







DOS部分是16位 文件里的说明数据全是结构体
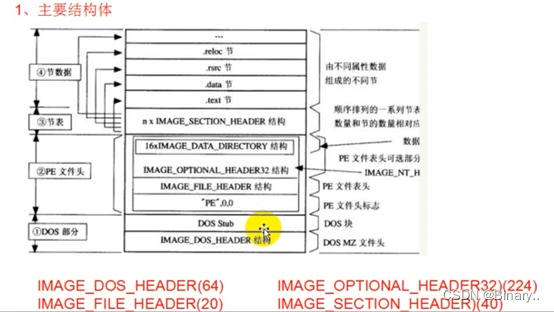
DOS MZ结构体最后4字节执向PE结构头 DOS MZ它们之间为DOS数据(编译器生成的,可修改)
在标准pe头中有扩展pe头大小,可以修改它干事情
节表后是编译器写的一些数据
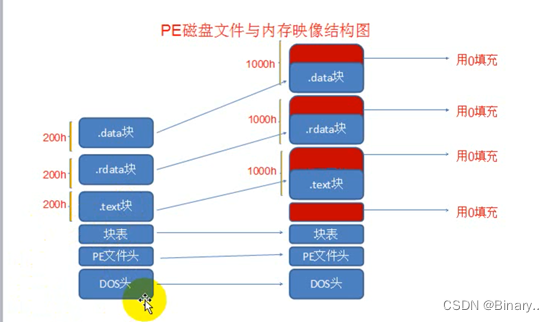
32位每个块按0x200对齐 内存0x1000对齐
DOS:头和尾不能修改 其他位置都可以
PE标准头:1.pe不能修改(4) 2.Machine为0,可在任意cpu下运行,014c 32位,8664 64位(2) 3.节表数量(2) 4.时间戳, 从1970-编译链接后的秒数(4) 5.6成员各4字节
7.扩展pe头的大小(2) 8 属性,下面截图(2)


Characteristics:

2.扩展PE头
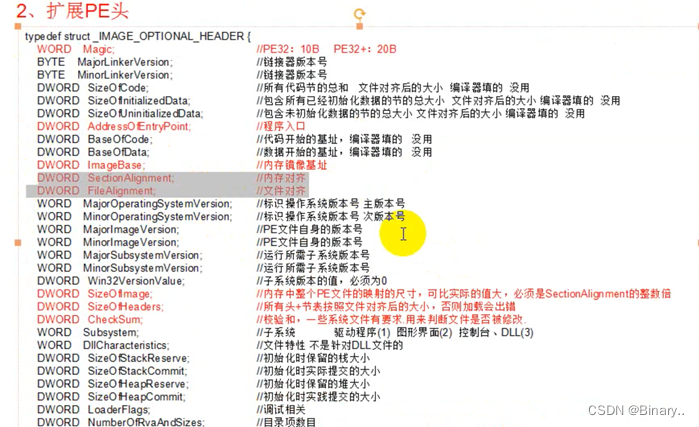
扩展pe:1. 10b 32位程序 20b 64位程序 (2) 2.3编译器名字版本等(各1) 4.代码段大小(4) 5.6 data bss (4) 7.程序main偏移(4) 8.9(各4) 10.程序基址(4) 11.12 内存对齐和文件对齐(各4)
13-19,13-18可任意修改,19必须全0(总0x10) 20.内存对齐后文件总大小(4) 21.(dos-节表)文件对齐后大小(4) 22.校验和 从文件头开始两个字节+两个字节,加到文件尾的和就是校验和,可能溢出(4) 23.子系统(内核程序,1.驱动程序,2.图形界面,3.控制台或dll,共4字节)
25.初始化时栈大小(4) 26.初始化时实际栈大小(4) 27.初始化时堆大小(4)
28.初始化时实际堆大小(4)
10成员(逻辑基址)+7成员(逻辑偏移)=main入口
32位扩展pe和64位扩展pe大小区别在于10成员(基址)和25-28成员(栈,堆)
扩展Pe是否扩充根据标准pe来确定 现在的编译器内存对齐和文件对齐有可能是一样的
节表:

1.字符串,节表名,例如text,data,但名字不能确定是否真的是text这些(8字节)
2.联合体,通常用第二成员来描述当前节真实不对齐的总大小(4) 3.内存对齐后节的偏移(4) 4.文件对齐后节的大小,但它不一定是正确的,如果存在bss就不包含在里面,只有第二个才包含(4) 5.文件对齐后节偏移(4) 10.节的属性
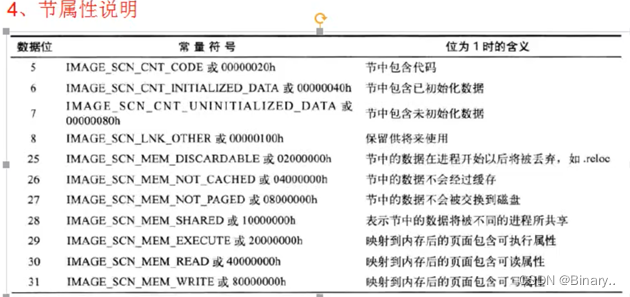
节属性:
RVA(相对虚拟地址):内存绝对地址-内存基址(就得到内存对齐后的偏移地址)
FOA:就是文件对齐后偏移
1.如果计算出来的RVA在dos-节表范围内,那RVA==FOA了,不用计算了,因为它们地址是连续的 2.不在头的时候,在扩展pe中找出内存对齐,文件对齐,基址,然后在节表中查找当前节表中内存起始点和文件起始点,然后通过这些数据可以求出FOA转RVA,RVA转FOA
空白区填写代码:跳转地址-(当前地址最高值+1) 例如 jo xxxxxxxx 4及以上就使用这个公式来套简单
一字节就ff为00-(-0x8) 0-0x7f(1-0x80),虽然在一字节范围内都可以使用
通过节表的第五个成员求出差值(当前节文件对齐后起点)
然后在扩展pe找出程序内存入口,基址,内存对齐,文件对齐,通过它们来改入口点
也就是先FOA转RVA 然后再用公式计算跳转值(基址+内存对齐后起点+差值)
总结一下:RVA通过节表的二(实际大小)三成员(内存对齐后起点)和基址来确定差值
扩大节空间:修改节表2.4成员,还有扩展pe头的第20个成员sizeofimage(文件内存对齐总大小),只要是大于等于就可以 如果添加代码,要修改节表最后成员的属性(可执行,在29位)
新增节:加壳,病毒等

在新增节的时候看上个节的2真实数据大小或4文件对齐大小来确定新节表的内存数据起点或文件数据起点(因为在上一个节中可能有很多无用数据,且额外添加的空间来存放的)
增加节的数据根据上一个节的数据来修改,内存起点用上一个节的2.3成员来确定
文件起点由上一个4.5成员确定
导出表:就是当前pe文件导出到其他pe文件中(要使用当前pe的函数等等),一般exe不导出,但不一定,一般是dll库最多
一共16张表,每个表占8字节(导出说明表),属性一样,前两个表为导出表和导入表,第一个成员为RVA(指向表),第二个是这个结构体的实际大小
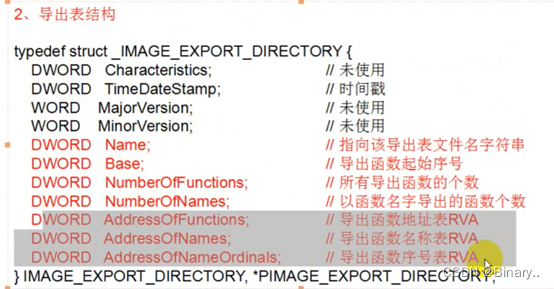
所有导出函数个数-以函数名导出函数个数=剩余的 在Base中,可以不取名字来隐藏
但对很懂底层的没有用,可以去分析没有取名的函数
导出函数地址表RVA:指向导出表函数地址
导出函数名称表RVA:是个二级指针,指向一级指针(一级指针指向名称地址)
名称地址有排序的,按scii递增
序号表:每个成员2字节 如果函数有名称,通过这三张表来查找对应函数地址(也需要Base)

函数没有名称时用查找值-起始值=递增的次数 例如 查找序号为21的,起始序号为15,然后就在函数地址表递增的找到(下标)

导入表:一个进程由多个pe文件构成的 PE文件提供导入表 PE文件依赖导入表模块(里面的一系列函数)

virtualAddress指向第一个导入表,每20字节为一个导入表,遇到20个\x00结束(RVA)
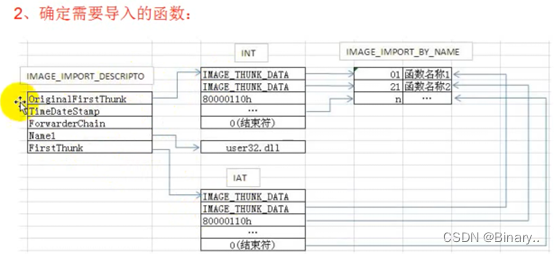

结构数组有多个说明使用了此模块的多少函数 遇到4字节全为0结束(64位为8)
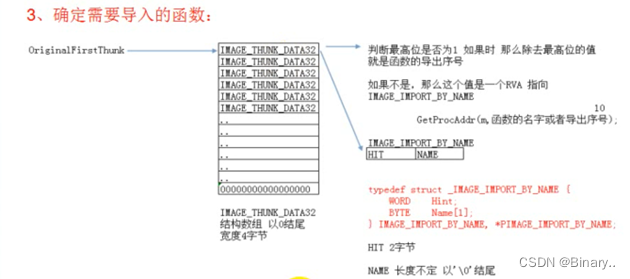
Chunk_data的31位为1,除去最高位的值就是导出序号,不是它的值就是指向IMPORT_BY_NAME结构体 Hint(2)如果不为0,就是此函数在导出表的索引
Name(1),指向当前函数名的第一个字符
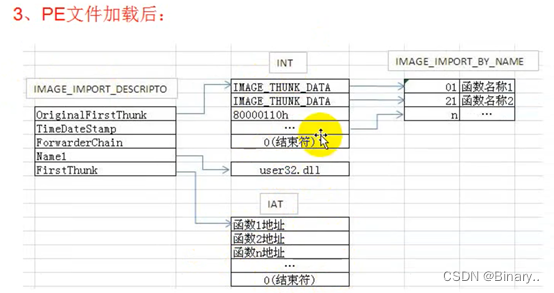
在文件中,1和5成员一样(INT和IAT),文件加载后第5个成员FirstThunk指向函数地址(IAT表)

重定位表: text的硬编码在初始化时就确定了,如果有多个模块的硬编码一样,然而它们映射的地址不一样,就会导致硬编码出错(除了首先映射是对的)
这时重定位表就起作用了,里面存放的是要修正的地址
我估计如果没开text随机化,text段应该是固定的,libc这些不固定 开了随机化就都需要重定位表 第6个表为重定位表 ,两个成员 1.VirtualAddress 重定位内存页的起始RVA,32位中操作系统给每个重定位表分配2^12个字节(4) 2.sizeofBlock 重定位块的中大小,包含这两个成员(4) 遇到8字节为0结束
为了节约大量空间 VirtualAddress为需要修正的RVA,表后边存的就是以2个字节一个单位的偏移,当偏移的最高3位为3时才是需要修复的(可能修复的全部在一堆,不修复的垃圾在一堆,不修复的是为了内存对齐),除去最高3位就是修复值(13-15)
shellcode:

IAT HOOK:例如泄露密码 在输入账号密码时肯定会用到函数API ,这时通过hook钩子来获取你输入的东西或者把函数修改成自己写的(外挂等) 外挂就是使用hook技术

















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









