







目录
多对多(ManyToManyField):在第三张关系表中新增数据
前言
django ORM 查询常用操作--随手记
一、单表实例
1、增删查改
1.1增:
方式一:并且实例化对象后要执行 对象.save() 才能在数据库中新增成功。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
book = models.Book(title="ORM教程",price=300,publish="XX出版社",pub_date="2023-04-17")
book.save()
return HttpResponse("<p>数据添加成功!</p>")
方式二:通过 ORM 提供的 objects 提供的方法 create 来实现(推荐)
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.create(title="如来神掌",price=200,publish="XX出版社",pub_date="2023-04-17")
print(books, type(books)) # Book object (18)
return HttpResponse("<p>数据添加成功!</p>")
方式三:批量插入 bulk_create
from django.shortcuts import render,HttpResponse
from app01 import models
def add_bulk_book(request):
for i in range(1000):
student = Stduent(id=xxx,title=xxx,price=xxx,publish='xx出版社',)
student_list.append(student_list)
models.Book.objects.bulk_create(student_list, batch_size=2000)# batch_size 参数值不知道多少时批量插入最快,知道请留言 感谢大佬
return HttpResponse("<p>批量添加成功!</p>")1.2 删
方式一:使用模型类的 对象.delete()。
返回值:元组,第一个元素为受影响的行数。
books=models.Book.objects.filter(pk=8).first().delete()方式二:使用 QuerySet 类型数据.delete()(推荐)
返回值:元组,第一个元素为受影响的行数。
books=models.Book.objects.filter(pk__in=[1,2]).delete()1.3 查
all() 使用 all() 方法来查询所有内容。
返回的是 QuerySet 类型数据,类似于 list,里面放的是一个个模型类的对象,可用索引下标取出模型类的对象。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.all()
print(books,type(books)) # QuerySet类型,类似于list,访问 url 时数据显示在命令行窗口中。
return HttpResponse("<p>查找成功!</p>")
filter() 方法用于查询符合条件的数据。
返回的是 QuerySet 类型数据,类似于 list,里面放的是满足条件的模型类的对象,可用索引下标取出模型类的对象。
pk=3 的意思是主键 primary key=3,相当于 id=3。
因为 id 在 pycharm 里有特殊含义,是看内存地址的内置函数 id(),因此用 pk。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.filter(pk=5)
print(books)
print("//")
books = models.Book.objects.filter(publish='XX出版社', price=300)
print(books, type(books)) # QuerySet类型,类似于list。
return HttpResponse("<p>查找成功!</p>")
exclude() 方法用于查询不符合条件的数据。
返回的是 QuerySet 类型数据,类似于 list,里面放的是不满足条件的模型类的对象,可用索引下标取出模型类的对象。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.exclude(pk=5)
print(books)
print("//")
books = models.Book.objects.exclude(publish='xx出版社', price=300)
print(books, type(books)) # QuerySet类型,类似于list。
return HttpResponse("<p>查找成功!</p>")
get() 方法用于查询符合条件的返回模型类的对象符合条件的对象只能为一个,如果符合筛选条件的对象超过了一个或者没有一个都会抛出错误。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.get(pk=5)
books = models.Book.objects.get(pk=18) # 报错,没有符合条件的对象
books = models.Book.objects.get(price=200) # 报错,符合条件的对象超过一个
print(books, type(books)) # 模型类的对象
return HttpResponse("<p>查找成功!</p>")
order_by() 方法用于对查询结果进行排序。
返回的是 QuerySet类型数据,类似于list,里面放的是排序后的模型类的对象,可用索引下标取出模型类的对象。
注意:
- a、参数的字段名要加引号。
- b、降序为在字段前面加个负号 -。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.order_by("price") # 查询所有,按照价格升序排列
books = models.Book.objects.order_by("-price") # 查询所有,按照价格降序排列
return HttpResponse("<p>查找成功!</p>")
reverse() 方法用于对查询结果进行反转。
返回的是 QuerySe t类型数据,类似于 list,里面放的是反转后的模型类的对象,可用索引下标取出模型类的对象。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
# 按照价格升序排列:降序再反转
books = models.Book.objects.order_by("-price").reverse()
return HttpResponse("<p>查找成功!</p>")
count() 方法用于查询数据的数量返回的数据是整数。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.count() # 查询所有数据的数量
books = models.Book.objects.filter(price=200).count() # 查询符合条件数据的数量
return HttpResponse("<p>查找成功!</p>")
first() 方法返回第一条数据返回的数据是模型类的对象也可以用索引下标 [0]。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.first() # 返回所有数据的第一条数据
return HttpResponse("<p>查找成功!</p>")
last() 方法返回最后一条数据返回的数据是模型类的对象不能用索引下标 [-1],ORM 没有逆序索引
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.last() # 返回所有数据的最后一条数据
return HttpResponse("<p>查找成功!</p>")
exists() 方法用于判断查询的结果 QuerySet 列表里是否有数据。
返回的数据类型是布尔,有为 true,没有为 false。
注意:判断的数据类型只能为 QuerySet 类型数据,不能为整型和模型类的对象。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.exists()
# 报错,判断的数据类型只能为QuerySet类型数据,不能为整型
books = models.Book.objects.count().exists()
# 报错,判断的数据类型只能为QuerySet类型数据,不能为模型类对象
books = models.Book.objects.first().exists()
return HttpResponse("<p>查找成功!</p>")values() 方法用于查询部分字段的数据。
返回的是 QuerySet 类型数据,类似于 list,里面不是模型类的对象,而是一个可迭代的字典序列,字典里的键是字段,值是数据。
注意:
- 参数的字段名要加引号
- 想要字段名和数据用 values
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
# 查询所有的id字段和price字段的数据
books = models.Book.objects.values("pk","price")
print(books[0]["price"],type(books)) # 得到的是第一条记录的price字段的数据
return HttpResponse("<p>查找成功!</p>")values_list() 方法用于查询部分字段的数据。
返回的是 QuerySet 类型数据,类似于 list,里面不是模型类的对象,而是一个个元组,元组里放的是查询字段对应的数据。
注意:
- 参数的字段名要加引号
- 只想要数据用 values_list
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
# 查询所有的price字段和publish字段的数据
books = models.Book.objects.values_list("price","publish")
print(books)
print(books[0][0],type(books)) # 得到的是第一条记录的price字段的数据
return HttpResponse("<p>查找成功!</p>")distinct() 方法用于对数据进行去重。
返回的是 QuerySet 类型数据。
注意:
- 对模型类的对象去重没有意义,因为每个对象都是一个不一样的存在。
- distinct() 一般是联合 values 或者 values_list 使用。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
# 查询一共有多少个出版社
books = models.Book.objects.values_list("publish").distinct() # 对模型类的对象去重没有意义,因为每个对象都是一个不一样的存在。
books = models.Book.objects.distinct()
return HttpResponse("<p>查找成功!</p>")filter() 方法基于双下划线的模糊查询(exclude 同理)。
注意:filter 中运算符号只能使用等于号 = ,不能使用大于号 > ,小于号 < ,等等其他符号。
__in 用于读取区间,= 号后面为列表 。
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
# 查询价格为200或者300的数据
books = models.Book.objects.filter(price__in=[200,300])
return HttpResponse("<p>查找成功!</p>")__gt 大于号 ,= 号后面为数字。
# 查询价格大于200的数据
books = models.Book.objects.filter(price__gt=200)__gte 大于等于,= 号后面为数字。
# 查询价格大于等于200的数据
books = models.Book.objects.filter(price__gte=200)__lt 小于,=号后面为数字。
# 查询价格小于300的数据
books=models.Book.objects.filter(price__lt=300)__lte 小于等于,= 号后面为数字。
# 查询价格小于等于300的数据
books=models.Book.objects.filter(price__lte=300)__range 在 ... 之间,左闭右闭区间,= 号后面为两个元素的列表。
books=models.Book.objects.filter(price__range=[200,300])__contains 包含,= 号后面为字符串。
books=models.Book.objects.filter(title__contains="功")__icontains 不区分大小写的包含,= 号后面为字符串。
books=models.Book.objects.filter(title__icontains="python") # 不区分大小写__startswith 以指定字符开头,= 号后面为字符串。
books=models.Book.objects.filter(title__startswith="x")__endswith 以指定字符结尾,= 号后面为字符串。
books=models.Book.objects.filter(title__endswith="教程")__year 是 DateField 数据类型的年份,= 号后面为数字。
books=models.Book.objects.filter(pub_date__year=2023) __month 是DateField 数据类型的月份,= 号后面为数字。
books=models.Book.objects.filter(pub_date__month=10) __day 是DateField 数据类型的天数,= 号后面为数字。
books=models.Book.objects.filter(pub_date__day=01)1.4 改
方式一:模型类的对象.属性 = 更改的属性值 模型类的对象.save()
返回值:编辑的模型类的对象。
books = models.Book.objects.filter(pk=7).first()
books.price = 400
books.save()方式二:QuerySet 类型数据.update(字段名=更改的数据)(推荐)
返回值:整数,受影响的行数
from django.shortcuts import render,HttpResponse
from app01 import models
def add_book(request):
books = models.Book.objects.filter(pk__in=[7,8]).update(price=888)
return HttpResponse(books)二、多表实例
表结构
书籍表 Book:title 、 price 、 pub_date 、 publish(外键,多对一) 、 authors(多对多)
出版社表 Publish:name 、 city 、 email
作者表 Author:name 、 age 、 au_detail(一对一)
作者详情表 AuthorDetail:gender 、 tel 、 addr 、 birthday
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
pub_date = models.DateField()
publish = models.ForeignKey("Publish", on_delete=models.CASCADE)
authors = models.ManyToManyField("Author")
class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=64)
email = models.EmailField()
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.SmallIntegerField()
au_detail = models.OneToOneField("AuthorDetail", on_delete=models.CASCADE)
class AuthorDetail(models.Model):
gender_choices = (
(0, "女"),
(1, "男"),
(2, "保密"),
)
gender = models.SmallIntegerField(choices=gender_choices)
tel = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
birthday = models.DateField()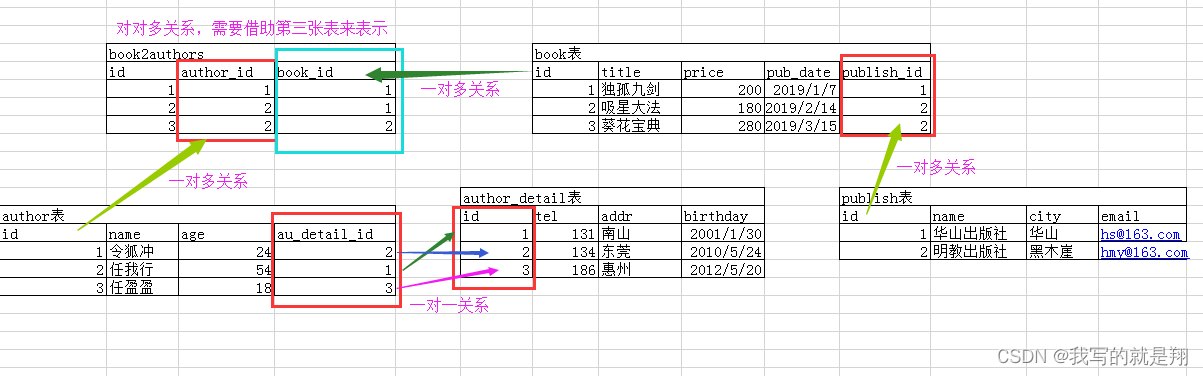
说明:
- 1、EmailField 数据类型是邮箱格式,底层继承 CharField,进行了封装,相当于 MySQL 中的 varchar。
- 2、Django1.1 版本不需要联级删除:on_delete=models.CASCADE,Django2.2 需要。
- 3、一般不需要设置联级更新.
- 4、外键在一对多的多中设置:models.ForeignKey("关联类名", on_delete=models.CASCADE)。
- 5、OneToOneField = ForeignKey(...,unique=True)设置一对一。
- 6、若有模型类存在外键,创建数据时,要先创建外键关联的模型类的数据,不然创建包含外键的模型类的数据时,外键的关联模型类的数据会找不到。
1、增
一对多(外键 ForeignKey)
方式一: 传对象的形式,返回值的数据类型是对象,书籍对象。
步骤:
- a. 获取出版社对象
- b. 给书籍的出版社属性 pulish 传出版社对象
def add_book(request):
# 获取出版社对象
pub_obj = models.Publish.objects.filter(pk=1).first()
# 给书籍的出版社属性publish传出版社对象
book = models.Book.objects.create(title="XX教程", price=200, pub_date="2023-04-10", publish=pub_obj)
print(book, type(book))
return HttpResponse(book)方式二: 传对象 id 的形式(由于传过来的数据一般是 id,所以传对象 id 是常用的)。
一对多中,设置外键属性的类(多的表)中,MySQL 中显示的字段名是:外键属性名_id。
返回值的数据类型是对象,书籍对象。
步骤:
- a. 获取出版社对象的 id
- b. 给书籍的关联出版社字段 pulish_id 传出版社对象的 id
def add_book(request):
# 获取出版社对象
pub_obj = models.Publish.objects.filter(pk=1).first()
# 获取出版社对象的id
pk = pub_obj.pk
# 给书籍的关联出版社字段 publish_id 传出版社对象的id
book = models.Book.objects.create(title="冲灵剑法", price=100, pub_date="2023-04-04", publish_id=pk)
print(book, type(book))
return HttpResponse(book)多对多(ManyToManyField):在第三张关系表中新增数据
方式一: 传对象形式,无返回值。
步骤:
- a. 获取作者对象
- b. 获取书籍对象
- c. 给书籍对象的 authors 属性用 add 方法传作者对象
def add_book(request):
# 获取作者对象
chong = models.Author.objects.filter(name="令狐冲").first()
ying = models.Author.objects.filter(name="任盈盈").first()
# 获取书籍对象
book = models.Book.objects.filter(title="XX教程").first()
# 给书籍对象的 authors 属性用 add 方法传作者对象
book.authors.add(chong, ying)
return HttpResponse(book)方式二: 传对象id形式,无返回值。
步骤:
- a. 获取作者对象的 id
- b. 获取书籍对象
- c. 给书籍对象的 authors 属性用 add 方法传作者对象的 id
def add_book(request):
# 获取作者对象
chong = models.Author.objects.filter(name="令狐冲").first()
# 获取作者对象的id
pk = chong.pk
# 获取书籍对象
book = models.Book.objects.filter(title="冲灵剑法").first()
# 给书籍对象的 authors 属性用 add 方法传作者对象的id
book.authors.add(pk)关联管理器(对象调用)
前提:
- 多对多(双向均有关联管理器)
- 一对多(只有多的那个类的对象有关联管理器,即反向才有)
语法格式:
正向:属性名 反向:小写类名加 _set
注意:一对多只能反向
常用方法:
add():用于多对多,把指定的模型对象添加到关联对象集(关系表)中。
注意:add() 在一对多(即外键)中,只能传对象( *QuerySet数据类型),不能传 id(*[id表])。
*[ ] 的使用:
# 方式一:传对象
book_obj = models.Book.objects.get(id=10)
author_list = models.Author.objects.filter(id__gt=2)
book_obj.authors.add(*author_list) # 将 id 大于2的作者对象添加到这本书的作者集合中
# 方式二:传对象 id
book_obj.authors.add(*[1,3]) # 将 id=1 和 id=3 的作者对象添加到这本书的作者集合中
return HttpResponse("ok")反向:小写表名_set
ying = models.Author.objects.filter(name="任盈盈").first()
book = models.Book.objects.filter(title="冲灵剑法").first()
ying.book_set.add(book)
return HttpResponse("ok")create():创建一个新的对象,并同时将它添加到关联对象集之中。
返回新创建的对象。
pub = models.Publish.objects.filter(name="明教出版社").first()
wo = models.Author.objects.filter(name="任我行").first()
book = wo.book_set.create(title="吸星大法", price=300, pub_date="1999-9-19", publish=pub)
print(book, type(book))
return HttpResponse("ok")2、删
remove():从关联对象集中移除执行的模型对象。
对于 ForeignKey 对象,这个方法仅在 null=True(可以为空)时存在,无返回值。
author_obj =models.Author.objects.get(id=1)
book_obj = models.Book.objects.get(id=11)
author_obj.book_set.remove(book_obj)
return HttpResponse("ok")clear():从关联对象集中移除一切对象,删除关联,不会删除对象。
对于 ForeignKey 对象,这个方法仅在 null=True(可以为空)时存在。
无返回值。
# 清空独孤九剑关联的所有作者
book = models.Book.objects.filter(title="XX教程").first()
book.authors.clear()3、查
基于对象的跨表查询。
正向:属性名称 反向:小写类名_set
一对多
查询主键为 1 的书籍的出版社所在的城市(正向)。
book = models.Book.objects.filter(pk=10).first()
res = book.publish.city
print(res, type(res))
return HttpResponse("ok")查询明教出版社出版的书籍名(反向)。
反向:对象.小写类名_set(pub.book_set) 可以跳转到关联的表(书籍表)。
pub.book_set.all():取出书籍表的所有书籍对象,在一个 QuerySet 里,遍历取出一个个书籍对象。
pub = models.Publish.objects.filter(name="明教出版社").first()
res = pub.book_set.all()
for i in res:
print(i.title)
return HttpResponse("ok")注意:
related_name:models中该属性的使用;当使用了该属性那就就直接使用 obj.related_name.all()
使用 related_name='demo_%(class)s' : obj.demo_小写 modles名称.all() 即可
一对一
查询令狐冲的电话(正向)
正向:对象.属性 (author.au_detail) 可以跳转到关联的表(作者详情表)
author = models.Author.objects.filter(name="令狐冲").first()
res = author.au_detail.tel
print(res, type(res))
return HttpResponse("ok")查询所有住址在黑木崖的作者的姓名(反向)。
一对一的反向,用 对象.小写类名 即可,不用加 _set。
反向:对象.小写类名(addr.author)可以跳转到关联的表(作者表)。
addr = models.AuthorDetail.objects.filter(addr="黑木崖").first()
res = addr.author.name
print(res, type(res))
return HttpResponse("ok")多对多
XX教程所有作者的名字以及手机号(正向)。
正向:对象.属性(book.authors)可以跳转到关联的表(作者表)。
作者表里没有作者电话,因此再次通过对象.属性(i.au_detail)跳转到关联的表(作者详情表)。
book = models.Book.objects.filter(title="XX教程").first()
res = book.authors.all()
for i in res:
print(i.name, i.au_detail.tel)
return HttpResponse("ok")查询任我行出过的所有书籍的名字(反向)。
author = models.Author.objects.filter(name="任我行").first()
res = author.book_set.all()
for i in res:
print(i.title)
return HttpResponse("ok")class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
pub_date = models.DateField()
authors = models.ManyToManyField("Author",related_name='book_authors')
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.SmallIntegerField()
注意:related_name 的使用
# 如上述models 方向查询
author = author.objects.filter(name="任我行").first()
books = author.book_authors.filter()基于双下划线的跨表查询
正向:属性名称__跨表的属性名称 反向:小写类名__跨表的属性名称
一对多
查询XX出版社出版过的所有书籍的名字与价格。
res = models.Book.objects.filter(publish__name="XX出版社").values_list("title", "price")反向:通过 小写类名__跨表的属性名称(book__title,book__price) 跨表获取数据。
res = models.Publish.objects.filter(name="XX出版社").values_list("book__title","book__price")
return HttpResponse("ok")多对多
查询任我行出过的所有书籍的名字。
正向:通过 属性名称__跨表的属性名称(authors__name) 跨表获取数据:
res = models.Book.objects.filter(authors__name="任我行").values_list("title")反向:通过 小写类名__跨表的属性名称(book__title) 跨表获取数据:
res = models.Author.objects.filter(name="任我行").values_list("book__title")一对一
查询任我行的手机号。
正向:通过 属性名称__跨表的属性名称(au_detail__tel) 跨表获取数据。
res = models.Author.objects.filter(name="任我行").values_list("au_detail__tel")反向:通过 小写类名__跨表的属性名称(author__name) 跨表获取数据。
res = models.AuthorDetail.objects.filter(author__name="任我行").values_list("tel")三、聚合查询
1. 平均值 Avg
计算所有图书的平均价格:
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数
...
res = models.Book.objects.aggregate(Avg("price"))
print(res, type(res))2.最大最小值 Max、Min
计算所有图书的数量、最贵价格和最便宜价格:
res=models.Book.objects.aggregate(c=Count("id"),max=Max("price"),min=Min("price"))
print(res,type(res)3.分组查询(annotate)
分组查询一般会用到聚合函数,所以使用前要先从 django.db.models 引入 Avg,Max,Min,Count,Sum(首字母大写)。
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数返回值:
- 分组后,用 values 取值,则返回值是 QuerySet 数据类型里面为一个个字典;
- 分组后,用 values_list 取值,则返回值是 QuerySet 数据类型里面为一个个元组。
MySQL 中的 limit 相当于 ORM 中的 QuerySet 数据类型的切片。
注意:
annotate 里面放聚合函数。
-
values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
-
values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
4.求和Sum
查询各个作者出的书的总价格:
res = models.Author.objects.annotate(all = Sum("book__price")).values("name","all")
print(res)四、F查询Q查询
1、F查询
from django.db.models import F表内的两个字段的值如何进行比较??且看Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
F(‘字段名’) 表示字段含义并非命名空间内变量的意思
from django.db.models import F
# 查询 评论数 大于 收藏数 的书籍
books = Book.objects.filter(comment_nums__gt=F('keep_nums'))
print(books) # <QuerySet [<Book: 明教>]>
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作
# 查询评论数大于收藏数2倍的书籍
Book.objects.filter(comment_nums__gt=F('keep_nums')*2)修改操作也可以使用F函数,比如将每一本书的价格提高30元:
Book.objects.all().update(price=F("price")+10) 2、Q查询
from django.db.models import Qfilter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
Q(字段条件) 进行 与或非 的 多条件过滤
与:&
或:|
非:~
from django.db.models import Q
Q(title__startswith='Py')
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
# 查询 价格 大于 30 或 评论数 大于 300
books = Book.objects.filter(Q(price__gt=30)|Q(comment_nums__gt=300))
print(books.query)
print(books) # <QuerySet [<Book>, <Book>, <Book>]>
等同于下面的SQL WHERE 子句:
WHERE price > 100 OR comment_nums =3000
可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用 ~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(pub_date__year=2020)).values_list("title")
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(pub_date__year=2023) | Q(pub_date__year=2023),
title__icontains="python"
)
五、JOIN 连接查询
在Django中,可以使用select_related和prefetch_related方法实现左连接(Left join)和内连接(Inner join)关联查询。
1、Inner join: 内连接 查询
内连接是一种关联查询方式,它会返回包含两个表中匹配的记录的结果集。如果某个表中没有匹配的记录,则不会包含在结果集中。
例如,假设我们有两个模型A和B:
class A(models.Model):
name = models.CharField(max_length=255)
class B(models.Model):
a = models.ForeignKey(A, on_delete=models.CASCADE)
value = models.IntegerField()
要查询所有A对象以及与之关联的且值相等的B对象,可以使用以下代码:
a_models = A.objects.filter(b__value=1).distinct()
for a in a_models:
print(a.name)
这将输出所有A对象及其关联的且值相等的B对象的名称。如果某个A对象没有关联的且值相等的B对象,则不会包含在结果集中。
2、Left join: 左连接 select_related
class A(models.Model):
name = models.CharField(max_length=255)
class B(models.Model):
a = models.ForeignKey(A, on_delete=models.CASCADE)
value = models.IntegerField()
要查询所有A对象以及与之关联的B对象,可以使用以下代码:
# 左连接查询
a_models = A.objects.select_related('b').all()
for a in a_models:
print(a.name, a.b.value)
这将输出所有A对象及其关联的B对象的值。如果某个A对象没有关联的B对象,则B对象的值为NULL。
例题:
class A(models.Model):
aa = models.CharField(max_length=255)
bb = models.CharField(max_length=255)
cc = models.CharField(max_length=255)
class B(models.Model):
a = models.ForeignKey(A,on_delete=models.CASCADE,max_length=255, null=True)
dd = models.CharField(max_length=255)
ee = models.IntegerField()需求:分页查询A表,但是需要使用B表中 a字段相同的ee和艰辛倒叙排序:
from django.db.models import Sum
# 对A模型进行分页查询,并根据B模型中的ee字段进行求和,然后按照A模型中的a字段进行升序排序
a_models = A.objects.values('aa').annotate(ee_sum=Sum('b__ee')).order_by('aa')
总结
Django之ORM跨表查询、join查询、聚合查询、分组查询_django join查询_Sunny_Future的博客-CSDN博客















 2907
2907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









