









begin






通过使用预处理指令来让程序并行化
1 #pragma omp 指令
#pragma omp 指令 [子句[子句]…]
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
// YOUR CODE HERE
#pragma omp parallel for
// END OF YOUR CODE
for (i = 0; i < 10; i++) {
printf("i = %d\n", i);
}
return 0;
}
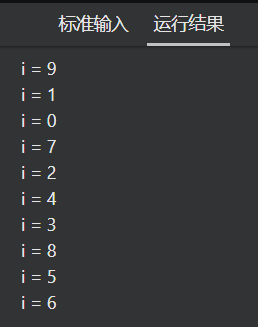
程序并行执行
2 fork/join
用于共享内存并行系统
多处理器程序设计
OpenMP并行执行的程序要全部结束后才会运行后面非并行部分的代码( fork/join并行模式 )
#include <stdio.h>
#include <time.h>
void foo()
{
int cnt = 0;
int t1 = clock();
int i;
for (i = 0; i < 1e8; i++) {
cnt++;
}
int t2 = clock();
printf("Time = %d\n", t2 - t1);
}
int main(int argc, char* argv[])
{
int t1 = clock();
int i;
// YOUR CODE HERE
#pragma omp parallel for
// END OF YOUR CODE
for (i = 0; i < 2; i++) {
foo();
}
int t2 = clock();
printf("Total time = %d\n", t2 - t1);
return 0;
}
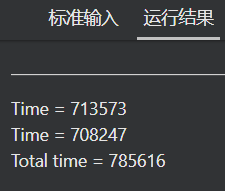
栗子:
求代码运行的时间
若没进行openmd并行,total time应该接近前两个时间之和
but进行openmd并行后,total time和前两个时间接近
3 #pragma omp parallel
parallel 是构造并行块的指令
可以配合for, sections一起使用
该指令后面用大括号来指定需要并行计算的代码
#pragma omp parallel [for | sections] [子句[子句]…]
{
//并行部分
}
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
// YOUR CODE HERE
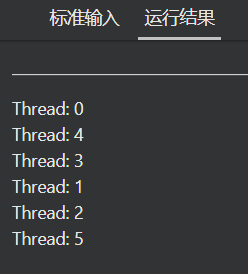
#pragma omp parallel num_threads(6)
// END OF YOUR CODE
{
printf("Thread: %d\n", omp_get_thread_num());
}
return 0;
}
#pragma omp parallel num_threads(6) 使程序并行执行
4 #pragma omp for
for 指令的使用方法
使一个for循环在多个线程中执行
for指令会与parallel指令同时使用(即parallel for指令)
还可以在parallel指令的并行块中单独使用
一个并行块中可以使用多个for指令
#pragma omp parallel
{
#pragma omp for
}
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
#pragma omp parallel
{
int i, j;
// YOUR CODE HERE
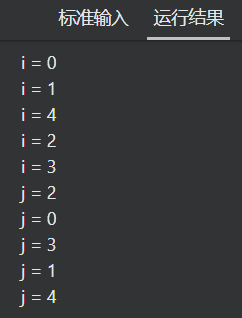
#pragma omp for
// END OF YOUR CODE
for (i = 0; i < 5; i++)
printf("i = %d\n", i);
// YOUR CODE HERE
#pragma omp for
// END OF YOUR CODE
for (j = 0; j < 5; j++)
printf("j = %d\n", j);
}
return 0;
}
5 sections
sections语句可以将代码分成不同的分块
section指令来指定分块
每一个分块并行执行
#pragma omp [parallel] sections [子句]
{
#pragma omp section
{
//代码
}
…
}
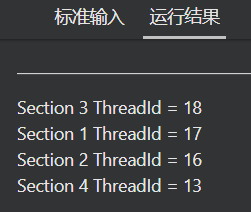
填上使用sections指令使程序并行执行
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
// YOUR CODE HERE
#pragma omp parallel sections
// END OF YOUR CODE
{
#pragma omp section
printf("Section 1 ThreadId = %d\n", omp_get_thread_num());
#pragma omp section
printf("Section 2 ThreadId = %d\n", omp_get_thread_num());
#pragma omp section
printf("Section 3 ThreadId = %d\n", omp_get_thread_num());
#pragma omp section
printf("Section 4 ThreadId = %d\n", omp_get_thread_num());
}
return 0;
}
7 private
private 子句可以将变量声明为线程私有
线程私有变量:每个线程都有一个该变量的副本,线程之间不会互相影响,其他线程无法访问其他线程的副本。
原变量在并行部分不起任何作用,也不会受到并行部分内部操作的影响。
#pragma omp parallel for private(i)
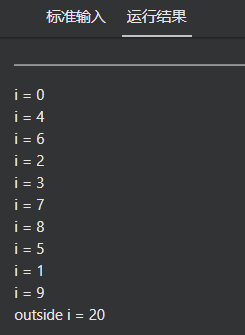
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i = 20;
// YOUR CODE HERE
#pragma omp parallel for private(i)
// END OF YOUR CODE
for (i = 0; i < 10; i++)
{
printf("i = %d\n", i);
}
printf("outside i = %d\n", i);
return 0;
}
8 firstprivate
private子句不能继承原变量的值
可以使用firstprivate子句来使线程私有变量继承原来变量的值
#pragma omp parallel for firstprivate(t)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int t = 20, i;
// YOUR CODE HERE
#pragma omp parallel for firstprivate(t)
// END OF YOUR CODE
for (i = 0; i < 5; i++)
{
t += i;
printf("t = %d\n", t);
}
printf("outside t = %d\n", t);
return 0;
}

9 astprivate
astprivate子句实现:退出并行部分时将计算结果赋值回原变量
根据OpenMP规范:在循环迭代中,是最后一次迭代的值赋值给原变量;如果是section结构,那么是程序语法上的最后一个section语句赋值给原变量。
如果类(class)变量作为lastprivate的参数时,需要一个缺省构造函数,除非该变量也作为firstprivate子句的参数;此外还需要一个拷贝赋值操作符。
#pragma omp parallel for firstprivate(t), lastprivate(t)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int t = 20, i;
// YOUR CODE HERE
#pragma omp parallel for firstprivate(t), lastprivate(t)
// END OF YOUR CODE
for (i = 0; i < 5; i++)
{
t += i;
printf("t = %d\n", t);
}
printf("outside t = %d\n", t);
return 0;
}
10 Share
Share子句可以将一个变量声明成共享变量
在多个线程内共享
attention:
在并行部分进行写操作时,要求共享变量进行保护,否则不要随便使用共享变量,尽量将共享变量转换为私有变量使用
#pragma omp parallel for shared(t)
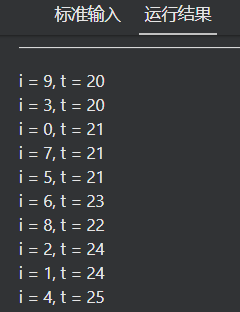
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int t = 20, i;
// YOUR CODE HERE
#pragma omp parallel for shared(t)
// END OF YOUR CODE
for (i = 0; i < 10; i++)
{
if (i % 2 == 0)
t++;
printf("i = %d, t = %d\n", i, t);
}
return 0;
}
11 reduction
reduction 对一个或者多个参数指定一个操作符
每一个线程都会创建这个参数的私有拷贝
在并行区域结束后,迭代运行指定的运算符,并更新原参数的值。
私有拷贝变量的初始值依赖于redtution的运算类型。
#pragma omp parallel for reduction(+: sum)
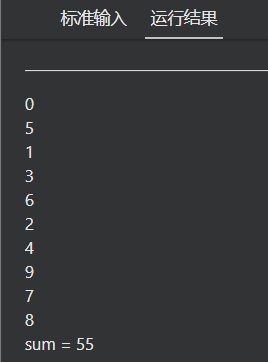
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i, sum = 10;
// YOUR CODE HERE
#pragma omp parallel for reduction(+: sum)
// END OF YOUR CODE
for (i = 0; i < 10; i++)
{
sum += i;
printf("%d\n", sum);
}
printf("sum = %d\n", sum);
return 0;
}
12 omp_get_dynamic
omp_get_dynamic
返回当前程序是否允许在运行时动态调整并行区域的线程数
int omp_get_dynamic()
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
printf("%d\n", omp_get_dynamic());
omp_set_dynamic(1);
#pragma omp parallel for
for (i = 0; i < 4; i++)
{
// YOUR CODE HERE
printf("%d\n", omp_get_dynamic());
// END OF YOUR CODE
}
return 0;
}
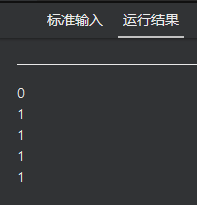
13 omp_set_dynamic
omp_set_dynamic
设置是否允许在运行时动态调整并行区域的线程数
void omp_set_dynamic(int)
当参数为0时,动态调整被禁用。
当参数为非0值时,系统会自动调整线程以最佳利用系统资源。
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
// YOUR CODE HERE
omp_set_dynamic(1);
// END OF YOUR CODE
#pragma omp parallel for
for (i = 0; i < 4; i++)
{
printf("%d\n", omp_get_thread_num());
}
return 0;
}
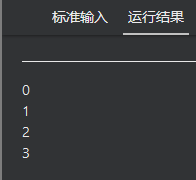
14 copyin
copyin
将主线程中变量的值拷贝到各个线程的私有变量中,让各个线程可以访问主线程中的变量。
其参数必须要被声明称threadprivate,对于类的话则并且带有明确的拷贝赋值操作符。
#pragma omp parallel for copyin(g)
#include <stdio.h>
#include <omp.h>
int g = 0;
#pragma omp threadprivate(g)
int main(int argc, char* argv[])
{
int i;
#pragma omp parallel for
for (i = 0; i < 4; i++)
{
g = omp_get_thread_num();
printf("thread %d, g = %d\n", omp_get_thread_num(), g);
}
printf("global g: %d\n", g);
// YOUR CODE HERE
#pragma omp parallel for copyin(g)
// END OF YOUR CODE
for (i = 0; i < 4; i++)
printf("thread %d, g = %d\n", omp_get_thread_num(), g);
return 0;
}
加copyin
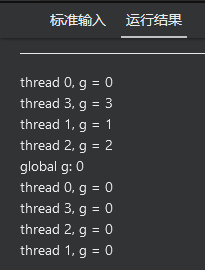 没加:
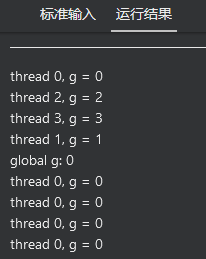
没加:
15 static调度
static
parallel for没有带schedule时,系统默认采用static调度方式。
假设有n次循环迭代,t个线程,那么每个线程大约分到n/t次迭代。
这种调度方式会将循环迭代均匀的分布给各个线程,各个线程迭代次数可能相差1次。
schedule(method)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
// YOUR CODE HERE
#pragma omp parallel for schedule(static)
// END OF YOUR CODE
for (i = 0; i < 10; i++)
{
printf("i = %d, thread %d\n", i, omp_get_thread_num());
}
return 0;
}
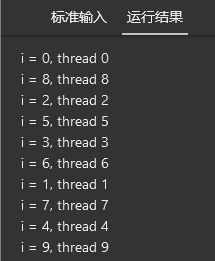
16 size参数
静态调度,通过指定size参数来分配一个线程的最小迭代次数。
指定size后,每个线程最多可能相差size次迭代。
可以推断出[0,size-1]的迭代是在第一个线程上运行
依次类推。
#pragma omp parallel for schedule(static, 3)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
// YOUR CODE HERE
#pragma omp parallel for schedule(static, 3)
// END OF YOUR CODE
for (i = 0; i < 10; i++)
{
printf("i = %d, thread %d\n", i, omp_get_thread_num());
}
return 0;
}
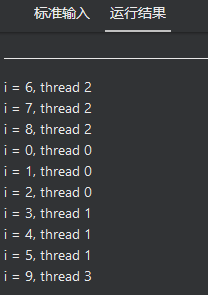
SIZE=3 差3次迭代
17 dynamic
dynamic
动态分配是将迭代动态分配到各个线程
依赖运行状态来确定
所以无法像静态调度一样事先预计进程的分配
哪一个线程先启动,哪一个线程迭代多久,都取决于系统的资源和线程的调度
#pragma omp parallel for schedule(dynamic)
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
// YOUR CODE HERE
#pragma omp parallel for schedule(dynamic)
// END OF YOUR CODE
for (i = 0; i < 10; i++)
{
printf("i = %d, thread %d\n", i, omp_get_thread_num());
}
return 0;
}

thread值很动态 @.@
18 omp_get_num_procs
omp_get_num_procs
返回调用函数时可用的处理器数目。
int omp_get_num_procs(void)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
printf("%d\n", omp_get_num_procs());
#pragma omp parallel
{
// YOUR CODE HERE
printf("%d\n", omp_get_num_procs());
// END OF YOUR CODE
}
return 0;
}
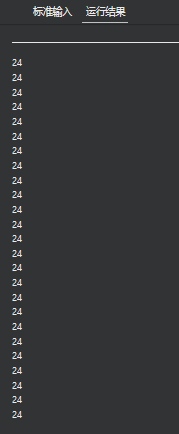
19 omp_get_num_procs
omp_get_num_threads
返回当前并行区域中的活动线程个数
如果在并行区域外部调用,返回1
int omp_get_num_threads(void)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
printf("%d\n", omp_get_num_threads());
#pragma omp parallel
{
// YOUR CODE HERE
printf("%d\n", omp_get_num_threads());
// YOUR CODE HERE
}
return 0;
}
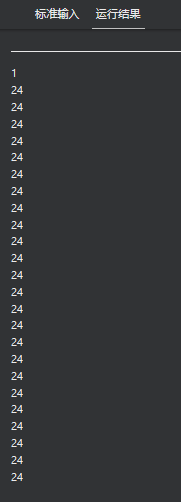
20 omp_get_thread_num
omp_get_thread_num
返回当前的线程号
int omp_get_thread_num(void)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
printf("%d\n", omp_get_thread_num());
#pragma omp parallel
{
// YOUR CODE HERE
printf("%d\n", omp_get_thread_num());
// END OF YOUR CODE
}
return 0;
}
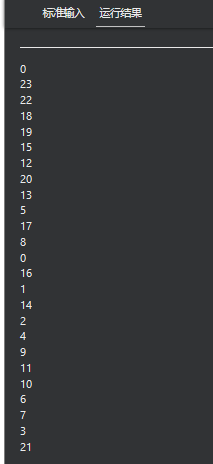
21 omp_set_num_threads
omp_set_num_threads
设置进入并行区域时,将要创建的线程个数
int omp_set_num_threads(void)
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
// YOUR CODE HERE
omp_set_num_threads(4);
// END OF YOUR CODE
#pragma omp parallel
{
printf("%d of %d threads\n", omp_get_thread_num(), omp_get_num_threads());
}
return 0;
}

22 omp_in_parallel
omp_in_parallel
可以判断当前是否处于并行状态
int omp_in_parallel();
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
printf("%d\n", omp_in_parallel());
omp_set_num_threads(4);
#pragma omp parallel
{
// YOUR CODE HERE
printf("%d\n", omp_in_parallel());
// END OF YOUR CODE
}
return 0;
}

23 omp_get_max_threads
omp_get_max_threads
可以用于获得最大的线程数量,根据OpenMP文档中的规定,这个最大数量是指在不使用num_threads的情况下,OpenMP可以创建的最大线程数量。
需要注意的是这个值是确定的,与它是否在并行区域调用没有关系。
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
// YOUR CODE HERE
printf("%d\n", omp_get_max_threads());
// END OF YOUR CODE
omp_set_num_threads(4);
#pragma omp parallel
{
printf("%d\n", omp_get_max_threads());
}
return 0;
}

24 OpenMP互斥锁
OpenMP中互斥锁
Openmp提供一系列函数来进行锁的操作
常用的4个函数:
void omp_init_lock(omp_lock*) 初始化互斥锁
void omp_destroy_lock(omp_lock*) 销毁互斥锁
void omp_set_lock(omp_lock*) 获得互斥锁
void omp_unset_lock(omp_lock*) 释放互斥锁
#include <stdio.h>
#include <omp.h>
static omp_lock_t lock;
int main(int argc, char* argv[])
{
int i;
omp_init_lock(&lock);
#pragma omp parallel for
for (i = 0; i < 5; ++i)
{
// YOUR CODE HERE
omp_set_lock(&lock);
// END OF YOUR CODE
printf("%d+\n", omp_get_thread_num());
printf("%d-\n", omp_get_thread_num());
// YOUR CODE HERE
omp_unset_lock(&lock);
// END OF YOUR CODE
}
omp_destroy_lock(&lock);
return 0;
}
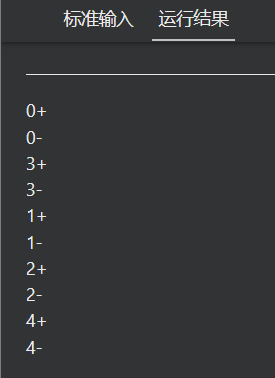
25 omp_test_lock
omp_test_lock
还有一个与互斥锁的相关的函数,用来尝试获得锁。
该函数可以看作是omp_set_lock的非阻塞版本。
bool omp_test_lock(omp_lock*)
#include <stdio.h>
#include <omp.h>
static omp_lock_t lock;
int main(int argc, char* argv[])
{
int i;
omp_init_lock(&lock);
#pragma omp parallel for
for (i = 0; i < 5; ++i)
{
// YOUR CODE HERE
if (omp_test_lock(&lock))
// END OF YOUR CODE
{
printf("%d+\n", omp_get_thread_num());
printf("%d-\n", omp_get_thread_num());
omp_unset_lock(&lock);
}
else
{
printf("fail to get lock\n");
}
}
omp_destroy_lock(&lock);
return 0;
}

end
























 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









