







目录
习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果编辑
习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果
习题6-3 当使用公式(6.50)作为循环神经网络得状态更新公式时,分析其可能存在梯度爆炸的原因并给出解决办法.
公式(6.50)为:
在公式 为在第K时刻函数g(*)的输入,在计算公式(6.34)中的误差项时,梯度可能过大,从而导致梯度爆炸问题。
解决办法:增加门控装置,使用LSTM网络。
习题6-4 推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果编辑

手动推导

避免梯度消失的效果

这只是一步的推导,如果是多个时间步,就是多个类似公式的累乘。从这一步的结果中我们可以发现,其结果的取值范围并不一定局限在[0,1]中,而是有可能大于1的。这个由LSTM自身的权值决定,依靠学习得到权值去控制依赖的长度,这便是LSTM缓解梯度消失的真相。综上可以总结为两个事实:
1、cell state传播函数中的“加法”结构确实起了一定作用,它使得导数有可能大于1;
2、LSTM中逻辑门的参数可以一定程度控制不同时间步梯度消失的程度。
习题6-5 推导GRU网络中参数的梯度,并分析其避免梯度消失的效果
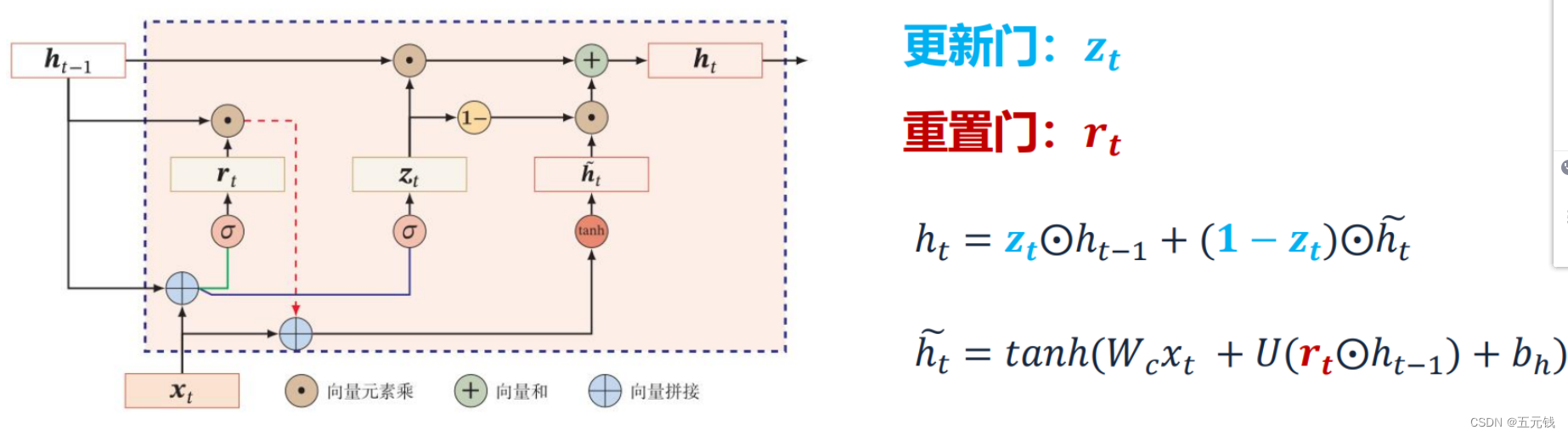
GRU它引⼊了重置⻔(reset gate)和更新⻔(update gate) 的概念,从而修改了循环神经⽹络中隐藏状态的计算⽅式。


LSTM与GRU二者结构十分相似,不同在于:
新的记忆都是根据之前状态及输入进行计算,但是GRU中有一个重置门控制之前状态的进入量,而在LSTM里没有类似门;
产生新的状态方式不同,LSTM有两个不同的门,分别是遗忘门(forget gate)和输入门(input gate),而GRU只有一种更新门(update gate);
LSTM对新产生的状态可以通过输出门(output gate)进行调节,而GRU对输出无任何调节。
GRU的优点是这是个更加简单的模型,所以更容易创建一个更大的网络,而且它只有两个门,在计算性上也运行得更快,然后它可以扩大模型的规模。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









