







树上搜索
题目
题目背景
西西艾弗岛大数据中心为了收集用于模型训练的数据,推出了一项自愿数据贡献的系统。岛上的居民可以登录该系统,回答系统提出的问题,从而为大数据中心提供数据。为了保证数据的质量,系统会评估回答的正确性,如果回答正确,系统会给予一定的奖励。
近期,大数据中心需要收集一批关于名词分类的数据。系统中会预先设置若干个名词类别,这些名词类别存在一定的层次关系。例如,“动物”是“生物”的次级类别,“鱼类”是“动物”的次级类别,“鸟类”是“动物”的次级类别,“鱼类”和“鸟类”是“动物”下的邻居类别。这些名词类别可以被按树形组织起来,即除了根类别外,每个类别都有且仅有一个上级类别。 并且所有的名词都可以被归类到某个类别中,即每个名词都有且仅有一个类别与其对应。一个类别的后代类别的定义是:若该类别没有次级类别,则该类别没有后代类别;否则该类别的后代类别为该类别的所有次级类别,以及其所有次级类别的后代类别。
下图示意性地说明了标有星号的类别的次级类别和后代类别。
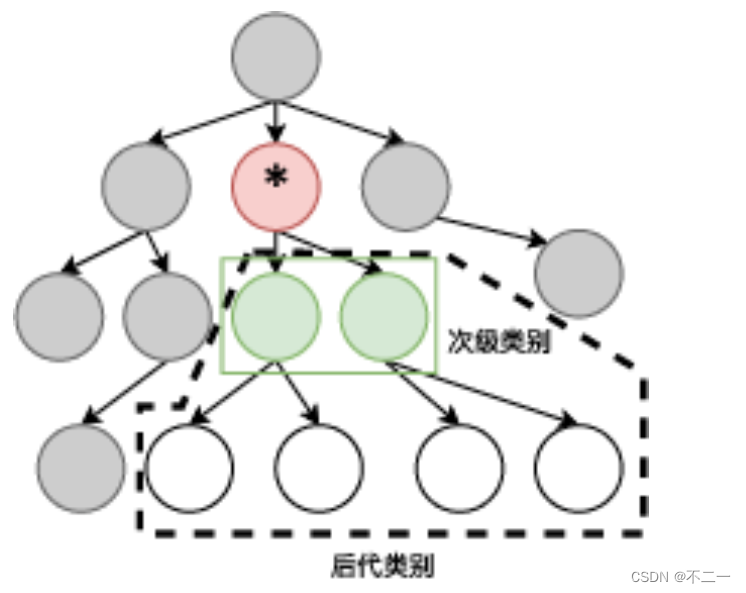
背景介绍,就是说明了后代类别就是后面的所有子孙节点
题目描述
小 C 观察了事先收集到的数据,并加以统计,得到了一个名词属于各个类别的可能性大小的信息。具体而言,每个类别都可以赋予一个被称为权重的值,值越大,说明一个名词属于该类别的可能性越大。由于每次向用户的询问可以获得两种回答,小 C 联想到了二分策略。他设计的策略如下:
-
对于每一个类别,统计它和其全部后代类别的权重之和,同时统计其余全部类别的权重之和,并求二者差值的绝对值,计为 w δ w_\delta wδ
-
选择 w δ w_\delta wδ最小的类别,如果有多个,则选取编号最小的那一个,向用户询问名词是否属于该类别;
-
如果用户回答“是”,则仅保留该类别及其后代类别,否则仅保留其余类别;
-
重复步骤 1,直到只剩下一个类别,此时即可确定名词的类别。
小 C 请你帮忙编写一个程序,来测试这个策略的有效性。你的程序首先读取到所有的类别及其上级次级关系,以及每个类别的权重。你的程序需要测试对于被归类到给定类别的名词,按照上述策略提问,向用户提出的所有问题。
输入格式
从标准输入读入数据。
输入的第一行包含空格分隔的两个正整数 𝑛和 𝑚,分别表示全部类别的数量和需要测试的类别的数量。所有的类别从 1到 𝑛编号,其中编号为 1 的是根类别。
输入的第二行包含 𝑛 个空格分隔的正整数
w
1
,
w
2
,
.
.
.
w
n
w_1,w_2,...w_n
w1,w2,...wn ,其中第 𝑖个数
w
i
w_i
wi 表示编号为 𝑖 的类别的权重。
输入的第三行包含 (𝑛−1) 个空格分隔的正整数
p
2
,
p
3
,
.
.
.
,
p
n
p_2,p_3,...,p_n
p2,p3,...,pn ,其中第 𝑖个数
p
i
+
1
p_{i+1}
pi+1
表示编号为 (𝑖+1) 的类别的上级类别的编号,其中
p
i
ϵ
[
1
,
n
]
p_i \epsilon [1,n]
piϵ[1,n]
接下来输入 𝑚行,每行一个正整数,表示需要测试的类别编号。
输出格式
输出 𝑚行,每行表示对一个被测试的类别的测试结果。表示按小 C 的询问策略,对属于给定的被测类别的名词,需要依次向用户提出的问题。
每行包含若干空格分隔的正整数,每个正整数表示一个问题中包含的类别的编号,按照提问的顺序输出。
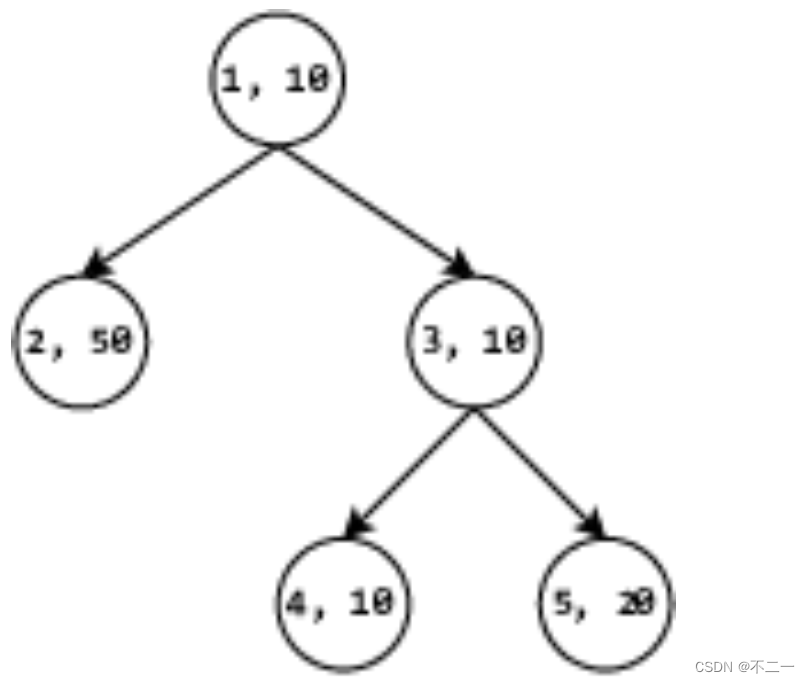
样例1输入
5 2
10 50 10 10 20
1 1 3 3
5
3
样例1输出
2 5
2 5 3 4
讲解
解题过程
数据输入
采用数据格式
有题目可知,该题目需要存储一个树,我选择使用字典来存储字典的形式如下(为样例示意)
{1: {'weights': 100, 'son': {2,3}},
2: {'weights': 50, 'son': {}},
3: {'weights': 40, 'son': {4,5}},
4: {'weights': 10, 'son': {}},
5: {'weights': 20, 'son': {}}}
采用字典存储,包含两个键
- ‘weights’:存储该节点的权值(即此节点的权重以及其所有后代节点的权重之和)
- ‘son’: 存储该节点的所有儿子
为什么采用这种形式,字典容易处理,包含权值的原因是后续的过程有统计全部类别的w的操作,可以避免重复运算,‘son’采用集合的形式,可以提升查询的效率且儿子的顺序不重要
数据读取
n,m = map(int,input().split())
weights = list(map(int,input().split()))
tree = {i + 1: {'weights':0,'son':set()} for i in range(n)}
# 用cfg读取节点的位置关系
cfg = list(map(int,input().split()))
for node, parent in enumerate(cfg, start=2):
tree[parent]['son'].add(node)
for k in tree.keys():
offspring = set()
w = 0
visit(tree,k,offspring)
for i in offspring:
w += weights[i-1]
tree[k]['weights'] = w
- 先读取n和m
- 将每个节点的权重存储在weights列表里面
- 初始化一个空树,有多少个节点字典中就有多少项
- 用cfg读取节点的位置关系
由于是从第二个节点开始的enmuerate的计数也从2开始
cfg上的数字代表了该位置上的节点的父节点是谁,所以在对应父节点的‘son’中添加该节点 - 权重初始化
介绍visit函数
如果node有子节点,便递归调用visit,将所有后代节点添加到nodes中(包括node)def visit(tree:dict,key,nodes:set): # 获取node节点的所有后代节点,并包括其本身,利用nodes集合回传 nodes.add(key) for i in tree[key]['son']: visit(tree,i,nodes)
初始化权重
将tree中的每一个节点遍历,找到其所有后代节点,利用weights计算出所有节点的权重和,即是tree中该节点[‘weigths’]中应该存储的
主流程
answer = [] # 保存答案
for _ in range(m):
cl = int(input()) # 测试类别
ans =[] # 存储每一行的答案
# 数据拷贝
current_weights = weights[:]
current_tree = {key: {'weights': value['weights'], 'son': set(value['son'])} for key, value in tree.items()}
# 主要循环
while len(current_tree) > 1:
num = batch(current_weights, current_tree, cl)
ans.append(str(num))
answer.append(ans)
- 通过cl读取本次测试的类别
- 数据拷贝(深拷贝),每次测试的初始树是不会变动的,所以不改变原始数据而是进行拷贝
- 主循环:
按题意,只有树种只剩下一个节点才结束过程
ans和answer只是用来记录答案
函数介绍
batch函数
def batch(weights, tree:dict, cl):
# 计算每个类别的w权重即题目的
omi = omiga(tree,weights)
# 找到 omi中权重最小的索引 即可用得到本次循环选中的节点
min_omi = min(i for i in omi if i != -1)
node = omi.index(min_omi) + 1
# 找到node所有的后代
offspring = set()
visit(tree,node,offspring)
# 判断是否cl在后代之中
if cl in offspring:
# 如果在则删除剩余节点
all_node = set(tree.keys())
delete = all_node - offspring
else:
# 如果不在则删除node及其后代
delete = offspring
# 进行树的删除和权值修改
delete_tree(weights, tree, delete,node)
return node
omiga函数
def omiga(tree:dict,weights)->list:
# 计算题目要求的每个类别的w权值,用列表返回
n = len(weights)
omi = [-1] * n
total_weight = sum(weights)
for key in tree.keys():
omi[key - 1] = abs(total_weight - 2 * tree[key]['weights'])
return omi
因为tree在中间可能会修改节点
便用 -1进行初始化omi并保持和weights权重长度相等,即能保留节点的位置关系
遍历每一个节点,由于我们有每一个节点的权重值
在计算
w
δ
w_\delta
wδ的时候可以非常方便
由定义可知
w
δ
w_\delta
wδ等于abs(我们每个节点存储的weights - 其他所有节点的权重之和)
实际上等效于abs(所有节点权重之和-节点存储的weights-节点存储的weights)
因为 其他所有节点的权重之和=所有节点权重之和-节点存储的weights
所以可以写成上式
继续看batch函数
# 找到 omi中权重最小的索引 即可用得到本次循环选中的节点
min_omi = min(i for i in omi if i != -1)
node = omi.index(min_omi) + 1
由于omi已经对应好节点的位置关系且删除的节点被置为了-1(因为在omiga中只有存在的节点才会遍历,只有存在的节点才会对应修改omi),所以直接按顺序找到其中的最小节点node
# 找到node所有的后代
offspring = set()
visit(tree,node,offspring)
# 判断是否cl在后代之中
if cl in offspring:
# 如果在则删除剩余节点
all_node = set(tree.keys())
delete = all_node - offspring
else:
# 如果不在则删除node及其后代
delete = offspring
通过visit找到node的所有后代(visit已经在数据输入部分介绍)
如果cl在offspring中则说明我们应该删除其余节点
如果不在 则直接把offspring中的所有节点删除即可
# 进行树的删除和权值修改
delete_tree(weights, tree, delete,node)
delete_tree 是本算法的关键
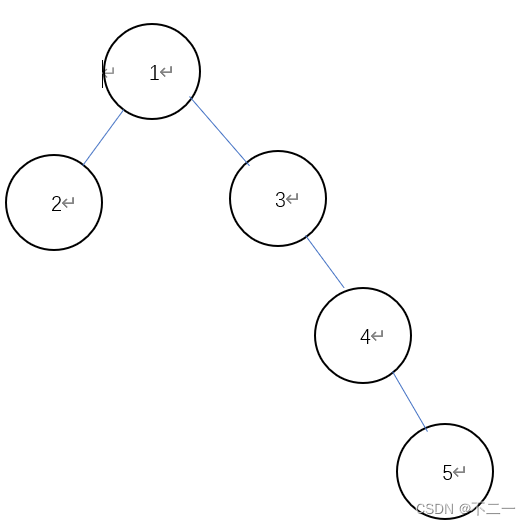
假设node = 4
则offspring 为 {4,5}
分为两种情况
-
cl in offspring
说明cl是在node子树其中的,我们需要进一步的问询才能确定cl的具体值此时的delete为{1,2,3} 说明我们要将除了4子树之外的全部删除
由于我们采用的是字典的形式除了要删除对应节点的键之外,还要寻找别的节点是否是该节点的父节点,如果是的话要在其[‘son’]列表中删除
但是在这种情况下,我们可以注意到,保留的节点全在4子树部分,他们不可能是删除节点的父亲,因为所有的后代都已经保留了,所以在删除的过程中无需检查[‘son’]列表
接下来看[‘weights’]的修改
由于[‘weights’]只和后代有关,删除的节点并不会影响到剩余节点的[‘weights’],所以也无需进行更改 -
cl not in offspring
说明cl是在其他的节点之中,我们要将4子树全部删除- 节点修改:注意到只有4子树的根节点即4有可能是别的节点的儿子之外,4的所有子孙均不可能是别的节点的儿子,所以可以等同于情况1直接删去。对于4节点我们单独进行处理,遍历剩余字典进行判断,删除含有4的部分
- 权重修改:我们需要思考一下树中存储的权重谁更改了
对于4的子孙不用考虑,他们全会直接删除
对于4也是删除
受影响的节点只有图中的{1,3},他们分别是4的父节点和爷节点,可以看出只有4节点的直系节点会受到影响,由于保存的权值是节点的权重和节点所有后代节点的权重之和,所以我们要找到4 的所有祖先,并且他们损失的值是4及其所有后代的权重之和即是树中存储的tree[4][‘weights’]
所以我们找到4所有的祖先将他们的权重减去tree[4][‘weights’]即可,而其他的权重无需修改
注:删除节点后要将其权重列表中的权重置0,确保omiga中求总权重正确
delete_tree函数
def delete_tree(weights, tree:dict, delete,root):
if root in delete:
delete.remove(root)
w = tree[root]['weights']
for d in delete:
del tree[d]
weights[d-1] = 0
# 单独处理根节点
parent = set()
find_parent(tree,root,parent)
for p in parent:
tree[p]['weights'] -= w
if root in tree[p]['son']:
tree[p]['son'].remove(root)
weights[root-1] = 0
del tree[root]
else:
for d in delete:
del tree[d]
weights[d-1] = 0
如果node不在delete中则说明属于情况1
可以非常简单的直接删除tree中的节点无需任何判断
如果在的话属于情况2
我们将node分离出来单独处理
w 保存随后祖孙节点应该减去的值
对于剩下的delete则可以像情况1一样处理直接删除
通过find_parent函数找到node的所有祖先
随后修改祖先的[‘weights’]
并将祖先中含有node的部分去除(其实也就父节点有)
随后将node在树中删去
并置权重列表中的值为0
以上就是算法的所有部分,在测试中可以拿到满分
def find_parent(tree:dict,node,parent:set):
# 找到node的所有父节点,并用parent回传(不包括node本身)
for k,v in tree.items():
if node in v['son']:
parent.add(k)
find_parent(tree,k,parent)
break
通过循环逐个判断节点是否为node的父节点
找到一个遍中断循环,因为只会有一个父节点
继续递归寻找父节点的父节点,直到找不到为止
完整代码
def omiga(tree:dict,weights)->list:
# 计算题目要求的每个类别的w权值,用列表返回
n = len(weights)
omi = [-1] * n
total_weight = sum(weights)
for key in tree.keys():
omi[key - 1] = abs(total_weight - 2 * tree[key]['weights'])
return omi
def visit(tree:dict,key,nodes:set):
# 获取node节点的所有后代节点,并包括其本身,利用nodes集合回传
nodes.add(key)
for i in tree[key]['son']:
visit(tree,i,nodes)
def delete_tree(weights, tree:dict, delete,root):
if root in delete:
delete.remove(root)
w = tree[root]['weights']
for d in delete:
del tree[d]
weights[d-1] = 0
# 单独处理根节点
parent = set()
find_parent(tree,root,parent)
for p in parent:
tree[p]['weights'] -= w
if root in tree[p]['son']:
tree[p]['son'].remove(root)
weights[root-1] = 0
del tree[root]
else:
for d in delete:
del tree[d]
weights[d-1] = 0
def find_parent(tree:dict,node,parent:set):
# 找到node的所有父节点,并用parent回传(不包括node本身)
for k,v in tree.items():
if node in v['son']:
parent.add(k)
find_parent(tree,k,parent)
break
def batch(weights, tree:dict, cl):
# 计算每个类别的w权重即题目的
omi = omiga(tree,weights)
# 找到 omi中权重最小的索引 即可用得到本次循环选中的节点
min_omi = min(i for i in omi if i != -1)
node = omi.index(min_omi) + 1
# 找到node所有的后代
offspring = set()
visit(tree,node,offspring)
# 判断是否cl在后代之中
if cl in offspring:
# 如果在则删除剩余节点
all_node = set(tree.keys())
delete = all_node - offspring
else:
# 如果不在则删除node及其后代
delete = offspring
# 进行树的删除和权值修改
delete_tree(weights, tree, delete,node)
return node
def main():
# 数据输入
n,m = map(int,input().split())
weights = list(map(int,input().split()))
tree = {i + 1: {'weights':0,'son':set()} for i in range(n)}
# 用cfg读取节点的位置关系
cfg = list(map(int,input().split()))
for node, parent in enumerate(cfg, start=2):
tree[parent]['son'].add(node)
# 权重初始化
for k in tree.keys():
offspring = set()
w = 0
visit(tree,k,offspring)
for i in offspring:
w += weights[i-1]
tree[k]['weights'] = w
answer = []
for _ in range(m):
cl = int(input())
ans =[]
# 数据拷贝
current_weights = weights[:]
current_tree = {key: {'weights': value['weights'], 'son': set(value['son'])} for key, value in tree.items()}
while len(current_tree) > 1:
num = batch(current_weights, current_tree, cl)
ans.append(str(num))
answer.append(ans)
for i in answer:
print(' '.join(i))
if __name__ == "__main__":
main()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









