






RDD对象
弹性分布式数据集
Resilient Distributed Datasets
数据输入
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 通过parallelize成员方法,将python数据容器转RDD对象
# 注:字符串会被拆分成一个个的字符,存入RDD对象
# 字典仅有key会被存入RDD
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("abcdef")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1":"value1", "key2":"value2"})
# 如果要查看RDD里面的内容,需要用collet方法
print(rdd3.collect())
# 通过textFile方法,读取文件来构建RDD对象
rdd_file = sc.textFile("hello.txt")
print(rdd_file.collect())
sc.stop()
数据计算
- map算子:接受一个处理函数,对RDD内的元素逐个处理,并返回一个新的RDD对象
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 通过map(RDD[T],f:(T)->U,)方法将全部数据乘以10
# (T) -> U 能接受一个参数传入,能返回一个返回值
# (T) -> T 传入什么类型,返回就是什么类型
res = rdd.map(lambda x: x * 10).map(lambda x: x + 5)
# 链式调用
print(res.collect())
- flatMap算子:对RDD执行map操作,然后进行 解除嵌套 操作
rdd2 = sc.parallelize(["hello world", "you are", "4 ", "i am", "so"])
res_m = rdd2.map(lambda x: x.split(" "))
res_fm = rdd2.flatMap(lambda x: x.split(" "))
print(res_m.collect())
# [['hello', 'world'], ['you', 'are'], ['4', ''], ['i', 'am'], ['so']]
print(res_fm.collect())
# ['hello', 'world', 'you', 'are', '4', '', 'i', 'am', 'so']
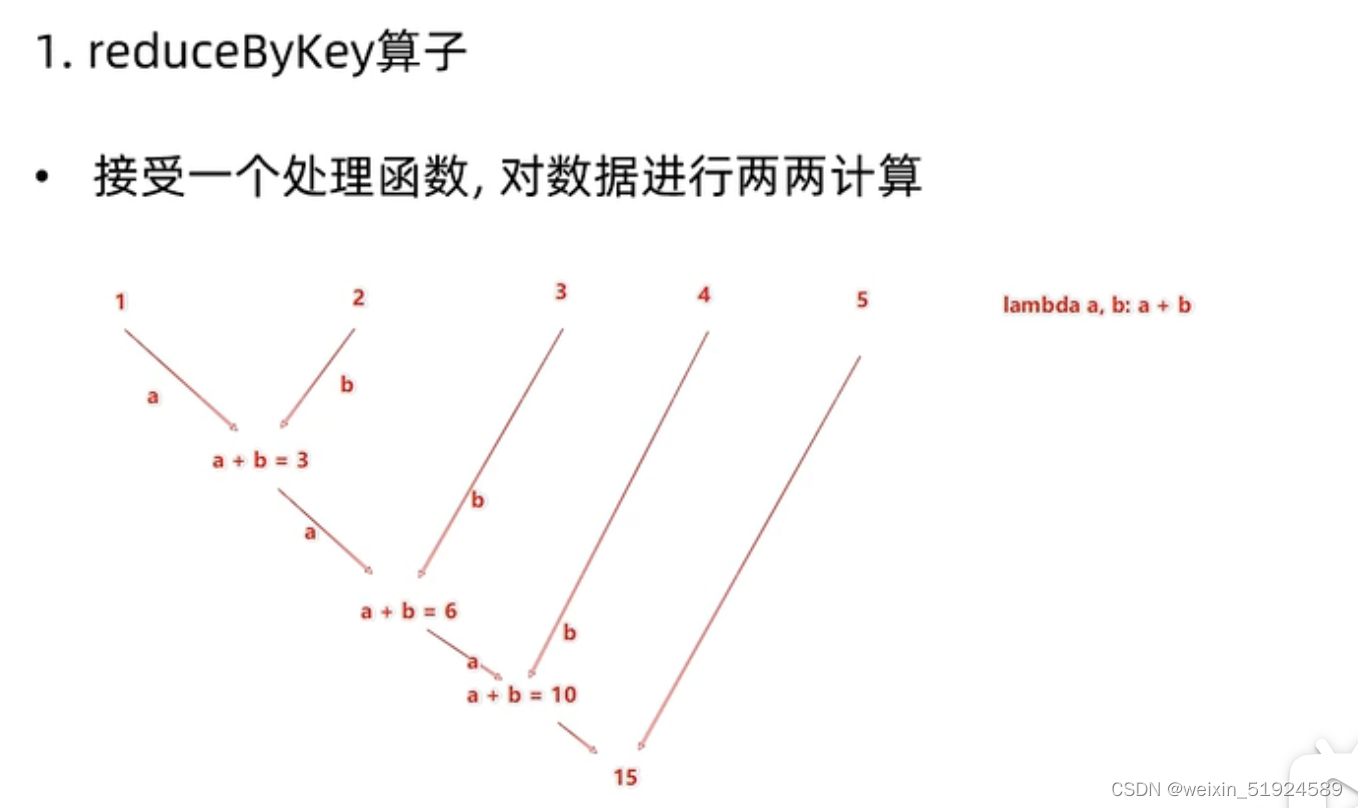
- reduceByKey算子:针对Key-Value型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成 组内数据(value) 的聚合操作
# reduceByKey(func)
# func: (V, V) -> V
# 接受2个传入参数,且类型一致,返回一个返回值,类型与传入参数类型一致
rdd = sc.parallelize([('男', 60), ('男', 50), ('女', 10), ('女', 22)])
res = rdd.reduceByKey(lambda a, b: a + b)
print(res.collect())
# 输出:[('男', 110), ('女', 32)]
rdd = sc.parallelize([("a", 1), ("a", 2), ("a", 3), ("b", 4)])
res = rdd.reduceByKey(lambda a, b: a + b)
print(res.collect())
# 输出结果:[('b', 4), ('a', 6)]
# a: 1+2 = 3 -> 3+3 -> 6 b: 4
注:reduceByKey算子是先根据key进行分组,然后再分别按计算每个分组,输入的func计算逻辑是针对分组之后。
- filter算子:接受一个处理函数,对RDD数据进行过滤,得到True的保留至返回值的RDD中
- distinct算子:对RDD数据进行去重,返回新RDD,无需传参
- sortBy算子: 对RDD数据进行排序,基于指定的排序依据
# sortBy(func, ascending=False, numPartitions=1)
# func: (T) -> U: 告知按照rdd中的哪个数据进行排序
# 如 lambda x: x[1] 表示按照rdd中的第二列元素进行排序
# ascending True 升序 False 降序
# numPartitions: 用多少分区排序 1:全局排序
rdd = sc.parallelize([("a", 11), ("b", 2), ("c", 6), ("d", 4)])
res = rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)
print(res.collect())
# 输出:[('a', 11), ('c', 6), ('d', 4), ('b', 2)]
数据输出
- collect算子:将RDD各个分区的数据,统一收集到Driver中,形成一个List对象,返回值类型为list
- reduce算子:对RDD数据集按照传入的逻辑进行聚合
- take算子: 取RDD的前N个元素,组成list返回
- count算子: 统计RDD内有多少条数据,返回值为数字
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd_list = rdd.collect()
print(rdd_list)
# rdd.reduce(func) 对RDD进行两两聚合
# func: (T, T) -> T
# 传入两个参数,一个返回值,返回值和参数类型一致
num = rdd.reduce(lambda a, b: a + b)
print(num)
take_list = rdd.take(3)
print(take_list)
num_count = rdd.count()
print(num_count)
- saveAsTextFile算子: 将RDD数据写入文本文件中,支持本地写出,hdfs等文件系统。
rdd.saveAsTextFile("路径")
输出的结果是一个文件夹
有几个分区就输出多少个结果文件
# 输出到文件中
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize("abcdef")
rdd3 = sc.parallelize({"key1":"value1", "key2":"value2"})
# 注:必须是不存在的文件,否则会报错
rdd1.saveAsTextFile("test1")
rdd2.saveAsTextFile("test2")
rdd3.saveAsTextFile("test3")

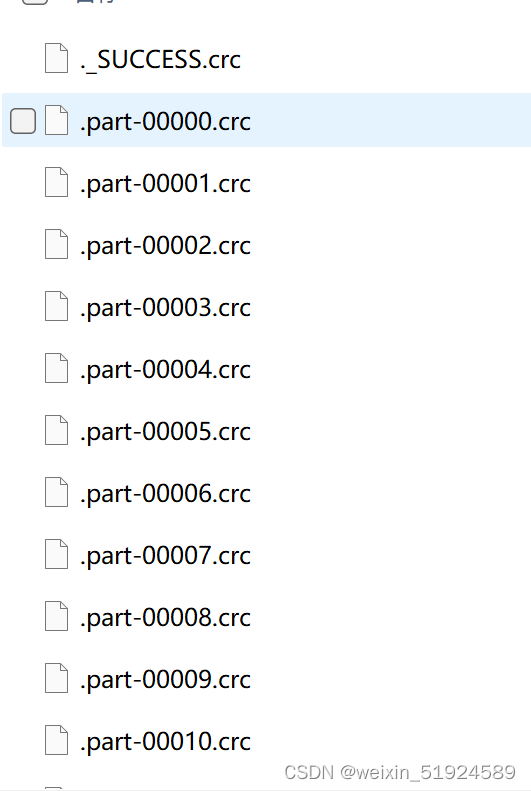
可以看出,写入的文件夹中有非常多的文件,可以通过修改分区个数来减少写入的文件个数
# 修改rdd分区为1个
# 方法一 设置属性全局并行度为1
conf.set('spark.default.parallelism', '1')
sc = SparkContext(conf=conf)
# 方法二 创建RDD时设置
rdd1 = sc.parallelize([1, 2, 3, 4, 5], numSlices=1)
rdd1 = sc.parallelize([1, 2, 3, 4, 5], 1)

















 5706
5706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









