






1.Flink 的并行度的怎么设置的?
Flink设置并行度的几种方式
1.代码中设置setParallelism()
全局设置:
| 1 |
|
算子设置(部分设置):
| 1 |
|
2.客户端CLI设置(或webui直接输入数量):
| 1 |
|
3.配置文件设置:
修改配置文件设置/conf/flink-conf.yaml的parallelism.defaul数值
4.最大并行度设置
全局设置:
| 1 |
|
算子设置(部分设置):
| 1 |
|
默认的最大并行度是近似于operatorParallelism + (operatorParallelism / 2),下限是127,上线是32768.
总结:Flink并行度配置级别 算子>全局env>客户端CLI>配置文件 。
2.介绍一下 Flink 作业中的 DataStream,Transformation?
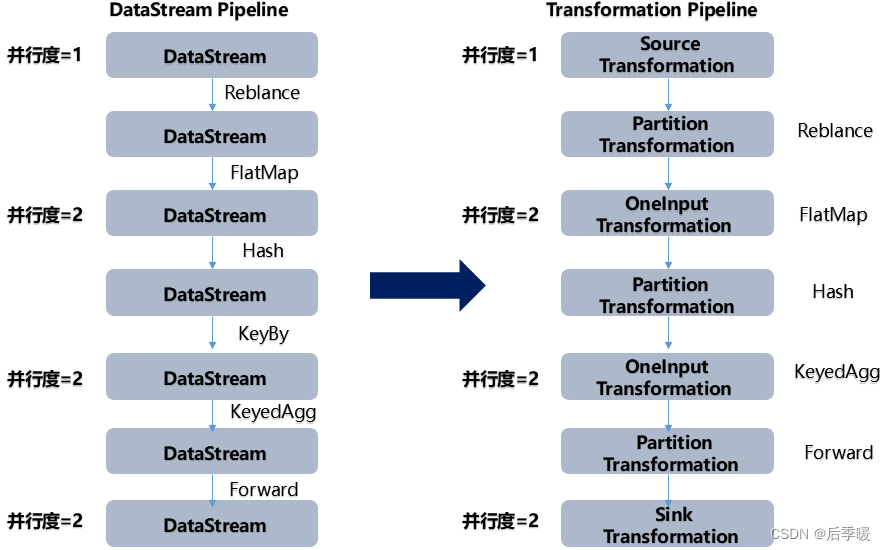
Flink 作业中,包含两个基本的块:数据流(DataStream)和 转换(Transformation)。
DataStream 是逻辑概念,为开发者提供 API 接口,Transformation 是处理行为的抽象,包含了数据的读取、计算、写出。所以 Flink 作业中的 DataStream API 调用,实际上构建了多个由 Transformation 组成的数据处理流水线(Pipeline)。
DataStream API 和 Transformation 的转换如下图:
3. Flink 的分区策略了解吗?
数据分区 在 Flink 中叫作 Partition。本质上来说,分布式计算就是把 一个作业 切分成子任务 Task, 将不同的数据交给不同的 Task 计算。
在分布式存储中, Partition 分区的概念就是把数据集切分成块,每一块数据存储在不同的机器上。同样 ,对于分布式计算引擎,也需要将数据切分,交给位于不同物理节点上的 Task 计算。
StreamPartitioner 是 Flink 中的数据流分区抽象接口,决定了在实际运行中的数据流分发模式, 将数据切分交给 Task 计算,每个 Task 负责计算一部分数据流。所有的数据分区器都实现了ChannelSelector 接口,该接口中定义了负载均衡选择行为。
// ChannelSelector 接口定义
public interface ChannelSelector<T extends IOReadablewritable> {
//下游可选 Channel 的数量
void setup (intnumberOfChannels);
//选路方法
int selectChannel (T record);
//是否向下游广播
boolean isBroadcast();
}
在该接口中可以看到,每一个分区器都知道下游通道数量,该通道在一次作业运行中是固定的,除非修改作业的并行度,否则该值不会改变。
目前 Flink 支持 8 88 种分区策略的实现,数据分区体系如下图:
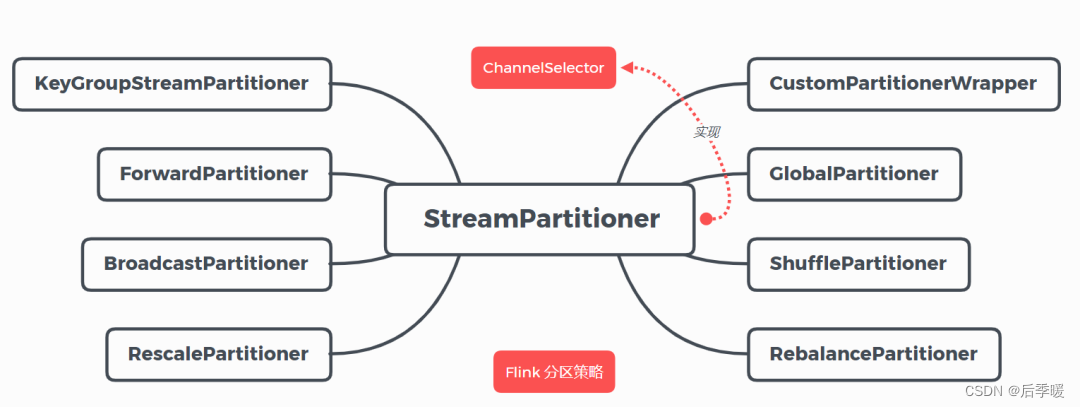
(1)GlobalPartitioner
数据会被分发到下游算子的第一个实例中进行处理。
(2)ForwardPartitioner
在 API 层面上 ForwardPartitioner 应用在 DataStream 上,生成一个新的 DataStream。
该 Partitioner 比较特殊,用于在同一个 OperatorChain 中上下游算子之间的数据转发,实际上数据是直接传递给下游的,要求上下游并行度一样。
(3)ShufflePartitioner
随机的将元素进行分区,可以确保下游的 Task 能够均匀地获得数据,使用代码如下:
dataStream.shuffle();
(4)RebalancePartitioner
以 Round-robin 的方式为每个元素分配分区,确保下游的 Task 可以均匀地获得数据,避免数据倾斜。使用代码如下:
dataStream.rebalance();
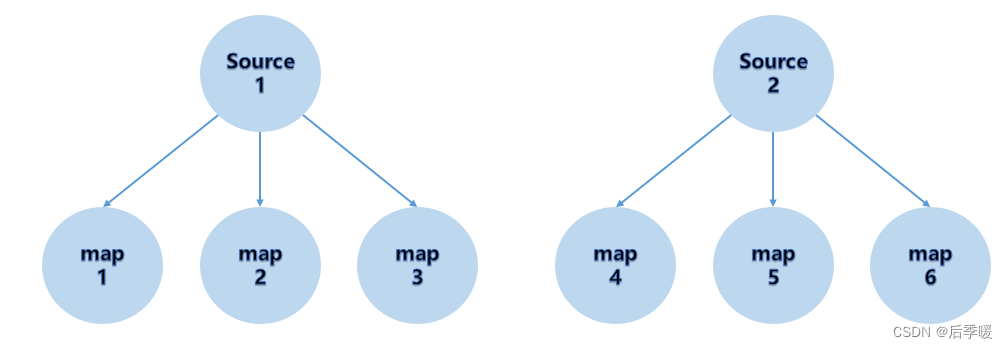
(5)RescalePartitioner
根据上下游 Task 的数量进行分区, 使用 Round-robin 选择下游的一个Task 进行数据分区,如上游有 2 22 个 Source.,下游有 6 66 个 Map,那么每个 Source 会分配 3 33 个固定的下游 Map,不会向未分配给自己的分区写入数据。这一点与 ShufflePartitioner 和 RebalancePartitioner 不同, 后两者会写入下游所有的分区。
运行代码如下:
dataStream.rescale();
(6)BroadcastPartitioner
将该记录广播给所有分区,即有 N NN 个分区,就把数据复制 N NN 份,每个分区 1 11 份,其使用代码如下:
dataStream.broadcast();
(7)KeyGroupStreamPartitioner
在 API 层面上,KeyGroupStreamPartitioner 应用在 KeyedStream上,生成一个新的 KeyedStream。
KeyedStream 根据 keyGroup 索引编号进行分区,会将数据按 Key 的 Hash 值输出到下游算子实例中。该分区器不是提供给用户来用的。
KeyedStream 在构造 Transformation 的时候默认使用 KeyedGroup 分区形式,从而在底层上支持作业 Rescale 功能。
(8)CustomPartitionerWrapper
用户自定义分区器。需要用户自己实现 Partitioner 接口,来定义自己的分区逻辑。
static class CustomPartitioner implements Partitioner<String> {
@Override
public int partition(String key, int numPartitions) {
switch (key){
case "1":
return 1;
case "2":
return 2;
case "3":
return 3;
default:
return 4;
}
}
}
4. 物理分区和key by的区别
顾名思义,“分区”(partitioning)操作就是要将数据进行重新分布,传递到不同的流分区去进行下一步处理。其实应该对分区操作并不陌生,前面介绍聚合算子时,已经提到了keyBy,它就是一种按照键的哈希值来进行重新分区的操作。只不过这种分区操作只能保证把数据按key“分开”,至于分得均不均匀、每个key 的数据具体会分到哪一区去,这些是完全无从控制的——所以有时也说keyBy是一种逻辑分区(logical partitioning)操作。
如果说keyBy这种逻辑分区是一种“软分区”,那真正硬核的分区就应该是所谓的“物理分区”(physical partitioning)。也就是要真正控制分区策略,精准地调配数据,告诉每个数据到底去哪里。其实这种分区方式在一些情况下已经在发生了:例如编写的程序可能对多个处理任务设置了不同的并行度,那么当数据执行的上下游任务并行度变化时,数据就不应该还在当前分区以直通(forward)方式传输了——因为如果并行度变小,当前分区可能没有下游任务了;而如果并行度变大,所有数据还在原先的分区处理就会导致资源的浪费。所以这种情况下,系统会自动地将数据均匀地发往下游所有的并行任务,保证各个分区的负载均衡。
有些时候,还需要手动控制数据分区分配策略。比如当发生数据倾斜的时候,系统无法自动调整,这时就需要重新进行负载均衡,将数据流较为平均地发送到下游任务操作分区中去。Flink 对于经过转换操作之后的DataStream,提供了一系列的底层操作接口,能够帮实现数据流的手动重分区。为了同keyBy相区别,把这些操作统称为“物理分区”操作。物理分区与keyBy另一大区别在于,keyBy之后得到的是一个KeyedStream,而物理分区之后结果仍是DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式。
常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast),下边分别来做了解
1.随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用DataStream的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区,因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同
经过随机分区之后,得到的依然是一个DataStream
可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为4,中间经历一次shuffle。执行多次,观察结果是否相同。
package com.kunan.StreamAPI.Transform;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class TransformPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素中读取数据
DataStreamSource<Event> Stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 1500L),
new Event("Alice", "./prod?id=100", 1800L),
new Event("Bob", "./prod?id=1", 2000L),
new Event("Alice", "./prod?id=200", 3000L),
new Event("Bob", "./home", 2500L),
new Event("Bob", "./prod?id=120", 3600L),
new Event("Bob", "./prod?id=130", 4000L)
);
//1、随机分区
Stream.shuffle().print().setParallelism(4);
env.execute();
}
}2.轮询分区(Round-Robin)
轮询也是一种常见的重分区方式。简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用DataStream的.rebalance()方法,就可以实现轮询重分区。rebalance使用的是Round-Robin负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
注:Round-Robin算法用在了很多地方,例如Kafka 和Nginx。
package com.kunan.StreamAPI.Transform;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class TransformPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素中读取数据
DataStreamSource<Event> Stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 1500L),
new Event("Alice", "./prod?id=100", 1800L),
new Event("Bob", "./prod?id=1", 2000L),
new Event("Alice", "./prod?id=200", 3000L),
new Event("Bob", "./home", 2500L),
new Event("Bob", "./prod?id=120", 3600L),
new Event("Bob", "./prod?id=130", 4000L)
);
//2、轮询分区
Stream.rebalance().print().setParallelism(4);
Stream.print().setParallelism(4); //输出和rebalance一致。Flink底层默认就是 rebalance 分区
env.execute();
}
}
3.重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用rescale()方法时,其实底层也是使用Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中,也就是说,“发牌人”如果有多个,那么rebalance的方式是每个发牌人都面向所有人发牌;而rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
当下游任务(数据接收方)的数量是上游任务(数据发送方)数量的整数倍时,rescale的效率明显会更高。比如当上游任务数量是2,下游任务数量是6 时,上游任务其中一个分区的数据就将会平均分配到下游任务的3 个分区中。
由于rebalance是所有分区数据的“重新平衡”,当TaskManager数据量较多时,这种跨节点的网络传输必然影响效率;而如果配置的taskslot数量合适,用rescale的方式进行“局部重缩放”,就可以让数据只在当前TaskManager的多个slot之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看,rebalance和rescale的根本区别在于任务之间的连接机制不同。rebalance将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源。
可以在代码中测试如下:
package com.kunan.StreamAPI.Transform;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class TransformPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素中读取数据
DataStreamSource<Event> Stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 1500L),
new Event("Alice", "./prod?id=100", 1800L),
new Event("Bob", "./prod?id=1", 2000L),
new Event("Alice", "./prod?id=200", 3000L),
new Event("Bob", "./home", 2500L),
new Event("Bob", "./prod?id=120", 3600L),
new Event("Bob", "./prod?id=130", 4000L)
);
//3、rescale重缩放分区
//这里使用了并行数据源的富函数版本
//这样可以调用getRuntimeContext方法来获取运行时上下文的一些信息
env.addSource(new RichParallelSourceFunction<Integer>() {
@Override
public void run(SourceContext<Integer> ctx) throws Exception {
for (int i = 0; i < 8; i++) {
//将奇偶数发送到0号和1号并行分区
if(i % 2 == getRuntimeContext().getIndexOfThisSubtask())
ctx.collect(i);
}
}
@Override
public void cancel() {
}
}).setParallelism(2);
// .rescale().print().setParallelism(4);
env.execute();
}
}
4.广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用DataStream的broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
package com.kunan.StreamAPI.Transform;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class TransformPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素中读取数据
DataStreamSource<Event> Stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 1500L),
new Event("Alice", "./prod?id=100", 1800L),
new Event("Bob", "./prod?id=1", 2000L),
new Event("Alice", "./prod?id=200", 3000L),
new Event("Bob", "./home", 2500L),
new Event("Bob", "./prod?id=120", 3600L),
new Event("Bob", "./prod?id=130", 4000L)
);
//4、广播
Stream.broadcast().print().setParallelism(4);
env.execute();
}
}
数据被复制然后广播到了下游的所有并行任务中去了.
5.全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
Stream.global().print().setParallelism(4);
6.自定义分区(Custom)
当Flink提供的所有分区策略都不能满足用户的需求时,可以通过使用partitionCustom()方法来自定义分区策略。
在调用时,方法需要传入两个参数,第一个是自定义分区器(Partitioner)对象,第二个是应用分区器的字段,它的指定方式与keyBy指定 key 基本一样:可以通过字段名称指定,也可以通过字段位置索引来指定,还可以实现一个KeySelector。
例如,可以对一组自然数按照奇偶性进行重分区。代码如下:
package com.kunan.StreamAPI.Transform;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
public class TransformPartitionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//从元素中读取数据
DataStreamSource<Event> Stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 1500L),
new Event("Alice", "./prod?id=100", 1800L),
new Event("Bob", "./prod?id=1", 2000L),
new Event("Alice", "./prod?id=200", 3000L),
new Event("Bob", "./home", 2500L),
new Event("Bob", "./prod?id=120", 3600L),
new Event("Bob", "./prod?id=130", 4000L)
);
//6、自定义分区
//将自然数按照奇偶分区
env.fromElements(1,2,3,4,5,6,7,8).partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) {
return key % 2;
}
}, new KeySelector<Integer, Integer>() {
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
}).print().setParallelism(4);
env.execute();
}
}
5.说说 Flink 窗口,以及划分机制。
窗口概念:将无界流的数据,按时间区间,划分成多份数据,分别进行统计(聚合)。
Flink 支持两种划分窗口的方式(time 和 count)。第一种,按 时间驱动 进行划分、另一种按 数据驱动 进行划分。
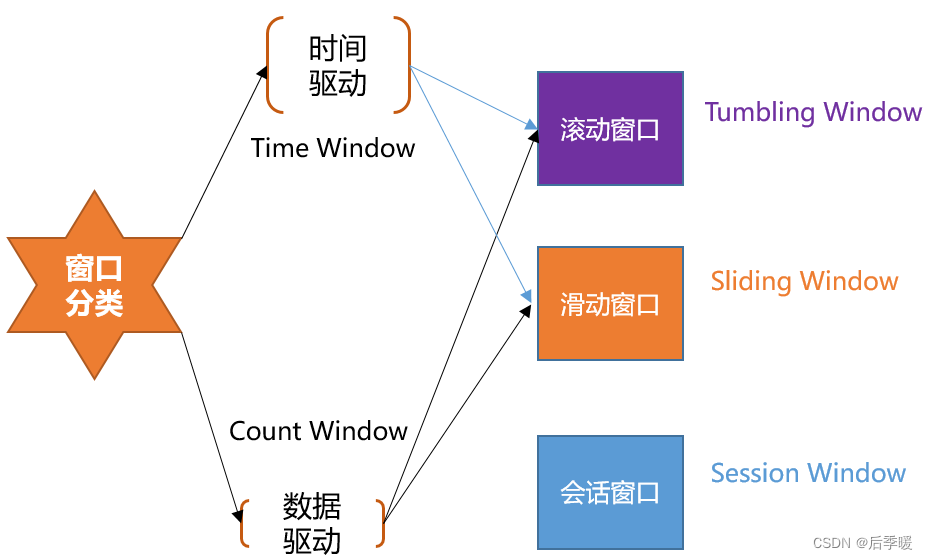
- 按时间驱动 Time Window 可以划分为 滚动窗口 Tumbling Window 和 滑动窗口 Sliding Window。
- 按数据驱动 Count Window 也可以划分为 滚动窗口 Tumbling Window 和 滑动窗口 Sliding Window。
-
Flink 支持窗口的两个重要属性(窗口长度
size和 滑动间隔interval),通过窗口长度和滑动间隔来区分滚动窗口和滑动窗口。 如果 size = interval,那么就会形成 tumbling-window(无重叠数据)——滚动窗口。如果 size(1min)> interval(30s),那么就会形成 sliding-window(有重叠数据)——滑动窗口
通过组合可以得出四种基本窗口:
(1)基于时间的滚动窗口:time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))。
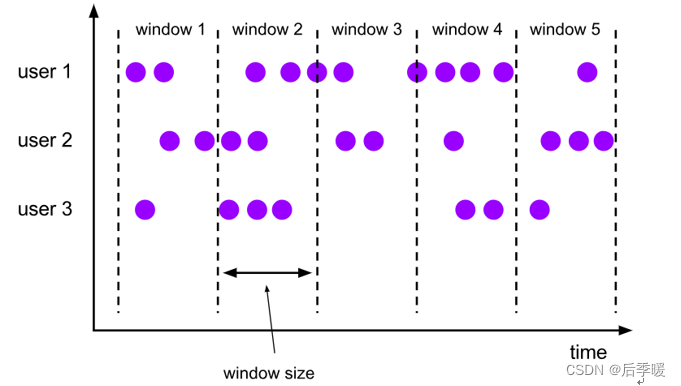
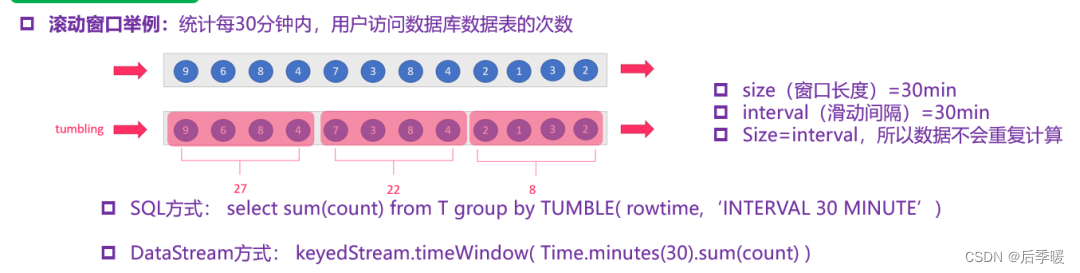
(2)基于时间的滑动窗口:time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(10), Time.seconds(5))。
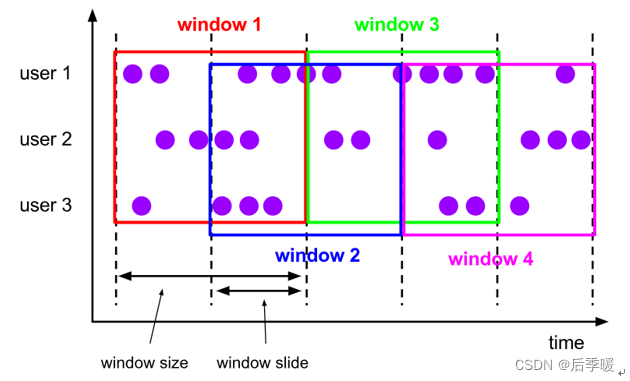
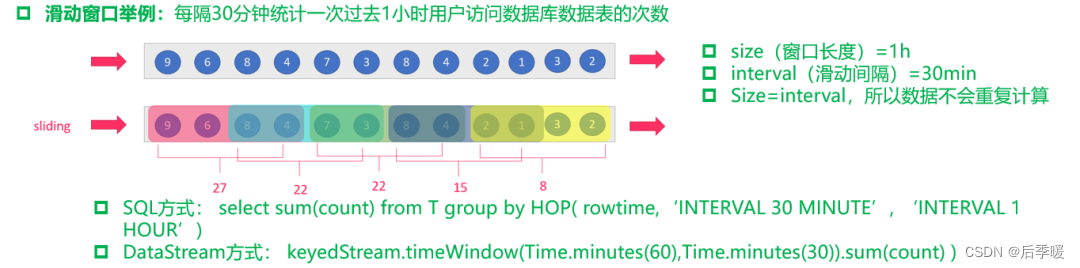
注:上图中有点小错误,应该是 size > interval,所以会有重叠数据。
(3)基于数量的滚动窗口:count-tumbling-window 无重叠数据的数量窗口,设置方式举例:countWindow(5)。
 (4)基于数量的滑动窗口:
(4)基于数量的滑动窗口:count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(10,5)。
Flink 中还支持一个特殊的窗口:会话窗口 SessionWindows。
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况。
session 窗口在一个固定的时间周期内不再收到元素,即非活动间隔产生,那么这个窗口就会关闭。
一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去,如下图所示:

6. 怎么处理延迟数据?
大数据面试题:Flink延迟数据是怎么解决的_大数据中数据延迟-CSDN博客
7. Flink 状态包括哪些?
(1) 按照由 用户管理 还是 Flink 管理,状态可以分为 原始状态 和 托管状态。
- 原始状态(
Raw State):由用户自行进行管理。 - 托管状态(
Managed State):由 Flink 自行进行管理的 State。
两者区别:
- 从状态管理方式来说,Managed State 由 Flink Runtime 管理,自动存储,自动恢复,在内存管理上有优化;而 Raw State 需要用户自己管理,需要自己序列化,Flink 不知道 State 中存入的数据是什么结构,只有用户自己知道,需要最终序列化为可存储的数据结构。
- 从状态数据结构来说,Managed State 支持已知的数据结构,如 Value、List、Map 等。而 Raw State 只支持字节数组,所有状态都要转换为二进制字节数组才可以。
- 从推荐使用场景来说,Managed State 大多数情况下均可使用,而 Raw State 是当 Managed State 不够用时,比如需要自定义 Operator 时,才会使用 Raw State。在实际生产过程中,只推荐使用 Managed State。
开启状态示例:
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
public class MyMapper extends RichMapFunction<String, Integer> {
private transient ValueState<Integer> state;
@Override
public void open(Configuration config) {
// 初始化状态
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>("myState", Integer.class);
state = getRuntimeContext().getState(descriptor);
}
@Override
public Integer map(String value) throws Exception {
// 读取状态
Integer currentState = state.value();
// 更新状态
state.update(currentState + 1);
// 返回结果
return currentState;
}
}
(2)State 按照 是否有 key 划分为 KeyedState 和 OperatorState 两种。

这里面键控不做详细介绍,较简单,主要介绍算子状态:
某种意义上说,算子状态是更底层的状态类型,因为它只针对当前算子并行任务有效,不需要考虑不同key的隔离。算子状态功能不如按键分区状态丰富,应用场景较少,它的调用方法也会有一些区别。
一、基本概念和特点
算子状态(OperatorState)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的key无关,所以不同key的数据只 要被分发到同一个并行子任务,就会访问到同一个OperatorState。
算子状态的实际应用场景不如KeyedState多,一般用在Source或Sink等与外部系统连接的算子上,或者完全没有key定义的场景。比如Flink的Kafka连接器中,就用到了算子状态。在我们给Source算子设置并行度后,Kafka消费者的每一个并行实例,都会为对应的主题(topic)分区维护一个偏移量,作为算子状态保存起来。这在保证Flink应用“精确一次”(exactly-once)状态一致性时非常有用。关于状态一致性的内容,会在后续详细展开。
算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间做重组分配。根据状态的类型不同,重组分配的方案也会不同。
二、 状态类型
算子状态也支持不同的结构类型,主要有三种:ListState、UnionListState和BroadcastState。
1.列表状态(ListState)
与KeyedState中的ListState一样,将状态表示为一组数据的列表。
与KeyedState中的列表状态的区别是:在算子状态的上下文中,不会按键(key)分别处理状态,所以每一个并行子任务上只会保留一个“列表”(list),也就是当前并行子任务上所有状态项的集合。列表中的状态项就是可以重新分配的最细粒度,彼此之间完全独立。
当算子并行度进行缩放调整时,算子的列表状态中的所有元素项会被统一收集起来,相当于把多个分区的列表合并成了一个“大列表”,然后再均匀地分配给所有并行任务。这种“均匀分配”的具体方法就是“轮询”(round-robin),与之前介绍的rebanlance数据传输方式类似,是通过逐一“发牌”的方式将状态项平均分配的。这种方式也叫作“平均分割重组”(even-splitredistribution)。
算子状态中不会存在“键组”(keygroup)这样的结构,所以为了方便重组分配,就把它直接定义成了“列表”(list)。这也就解释了,为什么算子状态中没有最简单的值状态(ValueState)。
2.联合列表状态(UnionListState)
与ListState类似,联合列表状态也会将状态表示为一个列表。它与常规列表状态的区别在于,算子并行度进行缩放调整时对于状态的分配方式不同。
UnionListState的重点就在于“联合”(union)。在并行度调整时,常规列表状态是轮询分配状态项,而联合列表状态的算子则会直接广播状态的完整列表。这样,并行度缩放之后的并行子任务就获取到了联合后完整的“大列表”,可以自行选择要使用的状态项和要丢弃的状态项。这种分配也叫作“联合重组”(unionredistribution)。如果列表中状态项数量太多,为资源和效率考虑一般不建议使用联合重组的方式。
3.广播状态(BroadcastState)
有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
因为广播状态在每个并行子任务上的实例都一样,所以在并行度调整的时候就比较简单,只要复制一份到新的并行任务就可以实现扩展;而对于并行度缩小的情况,可以将多余的并行子任务连同状态直接砍掉——因为状态都是复制出来的,并不会丢失。
在底层,广播状态是以类似映射结构(map)的键值对(key-value)来保存的,必须基于一个“广播流”(BroadcastStream)来创建。关于广播流,在“广播连接流”的讲解中已经做过介绍,稍后还会做一个总结。
三、代码实现
我们已经知道,状态从本质上来说就是算子并行子任务实例上的一个特殊本地变量。它的特殊之处就在于Flink会提供完整的管理机制,来保证它的持久化保存,以便发生故障时进行状态恢复;另外还可以针对不同的key保存独立的状态实例。按键分区状态(KeyedState)对这两个功能都要考虑;而算子状态(OperatorState)并不考虑key的影响,所以主要任务就是要让Flink了解状态的信息、将状态数据持久化后保存到外部存储空间。
看起来算子状态的使用应该更加简单才对。不过仔细思考又会发现一个问题:我们对状态进行持久化保存的目的是为了故障恢复;在发生故障、重启应用后,数据还会被发往之前分配的分区吗?显然不是,因为并行度可能发生了调整,不论是按键(key)的哈希值分区,还是直接轮询(round-robin)分区,数据分配到的分区都会发生变化。这很好理解,当打牌的人数从3个增加到4个时,即使牌的次序不变,轮流发到每个人手里的牌也会不同。数据分区发生变化,带来的问题就是,怎么保证原先的状态跟故障恢复后数据的对应关系呢?
对于KeyedState这个问题很好解决:状态都是跟key相关的,而相同key的数据不管发往哪个分区,总是会全部进入一个分区的;于是只要将状态也按照key的哈希值计算出对应的分区,进行重组分配就可以了。恢复状态后继续处理数据,就总能按照key找到对应之前的状态,就保证了结果的一致性。所以Flink对KeyedState进行了非常完善的包装,我们不需实现任何接口就可以直接使用。
而对于OperatorState来说就会有所不同。因为不存在key,所有数据发往哪个分区是不可预测的;也就是说,当发生故障重启之后,我们不能保证某个数据跟之前一样,进入到同一个并行子任务、访问同一个状态。所以Flink无法直接判断该怎样保存和恢复状态,而是提供了接口,让我们根据业务需求自行设计状态的快照保存(snapshot)和恢复(restore)逻辑。
1. CheckpointedFunction 接口
在Flink中,对状态进行持久化保存的快照机制叫作“检查点”(Checkpoint)。于是使用算子状态时,就需要对检查点的相关操作进行定义,实现一个CheckpointedFunction接口。
CheckpointedFunction 接口在源码中定义如下:
public interface CheckpointedFunction {
// 保存状态快照到检查点时,调用这个方法
void snapshotState(FunctionSnapshotContext context) throws Exception
// 初始化状态时调用这个方法,也会在恢复状态时调用
void initializeState(FunctionInitializationContext context) throws
Exception;
}
每次应用保存检查点做快照时,都会调用.snapshotState()方法,将状态进行外部持久化。而在算子任务进行初始化时,会调用.initializeState()方法。这又有两种情况:一种是整个应用第一次运行,这时状态会被初始化为一个默认值(defaultvalue);另一种是应用重启时,从检查点(checkpoint)或者保存点(savepoint)中读取之前状态的快照,并赋给本地状态。所以,接口中的.snapshotState()方法定义了检查点的快照保存逻辑,而.initializeState()方法不仅定义了初始化逻辑,也定义了恢复逻辑。
这里需要注意,CheckpointedFunction接口中的两个方法,分别传入了一个上下文(context)作为参数。不同的是,.snapshotState()方法拿到的是快照的上下文FunctionSnapshotContext,它可以提供检查点的相关信息,不过无法获取状态句柄;而.initializeState()方法拿到的是FunctionInitializationContext,这是函数类进行初始化时的上下文,是真正的“运行时上下文”。FunctionInitializationContext中提供了“算子状态存储”(OperatorStateStore)和“按键分区状态存储(”KeyedStateStore),在这两个存储对象中可以非常方便地获取当前任务实例中的OperatorState和KeyedState。例如:
ListStateDescriptor<String> descriptor =
new ListStateDescriptor<>(
"buffered-elements",
Types.of(String));
ListState<String> checkpointedState =
context.getOperatorStateStore().getListState(descriptor);
我们看到,算子状态的注册和使用跟KeyedState非常类似,也是需要先定义一个状态描述器(StateDescriptor),告诉Flink当前状态的名称和类型,然后从上下文提供的算子状态存储(OperatorStateStore)中获取对应的状态对象。如果想要从KeyedStateStore中获取KeyedState也是一样的,前提是必须基于定义了key的KeyedStream,这和富函数类中的方式并不矛盾。通过这里的描述可以发现,CheckpointedFunction是Flink中非常底层的接口,它为有状态的流处理提供了灵活且丰富的应用。
- 示例代码
接下来举一个算子状态的应用案例。在下面的例子中,自定义的SinkFunction会在CheckpointedFunction中进行数据缓存,然后统一发送到下游。这个例子演示了列表状态的平均分割重组(event-splitredistribution)。
package com.kunan.StreamAPI.FlinkStat;
import com.kunan.StreamAPI.Source.ClickSource;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
public class BufferingSinkExp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// env.enableCheckpointing(1000L);
// env.setStateBackend(new EmbeddedRocksDBStateBackend());
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
stream.print("数据输入: ");
//批量缓存输出
stream.addSink(new BufferingSink(10));
env.execute();
}
//自定义实现SinkFunction
public static class BufferingSink implements SinkFunction<Event>, CheckpointedFunction{
//定义当前类的属性。批量
private final int threshold;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
private List<Event> bufferedElements;
//定义一个算子状态
private ListState<Event> checkPointedState;
@Override
public void invoke(Event value, Context context) throws Exception {
bufferedElements.add(value);//缓存到列表
//判断如果达到阈值 就批量写入
if (bufferedElements.size() == threshold){
//用打印到控制台模拟写入到外部系统
for (Event element: bufferedElements){
System.out.println(element);
}
System.out.println("=======输出完毕========");
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
//清空状态
checkPointedState.clear();
//对状态进行持久化,复制缓存的列表到列表状态
for (Event element:bufferedElements)
checkPointedState.add(element);
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
//定义算子状态
ListStateDescriptor<Event> eventListStateDescriptor = new ListStateDescriptor<>("buffered-elements", Event.class);
checkPointedState = context.getOperatorStateStore().getListState(eventListStateDescriptor);
//如果从故障恢复,需要将ListState中的所有元素复制到列表中
if (context.isRestored()){
for (Event element:checkPointedState.get())
bufferedElements.add(element);
}
}
}
}
当初始化好状态对象后,可以通过调用.isRestored()方法判断是否是从故障中恢复。在代码中BufferingSink初始化时,恢复出的ListState的所有元素会添加到一个局部变量bufferedElements中,以后进行检查点快照时就可以直接使用了。在调用.snapshotState()时,直接清空ListState,然后把当前局部变量中的所有元素写入到检查点中。
对于不同类型的算子状态,需要调用不同的获取状态对象的接口,对应地也就会使用不同的状态分配重组算法。比如获取列表状态时,调用.getListState()会使用最简单的平均分割重组(even-splitredistribution)算法;而获取联合列表状态时,调用的是.getUnionListState(),对应就会使用联合重组(unionredistribution)算法。
8. 谈谈广播状态?
Broadcast State 是 Flink 1.5 引入的新特性。
广播状态可以用来解决如下问题:
一条流需要根据规则或配置处理数据,而规则或配置又是随时变化的。此时,就可将规则或配置作为广播流广播出去,并以Broadcast State的形式存储在下游Task中。下游Task根据Broadcast State中的规则或配置来处理常规流中的数据。
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.BroadcastStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastreams.BroadcastStream;
import org.apache.flink.streaming.api.datastreams.DataStream;
import org.apache.flink.util.Collector;
public class BroadcastExample {
public static void main(String[] args) throws Exception {
// 创建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建数据源
DataStream<Tuple2<String, String>> broadcastStream = env.fromElements(
Tuple2.of("config1", "value1"),
Tuple2.of("config2", "value2")
);
DataStream<Tuple3<String, String, String>> inputStream = env.fromElements(
Tuple3.of("key1", "subKey1", "message1"),
Tuple3.of("key2", "subKey2", "message2")
);
// 将广播数据转换成BroadcastStream
BroadcastStream<Tuple2<String, String>> broadcastBroadcastStream = broadcastStream.broadcast(new BroadcastStateDescriptor<>(DataType.VOID_TYPE_INFO, DataType.VOID_TYPE_INFO));
// 应用广播数据
DataStream<Tuple3<String, String, String>> outputStream = inputStream
.connect(broadcastBroadcastStream)
.process(new BroadcastProcessFunction(), TypeInformation.of(Tuple3.class));
// 执行程序
outputStream.print();
env.execute("Broadcast Example");
}
public static class BroadcastProcessFunction extends RichMapFunction<Tuple3<String, String, String>, Tuple3<String, String, String>> {
private BroadcastState<String, String> broadcastState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 初始化广播状态
broadcastState = getRuntimeContext().getBroadcastState(new BroadcastStateDescriptor<>(String.class, String.class));
}
@Override
public Tuple3<String, String, String> map(Tuple3<String, String, String> value) throws Exception {
for (Map.Entry<String, String> entry : broadcastState.immutableEntries()) {
// 使用广播状态的逻辑处理输入值
// ...
}
return value;
}
}
}示例2:
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.api.java.tuple.Tuple6;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* Desc
* 需求:
* 使用Flink的BroadcastState来完成
* 事件流和配置流(需要广播为State)的关联,并实现配置的动态更新!
*/
public class UserInfo {
public static void main(String[] args) throws Exception {
//1,获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2,读取数据源
//数据源1的格式:
//{"userID": "user_3", "eventTime": "2019-08-17 12:19:47", "eventType": "browse", "productID": 1}
//{"userID": "user_2", "eventTime": "2019-08-17 12:19:48", "eventType": "click", "productID": 1}
DataStreamSource<Tuple4<String, String, String, Integer>> eventDS = env.addSource(new MySource());
//数据源2的格式:在mysql中
/**
DROP TABLE IF EXISTS `user_info`;
CREATE TABLE `user_info` (
`userID` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`userName` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`userAge` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`userID`) USING BTREE
) ENGINE = MyISAM CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user_info
-- ----------------------------
INSERT INTO `user_info` VALUES ('user_1', '张三', 10);
INSERT INTO `user_info` VALUES ('user_2', '李四', 20);
INSERT INTO `user_info` VALUES ('user_3', '王五', 30);
INSERT INTO `user_info` VALUES ('user_4', '赵六', 40);
SET FOREIGN_KEY_CHECKS = 1;
*/
DataStreamSource<Map<String, Tuple2<String, Integer>>> configDS = env.addSource(new MySQLSource());
//3,数据转换
//3.1 广播配置表流
MapStateDescriptor<Void, Map<String, Tuple2<String,Integer>>> mapStateDescriptor = new MapStateDescriptor<>("config", Types.VOID, Types.MAP(Types.STRING, Types.TUPLE(Types.STRING, Types.INT)));
BroadcastStream<Map<String, Tuple2<String, Integer>>> broadcastDS = configDS.broadcast(mapStateDescriptor);
//3.2 连接广播流
BroadcastConnectedStream<Tuple4<String, String, String, Integer>, Map<String, Tuple2<String, Integer>>> connectDS = eventDS.connect(broadcastDS);
//3.3 补全主流用户信息
SingleOutputStreamOperator<Tuple6<String, String, String, Integer, String, Integer>> result = connectDS.process(new MyProcessFunction(mapStateDescriptor));
//4,执行
result.print();
env.execute();
}
private static class MySource implements SourceFunction<Tuple4<String, String, String, Integer>> {
private boolean isRunning = true;
@Override
public void run(SourceContext<Tuple4<String, String, String, Integer>> ctx) throws Exception {
Random random = new Random();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
while(isRunning){
int id = random.nextInt(4) + 1;
String userId = "user_" + id;
String eventTime = df.format(new Date());
String eventType = "type_" + random.nextInt(3);
int productId = random.nextInt(4);
ctx.collect(Tuple4.of(userId,eventTime,eventType,productId));
Thread.sleep(500);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
private static class MySQLSource extends RichSourceFunction<Map<String, Tuple2<String, Integer>>> {
private Connection conn = null;
private PreparedStatement ps = null;
private boolean flag = true;
private ResultSet rs = null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//连接数据库
Class.forName("com.mysql.cj.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC", "root", "123456");
String sql = "select `userID`, `userName`, `userAge` from `user_info`";
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<Map<String, Tuple2<String, Integer>>> ctx) throws Exception {
while (flag) {
Map<String, Tuple2<String, Integer>> map = new HashMap<>();
rs = ps.executeQuery();
while (rs.next()) {
String userID = rs.getString("userID");
String userName = rs.getString("userName");
int userAge = rs.getInt("userAge");
map.put(userID, Tuple2.of(userName, userAge));
}
ctx.collect(map);
Thread.sleep(5000);//每隔5s更新一下用户的配置信息!
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
if(conn != null) conn.close();
if(ps != null) ps.close();
if(rs != null) rs.close();
}
}
private static class MyProcessFunction extends BroadcastProcessFunction<Tuple4<String, String, String, Integer>,Map<String, Tuple2<String, Integer>>, Tuple6<String, String, String, Integer, String, Integer>> {
MapStateDescriptor<Void, Map<String, Tuple2<String,Integer>>> mapStateDescriptor;
public MyProcessFunction() {
}
public MyProcessFunction( MapStateDescriptor<Void, Map<String, Tuple2<String,Integer>>> mapStateDescriptor) {
this.mapStateDescriptor = mapStateDescriptor;
}
@Override
public void processElement(Tuple4<String, String, String, Integer> value, ReadOnlyContext ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
String userId = value.f0;
ReadOnlyBroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(mapStateDescriptor);
if(broadcastState != null){
Map<String, Tuple2<String, Integer>> map = broadcastState.get(null);
if(map != null) {
Tuple2<String, Integer> userInfo = map.get(userId);
String userName = userInfo.f0;
Integer userAge = userInfo.f1;
out.collect(Tuple6.of(userId, value.f1, value.f2, value.f3, userName, userAge));
}
}
}
@Override
public void processBroadcastElement(Map<String, Tuple2<String, Integer>> value, Context ctx, Collector<Tuple6<String, String, String, Integer, String, Integer>> out) throws Exception {
BroadcastState<Void, Map<String, Tuple2<String, Integer>>> broadcastState = ctx.getBroadcastState(mapStateDescriptor);
broadcastState.clear();
broadcastState.put(null,value);
}
}
}
















 4281
4281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











