







文章目录
实验思维导图
实验一
1.1 启动 Rstudio
1.2 新建 R Script 文件
1.3 read.csv()函数导入数据
mydata <- read.csv("~\\chengjidan.csv")
#路径:右下双斜杠
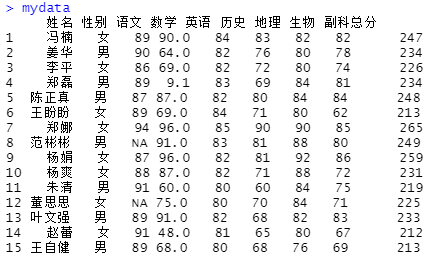
1.4 剔除冗余变量
#剔除第2、9列:无关、冗余变量(性别、副科总分)
mydata <- mydata[-c(2,9)]
#变量名[-c(x,y)],其中c表示column,删除第x列与第y列
head(mydata,3)
1.5 缺失值处理
#查看缺失值数量
sum(is.na(mydata))
#打印缺失值所在行
mydata[!complete.cases(mydata),]
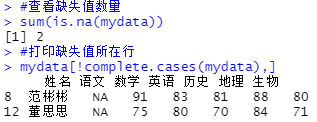
#获取缺失值所在行序号
sub <- which(is.na(mydata$语文))
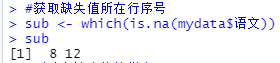
#删除有缺失值的样本,13obs
mydata_1 <- mydata[-sub,]
#提取缺失值样本,2obs
mydata_2 <- mydata[sub,]
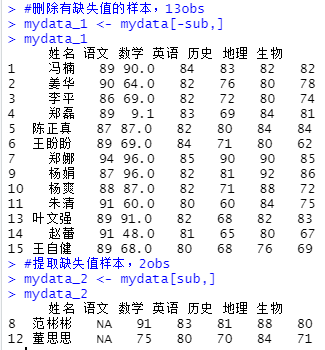
#语文avg
avg_chinese <- round(mean(mydata_1$语文),0)
#均值填补缺失值,data name$column:缺失的列
mydata_2$语文 <- rep(avg_chinese,2)
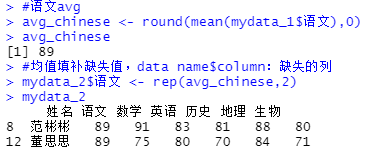
#rbind()合并mydata_1与mydata_2
result <- rbind(mydata_1,mydata_2)
result
1.6 异常值处理
#拆分绘图区域
par(mfrow = c(1,2))
#绘制单变量,横向
dotchart(mydata$数学)
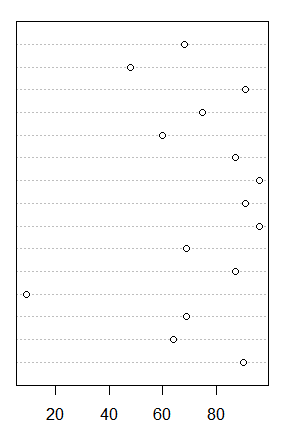
#箱型图查看异常值
#转置为横向
boxplot(mydata$数学,horizontal = T)

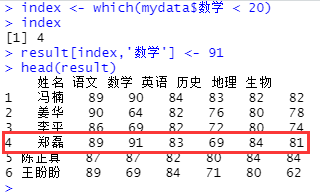
#筛选箱外值并手动赋值
index <- which(mydata$数学 < 20)
result[index,'数学'] <- 91
head(result)
实验二
2.1 启动 Rstudio
2.2 新建 R Script 文件
2.3 下载数据
数据下载链接–>bank-additional.zip–>目标路径
2.4 read.csv()函数导入数据
mydata <- read.csv("~\\bank-additional-full.csv", sep = ';')
#csv文件以逗号分隔
#seq 参数用来指定字符的分隔符号


2.5 简单探索数据
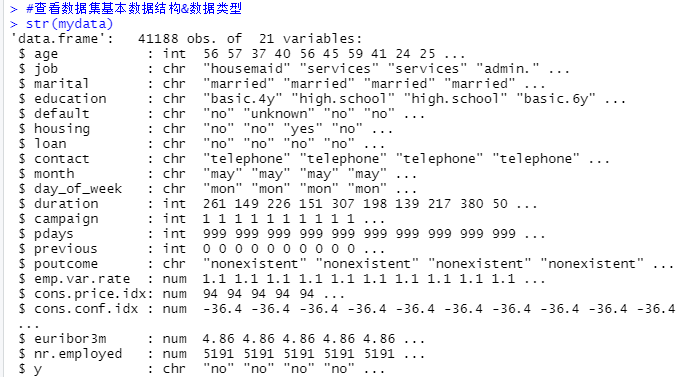
str(mydata)
#查看基本数据结构&数据类型
#这些变量包含 Factor、int、num 三个类型

summary(mydata) #查看每个变量的主要描述性统计量

2.6 识别缺失情况
prop.table(table(mydata$job))
prop.table(table(mydata$poutcome))
prop.table(table(mydata$education))

2.7 缺失值处理
job处理
#job列中的unknown更换为NA以便剔除
mydata$job[which(mydata$job == 'unknown')] <- NA
#na.omit()剔除含有缺失值的样本
mydata_clear1 <- na.omit(mydata)

poutcome处理
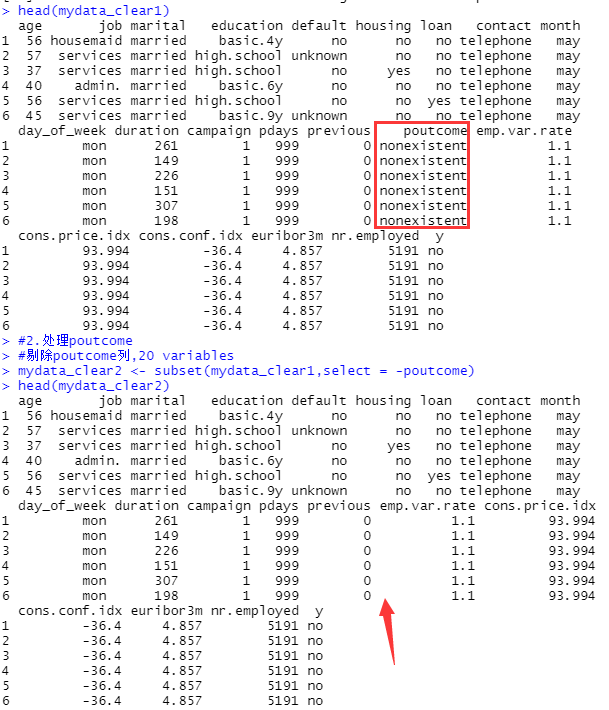
#剔除poutcome列,20 variables
mydata_clear2 <- subset(mydata_clear1,select = -poutcome)

education处理
#众数填补education列中的未知特征值
edu_max <- names(which.max(table(mydata_clear2$education)))
#which.max()将众数写入edu_max
mydata_clear2$education <- ifelse(mydata_clear2$education != 'unknown',
as.character(mydata_clear2$education),edu_max)
#ifelse()循环替换'unknown'
#在两个特征中有未知特征值:university degree

2.8 异常值识别
识别
参数boxwex:R-Documentation-boxwex
boxplot(mydata_clear2$age, boxwex = 0.7)
#箱线图boxplot()
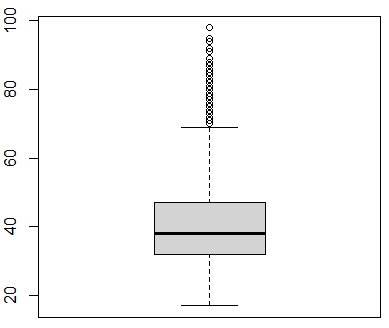
剔除
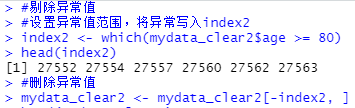
#设置异常值范围,将异常值写入index2
index2 <- which(mydata_clear2$age >= 80)
#删除异常值
mydata_clear2 <- mydata_clear2[-index2, ]
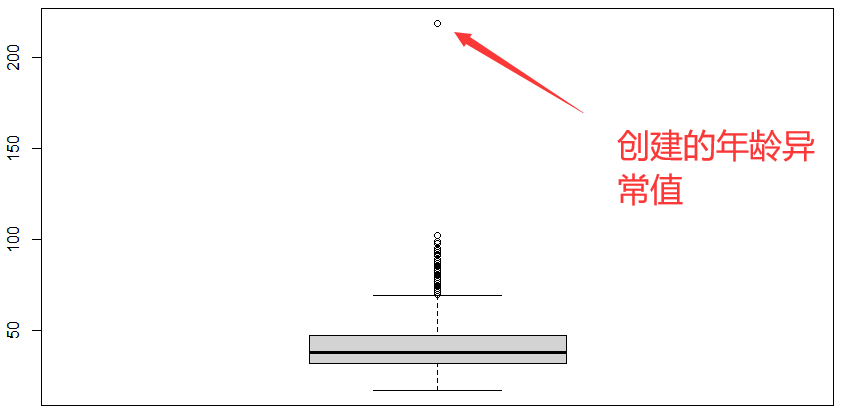
2.9 创建异常值
set.seed(1234)
#随机种子理解为:编号xxx的随机数发生,为了保证每次实验一致
index <- sample(1:nrow(mydata_clear2),5)
#sample(x,size,replace = FALSE)
#x为整体数据,以向量形式给出;
#size为抽取样本的数目;
#replace如果为F不重复抽样,T重复抽样,size<x
#nrow()函数用于返回指定矩阵的行数
mydata_clear2$age[index] <- mydata_clear2$age[index] * 3
#故意随机改变5个数据的index值
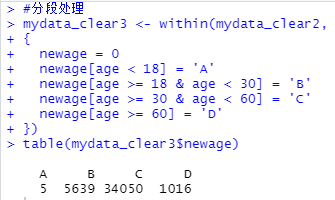
2.10 分段处理
#设置分段要求,即赋值
mydata_clear3 <- within(mydata_clear2,
{
newage = 0
newage[age < 18] = 'A'
newage[age >= 18 & age < 30] = 'B'
newage[age >= 30 & age < 60] = 'C'
newage[age >= 60] = 'D'
})
#table()查看统计
table(mydata_clear3$newage)
2.11 分层抽样
#安装caret程序包相关程序包
if(!suppressWarnings(require('caret'))){
install.packages('caret')
require('caret')
}
#createDataPartition()函数对y变量分层抽样
index3 <- createDataPartition(mydata_clear3$y, p = 0.8, list = F)
newdata <- mydata_clear3[index3, ]
#将抽样的数据放入newdata中
#p:用于训练的数据百分比
#list:逻辑-结果应该在一个列表(TRUE)或amatrix中,行数等于floor(p*length(y))和times列
#list = F理解为拆分完不在同一个表中

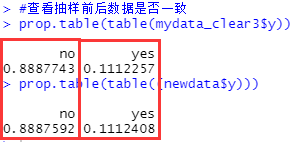
#查看抽样前后数据是否一致
prop.table(table(mydata_clear3$y))
prop.table(table((newdata$y)))
#发现抽样前和抽样后的数据在 y 上比较一致,证明这次分层抽样是成功
资料
Reference
R语言 set.seed()函数–junjunang–博客园














 1586
1586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









