







Windows安装Scrapy
安装Scrapy,命令如下:
pip install Scrapy
如果报错,可以尝试先安装以下库:
-
lxml
-
pyOpenSSL
-
Twisted
-
PyWin32
pip install lxml
创建项目
选择文件夹,打开cmd,输入以下命令创建一个项目
scrapy startproject 你的项目名

之后,切换到项目路径,然后创建爬虫项目
cd myproject scrapy genspider example example.com #example->爬虫名 example.com->爬取的域名
项目结构如下:
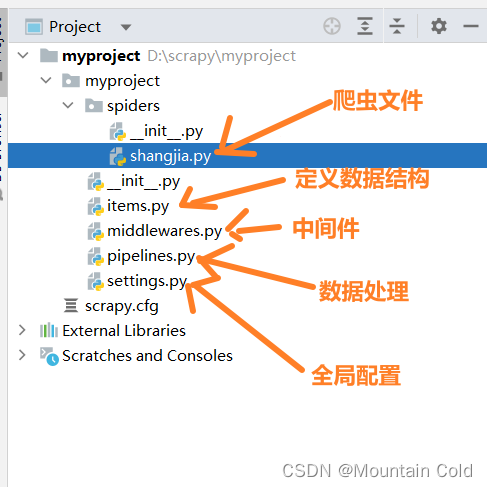
编写py文件
1.修改settings.py
根据实际需求,修改配置。
#是否遵循Robot协议,修改成False
ROBOTSTXT_OBEY = True
#下载间隔,修改成1s
DOWNLOAD_DELAY=1
#请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
#打开一个管道
ITEM_PIPELINES = {
'myproject.pipelines.MyprojectPipeline': 300,
}
2.编写items.py文件
import scrapy class MyprojectItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 以下是采集的字段 # name=scrapy.Field() info=scrapy.Field() #item['info'] pass
3.编写爬虫文件(shangjia.py)
import scrapy
from ..items import MyprojectItem
import json
class ShangjiaSpider(scrapy.Spider):
name = 'shangjia'
allowed_domains = ['shangjia.com']
start_urls = ['https://www.shangjia.com/market/varietyData/getVarietyContent?type=1&varietyId=60&order=2&page=1'] #可以根据实际开始url修改
max_page=10
page=1
def parse(self, response):
items = MyprojectItem()
print(response)
res = response.text
res=json.loads(res)
# for list in lists:
# items['content'] = list.xpath('/div/text()').get() # 获取图片链接
# yield items
print(type(res))
# items['content']=res['msg']
data_list=res['data']['list']
result_list=[]
for data in data_list:
js={
'name':data['forum_user']['nickName'],
'content':data['forum_info']['content']
}
result_list.append(js)
items['info']=result_list
yield items
if self.page < self.max_page: # 爬取10页内容
self.page += 1
# 构建下一个url
url = f'https://www.shangjia.com/market/varietyData/getVarietyContent?type=1&varietyId=60&order=2&page={str(self.page)}'
# 使用callback进行回调
yield scrapy.Request(url=url, callback=self.parse)
pass
4.编写pipelines.py
主要是对item进行数据处理
from itemadapter import ItemAdapter
# 处理提取的数据
class MyprojectPipeline:
def process_item(self, item, spider):
temp=[]
for info in item['info']:
info['content']=info['content'].replace('\n','') #简单处理
temp.append(info)
print(info) #打印
return temp
5.执行爬虫文件
5.1cmd命令行执行
在项目路径(myproject)下打开cmd,执行:
scrapy crawl 爬虫名 #本例中 scrapy crawl shangjia
5.2pycharm内执行
在spiders文件夹下创建run.py文件
from scrapy import cmdline
cmdline.execute('scrapy crawl shangjia'.split()) # 记得爬虫名改成自己的
然后执行run.py文件即可,采集过程如下:















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









