









1 主从复制
在复杂的业务系统中,有一句sql执行后导致锁表,并且这条sql的的执行时间有比较长,那么此sql执行的期间导致服务不可用,这样就会严重影响用户的体验度。
主从复制中分为「主服务器(master)「和」从服务器(slave)」,「主服务器负责写,而从服务器负责读」,Mysql的主从复制的过程是一个「异步的过程」。
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的
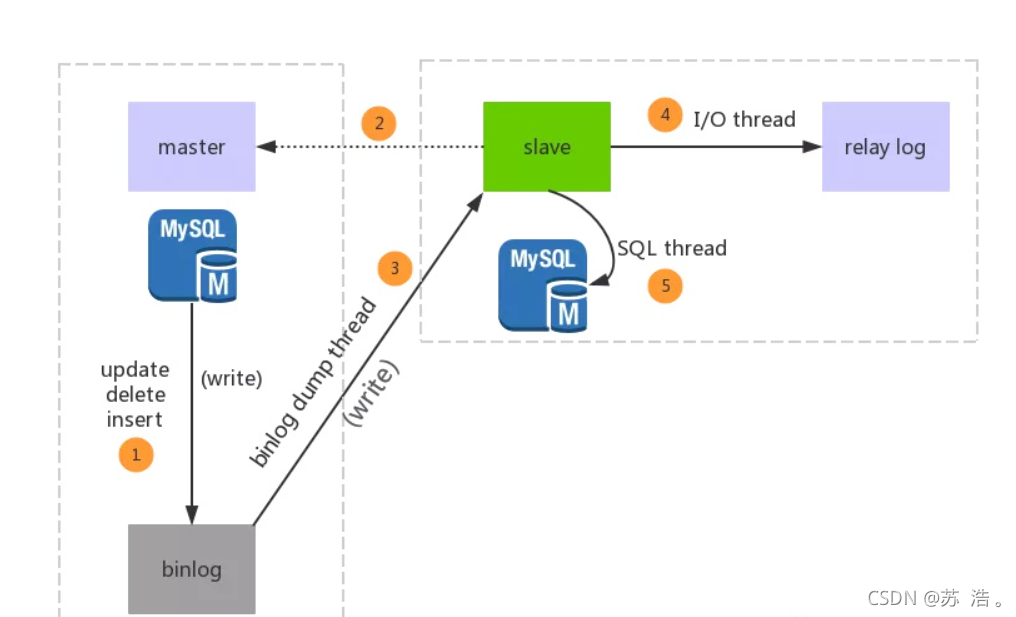

Mysql的主从复制中主要有三个线程:master(binlog dump thread)、slave(I/O thread 、SQL thread),Master一条线程和Slave中的两条线程
master(binlog dump thread)主要负责Master库中有数据更新的时候,会按照binlog格式,将更新的事件类型写入到主库的binlog文件中。Master会创建log dump线程通知Slave主库中存在数据更新,这就是为什么主库的binlog日志一定要开启的原因。
I/O thread线程在Slave中创建,该线程用于请求Master,Master会返回binlog的名称以及当前数据更新的位置、binlog文件位置的副本。然后,将binlog保存在 「relay log(中继日志)」 中,中继日志也是记录数据更新的信息。
SQL线程也是在Slave中创建的,当Slave检测到中继日志有更新,就会将更新的内容同步到Slave数据库中,这样就保证了主从的数据的同步。
主从搭建
主机(master_ip):192168.74.138
从机(slave_ip):192.168.74.150
注意:1.MySQL版本要相同,查看版本 select version();
2.uuid要不同 show variables like ‘%server_uuid%’;tip:找到/var/lib/mysql文件夹下的auto.cnf文件,修改里面的uuid值,保证各个db的uuid不一样,重启systemctl restart mysqld即可
(1)关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
vim /etc/selinux/config(永久禁用) SELINUX=disabled
(2)配置主库
vim /etc/my.cnf
[mysqld]
server_id=1
log-bin=mysql-bin
log-bin-index=master-bin.index
重启服务
systemctl restart mysqld
创建一个用于让从数据库连接的用户
mysql> create user 'copy'@'%' identified with mysql_native_password by 'XXXXXXX';
mysql>grant replication slave on *.* to 'copy'@'%';
mysql>flush privileges; 刷新授权信息
再从机上测试,用户的客户端能否正常登录
mysql -h 192.168.74.138 -ucopy -pXXXXXX
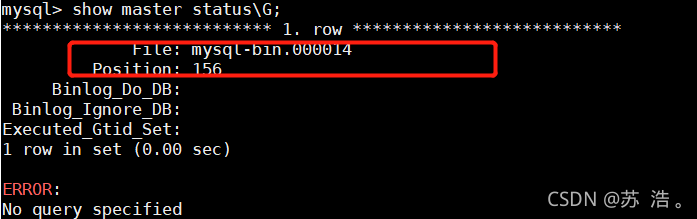
获取主节点当前brinary log 文件名和位置(记住)
show master status\G;
(3)配置从库
修改配置文件,必须指定中继日志的名称
[mysqld]
server_id=2
rlelay-log=relay-log
relay-log-index=relay-log.index
重启服务
systemctl restart mysqld
在从机(slave)节点上设置主节点参数
mysql>change master to
->master_host = ‘192.168.74.138’, #主库的IP地址
->master_user = ‘copy’, #在主库上创建的复制账号
->master_password = ‘XXXXXXXX’, #在主库上创建的复制账号密码
->master_log_file = ‘mysql-bin.000014’, #开始复制的二进制文件名(从主库查询结果中获取)
->master_log_pos = 156; #开始复制的二进制文件位置(从主库查询结果中获取)
开启主从同步
start slave;
查看主从同步状态
show slave status\G;

其中的IO线程和SQL线程均为yes,则配置成功
(4)测试主从复制是否成功
在主库创建数据库,从库上可以同步到创建的数据库内容,则证明数据同步成功

在从库上查看主库上创建的数据是否存在

注意:每次关机之后,要在从机开启slave
start slave
mysql 主从数据不一致,提示: Slave_SQL_Running: No 的解决方法
显示如下情况:表示slave不同步

解决方法(忽略错误,继续同步):
1、先停掉slave
mysql> stop slave;
2、跳过错误步数,后面步数可变
mysql> set global sql_slave_skip_counter=1;
3、再启动slave
mysql> start slave;
4、查看同步状态
mysql> show slave status\G;

2 读写分离
读写分离就是在主服务器上修改,数据会同步到从服务器,从服务器只能提供读取数据,不能写入,实现备份的同时也实现了数据库性能的优化,以及提升了服务器安全

使用Mycat实现读写分离
下载安装Mycat
Mycat官网: http://www.mycat.org.cn/
Mycat的架构其实很好理解,Mycat是代理,Mycat后面就是物理数据库。和Web服务器的Nginx类似。对于使用者来说,访问的都是Mycat,不会接触到后端的数据库

代理服务器ip : 192.168.74.151
**1.**安装jdk1.8
下载地址添加链接描述
解压缩包
tar -xzvf jdk-8u161-linux-x64.tar.gz -C /usr/local/java
环境变量文件/etc/profile配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_161
export JRE_HOME=
J
A
V
A
H
O
M
E
/
j
r
e
e
x
p
o
r
t
C
L
A
S
S
P
A
T
H
=
.
:
{JAVA_HOME}/jre export CLASSPATH=.:
JAVAHOME/jreexportCLASSPATH=.:{JAVA_HOME}/lib:
J
R
E
H
O
M
E
/
l
i
b
:
{JRE_HOME}/lib:
JREHOME/lib:CLASSPATH
export JAVA_PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
{JAVA_HOME}/bin:
JAVAHOME/bin:{JRE_HOME}/bin
export PATH=
P
A
T
H
:
PATH:
PATH:{JAVA_PATH}
使用source命令使修改即时生效,无需重启服务器
source /etc/profile
验证:
java -version

**2.**配置Mycat
解压缩包
tar -xzvf Mycat-server-1.6.7.1-release-20190627191042-linux.tar.gz
修改配置文件.server.xml
cd /mycat/conf
vim server.xml

并且删除user标签
修改配置文件schema.xml
schema.xml是最主要的配置项,首先看我的配置。database=“test” 必须是主从库都存在的数据库
<mycat:schema xmlns:mycat=“http://io.mycat/”>
<schema name=“nebula" checkSQLschema=“false” sqlMaxLimit=“100” dataNode=“dn1”/> <dataNode name=“dn1” dataHost=“auth” database=“nebula_cloud" />
select user()
<writeHost host=“hostM” url=“192.168.42.28:3306” user=“root” password=“Nebula@123">
</mycat:schema>

多余代码都可以删除

3.在从库创建用户test,只具有读权限的用户:
create user ‘test’@’%’ identified with mysql_native_password by ‘1914475347Cq!’;
GRANT select ON . TO ‘test’;赋权限
flush privileges;刷新列表
4.启动mycat
Mycat的启动也非常简单,进入到bin目录下
cd mycat/bin
##启动 ./mycat start(后台启动) ./mycat console(前台启动)
##停止 ./mycat stop
##重启 ./mycat restart
启动正常的结果如下:

如果在启动时发现异常,在logs目录中查看日志
wrapper.log 为程序启动的日志,启动时的问题看这个
mycat.log 为脚本执行时的日志,SQL脚本执行报错后的具体错误内容,查看这个文件
mycat.log是最新的错误日志,历史日志会根据时间生成目录保存。
查看端口

8066是业务端口,9066是管理端口
5.登录MyCat读写分离服务

打开命令行模式
查看心跳 #RS_CODE为1表示正常心跳

查看机器的读写分离配置情况

可以看到hostM1拥有W写权限,hostS2拥有R读权限
MyCat读写分离验证
使用navicat连接mycat,如下图所示,注意端口为8066

查看当前数据库
show databases;
测试写,在主库插入一条数据,查看是否成功,查看从库是否数据已经同步过去

测试写,有两种思路来验证:
1) 在从数据中关闭slave(即关闭主从复制);然后在mycat管理端中往某个表中插入一条数据;再使用select查询该表,可以看到查询出来的结果中并没有新的那条数据。(解释:因为关闭了主从复制,插入新数据在主库进行,而查询的是从库,为此不会查询到新插入的数据);
2)不关闭slave的主从复制,直接在从库中修改表中的某个值,而主库的值不变,直接使用查询表数据时会发现查询出来的结果是从库表中的数据(可以根据改变的值对比看出),这里为了确保读的是从库,我们用root账号登录从库,将刚才插入的数据name值改为别的,然后再次执行查询,看查询出的数据是否为从库的数据。(因为此时主库的name值为原来insert的,而从库的改为了别的)。
我遇到的问题
1.主从库中存在的数据库要相同(字节也要相同)
2.test用户的权限要改为所有,且密码算法相同

修改方法
update mysql.user set host=% where user=test;
update mysql.user set plugin=mysql_native_password where user=test;
3.数据库8种优化方式
1.优化数据库表结构的设计
字段的数据类型,数据类型的长度,表的存储引擎(MyISAM不支持事务,表级锁,但是查询速度快,InnoDB支持事务,行锁。)
2. SQL优化
最重要的方式就是使用索引,索引少了查询慢;索引多了占用空间大,执行增删改语句的时候需要动态维护索引,影响性能 选择率高(重复值少)且被where频繁引用需要建立B树索引;一般join列需要建立索引;复杂文档类型查询采用全文索引效率更好;索引的建立要在查询和DML性能之间取得平衡;复合索引创建时要注意基于非前导列查询的情况
1、通过慢查询日志发现有效率问题的SQL
2、避免select * 写法
3、避免复杂SQL语句
4、使用UNION ALL替代UNION
5、JOIN字段建议建立索引
6.使用连接(JOIN)来代替子查询(Sub-Queries
3.分区
分区就是把一张表的数据分成多个区块,这些区块可以在一个磁盘上,也可以在不同的磁盘上,分区后,表面上还是一张表,但数据散列在多个位置,这样一来,多块硬盘同时处理不同的请求,从而提高磁盘I/O读写性能,实现比较简单。
4.分库
其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
5.分表
当一个表的数据量很大的时候,查询就变的很慢,所以减少表里的记录的数量是优化的一种方式,这种方式就是将一张表的数据拆分成多张表,这样每张表的数量就减少了,这样查询速度就相对来说就快了一些。分表后,单表的并发能力提高了,磁盘I/O性能也提高了,写操作效率提高了.
6. 大事务
运行时间比较长,操作的数据比较多的事务 风险:锁定太多的数据,造成大量的阻塞和锁超时,回滚时所需时间比较长,执行时间长容易造成主从延迟
7. 数据库参数配置优化(很重要)
mysql是一个高度定制化的数据库系统,提供了很多配置参数(如最大连接数、数据库占用的内存等),这些参数都有默认值,一般默认值都不是最佳的配置,一般都需要根据应用程序的特性和硬件情况对mysql的配置进行调整。
例如最大连接数默认为100,即使SQL语句优化的再好,硬件设备配置再高,当请求超过100时都要再等待,这就是配置不合理导致MySQL不能发挥它的最大能力。
8. 系统内核优化
大多数MySQL都部署在linux系统上,所以操作系统的一些参数也会影响到MySQL性能
9. 主从复制,读写分离
通过使用MySQL主从复制,增删改操作走Master主服务器,查询走Slaver从服务器,这样就减少了只有一台MySQL服务器的压力。
10. 增加缓存层
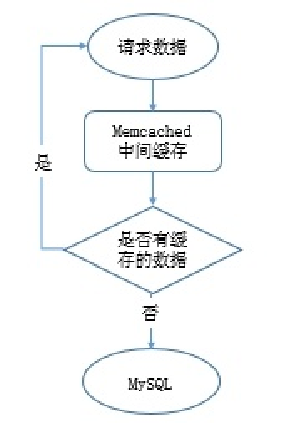
给数据库增加缓存系统,把热数据缓存到内存中,如果内存缓存中有要请求的数据就不再去数据库中返回结果,提高读性能。缓存实现有本地缓存和分布式缓存,本地缓存是将数据缓存到本地服务器内存中或者文件中,速度快。分布式可以缓存海量数据,扩展容易,主流的分布式缓存系统有memcached、redis,memcached性能稳定,数据缓存在内存中,速度很快,QPS可达8w左右。如果想数据持久化那就用redis,性能不低于memcached。
11. 升级服务器硬件
当所有优化手段都用了,性能仍需要优化,那么只有升级MySQL服务器端硬件了,更快的磁盘IO设备,更强的CPU,更大的内存,更大的网卡流量(带宽)等。加大物理内存,提高文件系统性能。将RAID级别调整为RAID1+0,相对于RAID1和RAID5有更好的读写性能(IOPS),毕竟数据库的压力主要来自磁盘I/O方面。将RAID级别调整为RAID1+0,相对于RAID1和RAID5有更好的读写性能(IOPS),毕竟数据库的压力主要来自磁盘I/O方面。
12.性能状态关键指标
总之对MySQL性能的提升,是通过各个方面来提升的,每个方面都提升一点,整体加起来就有明显的提升。














 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









