







概念
理想的搜索方法:不经过任何比较,一次直接从表中得到想要的搜索元素。
构造某种存储结构,通过某种函数(hashfunc)使元素的存储位置与他的关键key之间建立一一映射的关系,在查找的时候,可以很快找到该元素。
哈希方法中使用的转换函数称为哈希(散列)函数,构造出的数据结构称为哈希表(HashTable)(后者称为散列表)
哈希函数设计
常见的哈希函数:
1、直接定制法:
Hash(key)= A*key+B
优点:简单均匀
2、除留余数法——(常用)
Hash(key) = key%p(p<=m)
3、
…
冲突
冲突的发生是必然的,我们要做的是降低冲突率
例如使用除留余数法,会出现相同的余数的情况,(出现相同的哈希地址),这种情况称为哈希冲突(哈希碰撞)
避免冲突的方法:
1、设计好的哈希函数
2、负载因子的调节
调节负载因子
负载因子的计算是通过:
填入表中的元素 / 散列表的长度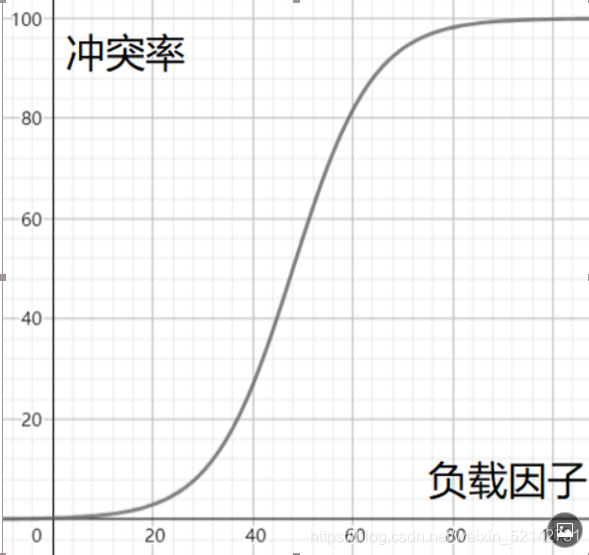
已知哈希表中的关键字个数是不可变的,那么我们只能调整哈希表中数组的大小。
冲突解决
闭散列
闭散列:也叫开放地址法,当发生冲突的时候,如果哈希表未被填满,那么就说明哈希表中还有空位,就将key放在冲突位置的“下一个”空位中。
开散列/哈希桶
开散列法,又叫链地址法,首先通过关键码集合用散列函数计算地址,将相同地址关键码放在同一子集合中,每个子集合称一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存在哈希表中。
简单理解就是:
一个数组,数组中存存链表的头结点,发生冲突的元素放在链表中。
注意:
假如元素发生聚集,那么就会退回成链表,所以需要我们合理解决冲突。
通常情况下我们认为哈希表的冲突率不高,冲突个数是可控的,每个桶中的链表长度是一个常数,所以通常意义上,我们认为哈希表的插入/删除/查找的时间复杂度是O(1)
实现自己的哈希表:
结点:
package HashTable;
public class Node {
int key;
Node next;
public Node(int key) {
this.key = key;
}
@Override
public String toString() {
return "Node{" +
"val=" + key +
", next=" + next +
'}';
}
}
MyHashTable:
package HashTable;
public class MyHashTable {
//存头结点的数组
Node[] array;
int size;
public MyHashTable() {
array = new Node[11];
size = 0;
}
//冲突因子
private double LOAD_FACTOR = 0.75;
//插入——头插
public boolean insert(int key) {
if (find(key)) {
return false;
}
int index = key % array.length;
Node node = new Node(key);
node.next = array[index];
array[index] = node;
size++;
if ((double) size / array.length > LOAD_FACTOR) {
grow();
}
return true;
}
//扩容
//2倍扩容
private void grow() {
Node[] newArray = new Node[array.length * 2];
for (Node head : array) {
Node cur = head;
while (cur != null) {
int index = cur.key % newArray.length;
Node next = cur.next;
cur.next = newArray[index];
newArray[index] = cur;
cur = next;
}
}
array = newArray;
}
//删除
public boolean remove(int key) {
int index = key % array.length;
Node cur = array[index];
Node prev = null;
while (cur != null) {
if (key == cur.key) {
if (prev != null) {
prev.next = cur.next;
} else {
array[index] = array[index].next;
}
size--;
return true;
}
prev = cur;
cur = cur.next;
}
return false;
}
//查找
public boolean find(int key) {
int index = key % array.length;
for (Node cur = array[index]; cur != null; cur = cur.next) {
if (cur.key == key) {
return true;
}
}
return false;
}
}
Test:
package HashTable;
import java.util.Random;
public class Test {
public static void main(String[] args) {
Random random = new Random(2020412);
MyHashTable hashTable = new MyHashTable();
for (int i = 0; i < 10000; i++) {
int key = random.nextInt();
if (key >= 0 && !hashTable.find(key)) {
hashTable.insert(key);
}
}
int min = Integer.MAX_VALUE;
int max = Integer.MIN_VALUE;
int sum = 0;
for (int i = 0; i < hashTable.array.length; i++) {
Node cur = hashTable.array[i];
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
if (count < min) {
min = count;
}
if (count > max) {
max = count;
}
sum += count;
}
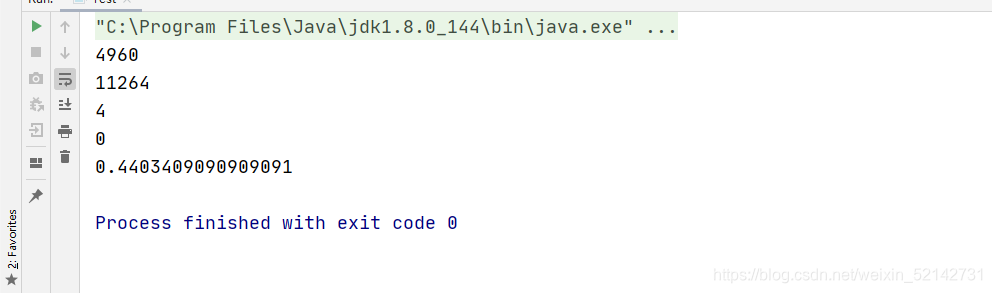
System.out.println(hashTable.size);
System.out.println(hashTable.array.length);
System.out.println(max);
System.out.println(min);
System.out.println((double) sum / hashTable.array.length);
}
}















 1940
1940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











