







 本文档详述了在Virtual Box中搭建Hadoop大数据环境的步骤,包括Ubuntu虚拟机的配置、Java安装、Hadoop分布式配置,并展示了如何解决过程中遇到的问题。实验涉及网络配置、SSH免密登录、Hadoop集群的启动与状态检查,以及日志和交通数据的大数据分析操作。
本文档详述了在Virtual Box中搭建Hadoop大数据环境的步骤,包括Ubuntu虚拟机的配置、Java安装、Hadoop分布式配置,并展示了如何解决过程中遇到的问题。实验涉及网络配置、SSH免密登录、Hadoop集群的启动与状态检查,以及日志和交通数据的大数据分析操作。
目录
1.将下载好的jdk-8u241-linux-x64.tar.gz使用tar命令解压
1.将下载好的hadoop-2.7.3.tar.gz包解压,执行解压命令,复制到Hadoop目录
2.解压完成后配置Hadoop环境变量,编辑profile文件
6.3台虚拟机全部配置完成后,在master节点执行如下指令格式化HDFS文件系统hdfs namenode –format
-
Hadoop简介
Hadoop是由Apache研发的开源分布式基础架构,它由Hadoop内核MapReduce Hadoop分布式文件系统(HDFS)及一些相关项目组成,其中,HDFS具有高容错性,负大数据存储;MapReduce则负责对HDES中的大量数据进行复杂的分布式计算。
Hadoop作为分布式架构,采用“分而治之”的设计思想:将大量数据分布式地存放于大量服务器上,采用分治的方式对大数据进行分析。在这种思想的驱使下,Hadoop实现了MapReduce的编程范式。其中“Map”意为映射,其工作是将一个键值对分解为多个键值对:“Reduce”意为归约,其工作是将多组键值对处理合并后产生新的键值对写人 HDFS。通过上述工作原理,MapReduce实现了将大数据工作拆分为多个小规模数据任务在大量服务器上分布式处理。
-
实验一:构建虚拟机网络
本实验的Hadoop平台搭建共使用3台Ubuntu虚拟机来完成,其中一台为master节点,两台为slave节点。
(一)Virtual Box的安装及配置
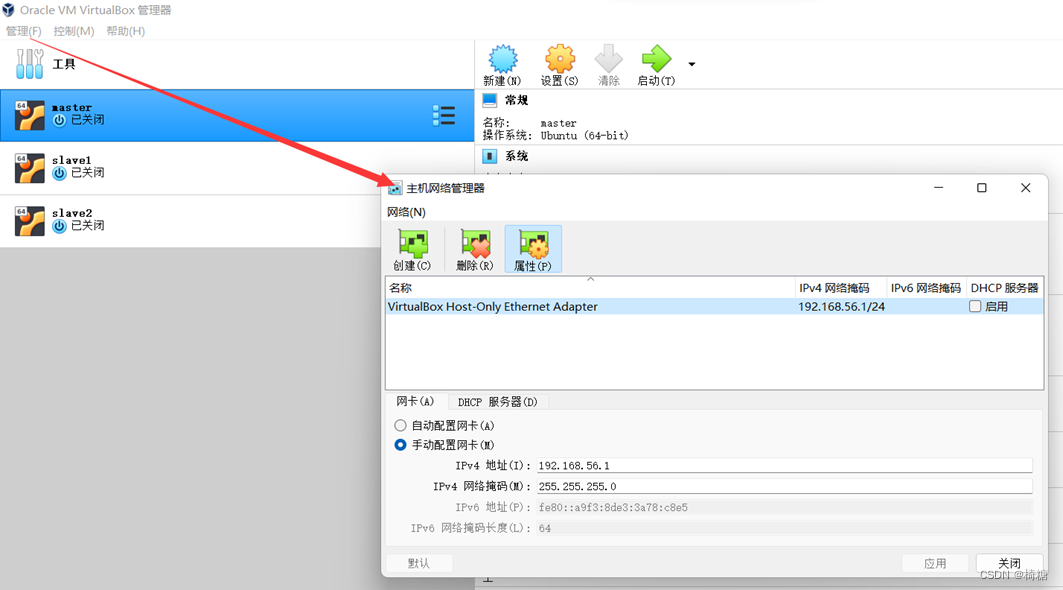
VirtualBox Host Only Ethernet Adapter 创建好之后,选择菜单栏中的“管理”——“主机网络管理器”,选择手动配置网卡,将IPv4地址设置为192. 168. 56. 1,IPv4网络掩码设置为255. 255. 255. 0,IPv6地址及网络掩码长度不需要修改,保持DHCP服务器不开启。
(二)Ubuntu虚拟机的安装及配置
创建3台虚拟机,在Virtual Box主界面单击“新建”按钮创建新的虚拟机。
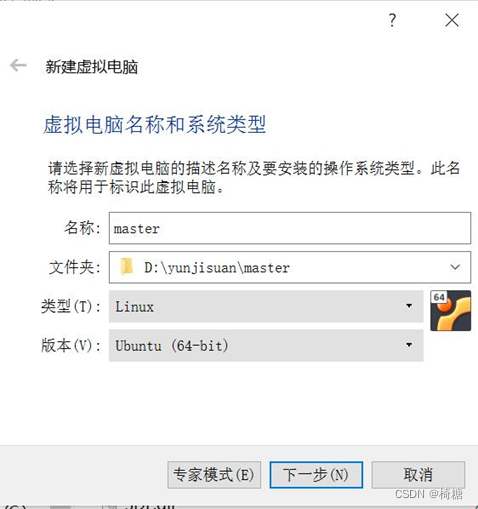
这里需要设置虚拟机的名称,在本实验中建议将3台虚拟机分别命名为master、slave1、slave2,以便识别。类型选择"Linux" ,版本选择"Ubuntu(64-bit)”。单击“下一步”按钮。
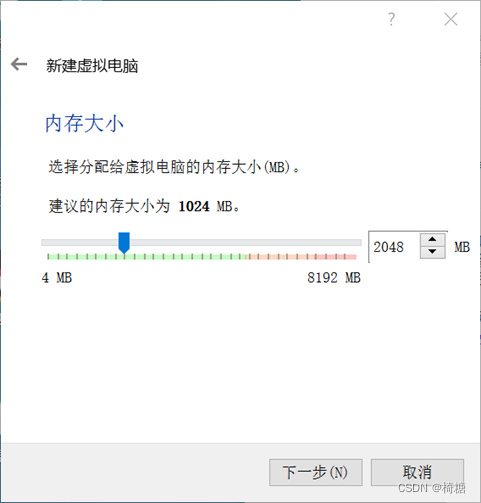
进行虚拟机配置的设置,虚拟机内存至少设置为2GB,以保证运行流畅,并为虚拟机创建足够大小的虚拟硬盘。
在创建完成后选中虚拟机,打开右侧的虚拟机设置,选择“网络”选项。其中网卡1默认为“网络地址转换(NAT)”,不需要更改,选择网卡2选中“启用网络连接”复选框。连接方式选择“仅主(Host-Only)网络”,界面名称选择前面建立的Virtual Box Host-Only Ethernet Adapter。在高级选项中设置混杂模式为“全部允许”,其他选项保持默认。
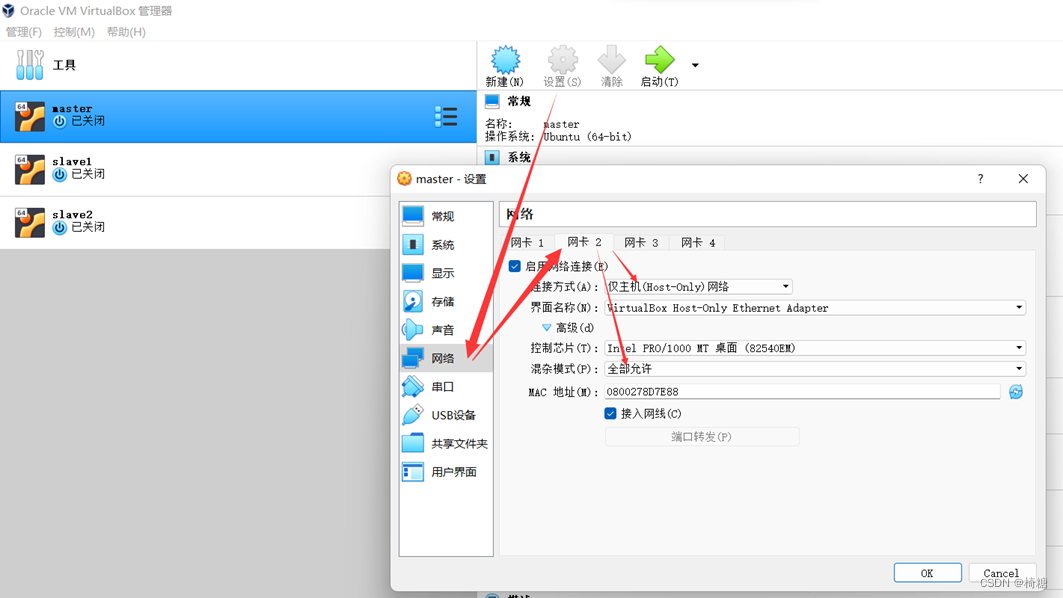
对3台虚拟机都进行上述网络配置,完成后可启动虚拟机,在启动时选择加载Ubuntu镜像即可进行虚拟机安装。
(三)修改Ubuntu系统内的网络配置
在系统安装成功后需要进行网络配置,主要包括3台虚拟机的互联与设置SSH免密登录。
1.查看网卡状态
在进人虚拟机系统后“ctrl+alt+t”打开终端,输入ifconfig –a命令查看当前网卡状态,如图所示。可以看到enp0s3网卡与enp0s8网卡。enp0s3网卡是虚拟机网络设置中的网卡1,负责通过主机连接互联网: enp0s8为Hos-Only网络,负责3台虚拟机组网内互通。不同机器的网卡名称可能不同,且Host Only网卡默认为关闭状态。
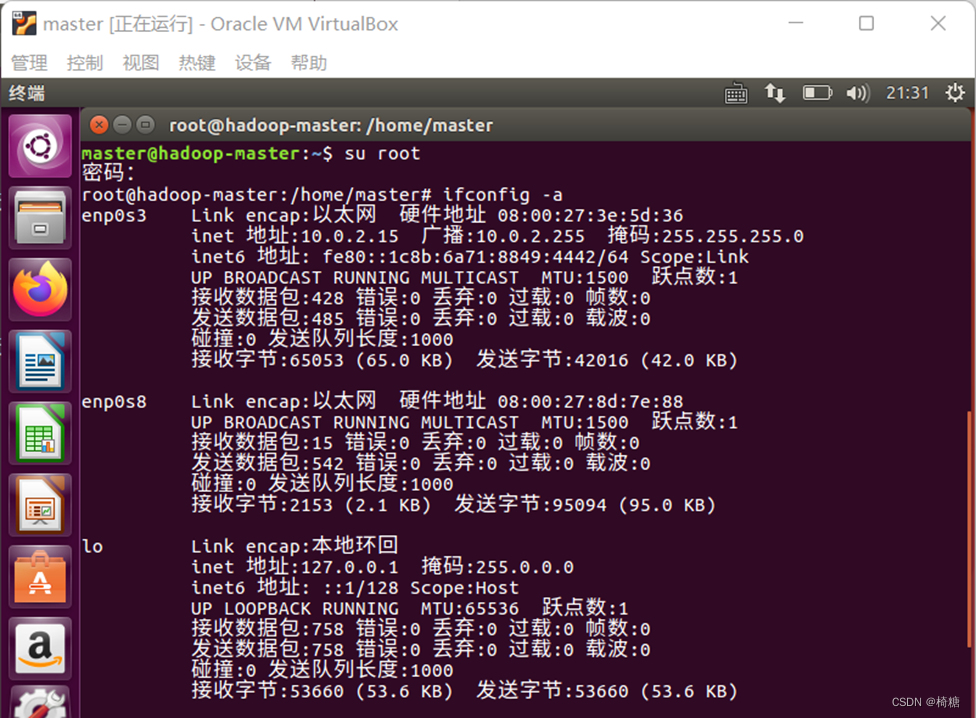
2.更改配置文件
配置网络启动Host-Only网卡,通过以下指令更改配置文件:
sudo vim /etc/network/interfaces
![]()
在文件中添加如下信息:
auto enp0s8
iface enp0s8 inet static
address 192.168.56.1
netmask 255.255.255.0
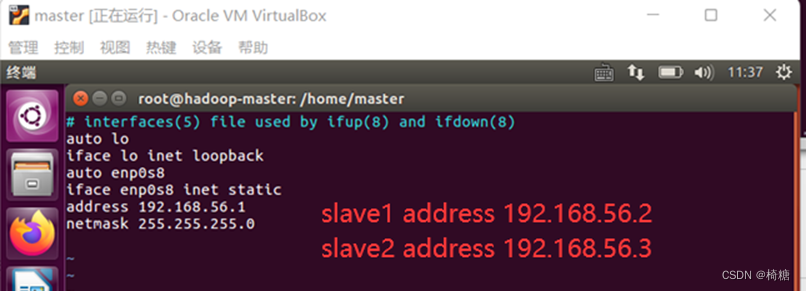
:wq保存退出
:wq!强制保存退出
3.启动网卡
修改完成后保存文件,输入以下指令启动网卡:
sudo ifup enp0s8
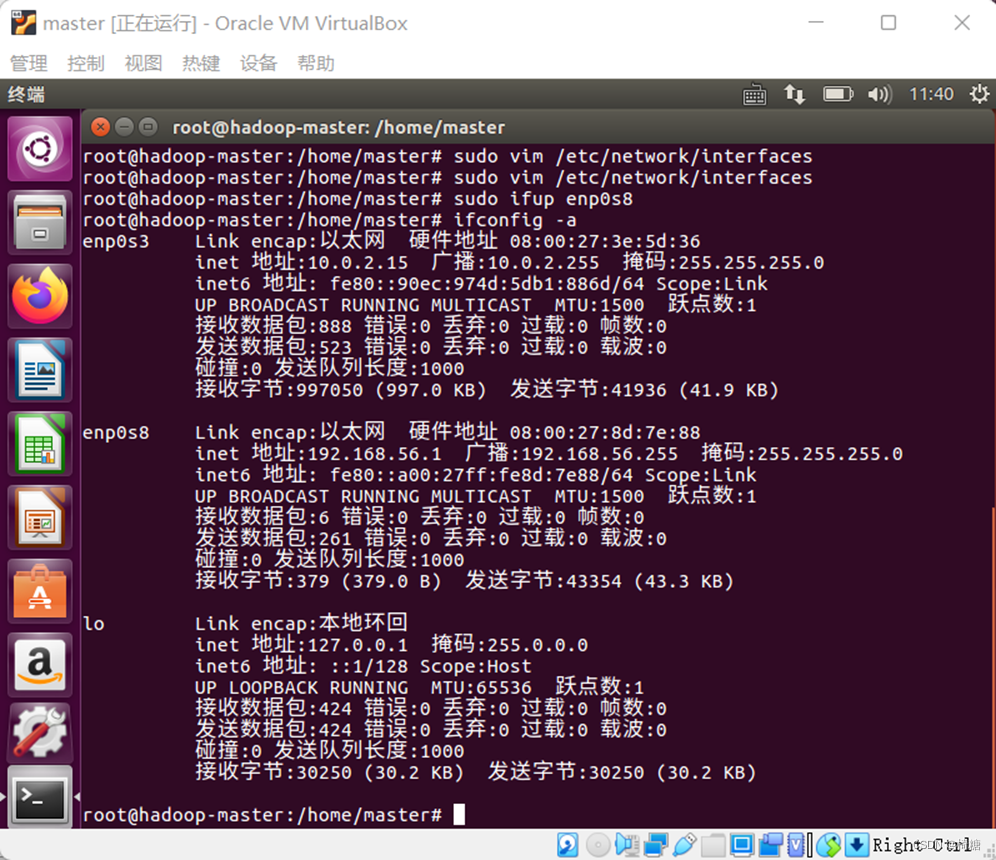
4.ping
配置成功后,3台主机之间相互ping
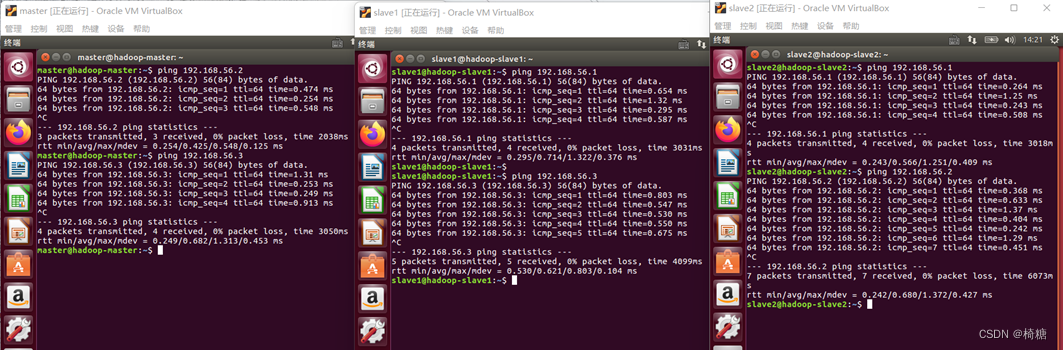
5.配置SSH免密登录
(1)在3台主机上安装SSH工具,命令如下:
sudo apt-get install openssh-server openssh-client
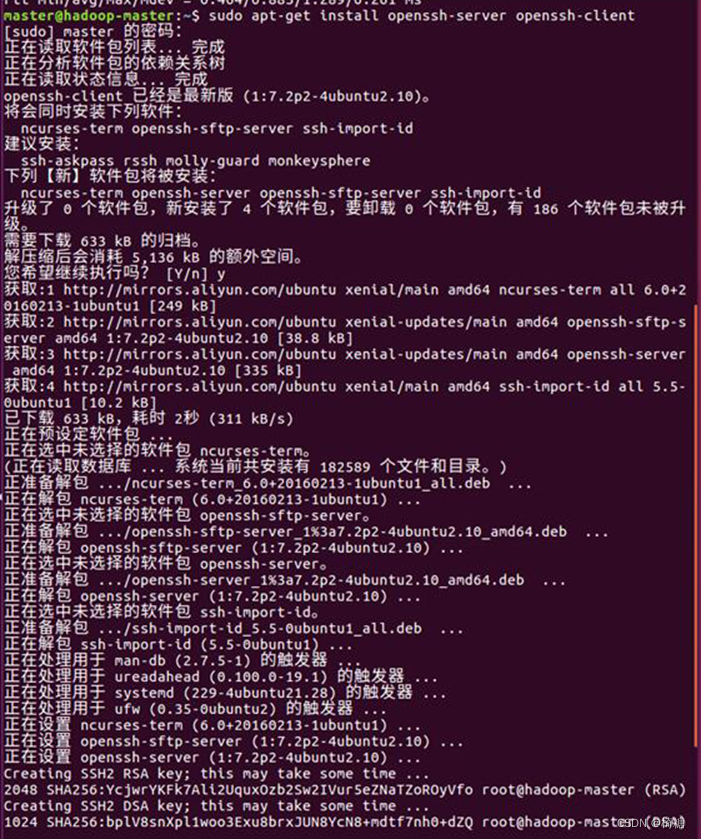
(2)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











