






1、安装分词器
上github上找人做好的分词器,放到es-plugin数据卷里,然后重启es即可
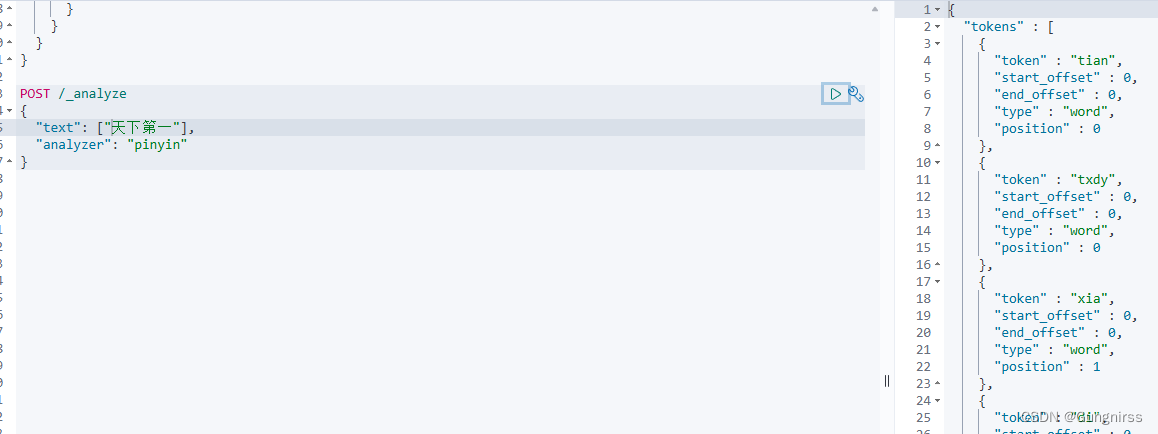
2、自定义分词器
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有iksmart
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
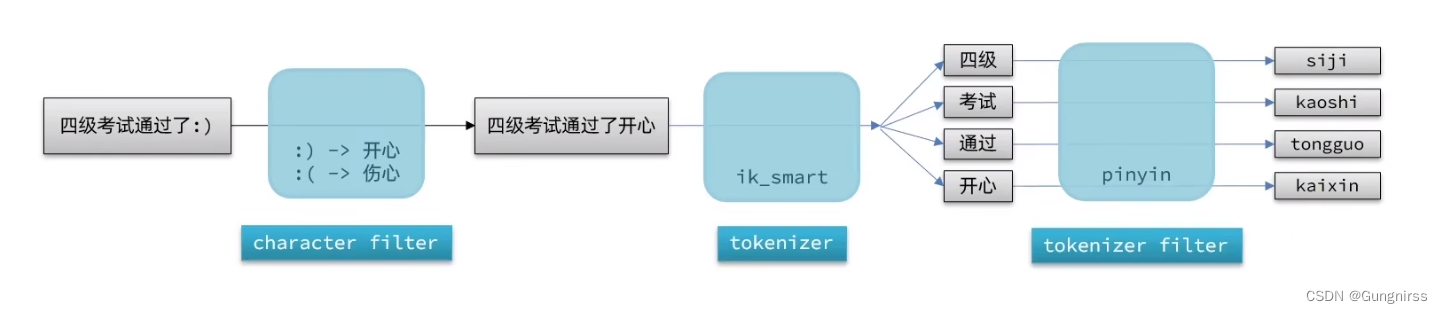
如何使用拼音分词器?
下载pinyin分词器
解压并放到elasticsearch的plugin目录
重启即可
如何自定义分词器?
创建索引库时,在settings中配置,可以包含三部分
character filter
tokenizer
filter
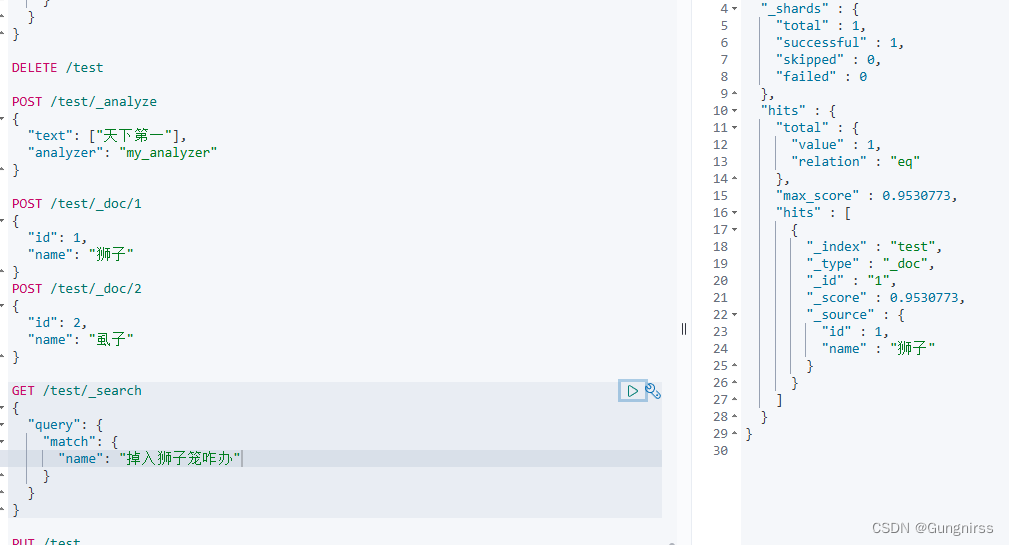
拼音分词器注意事项?
创建索引时可以用拼音分词器,搜索时不要用,否则容易出现重音词,例如搜索狮子,出现虱子
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}上述代码创建了新的索引库,并自定义了名为my_analyzer的分词器,其中使用了ik_max_word作为分词器的tokenizer,并增加了名为py的过滤器,类型为pinyin,即上文的拼音分词器,同时增加自定义其中设置以避免重音词汇出现。
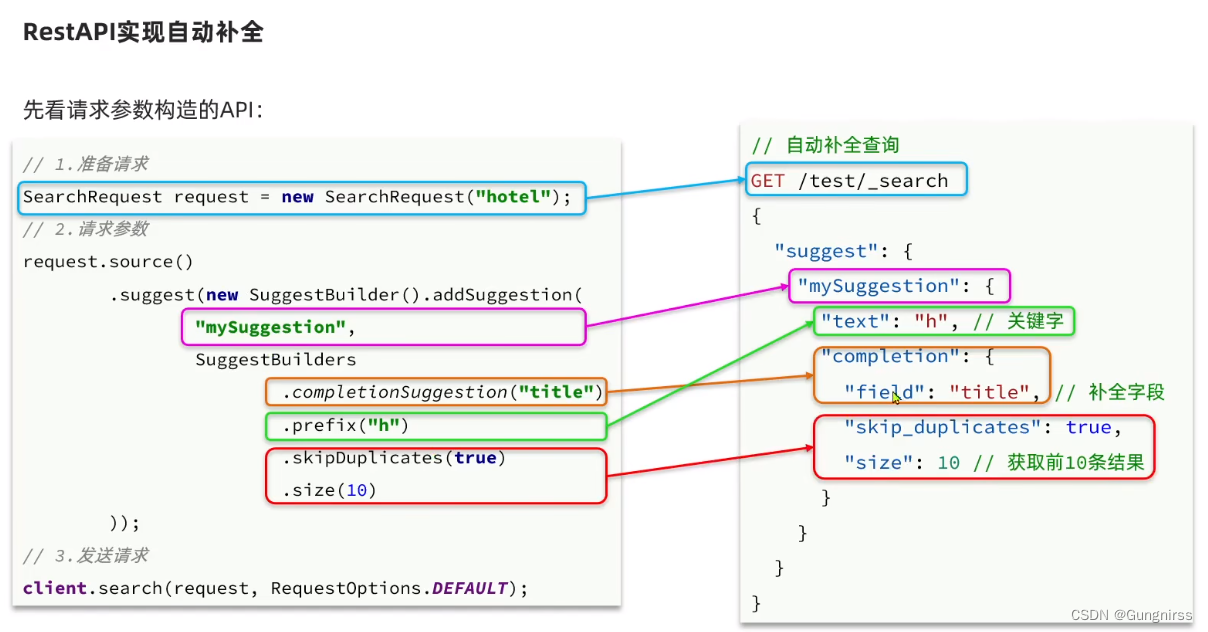
3、DSL与RestClient实现自动补全查询
自动补全对字段的要求:
类型是completion类型
字段值是多词条的数组

suggest查询主要用于提供自动补全、纠错和建议结果的功能
query查询主要用于执行全文搜索、过滤和获取文档等常规查询操作
completion是为用户提供与输入文本相关的自动补全和建议结果,从而提高搜索体验和准确性
GET /hotel/_search
{
"suggest": {
"suggestionsss": {
"text": "h",
"completion": {
"field": "suggestion",
"skip_duplicates": true,
"size": 10
}
}
}
}
这个请求是用来搜索hotel索引中的文档。在这个搜索请求中,使用了suggest功能来为用户提供搜索建议。在suggest对象中,定义了一个名为"suggestionsss"的suggester,该suggester使用了completion类型来生成搜索建议。
请求中的"text"参数指定了用户输入的搜索关键词为"h"。"field"参数指定了要在哪个字段(这里是"suggestion"字段)上进行建议生成。"skip_duplicates"参数指定了是否跳过重复的建议项,这里设置为true表示跳过。"size"参数指定了返回的建议项数量,这里设置为10表示返回10个建议项。
public List<String> suggest(String params) {
try {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"MySuggest",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(params.toString())
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
CompletionSuggestion suggestion = response.getSuggest().getSuggestion("MySuggest");
List<String> list = new ArrayList<>();
for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {
String s = option.getText().toString();
list.add(s);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}通常前端可以监控输入框,在输入的时候自动调用某个方法发送请求到后端对应api并将输入值作为参数传递,此时后端接收到参数便可调用以上方法匹配对应数据并返回。















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









