







1.导包
from sklearn.datasets import make_classification
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
X, y = make_classification(n_features=2, n_redundant=0,
n_informative=2, random_state=1,
n_clusters_per_class=1)
# n_features:特征总数
# n_redundant:冗余特征的数量。
# n_informative:信息特征的数量
# random_state:类似随机种子,复现随机数
# n_clusters_per_class:每个类的集群数
2.定义sigmoid函数
def sigmoid(z):
return 1.0/(1 + np.exp(-z))
#当一个神经元的激活函数是一个 Sigmoid函数时,这个单元的输出保证总是介于0和1之间。由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现
问:那什么时候用softmoid()函数?
答:拥有两个及其以上的输出节点的二分类或者多分类问题一般在输出节点上使用Softmax函数。
3.定义损失函数
def loss(y, y_hat):
loss = -np.mean(y*(np.log(y_hat)) - (1-y)*np.log(1-y_hat))
#mean()函数的功能是求取平均值
return loss 问:为什么使用交叉熵作为损失函数?而不用MSE损失函数?
答:在分类问题中,使用MSE损失函数,采取梯度下降法去学习时,会出现模型一开始训练时,学习速率非常慢的情况
4.定义梯度下降函数
def gradients(X, y, y_hat):
# X -->输入值.
# y -->真实值
# y_hat --> hypothesis/predictions 预测值
# w --> weights (parameter) 权重
# b --> bias (parameter) 偏差
# m-> number of training examples 训练样本数量
m = X.shape[0]
# Gradient of loss w.r.t weights.
dw = (1/m)*np.dot(X.T, (y_hat - y))
# Gradient of loss w.r.t bias.
db = (1/m)*np.sum((y_hat - y))
return dw, db5.定义画图函数(画出分类的边界)
def plot_decision_boundary(X, w, b):
# The Line is y=mx+c
# So, Equate mx+c = w.X + b
# Solving we find m and c
x1 = [min(X[:,0]), max(X[:,0])]
m = -w[0]/w[1]
c = -b/w[1]
x2 = m*x1 + c
# Plotting
fig = plt.figure(figsize=(10,8))
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "g^")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs")
plt.xlim([-2, 2])
plt.ylim([0, 2.2])
plt.xlabel("feature 1")
plt.ylabel("feature 2")
plt.title('Decision Boundary')
plt.plot(x1, x2, 'y-')6.归一化
def normalize(X):
m, n = X.shape
# 归一化
for i in range(n):
X = (X - X.mean(axis=0))/X.std(axis=0)
return X7.封装训练函数
def train(X, y, bs, epochs, lr):
# bs --> Batch Size.
# epochs --> 迭代次数
# lr --> 学习率
m, n = X.shape
# 将权重和偏差初始化为零
w = np.zeros((n,1))
b = 0
# Reshaping y.
y = y.reshape(m,1)
# 归一化
x = normalize(X)
# 创建一个空列表去存储losses
losses = []
for epoch in range(epochs):
for i in range((m-1)//bs + 1):
# Defining batches. SGD.
start_i = i*bs
end_i = start_i + bs
xb = X[start_i:end_i]
yb = y[start_i:end_i]
# 计算预测值
y_hat = sigmoid(np.dot(xb, w) + b)
# Getting the gradients of loss w.r.t parameters.
dw, db = gradients(xb, yb, y_hat)
# 更新参数
w -= lr*dw
b -= lr*db
# Calculating loss and appending it in the list.
l = loss(y, sigmoid(np.dot(X, w) + b))
losses.append(l)
# returning weights, bias and losses(List).
return w, b, losses8.封装预测函数
def predict(X):
# X --> Input.
# Normalizing the inputs.
x = normalize(X)
# Calculating presictions/y_hat.
preds = sigmoid(np.dot(X, w) + b)
# Empty List to store predictions.
pred_class = []
# if y_hat >= 0.5 --> round up to 1
# if y_hat < 0.5 --> round up to 1
pred_class = [1 if i > 0.5 else 0 for i in preds]
return np.array(pred_class)9.调用训练函数、画图函数
# Training
w, b, l = train(X, y, bs=100, epochs=1000, lr=0.01)
# Plotting Decision Boundary
plot_decision_boundary(X, w, b)
10.定义accuracy函数
def accuracy(y, y_hat):
num=np.sum(y == y_hat)
accuracy = num/ len(y)
return accuracy
accuracy(y,predict(X))11.实例
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.24)
# Training
w, b, l = train(X, y, bs=100, epochs=1000, lr=0.01)
# Plotting Decision Boundary
plot_decision_boundary(X, w, b)
accuracy(y, predict(X))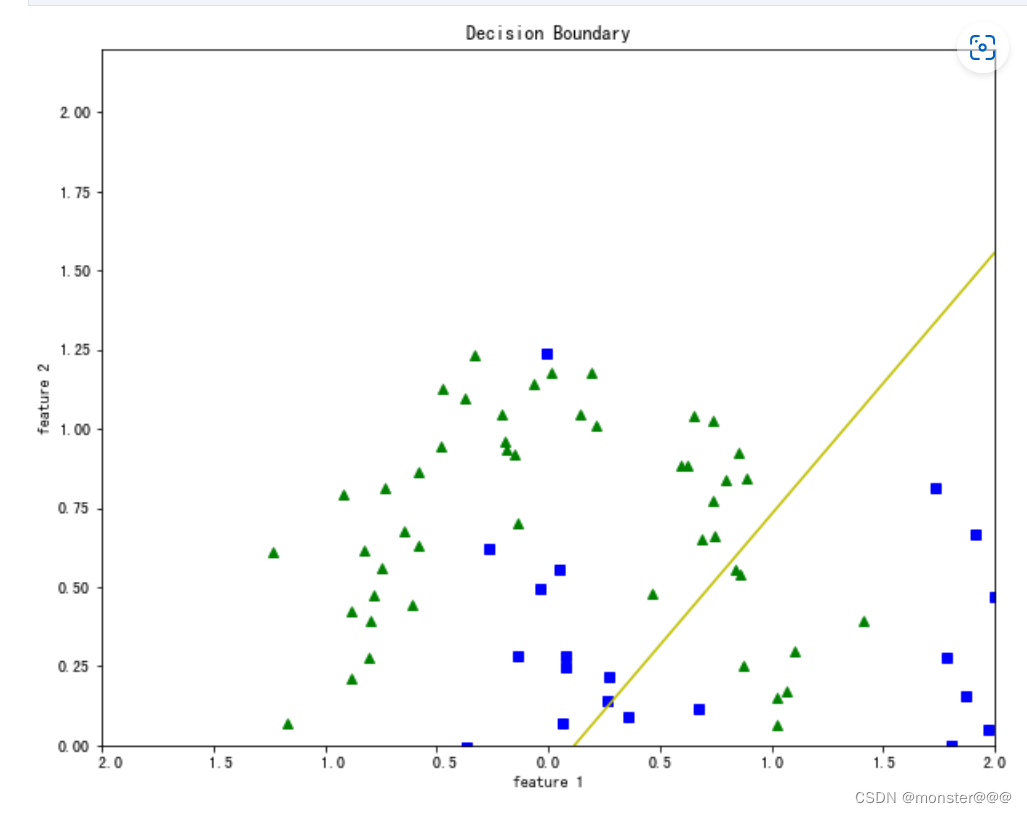














 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









