







 本文介绍SQL语言的发展历程、特点及语法概貌,并详细阐述数据定义功能,包括模式、数据类型、基本表、索引和视图的创建与管理。
本文介绍SQL语言的发展历程、特点及语法概貌,并详细阐述数据定义功能,包括模式、数据类型、基本表、索引和视图的创建与管理。
文章目录
前言
本文主要讲解了SQL语言的概述性内容,以及SQL语言中的一些语法定义和数据格式的定义。
一、SQL概述
1.SQL语言的产生和发展
1972年,IBM公司开始研制实验型关系数据库管理系统SYSTEM R,其配备的查询语言称为SQUARE(Specifying Queries As Relational Expression )语言,语言中使用了较多的数学符号。
1974年,Boyce和Chamberlin把SQUARE修改为SEQUEL (Structured English Query Language )语言。后来SEQUEL简称为SQL(Structured Query Language ),即“结构式查询语言”,SQL的发音仍“sequel”。现在SQL已经成为一个标准 。
2.SQL语言支持关系数据库的三级模式
用户用SQL语言对基本表和视图进行操作
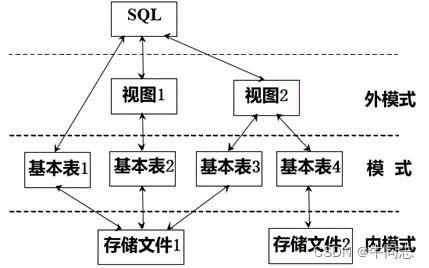
(1)基本表
1.本身独立存在的表, 一个关系对应一个表。(在关系型数据库中,表往往被称作“关系”)
2.一个(或多个)基本表对应一个存储文件。
3.一个表可以带若干索引, 索引也存放在存储文件中。
(2)存储文件
1.存储文件的逻辑结构组成了关系数据库的内模式
2.存储文件的物理结构是任意的, 对用户是透明的。
(3)视图
1.从一个或几个基本表或视图导出的表
2.是虚表, 只存放视图的定义而不存放对应数据
3.SQL语言的特点
(1)综合统一
1.SQL语言包含数据定义语言(DDL,data definition language),数据操纵语言(DML,data manipulation language),数据控制语言(DCL, Data Control Language )功能于一体。
2.可以独立完成数据库生命周期中的全部活动:
1.定义和修改、删除关系模式,定义和删除视图,插入数据,建立数据库;
2.对数据库中的数据进行查询和更新;
3.数据库重构和维护
4.数据库安全性、完整性控制,以及事务控制
5.嵌入式SQL和动态SQL定义
3.用户数据库投入运行后,可根据需要随时逐步修改模式,不影响数据库的运行。
4.数据操作符统一
(2)非过程语言
对于使用SQL语言来说,使用者只要提出“做什么”,无须了解存取路径,也不需要了解数据如何进行存取。存取路径的选择以及SQL的操作过程由系统自动完成。
(3)面向集合
SQL采用集合操作方式:
1.操作对象、查找结果可以是元组的集合
2.一次插入、删除、更新操作的对象可以是元组的集合
(4)以同一种语法结构提供多种使用方式
SQL是独立的语言,能够独立地用于联机交互的使用方式
SQL又是嵌入式语言,SQL能够嵌入到高级语言(例如C,C++,Java)程序中,供程序员设计程序时使用
4.SQL的语法概貌
(1)SQL的核心动词
| SQL功能 | 操作符 |
| 数据查询 | SELECT |
| 数据定义 | CREATE,ALTER,DROP |
| 数据操作 | INSERT,UPDATE,DELETE |
| 数据控制 | GRANT,REVOKE |
(2)SQL语言编写规则
1.SQL关键字不区分大小写
2.对象名和列名不区分大小写
3.字符值和日期值区分大小写
4.一条SQL语句可以单行或多行编写
二、数据定义
SQL的数据定义功能包括数据库定义、表定义、视图和索引的定义。
| 操作对象 | 创建 | 删除 | 修改 |
| 数据库 | CREATE DATABASE | DROP DATABASE | |
| 表 | CREATE TABLE | DROP TABLE | ALTER TABLE |
| 索引 | CREATE INDEX | DROP INDEX | |
| 视图 | CREATE VIEW | DROP VIEW |
1.模式
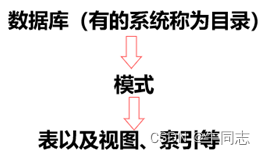
(1)模式的概念
指一系列逻辑数据结构或对象的集合
(2)模式的相关规则
1.模式与用户相对应,一个模式只能被一个数据库用户所拥有,并且模式的名称与这个用户的名称相同。
2.通常情况下,用户所创建数据库对象都保存在与自己同名的模式中。
3.同一模式中数据库对象的名称必须惟一,而在不同模式中的数据库对象可以同名。
4.默认情况下,用户引用的对象是与自己同名模式中的对象,如果要引用其他模式中的对象,需要在该对象名之前指明对象所属模式。
(3)定义模式
例子1:
CREATE SCHEMA “S-T” AUTHORIZATION WANG;
为用户WANG定义一个学生-课程模式“S-T”
例子2:
CREATE SCHEMA AUTHORIZATION WANG;
例2没有指定模式名,此时模式名默认为用户名。
定义模式实际上定义了一个命名空间。,在这个空间中可以定义该模式包含的数据库对象,例如基本表、视图、索引等。
在CREATE SCHEMA中可以接受CREATE TABLE,CREATE VIEW和GRANT子句.
创建模式的标准语法规则为:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>[<表定义子句>|<视图定义子句>|<授权定义子句>]
例子3:
CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1 (COL1 SMALLINT,
COL2 INT,
COL3 CHAR(20),
COL4 NUMERIC(10,3),
COL5 DECIMAL(5,2) );
为用户ZHANG创建了一个模式TEST,并且在其中定义一个表TAB1
(表的定义将在下文描述)
(4)删除模式
删除模式的标准语法规则为:
DELETE SCHEMA <模式名> <CASCADE|RESTRICT>
1.CASCADE(级联)
删除模式的同时把该模式中所有的数据库对象全部删除
2.RESTRICT(限制)
如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行。
仅当该模式中没有任何下属的对象时才能执行。
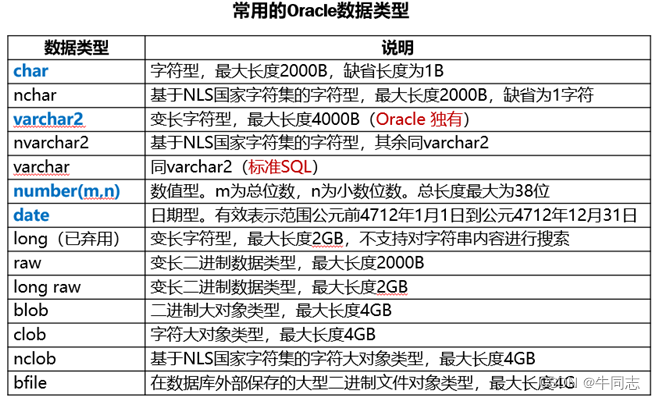
2.数据类型(域)
一个属性选用哪种数据类型要根据实际情况来决定,一般要从两个方面来考虑:
1.取值范围
2.做哪些运算
3.基本表
(1)定义基本表
命名规则和约定(表和列名):
1.必须以字母开头
2.1-30个字符长度
3.只允许包含A–Z, a–z, 0–9, _, $, and #
4.在一个模式内保证命名的唯一
5.不能使用Oracle内部的关键字
一般格式为:
CREATE TABLE <表名>
(<列名> <数据类型> [列级完整性约束条件]
,[<列名> <数据类型> [列级完整性约束条件]]
……
,[<表级完整性约束性条件>]);
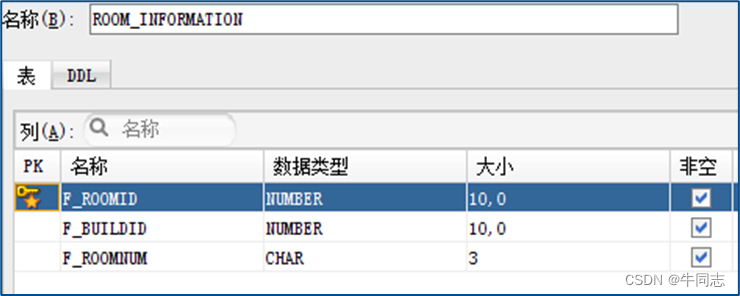
例子1:
CREATE TABLE ROOM_INFORMATION
(
F_ROOMID NUMBER(10,0) NOT NULL
,F_BUILDID NUMBER(10,0) NOT NULL
,F_ROOMNUM CHAR(3) NOT NULL
,CONSTRAINT ROMM_INFORMATION_PK PRIMARY KEY
(
F_ROOMID
)
ENABLE
);
(2)修改基本表
修改基本表的一般格式:
ALTER TABLE <表名>
[ADD <新列名> <数据类型> [完整性约束]]
[DROP <完整性约束名>]
[ALTER COLUMN <列名> <数据类型>];
其中
1.<表名>是要修改的基本表。
2.ADD子句用于增加新列和新的完整性约束条件
3.DROP子句用于删除指定的完整性约束条件
4.ALTER COLUMN子句用于修改原有的列定义。包括修改列名和数据类型。
例子1:
ALTER TABLE ROOM_INFORMATION ADD F_ROOMATTR VARCHAR2(10);
向ROOM_INFORMATION中,增加一列房间属性字段,其数据类型为varchr2(10)
例子2:
ALTER TABLE ROOM_INFORMATION ALTER COLUMN F_ROOMATTR VARCHAR2(20);
新加的房间属性字段,其varchar(10)不够存储当前值,需扩大为varchar2(20)
注意:
无论基本表中原来是否已有数据,新增加的列一律为空值。
修改原有的列定义有可能会破坏已有数据。
(3)删除基本表
一般格式为;
DROP TABLE <表名> [RESTRICT|CASCADE];
1.缺省情况是RESTRICT。
2.若选择RESTRICT:则该表的删除是有限制条件的。
欲删除的基本表不能被其他表的约束所引用(如CHECK,FOREIGN KEY等约束),不能有视图,不能有触发器(trigger),不能有存储过程或函数等。如果存在这些依赖该表的对象,则此表不能被删除。
3.若选择CASCADE:则该表的删除没有限制条件。在删除基本表的同时,相关的依赖对象,例如视图,都将被一起删除。
4.索引
索引:包含键(表或视图中的一个或多个列所生成),以及指针(映射到数据的存储位置的指针)
(1)索引的规则
1.索引的创建和维护由DBA和DBMS完成
- 索引由DBA或表的拥有者负责创建和撤消,其他用户不能随意创建和撤消索引。
- 索引由系统自动选择和维护。(不需要用户指定使用索引,也不需要用户打开索引或对索引执行重索引操作,这些工作都由DBMS自动完成)。
2.是否创建索引取决于表的数据量大小和对查询的要求
- 基本表中记录的数量越多,记录越长,越有必要创建索引,创建索引后加快查询速度的效果越明显。
- 记录较少的基本表,创建索引意义不大。
- 索引要根据数据查询或处理的要求而创建(对那些查询频度高、实时性要求高的数据一定要建立索引,否则不必考虑创建索引的问题)。
3.一个基本表,不要建过多索引
- 索引文件占用文件目录和存储空间,索引过多会使系统负担加重。
- 索引需要自身维护,当基本表的数据增加、删除或修改时,索引文件要随之变化,以保持与基本表一致。
- 索引过多会影响数据增、删、改的速度。
(2)避免使用索引的情形
⑴ 包含太多重复值的列;
⑵ 查询中很少被引用的列;
⑶ 值特别长的列;
⑷ 查询返回率很高的列(where sex=‘M’);
⑸ 具有很多NULL值的列;
⑹ 需要经常插、删、改的列;
⑺ 记录较少的基本表;
⑻ 需进行频繁、大批量数据更新的基本表。
(3)建立索引
一般格式为:
CREATE [UNIQUE][CLUSTERED] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>]]…);
1.索引可以建立在该表的一列或多列上,各列名之间用逗号分隔。每个<列名> 后面还可以用<次序>指定索引值的排列次序,可选ASC(升序,默认是升序)或DESC(降序)。
2.UNIQUE表明此索引的每一个索引值只对应唯一的数据记录。
3.CLUSTERED表示要建立的索引是聚簇索引,所谓聚簇索引是指索引项的顺序与表中记录的物理顺序一致的索引组织。
(4)删除索引
一般格式:
DROP INDEX <索引名>;
5.视图
(1)建立视图
一般格式;
CREATE VIEW <视图名> [(<列名>[,<列名>]…)]AS
<子查询>[WITH CHECK OPTION];
注意:
- 子查询可以是任意复杂的SELECT语句,但通常不允许含有ORDER BY子句和DISTINCT短语。
- WITH CHECK OPTION表示对视图进行UPDATE,INSERT和DELETE操作时要保证更新、插入或删除的行满足视图定义中的谓词条件(即子查询中的条件表达式)。
(2)删除视图
一般格式:
DROP VIEW <视图名> [CASCADE];
视图删除后,视图的定义将从数据字典中被删除。如果该视图上还导出了其他视图,则使用CASCADE级联删除语句,就可以把该视图和由它导出的所有视图一起删除。
基本表删除后,由该基本表导出的所有视图(定义)没有被删除,但均已无法使用了。删除这些视图(定义)需要使用DROP VIEW语句。
(3)更新视图
1.是指通过视图来插入、删除和修改数据。
2.因视图是虚表,故对视图的更新,最终要转化为对基本表的更新。
3.为防止用户通过视图进行更新数据,有意或无意对不属于视图范围内的基本表数据进行操作,可在定义视图时加上[WITH CHECK OPTION]子句。
不允许对视图进行数据更新的操作:
1.由两个以上基本表导出的视图
2.视图的列来自列表达式函数
3.视图中有分组子句或使用DISTINCT短语
4.视图定义中有嵌套查询,且内层查询中涉及与外层一样的导出该视图的基本表
5.在一个不允许更新的视图上定义的视图
总结
文章不妥之处请读者包容指正。
对于数据库基本概念有疑问的读者可以参考:
1.关系型数据库(二)—关系代数
2.关系型数据库(一)—关系数据模型与关系
3.数据库系统概述



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











