




JDK:Java Development Kit (JDK) 是 Sun 公司(已被 Oracle 收购)针对 Java 开发员的软件开发工具包。自从 Java 推出以来,JDK 已经成为使用最广泛的 Java SDK(Software development kit)。
简单说,JDK 就是 Java 程序员写代码、做开发必须用的工具包 —— 里面有编译 Java 代码的工具、运行 Java 程序的环境,还有各种写代码时要用到的基础 “零件”(比如类库)。
以前是 Sun 公司做的,后来 Sun 被 Oracle 收购,现在 JDK 就归 Oracle 管了。因为 Java 是最常用的编程语言之一,所以 JDK 也成了 Java 开发领域里用得最多的工具包。
新版本 JDK(比如 JDK 11 及以后)装完,Windows 系统通常会自动把关键路径加到环境变量,不用你手动弄;但老版本 JDK(比如 JDK 8 及之前)大多得自己手动配置环境变量。
mac/Linux 系统不管新老版本,基本都要自己手动配环境变量,JDK 不会自动弄。
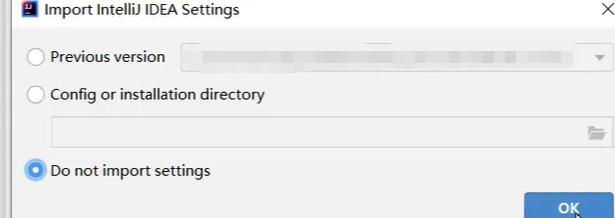
- Previous version:导入 “之前版本” IDEA 的设置(图中路径是之前旧版本 IDEA 存储配置的位置)。
- Config or installation directory:从指定的 “配置或安装目录” 导入设置。
- Do not import settings:不导入任何设置(当前选中了这一项,意味着用全新的、默认的设置启动 IDEA)。

勾选 “.java” 选项 ,在安装完成后,.java 文件就会默认使用 IDEA 打开。
在计算机系统中,尤其是在软件开发和操作系统相关的场景里,bin目录是一个常见的文件夹,它是 “binary”(二进制)的缩写 ,主要用来存放可执行文件
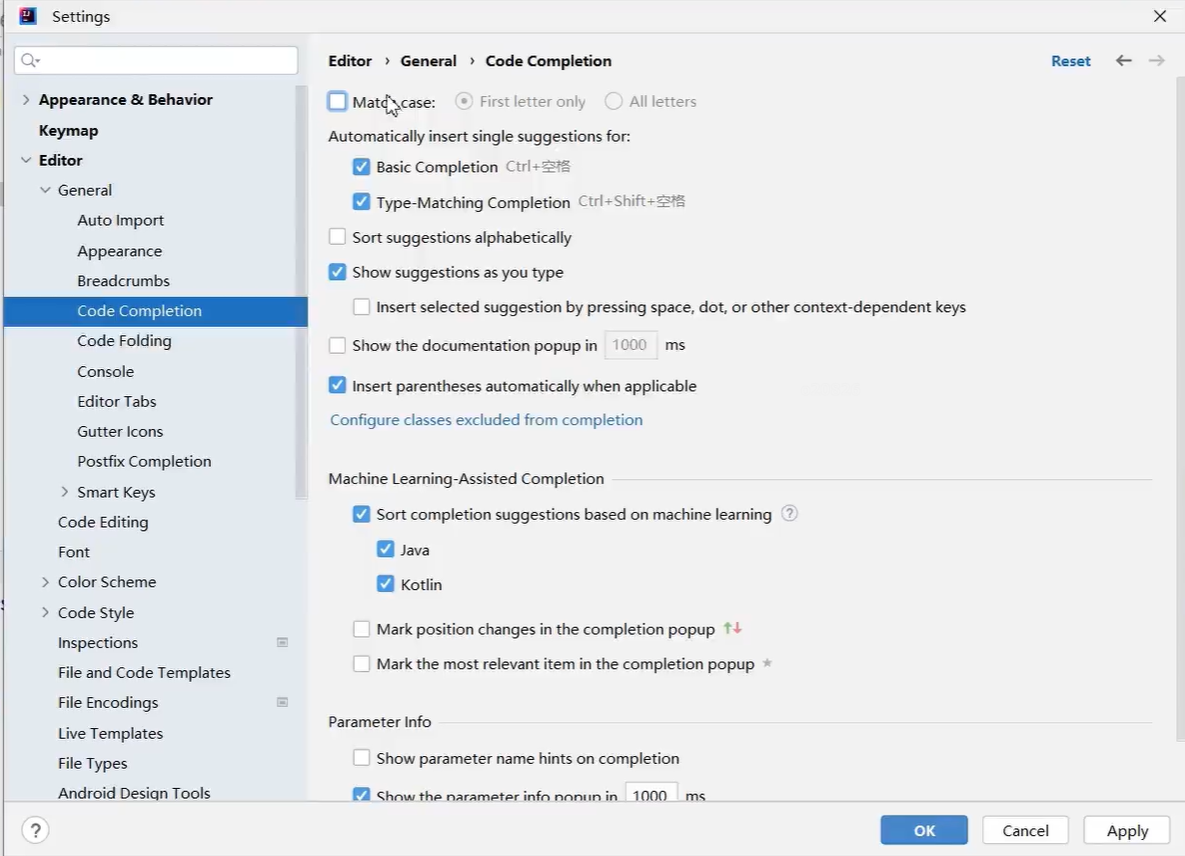
- 勾了 “Match case” 选 “首字母”:只看首字母大小写对不对,对了才提示。
- 勾了 “Match case” 选 “所有字母”:所有字母大小写都得对,才提示。
- 没勾 “Match case”:不管大小写,只要字母对就提示。
- 不管是局部变量还是成员变量,多次运行程序时,每次运行的内存地址通常都是不确定的、会变化的。
原因很简单:每次启动程序,系统内存的使用情况(哪些区域被占用、空闲区域有多少)都可能不同,变量所需的内存是动态分配的,所以每次分配到的具体地址地址一般不会一样。
只有在同一次程序运行中,变量在自己的生命周期内(没出作用域、对象没被回收),地址才是固定的。
- 有没有可能两次运行空间地址一样?
从理论上来说,有可能出现两次运行程序时变量地址相同的情况,但这种情况非常罕见,属于小概率事件。
这就像你两次去同一家餐厅,恰好坐到了同一个座位 —— 虽然有可能,但因为餐厅里的座位使用情况每次都可能不同(比如其他座位是否被占用),所以两次次坐坐到同一个座位的概率很低。
对于程序来说,每次每次运行时系统内存的整体状态(哪些区域被占用、哪些区域空闲)很难完全一致,因此变量恰好分配到同一地址的情况很少见,但并非完全不可能。
Java 中常用整数类型的取值范围如下:
byte:1 字节(8 位),范围是 -128 ~ 127short:2 字节(16 位),范围是 -32768 ~ 32767int:4 字节(32 位),范围是 -2147483648 ~ 2147483647long:8 字节(64 位),范围是 -9223372036854775808 ~ 9223372036854775807
在 Java 中,long类型变量后面不带L,有以下两种情况:
- 赋值数值较小,在
int类型取值范围内:如果赋值的数值在int类型的取值范围(-2147483648 ~ 2147483647 )内 ,比如long num = 10;,虽然没有写L,但 Java 编译器会自动将这个int类型的值转换为long类型,赋值给long类型变量num。 - 赋值数值超出
int类型取值范围 :当赋值的数值超出int类型取值范围, 比如long num = 2147483648;,此时编译器会报错,因为默认情况下,字面量被当作int类型,而2147483648超出了int类型的范围。这种情况下就必须在数值后面加上L(或l,建议用大写L,因为小写l易和数字1混淆),写成long num = 2147483648L;,明确告诉编译器这是一个long类型的字面量。
所以,在数值在int范围内时,long类型变量赋值可不写L ;超出int范围,就必须写L 来表明是long类型字面量。
- 声明
float类型的变量e并赋值为3.14f,注释说明如果用float类型表示一个小数,后面必须加上f,这是因为 Java 中默认的小数字面量是double类型,加上f/F才能明确指定为float类型。 - 声明
double类型的变量f并赋值为3.14,double是双精度浮点类型,能表示的小数范围比float更大、精度更高,Java 中默认的小数字面量就是double类型,所以不需要额外添加标识。
在 Java 中,float和double的精度情况如下:
float
float是单精度浮点型,占用 4 个字节(32 位) 。其中 1 位用于表示符号(正或负),8 位用于表示指数,剩下 23 位用于表示尾数(有效数字) 。它大约能精确到小数点后 6 - 7 位 。比如,float num = 3.1415926f;,实际存储和读取的值可能和输入的不完全一样,存在一定误差。
double
double是双精度浮点型,占用 8 个字节(64 位) 。1 位表示符号,11 位表示指数,52 位表示尾数 。它大约能精确到小数点后 15 - 16 位 ,精度比float高很多,能更准确地表示小数。比如double num = 3.14159265358979323846;,在一定范围内,能更接近真实值。Java 中
double类型的数值后面可以加d或D(大小写都行),用来明确表示这是double类型的字面量。不过通常没必要加,因为 Java 里默认的小数字面量(比如
3.14)本来就是double类型,加不加d/D效果一样。
不过要注意,不管是
float还是double,在表示一些特殊小数(如无限循环小数等)时,都可能出现精度丢失问题,无法精确表示。因为浮点数是用二进制科学计数法存的,像
1.1这类数,二进制里没法精准表示,只能近似存,所以float精度不是固定某几位,大概在小数点后 6 - 7 位左右波动。
在 Java 里,char 不是 1 个字节,而是 2 个字节(16 位)。
因为 Java 的char专门用来表示 Unicode 字符(能涵盖中文、英文、特殊符号等全球大部分字符),1 个字节(8 位)只能存 256 种状态,不够容纳这么多字符,所以用 2 个字节来保证对 Unicode 的支持。
比如 char c = '中'; 这样的写法是合法的,就是因为 2 个字节的空间能存下中文字符的 Unicode 编码。
不管char存储的是单个英文字符(如'a')、中文字符(如'中')还是其他 Unicode 字符,在 Java 中统一占用 2 个字节。
这是因为 Java 的char类型始终是基于 Unicode 编码设计的,无论字符本身是否能用 1 个字节表示,都会固定分配 2 个字节的空间来存储其 Unicode 编码值,确保对各种字符的统一支持。
Unicode 编码目前收录的字符超过 14 万个(持续扩展中)。
Java 中 char 是 2 个字节(16 位),能表示的范围是 2 的 16 次方(65536)个字符(0~65535),刚好覆盖 Unicode 中「基本多文种平面(BMP)」的字符(这部分是最常用的字符,包括大部分中文、英文等)。
对于超出 BMP 的罕见字符(如某些表情符号、古文字),Java 中需要用两个 char 组合表示(即「代理对」机制),本质上还是基于 16 位 char 的扩展。
BMP(基本多文种平面)包含65536 个字符,其编码范围从 U+0000 至 U+FFFF。
不过,其中从 U+D800 到 U+DFFF 是一个空段,不对应任何字符,这是为了用于映射辅助平面的字符而预留的。
U+0000 至 U+FFFF 是 Unicode 编码的表示方式,用来标记字符在编码表中的位置:
- U+ 是 Unicode 编码的固定前缀,代表 “这是一个 Unicode 编码”。
- 后面的 4 位十六进制数字(0000 到 FFFF)是具体编码值,范围对应十进制的 0 到 65535。
整个区间刚好覆盖了 Unicode 基本多文种平面(BMP)的所有字符,也就是最常用的那 65536 个字符(扣除预留的空段后实际略少)。
BMP(基本多文种平面)就是 Unicode 里最常用、覆盖范围最广的字符集合。
它包含了全球绝大多数日常使用的字符,比如:
- 所有英文大小写字母、数字、标点符号
- 大部分常用中文(简体 + 繁体)、日文、韩文
- 常见符号(如货币符号¥$、数学符号 ±×÷ 等)
日常办公、上网、沟通用到的字符,几乎都在 BMP 里;像一些罕见古文字、生僻表情符号这类不常用的字符,才会放在 BMP 之外的其他扩展平面。
Boolean
在Java中,boolean类型的大小没有明确规定(Java规范没强制指定字节数),具体由虚拟机(JVM)实现决定。 实际中常见两种处理方式: - 单独使用时,通常占用1字节(8位),因为计算机内存按字节寻址,无法直接操作更小单位。 - 数组中(boolean[]),可能优化为1位存储(8个boolean挤在1字节里),节省空间。 简单说:单个boolean一般占1字节,数组里更紧凑(1位/个)。
以下是Java中boolean类型的使用示例,体现其在不同场景下的存储特点(逻辑上的使用,不直接体现字节占用):
- 单个
boolean变量:
boolean isTrue = true;
boolean isFalse = false;
System.out.println(isTrue); // 输出 true
这里isTrue和isFalse作为单独变量时,通常各占1字节(具体由JVM决定)。
boolean数组(空间优化):
boolean[] flags = new boolean[8];
flags[0] = true;
flags[1] = false;
// ... 最多可存8个boolean值,可能仅占1字节总空间
数组中的boolean会被压缩存储,8个元素可能只占1字节(每个元素1位)。
无论存储方式如何,boolean的使用逻辑很简单:只能是true(真)或false(假),用于条件判断等场景。
不同 JVM 对 boolean 数组的存储方式可能不同,并非所有 JVM 都一定按 “1 位 / 元素” 压缩存储。
Java 规范只规定了 boolean 的取值是 true/false,但没强制要求数组的具体存储实现 —— 所以不同厂商(如 Oracle JVM、OpenJDK 的 HotSpot JVM、IBM JVM 等)可能有不同优化策略:
- 主流的 HotSpot JVM(日常开发最常用,比如 Oracle JDK、OpenJDK 默认用它)会做优化,把
boolean数组按 “1 位 / 元素” 压缩,8 个元素占 1 字节,节省内存; - 但也有少数 JVM 可能没做这个优化,直接按 “1 字节 / 元素” 存储
boolean数组(和单个boolean变量一样),此时 8 个元素就占 8 字节。
简单说:主流 JVM 会压缩,但不是所有 JVM 都必须这么做,具体看 JVM 的实现。


for 循环就是一种好用的循环结构,步骤很清晰:
- 先设好循环变量初始值;
- 再判断条件成不成立,成立就执行循环里的代码;
- 执行完循环代码,就调整循环变量(比如加 1、减 1);
- 接着又去判断条件,直到条件不成立,循环就停了。
在 Java 里,非static成员(方法、变量)是可以访问static成员(方法、变量)的 ,原因和访问方式如下:
原因
static成员属于类本身,在类加载时就创建并分配内存,不依赖类的实例。而非static成员属于类的实例对象,只有在创建对象后才存在。只要类被加载,非static成员就能访问已存在的static成员。
static
- 可直接调用:不用创建类的实例就能调用,通过类名直接调用,比如
ClassName.addNum();。像工具类中的方法,经常会被修饰为static,方便在不同地方直接使用,而不用每次都创建工具类对象。 - 内存共享:
static方法属于类,在类加载时就分配内存,整个程序运行期间都存在。不同地方调用static方法,访问的是同一份代码逻辑和资源。
方法重载:同一个类里,方法名相同,但参数(个数、类型、顺序)不同
在主流Java开发工具(如IntelliJ IDEA、Eclipse)中:
-
arr.for:快速生成增强for循环(foreach循环)
例:输入arr.for后按回车,自动生成:for (int num : arr) { // 循环体 } -
arr.fori:快速生成普通for循环(带索引)
例:输入arr.fori后按回车,自动生成:for (int i = 0; i < arr.length; i++) { // 循环体,可通过arr[i]访问元素 }
这是工具提供的代码模板快捷键,能快速生成遍历数组的循环结构,不是Java语言本身的语法
数组的声明、创建、赋值合并到一步完成
int[] arr = {15, 91, 47, 62};
// 没有修饰符的类(默认权限)
class MyClass {
// 没有修饰符的变量(默认权限)
int num;
// 没有修饰符的方法(默认权限)
void doSomething() {
// ...
}
}
不写修饰符是允许的,此时访问范围限定在 “同一个包内”
构造器
当一个类没有显式(手动)编写构造器时,Java 系统会自动为这个类提供一个空构造器(也叫默认构造器)。空构造器就是没有参数、方法体也为空(或者说不执行额外操作)的构造器,它的作用是能让我们创建这个类的对象。比如有一个Person类,没写构造器,系统就会默认生成public Person() {}这样的空构造器,之后就可以用Person p = new Person();来创建Person对象。
在Java中,只要一个类没有显式编写任何构造器,不管是否通过new创建该类的对象,Java编译器都会在编译阶段为这个类自动生成一个默认的空构造器(也叫无参构造器)。
比如你写了这样一个类:
class Student {
// 没有显式写任何构造器
String name;
int age;
}
此时,Java编译器会自动为Student类生成一个默认的空构造器,相当于编译器帮你隐式添加了:
public Student() {
// 空方法体,没有额外逻辑
}
哪怕你暂时没有写new Student()来创建对象,这个默认的空构造器也已经被编译器生成好了,等你后续需要创建对象时(比如写Student s = new Student();),就会调用这个默认构造器。
Java 为没有显式编写构造器的类自动生成默认空构造器,主要有以下几个原因:
1. 支持对象的创建
构造器的核心作用是初始化对象。当我们要创建一个类的对象时(比如用 new 类名() 的方式),必须调用构造器。如果没有默认构造器,且类中也没有其他显式构造器,就无法通过 new 类名() 这种最基础的方式创建对象,会导致语法错误。默认构造器的存在,保证了类至少有一个构造器可用,能让我们顺利创建对象。例如:
class Dog {
String name;
}
// 可以通过 new Dog() 创建对象,因为有默认空构造器
Dog dog = new Dog();
### 2. 与继承体系兼容
在 Java 的继承关系中,子类构造器在执行时,会默认先调用父类的构造器(如果子类构造器中没有显式调用父类构造器,就会隐式调用父类的无参构造器)。如果父类没有显式构造器,也没有默认构造器(假设 Java 不自动生成),那么子类构造器在隐式调用父类无参构造器时就会失败,导致继承关系无法正常工作。默认构造器的存在,确保了父类能被子类构造器正确调用,维持继承体系的顺畅。比如:
class Animal {
// 没有显式构造器,有默认空构造器
}
class Cat extends Animal {
public Cat() {
// 隐式调用父类 Animal 的默认空构造器,能正常执行
}
}
### 3. 简化类的编写
对于很多简单的类,可能不需要在构造器中做复杂的初始化操作,只是需要能创建对象即可。如果没有默认构造器,开发者就必须为每个这样的类都显式编写一个无参构造器,这会增加代码量,也显得繁琐。默认构造器的自动生成,简化了这类简单类的编写工作,让代码更简洁。比如一个只用来存储几个属性的 Person 类:
class Person {
String name;
int age;
// 无需显式写无参构造器,默认构造器已足够
}
其实这个规则的逻辑,本质是 Java 在 “帮开发者规避麻烦”,核心是围绕 “对象必须有合法的初始化入口” 来设计的
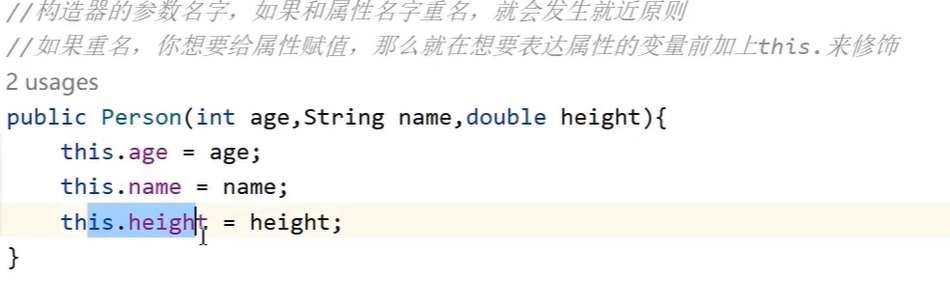
这段内容是在讲解 Java 中构造器里的变量作用域问题。当构造器的参数名和类的属性名(成员变量名)一样时,直接用参数名会遵循 “就近原则”,优先使用参数(局部变量)。如果想给类的属性赋值,就需要用 this.属性名 来明确指定是给类的成员变量赋值。比如代码里的 this.age = age; ,就是把构造器参数 age 的值赋给类的成员变量 age ,this.name 和 this.height 也是同样的道理。
默认值
在Java中,如果声明了成员变量(如int a)但没有手动赋值,会根据变量类型自动获得默认值:
-
基本类型:
- 整数类型(
byte、short、int、long)默认值为0 - 浮点类型(
float、double)默认值为0.0f和0.0 - 布尔类型(
boolean)默认值为false - 字符类型(
char)默认值为'\u0000'(空字符)
- 整数类型(
-
引用类型(如
String、数组、对象等):默认值为null
示例:
class Example {
int a; // 没赋值,默认是0
boolean b; // 默认是false
String s; // 默认是null
}
public class Main {
public static void main(String[] args) {
Example obj = new Example();
System.out.println(obj.a); // 输出 0
System.out.println(obj.b); // 输出 false
System.out.println(obj.s); // 输出 null
}
}
简单说:成员变量不手动赋值时,Java会自动给一个“初始值”,不会像局部变量那样必须手动赋值才能使用(局部变量不赋值直接用会报错)。
'\u0000'的 Unicode 编码值就是 0(十进制)。在 Unicode 编码标准中,
\u0000是编码值为0x0000(十六进制)的字符,对应的十进制数值就是 0,它表示 “空字符”(Null Character),是 Unicode 表中第一个字符,没有实际的可见图形,主要用于表示 “没有字符” 的状态。
-
如果一个类中有构造器,那么编译器就不会帮你分配默认的空构造器
-
尽量保证空构造器的存在,以后学到框架,某些框架底层需要空构造器,如果你没有添加就会报错。
-
快捷键:Alt+insert
在IntelliJ IDEA中,
Alt+Insert是一个非常实用的快捷键,主要用于快速生成代码或文件。具体功能如下:- 生成构造函数:在类内部按下
Alt+Insert,选择“Constructor”,可以根据类中的字段自动生成构造方法。例如,一个类中有name和age两个字段,使用该快捷键选择这两个字段后,可生成public ClassName(String name, int age){this.name = name;this.age = age;}这样的构造函数。 - 生成Getter/Setter方法:按下
Alt+Insert后选择“Getter”或“Setter”,或者直接选择“Getter and Setter”,可以为类中的字段快速生成访问器和修改器方法。 - 重写方法:选择“Override Methods”,可以快速实现父类或接口中定义的方法,如重写
toString()方法等。 - 实现接口方法:当类实现了某个接口但没有实现接口中的所有方法时,按下
Alt+Insert,选择“Implement Methods”,可以自动补全未实现的接口方法。 - 生成测试类:在项目视图中,在类名上按下
Alt+Insert,可以快速创建JUnit测试类。 - 新建文件/包:在项目的目录上按下
Alt+Insert,可以快速创建类、接口、包或资源文件等。
- 生成构造函数:在类内部按下
-
主流的 Java 编译器,比如 Oracle JDK 自带的
javac编译器 、Eclipse 内置的 ECJ 编译器、IntelliJ IDEA 默认使用的javac编译器以及 Kotlin 等语言调用的javac,都遵循 Java 语言规范。只要在 Java 代码中没有显式定义任何构造器,这些编译器都会按照规范,自动为类生成默认的无参构造器。这是 Java 语言规范所规定的内容,目的是为了保证 Java 程序在创建对象等场景下,有基础的构造器可用,不同编译器都会执行这一规则 。
不过,在一些非标准或特殊定制的编译器中,可能会因为对 Java 规范进行了特殊的修改或扩展,存在不遵循该规则的情况,但这种情况极为少见,在日常开发和使用的主流编译器中,都无需担心这个问题。
-
Java 语言规范(Java Language Specification,JLS)由Oracle 公司规定和维护,最早可以追溯到 Java 语言的开发者 Sun Microsystems 公司。
1995 年,Sun 公司推出 Java 语言,为了让 Java 能在不同平台上保持一致,规范其语法、语义等细节,就制定了 Java 语言规范。它涵盖了从词法结构(像关键字、标识符)、语法规则(比如语句结构、表达式写法),到面向对象特性(如类、接口、继承)、内存管理 、异常处理等各个方面。
后来,Oracle 公司收购了 Sun 公司,便由 Oracle 继续负责 Java 语言规范的更新和完善,根据 Java 版本的迭代(像 Java 8、Java 11、Java 17 等 ),不断新增或优化相关规则,以适应新的技术需求和编程场景。
此外,Java 社区(Java Community Process,JCP)在 Java 语言规范的发展过程中也起到重要作用,它由众多 Java 开发者、企业和组织参与,会通过 JSR(Java Specification Requests ,Java 规范提案)对 Java 语言规范的改进提供建议,最终由 Oracle 来整合并落实到正式的规范文档中。
主流的 Java 编译器(比如 javac、ECJ 等)都是严格按照 Java 语言规范来设计的。
封装
封装就是把对象内部复杂的东西藏起来,只对外提供简单好用的接口。就像一个黑盒子,内部怎么运作不用管,只用通过它暴露的少量方法来使用。这样做能让程序更安全、更好维护和扩展,也符合 “高内聚(自己的事自己干,别让外部瞎掺和)、低耦合(对外只露一点,减少和外部的关联)” 的程序设计追求。
比如属性私有化,然后set/get方法
但封装不只是这一点,还能藏方法逻辑、模块里的复杂东西,对外只露有用的。
打个比方,把程序想象成一个工厂:
藏方法逻辑
比如工厂里有个制作手机的makePhone方法,这个方法内部要先采购零件(获取原材料数据),再进行组装(各种计算和操作),最后检测(质量验证逻辑)。
封装方法逻辑,就是把采购、组装、检测这些具体怎么操作的细节都藏起来,不让工厂外面的人知道。外面的人(其他代码)只需要调用makePhone这个方法,告诉工厂要生产手机,就能拿到做好的手机(得到返回结果 ),不用管工厂里面具体是怎么一步步把手机做出来的。这样要是工厂换了采购渠道,或者改变了组装工艺(方法内部逻辑修改),只要makePhone方法对外提供的调用方式(参数和返回值)不变,外面调用它的代码就不受影响。
藏模块里的复杂东西
再把整个工厂看作一个模块。工厂里除了制作手机,还有管理员工考勤、安排生产计划、处理物流发货等好多复杂的业务。
封装模块里的复杂东西,就是把这些复杂业务的具体运作细节都藏起来。只对外提供几个关键的“窗口” ,比如客户只需要通过“订单接收窗口”(模块暴露的接口,像订单处理方法)下订单,就能收到手机,不用了解工厂内部员工考勤是怎么管理的,生产计划是怎么安排的,物流发货是怎么运作的。这样整个工厂(模块)的内部结构哪怕调整了,只要“订单接收窗口”(接口)还能正常工作,和工厂打交道(调用模块)的客户(其他代码)就不会受到影响,而且也让模块更容易被理解和使用 。
简单说: - 藏方法逻辑:你调用“做手机”的功能,不用管里面是怎么采购零件、组装的,只要给你手机就行。 - 藏模块复杂东西:你用“手机工厂”这个模块,不用管厂里怎么管员工、排生产,只要下单能拿到手机就够。 核心就是:复杂的内部操作全遮住,只给你能用的简单入口。
继承
不一定,继承里子类和父类的关系,可能是“抽象→具体”,也可能是“具体→具体”,关键看父类是不是抽象类。
简单说:
- 如果父类是抽象类(比如“动物”这种没法直接实例化的),子类是具体类(比如“猫”“狗”能实例化),那就是“抽象→具体”——子类把父类的抽象概念落地成具体事物;
- 如果父类是具体类(比如“猫”),子类也是具体类(比如“橘猫”),那就是“具体→具体”——子类在父类的基础上多了点具体特性(比如橘猫更爱睡觉)。
所以“抽象与具体”只是继承的一种常见情况,不是全部。
可以这么理解,大部分情况下父类确实比子类“更抽象”——父类描述的是更宽泛、通用的特征,子类则在这个基础上增加了更具体、细化的内容。 比如: - 父类“动物”,描述的是“会动、需要进食”这种所有动物共有的特征,很抽象;子类“猫”,不仅有“动物”的共性,还多了“会喵喵叫、爱抓老鼠”这些具体特点,比父类具体。 - 就算父类是具体类(比如“猫”),子类“橘猫”也比它更具体——“猫”是通用概念,“橘猫”还多了“毛色橘、易发胖”这些更细化的属性。 但要注意,这里的“抽象”是相对的,不是说父类一定是
abstract关键字定义的抽象类,而是指父类的范围更广、特征更通用,子类则是父类这个大范畴里的具体分支。小部分情况是:父类和子类“抽象程度差不多”,甚至父类反而比子类“更具体”——这种情况多发生在“功能扩展”而非“概念细化”的继承场景中。
比如:
- 父类是“具体的工具类”(如
BasicCalculator,能算加减乘除,是完全可实例化的具体类),子类ScientificCalculator继承它,只是新增了“开方、三角函数”等功能,但两者本质都是“计算器”,父类的“加减乘除”是具体功能,子类没在“概念抽象度”上比父类更具体,只是多了功能。- 父类是“具体的业务类”(如
Student,有姓名、学号等具体属性和“上课”方法),子类StudentLeader继承它,只多了“组织班会”的方法,两者都是“学生”这个具体概念,父类没有比子类更抽象,只是子类多了个角色相关的功能。简单说:当继承不是为了“把宽泛概念变具体”,而是为了“给具体事物加功能”时,父类和子类的抽象程度就没明显差距,甚至父类(作为基础具体类)会显得和子类一样具体。
“拓展”是继承的核心用途之一,但不是全部,它还有更基础的作用——复用代码。
简单说,继承主要干两件事:
复用父类代码:父类已经写好的属性(比如“姓名”“年龄”)、方法(比如
getAge()),子类不用再重复写,直接“拿过来用”,省功夫。
比如父类Person有name和getName(),子类Student继承后,不用再写一遍name和getName(),直接就能用this.getName()。拓展子类功能:在复用的基础上,子类可以加自己独有的东西。
比如Student在Person的基础上,新增“学号”属性和“交作业”方法——这就是对父类功能的拓展。所以不能只说“为了拓展”,复用父类已有的代码,减少重复劳动,也是继承很重要的目的。拓展是“在复用之上做加法”,两者结合才是继承的核心价值。
父类里set/get方法都是private的,子类继承能调用吗?
不能。
如果父类的set/get方法被private修饰,子类是无法直接调用的。
因为private是最严格的访问权限,只能在当前类内部使用,即使是子类也无权访问。
比如:
class Parent {
private String name;
// private的get方法
private String getName() {
return name;
}
}
class Child extends Parent {
void test() {
getName(); // 报错!子类不能调用父类的private方法
}
}
如果想让子类能用,父类的set/get方法通常用protected或public修饰符——protected允许许子类访问,public则允许所有地方访问。
重写
- 方法的重写:发生在子类和父类中,当子类对父类提供的方法不满意的时候,要对父类的方法进行重写。
- 方法的重写有严格的格式要求:子类的方法名字和父类必须一致,参数列表(个数,类型,顺序)也要和父类一致。
extends(继承类)和implements(实现接口)都能实现“重写”,但本质和规则不太一样,通俗说就是:前者是“改父类的方法”,后者是“填接口的空方法”。
1. extends 继承类时的重写(真正的“覆盖”)
当子类用 extends 继承一个普通父类(或抽象父类)时,重写是“子类用自己的方法实现,替换父类中同名、同参数、同返回值的方法”,核心是“改实现”。
比如父类 Animal 有个 cry() 方法:
class Animal {
void cry() {
System.out.println("动物叫"); // 父类的默认实现
}
}
子类 Cat 继承后重写 cry(),把“动物叫”改成“喵喵叫”:
class Cat extends Animal {
@Override // 注解标记重写,规范且防错
void cry() {
System.out.println("喵喵叫"); // 子类的新实现,覆盖父类
}
}
这时调用 new Cat().cry(),执行的是子类重写后的方法。
2. implements 实现接口时的“重写”(其实是“实现”)
接口里的方法默认是“空的”(没有方法体,必须让实现类填内容),所以用 implements 时,子类的“重写”本质是“把接口的空方法补全实现”,核心是“填内容”。
比如接口 Swim 有个空方法 swim():
interface Swim {
void swim(); // 接口方法:只有声明,没有实现(像个“待填的空”)
}
类 Fish 实现接口时,必须“填”这个空——写 swim() 的具体实现,看起来像“重写”,其实是“完成接口要求的内容”:
class Fish implements Swim {
@Override
void swim() {
System.out.println("鱼用鳍游"); // 补全接口的空方法
}
}
如果不“填”(不实现接口的所有方法),这个类就必须定义成抽象类(让子类去填)。
一句话区分
extends重写:父类有现成实现,子类改它;implements重写:接口只有空声明,子类填它。

@Override
可以不写,但强烈建议写。
简单说:
- 不写的话,只要方法名、参数、返回值和父类/接口一致,代码也能正常重写并运行;
- 但写了
@Override,编译器会帮你“把关”——如果不小心写错了方法名(比如把cry()写成cryy())、参数不对,编译器会直接报错,避免你因为手误搞出“看似重写、实际没重写”的 bug。
比如你想重写父类的getName(),却写成getNames(),没加@Override的话,编译器不会提醒,代码会默默多一个普通方法,而不是重写;加了@Override,编译器立刻会说“找不到要重写的方法”,帮你及时发现错误。
所以为了代码不出错、更规范,尽量加上。
多态
下面是用Java实现的多态示例,同样以动物叫为例:
// 父类:动物
class Animal {
// 父类定义"叫"的方法
public void speak() {
// 父类方法可以留空或提供默认实现
}
}
// 子类:猫
class Cat extends Animal {
// 重写父类的speak方法
@Override
public void speak() {
System.out.println("喵喵");
}
}
// 子类:狗
class Dog extends Animal {
// 重写父类的speak方法
@Override
public void speak() {
System.out.println("汪汪");
}
}
// 测试类
public class Main {
// 统一的调用方法,参数为父类类型
public static void makeSound(Animal animal) {
animal.speak(); // 实际调用的是子类的实现
}
public static void main(String[] args) {
Animal cat = new Cat(); // 父类引用指向子类对象
Animal dog = new Dog();
makeSound(cat); // 输出:喵喵
makeSound(dog); // 输出:汪汪
}
}
在Java中,多态通过三个要素实现:
- 继承(Cat和Dog继承自Animal)
- 方法重写(子类重写了父类的speak()方法)
- 父类引用指向子类对象(Animal cat = new Cat())
这样做的好处是:我们可以用统一的方式(makeSound方法)处理不同的子类对象,无需关心具体是哪种动物,体现了"同一行为,不同表现"的多态特性。
多态跟属性无关,多态指的是方法的多态,而不是属性的多态。
这是在说明多态的一个关键特点:多态主要体现在方法上,和属性没有关系。也就是说,当我们讨论多态时,关注的是同一个方法在不同情况下有不同的表现形式,而不是属性会有这样的多态情况。比如前面例子里,speak方法在Cat和Dog里有不同实现,这是方法的多态;但如果Animal有个name属性,Cat和Dog即使对name有不同赋值等情况,也不属于多态的范畴。
class Animal {
String name = "动物";
}
class Cat extends Animal {
String name = "猫"; // 隐藏父类属性,不是重写
}
public class Test {
public static void main(String[] args) {
Animal animal = new Cat();
System.out.println(animal.name); // 输出"动物"(根据引用类型Animal决定)
}
}
这里虽然Cat有自己的name,但通过Animal类型引用访问时,得到的仍是父类的name,这与多态的 “动态绑定” 特性完全不同。
所以,属性的不同赋值或定义,不属于多态范畴。
总结
多态有三个关键要素,分别是继承(子类继承父类)、重写(子类重写父类的方法)、父类引用指向子类对象。多态的好处在于能够提高代码的扩展性,当需要添加新的子类时,不需要修改大量已有的代码,只需要按照多态的规则进行编写,就可以让新的子类也能被统一的代码逻辑所处理。
在Java 中除了通过继承实现的多态(子类继承父类,重写父类方法 ,父类引用指向子类对象),还有通过接口实现的多态,下面分别为你介绍:
继承实现多态
通过继承关系,子类重写父类的方法,再使用父类引用指向子类对象来实现多态。代码示例如下:
// 定义父类动物
class Animal {
public void speak() {
System.out.println("动物发出叫声");
}
}
// 定义子类猫,继承自动物类
class Cat extends Animal {
@Override
public void speak() {
System.out.println("喵喵");
}
}
// 定义子类狗,继承自动物类
class Dog extends Animal {
@Override
public void speak() {
System.out.println("汪汪");
}
}
class Test {
public static void main(String[] args) {
Animal cat = new Cat(); // 父类引用指向子类对象
Animal dog = new Dog();
cat.speak(); // 输出喵喵
dog.speak(); // 输出汪汪
}
}
在这个例子里,Cat和Dog继承自Animal,重写了speak方法,当使用Animal类型的引用调用speak方法时,会根据实际指向的子类对象,调用子类重写后的方法 。
接口实现多态
一个类实现多个接口,或者多个类实现同一个接口,实现接口中的抽象方法,然后通过接口引用指向实现类对象,来达成多态效果。示例代码如下:
// 定义一个接口
interface Shape {
void draw(); // 抽象方法,用于绘制图形
}
// 定义圆形类,实现Shape接口
class Circle implements Shape {
@Override
public void draw() {
System.out.println("绘制圆形");
}
}
// 定义矩形类,实现Shape接口
class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("绘制矩形");
}
}
class TestInterfacePolymorphism {
public static void main(String[] args) {
Shape circle = new Circle(); // 接口引用指向实现类对象
Shape rectangle = new Rectangle();
circle.draw(); // 输出绘制圆形
rectangle.draw(); // 输出绘制矩形
}
}
在这个例子中,Circle和Rectangle都实现了Shape接口,并重写了draw方法,通过Shape接口类型的引用调用draw方法时,就会根据实际指向的实现类,调用对应的draw实现方法,这就是通过接口实现的多态。
无论是继承还是接口,多态的本质都是在运行时根据对象的实际类型来决定调用哪个方法,让代码更加灵活、可维护和可扩展。
继承与接口的设计理念
从设计理念来看:
-
继承:更偏向“是一种”的关系,比如“猫是一种动物”,是具体事物(猫)和更抽象概念(动物),或者具体事物(波斯猫)和具体事物(猫)之间的关联,体现的是类与类之间的纵向关系,侧重于代码的复用和类型的层次结构。
-
接口:就像工厂里的规则文档,规定了“所有产品(实现类)都得有这些生产步骤(方法)”,但具体每个产品怎么执行这些步骤(方法实现)可以不同。它是一种“必须遵守的契约”,强调的是横向的行为规范,让不同的类(即使彼此无继承关系)能遵循同一套行为标准,从而在流程中被统一处理,提升系统的灵活性和可扩展性。
-
继承:指子类继承父类的属性和方法,能提高代码的复用性,体现的是“is - a”(“是一种”)的关系。比如,“猫”类继承“动物”类,说明“猫”是一种“动物”。
-
实现:是实现类对接口的实现,用于遵循接口规定的规则,体现的是“has - a”(“有一个”)的关系。比如,“汽车”类实现“可行驶”接口,意味着“汽车”有“可行驶”的能力。
异常处理
- 异常的定义:程序运行过程中发生的不正常事件,会中断程序运行,如所需文件找不到、网络连接问题、算术运算错误(被零除等)、数组下标越界、操作不存在的类或
null对象、类型转换异常等常见异常情况。 - Java 异常处理的优势:能将异常处理代码和业务代码分离,让程序更优雅,具备更好的容错性和健壮性。
- Java 异常处理通过
try、catch、finally、throw、throws这 5 个关键字来实现。
下面通过一个简单的例子来展示 Java 异常处理(以 try - catch 为例):
public class ExceptionDemo {
public static void main(String[] args) {
// 可能出现异常的代码放在 try 块中
try {
int result = 10 / 0; // 这里会发生算术异常(被零除)
System.out.println("计算结果:" + result);
} catch (ArithmeticException e) {
// catch 块捕获特定的异常(这里是算术异常),并进行处理
System.out.println("出现异常啦!原因是:" + e.getMessage());
}
System.out.println("程序继续执行,没有因为异常而完全中断~");
}
}
代码解释
try块:把可能抛出异常的代码(这里是10 / 0,会引发算术异常)包裹起来。catch块:当try块里的代码抛出ArithmeticException(算术异常)时,就会进入对应的catch块。在这个catch块中,我们打印出异常的原因。- 运行结果:程序不会因为
10 / 0这个错误而直接崩溃,而是会执行catch里的处理逻辑,然后继续执行后面的代码(输出“程序继续执行,没有因为异常而完全中断~”)。
在IDEA中,使用
try - catch有以下常用快捷键:快速为选中代码添加try - catch块
- 操作步骤:
- 选中你想要包裹在
try - catch中的代码,可以是一行代码,也可以是一个代码块。- 按下快捷键**
Ctrl + Alt + T** (Windows和Linux系统),或者Command + Option + T(Mac系统) 。- 这时候会弹出一个菜单,选择**
Surround with try/catch**选项,IDEA就会自动为选中的代码添加合适的try - catch块,并且根据代码可能抛出的异常类型,自动生成对应的catch块。
这段文字是在讲解 Java 中 try - catch 的执行情况,分三种情形:
- 情况1:
try里的代码没异常,那就不执行catch里的代码,直接执行catch后面的代码。 - 情况2:
try里的代码有异常,且catch里的异常类型能匹配(相同或者是父类异常),Java 会生成异常对象,找到匹配的catch块执行里面的代码,之后执行catch后面的代码,try里没执行完的语句就不执行了。 - 情况3:
try里的代码有异常,但catch里的异常类型不匹配,catch里的代码不执行,catch后面的代码也不执行,程序直接中断。
还提到了 catch 块处理异常的一种方式:自定义内容输出。
在
catch块中进行自定义内容输出,是处理异常时常用的方式之一,目的是让异常提示更直观、更符合业务场景,方便开发者或用户理解问题所在。例如,当程序读取文件失败时,默认的异常信息可能包含复杂的堆栈跟踪或系统级描述,而通过自定义输出,可以转化为更友好的提示:
try { // 尝试读取文件 FileReader fr = new FileReader("data.txt"); } catch (FileNotFoundException e) { // 自定义异常内容输出,而非直接打印默认异常信息 System.out.println("操作失败:找不到指定的文件 'data.txt',请检查文件路径是否正确。"); // 也可以结合默认异常信息一起输出(便于调试) // e.printStackTrace(); // 打印完整异常堆栈,用于开发阶段排查问题 }这里的核心是:
catch块捕获异常后,不局限于使用e.printStackTrace()打印默认信息,而是根据实际需求,用System.out.println()等方式输出自定义文本,让异常处理更灵活、更贴近业务逻辑的表达。
某种情况
public class Main {
public static void main(String[] args) {
int a, b, c;
try {
a = 10;
b = 0;
c = a / b;
} catch (Exception e) {
// 捕获到异常后,抛出运行时异常,程序在此处中断
throw new RuntimeException(e);
}
// 由于异常抛出,程序不会执行到这里,所以a无法打印
System.out.println(a);
}
}
一、多个catch块
- 执行顺序:当
try块可能抛出多种不同类型的异常时,可以编写多个catch块。Java 会按照catch块的书写顺序,从上到下依次检查异常类型是否匹配。一旦找到匹配的catch块,就执行该块代码,后面的catch块不再检查。 - 异常捕获规则:子类异常的
catch块要写在父类异常的catch块前面。比如FileNotFoundException是IOException的子类,如果先写捕获IOException的catch块,那么捕获FileNotFoundException的catch块将永远不会执行 。示例代码如下:
try {
// 可能抛出多种异常的代码
} catch (FileNotFoundException e) {
// 处理文件未找到异常
} catch (IOException e) {
// 处理更宽泛的IO异常
}
二、finally块
- 执行时机:
finally块是可选的,不管try块中的代码是否抛出异常,也不管catch块是否执行,finally块中的代码都会在try - catch结构结束时执行(除非在try或catch块中执行了System.exit(0)等终止程序的操作)。 - 用途:常用于资源的释放,比如关闭文件流、数据库连接等。示例如下:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class TryCatchFinallyExample {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("test.txt");
// 读取文件相关操作
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fis != null) {
try {
fis.close(); // 确保文件流被关闭
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
三、异常重新抛出
- 在catch块中重新抛出:在
catch块中捕获到异常后,有时不希望在当前方法处理,而是想让调用该方法的上层方法来处理,可以使用throw语句重新抛出异常。例如:
public class ExceptionRethrow {
public static void method1() throws IOException {
try {
// 可能抛出IOException的代码
} catch (IOException e) {
System.out.println("method1中捕获到异常,重新抛出");
throw e; // 重新抛出捕获到的异常
}
}
public static void main(String[] args) {
try {
method1();
} catch (IOException e) {
System.out.println("在main方法中处理异常");
}
}
}
- 注意事项:如果一个方法中可能抛出受检异常,且没有在方法内部处理,就需要在方法声明处使用
throws关键字声明该异常,告知调用者这个方法可能会抛出的异常类型。
IDEA的导航栏(菜单栏)一直显示
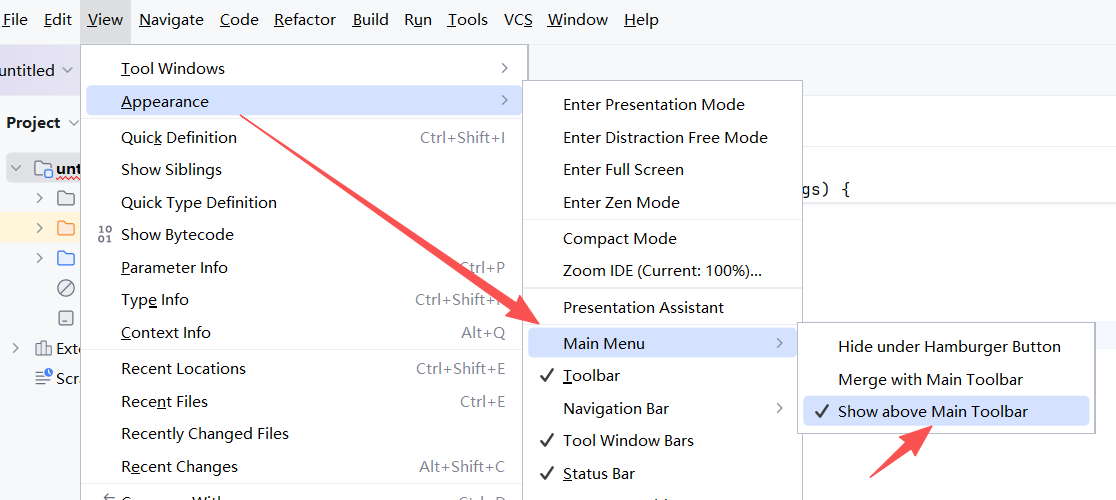
从你提供的截图来看,要让IDEA的导航栏(菜单栏)一直显示 ,具体操作路径如下:
- 点击菜单栏中的
View选项 ,打开下拉菜单。 - 在下拉菜单里找到
Appearance选项,鼠标悬停上去,会展开二级菜单。 - 在展开的二级菜单中,查看
Main Menu选项是否勾选 。如果没有勾选,点击勾选它,这样导航栏(菜单栏)就会一直显示在界面上了。
常见异常
Java 中的异常分为两大类:受检异常(Checked Exception) 和非受检异常(Unchecked Exception),以下是常见异常及其作用:
一、非受检异常(继承自 RuntimeException,编译时不强制处理)
-
NullPointerException(空指针异常)- 作用:当调用
null对象的方法或访问其属性时抛出。 - 示例:
String s = null; s.length();
- 作用:当调用
-
IndexOutOfBoundsException(索引越界异常)- 子类:
ArrayIndexOutOfBoundsException(数组索引越界)、StringIndexOutOfBoundsException(字符串索引越界)。 - 作用:访问数组、字符串等容器时,索引超出有效范围(如负数或大于等于长度)时抛出。
- 示例:
int[] arr = {1,2}; arr[3];
- 子类:
-
ArithmeticException(算术异常)- 作用:算术运算出错时抛出(最常见为除以 0)。
- 示例:
int a = 10 / 0;
-
ClassCastException(类型转换异常)- 作用:强制类型转换失败时抛出(如将
String强转为Integer)。 - 示例:
Object obj = "hello"; Integer num = (Integer) obj;
- 作用:强制类型转换失败时抛出(如将
-
IllegalArgumentException(非法参数异常)- 作用:方法接收到无效参数时抛出(通常由开发者主动抛出)。
- 示例:
if (age < 0) throw new IllegalArgumentException("年龄不能为负数");
-
NoSuchElementException(无此元素异常)- 作用:访问集合中不存在的元素时抛出(如迭代器遍历完后继续调用
next())。
- 作用:访问集合中不存在的元素时抛出(如迭代器遍历完后继续调用
二、受检异常(编译时必须处理,否则报错)
-
IOException(IO 异常)- 子类:
FileNotFoundException(文件未找到)、EOFException(文件读取到末尾)等。 - 作用:文件读写、网络传输等 IO 操作失败时抛出。
- 示例:读取不存在的文件
new FileInputStream("test.txt")。
- 子类:
-
ClassNotFoundException(类未找到异常)- 作用:通过类名动态加载类时,找不到对应类的字节码文件(
.class)时抛出。 - 示例:
Class.forName("com.example.User")(类路径错误)。
- 作用:通过类名动态加载类时,找不到对应类的字节码文件(
-
InterruptedException(中断异常)- 作用:线程在休眠(
sleep())或等待(wait())时被其他线程中断时抛出。 - 示例:
Thread.sleep(1000)被interrupt()中断。
- 作用:线程在休眠(
-
SQLException(数据库异常)- 作用:数据库操作(如连接失败、SQL 语法错误)时抛出。
- 示例:执行错误的 SQL 语句
select * from userx(表不存在)。
三、错误(Error,非异常,通常无法处理)
OutOfMemoryError(内存溢出错误):程序占用内存超过虚拟机限制。StackOverflowError(栈溢出错误):递归调用过深导致栈内存耗尽。- 特点:属于严重问题,一般由 JVM 抛出,开发者无需处理,需从代码或环境层面解决。
这些异常的作用本质是标识程序运行中的不同错误场景,帮助开发者定位问题,通过 try-catch 处理后可避免程序直接崩溃,提升健壮性。
除了上述常见异常外,Java 中还有一些其他的异常:
受检异常
CloneNotSupportedException
- 作用:当一个类没有实现
Cloneable接口,却调用了Object类的clone()方法时,就会抛出这个异常。因为只有实现了Cloneable接口的类,才能合法地进行对象克隆操作。- 示例:
class MyClass { // 未实现 Cloneable 接口 } public class Main { public static void main(String[] args) { MyClass obj = new MyClass(); try { MyClass clonedObj = (MyClass) obj.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } } }
NoSuchMethodException
- 作用:当使用反射机制,试图访问一个类中不存在的方法时抛出。比如通过
Class.getMethod()或Class.getDeclaredMethod()方法获取类的方法,传入的方法名或参数类型与实际不匹配时就会触发该异常。- 示例:
import java.lang.reflect.Method; public class Main { public static void main(String[] args) { try { Method method = String.class.getMethod("notExistMethod"); } catch (NoSuchMethodException e) { e.printStackTrace(); } } }
ParseException
- 作用:在进行数据解析时,如果数据格式不符合预期就会抛出。常见于
SimpleDateFormat类对日期字符串进行解析时,若日期字符串格式和指定的格式模式不匹配,就会触发此异常。- 示例:
import java.text.ParseException; import java.text.SimpleDateFormat; public class Main { public static void main(String[] args) { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); try { sdf.parse("2025/09/20"); } catch (ParseException e) { e.printStackTrace(); } } }非受检异常
ConcurrentModificationException
- 作用:在多线程环境下,当一个线程正在遍历集合(如
ArrayList、HashMap等非线程安全集合),另一个线程对该集合进行了结构上的修改(如添加、删除元素),就会抛出这个异常。单线程中,在使用迭代器遍历集合时,直接通过集合对象修改集合结构,也会触发此异常。- 示例:
import java.util.ArrayList; import java.util.Iterator; public class Main { public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); list.add(1); list.add(2); Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()) { Integer num = iterator.next(); if (num == 1) { list.remove(num); } } } }
IllegalStateException
- 作用:表示对象当前处于非法或不适当的状态,无法执行请求的操作。比如在
Scanner对象已经关闭后,再次调用它的方法进行输入读取就会抛出此异常。- 示例:
import java.util.InputMismatchException; import java.util.NoSuchElementException; import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); scanner.close(); try { int num = scanner.nextInt(); } catch (IllegalStateException e) { e.printStackTrace(); } } }这些异常进一步完善了 Java 的异常体系,覆盖了更多程序运行过程中可能出现的错误场景,帮助开发者写出更加健壮和稳定的代码。
在 Java 异常处理中,缩小异常范围(精准捕获特定异常)比直接用 Exception 更好,原因如下:
1. 代码可读性与可维护性更高
- 直接捕获
Exception会捕获所有类型的异常(包括受检异常、运行时异常等),但很多异常的处理逻辑是不同的。 - 精准捕获特定异常,能让代码阅读者一眼明白“这段代码针对哪种错误场景处理”。
示例:
// 不好的写法:捕获所有异常
try {
// 可能涉及文件操作、网络请求、算术运算等多种逻辑
FileInputStream fis = new FileInputStream("test.txt");
int result = 10 / 0;
} catch (Exception e) {
// 无法区分是文件没找到,还是除以 0,只能统一处理
System.out.println("发生了异常");
}
// 更好的写法:精准捕获
try {
FileInputStream fis = new FileInputStream("test.txt");
int result = 10 / 0;
} catch (FileNotFoundException e) {
// 专门处理“文件没找到”的情况(比如提示用户检查文件路径)
System.out.println("文件不存在,请检查路径");
} catch (ArithmeticException e) {
// 专门处理“算术错误”(比如提示用户输入合法数字)
System.out.println("算术运算错误,除数不能为 0");
}
### 2. 避免隐藏真正的错误
- 如果直接捕获
Exception,可能会把一些本应终止程序的严重错误(如OutOfMemoryError这类Error,或关键业务逻辑的运行时异常)“悄悄处理掉”,导致问题被掩盖,后续难以排查。 - 精准捕获特定异常,能保证“只处理预期内的错误”,意外的严重错误会正常暴露,便于及时修复。
3. 符合“单一职责”原则
每个 catch 块只处理一种特定异常,职责更单一,也更符合面向对象的设计思想。
总结
- 优先精准捕获特定异常(如
FileNotFoundException、ArithmeticException等)。 - 只有当多种异常的处理逻辑完全相同时,才考虑捕获更通用的异常(但仍要避免直接捕获
Exception或Throwable)。
throw:主动抛出具体异常对象
public void checkAge(int age) {
if (age < 0) {
// 当年龄为负数时,主动抛出非法参数异常
throw new IllegalArgumentException("年龄不能为负数");
}
}
throws:声明方法可能抛出的异常
// 声明方法可能抛出文件未找到异常
public void readFile(String path) throws FileNotFoundException {
// 调用可能抛出FileNotFoundException的方法
FileInputStream fis = new FileInputStream(path);
}
ArrayList
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
// 1. 创建ArrayList(存储Integer类型)
ArrayList<Integer> numbers = new ArrayList<>();
// 2. 添加元素
numbers.add(10); // 末尾添加
numbers.add(20);
numbers.add(1, 15); // 指定索引插入(索引1位置)
System.out.println("添加后: " + numbers); // [10, 15, 20]
// 3. 获取元素
int first = numbers.get(0);
System.out.println("索引0的元素: " + first); // 10
// 4. 修改元素
int oldValue = numbers.set(1, 18); // 替换索引1的元素
System.out.println("修改后: " + numbers); // [10, 18, 20]
System.out.println("被替换的值: " + oldValue); // 15
// 5. 删除元素
int removedByIndex = numbers.remove(0); // 按索引删除
System.out.println("删除索引0后: " + numbers); // [18, 20]
System.out.println("被删除的值: " + removedByIndex); // 10
boolean isRemoved = numbers.remove(Integer.valueOf(20)); // 按值删除
System.out.println("删除值20后: " + numbers); // [18]
System.out.println("是否删除成功: " + isRemoved); // true
// 6. 其他常用方法
System.out.println("当前大小: " + numbers.size()); // 1
System.out.println("是否包含18: " + numbers.contains(18)); // true
System.out.println("是否为空: " + numbers.isEmpty()); // false
// 7. 遍历方式
System.out.println("\n普通for循环遍历:");
for (int i = 0; i < numbers.size(); i++) {
System.out.println(numbers.get(i));
}
// 添加更多元素用于演示
numbers.add(30);
numbers.add(40);
System.out.println("\n增强for循环遍历:");
for (int num : numbers) {
System.out.println(num);
}
System.out.println("\nforEach遍历(Java 8+):");
numbers.forEach(System.out::println);
// 8. 清空列表
numbers.clear();
System.out.println("\n清空后是否为空: " + numbers.isEmpty()); // true
}
}
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.stream.Collectors;
public class ArrayListRemoveDemo {
public static void main(String[] args) {
List<Book> books = new ArrayList<>();
books.add(new Book(1, "Java编程"));
books.add(new Book(2, "Python入门"));
books.add(new Book(3, "数据结构"));
books.add(new Book(2, "Python进阶")); // 重复id示例
// 目标:删除所有id=2的书籍
// 方法1:使用迭代器(安全删除,适合多线程或复杂场景)
Iterator<Book> iterator = books.iterator();
while (iterator.hasNext()) {
if (iterator.next().getId() == 2) {
iterator.remove(); // 迭代器自带的删除方法,安全高效
}
}
System.out.println("方法1删除后:" + books);
// 重新初始化列表用于测试其他方法
books.clear();
books.add(new Book(1, "Java编程"));
books.add(new Book(2, "Python入门"));
books.add(new Book(3, "数据结构"));
books.add(new Book(2, "Python进阶"));
// 方法2:使用removeIf(Java 8+,简洁高效,推荐单线程)
books.removeIf(book -> book.getId() == 2); // 一行代码搞定
System.out.println("方法2删除后:" + books);
// 重新初始化列表
books.clear();
books.add(new Book(1, "Java编程"));
books.add(new Book(2, "Python入门"));
books.add(new Book(3, "数据结构"));
books.add(new Book(2, "Python进阶"));
// 方法3:使用Stream过滤(不修改原列表,适合需要保留原列表的场景)
List<Book> filteredBooks = books.stream()
.filter(book -> book.getId() != 2) // 保留id≠2的元素
.collect(Collectors.toList());
System.out.println("方法3过滤后:" + filteredBooks);
System.out.println("原列表未改变:" + books);
}
}
File 类在 Java 中主要用于对文件和目录进行操作。它可以封装要操作的文件或目录的路径等信息,能实现查看文件大小、判断文件是否隐藏、是否可读等操作。不过,File 类有局限,它不涉及文件内容的操作,比如读取或写入文件里的具体数据,若要进行文件内容相关操作,就需要借助 Java 的 I/O 流来完成。
IO流
这是关于 Java 中 I/O 流分类的内容。
I/O 流主要有三种分类方式:
-
按方向分,有输入流(把数据读进来)和输出流(把数据写出去);
-
按处理单元分,有字节流(以字节为单位处理数据,适合处理图片、音频等)和字符流(以字符为单位处理数据,适合处理文本);
-
按功能分,有节点流(直接和数据源打交道)和处理流(对节点流进行包装,增强功能)。
可以把节点流想象成直接从“水源”(像文件、内存等数据源)取水的工具,而处理流就是在这个工具外面套的“过滤装置”,能让取水(数据操作)更高效或者具备更多功能,比如缓冲、转换等,是对节点流的包装强化。
- 节点流就像单根直接连到数据源的管子,比如直接连到文件的管子,数据直接从文件通过这根管子传输。
- 处理流呢,像是在节点流这根管子外,又套了一根或多根管子,这些 “外层管子” 能给数据传输加 buff,比如有的管子能帮着缓冲数据(让传输更顺畅),有的能转换数据格式,相当于对节点流进行了功能增强,是 “包装” 后的组合管子~
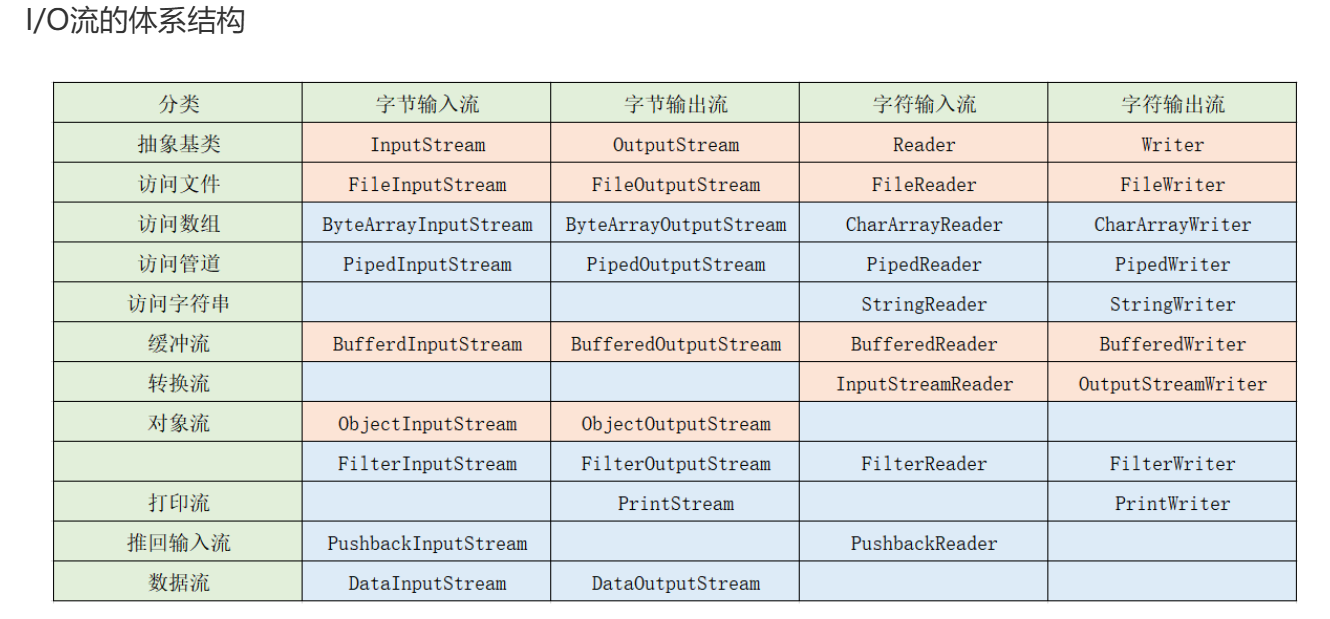
- 写入
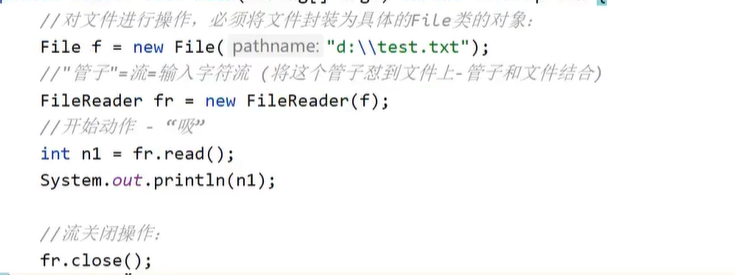
- 写出
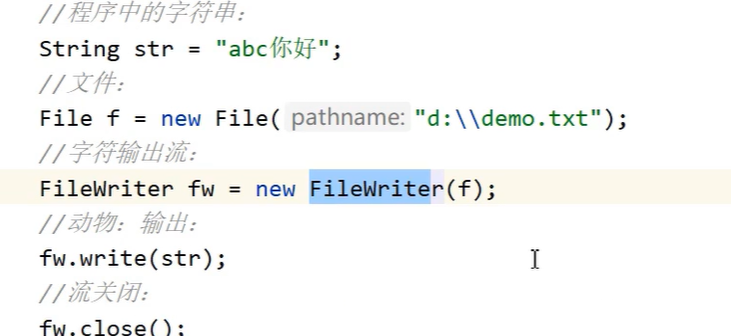
- 对象流:
ObjectInputStream、ObjectOutputStream(专门用于对象的输入输出,能把对象写入文件或者从文件中读取对象)这些类都属于对象流相关的类。 - 序列化:一个类要实现
Serializable接口,这样它的对象才能够被输出到文件中(也就是实现对象的持久化存储等操作)。
假设你把一个Person对象(有name、age属性)序列化后,存到了test.txt文件里(此时文件里是一堆代表这个对象的字节)。当你想重新把这个Person对象读出来时:
- 先用
FileInputStream打开test.txt,把文件里的字节读进来。 - 再把
FileInputStream传给ObjectInputStream(相当于ObjectInputStream拿着FileInputStream读好的字节)。 - 最后通过
ObjectInputStream的readObject()方法,就能把这些字节还原成一个Person对象。
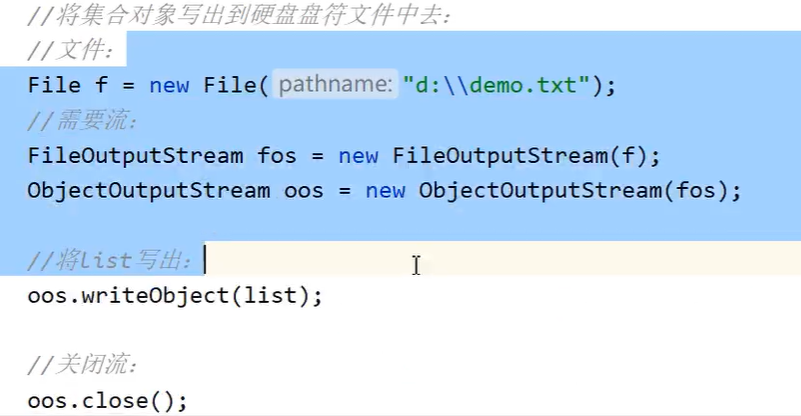


new FileWriter(file)这一步,会自动创建文件(如果文件原本不存在的话)。
writeObject() 方法本身不会主动判断“覆盖”或“追加”,它的行为取决于底层流的打开方式:
-
如果底层流(比如
FileOutputStream)是以“覆盖模式”打开(默认方式,如new FileOutputStream("file.dat")),那么使用writeObject()写入对象时,会覆盖文件原有内容,文件里最终只会保留最后一次写入的对象。 -
如果底层流是以“追加模式”打开(构造时加第二个参数
true,如new FileOutputStream("file.dat", true)),那么writeObject()写入的对象会追加到文件末尾,不会覆盖原有内容,文件里会保留多次写入的所有对象。
简单说:writeObject() 的“覆盖/追加”特性,由它依赖的底层输出流的打开方式决定,而非方法本身。
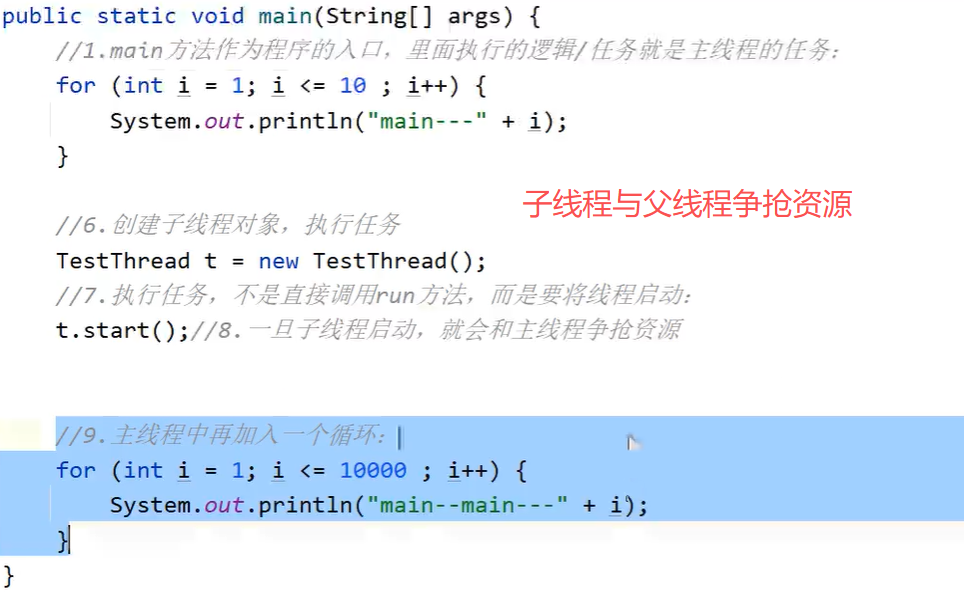
线程是进程内部的一条执行路径。一个进程可以被细化成多个线程,如果一个进程能在同一时间并行执行多个线程,就说明它支持多线程。
线程
// 方式1:继承Thread类
class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("Thread-" + Thread.currentThread().getId() + ": " + i);
try {
Thread.sleep(100); // 休眠100毫秒
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 方式2:实现Runnable接口
class MyRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println("Runnable-" + Thread.currentThread().getId() + ": " + i);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 方式3:实现Callable接口
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i <= 5; i++) {
sum += i;
System.out.println("Callable-" + Thread.currentThread().getId() + ": 累加" + i + ",当前和为" + sum);
Thread.sleep(100);
}
return sum; // 返回计算结果
}
}
public class ThreadExamples {
public static void main(String[] args) {
// 启动方式1创建的线程
MyThread thread1 = new MyThread();
thread1.start();
// 启动方式2创建的线程
Thread thread2 = new Thread(new MyRunnable());
thread2.start();
// 启动方式3创建的线程
FutureTask<Integer> futureTask = new FutureTask<>(new MyCallable());
Thread thread3 = new Thread(futureTask);
thread3.start();
// 获取Callable的返回结果
try {
int result = futureTask.get();
System.out.println("Callable计算结果:" + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
以下是 Java 中创建线程的三种方式的代码示例:
代码说明:
-
继承Thread类:
- 自定义类
MyThread继承Thread,重写run()方法定义线程任务 - 通过
start()方法启动线程(而非直接调用run())
- 自定义类
-
实现Runnable接口:
- 自定义类
MyRunnable实现Runnable接口,实现run()方法 - 需要将其作为参数传入
Thread构造器,再通过Thread对象的start()启动
- 自定义类
-
实现Callable接口:
- 自定义类
MyCallable实现Callable<Integer>接口,实现call()方法 call()方法有返回值(此处为Integer类型),且可抛出异常- 通过
FutureTask包装Callable对象,再传入Thread启动 - 可通过
futureTask.get()获取call()的返回结果
- 自定义类
三种方式都通过start()方法启动线程,使线程进入就绪状态,等待CPU调度执行。运行后可以看到多个线程交替执行的效果。
在实现
Callable接口创建线程时,不是一定要通过FutureTask,还可以通过以下方式:使用
ExecutorService(推荐方式)
ExecutorService是 Java 提供的线程池框架,它可以管理和调度线程,并且方便获取Callable任务的返回值。示例代码如下:import java.util.concurrent.*; class MyCallable implements Callable<Integer> { @Override public Integer call() throws Exception { int sum = 0; for (int i = 0; i <= 5; i++) { sum += i; System.out.println("Callable-" + Thread.currentThread().getId() + ": 累加" + i + ",当前和为" + sum); Thread.sleep(100); } return sum; } } public class CallableWithoutFutureTask { public static void main(String[] args) { // 创建一个固定大小为1的线程池 ExecutorService executorService = Executors.newFixedThreadPool(1); // 提交Callable任务,返回Future对象 Future<Integer> future = executorService.submit(new MyCallable()); try { // 获取任务执行结果 int result = future.get(); System.out.println("Callable计算结果:" + result); } catch (InterruptedException | ExecutionException e) { e.printStackTrace(); } finally { // 关闭线程池 executorService.shutdown(); } } }在这个示例中:
- 使用
Executors.newFixedThreadPool(1)创建了一个固定大小为 1 的线程池executorService。- 通过
executorService.submit(new MyCallable())提交Callable任务,该方法会返回一个Future对象,用于获取任务的执行结果。- 使用
future.get()阻塞等待任务执行完成,并获取返回值。- 最后在
finally块中调用executorService.shutdown()关闭线程池,释放资源。自己实现类似
Future功能的机制(不推荐,较为复杂)可以基于
java.util.concurrent.locks.Condition等工具,自行实现一个机制来阻塞等待任务执行完成,并获取结果。不过这种方式比较复杂,涉及到多线程同步、状态管理等细节,通常情况下,使用FutureTask或者ExecutorService已经能很好地满足需求,所以一般不会采用这种方式 。相比之下,使用
FutureTask是一种比较灵活的方式,它既可以单独配合Thread使用,也可以作为任务提交到ExecutorService中。而使用ExecutorService则更适合管理多个线程任务,尤其是在需要线程池来提高性能和资源管理的场景下。
网络通信协议就是计算机之间通信的 “约定规矩”,规定了传输速度、代码格式、怎么控制传输和出错咋处理这些事。
因为网络里设备间联系复杂,所以把协议拆成简单的小部分,再分层组合起来。每层只和同层、相邻下层打交道,上层不用管更下层的事
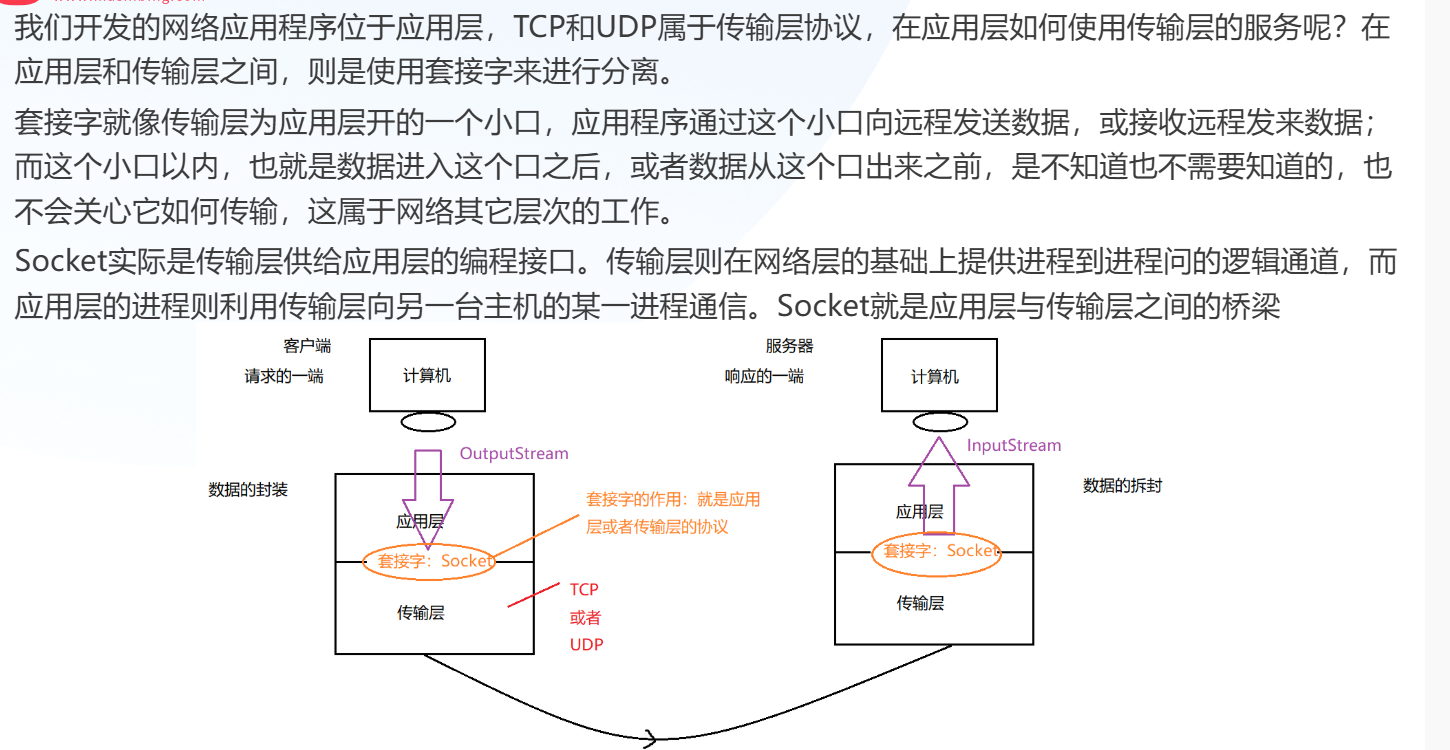
应用层(比如我们开发的网络应用程序)要用到传输层(像 TCP、UDP 这些协议)的服务,得通过 “套接字” 来衔接。套接字就像传输层给应用层开的一个 “小窗口”,应用程序通过这个窗口收发数据,不用管窗口里以及更下层(网络其他层次)数据怎么传输,只负责通过窗口和传输层交互就行。它是应用层和传输层之间的桥梁,让应用层能利用传输层和另一台主机的进程通信。

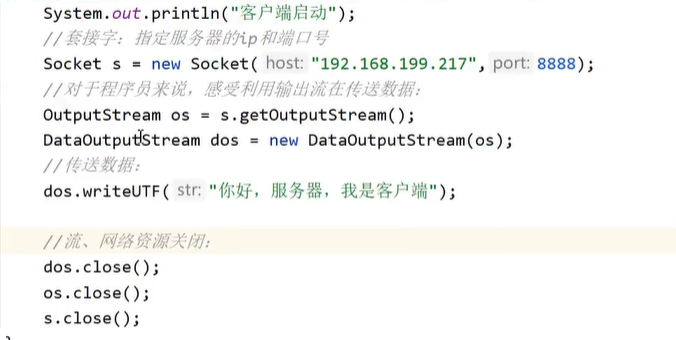
OutputStream os = s.getOutputStream();:从Socket对象中获取输出流OutputStream,用于向服务器发送数据。DataOutputStream dos = new DataOutputStream(os);:将获取到的OutputStream包装成DataOutputStream,DataOutputStream提供了更方便的方法来写入各种类型的数据(这里是字符串)。
双向通信
XML
XML(可扩展标记语言)。 XML是一种纯文本的标记语言,它本身“不作为”,不会主动去做事情。它的设计目的是用来结构化、存储以及传输信息,只是把信息包装在XML标签里。要传送、接收和显示XML文档,还需要编写软件或程序来实现这些操作。
Extensible Markup Language
XML(可扩展标记语言)文档的语法规则,主要内容如下:
- 必须有声明语句:XML声明是XML文档的第一句,格式为
<?xml version="1.0" encoding="utf-8"?>。 - 有且只有一个根元素:良好格式的XML文档得有一个根元素,它是声明后建立的第一个元素,其他元素都是它的子元素,且根元素要完全包含文档中其他所有元素。
- 注意大小写:XML文档里大小写有区别,“A”和“a”是不同标记。
- 标记必须成对:所有标记都得有相应的结束标记,有开始标记就必须有结束标记,否则会出错。
- 属性值用引号:所有属性值必须加引号,单引号或双引号都可以,建议用双引号,不然会出错。
- 可加入注释:注释格式为
<!-- 注释内容 -->。
<?xml version="1.0" encoding="utf-8"?>
<!--
注释部分:
version :版本号
encoding : 文档编码
students:根标签 根元素
student:字标签 子元素
name,age,sex,score:student子标签的子标签
id="1" 属性
-->
<students>
<student id="1" >
<name>丽丽</name>
<age>19</age>
<sex>女</sex>
<score>89.6</score>
</student>
<student id="2">
<name>露露</name>
<age>21</age>
<sex>女</sex>
<score>73.6</score>
</student>
<student id="3">
<name>明明</name>
<age>17</age>
<sex>男</sex>
<score>72.9</score>
</student>
</students>
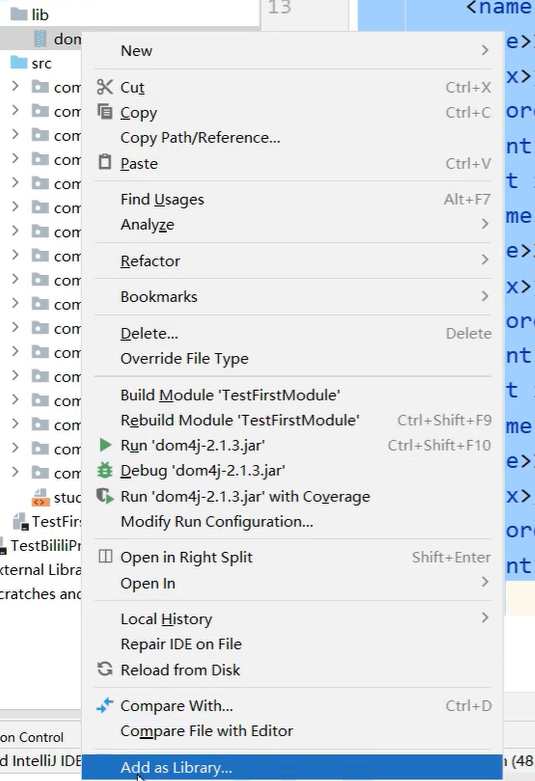
用于将 dom4j - 2.1.3.jar 这样的 Java 库文件添加为项目的库,以便在项目中使用该库提供的功能,比如利用 dom4j 库来进行 XML 文档的解析等操作。
xml解析
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
public class Test {
public static void main(String[] args) throws DocumentException {
//读取XML:
//1.创建一个xml解析器对象:(就是一个流)
SAXReader sr=new SAXReader();
//2.读取xml文件,返回Document对象出来:
Document dom = sr.read(new File("TestFirstModule/src/a.xml"));
System.out.println(dom);//这里就相当于将整个文档封装为Document对象了啊!
//3.获取根节点:(根节点只有一个啊!)
Element studentsEle = dom.getRootElement();
//4.获取根节点下的多个子节点:
Iterator<Element> it1 = studentsEle.elementIterator();
while(it1.hasNext()){
//4.1获取到子节点:
Element studentEle = it1.next();
//4.2获取子节点的属性:
List<Attribute> atts = studentEle.attributes();
for(Attribute a:atts){
System.out.println("该子节点的属性:"+a.getName()+"---"+a.getText());
}
//4.3获取到子节点的子节点啊:
Iterator<Element> it2 = studentEle.elementIterator();
while(it2.hasNext()){
Element eles=it2.next();
System.out.println("节点:"+eles.getName()+"---"+eles.getText());
}
//5.每组输出后加一个换行:
System.out.println();
}
}
}
注解
- 什么是注解:代码里的特殊标记,能在编译、类加载、运行时被读取处理,可在不改变原有逻辑时嵌入补充信息,供工具验证或部署。
- 注解的使用:加
@符号,当作修饰符,修饰包、类、方法等程序元素。 - 注解的重要性:JavaSE中用途简单,如标记过时功能;JavaEE/Android里作用关键,可配置应用切面,替代繁冗代码和XML配置,未来开发多基于注解,框架也和注解、反射、设计模式相关。

MySQL
MySQL 数据库最初由瑞典 MySQL AB 公司开发,2008 年 1 月 16 日被 Sun 公司收购,2009 年 Sun 公司又被 Oracle 收购。它具有体积小、速度快、成本低、跨平台、开放源码等优点,广泛应用于互联网的中小型网站,像网易、新浪等大型网站也开始使用。
port默认3306
在 MySQL 中,root 用户通常被视为超级管理员。 它拥有对 MySQL 数据库服务器的最高权限,可以执行所有操作,比如创建、删除数据库,管理其他用户(创建、授权、删除用户等),对任何数据库和表进行增删改查等操作。就好比系统的“总管理员”,能全方位掌控 MySQL 数据库相关的所有事务。不过,正因为权限极大,在实际生产环境中,一般不会直接用 root 账号进行日常操作,而是创建权限合适的普通用户,以保障数据库的安全。
mysql -hlocalhost -uroot -p
密码:root
连接测试navicat报错2059后执行如下命令:
alter user 'root'@'localhost' identified by 'root' password expire never;
alter user 'root'@'localhost' identified with mysql_native_password by 'root';

utf8、utf8mb3、utf8mb4 和 utf16 都是常见的字符编码方式,它们在字符存储和处理上有一些区别:
UTF8
- 存储方式:严格意义上的 UTF8 是一种可变长的字符编码,它使用 1 - 4 个字节来表示一个字符。可以表示世界上几乎所有的字符。比如,英文字母等 ASCII 字符用 1 个字节存储,常见汉字一般用 3 个字节存储,一些罕见的 Unicode 字符用 4 个字节存储 。
- 应用场景:广泛应用于网页、文本文件以及很多数据库系统中,是互联网上最常用的字符编码方式之一。
UTF8MB3
- 存储方式:在 MySQL 数据库中,早期版本的
utf8实际上是utf8mb3,它是 UTF8 的一个子集, 最多只能用 3 个字节来表示一个字符。 - 应用场景:在不涉及 4 字节 Unicode 字符(如 emoji 表情)的场景下可以使用。但随着 emoji 等特殊字符的广泛使用,这种编码方式逐渐无法满足需求。
UTF8MB4
- 存储方式:是 UTF8 的超集,和真正的 UTF8 一样, 可以用 1 - 4 个字节来表示一个字符, 能完整支持所有的 Unicode 字符,包括 4 字节的 emoji 表情、罕见的象形文字等。
- 应用场景:当数据库需要存储多种语言文字,特别是要包含 emoji 等特殊字符时,
utf8mb4是很好的选择。
UTF16
- 存储方式:使用 2 个或 4 个字节来表示一个字符。基本多文种平面(BMP)内的字符用 2 个字节表示,补充平面的字符用 4 个字节表示。
- 应用场景:在 Windows 操作系统的很多 API 中广泛使用,在一些跨平台的软件开发中,当需要处理多种语言且对字符存储和处理有特定要求时也会用到。不过,相比 UTF8,它占用的存储空间通常更大 。
总体而言,选择哪种字符编码取决于具体的应用场景和需求,如果更注重兼容性和通用性,同时要处理 emoji 等特殊字符,utf8mb4 是比较好的选择;如果是特定的 Windows 平台开发,utf16 可能会更合适 。
写SQL
-
varchar(20)就是说这个字段最多存 20 个字符,多了存不进去,能约束数据长度,也省空间。 -
如果不指定
VARCHAR的长度(像写成VARCHAR而不是VARCHAR(n),不过不同数据库对这种写法的支持不同,有些数据库要求必须指定长度),在很多关系型数据库(比如 MySQL)中,这种写法是不合法的,会报错,无法成功创建表。
varchar(20) 存 5 个字符时,实际占用空间分两部分:
- 5 个字符本身的字节数(比如存 5 个英文,占 5 字节;存 5 个中文,在
utf8mb4下占 15 字节); - 1 - 2 字节的“长度标记”(用来记录这 5 个字符实际占多少字节)。
总体就是“字符字节数 + 1 - 2 字节”,比 char(20) 固定占 20 字符的空间(utf8mb4 下是 80 字节)要省很多。
JDBC
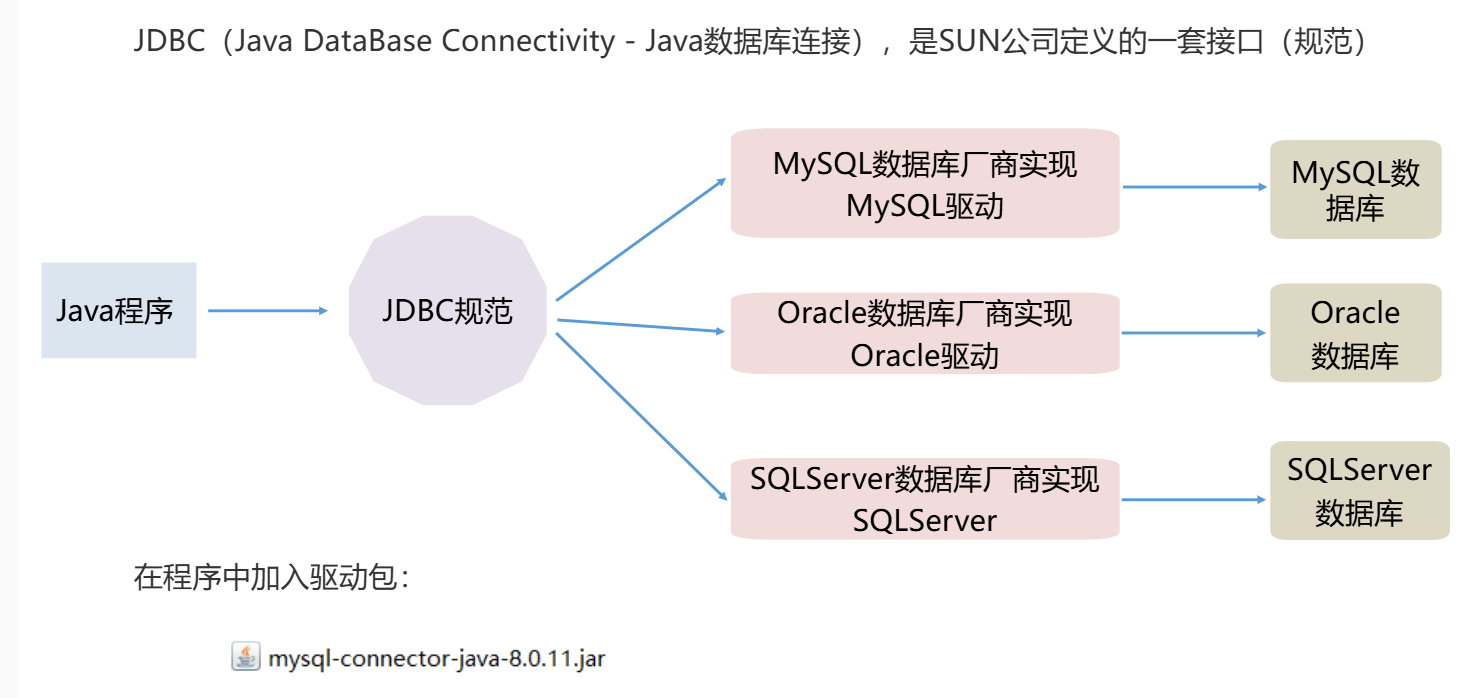
图中实体是JDBC(Java DataBase Connectivity - Java数据库连接)。
JDBC是SUN公司定义的一套用于Java程序连接数据库的接口规范。Java程序通过遵循JDBC规范,再结合不同数据库厂商(如MySQL、Oracle、SQLServer等)提供的相应驱动包(比如图中提到的mysql-connector-java-8.0.11.jar),就能实现与不同数据库(MySQL数据库、Oracle数据库、SQLServer数据库等)的连接和交互,这样Java程序就可以对数据库进行增删改查等操作了。
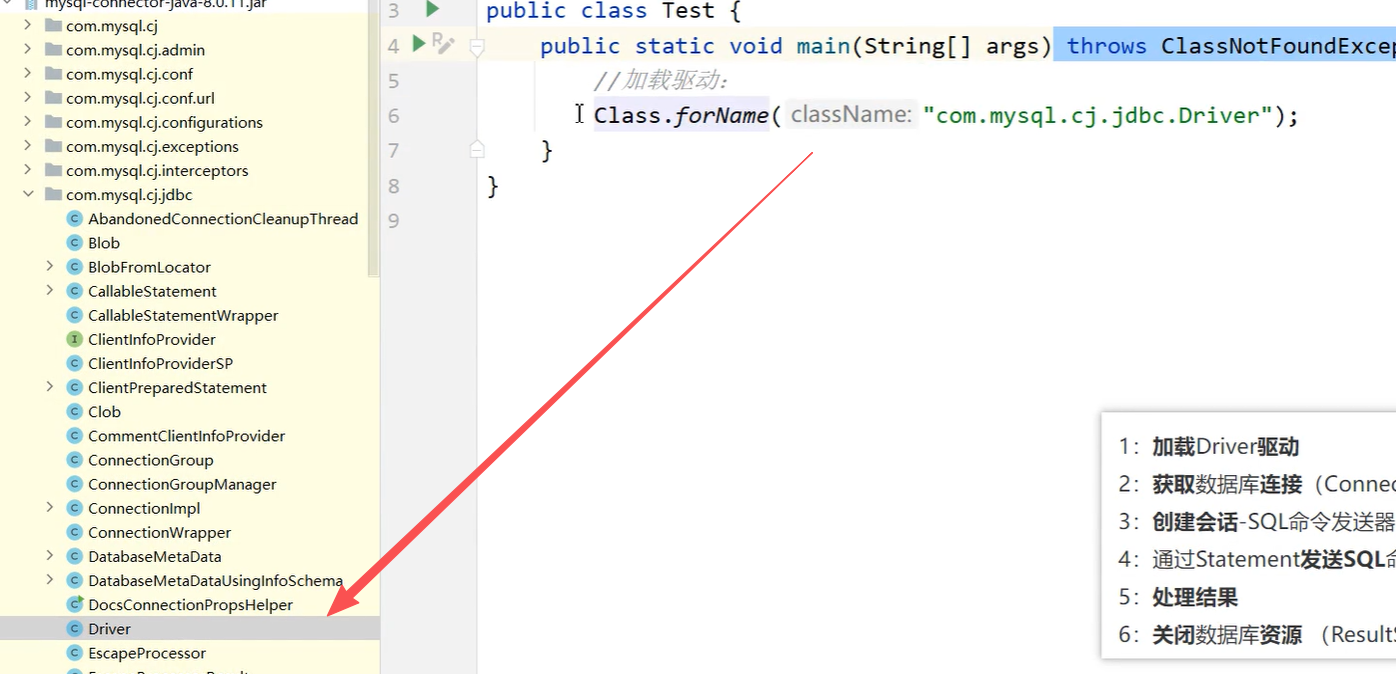
JDBC访问数据库编码步骤
1:加载Driver驱动
2:获取数据库连接(Connection)
3:创建会话 - SQL命令发送器(Statement)
4:通过Statement发送SQL命令并得到结果
5:处理结果
6:关闭数据库资源(ResultSet、Statement、Connection)
这段内容是关于JDBC连接MySQL数据库的URL配置及各参数含义的说明。
String url="jdbc:mysql://127.0.0.1:3306/数据库名称?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true";
是JDBC连接MySQL数据库的统一资源定位符(URL)。其中:
useSSL=false表示不使用SSL认证机制;useUnicode=true表示使用Unicode字符集;characterEncoding=UTF-8表示使用UTF - 8的字符编码策略;serverTimezone=Asia/Shanghai表示设置时区为东八区(上海时区);allowPublicKeyRetrieval=true表示允许客户端从服务器获取公钥。
1. SSL 认证
简单说就是 “网络连接的安全锁”。
比如你用手机连WiFi、在网上填信息(像登录账号、付款)时,数据会在手机/电脑和服务器之间传输。如果没开SSL认证,这些数据可能被别人“偷看”甚至篡改(比如盗走密码);开了SSL认证,数据会被加密,就像装在带锁的箱子里传输,只有目标服务器能打开,更安全。
你之前看的JDBC配置里写useSSL=false,就是暂时关掉这个安全锁(一般开发测试时用,正式用数据库建议开,设为true)。
2. 东八区
就是 “咱们中国用的时间 zone”。
地球分24个时区(像把地球按经度切成24块,每块对应一个小时),“东八区”是其中一块,范围包括中国大部分地区(还有新加坡、马来西亚等)。
它比国际标准时间(英国格林尼治时间)快8小时——比如国际标准时间是凌晨0点,咱们东八区就是早上8点。
数据库配置里写serverTimezone=Asia/Shanghai,就是让数据库用咱们这边的时间,避免存数据时出现“时间对不上”的问题(比如你明明今天下午存的数据,数据库显示昨天,就是时区没设对)。
allowPublicKeyRetrieval
这就好比客户端(比如你的Java程序)要和数据库服务器“安全对话”,得先拿到服务器的“公钥”(一种用于加密的密钥)。allowPublicKeyRetrieval=true 就是允许客户端主动从数据库服务器那里获取这个公钥,有了公钥,后续客户端和服务器之间传输数据时,就能用公钥来加密,让数据传输更安全,防止被第三方轻易窃取或篡改。
当你设置useSSL=true(开启SSL安全连接)时,程序和数据库之间要建立加密通道:
- 数据库服务器会有一个"公钥",相当于加密用的"锁"
- 你的程序需要先拿到这个"公钥",才能给要发送的数据"上锁"
allowPublicKeyRetrieval=true就是明确告诉程序:“可以主动去要这个公钥”
如果没开这个配置,程序可能拿不到公钥拿不到,SSL连接就会失败。
而如果useSSL=false(不加密),本来就不需要公钥,这个配置就相当于"多余的开关",开着也没用。
驱动(Driver)就像“翻译官”,里面主要包含:
- 能让Java程序看懂数据库“语言”的代码(比如MySQL、Oracle各有自己的通信格式);
- 实现了JDBC接口的具体代码(Java定义了接口规范,驱动负责实际执行)。
必须加载驱动,是因为Java程序本身只认识JDBC的通用接口,不知道具体数据库(比如MySQL)怎么连接、怎么传数据。加载驱动后,这个“翻译官”才会生效,让程序能和数据库“对话”,完成后续的连接、发命令等操作。
executeUpdate 方法会返回一个 int 类型的值,这个值表示受影响的行数。
具体看代码
HTML的作用:学习HTML就是学习各种各样的标签,然后组成一个页面,这个页面可以被浏览器解析,解析完以后可以在浏览器中将页面进行展示。
- HTML:是网页的 “骨架”,负责搭建网页的基本结构,比如确定哪里放标题、哪里放图片、哪里是段落文字这些内容的布局框架。
- CSS:是网页的 “颜值担当”,用来给网页 “化妆打扮”,像设置文字的颜色、大小、字体,给网页加背景、调整元素的位置和间距,让网页看起来更美观。
- JS:是网页的 “灵魂”,能让网页 “动起来”“活起来”,比如实现点击按钮弹出提示、图片自动轮播、表单输入验证等交互功能,让网页不再是静态的,能和用户互动。
外部样式

- 引入外部css:link单标签
- 引入外部js:script
在HTML中引入外部文件的方式是这样的:
- 引入外部CSS文件用
<link>单标签,一般放在<head>里,格式像这样:
<link rel="stylesheet" href="样式文件路径.css">
- 引入外部JS文件用
<script>标签,通常放在<body>底部(让HTML先加载),格式是:
<script src="脚本文件路径.js"></script>
这样做的好处是把结构(HTML)、样式(CSS)、行为(JS)分开,方便后期维护和修改。
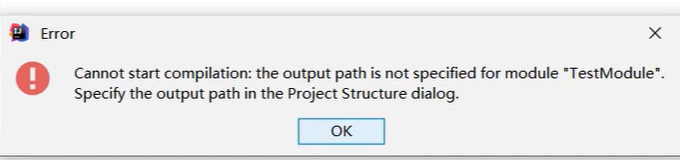
这是一个编译错误提示,意思是:无法开始编译,因为模块“TestModule”没有指定输出路径。需要在“项目结构”对话框中指定输出路径。 简单来说,就是你要编译的这个叫“TestModule”的模块,没告诉编译器编译后的文件要放到哪里,所以得去“项目结构”那里设置一下输出路径才行。
Maven
非 Maven 项目的缺点:
- 项目里要用的 jar 包资源,得自己从网上下载,再手动导入到项目中,管理起来不方便。
- 对 jar 包的版本进行控制很麻烦。
- 依赖传递问题难处理如果项目中用到的 A jar 包,本身还依赖 B、C 两个 jar 包(即 “依赖的依赖”),非 Maven 项目需要开发者自己手动识别并下载 B、C 包,很容易漏掉关键依赖,导致项目报错(比如 “类找不到”),而 Maven 会自动帮你管理这种依赖传递。
- 项目移植 / 协作成本高如果要把项目传给同事,或者部署到另一台电脑,非 Maven 项目需要把所有用到的 jar 包一起拷贝(通常放在 “lib” 文件夹里),文件体积大且容易遗漏;而 Maven 项目只需要一个 “pom.xml” 配置文件,同事拿到后,Maven 会自动下载所有依赖的 jar 包,不用手动拷贝。
- 缺乏统一的项目结构规范Maven 有固定的项目目录结构(比如 Java 代码放在 “src/main/java”,配置文件放在 “src/main/resources”),团队协作时大家遵循同一套结构,沟通成本低;非 Maven 项目则没有统一标准,不同开发者可能会自定义目录(比如有的叫 “code”,有的叫 “javaSource”),后续维护时找文件很麻烦。
- 打包、构建流程繁琐如果要把项目打包成可运行的 jar 包或 war 包(用于部署到服务器),非 Maven 项目需要手动配置打包工具(比如 Eclipse 的导出功能),还得手动处理依赖 jar 包的打包方式(比如要不要把依赖包一起打进最终的包);而 Maven 只需要执行一句命令(如 “mvn package”),就能自动按配置完成打包,流程更标准化。
Maven仓库就像“资源超市”,分这几类
- 中央仓库:是Maven官方的“大超市”,里面有超多流行的jar包(开发用的资源包)。但它在国外,咱们访问经常慢甚至连不上,就像国外的超市,咱网购从那发货很慢。
- 本地仓库:是你自己电脑里的“小仓库”,用来缓存从远程(中央或镜像仓库)下载的jar包。相当于你把国外超市的东西,先囤点到自家小仓库,下次用就不用再去远的地方取了,还能存自己没发布的临时开发资源。
- 镜像仓库:因为中央仓库访问慢,国内就有了“代购超市”(像阿里云、华为云的镜像)。它把中央仓库的东西复制了一份,咱们从国内这“代购超市”拿东西,速度就快多了,不过本质还是远程的仓库。
然后找依赖(找jar包)的流程也简单:Maven项目先去自己电脑的本地仓库找,找不到的话,就看配置里有没有指定镜像仓库,指定了就去镜像仓库找,没指定就去中央仓库找,找到后会放到本地仓库,下次用就方便啦。
Maven,它是用 Java 语言编写的、基于项目对象模型(POM)的项目管理工具软件。开发者可以通过简短的描述信息来管理项目的构建、报告和文档,能更好地帮助完成项目管理。
同时通过对比普通项目和 Maven 项目,展现出 Maven 的优势:普通项目里,不同子项目(如项目 A、项目 B)可能会重复依赖相同的资源(像 Spring core 等),造成资源冗余;而 Maven 项目通过 “仓库” 来管理公共资源(如 Spring core),不同子项目可以共享仓库里的资源,避免了重复,让项目管理更高效。
资源坐标和依赖不是一回事,但关系很紧密:
- 资源坐标:是Maven里给每个jar包(资源)编的“唯一身份证”,由
GroupId(组织标识)、ArtifactId(项目/包名)、Version(版本号)组成,能精准找到某个具体的jar包。 - 依赖:是你的项目“需要用别人的jar包”这个需求。而声明依赖时,得用资源坐标来指定“要用哪个组织、哪个项目、哪个版本的jar包”。
简单说,资源坐标是“目标jar包的身份信息”,依赖是“项目要用这个jar包”的需求,声明依赖得靠资源坐标来定位具体jar包。
Maven的资源坐标就像资源的“地址”,能精准找到对应的jar包:
- GroupId:类似公司“门牌号”,同一公司的项目用相同的,比如
com.xx。 - ArtifactId:是项目(jar包)的“名字”,比如
mysql-connector-java。 - Version:是版本号,比如
8.0.28,区分同一项目的不同版本。
Maven配置
- 本地仓库
- 镜像仓库
- 配置JDK:在使用Maven后,项目由Maven来完成编译和打包运行,需要指定使用的JDK版本。
以下是在 Maven 项目中指定使用 JDK 17 版本的完整 pom.xml 核心配置代码(通常将 <profiles> 等配置放在 pom.xml 中):
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 其他项目基本信息,如 groupId、artifactId、version 等 -->
<profiles>
<profile>
<id>jdk-17</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>17</jdk>
</activation>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<maven.compiler.compilerVersion>17</maven.compiler.compilerVersion>
</properties>
</profile>
</profiles>
</project>
把这段配置放到 Maven 项目的 pom.xml 文件里,Maven 就会用 JDK 17 来编译、打包项目啦~
Maven降版本操作
在开发中,有时需要降低 Maven 和 JDK 的版本,主要有这些原因:
1. 项目兼容性要求
- Maven 版本:有些旧项目是基于低版本 Maven 开发的,高版本 Maven 可能在构建流程、插件兼容等方面和旧项目不匹配。比如项目里用的某些 Maven 插件,在高版本 Maven 下可能出现兼容性问题,导致构建失败,换成低版本(如 3.6.3)能保证项目正常构建。
- JDK 版本:很多旧的框架、库或者项目本身的代码,是基于 JDK 8 开发的。如果用更高版本 JDK(比如 JDK 17),可能会因为 JDK 版本升级带来的 API 变化、语法特性差异等,导致项目运行报错,所以得换回 JDK 8 来保证项目能正常运行。
2. 开发环境一致性
团队里其他成员用的是低版本的 Maven 和 JDK,为了让大家的开发环境一致,避免因为环境差异导致的各种问题(比如你用高版本能跑,别人用低版本跑不了),就会统一降低版本,保持团队开发环境的一致性。
3. 部署环境限制
项目最终要部署的服务器上,安装的是低版本的 JDK(比如 JDK 8),如果本地用高版本 JDK 开发,可能会出现本地能运行,部署到服务器就出错的情况,所以本地也得用和服务器一致的低版本 JDK,减少部署时的问题。
Maven和JDK版本相关,是因为:
-
Maven本身靠Java跑
Maven是用Java写的,得靠JDK才能运行。高版本Maven可能用到了新版JDK的特性,比如Maven 3.8+就需要JDK 8及以上,老JDK跑不动新Maven。 -
项目代码和JDK绑定
你的项目代码是用某个JDK版本写的(比如JDK 8的语法),Maven编译时得用对应的JDK版本。
如果Maven配了高版本JDK(比如17)去编译老代码,可能不认识老语法;用低版本JDK编译新代码,又不支持新特性(比如JDK 17的密封类),就会报错。
其实是反过来:高版本JDK通常能兼容老语法,但老代码可能用了高版本JDK里被移除或修改的功能,导致报错。
举个例子:
JDK 17移除了一些JDK 8里的旧功能(比如某些不常用的API)。如果老代码刚好用到了这些被移除的功能,用JDK 17编译时,就会提示“找不到这个功能”,看似“不认识”,其实是这个功能在高版本里没了。再比如:
JDK 9之后对模块管理更严格,老代码里有些“不规范”的写法(比如直接访问JDK内部类),在JDK 8里能跑,但在高版本JDK里会被视为错误,编译不过。所以不是高版本JDK不认识老语法,而是老代码可能依赖了高版本JDK里已改变或移除的功能,导致不兼容。
简单说:Maven自己要靠JDK跑,同时它还得用合适的JDK版本帮你编译代码,版本对不上就容易出问题。
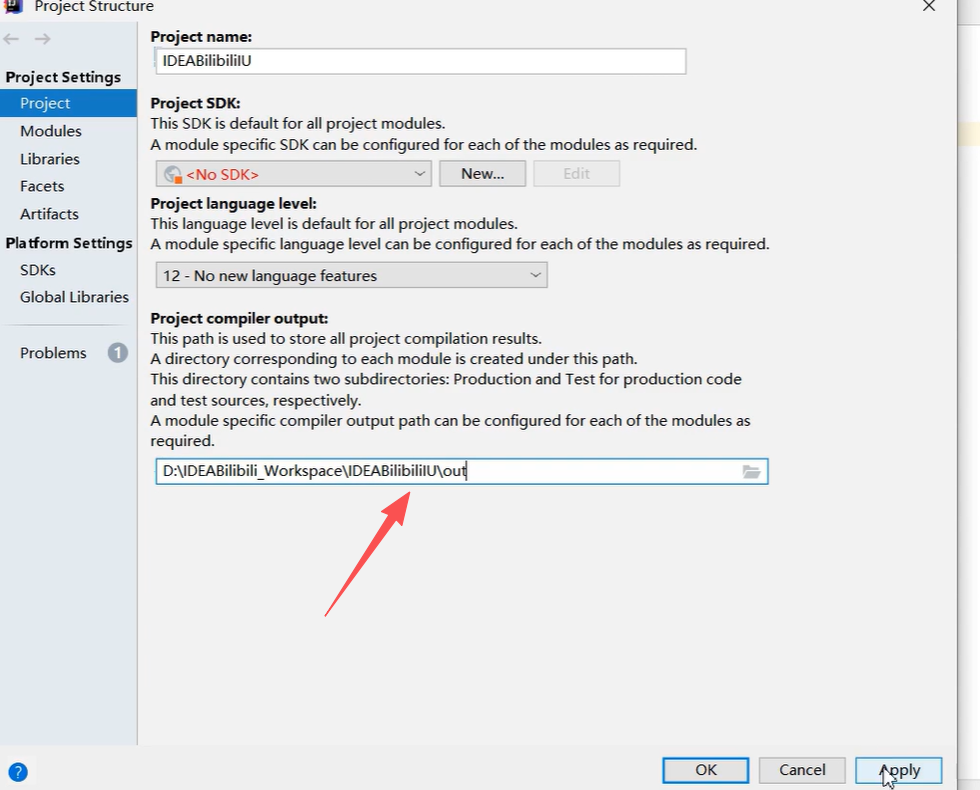
- Maven:低版本3.6.3
- JDK:换为低版本8
创建Maven项目
Maven项目模版

这些Maven模板就像“项目模板”,作用很简单:
- 选个模板,能直接生成项目的基本架子(目录、配置文件这些),不用自己手动建。
- 不同模板对应不同类型项目(比如Web项目、普通Java项目),还会自动加好相关依赖,省得自己一个个找着加。
Maven的这些模板(也叫archetype),就像是预先做好的“项目骨架”。
比如说,你要建个普通Java项目,选maven-archetype-quickstart模板,它会自动给你生成src/main/java(放主代码)、src/test/java(放测试代码)这些标准目录,还有基础的pom.xml配置文件,不用你手动去建文件夹、写配置了。
要是做Web项目,选maven-archetype-webapp模板,不仅能生成Web项目该有的目录结构,还会在pom.xml里自动加上Servlet等Web开发需要的依赖,你不用自己再去网上找这些依赖、手动配置了,能省不少事儿,快速把项目的基本架子搭起来,然后专注写业务代码。
不同的模板对应不同类型的项目,像和Apache Camel相关的模板,还会预先配置好Camel的依赖和基础代码结构,方便做消息处理这类应用开发,能让你更快上手,也能遵循对应的项目开发规范。
Maven 中央仓库(Central Repository)
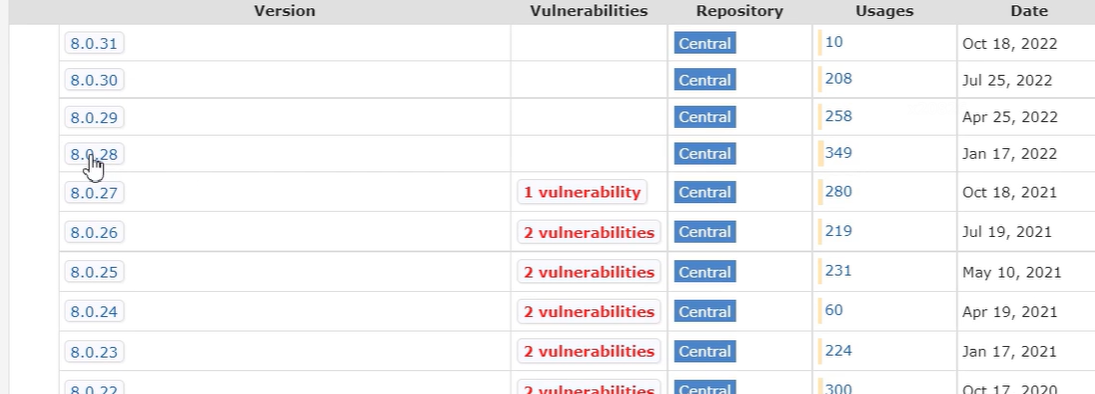
- Version:依赖的版本号,比如图中的
8.0.31、8.0.30等,不同版本可能包含不同的功能更新、 bug 修复等。 - Vulnerabilities:漏洞情况,像
8.0.27版本标注了“1 vulnerability”,说明该版本存在 1 个已知漏洞,在选择依赖版本时,通常会优先避免有已知漏洞的版本,保障项目安全。 - Repository:存储该依赖的仓库,这里都是
Central,即 Maven 中央仓库,是 Maven 默认的核心仓库,里面存放了大量常用的依赖供开发者使用。 - Usages:使用次数,能反映出该版本的流行程度,一般来说,使用次数多的版本经过了更广泛的测试,相对更稳定可靠,比如
8.0.28版本有 349 次使用,说明较多项目采用了这个版本。 - Date:版本发布日期,可用于判断版本的新旧,通常较新的版本会包含更多的改进,但也要结合项目对依赖稳定性、兼容性的需求来选择。
简单来讲,这张表帮助开发者从版本、漏洞、流行度、发布时间等维度,挑选适合项目的 Maven 依赖版本。
私有项目不会被统计,主要是两点:
- 私有项目是企业/团队内部的,藏得严(有访问限制),Maven仓库的统计系统根本看不着、拿不到数据。
- 很多私有项目用的是公司自己的内部仓库(不是公共的Maven中央仓库),数据不跟公共仓库互通,自然统计不到。
在 Maven 中,<dependency> 里的 groupId、artifactId、version 这三个元素组合起来,被称为依赖的 “坐标”。
框架
- 重复/基础代码封装,同时添加额外功能。
- 释放程序员写代码精力,更关注业务层面
- 半成品
“开发周期更短” 可以简单理解为开发时间变短。
常见Java框架分类:
- 持久层框架。MyBatis、Hibernate、Spring Data、iBatis
- MVC框架:Spring MVC、Struts1、Struts2
- 项目管理框架:Spring Framework、Spring Boot
- 微服务框架。Spring Cloud
- 权限管理框架:Spring Security、Shiro。
在软件开发(尤其是 Java 后端开发)中,“层”是基于分层架构的概念,把系统按功能或职责拆分成不同层级,让各层专注做自己的事,降低耦合、方便维护。结合常见 Java 框架的分层,给你解释下核心的“层”:
1. 持久层(对应“持久层框架”)
- 作用:负责和数据库打交道,完成数据的“持久化”(把内存里的临时数据存到数据库等持久存储介质,或从数据库读取数据)。
- 例子:像 MyBatis、Hibernate 这些框架,就是帮你写 SQL、执行数据库操作、把数据库里的数据转成 Java 对象(或反过来),不用你手动写 JDBC 连接、Statement 操作这些繁琐代码。
持久层先去数据库把需要的数据(比如商品库存、用户信息)取出来,然后把数据交给 Model;Model 拿到数据后,就用这些数据做业务逻辑处理(比如判断库存够不够、算订单总价)。
比如下单时:
- 持久层 → 去数据库查衣服库存(得到 “50 件”),把 “50 件” 这个数据交给 Model;
- Model → 拿到 “50 件”,再结合你下单的 “1 件”,做业务判断(50≥1,库存够),同时算总价(1×100=100 元)。
全程 Model 不用碰数据库,只拿持久层给的数据干活~
2. MVC 层(对应“MVC 框架”)
MVC 是 Model(模型)、View(视图)、Controller(控制器) 的缩写,是一种 Web 应用的分层设计模式:
-
Model:处理数据和业务逻辑(比如从数据库取数据、做计算)。
- Model 更像一个 “概念”,指的是处理数据和业务逻辑的部分(MVC 模式里的一层)。
- Service 层是具体实现 Model 功能的 “代码结构”—— 在实际项目中,我们会专门写一个 Service 层来放业务逻辑代码(比如订单计算、库存判断),这部分代码就属于 Model 的范畴。
-
View:负责页面展示(比如 JSP、Thymeleaf 模板,决定用户看到什么)。
-
Controller:接收用户请求,调用 Model 处理,再把结果给 View 展示。
-
例子:Spring MVC、Struts 这些框架,就是帮你规范和简化 MVC 各层的协作,比如 Controller 怎么接收请求、Model 怎么传数据给 View 等。
3. 项目管理/整体框架层(对应“项目管理框架”)
- 作用:给整个项目提供基础支撑,整合各组件、管理Bean(Java对象)、实现依赖注入等核心功能,让项目能“跑起来”并高效协作。
- 例子:Spring Framework 是核心基础,提供了 IOC(控制反转)、AOP(面向切面编程)等核心能力;Spring Boot 则是在 Spring 基础上,让项目“开箱即用”,简化配置,快速搭建完整项目。
4. 微服务层(对应“微服务框架”)
- 背景:大型项目拆成多个“微服务”(每个服务小而独立,负责一块业务),需要框架来管理服务间的调用、注册、配置等。
- 作用:Spring Cloud 这类框架,提供了服务注册与发现、负载均衡、熔断器(防止服务雪崩)、配置中心等能力,让微服务之间能高效、稳定地协作。
5. 权限管理层(对应“权限管理框架”)
- 作用:控制“谁能访问什么资源”,比如用户登录、判断用户有没有权限访问某个接口或页面。
- 例子:Spring Security、Shiro 这些框架,帮你做用户认证(登录)、授权(判断权限)、防止 CSRF(跨站请求伪造)等安全相关的工作,不用自己从头写权限逻辑。
简单总结:分层是为了分工明确、降低复杂度,不同层专注不同职责,框架则是帮你把各层的通用工作简化,让你更聚焦业务~
SSM
SSM 是按 MVC 架构思路搭建的项目,但不能说 SSM 本身“就是”MVC 架构——SSM 是“框架组合”,MVC 是“设计思路”,前者是实现后者的工具组合。
具体拆解开就清楚了:
- SSM 指的是 Spring + Spring MVC + MyBatis 三个框架的组合;
- 其中,Spring MVC 是核心,它直接实现了 MVC 架构的分层:
- Controller 层:由 Spring MVC 负责(接收用户请求、分发任务);
- Model 层:由你写的业务逻辑代码(Service)+ Spring 管理的对象构成(处理业务、封装数据);
- View 层:由 JSP、Thymeleaf 等负责(展示页面);
- 而 MyBatis 是持久层框架,它不属于 MVC 架构的一部分,只负责帮 Model 层“拿数据”(和数据库交互),是配合 MVC 工作的“辅助工具”;
- Spring 则是胶水,负责整合 Spring MVC 和 MyBatis,管理所有组件(比如让 Controller 能调用 Service、Service 能调用 MyBatis)。
简单说:你用 SSM 组合框架,本质是“靠 Spring MVC 实现了 MVC 架构”,同时用 MyBatis 做持久层、Spring 做整合——SSM 是“按 MVC 架构干活的一套工具”,不是 MVC 架构本身。
ORM 框架(Object-Relational Mapping,对象关系映射框架)
你可能是想了解 ORM 框架(Object-Relational Mapping,对象关系映射框架)——因为“ROM”在开发中不常见,而 ORM 是和数据库交互、配合 MVC/SSM 常用的核心框架,刚好和你之前聊的“持久层”“Model 用数据”强相关。
简单说,ORM 框架的核心作用是**“把数据库表和 Java 对象对应起来”**,让你不用写复杂 SQL,直接用操作 Java 对象的方式来操作数据库。
1. 为啥需要 ORM 框架?(解决的痛点)
没有 ORM 时,你操作数据库要写很多“重复且繁琐”的代码:
比如数据库里有张 user 表(字段:id、name、age),Java 里有个 User 类(属性:id、name、age)。
- 查数据:要写
SELECT id,name,age FROM user WHERE id=1,再手动把查询结果的每一列值,挨个赋值给User对象的属性; - 存数据:要写
INSERT INTO user(name,age) VALUES(?,?),再手动把User对象的属性值,对应传到 SQL 的占位符里。
而 ORM 框架能帮你“省掉这些手动对应步骤”——你只要操作 User 对象,框架会自动帮你转成 SQL 去操作数据库。
2. 举个例子(用常见的 ORM 框架 MyBatis)
还是用 user 表和 User 类:
- 你先写个“映射文件”,告诉框架:
User类的id属性对应user表的id字段,name对应name字段…(这一步叫“映射配置”); - 查数据时:你调用
getUserById(1)方法(自己定义),MyBatis 会自动生成SELECT ... WHERE id=1的 SQL,执行后直接返回一个User对象(不用手动赋值); - 存数据时:你创建一个
User对象(user.setName("张三"); user.setAge(20)),调用saveUser(user)方法,MyBatis 会自动生成INSERT语句,把对象的属性值存到数据库里。
3. ORM 框架和你之前聊的“持久层”“SSM”啥关系?
- 它是 持久层的核心工具:之前说“持久层管和数据库打交道”,ORM 框架就是帮持久层干这个活的“利器”;
- 在 SSM 里的角色:SSM 中的 MyBatis 就是一款主流 ORM 框架——Model 层(Service)要数据时,会调用持久层(DAO 层),而 DAO 层就是通过 MyBatis(ORM 框架)去数据库拿数据,再把数据封装成 Java 对象给 Model。
简单总结:ORM 框架是“Java 对象和数据库表的翻译官”,帮你少写 SQL、少做重复工作,专注于业务逻辑(Model 层的活),是后端开发里和数据库交互的“刚需工具”。
MyBatis xml名字问题

在 MyBatis 中,XML 映射文件里的 id 不一定必须和 Mapper 接口的方法名完全一样,但实际开发中几乎都会保持一致,原因很简单:
- 如果
id和方法名一致,MyBatis 能“自动关联”它们(通过接口全类名 + 方法名找到对应的 SQL),不用额外配置,直观又方便。 - 如果
id和方法名不一样,需要手动通过注解(比如@Select("xxx")里指定statementId)来关联,反而多此一举,还容易出错。
所以,约定俗成都是让 id 和方法名保持一致,这是最简单、最不容易出问题的做法~
返回类型是List,但写Book就可以
在 MyBatis 里,这是因为 MyBatis 会自动帮你做“列表封装”。
你指定 resultType="com.pojo.Book",意思是“每一条查询结果,都封装成 Book 对象”;而如果你的 Mapper 接口方法定义的返回值是 List<Book>,MyBatis 会自动把所有 Book 对象收集起来,放到一个 List 里返回给你。
举个例子:
- 执行
select * from t_book,查出来 3 条图书数据; - MyBatis 会把每条数据都转成一个
Book对象; - 然后把这 3 个
Book对象,打包成一个List<Book>返回。
所以你不用在 resultType 里写 List,只需要指定“单个元素的类型(Book)”,MyBatis 就知道要把多个结果封装成列表~
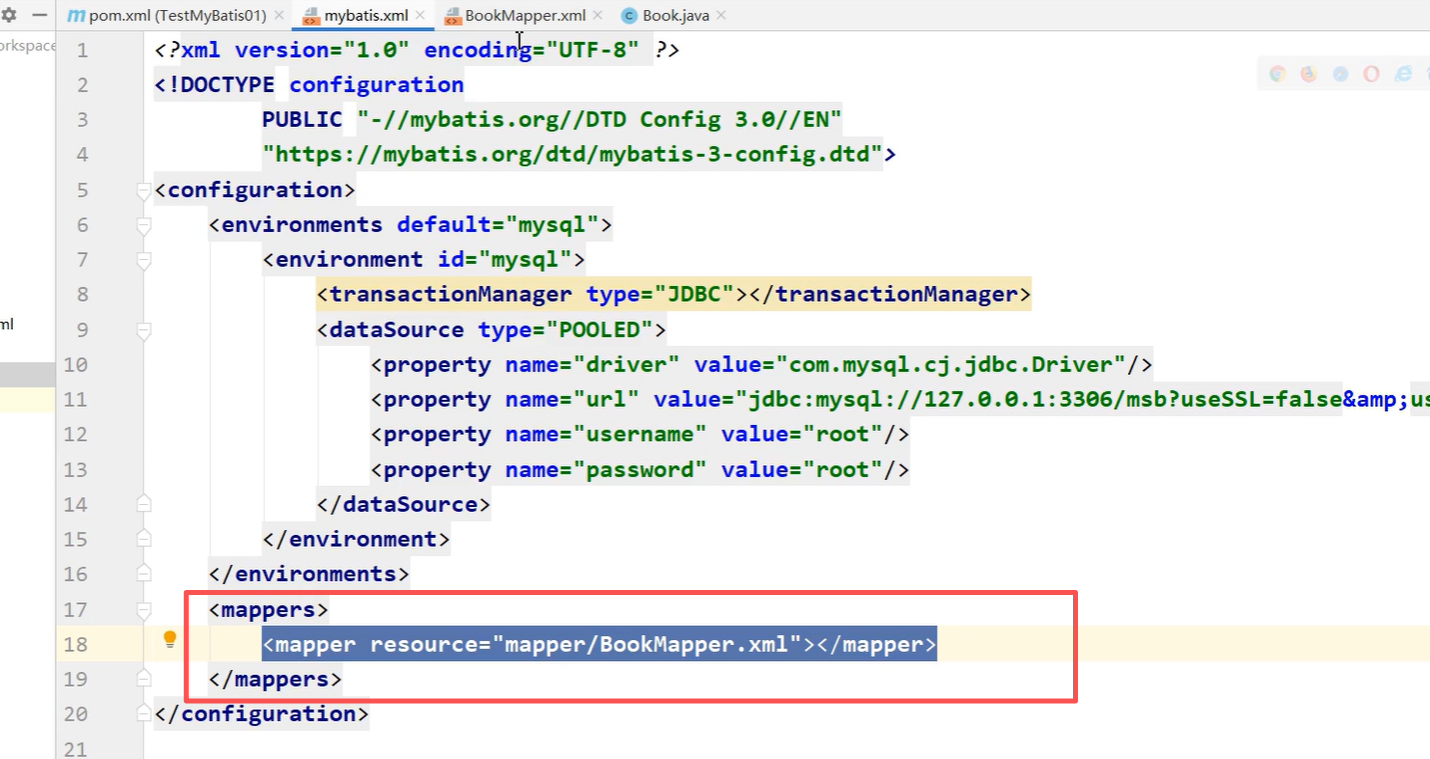
核心配置文件加入mapper
- 类型别名
- 抽象配置文件
- MyBatis配置日志功能
MyBatis 框架如何配置日志功能,方便我们开发时查看 SQL 执行、框架内部流程等信息,排查问题也更方便。
- MyBatis 内置日志工厂:MyBatis 自身有一套“日志管理机制”,能自动识别并使用项目里配置的日志工具。
- 支持的日志类型:列出了 MyBatis 能对接的几种主流日志工具,比如 SLF4J、Log4j 等。其中
Log4j (deprecated since 3.5.9)意思是 Log4j 从 MyBatis 3.5.9 版本开始被“弃用”(不推荐新项目用,老项目能用但后续可能不维护)。 - 增加 Log4j 的依赖:如果想让 MyBatis 用 Log4j 打日志,需要在项目的依赖配置(比如 Maven 的
pom.xml)里,加入这段<dependency>代码。这样项目就能引入 Log4j 相关的库,MyBatis 也能借助 Log4j 输出日志了。
在 MyBatis 中配置 Log4j 日志,让 MyBatis 能输出更详细的日志(比如 SQL 执行过程、框架内部流程等),方便开发和调试。
逐部分解释:
1. 配置文件要求
要在项目的 resources 目录下,新建一个 名叫 log4j.properties 的配置文件(名字和扩展名必须严格一致,Log4j 才会自动识别)。
2. Log4j 日志级别
Log4j 定义了从高到低的日志级别:fatal(致命错误)> error(错误)> warn(警告)> info(普通信息)> debug(调试信息)> trace(跟踪信息)。
级别越高,输出的日志越少(比如 fatal 只输出最严重的错误,trace 会输出极详细的跟踪信息)。
3. 核心配置解析
log4j.rootLogger = DEBUG, console:- 把全局日志级别设为
DEBUG(会输出DEBUG及更高级别的日志); - 指定日志输出到名叫
console的“输出器”(下面会配置console是控制台输出)。
- 把全局日志级别设为
### console ###部分:- 配置“控制台输出器”的规则:
log4j.appender.console = org.apache.log4j.ConsoleAppender:指定输出到控制台;log4j.appender.console.Target = System.out:输出到系统标准输出(就是你平时看到的控制台打印);log4j.appender.console.layout = org.apache.log4j.PatternLayout:指定日志“格式模板”;log4j.appender.console.layout.ConversionPattern = [...]:具体的日志格式(比如包含时间、日志级别、类名、日志内容等)。
- 配置“控制台输出器”的规则:
4. 按需调整日志(看 SQL 执行)
如果只想看 MyBatis 中 mapper.xml 里的 SQL 执行过程,可以“全局调高、局部调低”:
- 全局日志级别设为
ERROR(减少无关日志); - 给
mapper.xml对应的“命名空间”(比如a.b)单独设日志级别为TRACE(让 SQL 相关的详细日志能输出)。
配置方式就是在log4j.properties里加:log4j.logger.a.b = TRACE(a.b替换成你实际的mapper命名空间)。
简单说:这段内容是教你“通过 Log4j 配置,让 MyBatis 输出你想要的日志信息”,尤其是调试 SQL 执行时很有用~

















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









