






1、安装MySQL
·MySQL5.7版本——公司主流使用
2、MySQL初始
2.1 MySQL的客户端和服务端
MySQL也分为客户端和服务端,我们说的MySQL约定俗成的为MySQL的服务端。
MySQL服务端:数据库管理软件。 mysql
MySQL客户端:程序员使用的和数据库监护的软件
注意:一般的linux命令行当中使用的"mysql"指令为mysql的客户端。
扩展:
服务端为啥会有两个进程
mysql mysql——safe:守护进程,守护mysql
mysql_safe 当mysql挂掉的时候,快速拉起mysql.
2.2 启动MySQL服务端
启动: systemctl start mysql
关闭: systemctl stop mysql
重启: systemctl restart mysql
自启动: systemctl enable mysql
开机不启动: systemctl disable mysql
2.3 连接MySQL服务端
mysql -h [ 服务端所在IP地址] -P [服务端侦听端口] -u [用户名] -p [密码]
一般情况下,不输入-h ,默认连接本地(就是执行mysql客户端命令所在的机器)
不输入-P,默认的端口为3306
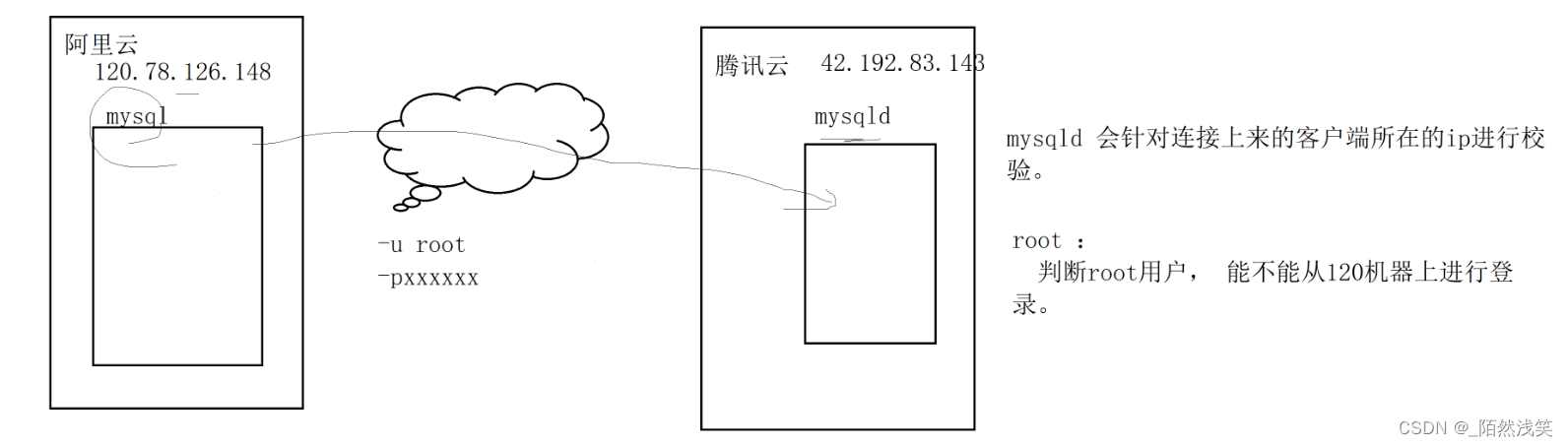
2.4 MySQL服务端,数据库,表的关系
mysql服务端是数据库管理软件
服务端可以管理多个数据库
每个数据库当中可以有多个表
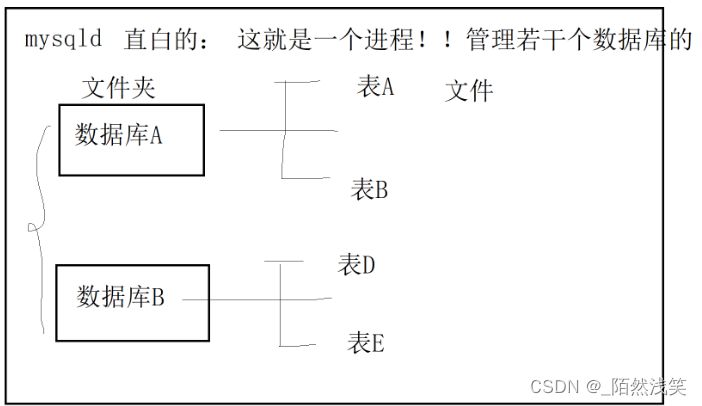
2.5 MySQL服务端分层认识
mysql:管理若干个数据库
连接层功能:
1、连接建立
1.1 跨网络,tcp
1.2 同一台机器,本地域套接字 AF_UNIX(进程间通信)
2、校验用户名和密码
3、校验客户端的ip地址
一般mysql刚安装好,默认创建的用户是不支持跨网络连接的

存储引擎:
数据库管理系统如何存储数据,如何为存储数据建立索引和如何更新、查询数据等技术的实现方法。
功能:1、执行sql
2、获取执行结果
3、结果返回给服务层
2.6 存储引擎
存储引擎分为MyTsAM() 和 InnoDB
InnoDB在并发执行数据库操作支持的更好,所以,企业都会选择更加”安全“的存储引擎
MyTsAM的优势在于读取的速度快,不支持事务。多用于web程序。
2.7 建立数据库demo测试
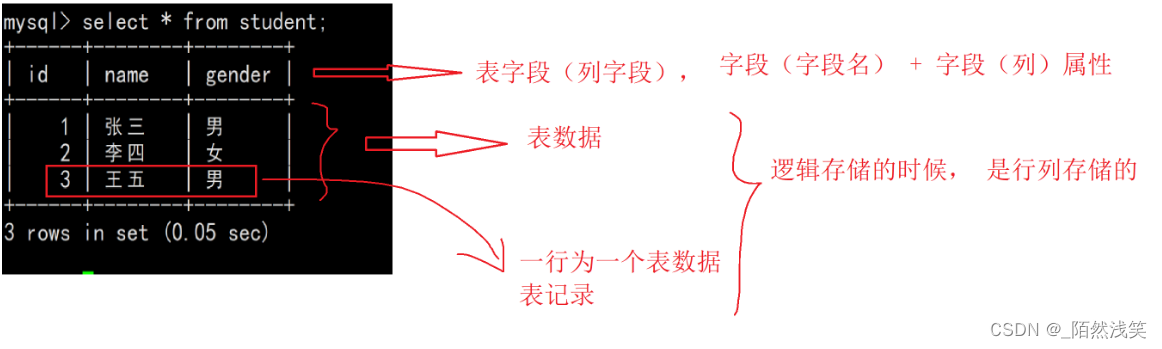
2.8 SQL语言的分类
DDL 【data fefinition language】 数据定义语言,用来维护存储数据库的结构
代表指令:create drop alter
DML【data manipulation language】 数据操控语言,用来对数据进行操作
代表指令:insert delete update
DML中又单独分了一个DOL,数据查询语言,代表指令:select
DCL【data control language】 数据控制语言,主要负责权限管理和事务
代表指令:grant revoke comit
3、库的操作
3.1 创建数据库
命令范式:create database [数据库名称] [字符集] [校对规则];
[字符集] : charset
[校对规则] : collation
字符集和校对规则都有默认值:
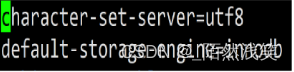
3.2 数据库字符集
3.2.1 字符集的选择决定了数据库能够存储的字符范围。例如,如果是ASCII,只能表示128字符。
3.2.2 系统默认的字符集,show variables like character_set_database
utf8:支持中文,所以想好要存储中文数据,就要选择这个字符集。最多3个字节表示一个字符
3.2.3 系统支持的字符集:show charset;
3.3 数据库校对规则
校对规则决定了当前数据库是否大小写敏感,会u对查询的排序起到影响。
总结:后缀为——ci 的不区分大小写。后缀为_bin 的区分大小写
3.4 操纵数据库
3.4.1 查看当中服务端管理多少数据库:show databases;
3.4.2 查看如何创建某个数据库的
show create database[数据库名字];
3.4.3 修改数据库属性:alter database [数据库名称] [属性]=[新属性];
3.4.4 删除数据库: drop database [数据库名称];
3.4.5 查看当前数据库连接状态: show processlist;
3.4.6 数据库的备份
备份:
mysqldump -P3306 -u -p [mima] -B 数据库名->数据库备份存储的文件路径
还原:
source 数据库备份存储的文件路径
3.4.7 数据库表的备份
备份:
mysqldump -P3306 -u root -p 数据库名 表名1 表名2 >:mytest.sql
还原:
如果备份一个数据库时,没有带上-B参数,在恢复数据库时,需要先创建空数据库,然后使用数据库,在使用source来还原。
4、表的操作
4.1、创建表
语法规则:
CREATE TABLE table_name(
field1 datatype,
field2 datatype,
field3 datatype,
)character set 字符集 collate 校对规则 engine 存储引擎;
字符集和校对规则不设置,默认采用数据库的字符集和校对规则
4.2、MyISAM的存储
xxx.frm: 表结构
xxx.MYD:表数据
xxx.MYI: 表索引
4.3、InnoDB的存储
.frm 文件:表结构文件
.ibd文件: 表数据文件
4.4、查看表结构
查看如何创建表: show create table [表名称]
查看表结构:desc [表名称]
4.5、修改表
增加列
alter table [表名称] add [列名称] [列属性] [comment [备注]] [after birthday];
如果没有after,默认是增加到最后
修改属性
alter table [表名称] modify [列名称] [列属性];
修改表名
alter table [表名称] change [老名称] [新名称]
修改列名
alter table[表名称] change [老名称] [新名称] [列类型]
4.6、删除表
删除列
alter table [表名称] drop [列名称]
该命令会将列的全部数据删除
4.7、简单的插入数据
insert into [表名称] values(val1,val2...);
4.8、全量查询数据
select *from [表名称];
5、数据类型
5.1 、数值类行
浮点数据类型:
float [(M.D) ]: 占用4个字节,M表示位数,D表示小数位数
精度保证:6~7位
double[(M,D)]:占用8个字节,M表示位数,D表示小数位数
精度保证:15~16位
decimal [(M,D)]:M表示位数,D,表示小数位数
理论上精度不会丢失,因为是按照字符串进行保存。但是在存储的时候,一定确定存储的小数和D的关系。
eg decimal(10,2):存入1.123,实际存入1.12
M,最大为65,D最大为30
5.2、文本类行
TEXT:大文本类行
5.3、二进制类行
BLOB:二进制类行
5.4、字符串类行
5.4.1、 固定长度字符串:
char(size):固定长度字符串,size是可以存储的长度,单位为字符,最长长度值可以为255
5.4.2、 可变长度字符串:
varchar(size):可变长度字符串,size表示字符长度,最大长度65535个字节
size最大多大?
·有1~3字节记录字符串多长,按照最大情况计算,所有剩余字节数量就为65532
·utf8字符集,字符占用的字节数量为1~3字节,按照最大3字节计算
65535/3=21844
总结:size的大小和字符集息息相关;
5.4.3、char和varchar比较
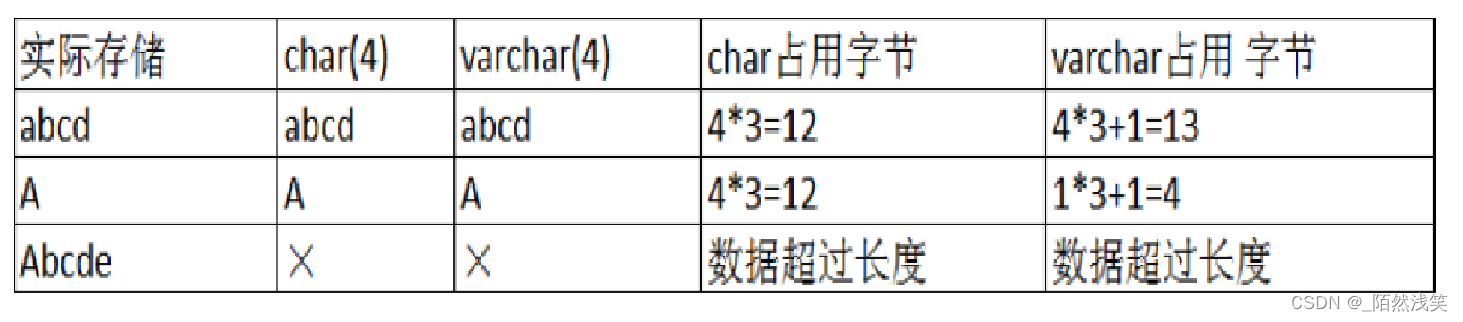
如何选择定长或变长字符串?
·如果数据确定长度都一样,就使用定长(char),比如:手机号
·如果数据长度有变化,就使用变长(varchar),比如:名字。但必须保证最长的能存进去。
·定长的磁盘空间比较浪费,但是效率高。
·定长的磁盘空间比较节省,但是效率低。
·定长的意义是,直接开辟好对应的空间。
·变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
5.4.4、时间/日期类行
常用的日期有如下三个:
date:日期 yyy-mm-dd,占用三字节
datetime 时间日期格式 yyy-mm-dd HH:ii:ss 表示范围从1000到9999,占用8字节
timestamp: 时间戳,从 1970年开始的yyy-mm-dd HH:ii:ss 格式和datetime完全一致,占用四字节
5.5、枚举类型
enum('选项1’,'选项2','选项3',....);
该设定只是提供了若干个选项的值,最终一个单元格中,实际中存储了其中一个值;
5.6、集合类型
set('选项1’,'选项2','选项3',....);
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;
集合查询使用find_in_set函数:
find_in_set(sub,str_list):如果 sub_list中 ,则返回下标;如果不在,返回0;
str_list用逗号分隔的字符串。
6、表的约束(指的是除了列字段类型约束之外的约束)
6.1、空属性
null : 可以为空
not null : 不可以为空
6.2、默认值
default [val];
当插入数据的时候,不插入设置有默认值的时候,采用默认值。
6.3、列描述
comment: 列描述,对于插入/删除/查询 没有影响。相当于是注释。
6.4、zerofill格式化输出
设置了zerofill 的字段会按照设定的宽度进行输出。如果本身宽度不够,高位补0。但是在真实存在存储的时候,还是按照原生的数字进行存储的。
例如:int (5) 在输出的时候,就会输入5位。
6.5、主键(主键约束/主键索引)
约束列字段:primary key
·不能为空,不能重复
·一张表只能有一个主键
·主键列通常为整数(方便索引建立)
创建主键的三种方式:
1、创建表时制定
1.1 直接在某个字段后面指定
create table [表名称] (字段1 字段类型1类型 primary key,...);
1.2 在所有字段后面进行指定
create table [表名称] (字段1 字段类型1类型,字段2 字段类型2类型,字段3 字段类型3类型,primary key(字段名称));
2、alter修改表结构
alter table [表名称] add primary key ([列名称])
删除主键:
alter 修改表结构
alter table [表名称] drop primary key
复合主键:
当表中的字段值有重复的可能,但是还想建立主键,可以使用多个列建立复合主键:
复合主键的列的值,在表当中是唯一的:
创建格式:
create table [表名称] (字段1 字段1类型,字段2 字段2类型,字段3 字段3类型,primary key (字段1名称,字段2名称));
6.6、自增长
auto_increment: 当对应的字段,不给值,会自动的被系统触发,系统会从当前字段中已经有的最大值+1操作,得到一个新的不同的值。
自增长的特点:
任何一个字段要做自增长,前提是本身是一个索引(key一栏有值)
自增长字段必须是整数
一张表最多只能有一个自增长
6.7、唯一键
一张表中往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以解决表中有多个字段需要唯一性约束的问题。
唯一i见的本质和主键大同小异,唯一键允许为空,而且可以多个为空,空子段不做唯一比较
唯一键:unique
不能重复,可以为空
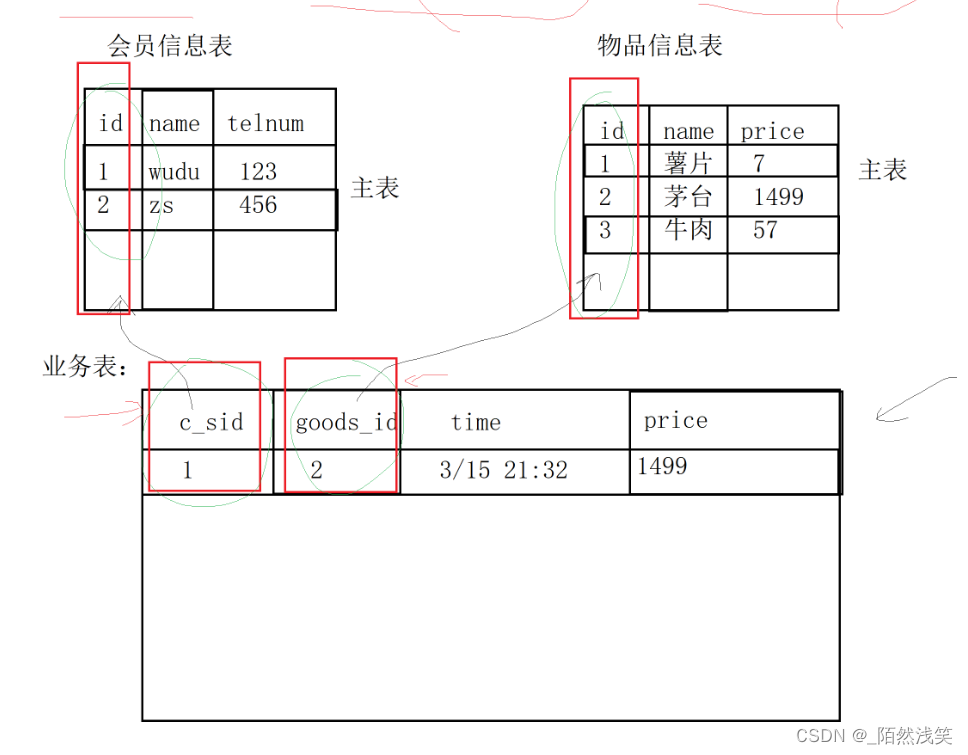
6.8、外键
外键定义了表和表之间的关系
两个表从逻辑上区别分为 主表和从表
外键的约束在从表上。
主表的字段需要为主键
从表定义的外键,本质上是向通过主表的字段值,来约束从表当中的外键列;
创建方式:
foreign key (字段名)references 主表(列):放在从表的时候,定义外表















 2072
2072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









