







一、SQL简介
- 英文:Structured Query Language,简称SQL
- 结构化查询语言,一门操作关系型数据库的编程语言
- 定义操作所有关系型数据库的统一标准
- 对于同一个需求,每一种数据库操作的方式可能会存在一些不一样的地方,我们称为“方言”
二、SQL 通用语法
- SQL语句可以单行或多行书写,以分号结尾
- MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写
- 注释
– 单行注释:- - 注释内容 或 #注释内容
– 多行注释:/* 注释 */
三、SQL 分类

四、DDL - 数据定义语言
1. 操作数据库
a. 查询
SHOW DATABASES;
b. 创建
- 创建数据库
CREATE DATABASE 数据库名称;
- 创建数据库(判断,如果不存在则创建)
CREATE DATABASE IF NOT EXISTS 数据库名称;
c. 删除
- 删除数据库
DROP DATABASE 数据库名称;
- 删除数据库(判断,如果存在则删除)
DROP DATABASE IF EXISTS 数据库名称;
d. 使用数据库
- 查看当前使用的数据库
SELECT DATABASE();
- 使用数据库
USE 数据库名称;
2. 操作表
a. 查询
- 查询当前数据库下所有表名称
SHOW TABLES;
- 查询表结构
DESC 表名称;
b. 创建
CREATE TABLE 表名(
字段名1 数据类型1,
字段名2 数据类型2,
...
字段名n 数据类型n
);
注意:最后一行末尾,不能加逗号
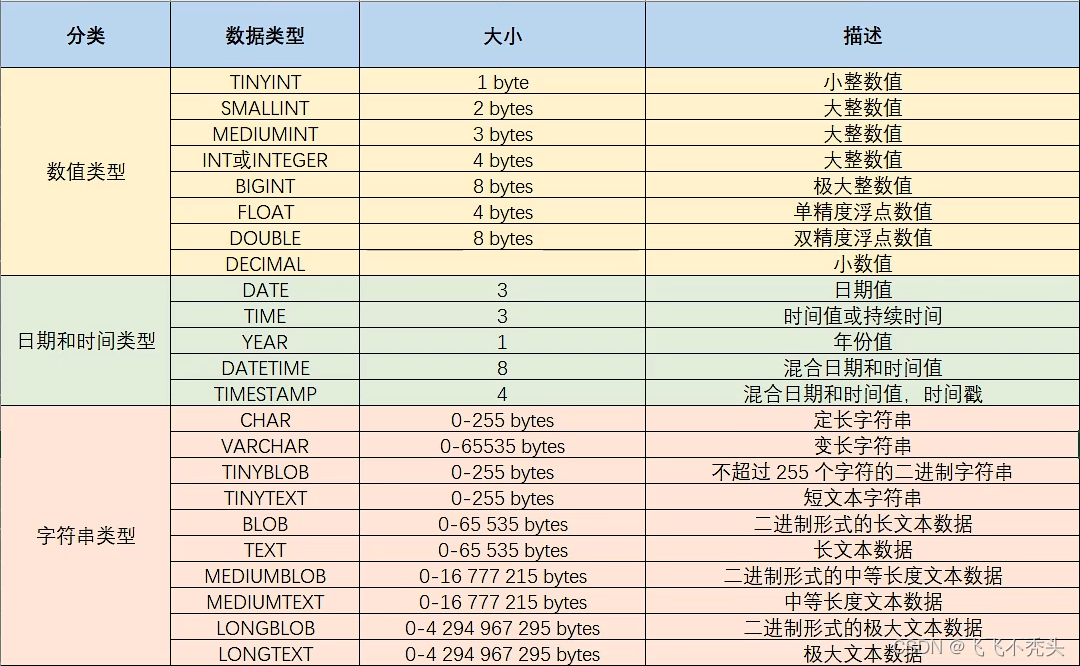
MySQL 支持多种类型,可以分为三类:
- 数值
- 日期
- 字符串
具体如下:
注意:
-
DOUBLE 类型的定义格式:字段名 DOUBLE(总长度,小数点后保留的位数)
其中总长度是存储数据的位数个数+小数点保留的位数个数- - - > 0~100 - - - > double(5,2) -
定长字符串定义后,系统会分配用户定义的字符串长度,即使存储的字符空间没有达到规定的长度,系统也会自动将剩余字符空间以默认值补全,所以其存储的性能高却浪费空间
变长字符串定义后,存储的字符大小就是字符空间大小,所以其存储的性能低却节约空间
c. 删除
- 删除表
DROP TABLE 表名;
- 删除表时判断表是否存在
DROP TABLE IF EXISTS 表名;
d. 修改
- 修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
- 添加一列
ALTER TABLE 表名 ADD 列名 数据类型;
- 修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
- 修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
- 删除列
ALTER TABLE 表名 DROP 列名;
五、DML - 数据操作语言
1. 添加数据
- 给指定列添加数据
INSERT INTO 表名(列名1,列名2,...) VALUES(值1,值2,...);
- 给全部列添加数据
INSERT INTO 表名 VALUES(值1,值2,...);
- 批量添加数据
INSERT INTO 表名(列名1,列名2,...) VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...)...;
INSERT INTO 表名 VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...)...;
2. 修改数据
UPDATE 表名 SET 列名1=值1,列名2=值2,...[WHERE 条件];
注意:修改语句中如果不加条件,则将所有数据都修改!
3. 删除数据
DELETE FROM 表名 [WHERE 条件];
注意:删除语句中如果不加条件,则将所有数据都删除!
六、DQL - 数据查询语句
1. 基础查询
- 查询多个字段
SELECT 字段列表 FROM 表名;
SELECT * FROM 表名; -- 查询所有数据
- 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
- 起别名
AS:AS也可以省略
2. 条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表;
条件:
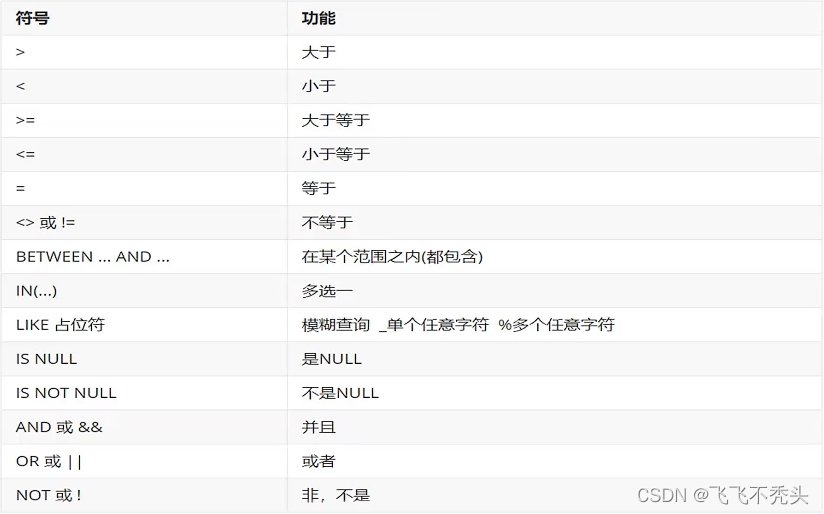
模糊查询举例:
- 查询 stu 表中姓‘马’的学员信息
SELECT * FROM stu WHERE name LIKE = '马%';
- 查询 stu 表中第二个字是‘花’的学员信息
SELECT * FROM stu WHERE name LIKE = '_花%';
- 查询 stu 表中名字中包含‘德’的学员信息
SELECT * FROM stu WHERE name LIKE = '%德%';
3. 排序查询
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1[排序方式1],排序字段名2[排序方式2]...;
排序方式:
- ASC:升序排列(默认值)
- DESC:降序排列
注意:如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
4. 分组查询
a. 聚合函数
概念: 将一列数据作为一个整体,进行纵向计算。
聚合函数分类:
| 函数名 | 功能 |
|---|---|
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
聚合函数语法:
SELECT 聚合函数名(列名) FROM 表;
注意:null 值不参与所有聚合函数运算
b. 分组查询
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
where 和 having 区别:
- 执行时机不一样:where 是分组之前进行限定,不满足 where 条件,则不参与分组,而 having 是分组之后对结果进行过滤。
- 可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
执行顺序:where > 聚合函数 > having
举例:
- 查询男同学和女同学各自的数学平均分
select sex, avg(math) from stu group by sex;
- 查询男同学和女同学各自的数学平均分,以及各自人数
select sex, avg(math), count(*) from stu group by sex;
- 查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组
select sex, avg(math), count(*) from stu where math > 70 group by sex;
- 查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2个
select sex, avg(math), count(*) from stu where math > 70 group by sex having count(*) > 2;
5. 分页查询
SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询条目数;
- 起始索引:从0开始
计算公式: 起始索引 = (当前页码 - 1)* 每页显示的条数
注意:
- 分页查询 limit 是 MySQL 数据库的方言
- Oracle 分页查询使用 rownumber
- SQL Server 分页查询使用 top















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









