域(如医学、法律和金融等)可能不如专用模型有效。这些领域通常需要专门训练 Embedding 模型来捕捉特定的专业术语和语境。为特定业务需求优化的 Embedding 模型能够显著提升检索和生成的质量。例如,通过结合向量检索和重排序(reranking)技术,可以进一步优化结果。
-
处理长文本的能力: 切分的文本片段后续需要通过 Embedding 模型进行向量化,所以必须考虑向量模型对输入文本块的 tokens 长度限制,超出这个限制则会导致模型对文本进行截断,从而丢失信息,影响下游任务的性能。不同的 Embedding 模型对文本块长度的支持能力不同。比如,BERT 及其变体通常支持最多 512 个tokens,处理长文本时则需要将文本分成更小的块,意味着需要更加精细化的分块策略。而 Jina AI 的 Embedding 模型和 bge-m3 模型则支持 8K 的 tokens 输入,适合处理长文本块。
-
模型的可扩展性与易用性 : 微调和更新的能力:对于一个不断迭代的RAG系统,选择一个能够轻松微调和持续更新的模型至关重要。比如Hugging Face的Transformers库、FlaggEmbedding提供了便捷的微调工具。模型是否易于集成进现有的RAG架构?文档是否清晰?社区支持如何?
-
成本与可用性: 开源模型(如 E5 系列)免费,专有模型(如 OpenAI 的 text-embedding-3-large)可能涉及 API 费用和隐私问题
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以在文末CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享

AI产品经理,0基础小白入门指南
作为一个零基础小白,如何做到真正的入局AI产品?
什么才叫真正的入局?
是否懂 AI、是否懂产品经理,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
你是否遇到这些问题:
1、传统产品经理
不懂Al无法对AI产品做出判断,和技术沟通丧失话语权
不了解 AI产品经理的工作流程、重点
2、互联网业务负责人/运营
对AI焦虑,又不知道怎么落地到业务中想做定制化AI产品并落地创收缺乏实战指导
3、大学生/小白
就业难,不懂技术不知如何从事AI产品经理想要进入AI赛道,缺乏职业发展规划,感觉遥不可及
为了帮助开发者打破壁垒,快速了解AI产品经理核心技术原理,学习相关AI产品经理,及大模型技术。从原理出发真正入局AI产品经理。
这里整理了一些AI产品经理学习资料包给大家
📖AI产品经理经典面试八股文
📖大模型RAG经验面试题
📖大模型LLMS面试宝典
📖大模型典型示范应用案例集99个
📖AI产品经理入门书籍
📖生成式AI商业落地白皮书
🔥作为AI产品经理,不仅要懂行业发展方向,也要懂AI技术,可以帮助大家:
✅深入了解大语言模型商业应用,快速掌握AI产品技能
✅掌握AI算法原理与未来趋势,提升多模态AI领域工作能力
✅实战案例与技巧分享,避免产品开发弯路
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
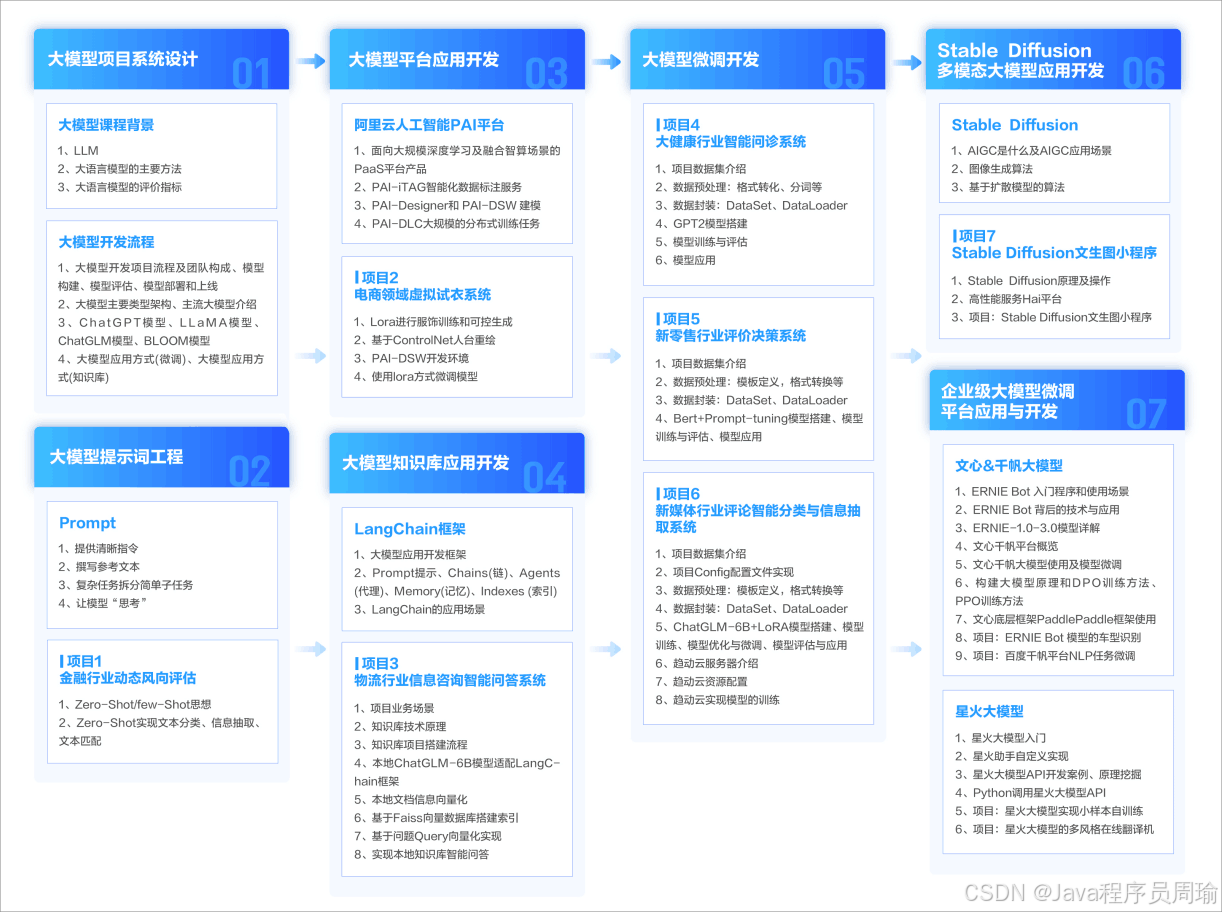
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享免费领取【保证100%免费】🆓


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









