






Yang BAO -- Antai College of Economics and Management, Shanghai Jiao Tong University
Bin KE -- Department of Accounting, NUS Business School, National University of Singapore
Bin LI -- Department of Finance, Economics and Management School, Wuhan University
Julia YU -- McIntire School of Commerce, University of Virginia
Jie ZHANG -- School of Computer Engineering, Nanyang Technological University
Journal of Accounting Research
Received 7 October 2015; accepted 1 October 2019
论文简介: 该研究运用机器学习方法构建了一个前沿的财务舞弊预测模型。研究结果表明,在构建模型的过程中,将领域专业知识与机器学习方法相结合具有显著价值。在模型输入变量的选取上,该研究以现有会计理论为基础,但有别于以往的会计研究,作者直接采用原始会计数据而非财务比率。在方法选择上,该研究没有采用传统的Logistic回归方法,而是使用了机器学习领域最具优势的方法之一——集成学习。在模型评估方面,该研究引入了一个更适合财务舞弊预测任务的新型性能评价指标,这一指标在排序问题中得到了广泛应用。基于同一组理论驱动的原始会计数据,作者提出的新型财务舞弊预测模型显著优于两个基准模型:一是Dechow等人提出的基于财务比率的Logistic回归模型,二是Cecchini等人开发的支持向量机模型(该模型通过金融核函数将原始会计数据映射为更全面的比率指标)。
表1的统计显示,1979-2014年间共检测出1,171个舞弊样本年度。然而,每年被发现的舞弊案例比例都很低,普遍不超过上市公司总数的1%。这种低检出率反映了舞弊预测工作始终面临的巨大挑战。在2003-2014年的测试期间,观察到的舞弊比例更是呈现出持续下降的趋势:2003-2005年间的平均舞弊比例为0.94%,2006-2008年间降至0.51%,2009-2011年间降至0.46%,到2012-2014年间更是降至0.21%。假如我们认为2003-2014年间舞弊的实际发生率并未改变,那么表1反映的这种舞弊检出率下降趋势就表明,未被发现的舞弊案例可能在逐年增加。这一现象与我们前文提到的2008年金融危机后监管机构削弱会计舞弊执法力度的情况不谋而合。另一种可能的解释是,金融危机后监管机构用于调查会计舞弊的资源减少,导致完成舞弊调查所需的时间变长。由于每年被发现的舞弊样本数量本来就很少,如果测试年度中存在大量未被发现的舞弊案例,很可能会导致样本外测试的结果产生根本性偏差。因此,我们将2003-2008年作为主要测试样本。同时,为了增强研究结果的可靠性,我们还使用了2003-2005年、2003-2011年和2003-2014年等其他时间区间进行了测试。

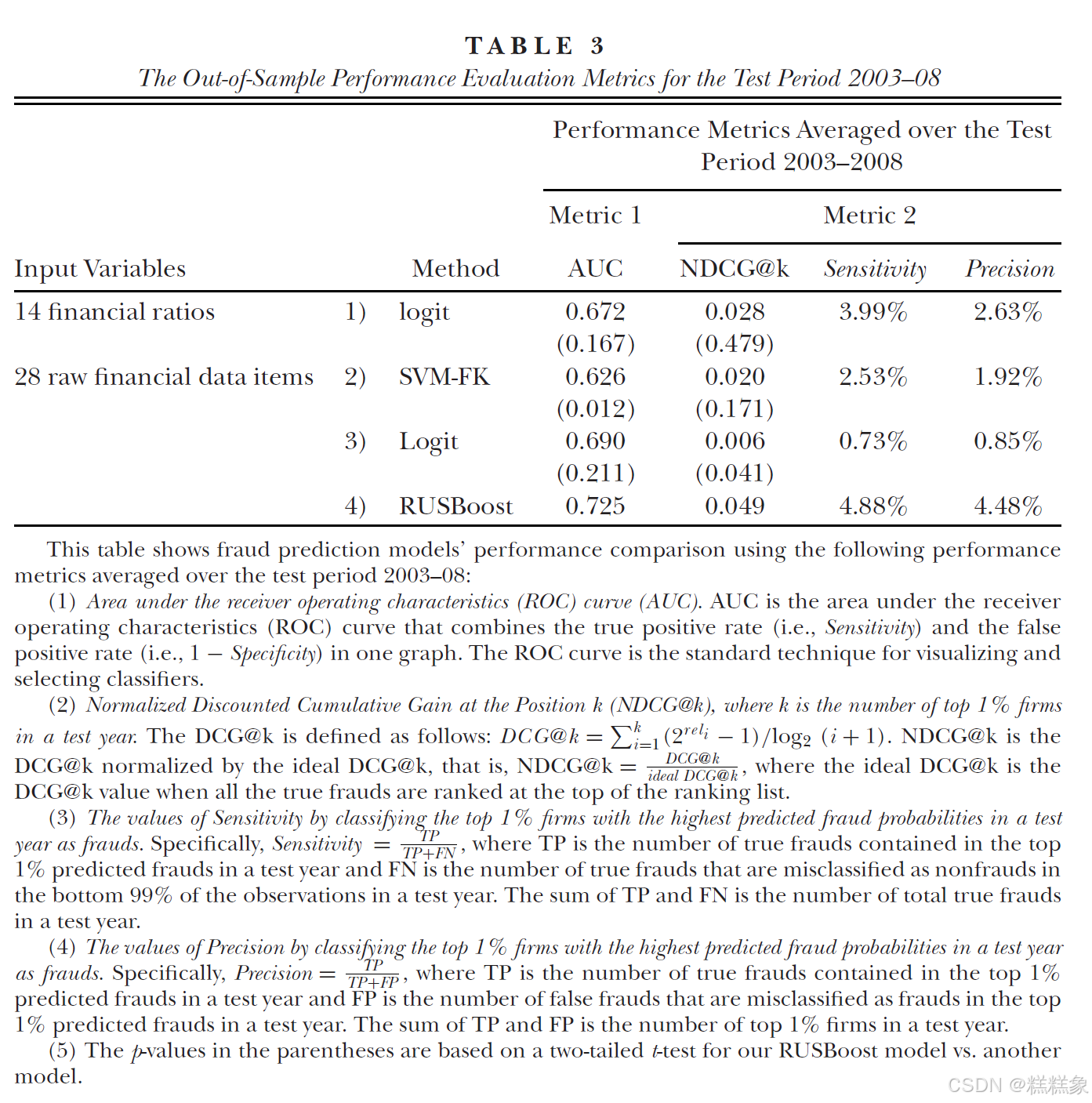
表3报告了Dechow等人模型在2003-2008年测试期间的样本外性能评估结果,评估指标包括AUC和NDCG@k。表3同时也列出了我们的集成学习模型与其他模型之间配对t检验的结果(括号中给出)。不过,由于这类t检验只有6个观测值(检验效力较低),我们在下文推断中并不依赖这些检验结果,而是着重关注不同舞弊检测模型在这两个性能评估指标上的差异程度。
与Dechow等人(2011年)的研究结果一致,三个测试年度的平均AUC值为0.672,远高于随机猜测的临界值0.50。平均NDCG@k值为0.028。敏感度(定义见表3)的平均值为3.99%,这表明在预测舞弊概率最高的前1%观测值中,包含了总体中3.99%的真实舞弊案例。同样,精确度(定义见表3)的平均值为2.63%,这意味着在预测舞弊概率最高的前1%观测值中,仅有2.63%是真实的舞弊案例。尽管这个比例看似不高,但相比2003-2008年完整测试样本中0.73%的无条件平均舞弊发生率而言,已经高出很多。
-
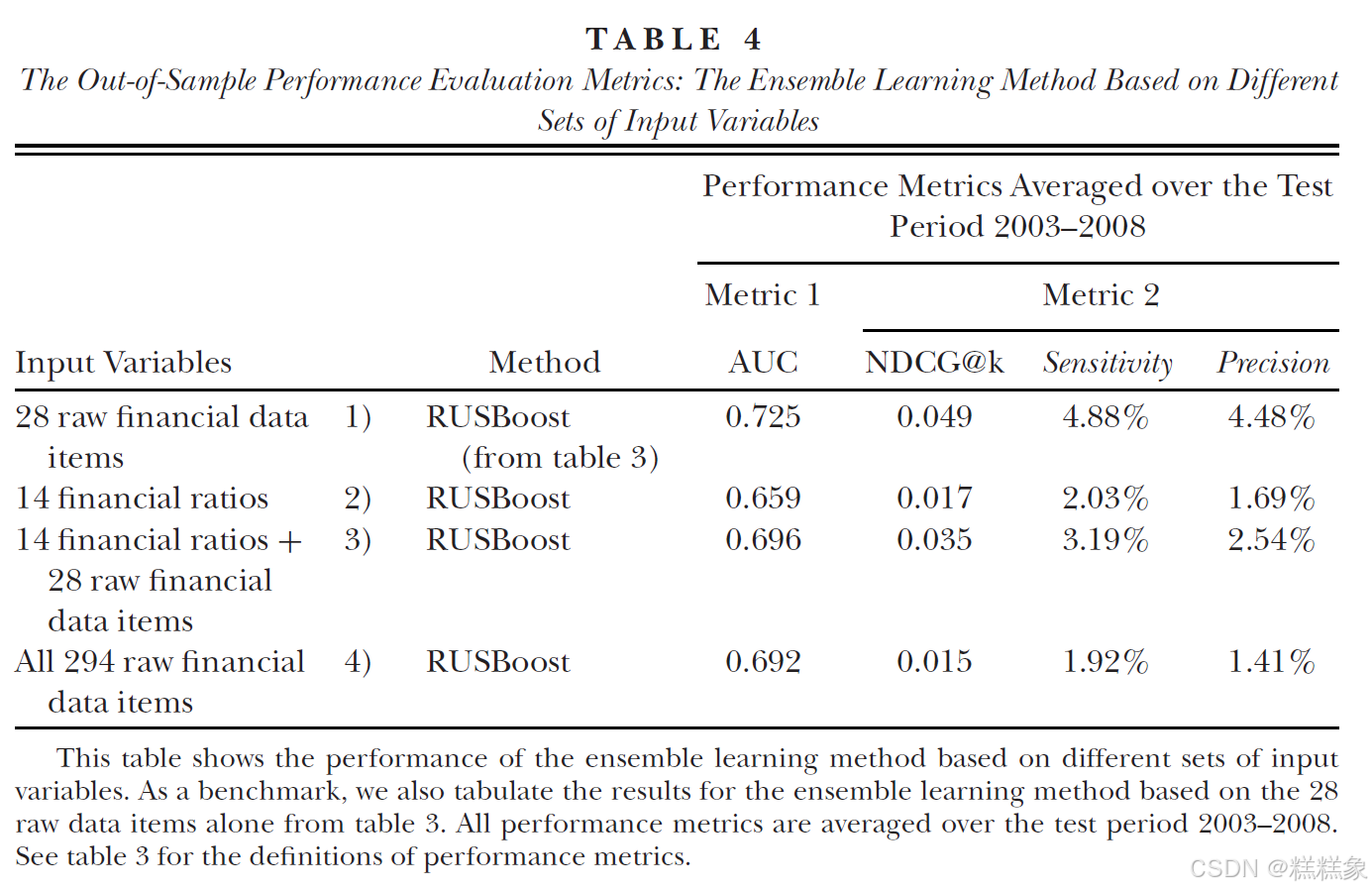
本文进一步探讨是否可以通过单独使用14个财务比率,或同时使用28个原始数据项和14个财务比率来提升集成学习方法的预测效果。表4报告了这两种替代模型的样本外性能统计结果。
-
研究发现,这两种替代的集成学习模型并未表现出比单独基于28个原始数据项的集成学习模型更优的性能。这一发现支持了我们的推测:当采用灵活而强大的机器学习方法处理28个原始数据项时,由这些原始数据计算得出的财务比率在舞弊预测中不再具有增量效用。
-
模型表现随特征维度增加而下降的现象可以从以下几个方面解释:
- 首先,这反映了机器学习中的"维度灾难"(Curse of Dimensionality)问题。当特征维度从28个增加到294个时,在样本数量不变的情况下,样本空间会变得极其稀疏。这种稀疏性可以理解为:在低维空间(如28维)中相对密集的样本点,被投射到高维空间(如294维)后,样本点之间的距离急剧增加,导致每个样本点需要覆盖的空间范围显著扩大。这使得模型在进行预测时难以找到充分的相似样本作为参考,从而影响了预测准确性。
- 其次,特征冗余和噪声的问题不容忽视。294个原始财务数据中可能存在大量高度相关的变量,这些冗余特征不仅没有为模型提供额外的有效信息,反而增加了模型的复杂度。同时,部分变量可能与舞弊预测关系微弱,这些噪声特征的引入反而干扰了模型对关键模式的识别和学习。
- 第三,从信息密度的角度来看,28个经过筛选的原始数据项很可能代表了最具预测价值的财务指标。当引入大量额外变量时,这些核心指标的预测能力被稀释,反而降低了模型的整体表现。这一现象印证了特征选择在模型构建中的重要性,即精心挑选的少量高质量特征往往优于包含所有可能特征的数据集。
- 最后,这个问题还涉及模型复杂度与样本量之间的平衡。当特征数量大幅增加时,模型需要指数级增长的训练样本来充分学习这些特征之间的复杂关系。如果训练样本的规模相对有限,模型就难以准确捕捉高维特征空间中的真实模式,最终导致预测性能的下降。这说明在构建财务舞弊预测模型时,需要审慎权衡特征数量与可用样本规模之间的关系。
-
2003-2014年期间观察到的舞弊频率几乎呈单调下降趋势,这种下降的一个可能原因是存在未被发现的舞弊案例,这一情况在金融危机后的时期尤为明显。因此,在表3中我们将测试期间限定在2003-2008年。为验证主要研究结果的稳健性,我们采用了以下几个不同的测试样本区间重复了表3的分析:2003-2005年、2003-2011年和2003-2014年。基于3.2节所述原因,我们有理由认为未被发现的舞弊问题随时间推移而愈发严重。因此,使用更长测试期间所得到的性能评估结果的可靠性相对较低。
-
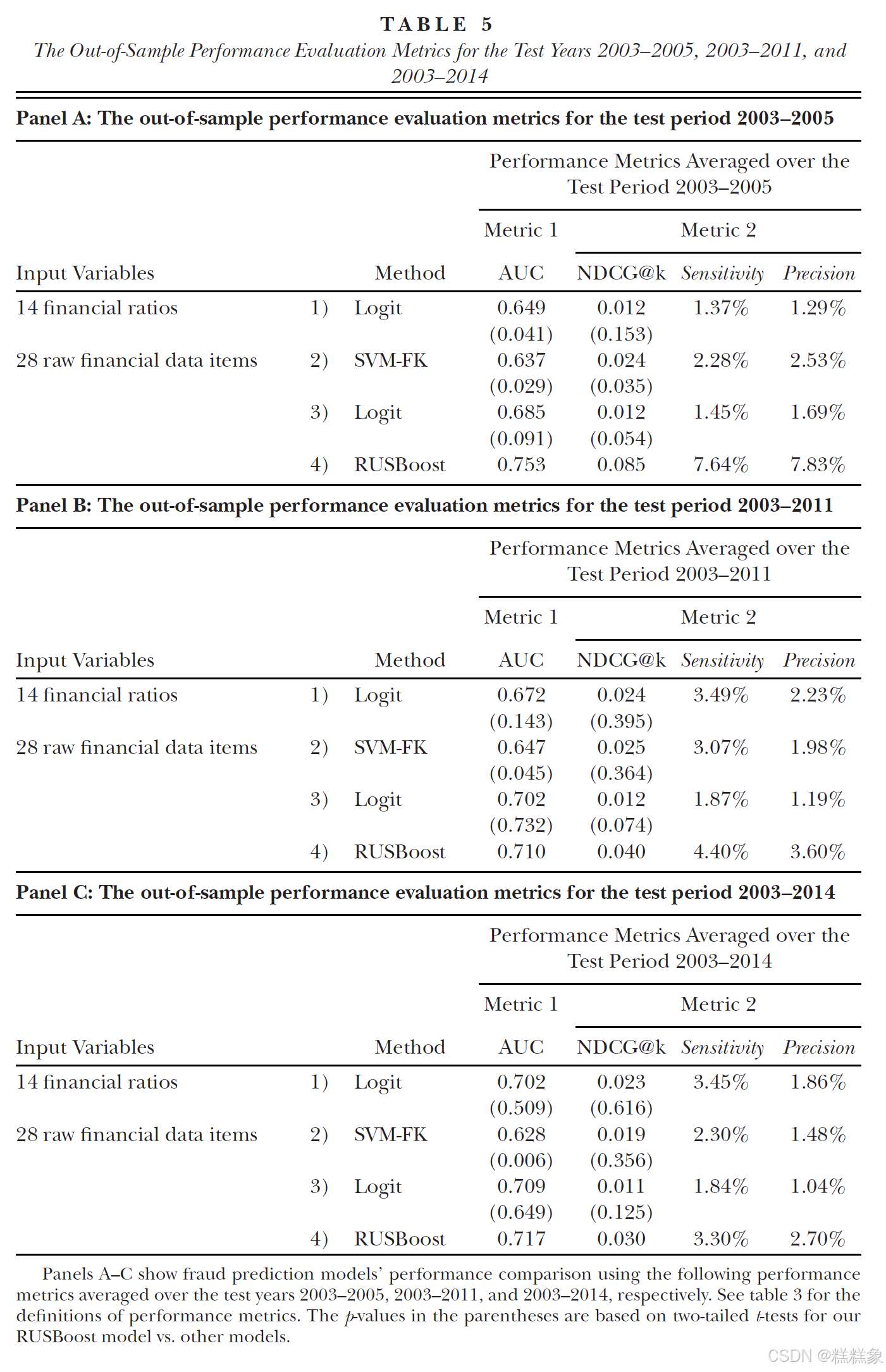
表5全面展示了研究结果。其中,A至C面板分别呈现了2003-2005年、2003-2011年和2003-2014年三个时期的分析数据。通过分析,我们得出了以下几个重要发现:
- 第一,在所有测试区间中,无论是以AUC还是NDCG@k作为评价标准,集成学习模型始终表现最佳。这一结果有力证实了该模型的稳健性。
- 第二,随着测试期间的延长,集成学习模型的性能呈现出明显的下降趋势。具体而言,从2003-2005年到2003-2008年,再到2003-2011年和2003-2014年,模型表现逐步走低。值得注意的是,在最早的测试区间(2003-2005年),基于原始数据的集成学习模型展现出最优异的性能,其AUC和NDCG@k平均值分别高达0.753和0.085,远超表3中2003-2008年测试期间所得到的0.725和0.049。这一现象表明,那些未被发现的舞弊案例很可能严重影响了集成学习模型的预测效果。
- 第三,从AUC指标来看,Dechow等人提出的模型在2003-2005年到2003-2014年期间略有性能提升,这与一般认知不符。然而,从NDCG@k指标来看却未发现类似趋势。至于Cecchini等人的模型,其性能在不同时期则没有表现出明显的变化规律。
-
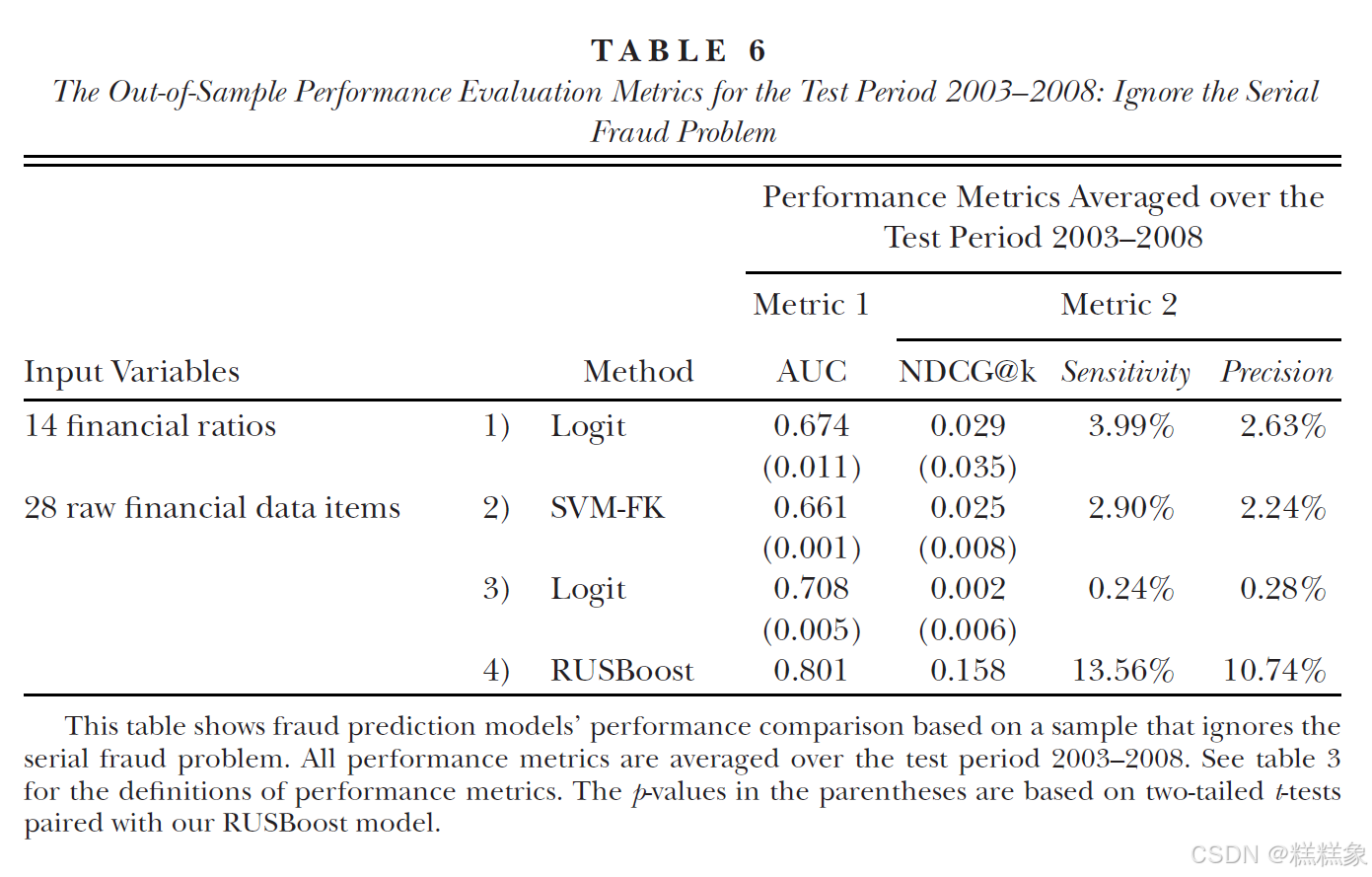
本研究前面报告的所有结果都基于一个排除了连续舞弊影响的样本。以往的舞弊预测研究大多没有探讨连续舞弊对预测效果的影响。因此,在本节中,我们以2003-2008年为测试期间,重新运行了所有舞弊预测模型,这次特意保留了连续舞弊样本。研究结果见表6。
-
与我们预期一致,当保留连续舞弊样本时,表6中集成学习模型的表现较表3中同一模型有了最为显著的提升。这充分说明了在构建舞弊预测模型时,妥善处理连续舞弊问题的必要性。值得注意的是,尽管各模型的具体表现有所不同,但表6中模型的整体性能排名与表3基本保持一致。这表明连续舞弊问题并未对本研究的核心结论产生实质性影响。
-
表7的A部分报告了本研究集成学习模型在六个测试年度中28个原始数据项的平均重要性描述性统计结果。这28个原始数据项按平均特征重要性从高到低排序。对集成学习模型卓越性能贡献最大的前10个重要特征(或原始数据项)按重要性降序排列如下:(1)已发行普通股数量;(2)流动资产总额;(3)普通股和优先股发行;(4)固定资产总额;(5)应付账款;(6)现金及短期投资;(7)年度财年收盘价;(8)留存收益;(9)存货总额;(10)普通股权益总额。
-
值得注意的是,"已发行普通股数量"和"年度财年收盘价"为舞弊预测提供了重要信息。我们推测"已发行普通股数量"之所以能有效预测会计舞弊,很可能是因为实施舞弊的公司往往会发行普通股(Dechow、Sloan和Sweeney,1995;Dechow等,2011)。同样,"年度财年收盘价"之所以能提供有价值的舞弊可能性信息,是因为在财务报表失实期间,公司员工和其他相关利益相关者往往会进行知情交易(Summers和Sweeney,1998;Kedia和Philippon,2007;Agrawal和Cooper,2015)

-
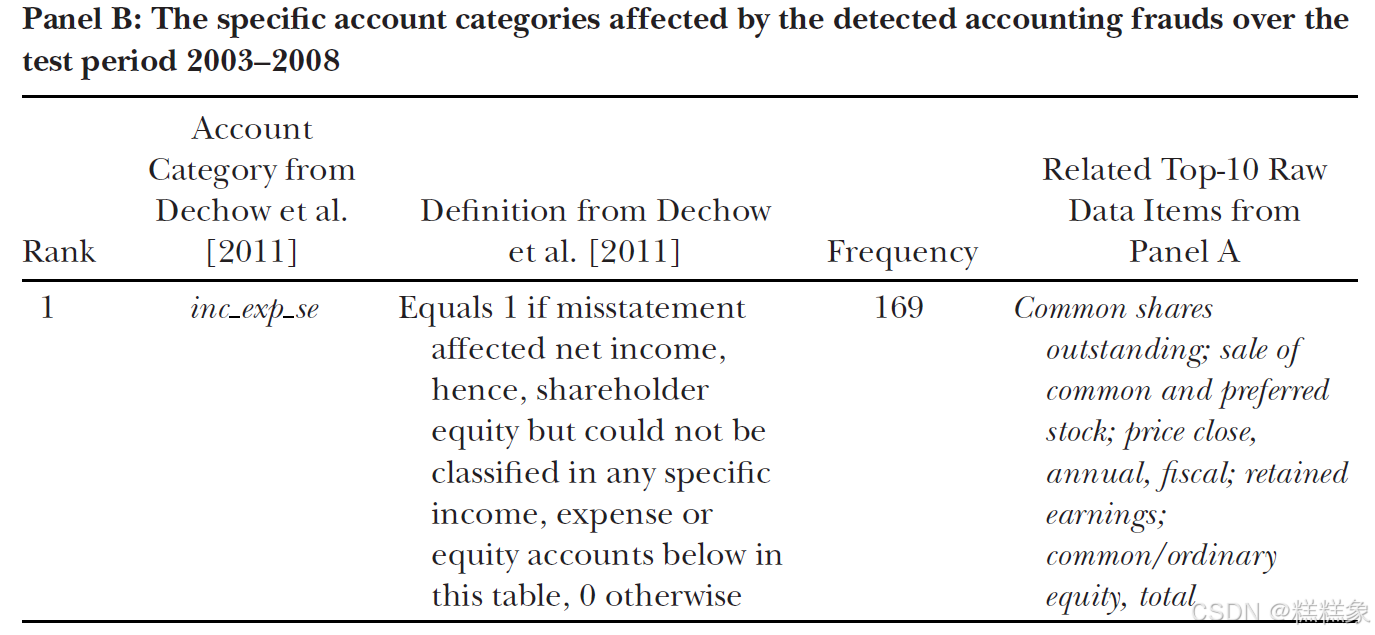
为了对比集成学习模型的表现,表7的B部分列出了2003-2008年期间AAER报告中受到舞弊影响的具体财务报表科目,并按照各科目受舞弊影响的频率进行排序。随后,我们将A部分中排名前10的原始会计数据项与B部分中的这些具体科目进行对应。B部分的数据(包括11个具体科目类别)直接来源于Dechow等(2011)的研究,而他们的数据则是从AAER中收集整理的。
-
对比发现,我们最后一列中排名前10的原始数据项与Dechow等研究中第二列排名靠前的具体科目有很大的重合度。这一证据表明,我们的集成学习方法能够有效识别出最常受到舞弊影响的具体会计科目。另一个值得关注的发现是,根据Dechow等(2011)的研究,受舞弊影响最频繁的科目类别是"inc exp se"。这是表7中B部分一个混合类别,用于归集那些无法明确划分为收入、费用或权益类的受影响科目。与"inc exp se"对应的原始数据项包括"已发行普通股数量"、"普通股和优先股发行"、"年度财年收盘价"、"留存收益"和"普通股权益总额"。有趣的是,正如表7的A部分所示,这些原始数据项恰恰是最重要的舞弊预测指标。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









