






目录
零、文件使用介绍
文件下载ProxyServerV4
提取码:1111
系统启动方法:在根目录打开终端,键入./init.sh完成相关依赖的安装,键入./run.sh,并进入parent文件夹键入命令python3 doconfig,(如果失败显示no module,返回上级文件夹将init.sh文件中pip
3 install命令前的sudo都删掉重新执行./init.sh)启动防护系统,完成浏览器的代理配置后,即可。
(一)网络浏览器进行代理设置
手动配置代理
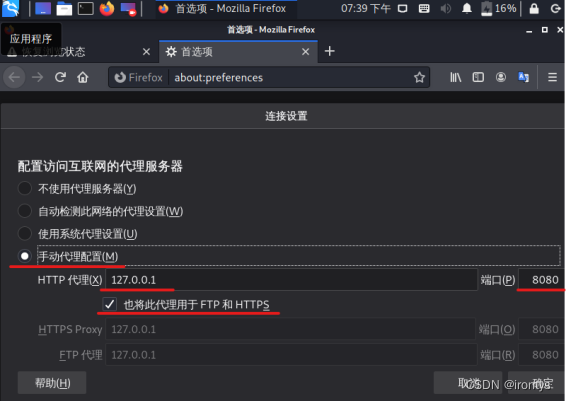
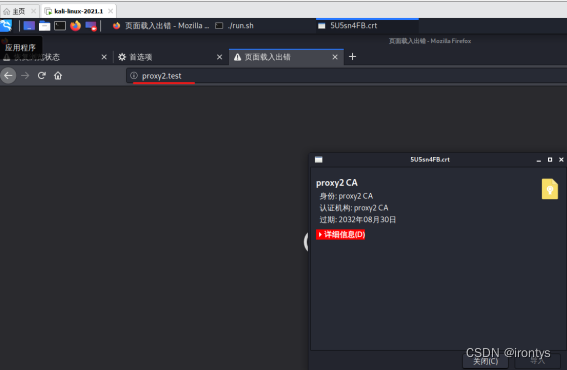
导入证书(需先运行项目文件夹下的run.sh文件)
访问proxy2.test,将证书导入网络浏览器。
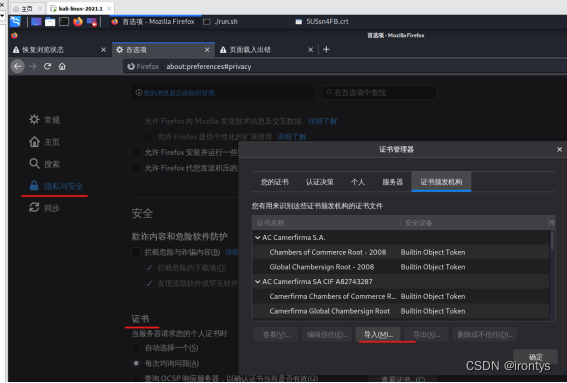
(二)搭建与配置flask框架的前端防护规则管理系统
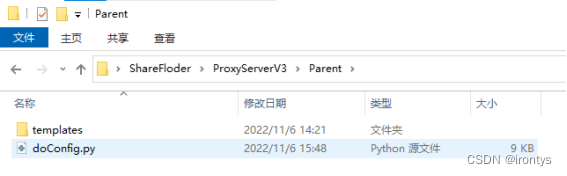
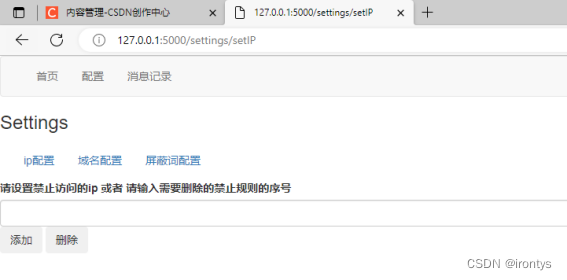
安装flask相关依赖,启动下图目录下的doConfig文件,网络浏览器访问127.0.0.1:5000(可以更换为任意可访问的服务器IP),进行登录配置,默认用户名和密码均为admin。
(三)申请百度图片审核api流程及使用方法
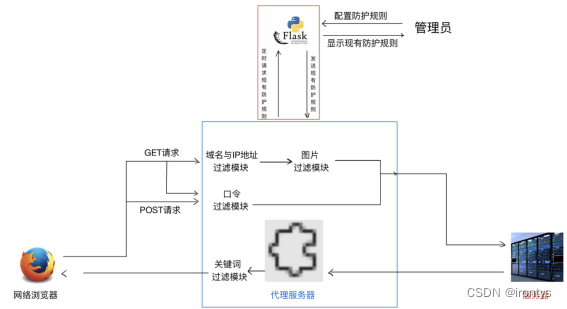
一、背景意义
互联网上鱼龙混杂,青少年上网时可能会看了不该看的内容,危害其身心健康。考虑在浏览器中添加正向代理对上网内容进行安全审查.
二、研究内容
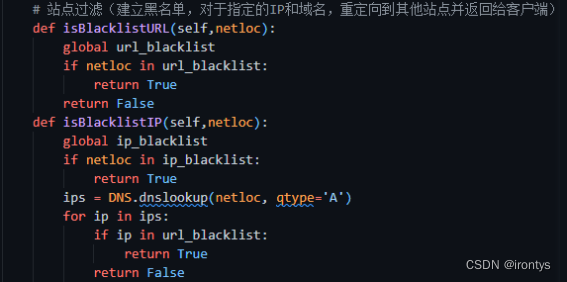
站点过滤:建立黑名单,对于指定的IP和域名,重定向到其他站点并返回给客户端;
关键词过滤:对于正常网页中的内容,如果发现指定的非法词汇,则将其替换成其他词,并返回给客户端;
过滤规则可视化:以Web可视化形式对过滤规则增删改查;
口令过滤:主动发现明文发送的用户名和密码,阻止发送;
图像过滤:发现并过滤非法图像,将其替换成空白图像
三、技术说明
项目各模块实现
1.站点过滤
建立黑名单,对于指定的IP和域名,重定向到其他站点并返回给客户端
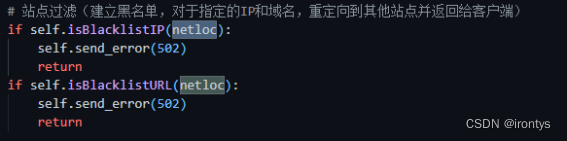
通过url.split函数得到所访问网站的域名或者当前访问的ip地址,如果当前浏览器访问的为一个ip地址,则判断其是否在黑名单中,如果是一个域名,则分别判断其是否在域名黑名单中和其通过DNS解析后的道德ip地址是否在ip黑名单中,如果判定不通过,则将当前站点重定向到502Bad Gateway页面。
2.关键词过滤
对于正常网页中的内容,如果发现指定的非法词汇,则将其替换成其他词,并返回给客户端;
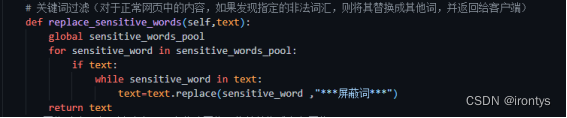
在服务器向客户端发送response报文时,对其中内容进行检查,将其中所有的非法词汇替换为指定的内容。并将修改后的内容发送给客户端。
3.过滤规则可视化
以Web可视化形式对过滤规则增删改查

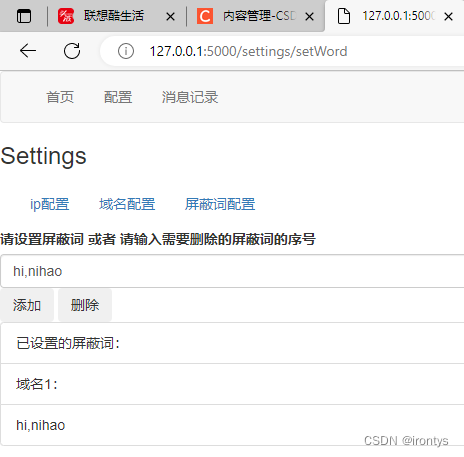
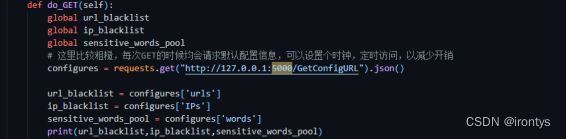
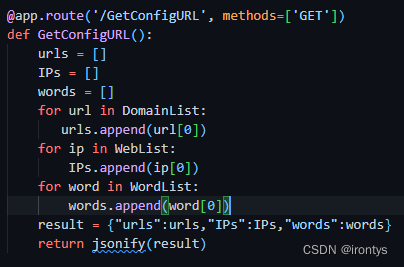
前端代理规则配置页面使用flask框架,在该项目中,代理服务器周期性地访问代理规则配置页面,以动态获取代理服务器在运行过程中会用到的代理规则。
配置页面支持对代理规则的动态增删,并可以直观的看到当前已设置的代理规则。
4.口令过滤
主动发现明文发送的用户名和密码,阻止发送

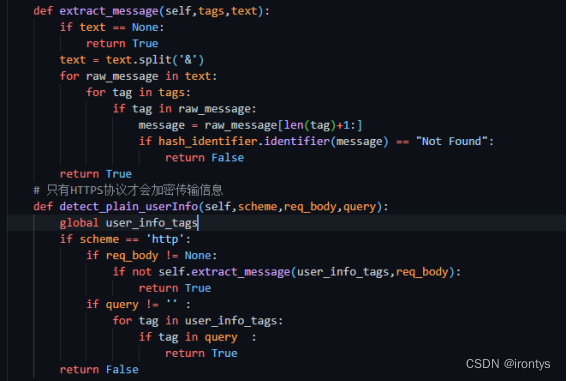
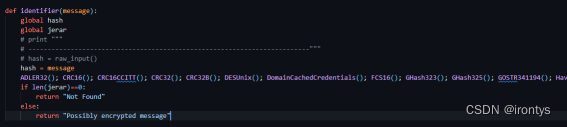
本项目阻止客户端通过http协议向服务器传输明文形式的用户信息,通过提取GET方式中的query和POST方式的request body中的内容,用hash_identifier.py分析其中参数是否为加密信息的方式,来规避此类风险。
如果判定客户端通过http协议以明文的形式在网络上向服务器传递用户信息,则阻止此次信息的发送。
hash_identifier.py对用户信息的内容进行分析,判断其是否可能为某一种加密方式加密后的结果,并返回响应信息。
5.图像过滤
发现并过滤非法图像,将其替换成空白图像
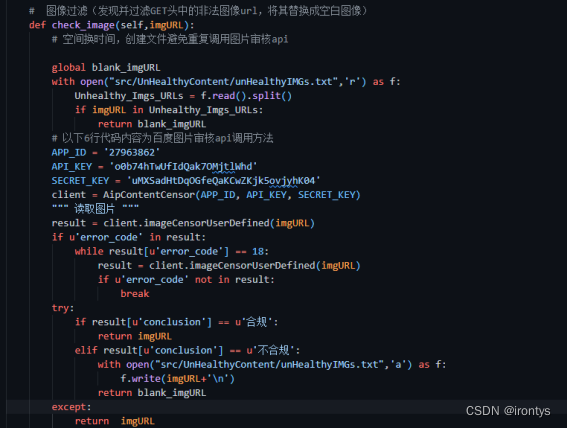
在客户端请求服务器后,服务器向客户端发送当前网页的源代码,在浏览器解析时,如果某一条目包含图片链接,则浏览器会发送GET请求,请求图片内容,本项目代理服务器正是在此时对请求的图片进行内容审核,如果图片内容不能够通过审核,则将本次图片的GET请求重定向到一个空白图片。
所用的图片审核模块为百度提供的内容审核api,通过调用百度提供的api调用方法,可以得到图片内容审查的结果。
主体服务器文件
# -*- coding: utf-8 -*-
import sys
import os
import socket
import ssl
import select
import httplib
import urlparse
import threading
import gzip
import zlib
import time
import re
import requests
import DNS
from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler
from SocketServer import ThreadingMixIn
from cStringIO import StringIO
from subprocess import Popen, PIPE
from aip import AipContentCensor
import hash_identifier
# 一个空白图片的连接,用于图片过滤的替换
blank_imgURL = 'https://ss1.baidu.com/9vo3dSag_xI4khGko9WTAnF6hhy/zhidao/wh%3D450%2C600/sign=0522dd202e2eb938ec3872f6e052a903/21a4462309f79052c9e799ff0df3d7ca7acbd573.jpg'
sensitive_words_pool = []
url_blacklist = []
user_info_tags = []
ip_blacklist = []
def with_color(c, s):
return "\x1b[%dm%s\x1b[0m" % (c, s)
# 返回path文件/文件夹对应的绝对路径
def join_with_script_dir(path):
return os.path.join(os.path.dirname(os.path.abspath(__file__)), path)
class ThreadingHTTPServer(ThreadingMixIn, HTTPServer):
address_family = socket.AF_INET6
daemon_threads = True
def handle_error(self, request, client_address):
# surpress socket/ssl related errors
cls, e = sys.exc_info()[:2]
if cls is socket.error or cls is ssl.SSLError:
pass
else:
return HTTPServer.handle_error(self, request, client_address)
class ProxyRequestHandler(BaseHTTPRequestHandler):
cakey = join_with_script_dir('src/certsAndKeys/ca.key')
cacert = join_with_script_dir('src/certsAndKeys/ca.crt')
certkey = join_with_script_dir('src/certsAndKeys/cert.key')
certdir = join_with_script_dir('src/certsAndKeys/certs/')
timeout = 5
lock = threading.Lock()
def __init__(self, *args, **kwargs):
self.tls = threading.local()
self.tls.conns = {}
BaseHTTPRequestHandler.__init__(self, *args, **kwargs)
def log_error(self, format, *args):
# surpress "Request timed out: timeout('timed out',)"
if isinstance(args[0], socket.timeout):
return
self.log_message(format, *args)
# 代理服务器和客户端之间建立TCP连接
def do_CONNECT(self):
# 判断存在证书文件
if os.path.isfile(self.cakey) and os.path.isfile(self.cacert) and os.path.isfile(self.certkey) and os.path.isdir(self.certdir):
self.connect_intercept()
else:
self.connect_relay()
# https协议,使用证书建立ssl加密的tcp的HTTP connection, 本程序默认建立https连接
def connect_intercept(self):
hostname = self.path.split(':')[0]
certpath = "%s/%s.crt" % (self.certdir.rstrip('/'), hostname)
with self.lock:
if not os.path.isfile(certpath):
epoch = "%d" % (time.time() * 1000)
p1 = Popen(["openssl", "req", "-new", "-key", self.certkey, "-subj", "/CN=%s" % hostname], stdout=PIPE)
p2 = Popen(["openssl", "x509", "-req", "-days", "3650", "-CA", self.cacert, "-CAkey", self.cakey, "-set_serial", epoch, "-out", certpath], stdin=p1.stdout, stderr=PIPE)
p2.communicate()
self.wfile.write("%s %d %s\r\n" % (self.protocol_version, 200, 'Connection Established'))
self.end_headers()
self.connection = ssl.wrap_socket(self.connection, keyfile=self.certkey, certfile=certpath, server_side=True)
# 下属两个变量为用于收发数据而开辟的缓冲区
self.rfile = self.connection.makefile("rb", self.rbufsize)
self.wfile = self.connection.makefile("wb", self.wbufsize)
conntype = self.headers.get('Proxy-Connection', '')
if self.protocol_version == "HTTP/1.1" and conntype.lower() != 'close':
self.close_connection = 0
else:
self.close_connection = 1
# 非https协议,直接传输,建立无加密的信道
def connect_relay(self):
address = self.path.split(':', 1)
address[1] = int(address[1]) or 443
try:
s = socket.create_connection(address, timeout=self.timeout)
except Exception as e:
self.send_error(502)
return
self.send_response(200, 'Connection Established')
self.end_headers()
conns = [self.connection, s]
self.close_connection = 0
while not self.close_connection:
rlist, wlist, xlist = select.select(conns, [], conns, self.timeout)
if xlist or not rlist:
break
for r in rlist:
other = conns[1] if r is conns[0] else conns[0]
data = r.recv(8192)
########接受的报文并没有传输的数据
if not data:
self.close_connection = 1
break
other.sendall(data)
# 本项目使用do_GET实现了GET和POST方法
# 这是因为在项目调试环节POST方法遇到的较少,且处理数据情况与GET方法处理基本一致,为减少代码量,而令do_POST = do_GET()
def do_GET(self):
global url_blacklist
global ip_blacklist
global sensitive_words_pool
# 这里比较粗糙,每次GET的时候均会请求默认配置信息,可以设置个时钟,定时访问,以减少开销
configures = requests.get("http://127.0.0.1:5000/GetConfigURL").json()
url_blacklist = configures['urls']
ip_blacklist = configures['IPs']
sensitive_words_pool = configures['words']
print(url_blacklist,ip_blacklist,sensitive_words_pool)
if self.path == 'http://proxy2.test/':
self.send_cacert()
return
req = self
###### self.headers.get只接收所传递变量对应header的内容,是指对应的那一行
content_length = int(req.headers.get('Content-Length', 0))
req_body = self.rfile.read(content_length) if content_length else None
if req.path[0] == '/':
#判断connection是否为ssl加密,是则用https协议,否则http协议
if isinstance(self.connection, ssl.SSLSocket):
req.path = "https://%s%s" % (req.headers['Host'], req.path)
else:
req.path = "http://%s%s" % (req.headers['Host'], req.path)
if req.path is None:
return
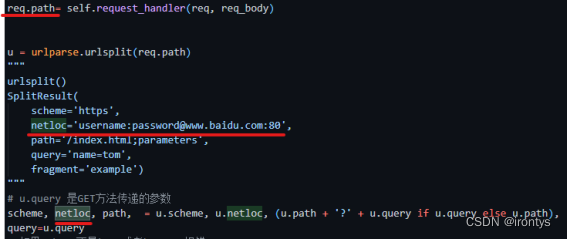
req.path= self.request_handler(req, req_body)
u = urlparse.urlsplit(req.path)
"""
urlsplit()
SplitResult(
scheme='https',
netloc='username:password@www.baidu.com:80',
path='/index.html;parameters',
query='name=tom',
fragment='example')
"""
# u.query 是GET方法传递的参数
scheme, netloc, path, = u.scheme, u.netloc, (u.path + '?' + u.query if u.query else u.path),
query=u.query
# 如果scheme不是http或者https,报错
assert scheme in ('http', 'https')
global user_info_tags
# 站点过滤(建立黑名单,对于指定的IP和域名,重定向到其他站点并返回给客户端)
if self.isBlacklistIP(netloc):
self.send_error(502)
return
if self.isBlacklistURL(netloc):
self.send_error(502)
return
# 处理POST请求,因为POST请求含req_body(不为None)
if self.detect_plain_userInfo(scheme,req_body,query):
print("_______Detected_Plain_User_Infomation__Dialog_IS_Banned______________________")
return
# net location
if netloc:
req.headers['Host'] = netloc
setattr(req, 'headers', self.filter_headers(req.headers))
#以上是GET请求处理req发送部分,以下是处理response部分
# 如果使用http或https协议,建立代理服务器与服务器的连接
try:
origin = (scheme, netloc)
if not origin in self.tls.conns:
if scheme == 'https':
self.tls.conns[origin] = httplib.HTTPSConnection(netloc, timeout=self.timeout)
else:
self.tls.conns[origin] = httplib.HTTPConnection(netloc, timeout=self.timeout)
conn = self.tls.conns[origin]
conn.request(self.command, path, req_body, dict(req.headers))
res = conn.getresponse()
version_table = {10: 'HTTP/1.0', 11: 'HTTP/1.1'}
setattr(res, 'headers', res.msg)
setattr(res, 'response_version', version_table[res.version])
# 如果response的content即res_body为空
if not 'Content-Length' in res.headers and 'no-store' in res.headers.get('Cache-Control', ''):
# self.response_handler(req, req_body, res, '')
setattr(res, 'headers', self.filter_headers(res.headers))
self.relay_streaming(res)
with self.lock:
self.save_handler(req, req_body, res, '')
return
res_body = res.read()
except:
# 502 Bad Gateway是指错误网关,无效网关
# 上游服务器和网关/代理使用不一致的协议交换数据
if origin in self.tls.conns:
del self.tls.conns[origin]
self.send_error(502)
return
# 传输的res格式可以视为文件类型,首先解码为明文,在对其进行修改
if res_body is not None:
try:
content_encoding = res.headers.get('Content-Encoding', 'gzip')
res_body_plain = self.decode_content_body(res_body, content_encoding)
except:
content_encoding = res.headers.get('Content-Encoding', 'identity')
res_body_plain = self.decode_content_body(res_body, content_encoding)
res_body_plain = self.response_handler(req, req_body, res, res_body_plain)
res_body = self.encode_content_body(res_body_plain, content_encoding)
res.headers['Content-Length'] = str(len(res_body))
setattr(res, 'headers', self.filter_headers(res.headers))
# 向客户端传输数据
self.wfile.write("%s %d %s\r\n" % (self.protocol_version, res.status, res.reason))
for line in res.headers.headers:
self.wfile.write(line)
self.end_headers()
self.wfile.write(res_body)
self.wfile.flush()
# 在终端上打印一些信息
with self.lock:
self.save_handler(req, req_body, res, res_body_plain)
# 向客户端传输数据
def relay_streaming(self, res):
self.wfile.write("%s %d %s\r\n" % (self.protocol_version, res.status, res.reason))
for line in res.headers.headers:
self.wfile.write(line)
self.end_headers()
try:
while True:
chunk = res.read(8192)
if not chunk:
break
self.wfile.write(chunk)
self.wfile.flush()
except socket.error:
# connection closed by client
pass
# 由于对POST方法区别于GET部分较少,为减少代码量,共用同一个函数,POST方法特色函数一再do_GET()中标注
do_POST = do_GET
do_HEAD = do_GET
do_PUT = do_GET
do_DELETE = do_GET
do_OPTIONS = do_GET
def filter_headers(self, headers):
# http://tools.ietf.org/html/rfc2616#section-13.5.1
# Hop-by-hop Headers中的响应头,对一次连接有意义,然而,这些响应头不应该被缓存或者层层转发。反过来理解,也就是层层转发以上响应头,请求可能会出问题。
hop_by_hop = ('connection', 'keep-alive', 'proxy-authenticate', 'proxy-authorization', 'te', 'trailers', 'transfer-encoding', 'upgrade')
for k in hop_by_hop:
del headers[k]
# accept only supported encodings
if 'Accept-Encoding' in headers:
ae = headers['Accept-Encoding']
filtered_encodings = [x for x in re.split(r',\s*', ae) if x in ('identity', 'gzip', 'x-gzip', 'deflate')]
headers['Accept-Encoding'] = ', '.join(filtered_encodings)
return headers
def encode_content_body(self, text, encoding):
if encoding == 'identity':
data = text
elif encoding in ('gzip', 'x-gzip'):
io = StringIO()
with gzip.GzipFile(fileobj=io, mode='wb') as f:
f.write(text)
data = io.getvalue()
elif encoding == 'deflate':
data = zlib.compress(text)
else:
raise Exception("Unknown Content-Encoding: %s" % encoding)
return data
def decode_content_body(self, data, encoding):
if encoding == 'identity':
text = data
elif encoding in ('gzip', 'x-gzip'):
io = StringIO(data)
with gzip.GzipFile(fileobj=io) as f:
text = f.read()
elif encoding == 'deflate':
try:
text = zlib.decompress(data)
except zlib.error:
text = zlib.decompress(data, -zlib.MAX_WBITS)
else:
raise Exception("Unknown Content-Encoding: %s" % encoding)
return text
def send_cacert(self):
with open(self.cacert, 'rb') as f:
data = f.read()
self.wfile.write("%s %d %s\r\n" % (self.protocol_version, 200, 'OK'))
self.send_header('Content-Type', 'application/x-x509-ca-cert')
self.send_header('Content-Length', len(data))
self.send_header('Connection', 'close')
self.end_headers()
self.wfile.write(data)
def print_info(self, req, req_body, res, res_body):
def parse_qsl(s):
return '\n'.join("%-20s %s" % (k, v) for k, v in urlparse.parse_qsl(s, keep_blank_values=True))
req_header_text = "%s %s %s\n%s" % (req.command, req.path, req.request_version, req.headers)
res_header_text = "%s %d %s\n%s" % (res.response_version, res.status, res.reason, res.headers)
print(with_color(33, req_header_text))
u = urlparse.urlsplit(req.path)
if u.query:
query_text = parse_qsl(u.query)
print(with_color(32, "==== QUERY PARAMETERS ====\n%s\n" % query_text))
cookie = req.headers.get('Cookie', '')
if cookie:
# 0
cookie = parse_qsl(re.sub(r';\s*', '&', cookie))
print(with_color(32, "==== COOKIE ====\n%s\n" % cookie))
auth = req.headers.get('Authorization', '')
if auth.lower().startswith('basic'):
token = auth.split()[1].decode('base64')
print(with_color(31, "==== BASIC AUTH ====\n%s\n" % token))
if req_body is not None:
content_type = req.headers.get('Content-Type', '').split('/')[0]
print(with_color(32, "==== REQUEST BODY ====\n%s\n" % req_body))
print(with_color(36, res_header_text))
cookies = res.headers.getheaders('Set-Cookie')
if cookies:
cookies = '\n'.join(cookies)
print(with_color(31, "==== SET-COOKIE ====\n%s\n" % cookies))
if res_body is not None:
# content_type:"text/html; charset=UTF-8"
content_type = res.headers.get('Content-Type', '').split('/')[0]## 获取内容的类型如text image等
if content_type == 'image':
print(with_color(32, "==== RESPONSE BODY ——TYPE=%s====\n\n" % (content_type)))
else:
print(with_color(32, "==== RESPONSE BODY ——TYPE=%s====\n%s\n" % (content_type,res_body)))
def add_url_blacklist(self,url):
global url_blacklist
url_blacklist.append(url)
return
def add_sensitive_word(self,word):
global sensitive_words_pool
sensitive_words_pool.append(word)
return
def extract_message(self,tags,text):
if text == None:
return True
text = text.split('&')
for raw_message in text:
for tag in tags:
if tag in raw_message:
message = raw_message[len(tag)+1:]
if hash_identifier.identifier(message) == "Not Found":
return False
return True
# 只有HTTPS协议才会加密传输信息
def detect_plain_userInfo(self,scheme,req_body,query):
global user_info_tags
if scheme == 'http':
if req_body != None:
if not self.extract_message(user_info_tags,req_body):
return True
if query != '' :
for tag in user_info_tags:
if tag in query :
return True
return False
# 站点过滤(建立黑名单,对于指定的IP和域名,重定向到其他站点并返回给客户端)
def isBlacklistURL(self,netloc):
global url_blacklist
if netloc in url_blacklist:
return True
return False
def isBlacklistIP(self,netloc):
global ip_blacklist
if netloc in ip_blacklist:
return True
ips = DNS.dnslookup(netloc, qtype='A')
for ip in ips:
if ip in url_blacklist:
return True
return False
# 关键词过滤(对于正常网页中的内容,如果发现指定的非法词汇,则将其替换成其他词,并返回给客户端)
def replace_sensitive_words(self,text):
global sensitive_words_pool
for sensitive_word in sensitive_words_pool:
if text:
while sensitive_word in text:
text=text.replace(sensitive_word ,"***屏蔽词***")
return text
# 图像过滤(发现并过滤body中非法图像,将其替换成空白图像)
# 图像过滤(发现并过滤GET头中的非法图像url,将其替换成空白图像)
def check_image(self,imgURL):
# 空间换时间,创建文件避免重复调用图片审核api
return imgURL
global blank_imgURL
with open("src/UnHealthyContent/unHealthyIMGs.txt",'r') as f:
Unhealthy_Imgs_URLs = f.read().split()
if imgURL in Unhealthy_Imgs_URLs:
return blank_imgURL
# 以下6行代码内容为百度图片审核api调用方法
APP_ID = '27963862'
API_KEY = 'o0b74hTwUfIdQak7OMjtlWhd'
SECRET_KEY = 'uMXSadHtDqOGfeQaKCwZKjk5ovjyhK04'
client = AipContentCensor(APP_ID, API_KEY, SECRET_KEY)
""" 读取图片 """
result = client.imageCensorUserDefined(imgURL)
# 返回值如下
# return example {u'log_id': 16631177830015238, u'isHitMd5': False, u'conclusionType': 1, u'conclusion': u'\u5408\u89c4'}
# example[u'conclusion''] = u'合规'/u'不合规(\u4e0d\u5408\u89c4)'
# 访问api可能会由于访问速度过快等原因访问失败,此时反复访问直至正常访问api
if u'error_code' in result:
while result[u'error_code'] == 18:
result = client.imageCensorUserDefined(imgURL)
if u'error_code' not in result:
break
try:
if result[u'conclusion'] == u'合规':
# print(result[u'conclusion'])
return imgURL
elif result[u'conclusion'] == u'不合规':
with open("src/UnHealthyContent/unHealthyIMGs.txt",'a') as f:
f.write(imgURL+'\n')
# print(result[u'conclusion'])
return blank_imgURL
except:
# print("不能正确识别图片:",imgURL)
return imgURL
# 实现GET请求的图片过滤的方法。由于浏览器接收到response后,会GET请求遇到的每一个链接实体,所以对每一个GET进行图片审核,若该实体类型为image,且审核结果为“不合规”,则将此图片链接重定向到空白图片
def request_handler(self, req, req_body):
global blank_imgURL
with open("src/UnHealthyContent/unHealthyIMGs.txt",'r') as f:
Unhealthy_Imgs_URLs =[]# f.read().split()
imgURL = req.path
content_type = req.headers['Accept'].split('/')[0]
if content_type == 'image':
if imgURL not in Unhealthy_Imgs_URLs:
if self.check_image(imgURL) == blank_imgURL:
req.path = blank_imgURL
Unhealthy_Imgs_URLs.append(imgURL)
else:
req.path = blank_imgURL
return req.path
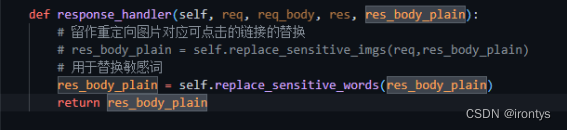
def response_handler(self, req, req_body, res, res_body_plain):
# 留作重定向图片对应可点击的链接的替换
# res_body_plain = self.replace_sensitive_imgs(req,res_body_plain)
# 用于替换敏感词
res_body_plain = self.replace_sensitive_words(res_body_plain)
return res_body_plain
def save_handler(self, req, req_body, res, res_body):
self.print_info(req, req_body, res, res_body)
## 由于前述代码不能修改在浏览器中显示的源代码,即未对res_body做修改,该函数实现了此功能,并可以实现HTML语法中a标签出现的图片链接对应的可点击链接重定向到其他页面
## 但考虑到不同的网页所用标签规则不一样,而且replace函数代价极大影响效率,为减少代码量、提高效率,特此省略
# def replace_sensitive_imgs(self,req,res_body_plain):
# from bs4 import BeautifulSoup
# bs = BeautifulSoup(res_body_plain)
# global blank_imgURL
# ## 令所有的<a>标签中非法图片对应的链接不可被点击
# for item in bs.find_all('a'):
# imgURL = str(item.get("data-original"))
# href = str(item.get("href"))
# if href == 'None' or imgURL == 'None':
# continue
# if self.check_image(imgURL) == blank_imgURL:
# res_body_plain = res_body_plain.replace(href,"DO not to view")
# 将浏览器显示网页的源代码中的非法图片路径切换为空白图片的路径
# URLs_to_be_inspect = self.extract_URLs_to_be_inspect(bs)
# for item in URLs_to_be_inspect:
# imgURL = item
# if self.check_image(imgURL) == blank_imgURL:
# res_body_plain = res_body_plain.replace(imgURL,blank_imgURL)
# if req.path == blank_imgURL:
# # print(req.path,init_req_path)
# res_body_plain = res_body_plain.replace(req.path,"req.path")
# return res_body_plain
# def extract_URLs_to_be_inspect(self,beautifulSoup_text):
# bs = beautifulSoup_text
# URLs_to_be_inspect = []
# for item in bs.find_all('a'):
# URLs_to_be_inspect.append(str(item.get("data-original")))
# for item in bs.find_all('img'):
# URLs_to_be_inspect.append(str(item.get("src")))
# return URLs_to_be_inspect
# ServerClass = HTTPServer
# HandlerClass = SimpleHTTPRequestHandler
def test(HandlerClass=ProxyRequestHandler, ServerClass=ThreadingHTTPServer, protocol="HTTP/1.1"):
if sys.argv[1:]:
port = int(sys.argv[1])
else:
port = 8080
server_address = ('', port)
HandlerClass.protocol_version = protocol
httpd = ServerClass(server_address, HandlerClass)
sa = httpd.socket.getsockname()
print("Serving HTTP Proxy on", sa[0], "port", sa[1], "...")
httpd.serve_forever()
if __name__ == '__main__':
test()















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









