







动态网页特征
网页的数据并不会出现在源代码中,获取新数据时网址是不会变化的。
以上甲网站为例原油期货sc2212行情 - 原油期货sc2212走势预测分析 - 上甲 (shangjia.com),该页面的评论信息需要不断下滑,评论数据才会增加。源代码中并不包含所有的数据,只有请求后才会更新一部分。
采集思路
思路一般有两种:
-
分析数据接口,然后构造请求url进行数据请求
-
采用 Selenium 模拟浏览器点击的方式获取数据
以上甲网站为例原油期货sc2212行情 - 原油期货sc2212走势预测分析 - 上甲 (shangjia.com),采集该页面的评论信息。
1.分析数据接口,然后构造请求url进行数据请求。
分析过程
上甲原油行情页面的评论是一页到底的,没有分页,但是评论是动态请求的。
首先打开检查,缓慢下滑评论页面,观察源代码的变化(也可以观察【网络】选项的变化),发现如图的现象。找到了js函数,之后全局搜索该js函数。
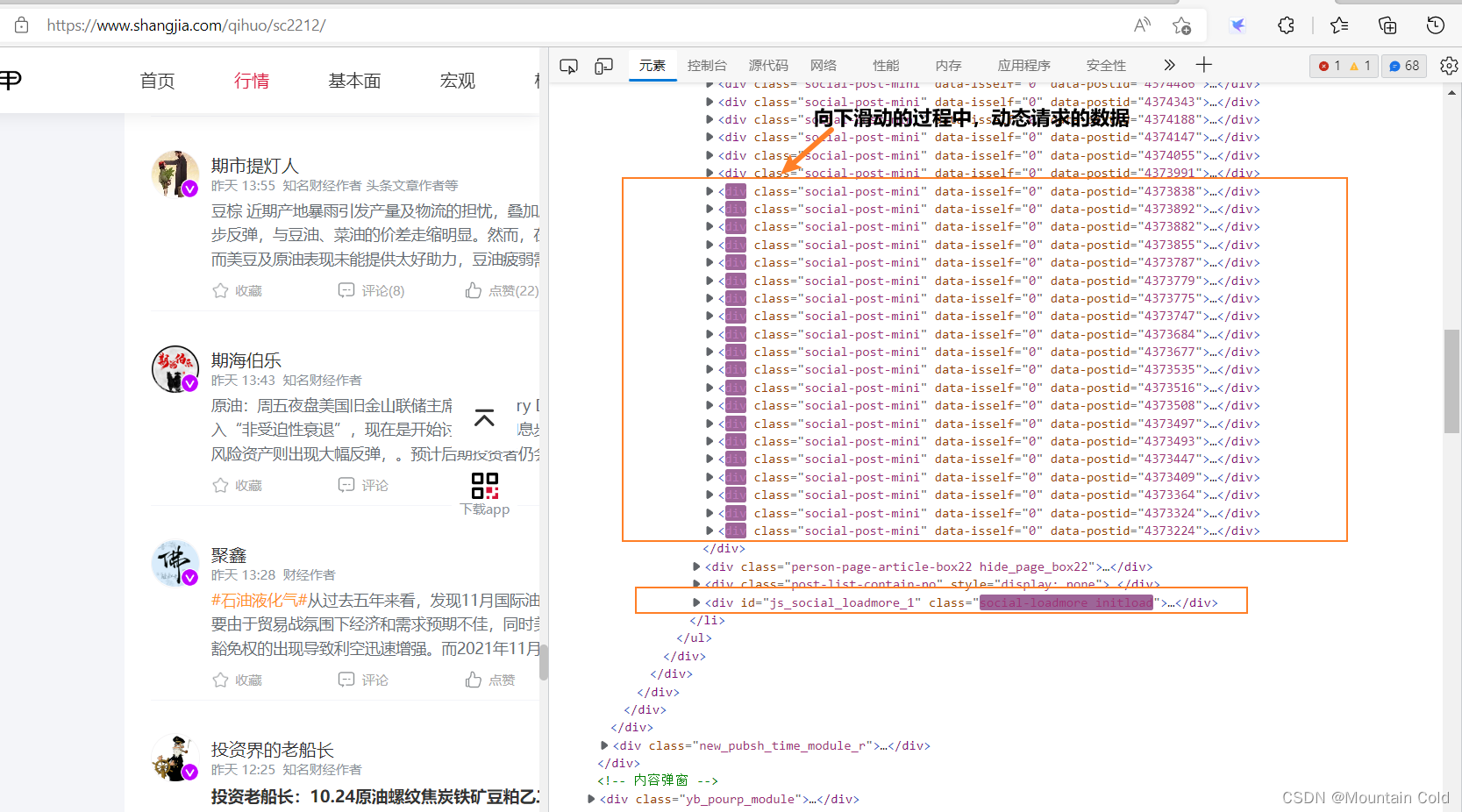
全局搜索发现,然后查看该函数,发现使用了getVarietyContent函数,明显是数据请求接口。之后只需要找到getVarietyContent的格式即可构造出请求url。
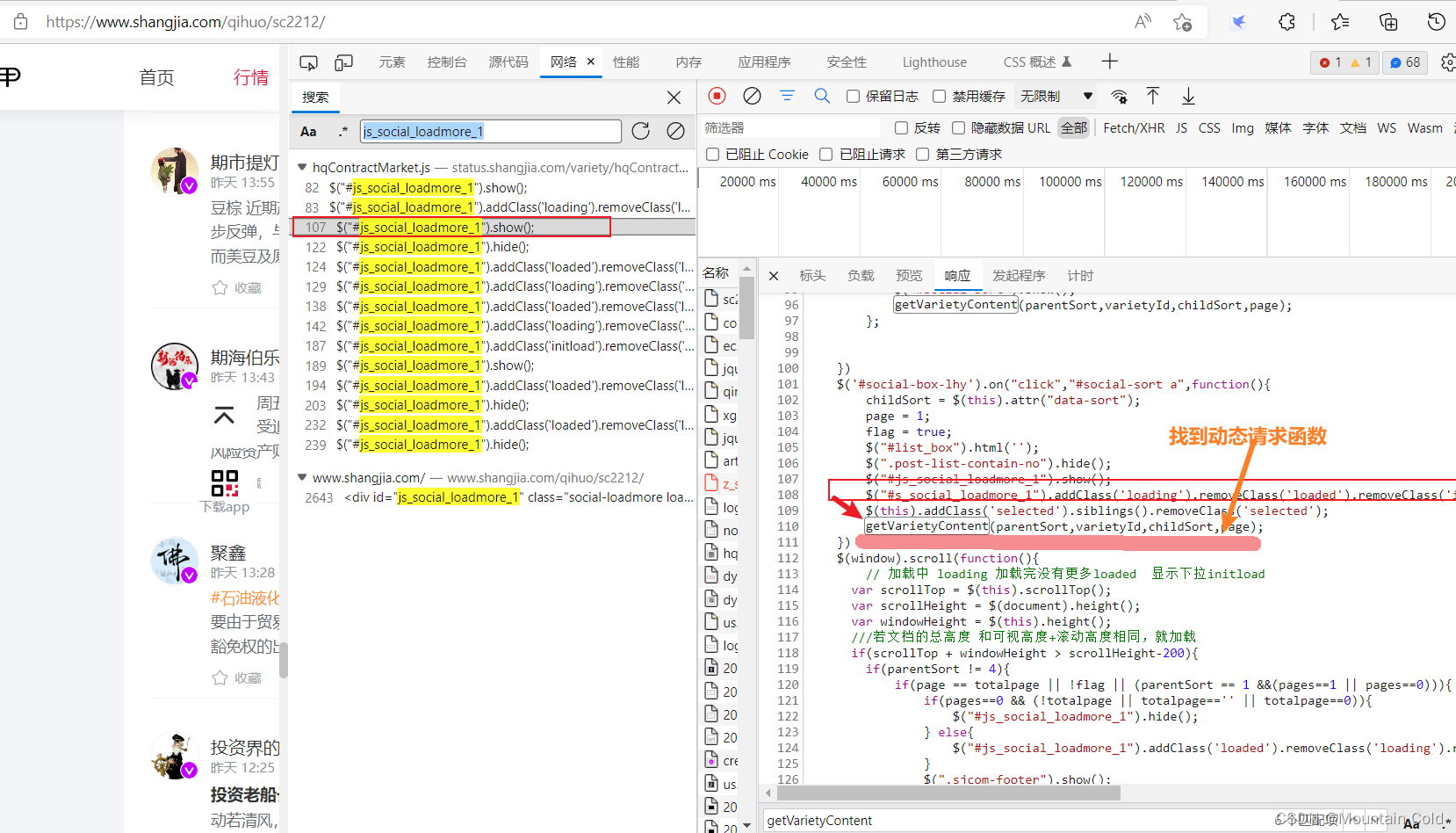
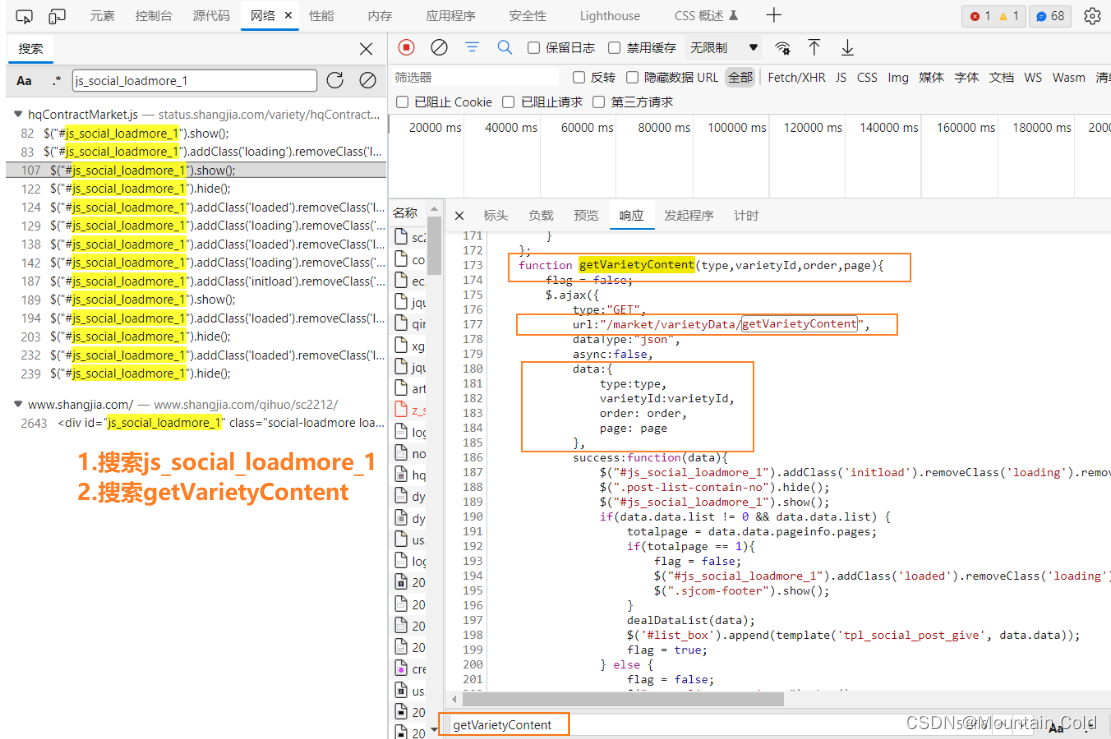
由上图基本确定,数据请求接口是:https://www.shangjia.com/market/varietyData/getVarietyContent?type={}&varietyId={}&order={}&page={}
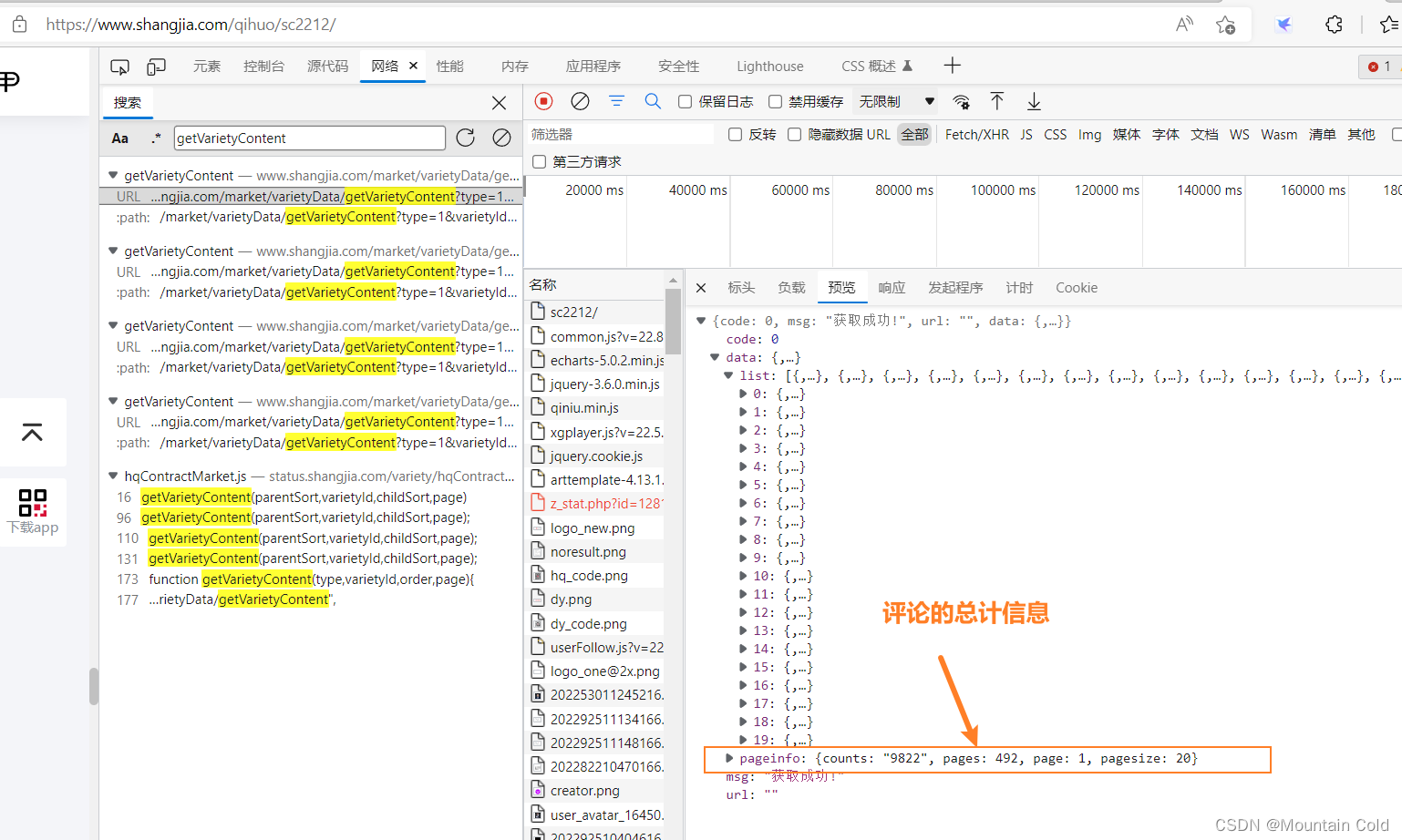
ctrl+F搜索函数名,可以发现具体的一个数据接口:https://www.shangjia.com/market/varietyData/getVarietyContent?type=1&varietyId=60&order=2&page=1。此时我们已经完成数据接口的分析,之后迭代请求该接口【https://www.shangjia.com/market/varietyData/getVarietyContent?type={}&varietyId={}&order={}&page={}】即可获取全部的评论信息。值得注意的是,迭代的次数不应该超过总的页数,总页数可以从预览选项中看到,见下图。

完整代码
# -*- coding: utf-8 -*-
# @Time : 2022/10/25 11:32
# @Author : wjy
# @FileName: l.py
import time
import requests
import json
def request_varietyUrl(url,timeout=5,headers=None):
"""返回获取的信息,[[{},{},...]],若到结束位置或请求失败返回None"""
ct=3
while ct>0:
try:
resp = requests.request('GET',url=url, timeout=timeout,headers=headers)
if resp.status_code==200:
result=json.loads(resp.text)
# print(result)
data_list=result['data']['list']
# print(data_list)
#判断是否为空
if len(data_list)==0:
return None
return data_list
else:
ct=ct-1
except:
print('失败')
return None
def getPages_varietyUrl(url,timeout=5):
"""返回页数,失败返回None"""
ct = 3
while ct > 0:
try:
resp = requests.request('GET', url=url, timeout=timeout)
if resp.status_code == 200:
result = json.loads(resp.text)
pageinfo = result['data']['pageinfo']
pages = pageinfo['pages'] # 页数
print(pages)
return pages
else:
ct = ct - 1
except:
print('失败')
return None
def getOutcome(timeout=5, timedelay=1, headers=None,maxPage=10):
"""获取评论信息"""
# 请求
# https://www.shangjia.com/market/varietyData/getVarietyContent?type=1&varietyId=60&order=2&page=2
# base_url = 'https://www.shangjia.com/market/varietyData/getVarietyContent?type=1&varietyId=' + str(varietyId) + '&order=2&page='
base_url = 'https://www.shangjia.com/market/varietyData/getVarietyContent?type=1&varietyId=60&order=2&page='
result = request_varietyUrl(url=base_url + '1')
if result is None:
print('请求失败')
pages = getPages_varietyUrl(base_url + '1', timeout=timeout) # 获取页数
flag = False # 结束标志
pages=min(maxPage,pages)
for i in range(1, pages + 1):
print('页数:' + str(i))
url = base_url + str(i)
time.sleep(timedelay) # 延迟
result = request_varietyUrl(url=url, timeout=timeout, headers=headers)
print(result)
if __name__ == '__main__':
getOutcome()
执行结果

2.采用 Selenium 模拟浏览器点击的方式获取数据
-
安装谷歌浏览器,并查看版本号。
-
下载对应版本号的Chromedriver.exe,项目文件夹下。
-
s = Service(chromedriver_path),chromedriver_path为Chromedriver.exe的绝对路径
我们采用selenium 模拟浏览器(谷歌浏览器)的行为。浏览器能请求到的,使用selenium也能请求到。
当然针对不同的浏览器有不同的driver。以下列出了不同浏览器及其对应的driver:
Chrome:https://sites.google.com/a/chromium.org/chromedriver/downloads Firefox:Releases · mozilla/geckodriver · GitHub Edge:Microsoft Edge WebDriver - Microsoft Edge Developer Safari:WebDriver Support in Safari 10 | WebKit
selenium的API说明
#chromedriver的绝对路径 driver_path 初始化一个driver,并且指定chromedriver的路径 s = Service(chromedriver_path) driver = Chrome(service=s, options=chrome_options) 请求网页 driver.get(“https://www.baidu.com/”) 通过page_source获取网页源代码 driver.page_source 其余api见:https://selenium-python.readthedocs.io/installation.html#introduction
源代码
import os
from bs4 import BeautifulSoup
import time
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options # 使用无头浏览器
from selenium.webdriver.common.by import By
chrome_options = Options()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) # =>去掉浏览器正在受到自动测试软件的控制
chrome_options.add_experimental_option('useAutomationExtension', False)
chrome_options.add_argument("disable-web-security")#允许重定向
chrome_options.add_argument("--headless") # => 为Chrome配置无头模式
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--start-maximized') # 最大化运行(全屏窗口),不设置,取元素会报错
base_path = os.path.dirname(os.path.abspath(__file__))
#获取chromedriver.exe的绝对路径
chromedriver_path=os.path.join(base_path,os.path.join("tools","chromedriver.exe."))
"""1.滚动下滑,获取网页 2.对html文本提取相应的数据,并转换成统一格式"""
def getOutcome(varietyUrl,timeout=5, timedelay=2, headers=None,maxPage=10):
"""获取评论信息,保存到outcome.json"""
s = Service(chromedriver_path)
driver = Chrome(service=s, options=chrome_options)
driver.implicitly_wait(timeout)#隐式等待
#请求
driver.get(varietyUrl)
pre = ''
now = 't'
ct = 0
while now != pre: # 判断页面是否到底 ///
pre = driver.find_element(by=By.XPATH, value='//*[@id="list_box"]/*[last()]')
jscode = 'window.scrollTo(0,document.body.scrollHeight)'
driver.execute_script(jscode)
time.sleep(0.5) # 等待资源加载完毕
now = driver.find_element(by=By.XPATH, value='//*[@id="list_box"]/*[last()]')
ct = ct + 1
if ct>maxPage:
break
time.sleep(timedelay)
time.sleep(timedelay)
html = BeautifulSoup(driver.page_source, "lxml")
# print(html)
info_list=html.findAll("div",class_="social-post-mini")
for info in info_list:
content=info.find_all("div",class_="content conten_href conten_first string_sub")[0].text.replace(' ','').replace('\n','')
name=info.find_all("div",class_="name")[0].text.replace(' ','').replace('\n','')
data = {
"name": name,
"content": content, # 评论内容
}
print(data)
if __name__ == '__main__':
getOutcome(varietyUrl='https://www.shangjia.com/qihuo/sc2212/')
执行结果
















 681
681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









