






k近邻算法是一种最简单最经典的机器学习算法之一。该算法的原理为:当对测试样本进行分类时,首先通过扫描训练样本集,找到与该测试样本最相似的k个训练样本,根据这个样本的类别进行投票确定测试样本的类别。也可以通过个样本与测试样本的相似程度进行加权投票。如果需要以测试样本对应每类的概率的形式输出,可以通过个样本中不同类别的样本数量分布来进行估计。
以下通过一个例子了解k近邻算法。
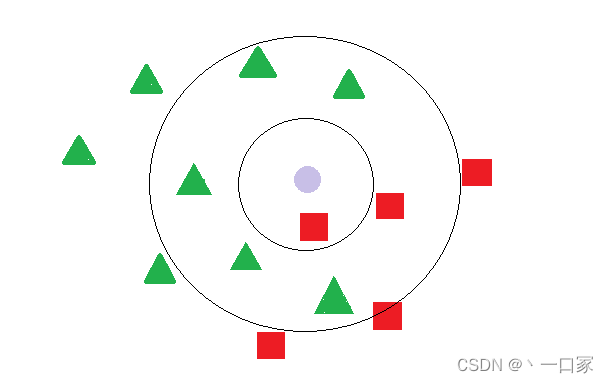
利用k近邻算法确认紫圆为哪个类别。若k=1,则找到离图中紫圆最近的1个样本,这个样本为红色正方形,故紫圆属于红色正方形类别;若k=7,则找到离紫圆最近的7个样本,这7个样本中有5个绿色三角形和两个红色正方形,其中类数三角形数量比红色正方形多,故紫圆属于绿色三角形。由以上例子可知k近邻算法对样本的分类及其依赖于k的取值。
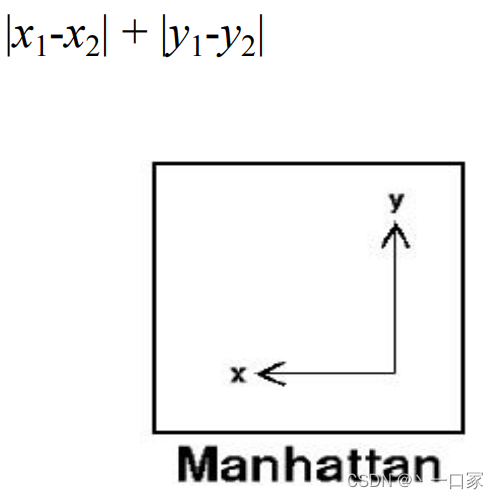
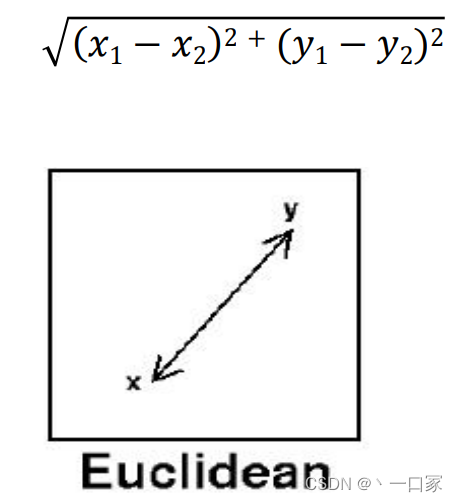
当然k近邻算法对距离的计算方式有多种,其中以Manhattan 距离与Euclidean 距离为主。
我们一般采用Euclidean 距离。
在上述介绍中我们得知k近邻算法对样本的分类及其依赖于k的取值。k值不可取过大或过小。
- k值越大,模型的偏差越大,对噪声数据越不敏感,当k值很大时,可能造成欠拟合;
- k值越小,模型的方差就会越大,当k值太小,就会造成过拟合。
以下为k值取值过大或过小时的例子。
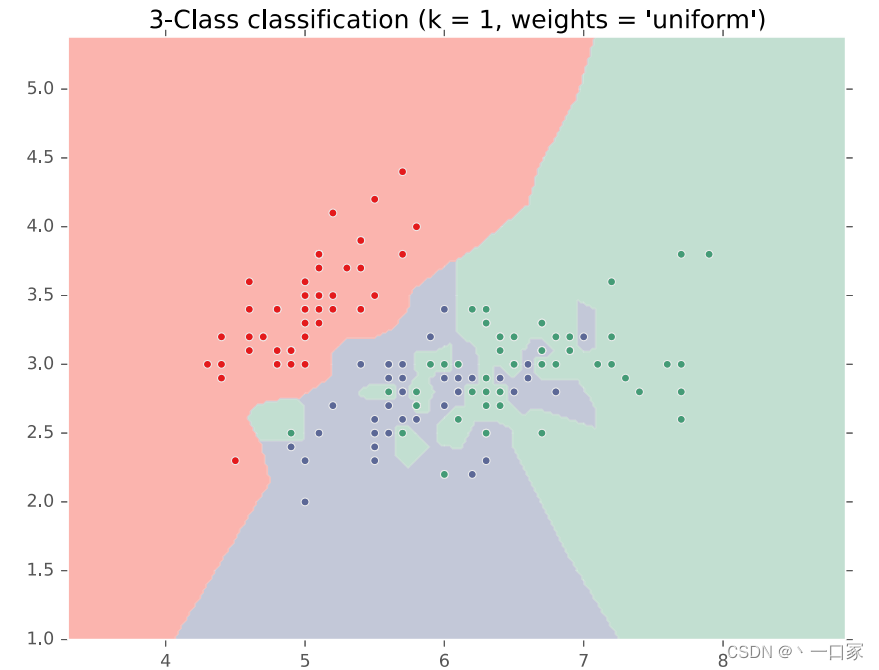
如图当k=1时在图中紫色图层中夹杂了参差不齐的绿色图层,该训练结果并非很好的划分了红绿紫三个区域,造成了过拟合现象。
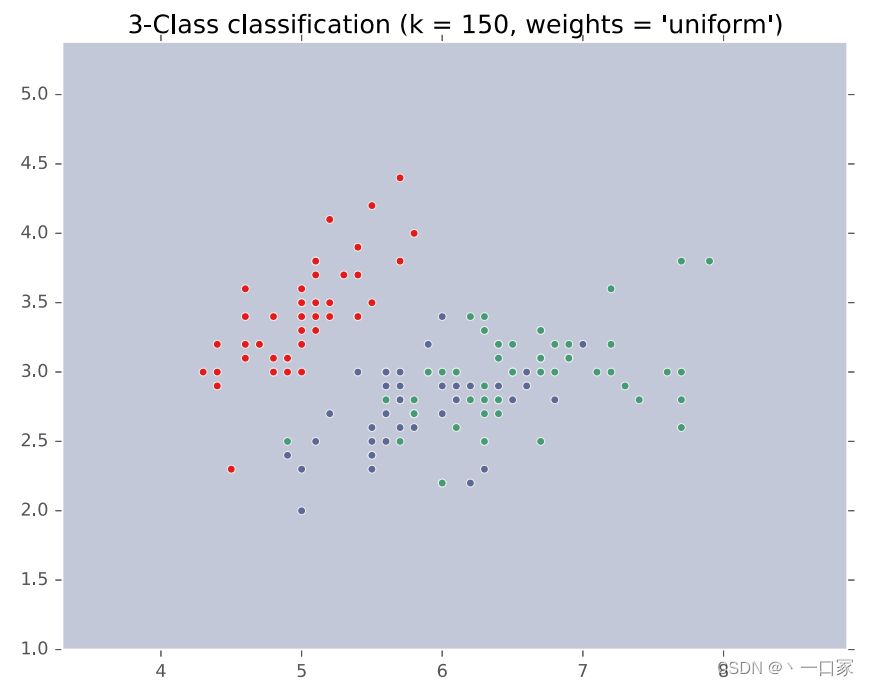
如图当k=150时由于无论取图上哪个点都是紫色点投票最多,故该点必被分类为紫色一类,造成了欠拟合现象。
因此k的取值因满足以下两个条件:
1.近邻点要有相同/相近的类别
2.特征维度的尺度(范围)要具备一致性
接下来看一例子:

如上图,若我们用传统的Euclidean 距离作为k近邻算法判断距离的标准,我们会惊讶的发现每年获得的飞行常客里程数将占到距离的绝大部分比重,也就是说样本的分类基本上只与每年获得的飞行常客里程数相关联了。所以我们要进行数值归一化的处理,使得上图中三个特征的权重相等。
数据归一化的处理方法有很多种,比如0-1标准化、Z-score标准化、Sigmoid压缩法等等,在这里我们使用最简单的0-1标准化,公式如下:
![]()
接下来调用鸢尾花Iris数据集,利用k近邻算法训练该数据集并评估模型准确率。
1.鸢尾花Iris数据集介绍
· Iris (/ˈaɪrɪs/) 数据集是机器学习任务中常用的分类实验数据集,由Fisher在1936年整理。
· Iris :Anderson’s Iris data set, 中文名称:安德森鸢尾花数据集
· Iris 数据集一共包含150个样本,分3类,每类50个数据,每个数据包含4个特征。4个特征分别为: Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度),特征值都为正浮点数,单位为厘米。根据4个特征预测鸢尾花属于 Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾)
数据集结构与数据大致如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
iris = load_iris()
print(iris) 
其中前部分为特征: Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)后部分为标签:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾)(分别利用0,1,2代替原有标签名)。
2.sklearn中 neighbors.KNeighborsClassifier参数说明
在sklearn库中,KNeighborsClassifier是实现K近邻算法的一个类,一般都使用欧式距离进行测量。
KNeighborsClassifier(n_neighbors=5,weights=’uniform’,algorithm=’auto’,leaf_size=30,p=2,metric=’minkowski’,metric_params=None,n_jobs=1,**kwargs)
n_neighbors: int, 可选参数(默认为 5)用于kneighbors查询的默认邻居的数量;
weights(权重): str or callable(自定义类型), 可选参数(默认为 ‘uniform’)用于预测的权重函数;
algorithm(算法): {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, 可选参数(默认为 ‘auto’)计算最近邻居用的算法;
leaf_size(叶子数量): int, 可选参数(默认为 30),传入BallTree或者KDTree算法的叶子数量;
p: integer, 可选参数(默认为 2)用于Minkowski metric(闵可夫斯基空间)的超参数。p = 1, 相当于使用曼哈顿距离 (l1),p = 2, 相当于使用欧几里得距离(l2);
metric(矩阵): string or callable, 默认为 ‘minkowski’用于树的距离矩阵。默认为闵可夫斯基空间,如果和p=2一块使用相当于使用标准欧几里得矩阵;
metric_params(矩阵参数): dict, 可选参数(默认为 None),给矩阵方法使用的其他的关键词参数;
n_jobs: int, 可选参数(默认为 1)用于搜索邻居的,可并行运行的任务数量。如果为-1, 任务数量设置为CPU核的数量。不会影响fit方法.
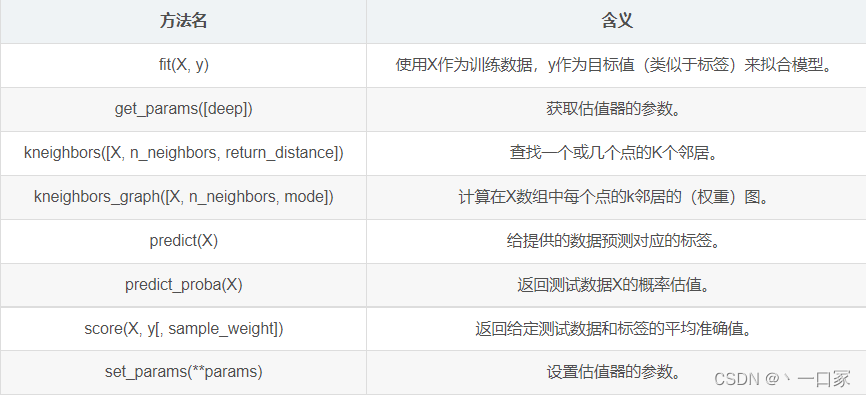
- 方法:
3. 编写代码,实现对iris数据集的k近邻算法分类及预测
一:引入库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np二:加载数据集,定义区分特征与标记
iris = load_iris()
#date为特征数据集
data = iris.get("data")
#target为标记数据集
target = iris.get("target")三:划分测试集与训练集
#划分测试集占20%
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0)四:定义k值
#定义k值
KNN = KNeighborsClassifier(n_neighbors=5)五:评价模型的准确率
test_score = KNN.score(x_test, y_test)
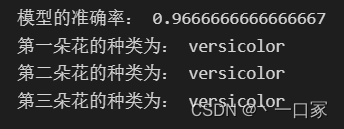
print("模型的准确率:", test_score)
六:使用模型预测未知种类样本
#定义三个测试数据
X1 = np.array([[1.9, 2.8, 4.7, 1.1], [5.8, 2.7, 4.1, 1.5], [3.6, 2.5, 3.1, 2.1]])
prediction = KNN.predict(X1)
#根据预测值找出对应花名
a = iris.get("target_names")[prediction]
print("第一朵花的种类为:", a[0])
print("第二朵花的种类为:", a[1])
print("第三朵花的种类为:", a[2])完整代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
if __name__ == '__main__':
iris = load_iris()
#date为特征数据集
data = iris.get("data")
#target为标记数据集
target = iris.get("target")
#划分测试集占20%
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=0)
#定义k值
KNN = KNeighborsClassifier(n_neighbors=5)
KNN.fit(x_train, y_train)
train_score = KNN.score(x_train, y_train)
test_score = KNN.score(x_test, y_test)
print("模型的准确率:", test_score)
#定义三个测试数据
X1 = np.array([[1.9, 2.8, 4.7, 1.1], [5.8, 2.7, 4.1, 1.5], [3.6, 2.5, 3.1, 2.1]])
prediction = KNN.predict(X1)
#根据预测值找出对应花名
a = iris.get("target_names")[prediction]
print("第一朵花的种类为:", a[0])
print("第二朵花的种类为:", a[1])
print("第三朵花的种类为:", a[2])结果
接下来改变k值观察模型准确率。
当k=100时:
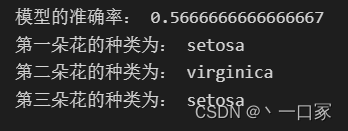
当 k=50时:
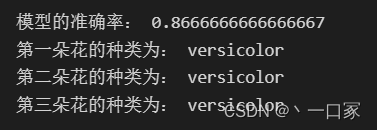
当k=120时:

可以看出当k值越来越高至接近样本总数150时它的准确率越来越低,这吻合了上文介绍的k值过大造成的欠拟合现象。
k近邻算法优缺点
优点:
1. 简单有效
2.重新训练的代价低(没有构建模型)
3.适合类域交叉样本:KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
4.适合大样本自动分类:该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
缺点:
1.惰性学习:KNN算法是懒散学习方法(lazy learning,基本上不学习),一些积极学习的算法要快很多
2.类别评分不是规格化:不像一些通过概率评分的分类
3.输出可解释性不强:例如决策树的输出可解释性就较强
4.对不均衡的样本不擅长:当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
5.计算量较大:目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。

















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









