







函数分析
stoi() & atoi()
stoi()
int stoi (const string& str, size_t* idx = 0, int base = 10);
int stoi (const wstring& str, size_t* idx = 0, int base = 10);
Convert string to integer
Parses str interpreting its content as an integral number of the specified base, which is returned as an int value.
If idx is not a null pointer, the function also sets the value of idx to the position of the first character in str after the number.
The function uses strtol (or wcstol) to perform the conversion (see strtol for more details on the process).
C++的字符处理函数,把数字字符串转换成int输出
头文件#include
stoi()会做范围检查,默认范围是在int的范围内的,如果超出范围的话则会runtime error!
遇到非法字符会停下来
ps. atoi()
atoi()的参数是 const char* ,因此对于一个字符串str我们必须调用 c_str()的方法把这个string转换成 const char类型的,而stoi()的参数是const string,不需要转化为 const char*;
atoi()不会做范围检查,如果超出范围的话,超出上界,则输出上界,超出下界,则输出下界;范围[-2147483648,2147483647]
遇到非法字符会停下来
eg.
string s1 = “21474827567”
cout << stoi( s1 ) << endl;
cout << atoi( s1.c_str() ) << endl;
strtol()
参考百度百科
strtol函数会将参数nptr字符串根据参数base来转换成长整型数,参数base范围从2至36。
long int strtol( const char *nptr, char ** endptr, int base );
将string字符串转换为int类型,但这个函数可以自定义转换的string字符串的类型(第三个参数可定义string字符串的类型),strtol超过int范围,不会报错,只会输出最大或者最小值[-2147483648,2147483647],遇到非法字符,则同样停止,不会报错;
参数base范围从2至36,或0,参数base代表采用的进制方式,如base值为10则采用10进制,若base值为16则采用16进制等。当base值为0时则是采用10进制做转换,但遇到如’0x’前置字符则会使用16进制做转换、遇到’0’前置字符而不是’0x’的时候会使用8进制做转换。
一开始strtol()会扫描参数nptr字符串,跳过前面的空格字符,直到遇上数字或正负符号才开始做转换,再遇到非数字或字符串结束时(’\0’)结束转换,并将转换数值返回。参数endptr指向停止转换的位置,若字符串nptr的所有字符都成功转换成数字则endptr指向串结束符’\0’。判断是否转换成功,应检查**endptr是否为’\0’。
endptr是一个传出参数,函数返回时指向后面未被识别的第一个字符。例如char *pos; strtol(“123abc”, &pos, 10);,strtol返回123,pos指向字符串中的字母a。如果字符串开头没有可识别的整数,例如char *pos;
strtol(“ABCabc”, &pos, 10);则strtol返回0,pos指向字符串开头,可以据此判断这种出错的情况,而这是atoi处理不了的。
eg.
string s = “111nnn1111”;
cout << strtol( s.c_str(), nullptr, 10 ) << endl;
next_permutation
STL提供计算排列组合的算法:next_permutation 和 prev_permutation.
函数next_permutation()是按照字典序产生排列的,并且是从数组中当前的字典序开始依次增大直至到最大字典序
参考博客:this
考虑三个字符所组成的序列{a,b,c}
必须了解:解什么是“下一个”排列组合,什么是“前一个”排列组合。
序列{a,b,c}有六个可能的排列组合:abc,acb,bac,bca,cab,cba。这些排列组合根据less-than操作符做字典顺序(lexicographical)的排序。
eg.面对bca,其前一个排列组合是bac,而其后一个排列组合是cab。序列abc没有“前一个”排列组合,cba没有“后一个”排列组合。(即字典序相关)
next_permutation()会取得[first,last]所标示之序列的下一个排列组合,如果没有下一个排列组合,便返回false;否则返回true。
这个算法有两个版本。版本一使用元素型别所提供的less-than操作符来决定下一个排列组合,版本二则是以仿函数comp来决定。
simple应用:
输出序列{1,2,3,4}字典序的全排列。(less-than)
伪代码
int a[N]={1,2,3,4,...,n};
sort(a,a+n); /* sort排序*/
do /*如果是while循环,则需要提前输出*/
{
for(int i=0;i<n;i++)
cout<<a[i]<<" ";
cout<<endl;
}while(next_permutation(a,a+n));
扩展:1.直接算出集合{1, 2, …, m}的第n个排列
2.给定一种排列,如何算出这是第几个排列呢
第二版本(comp)
函数原型:
#include
bool next_permutation (i terator start, iterator end )
当前序列不存在下一个排列时,函数返回false,否则返回true
next_permutation(node,node+n,cmp) 可以对结构体num按照自定义的排序方式cmp进行排序。
注:以下代码from this 原博客
char 类型的next_permutation
int main()
{
char ch[205];
cin >> ch;
sort(ch, ch + strlen(ch) );
//该语句对输入的数组进行字典升序排序。如输入9874563102 cout<<ch; 将输出0123456789,这样就能输出全排列了
char *first = ch;
char *last = ch + strlen(ch);
do {
cout<< ch << endl;
}while(next_permutation(first, last));
return 0;
}
//这样就不必事先知道ch的大小了,是把整个ch字符串全都进行排序
//若采用 while(next_permutation(ch,ch+5)); 如果只输入1562,就会产生错误,因为ch中第五个元素指向未知
//若要整个字符串进行排序,参数5指的是数组的长度,不含结束符
string 类型的next_permutation
int main()
{
string s;
while(cin>>s && s!="#")
{
if(next_permutation(s.begin(),s.end())) //从当前输入位置开始
cout << s << endl;
else cout << "Nosuccesor\n";
}
}
int main()
{
string s;
while(cin>>s && s!="#")
{
sort(s.begin(), s.end());//全排列
cout << s << endl;
while(next_permutation(s.begin(), s.end()))
cout << s << endl;
}
}
题目:
AtCoder Beginner Contest 221 C - Select Mul
题面:
 Sample Input 3
Sample Input 3
998244353
Sample Output 3
939337176
大意:将一串数字X 分成任意的两串x1,x2,使得乘积x1 * x2最大,输出MAX(x1*x2)
分析:
一开始我想采用贪心的做法,将数字存在数组里,先sort一遍数组,然后从大到小将数字间隔放在两个数组里,得到answer,最后一位要注意(eg.simple input 998244353 要分成 9843*95432),但是感觉这样只有奇数的会满足,偶数的不会,所以WA了一半。
Editorial:
由于N<=109, 所以数字最多才为9个
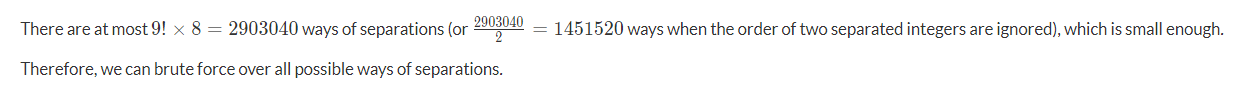 所以可以采用暴力做法.
所以可以采用暴力做法.
With a little more observation, we can see that accepting leading zeros does not affect the answer. (前导零不会影响结果)
Editorial by en_translator Sample code (C++)
#include<bits/stdc++.h>
using namespace std;
int main(){
string N; cin >> N;
sort(N.begin(),N.end()); //排序,因为next_permutation
int ans = 0;
do{
for(int i=1; i<N.size(); i++){ // i相当于隔板,将string N 分成了两个部分
int l = 0, r = 0;
for(int j=0; j<i; j++) l = l*10+N[j]-'0';
for(int j=i; j<N.size(); j++) r = r*10+N[j]-'0';
ans = max(ans,l*r);
}
}while(next_permutation(N.begin(),N.end())); // 全排列
cout << ans << endl;
}
or:
// for(int j=0; j<i; j++) l += N[j];
// for(int j=i; j<N.size(); j++) r += N[j];
// ans = max(ans,stoi(l)*stoi(r));
进一步观察,我们可以看到,当达到最大值时,分离的两个变量作为一个数字序列是单调不递增的。
根据这个性质,我们可以看到我们应该检查的分离次数是29(或28如果两个分开的整数的顺序被忽略)。
 补充:
补充:
正确的贪心:
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main() {
string s;
cin >> s;
sort(s.rbegin(), s.rend());
int sa = (char)(s[0]-'0');
int sb = (char)(s[1]-'0');
for (size_t i = 2; i < s.size(); i++){
if (sa<sb) sa *= 10, sa += (char)(s[i]-'0');
else sb *= 10, sb += (char)(s[i]-'0');
}
cout << sa*sb << "\n";
return 0;
}
核心:判断 sa < sb, 才能正确的贪心,让两个数的乘积尽可能的大(若是偶数尽可能平均,若是奇数让前面值小的数多一位)构造 - > 前面数大,后面数小
eg. 123456
max: 631 * 542















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









