






本文是对论文raft-extended的内容总结以及对MIT对应项目lab2的代码梳理
Raft算法大致介绍
Raft是一种共识算法,用于管理在多机上冗余的日志。它的功能等同于Paxos算法,并且它拥有更出色的效率.Raft的共识机制包括:
1.leader选举
2.日志拼接
3.安全和可恢复
直观来讲,raft主要工作在并发客户端请求和多台服务器响应的中间层部分,它保证了这多台服务器的状态强一致性.
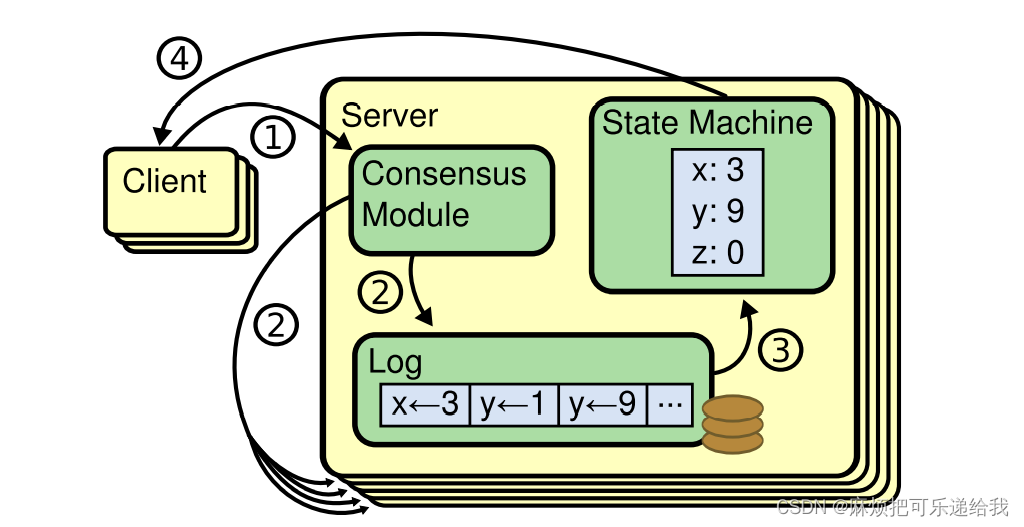
如上图,Consensus Module即为Raft工作的层次,通过Raft可以保证部署在多台服务器上的StateMachine的状态一致性.这里StateMachine的例子包括Zookeeper,Chubby,或者是一个简单的键值对存储服务器.Raft是怎么保证StateMachine状态一致性的呢?其实是通过将客户端操作日志进行冗余备份实现的,只需要保证每台机器上的操作日志的提交结果一致,那么每台机器的最终状态就是一致的.
Raft State介绍

Persistent的状态是要求每次变更之后持久化的,以便服务器宕机之后恢复.而Volatile的状态则不需要持久化,只需要在宕机之后重新初始化即可.其中leader需要维护的状态需要在每次被选举为leader之后重新初始化.
//
// A Go object implementing a single Raft peer.
//
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
//Persistent state on all servers
currentTerm int
votedFor int
log []LogEntry
//Volatile state on all servers:
applyCh chan ApplyMsg
commitIndex int
lastApplied int
lastIncludedIndex int
lastIncludedTerm int
snapShot []byte
/**
0 follower
1 candidate
2 leader
**/
currentState int
heartsbeats int
//Volatile state on leaders:
/*
for each server, index of the next log entry
to send to that server (initialized to leader
last log index + 1)
*/
nextIndex []int
/*
for each server, index of highest log entry
known to be replicated on server
(initialized to 0, increases monotonically)
*/
matchIndex []int
}
mu是我们定义的互斥量,用来保证多线程环境下对某些共享变量的保护.
Raft Leader选举介绍
在Raft中,每个节点都有一个超时时间,这个超时时间是随机的,一旦达到超时时间,该节点就会发起leader选举请求,并将自身term加一.而leader为了避免其他节点频发发起选举,会每隔一段时间发送一个心跳,一旦其他节点收到心跳,就重置超时时间.对应代码实现如下:
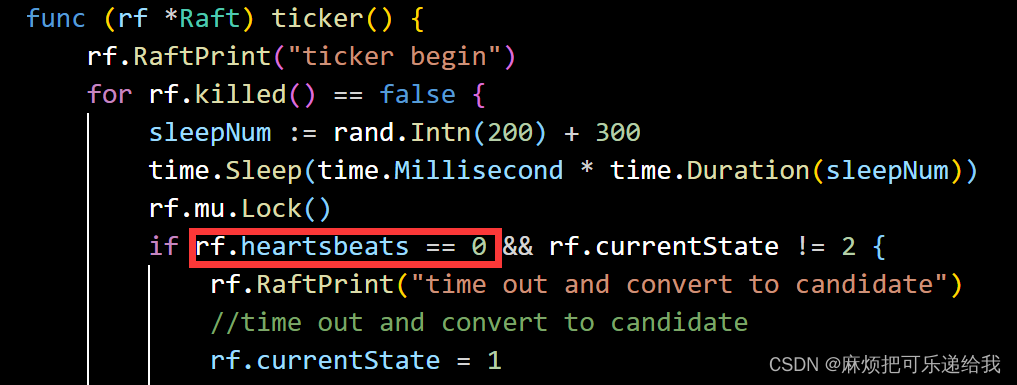
每次follower收到leader的心跳时,都会把heartbeats设置为1,从而防止
在Raft 的初始状态下,没有任何一个节点是leader,此时,由于每个节点的超时时间是在一定范围内随机的,因此一定会有一个节点先超时,然后向其他发起leader选举rpc.论文里关于该rpc的定义如下:

一旦开始选举, follower会先把自身状态更新为候选者状态,然后投票对象设置为自己,然后并行发送rpc给其他peer,对应代码实现如下:
rf.currentTerm++
rf.votedFor = rf.me
随后设置rpc请求所需参数
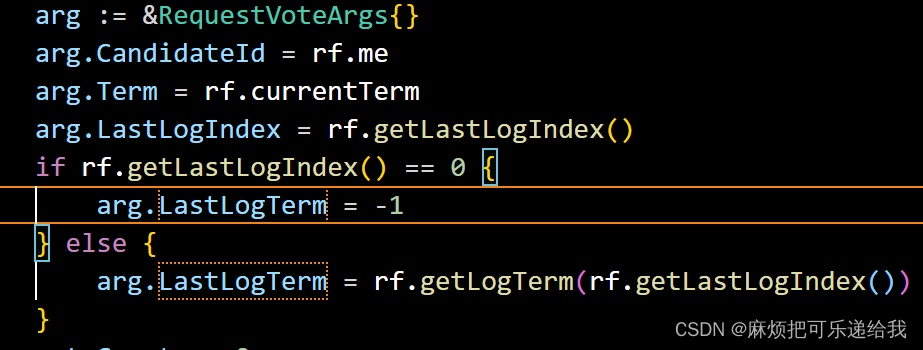
然后并行发送请求给每个peer
for i := 0; i < len(rf.peers); i++ {
go func(x int, term int) {
reply := RequestVoteReply{}
ok := rf.sendRequestVote(x, arg, &reply)
rf.mu.Lock()
if rf.currentTerm > term {
rf.RaftPrint("Expired voting results, discard")
rf.mu.Unlock()
return
}
if !ok {
rf.RaftPrint("we can't get message from server id = " + strconv.Itoa(x))
remainCount--
rf.mu.Unlock()
return
}
if reply.Term > rf.currentTerm {
rf.RaftPrint("find someone's term bigger than mine, update my term and convert to follower")
rf.currentState = 0
rf.currentTerm = reply.Term
rf.votedFor = -1
rf.persist()
} else if reply.VoteGranted {
voteCount++
if voteCount > len(rf.peers)/2 {
rf.RaftPrint("find voteCount has beyound half")
remainCount = 0
}
}
remainCount--
rf.mu.Unlock()
}(i, rf.currentTerm)
}
可以看到,这里每次for循环内都创建了一个go线程来完成rpc的发送,因此我们需要在for循环下面阻塞来等待选举结果出来之后再继续执行后续逻辑.
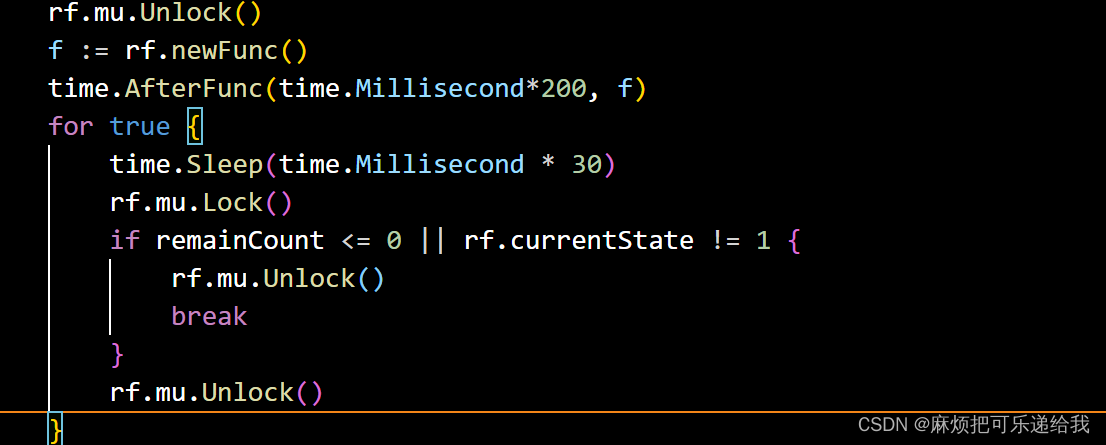
当获得半数人以上的同意时(remainCount = 0)或者达到总的超时时间(这里设置的是200毫秒),就会中止阻塞,查看选举结果
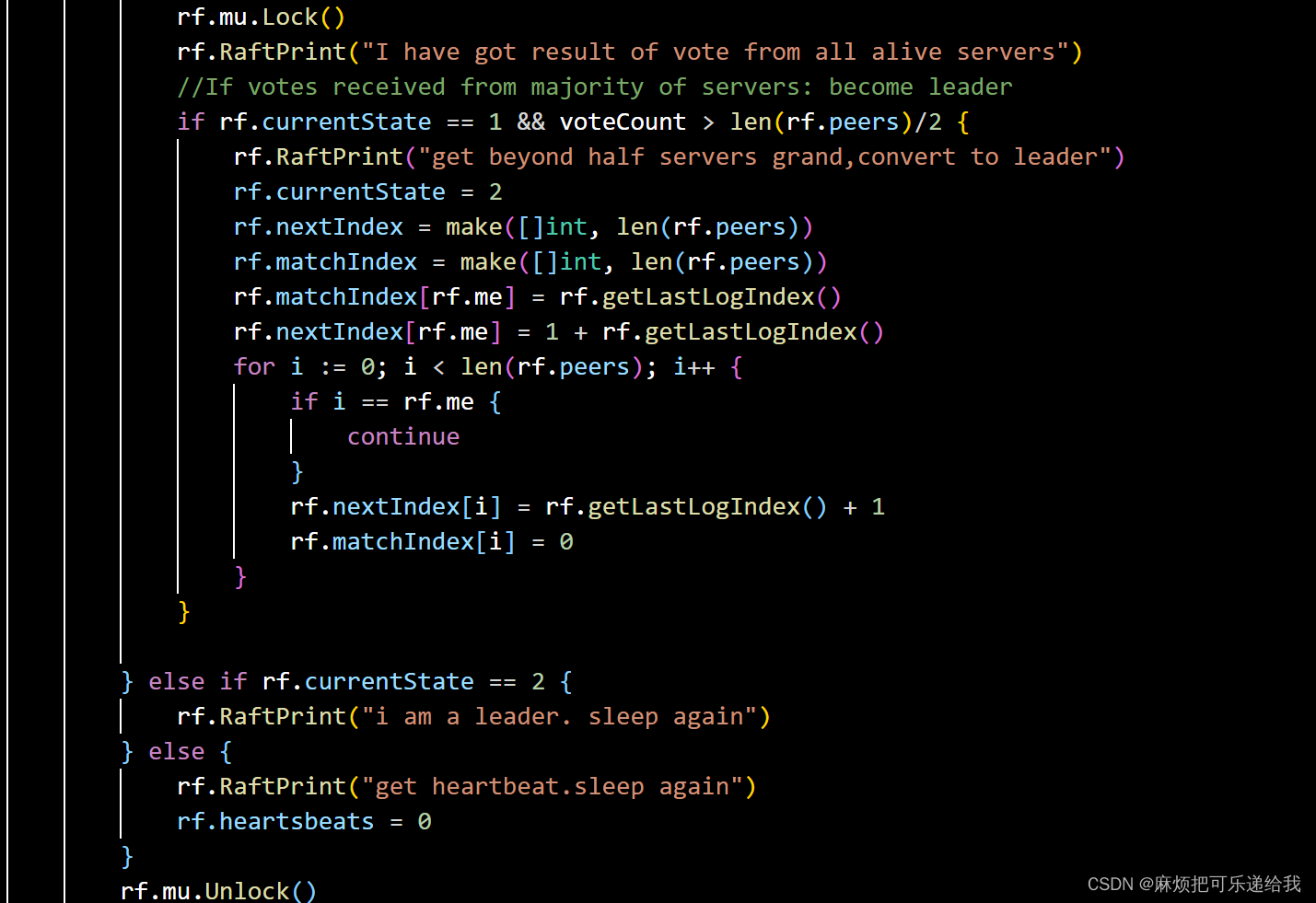
如果获得半数以上投票,就会将自身状态从candidate转为leader,并重新初始化那些leader专属的变量.目前为止讲解的都是发送方的流程,那么接收方该如何判断是否该投票给这个candidate呢?我们来看该rpc的响应流程
rf.mu.Lock()
defer rf.mu.Unlock()
rf.RaftPrint("get heartbeat from candidate. candidate id = " + RaftToString(args.CandidateId))
rf.heartsbeats = 1
首先,当一个peer收到一个requestVote RPC时,会将他视为一次有效心跳,从而避免自己也被唤醒加入到选举过程中
reply.Term = rf.currentTerm
if args.Term < rf.currentTerm {
rf.RaftPrint("VoteRequest's term less than mine, discard and granted false for request from raft id = " + RaftToString(args.CandidateId))
reply.VoteGranted = false
return
}
if args.Term > rf.currentTerm {
rf.RaftPrint("VoteRequest's term bigger than mine, convert to follower")
rf.currentTerm = args.Term
rf.currentState = 0
rf.votedFor = -1
rf.persist()
}
moreUpToDate := false
if rf.getLastLogIndex() == 0 {
moreUpToDate = true
} else {
myLastTerm := rf.getLogTerm(rf.getLastLogIndex())
moreUpToDate = args.LastLogTerm > myLastTerm || (args.LastLogTerm == myLastTerm && args.LastLogIndex >= rf.getLastLogIndex())
}
if (rf.votedFor == -1 || rf.votedFor == args.CandidateId) && moreUpToDate {
rf.RaftPrint("Granted true for request from raft id = " + RaftToString(args.CandidateId))
reply.VoteGranted = true
rf.votedFor = args.CandidateId
rf.persist()
return
}
rf.RaftPrint("Granted false for request from raft id = " + RaftToString(args.CandidateId))
reply.VoteGranted = false
随后可以看到,如果自身的Term比请求方的Term大,那么就拒绝投票,并将自身Term写入reply以便请求方更新自己的term.而如果请求方的Term比自己的大,那么自己就应该更新自己的term,并且将状态转回(无论本身是否)follower.接着,我们还不能对该请求者进行投票,如果我们此时的voteFor以及有值,并且这个值和请求方的不一致,那么说明我们在这轮Term里已经投过票了,因此不能投票给请求者.如果voteFor 为 -1,并且请求方的日志至少比我的更新(或者一样),那么就可以进行投票
投票机制的rpc调用
go rf.ticker()
总结
投票机制可以保证每段时间内只有一个有效leader,并且当某个leader宕机时,会很快选举出下一个leader,除非大多数的节点都宕机(2f+1个节点允许f个节点宕机).而如果有些节点陷入了网络故障中,自认为自己是leader(因为始终无法得到其他节点的消息),一旦网络故障回复,这个过时的leader会因为自己的日志过于落后而无法得到投票.
Raft日志拼接介绍
在raft的设计中,leader负责向其他follower转发客户端发来的log,而如果客户端没有发来log,leader也要定期向其他follower发送空的log来表示心跳.
在代码设计里,我们实现了一个方法叫做sendRpc,它负责当前节点对其他节点的rpc发送.只有当当前节点为leader时,才会发送appendEntryRpc
.前面提到过,Raft是一个强一致性的算法,那么该如何保证日志的一致性呢?因为有可能某些节点的日志非常落后,或者某些节点的日志特别超前.

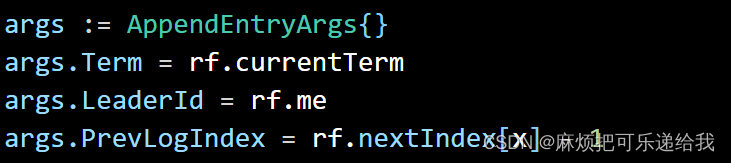
在这里,我们选择的办法是,每次发送appendRpc的时候,携带一个preLogTerm和PreLogIndex,当接受到leader发来的rpc 时,先判断自己日志是否在prelogIndex处有节点,并且该节点的Term等于preLogTerm,如果满足这个条件,那么会在这个节点后拼接传来的日志
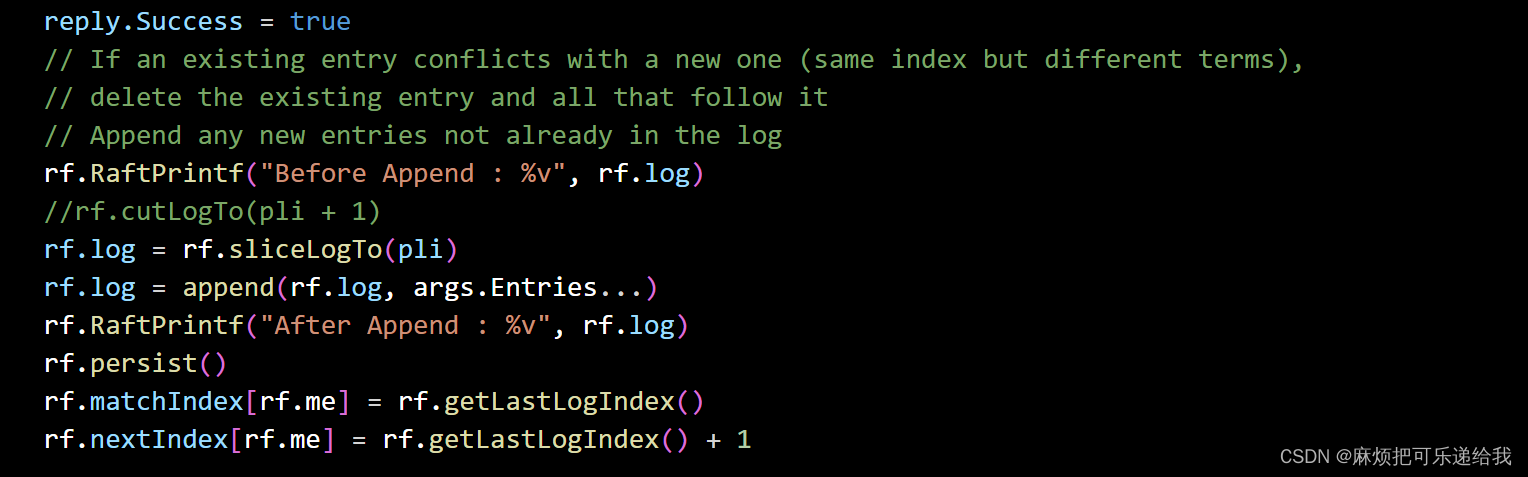
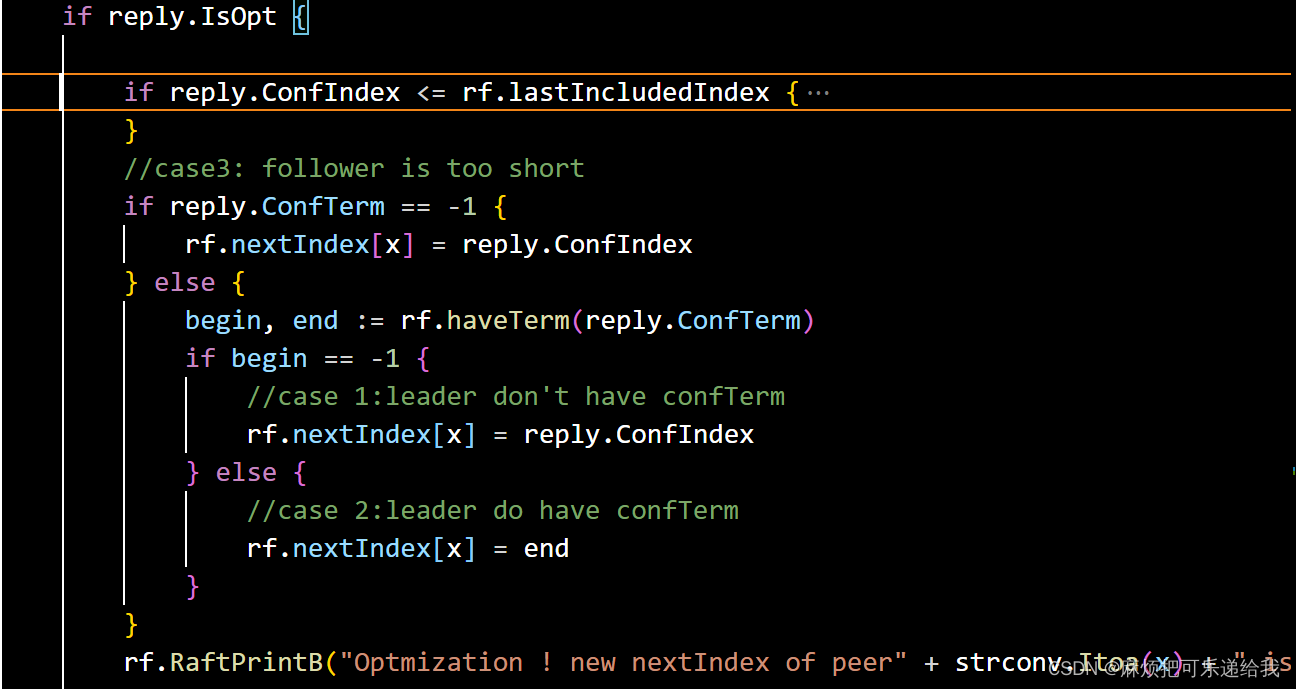
,而如果不满足
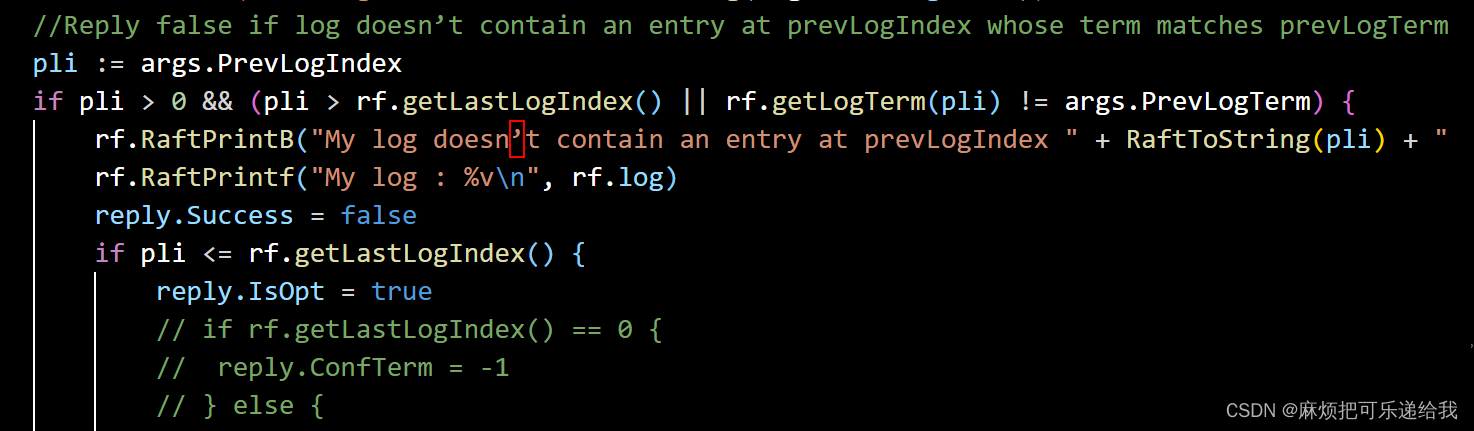
就将冲突位置的Term以及在log中该Term的第一个节点的Index返回给leader以便leader更新发给自己的参数
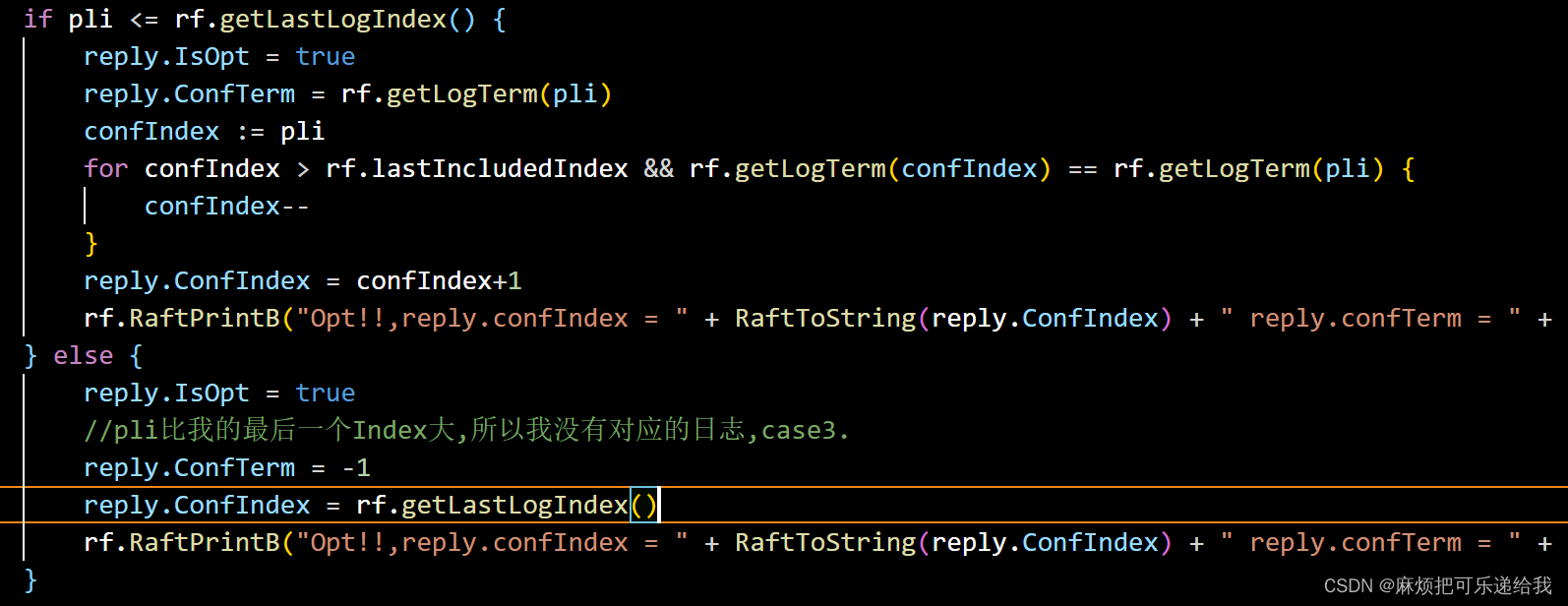
同时,如果leader的commitIndex比自己的要大时,要更新自己的CommitIndex

leader的CommitIndex会在有半数以上节点都表示成功拼接了该index的日志之后进行更新
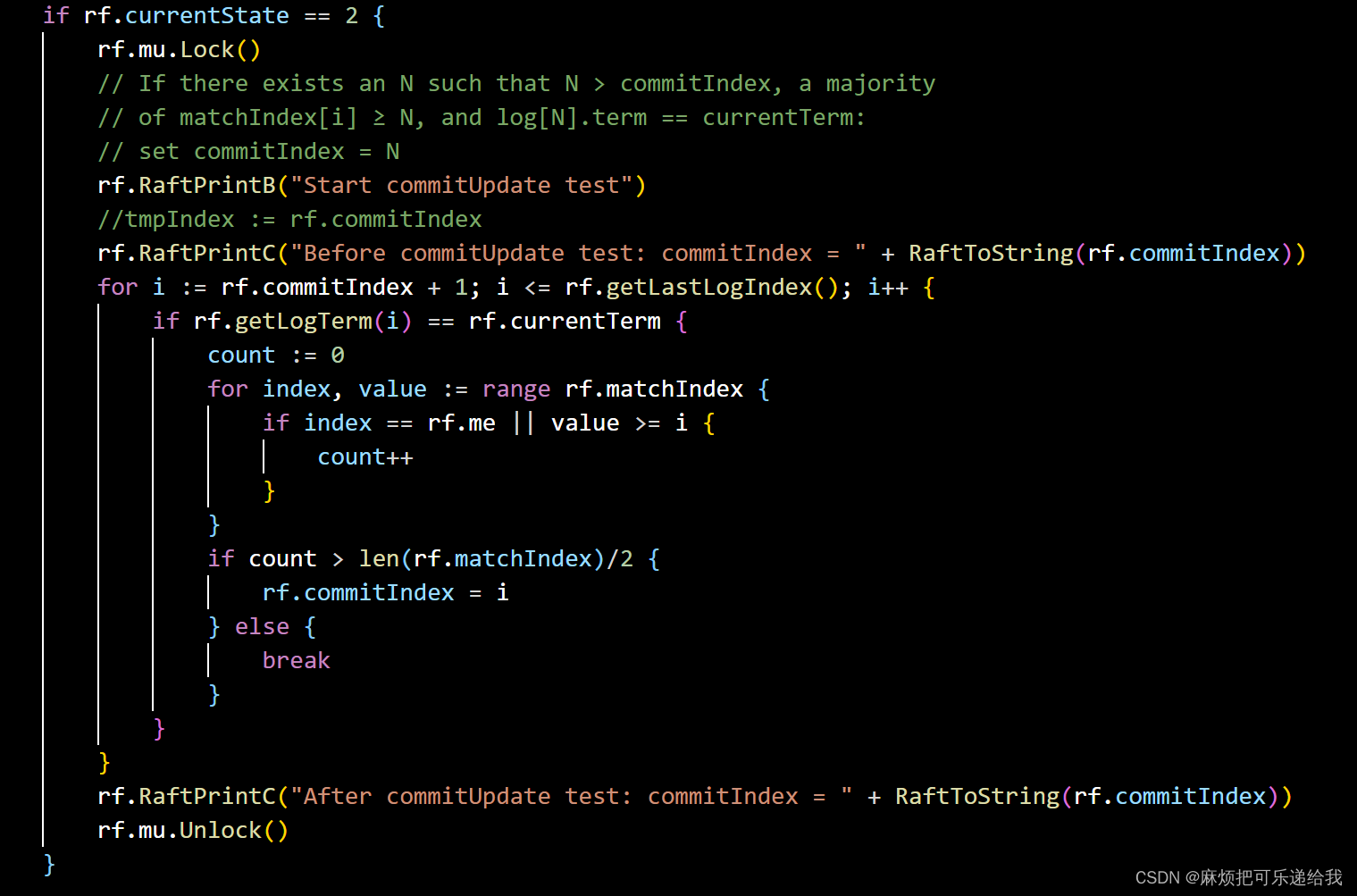
我们为此专门启动了一个线程worker来持续监测是否有半数的follower已经收到了日志
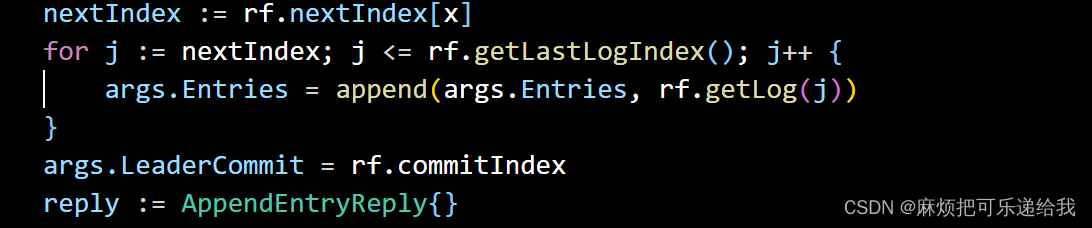
而leader方面,当它收到了follower发来的reply 之后,他会判断是否拼接成功了,如果成功,则更新matchIndex和nextIndex,
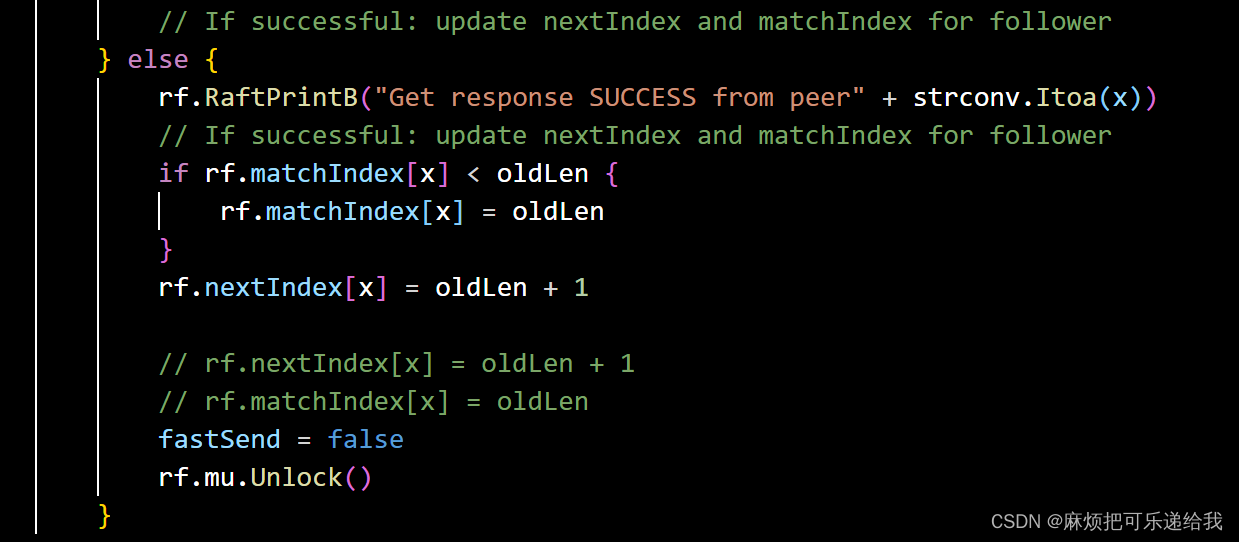
否则,改变PreLogIndex和PreLogTerm后重新发送rpc(由于这两个Pre是由mmatchIndex和nextIndex决定的,所以这里先更新了两个Index,等到下一次循环时构造参数时就会影响两个Pre)
需要注意的是,当有需要追加的log时,就发log,当没有时,也发,只不过把这次当做一个心跳
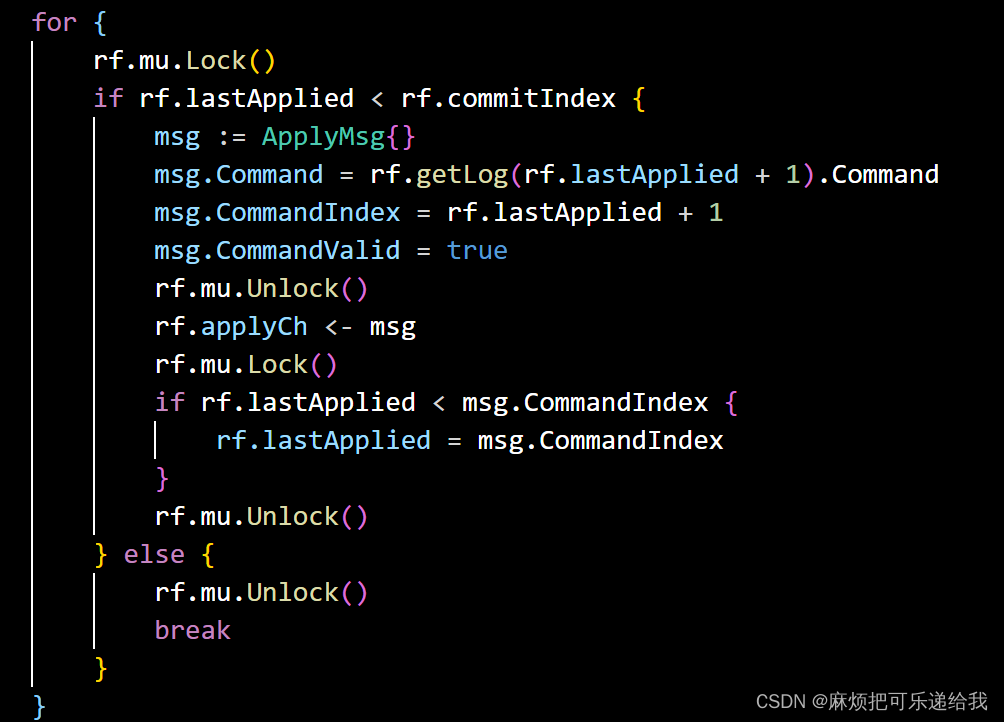
当我们发现matchIndex小于CommitIndex时,就可以使matchIndex追赶上CommitIndex,并且应用这些日志给server
Raft快照存储介绍
当我们的日志越来越长的时候,就需要外界提供给我们一个服务,来将我们raft此时的状态做一次快照,从而我们就可以去掉那些已经做过快照的日志.
而当我们需要发送的日志由于快照我们不再持有了,我们会通过InstallSnapShotRpc来替代,直接将我们的快照发送给follower
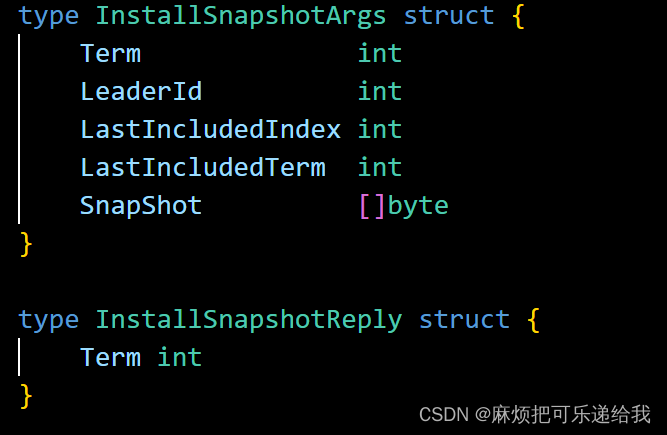
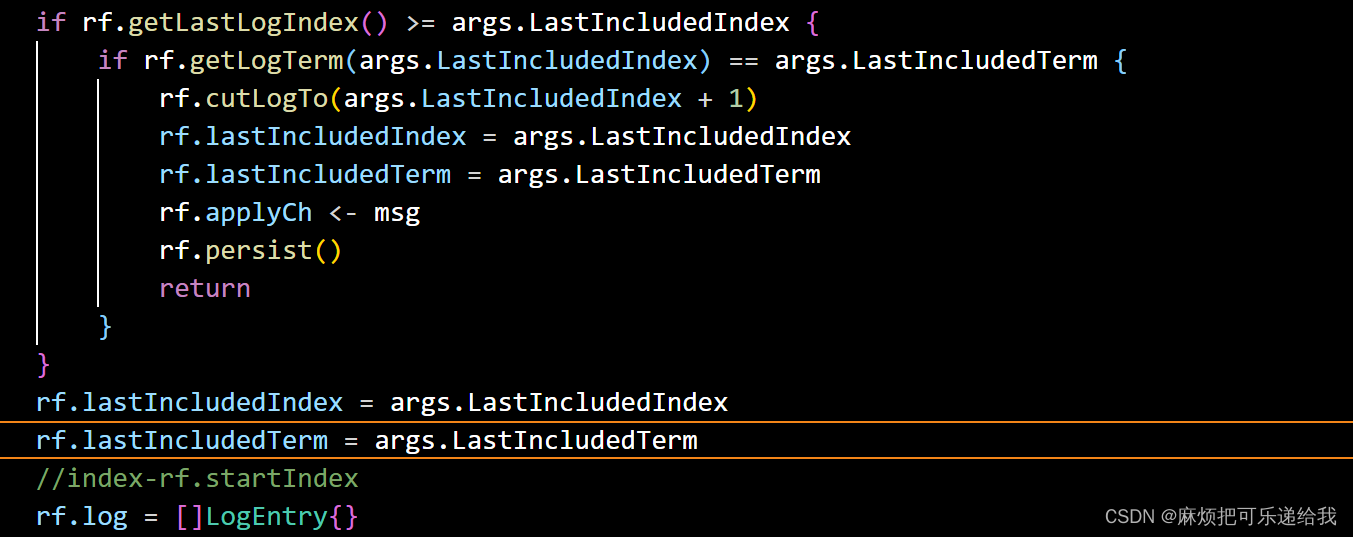
参数里包括我们快照里存储的最后一个log的index 和term .当follower接收到leader发来的快照请求时,会直接将快照存储,并且切割掉多余的日志














 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









