







文章目录
引言
reward 信号作为训练中的反馈指标,其值越高表示机器人越接近目标行为(如精确跟踪指令、稳定步态、正确足部动作、合理姿态等),而值较低或负值则提示不良的运动模式。强化学习算法会根据这些信号不断调整策略,以逐步改进机器人的控制性能。
1. track_lin_vel_xy_exp
def track_lin_vel_xy_exp(
env: ManagerBasedRLEnv, std: float, command_name: str, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")
) -> torch.Tensor:
"""Reward tracking of linear velocity commands (xy axes) using exponential kernel."""
# extract the used quantities (to enable type-hinting)
asset: RigidObject = env.scene[asset_cfg.name]
# compute the error
lin_vel_error = torch.sum(
torch.square(env.command_manager.get_command(command_name)[:, :2] - asset.data.root_lin_vel_b[:, :2]),
dim=1,
)
reward = torch.exp(-lin_vel_error / std**2)
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
此奖励函数鼓励机器人在本体坐标系(body frame)的xy平面上追踪给定的线性速度指令,同时保持直立姿态。其设计结合了速度追踪误差的指数型奖励和姿态稳定性约束。
-
速度追踪误差计算:
指令获取:从命令管理器(command_manager)中提取目标xy速度(command_name),假设指令在本体坐标系下。
实际速度:读取机器人根关节在本体坐标系下的实际xy速度(root_lin_vel_b[:, :2])。
误差计算:计算目标速度与实际速度在xy平面上的欧氏距离平方误差(lin_vel_error)。
-
指数型奖励函数:
将误差通过指数衰减转换为奖励值:exp(-lin_vel_error / std²)。
参数作用:std 控制奖励对误差的敏感度,std 越大,奖励对误差的容忍度越高。
-
姿态稳定性约束:
重力投影项:通过机器人本体坐标系下的重力方向(projected_gravity_b[:, 2])判断姿态。
- 直立时,z方向重力投影值为负(如 -1.0 表示完全对齐世界坐标系上方向)。
奖励缩放:
- 将 -projected_gravity_b[:, 2] 限制在 [0, 0.7] 区间后除以 0.7,得到比例因子 [0, 1]。
意义:当机器人直立(倾斜角 ≤ 45°)时,比例因子为 1(满奖励);倾斜角增大时,奖励按比例衰减;倒置时(如倾斜角 ≥ 90°),奖励归零。
-
奖励公式:
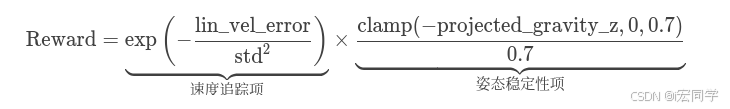
2. track_lin_vel_z_exp
同理得
def track_ang_vel_z_exp(
env: ManagerBasedRLEnv, std: float, command_name: str, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")
) -> torch.Tensor:
"""Reward tracking of angular velocity commands (yaw) using exponential kernel."""
# extract the used quantities (to enable type-hinting)
asset: RigidObject = env.scene[asset_cfg.name]
# compute the error
ang_vel_error = torch.square(env.command_manager.get_command(command_name)[:, 2] - asset.data.root_ang_vel_b[:, 2])
reward = torch.exp(-ang_vel_error / std**2)
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
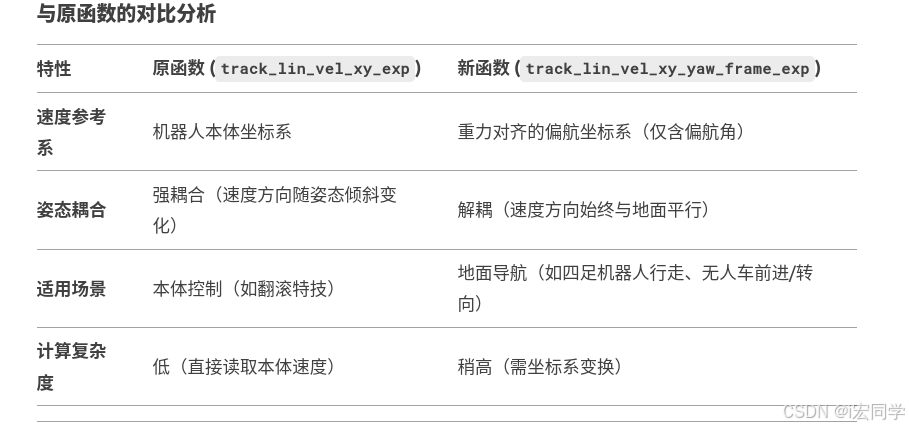
3. track_lin_vel_xy_yaw_frame_exp
def track_lin_vel_xy_yaw_frame_exp(
env, std: float, command_name: str, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")
) -> torch.Tensor:
"""Reward tracking of linear velocity commands (xy axes) in the gravity aligned robot frame using exponential kernel."""
# extract the used quantities (to enable type-hinting)
asset = env.scene[asset_cfg.name]
vel_yaw = quat_rotate_inverse(yaw_quat(asset.data.root_quat_w), asset.data.root_lin_vel_w[:, :3])
lin_vel_error = torch.sum(
torch.square(env.command_manager.get_command(command_name)[:, :2] - vel_yaw[:, :2]), dim=1
)
reward = torch.exp(-lin_vel_error / std**2)
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
激励机器人在重力对齐的偏航坐标系(Yaw-Aligned Frame)中追踪给定的XY线性速度指令,同时保持直立姿态。该坐标系仅包含机器人的偏航角(绕世界Z轴的旋转),忽略俯仰和翻滚,使得速度追踪方向始终与地面平行。
(1)坐标系转换:世界速度 → 偏航坐标系速度
vel_yaw = quat_rotate_inverse( # 逆旋转(坐标系变换)
yaw_quat(asset.data.root_quat_w), # 提取偏航角四元数
asset.data.root_lin_vel_w[:, :3] # 世界坐标系下的线速度
)
yaw_quat 函数:
从机器人世界坐标系姿态四元数 root_quat_w 中提取仅含偏航角的分量,生成新的四元数。例如:若机器人俯仰 30° 且偏航 45°,
则生成的偏航四元数对应绕世界Z轴旋转 45°。
quat_rotate_inverse 操作:
将世界坐标系下的线速度 root_lin_vel_w 通过逆旋转变换到偏航坐标系。
等效于将速度投影到水平地面平面。
(2)速度追踪误差计算
lin_vel_error = torch.sum(
torch.square(command[:, :2] - vel_yaw[:, :2]), # XY平面误差
dim=1
)
输入指令:command_name 指定的目标速度(假设已在偏航坐标系下)。
误差定义:目标速度与偏航坐标系下实际速度的欧氏距离平方和(仅XY平面)。
(3)指数型奖励计算
reward = torch.exp(-lin_vel_error / std**2)
敏感度控制:std 参数决定奖励对误差的敏感度。std 越小,奖励对误差的惩罚越严格。
(4)姿态稳定性约束
reward *= torch.clamp(-projected_gravity_b[:, 2], 0, 0.7) / 0.7
重力投影项:projected_gravity_b[:, 2] 表示重力在机器人本体坐标系Z轴的分量。
直立时:该值为 -1.0 → -projected_gravity_b[:, 2] = 1.0。
倾斜时:随倾斜角度增大,该值逐渐减小。
倒置时:该值为 1.0 → -projected_gravity_b[:, 2] = -1.0(被 clamp 限制为 0)。
缩放逻辑:
直立时(倾斜角 ≤ ~45°):缩放因子为 1.0(最大奖励)。
倾斜角 > 45°:缩放因子线性衰减。
倒置时(倾斜角 ≥ 90°):缩放因子为 0.0(奖励归零)。
def yaw_quat(quat: torch.Tensor) -> torch.Tensor:
"""Extract the yaw component of a quaternion.
Args:
quat: The orientation in (w, x, y, z). Shape is (..., 4)
Returns:
A quaternion with only yaw component.
"""
shape = quat.shape
quat_yaw = quat.clone().view(-1, 4)
qw = quat_yaw[:, 0]
qx = quat_yaw[:, 1]
qy = quat_yaw[:, 2]
qz = quat_yaw[:, 3]
yaw = torch.atan2(2 * (qw * qz + qx * qy), 1 - 2 * (qy * qy + qz * qz))
quat_yaw[:] = 0.0
quat_yaw[:, 3] = torch.sin(yaw / 2)
quat_yaw[:, 0] = torch.cos(yaw / 2)
quat_yaw = normalize(quat_yaw)
return quat_yaw.view(shape)
从四元数中提取绕 世界坐标系Z轴 的偏航角(yaw)分量,生成一个新的四元数。该四元数仅保留原始姿态中的偏航旋转,忽略俯仰(pitch)和翻滚(roll)分量。

4. track_ang_vel_z_world_exp
def track_ang_vel_z_world_exp(
env, command_name: str, std: float, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")
) -> torch.Tensor:
"""Reward tracking of angular velocity commands (yaw) in world frame using exponential kernel."""
# extract the used quantities (to enable type-hinting)
asset = env.scene[asset_cfg.name]
ang_vel_error = torch.square(env.command_manager.get_command(command_name)[:, 2] - asset.data.root_ang_vel_w[:, 2])
reward = torch.exp(-ang_vel_error / std**2)
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
该函数用于计算机器人跟踪绕世界坐标系z轴(yaw方向)角速度命令的奖励,结合了跟踪准确性和姿态稳定性。以下是代码的解析:
函数功能:
角速度跟踪奖励:计算机器人实际角速度与目标角速度在z轴方向的误差,使用指数函数转换为奖励,误差越小奖励越高。
姿态稳定性惩罚:根据机器人姿态调整奖励,直立时系数最大,倾斜或倒置时系数降低甚至归零,确保运动稳定性。
参数解析:
env: 环境对象,提供场景和机器人数据。
command_name: 角速度命令的名称,用于从命令管理器获取目标值。
std: 控制指数衰减宽度的标准差,值越大对误差容忍度越高。
asset_cfg: 场景实体配置,默认机器人。
5. joint_power
def joint_power(env: ManagerBasedRLEnv, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")) -> torch.Tensor:
"""Reward joint_power"""
# extract the used quantities (to enable type-hinting)
asset: Articulation = env.scene[asset_cfg.name]
# compute the reward
reward = torch.sum(
torch.abs(asset.data.joint_vel[:, asset_cfg.joint_ids] * asset.data.applied_torque[:, asset_cfg.joint_ids]),
dim=1,
)
return reward
函数解析:joint_power 函数用于计算机器人关节功率的奖励或惩罚项,旨在优化能量效率。以下为详细解析:
函数功能
关节功率计算:通过关节速度与应用扭矩的乘积绝对值之和,衡量机器人的能量消耗。
能量效率激励:鼓励策略降低关节功率,减少不必要的能量浪费,促进高效运动。
参数解析
env:强化学习环境对象,提供机器人状态数据(如关节速度、扭矩)。
asset_cfg:场景实体配置,默认机器人,可指定特定关节(通过 joint_ids)进行计算。
6. stand_still_without_cmd
def stand_still_without_cmd(
env: ManagerBasedRLEnv,
command_name: str,
command_threshold: float,
asset_cfg: SceneEntityCfg = SceneEntityCfg("robot"),
) -> torch.Tensor:
"""Penalize joint positions that deviate from the default one when no command."""
# extract the used quantities (to enable type-hinting)
asset: Articulation = env.scene[asset_cfg.name]
# compute out of limits constraints
diff_angle = asset.data.joint_pos[:, asset_cfg.joint_ids] - asset.data.default_joint_pos[:, asset_cfg.joint_ids]
reward = torch.sum(torch.abs(diff_angle), dim=1)
reward *= torch.linalg.norm(env.command_manager.get_command(command_name), dim=1) < command_threshold
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
函数功能
静止惩罚:当指令范数低于阈值(无有效指令)时,计算机器人关节位置与默认值的偏差,施加惩罚。
姿态稳定性:根据机器人直立程度调整惩罚权重,直立时惩罚最大,倾斜或倒下时降低惩罚。
指令感知:仅在没有指令时激活惩罚,避免干扰正常运动控制。
参数解析
env:强化学习环境对象,提供机器人状态及指令数据。
command_name:指令名称,用于判断当前是否有有效指令。
command_threshold:指令范数阈值,低于此值视为无指令。
asset_cfg:场景实体配置,默认机器人,可指定关节子集(通过 joint_ids)。
7. joint_pos_penalty
def joint_pos_penalty(
env: ManagerBasedRLEnv,
command_name: str,
asset_cfg: SceneEntityCfg,
stand_still_scale: float,
velocity_threshold: float,
command_threshold: float,
) -> torch.Tensor:
"""Penalize joint position error from default on the articulation."""
# extract the used quantities (to enable type-hinting)
asset: Articulation = env.scene[asset_cfg.name]
cmd = torch.linalg.norm(env.command_manager.get_command(command_name), dim=1)
body_vel = torch.linalg.norm(asset.data.root_lin_vel_b[:, :2], dim=1)
running_reward = torch.linalg.norm(
(asset.data.joint_pos[:, asset_cfg.joint_ids] - asset.data.default_joint_pos[:, asset_cfg.joint_ids]), dim=1
)
reward = torch.where(
torch.logical_or(cmd > command_threshold, body_vel > velocity_threshold),
running_reward,
stand_still_scale * running_reward,
)
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
函数解析:joint_pos_penalty 函数动态调整机器人关节位置偏离默认值的惩罚强度,结合运动状态和姿态稳定性实现多条件约束:
运动状态感知:根据指令强度(cmd)和本体速度(body_vel)判断是否处于运动状态。
惩罚动态缩放:静止状态时放大惩罚,运动状态时维持基础惩罚。
姿态自适应:通过重力投影系数调整惩罚权重,直立时惩罚最强,倾斜或倒置时减弱。

torch.linalg.norm(…, dim=1)
沿着维度 1 计算每个指令向量的范数(默认为 L2 范数,也就是欧几里得范数),得到一个形状为 (N,) 的张量,每个元素表示对应指令向量的大小。
关键逻辑拆解
- 运动状态判断:
condition = (cmd > command_threshold) or (body_vel > velocity_threshold)
条件成立(运动状态):使用基础惩罚值 running_reward,允许关节适度偏离默认位置以适应运动需求。
条件不成立(静止状态):惩罚值缩放为 stand_still_scale * running_reward,强化静止时的关节位置保持。
- 设计意图:运动时降低惩罚避免限制动作灵活性,静止时提高惩罚维持稳定姿态。
- 关节位置偏差计算:
running_reward = ||joint_pos - default_joint_pos||₂
计算各关节实际位置与默认位置的欧氏距离,反映整体偏差程度。
- 姿态稳定性调整:
reward *= clamp(-gravity_proj_z, 0, 0.7) / 0.7
直立(gravity_proj_z = -1):系数=1,全额施加惩罚。
倾斜(-0.7 < gravity_proj_z < 0):系数∈(0,1),按倾斜比例减弱惩罚。
倒置(gravity_proj_z ≥ 0):系数=0,禁用惩罚,优先恢复平衡。
8. class GaitReward
class GaitReward(ManagerTermBase):
"""Gait enforcing reward term for quadrupeds.
This reward penalizes contact timing differences between selected foot pairs defined in :attr:`synced_feet_pair_names`
to bias the policy towards a desired gait, i.e trotting, bounding, or pacing. Note that this reward is only for
quadrupedal gaits with two pairs of synchronized feet.
"""
def __init__(self, cfg: RewTerm, env: ManagerBasedRLEnv):
"""Initialize the term.
Args:
cfg: The configuration of the reward.
env: The RL environment instance.
"""
super().__init__(cfg, env)
self.std: float = cfg.params["std"]
self.command_name: str = cfg.params["command_name"]
self.max_err: float = cfg.params["max_err"]
self.velocity_threshold: float = cfg.params["velocity_threshold"]
self.command_threshold: float = cfg.params["command_threshold"]
self.contact_sensor: ContactSensor = env.scene.sensors[cfg.params["sensor_cfg"].name]
self.asset: Articulation = env.scene[cfg.params["asset_cfg"].name]
# match foot body names with corresponding foot body ids
synced_feet_pair_names = cfg.params["synced_feet_pair_names"]
if (
len(synced_feet_pair_names) != 2
or len(synced_feet_pair_names[0]) != 2
or len(synced_feet_pair_names[1]) != 2
):
raise ValueError("This reward only supports gaits with two pairs of synchronized feet, like trotting.")
synced_feet_pair_0 = self.contact_sensor.find_bodies(synced_feet_pair_names[0])[0]
synced_feet_pair_1 = self.contact_sensor.find_bodies(synced_feet_pair_names[1])[0]
self.synced_feet_pairs = [synced_feet_pair_0, synced_feet_pair_1]
def __call__(
self,
env: ManagerBasedRLEnv,
std: float,
command_name: str,
max_err: float,
velocity_threshold: float,
command_threshold: float,
synced_feet_pair_names,
asset_cfg: SceneEntityCfg,
sensor_cfg: SceneEntityCfg,
) -> torch.Tensor:
"""Compute the reward.
This reward is defined as a multiplication between six terms where two of them enforce pair feet
being in sync and the other four rewards if all the other remaining pairs are out of sync
Args:
env: The RL environment instance.
Returns:
The reward value.
"""
# for synchronous feet, the contact (air) times of two feet should match
sync_reward_0 = self._sync_reward_func(self.synced_feet_pairs[0][0], self.synced_feet_pairs[0][1])
sync_reward_1 = self._sync_reward_func(self.synced_feet_pairs[1][0], self.synced_feet_pairs[1][1])
sync_reward = sync_reward_0 * sync_reward_1
# for asynchronous feet, the contact time of one foot should match the air time of the other one
async_reward_0 = self._async_reward_func(self.synced_feet_pairs[0][0], self.synced_feet_pairs[1][0])
async_reward_1 = self._async_reward_func(self.synced_feet_pairs[0][1], self.synced_feet_pairs[1][1])
async_reward_2 = self._async_reward_func(self.synced_feet_pairs[0][0], self.synced_feet_pairs[1][1])
async_reward_3 = self._async_reward_func(self.synced_feet_pairs[1][0], self.synced_feet_pairs[0][1])
async_reward = async_reward_0 * async_reward_1 * async_reward_2 * async_reward_3
# only enforce gait if cmd > 0
cmd = torch.linalg.norm(env.command_manager.get_command(self.command_name), dim=1)
body_vel = torch.linalg.norm(self.asset.data.root_com_lin_vel_b[:, :2], dim=1)
reward = torch.where(
torch.logical_or(cmd > self.command_threshold, body_vel > self.velocity_threshold),
sync_reward * async_reward,
0.0,
)
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
"""
Helper functions.
"""
def _sync_reward_func(self, foot_0: int, foot_1: int) -> torch.Tensor:
"""Reward synchronization of two feet."""
air_time = self.contact_sensor.data.current_air_time
contact_time = self.contact_sensor.data.current_contact_time
# penalize the difference between the most recent air time and contact time of synced feet pairs.
se_air = torch.clip(torch.square(air_time[:, foot_0] - air_time[:, foot_1]), max=self.max_err**2)
se_contact = torch.clip(torch.square(contact_time[:, foot_0] - contact_time[:, foot_1]), max=self.max_err**2)
return torch.exp(-(se_air + se_contact) / self.std)
def _async_reward_func(self, foot_0: int, foot_1: int) -> torch.Tensor:
"""Reward anti-synchronization of two feet."""
air_time = self.contact_sensor.data.current_air_time
contact_time = self.contact_sensor.data.current_contact_time
# penalize the difference between opposing contact modes air time of feet 1 to contact time of feet 2
# and contact time of feet 1 to air time of feet 2) of feet pairs that are not in sync with each other.
se_act_0 = torch.clip(torch.square(air_time[:, foot_0] - contact_time[:, foot_1]), max=self.max_err**2)
se_act_1 = torch.clip(torch.square(contact_time[:, foot_0] - air_time[:, foot_1]), max=self.max_err**2)
return torch.exp(-(se_act_0 + se_act_1) / self.std)
(1) 类定义与用途
目的:
该类实现了一个步态奖励项,用于强化学习中鼓励四足机器人按照期望的步态(如小跑、跳跃或并步)运动。
适用范围:
仅针对具有两组同步足(两对同步脚)的四足步态设计。
继承:
继承自 ManagerTermBase,因此它是一个奖励项管理器,能够被环境和策略调用。
(2)构造函数 __ init __
参数说明:
cfg: 奖励项的配置信息,其中包含各种参数。
env: 强化学习环境实例,包含场景、传感器、机器人等信息。
主要成员变量初始化:
self.std: 标准差参数,用于后续奖励函数中控制指数衰减的“陡峭度”。
self.command_name: 指令名称,用于从环境中获取期望命令。
self.max_err: 允许的最大误差,用于对误差进行截断(clip)。
self.velocity_threshold 与 self.command_threshold: 分别对应速度和指令的阈值,只有当命令或速度超过阈值时才施加步态奖励。
self.contact_sensor: 从环境中提取用于检测足部接触情况的传感器。
self.asset: 从环境中获取机器人(或其它目标实体)的物理实体对象。
同步足对设置:
从配置 cfg.params 中获取 synced_feet_pair_names,该参数定义了两对需要同步的足。
代码要求必须有两对,每对包含两个足;否则抛出错误。
使用 self.contact_sensor.find_bodies 根据名称查找足部对应的 body id,并保存为 self.synced_feet_pairs。
(3) 核心方法 __ call __
def __call__(
self,
env: ManagerBasedRLEnv,
std: float,
command_name: str,
max_err: float,
velocity_threshold: float,
command_threshold: float,
synced_feet_pair_names,
asset_cfg: SceneEntityCfg,
sensor_cfg: SceneEntityCfg,
) -> torch.Tensor:
- 功能:
在每个时间步计算步态奖励,该奖励由多个项组合而成,主要包含两部分:
同步奖励(sync_reward): 奖励同一对足之间接触或离地时间尽量一致。
反同步奖励(async_reward): 奖励不同对足之间的接触与离地时间尽量错开(即一个足接触时另一足处于空中)。
- 计算流程:
同步奖励计算:
分别调用辅助函数 _sync_reward_func 计算两对同步足之间的奖励:
sync_reward_0 = self._sync_reward_func(self.synced_feet_pairs[0][0], self.synced_feet_pairs[0][1])
sync_reward_1 = self._sync_reward_func(self.synced_feet_pairs[1][0], self.synced_feet_pairs[1][1])
sync_reward = sync_reward_0 * sync_reward_1
两对足的同步奖励相乘,要求两组均同步时奖励高。
反同步奖励计算:
对于不同同步对之间的足,使用 _async_reward_func 计算奖励:
async_reward_0 = self._async_reward_func(self.synced_feet_pairs[0][0], self.synced_feet_pairs[1][0])
async_reward_1 = self._async_reward_func(self.synced_feet_pairs[0][1], self.synced_feet_pairs[1][1])
async_reward_2 = self._async_reward_func(self.synced_feet_pairs[0][0], self.synced_feet_pairs[1][1])
async_reward_3 = self._async_reward_func(self.synced_feet_pairs[1][0], self.synced_feet_pairs[0][1])
async_reward = async_reward_0 * async_reward_1 * async_reward_2 * async_reward_3
这里组合多种反同步关系,以鼓励不同对足之间呈现交替接触与离地的状态。
指令与速度阈值判断:
计算当前指令向量的范数(大小):
cmd = torch.linalg.norm(env.command_manager.get_command(self.command_name), dim=1)
计算机器人机体在水平面(前后左右)的速度大小:
body_vel = torch.linalg.norm(self.asset.data.root_com_lin_vel_b[:, :2], dim=1)
只有当指令或速度超过预设阈值时,才将同步与反同步奖励相乘作为最终奖励,否则奖励为 0:
reward = torch.where(
torch.logical_or(cmd > self.command_threshold, body_vel > self.velocity_threshold),
sync_reward * async_reward,
0.0,
)
重力调制:
为了进一步惩罚不利于机器人保持平衡的状态,最终奖励还乘以一个与重力方向相关的因子:
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
该因子确保当机器人受到更合理的重力投影时(例如保持直立),奖励更高。
返回奖励:
最终返回一个张量,代表当前时间步的步态奖励。
def _sync_reward_func(self, foot_0: int, foot_1: int) -> torch.Tensor:
"""Reward synchronization of two feet."""
air_time = self.contact_sensor.data.current_air_time
contact_time = self.contact_sensor.data.current_contact_time
# penalize the difference between the most recent air time and contact time of synced feet pairs.
se_air = torch.clip(torch.square(air_time[:, foot_0] - air_time[:, foot_1]), max=self.max_err**2)
se_contact = torch.clip(torch.square(contact_time[:, foot_0] - contact_time[:, foot_1]), max=self.max_err**2)
return torch.exp(-(se_air + se_contact) / self.std)
def _async_reward_func(self, foot_0: int, foot_1: int) -> torch.Tensor:
"""Reward anti-synchronization of two feet."""
air_time = self.contact_sensor.data.current_air_time
contact_time = self.contact_sensor.data.current_contact_time
# penalize the difference between opposing contact modes air time of feet 1 to contact time of feet 2
# and contact time of feet 1 to air time of feet 2) of feet pairs that are not in sync with each other.
se_act_0 = torch.clip(torch.square(air_time[:, foot_0] - contact_time[:, foot_1]), max=self.max_err**2)
se_act_1 = torch.clip(torch.square(contact_time[:, foot_0] - air_time[:, foot_1]), max=self.max_err**2)
return torch.exp(-(se_act_0 + se_act_1) / self.std)
_sync_reward_func(同步奖励函数)
功能:激励同一组足部的触地/腾空时间同步,确保组内动作协调。
- 步骤解析:
(1) 数据获取:
air_time = contact_sensor.data.current_air_time # 各足腾空时间 [batch_size, num_feet]
contact_time = contact_sensor.data.current_contact_time # 各足触地时间 [batch_size, num_feet]
current_air_time:每只脚最近一次连续腾空的时间长度(单位:秒)。
current_contact_time:每只脚最近一次连续触地的时间长度。
(2)计算同步误差:
se_air = torch.square(air_time[:, foot_0] - air_time[:, foot_1]) # 腾空时间差平方
se_contact = torch.square(contact_time[:, foot_0] - contact_time[:, foot_1]) # 触地时间差平方
示例:若左前脚(foot_0)腾空0.2秒,右后脚(foot_1)腾空0.25秒 → 误差 = (0.05)² = 0.0025。
(3)误差截断:
se_air = torch.clip(se_air, max=max_err**2) # 限制最大误差不超过max_err²
se_contact = torch.clip(se_contact, max=max_err**2)
目的:防止单次巨大误差(如某脚卡住)导致奖励崩溃,提升训练稳定性。
(4)奖励计算:
reward = exp( -(se_air + se_contact) / std )
效果:误差为0时奖励=1,误差趋近max_err²时奖励=exp(-max_err²/std)。
参数影响:std越小,奖励对误差越敏感(严格同步);std越大,允许更大误差。
_async_reward_func(异步奖励函数)
功能:激励不同组足部的触地/腾空时间错开,确保跨组动作交替。
步骤解析:
数据获取:与同步函数相同,获取腾空与触地时间。
计算异步误差:
se_act_0 = (air_time[:, foot_0] - contact_time[:, foot_1])² # foot0腾空 vs foot1触地
se_act_1 = (contact_time[:, foot_0] - air_time[:, foot_1])² # foot0触地 vs foot1腾空
设计意图:理想异步时,foot0腾空对应foot1触地,反之亦然,故二者差异应趋近于0。
示例(小跑步态):
foot0腾空期间,foot1应触地 → 若foot1也腾空,则air_time[foot0] - contact_time[foot1]为负,平方后增大误差。
误差截断与奖励计算:
se_act_0 = torch.clip(se_act_0, max=max_err**2)
se_act_1 = torch.clip(se_act_1, max=max_err**2)
reward = exp( -(se_act_0 + se_act_1) / std )
效果:当两足完美交替(如foot0腾空时foot1触地),误差=0,奖励=1。
9. joint_mirror
def joint_mirror(env: ManagerBasedRLEnv, asset_cfg: SceneEntityCfg, mirror_joints: list[list[str]]) -> torch.Tensor:
# extract the used quantities (to enable type-hinting)
asset: Articulation = env.scene[asset_cfg.name]
if not hasattr(env, "mirror_joints_cache") or env.mirror_joints_cache is None:
env.mirror_joints_cache = [
asset.find_joints(joint_name) for joint_pair in mirror_joints for joint_name in joint_pair
]
# compute out of limits constraints
diff1 = torch.sum(
torch.square(
asset.data.joint_pos[:, env.mirror_joints_cache[0][0]]
- asset.data.joint_pos[:, env.mirror_joints_cache[1][0]]
),
dim=-1,
)
diff2 = torch.sum(
torch.square(
asset.data.joint_pos[:, env.mirror_joints_cache[2][0]]
- asset.data.joint_pos[:, env.mirror_joints_cache[3][0]]
),
dim=-1,
)
reward = 0.5 * (diff1 + diff2)
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
return reward
这段代码定义了一个名为 joint_mirror 的函数,其主要作用是计算机器人关节镜像(对称)约束下的奖励值,衡量机器人左右(或对称部分)关节位置的相似性。下面逐步解析代码的实现细节:
(1)函数签名与参数
def joint_mirror(env: ManagerBasedRLEnv, asset_cfg: SceneEntityCfg, mirror_joints: list[list[str]]) -> torch.Tensor:
参数说明:
env:强化学习环境,包含场景、机器人和其它实体信息。
asset_cfg:配置对象,用于指定要操作的机器人或实体名称。
mirror_joints:一个二维列表,每个子列表包含一对对称关节的名称。函数利用这些关节对来计算镜像差异。
返回值:
返回一个 PyTorch 张量,表示计算出的奖励值,通常奖励值越低表示镜像误差越小(或根据设计,反之)。
(2)提取机器人实体
asset: Articulation = env.scene[asset_cfg.name]
从环境场景中获取指定名称的机器人实体(Articulation 对象),该对象包含了机器人关节的位置数据等信息。
(3)缓存镜像关节信息
if not hasattr(env, "mirror_joints_cache") or env.mirror_joints_cache is None:
env.mirror_joints_cache = [
asset.find_joints(joint_name) for joint_pair in mirror_joints for joint_name in joint_pair
]
目的:
为了避免每次调用都重复查找关节,将镜像关节的索引(或标识)缓存到 env.mirror_joints_cache 中。
实现细节:
判断环境中是否已经存在 mirror_joints_cache 属性,若不存在或为 None,则执行缓存操作。
对于 mirror_joints 中每个子列表(代表一对对称关节),对其中的每个 joint_name,调用 asset.find_joints(joint_name) 查找对应的关节,并将结果存入列表中。
(4)计算关节位置差异
- 计算第一对镜像关节的差异
diff1 = torch.sum(
torch.square(
asset.data.joint_pos[:, env.mirror_joints_cache[0][0]]
- asset.data.joint_pos[:, env.mirror_joints_cache[1][0]]
),
dim=-1,
)
过程说明:
从 asset.data.joint_pos 中提取缓存中第一对关节的位置信息。这里假定 env.mirror_joints_cache[0][0] 和 env.mirror_joints_cache[1][0] 分别代表第一对关节的索引。
计算这两个关节位置之间的差异,然后对差异进行平方(保证误差为非负)。
使用 torch.sum(..., dim=-1) 对最后一个维度求和,得到一个代表误差大小的标量或张量。
- 计算第二对镜像关节的差异
diff2 = torch.sum(
torch.square(
asset.data.joint_pos[:, env.mirror_joints_cache[2][0]]
- asset.data.joint_pos[:, env.mirror_joints_cache[3][0]]
),
dim=-1,
)
过程说明:
类似地,提取缓存中第二对关节的位置信息(假定索引分别为 env.mirror_joints_cache[2][0] 和 env.mirror_joints_cache[3][0])。
计算两者的差异的平方,并对最后一维求和得到误差度量。
(5)组合误差计算奖励
reward = 0.5 * (diff1 + diff2)
解释:
将两对关节的误差相加,并乘以 0.5 得到平均误差或加权后的误差。
这个误差值反映了机器人的镜像一致性,误差越小表示左右对称性越好。
- 重力方向的调制
reward *= torch.clamp(-env.scene["robot"].data.projected_gravity_b[:, 2], 0, 0.7) / 0.7
作用:
获取机器人在机体坐标系下重力在 Z 轴的投影值 env.scene["robot"].data.projected_gravity_b[:, 2]。
取其负值并使用 torch.clamp 限制在 [0, 0.7] 范围内,再除以 0.7进行归一化。
该调制因子通常用于根据机器人姿态(如是否直立)调整奖励,使得在机器人保持平衡时,镜像约束的奖励效果更明显。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











