







什么是Hive?
Apache Hive 是一种分布式容错数据仓库系统,可进行大规模分析。Hive是基于Hadoop的数据仓库工具,能够将结构化数据映射为一张数据表并提供SQL查询功能。本质是将SQL转换为MR或者Spark任务进行运算,底层使用HDFS进行数据存储。
Hive 架构
Hive 架构主要有以下部分组成:Hive Client、Hive Service、Processing and Resource Management、Distributed Storage
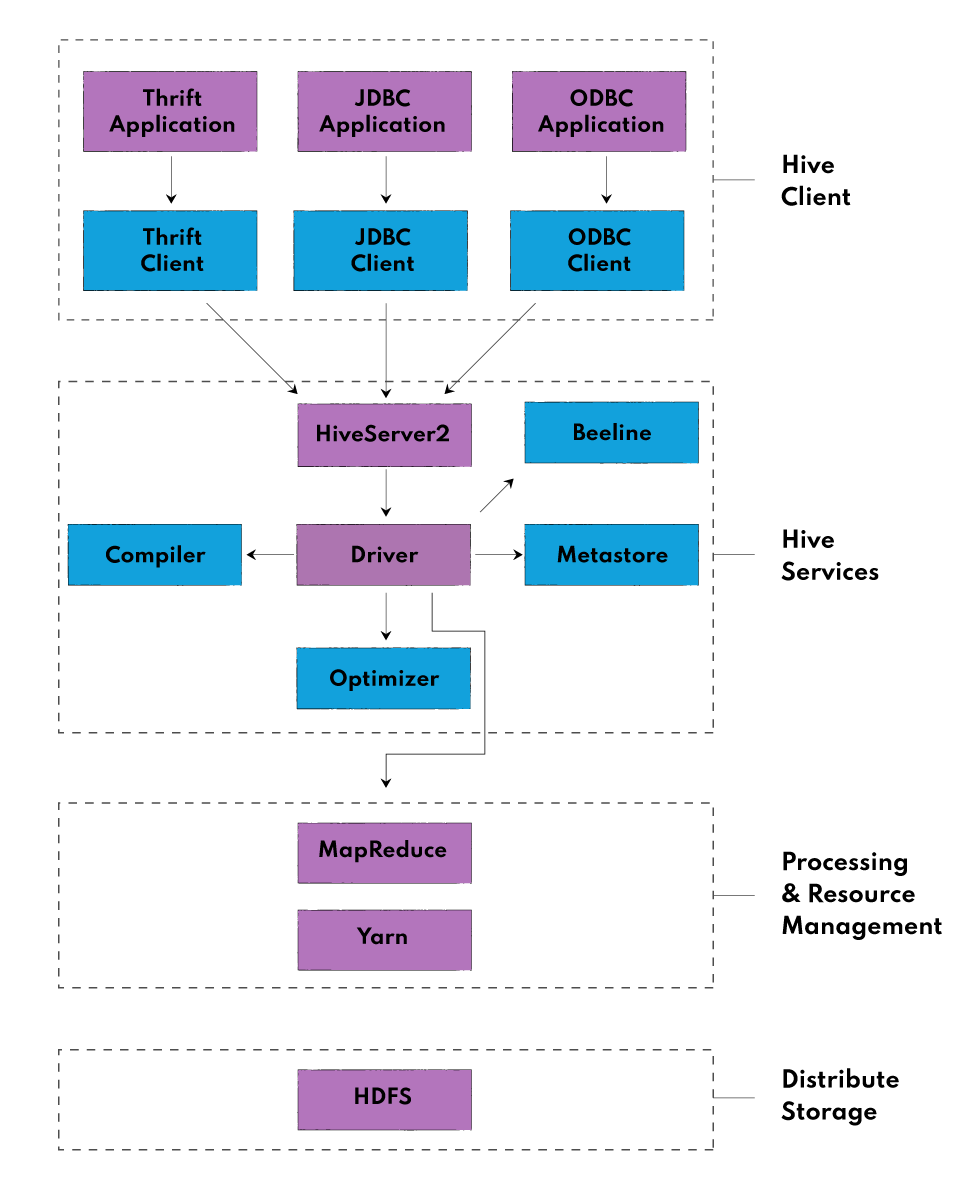
Hive Clients
Hive Clients 主要用于使用者可以通过多种语言直接使用Hive仓库,例如可以用Python、Java、C++等语言编写程序。Hive Clients 也分几种类型
- Thrift Client: Hive 服务器基于 Apache Thrift,因此可以处理来自 Thrift 客户端的请求
- JDBC Client:Hive 允许 Java 应用程序使用 JDBC 驱动程序与其连接。JDBC 驱动程序使用 Thrift 与 Hive 服务器通信。
- ODBC Client:Hive ODBC 驱动程序允许基于 ODBC 协议的应用程序连接到 Hive。与 JDBC 驱动程序类似,ODBC 驱动程序使用 Thrift 与 Hive 服务器通信。
Hive Service
为了运行不同的查询服务,Hive 提供了多种服务组件,例如:Hive Server2,Beeline等
- Beeline:Beeline 是 HiveServer2 支持的commend shell,用户可在此向系统提交查询和命令。它是基于 SQLLINE CLI(纯 Java 控制台工具,用于连接关系数据库和执行 SQL 查询)的 JDBC Client。
- Hive Server2:HiveServer2 是 HiveServer1 的后续版本。HiveServer2 可让客户端对Hive执行查询。它允许多个客户端向 Hive 提交请求并检索最终结果。其基本设计目的是为 JDBC 和 ODBC 等开放式 API 客户端提供最佳支持。
HiveServer1实际就是Thrift Server,能够支持不同Client向Hive提交查询请求,但是不能多线程处理多个Client的命令,因此被HiveServer2所替代。
- Hive Driver: Hive 驱动程序接收用户通过命令 shell 提交的 HiveQL 语句。它会为查询创建会话句柄,并将查询发送给编译器。
- Hive Compiler:Hive 编译器对查询进行解析。它利用元存储库中存储的元数据,对不同的查询块和查询表达式进行语义分析和类型检查,并生成执行计划。执行计划就是DAG(有向无环图),其中每个阶段都是 map/reduce 作业、HDFS 上的操作和元数据操作。
- Optimizer: 优化器对执行计划执行转换操作,并拆分任务,以提高效率和可扩展性。
- MetaStore:Metastore 是一个中央存储库,用于存储有关表和分区结构的元数据信息,包括列和列类型信息。它还存储读/写操作所需的序列化器和反序列化器信息,以及存储数据的 HDFS 文件。这种元存储一般是关系数据库。元存储提供了一个 Thrift 接口,用于查询和操作 Hive 元数据。
- HCatalog:HCatalog 是 Hadoop 的表和存储管理层。它能让使用不同数据处理工具(如 Pig、MapReduce 等)的用户在网格上轻松读写数据。它建立在 Hive 元存储之上,将 Hive 元存储的表格数据公开给其他数据处理工具。
- WebHCat:WebHCat 是 HCatalog 的 REST API。它是执行 Hive 元数据操作的 HTTP 接口。它为用户运行 Hadoop MapReduce(或 YARN)、Pig 和 Hive 作业提供服务。
Processing and Resource Management
Hive 内部使用 MapReduce 框架作为执行查询的实际引擎。MapReduce 是一种软件框架,用于编写在大型商业集群硬件上并行处理海量数据的应用程序。MapReduce 任务的工作方式是将数据分割成块,由 map-reduce 任务进行处理。
Distributed Storage
Hive 构建在 Hadoop 之上,因此它使用底层的 Hadoop 分布式文件系统进行分布式存储。
Hive 运行过程
- 提交查询:用户通过客户端提交查询任务
- 获取执行计划:Driver接受查询,为查询创建会话句柄,并将查询传递给编译器以生成执行计划。
- 获取元信息:编译器会向元数据库发送元数据请求并获取数据表的元信息,编译器利用这些元数据对查询树中的表达式进行类型检查和语义分析。然后,编译器会生成执行计划(有向无环图)。对于 Map Reduce 作业,该计划包含 map 运算计划(map operator tree)(在映射器上执行的运算符树)和 reduce 运算计划(reduce operate tree)(在 reducer 上执行的运算符树)。
- 发送执行计划:编译器将执行计划发送给Driver
- 执行查询计划:Driver接收到执行计划后会发送给执行引擎进行查询执行
- 提交任务给MapReduce:执行引擎将DAG的stages发送给相应的组件。对于每个task任务,从HDFS中读取数据和写入数据都会用到序列化器和反序列化器。task运行成功后,将结果通过序列化器写入HDFS临时文件,为下一阶段的任务提供数据支持。最后将计算结果写入到HDFS表中。
- 返回结果:执行引擎会直接从 HDFS 读取临时文件的内容,作为Driver获取调用的一部分。然后,Driver将结果发送到 Hive 接口。















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









