




 本文详细解释了MySQL中select…forupdate锁的工作原理,包括其在InnoDB存储引擎下的行为,以及如何受事务隔离级别影响。通过实例分析了行锁与表锁的区别,以及不同查询条件对锁获取的影响,同时提到了防止死锁的方法和相关表字段的监控.
本文详细解释了MySQL中select…forupdate锁的工作原理,包括其在InnoDB存储引擎下的行为,以及如何受事务隔离级别影响。通过实例分析了行锁与表锁的区别,以及不同查询条件对锁获取的影响,同时提到了防止死锁的方法和相关表字段的监控.
select…for update锁详解
select…for update的作用就是:如果A事务中执行了select…for update,那么在其提交或回滚事务之前,B,C,D…事务是无法操作(写)A事务select…for update所命中的数据的!
前提条件
MySQL中通过select…for update实现悲观锁
select…for update仅适用于InnoDB,且查询需命中,事务需在手动提交下才能生效
MySQL事务隔离级别的不同会影响到上锁策略,本文内容基于MySQL默认隔离级别可重复读(REPEATABLE-READ)
-- 查询当前事务隔离级别
-- MySQL5.7.20版本之前
SHOW VARIABLES LIKE 'tx_isolation';
-- MySQL5.7.20版本及之后
SHOW VARIABLES LIKE 'transaction_isolation';
-- 都可使用
SELECT @@transaction_isolation;
-- 设置事务隔离级别为REPEATABLE-READ;session范围为当前会话,global全局范围
-- 方式1:
-- SET [GLOBAL|SESSION] TRANSACTION ISOLATION LEVEL 隔离级别;
-- 其中,隔离级别格式:
-- > READ UNCOMMITTED
-- > READ COMMITTED
-- > REPEATABLE READ
-- > SERIALIZABLE
set session transaction isolation level repeatable read;
-- 或
set global transaction isolation level repeatable read;
-- 方式2:
-- SET [GLOBAL|SESSION] TRANSACTION_ISOLATION = '隔离级别'
-- 其中,隔离级别格式:
-- > READ-UNCOMMITTED
-- > READ-COMMITTED
-- > REPEATABLE-READ
-- > SERIALIZABLE
SET SESSION TRANSACTION_ISOLATION = 'REPEATABLE-READ';
-- 或
SET GLOBAL TRANSACTION_ISOLATION = 'REPEATABLE-READ';
行锁,表锁
行锁:锁的是数据行,一条或多条数据
表锁:锁的是表,将整张表的全部数据锁住
select…for update锁的是行还是表,可以通过相关查询判断:
-- 查看正在执行的事务列表
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
-- 查看正在锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
-- 查看等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
-- 查询是否锁表
SHOW OPEN TABLES WHERE In_use > 0;
-- 查询进程
SHOW PROCESSLIST;
-- 查询死锁信息
SHOW ENGINE INNODB STATUS;
-- 杀死进程
KILL <thread_id>;
-- 设置超时时间防止死锁
SET innodb_lock_wait_timeout = <timeout_value>;
相关表字段分析:
innodb_trx表:
trx_id:事务ID。
trx_state:事务状态,有以下几种状态:RUNNING、LOCK WAIT、ROLLING BACK 和 COMMITTING。
trx_started:事务开始时间。
trx_requested_lock_id:事务当前正在等待锁的标识,可以和 INNODB_LOCKS 表 JOIN 以得到更多详细信息。
trx_wait_started:事务开始等待的时间。
trx_weight:事务的权重。
trx_mysql_thread_id:事务线程 ID,可以和 PROCESSLIST 表 JOIN。
trx_query:事务正在执行的 SQL 语句。
trx_operation_state:事务当前操作状态。
trx_tables_in_use:当前事务执行的 SQL 中使用的表的个数。
trx_tables_locked:当前执行 SQL 的行锁数量。
trx_lock_structs:事务保留的锁数量。
trx_lock_memory_bytes:事务锁住的内存大小,单位为 BYTES。
trx_rows_locked:事务锁住的记录数。包含标记为 DELETED,并且已经保存到磁盘但对事务不可见的行。
trx_rows_modified:事务更改的行数。
trx_concurrency_tickets:事务并发票数。
trx_isolation_level:当前事务的隔离级别。
trx_unique_checks:是否打开唯一性检查的标识。
trx_foreign_key_checks:是否打开外键检查的标识。
trx_last_foreign_key_error:最后一次的外键错误信息。
trx_adaptive_hash_latched:自适应散列索引是否被当前事务锁住的标识。
trx_adaptive_hash_timeout:是否立刻放弃为自适应散列索引搜索 LATCH 的标识。
innodb_locks表:
lock_id:锁 ID。
lock_trx_id:拥有锁的事务 ID。可以和 INNODB_TRX 表 JOIN 得到事务的详细信息。
lock_mode:锁的模式。有如下锁类型:行级锁包括:S、X、IS、IX,分别代表:共享锁、排它锁、意向共享锁、意向排它锁。表级锁包括:S_GAP、X_GAP、IS_GAP、IX_GAP 和 AUTO_INC,分别代表共享间隙锁、排它间隙锁、意向共享间隙锁、意向排它间隙锁和自动递增锁。
lock_type:锁的类型。RECORD 代表行级锁,TABLE 代表表级锁。
lock_table:被锁定的或者包含锁定记录的表的名称。
lock_index:当 LOCK_TYPE=’RECORD’ 时,表示索引的名称;否则为 NULL。
lock_space:当 LOCK_TYPE=’RECORD’ 时,表示锁定行的表空间 ID;否则为 NULL。
lock_page:当 LOCK_TYPE=’RECORD’ 时,表示锁定行的页号;否则为 NULL。
lock_rec:当 LOCK_TYPE=’RECORD’ 时,表示一堆页面中锁定行的数量,亦即被锁定的记录号;否则为 NULL。
lock_data:当 LOCK_TYPE=’RECORD’ 时,表示锁定行的主键;否则为NULL。
innodb_lock_waits表:
requesting_trx_id:请求事务的 ID。
requested_lock_id:事务所等待的锁定的 ID。可以和 INNODB_LOCKS 表 JOIN。
blocking_trx_id:阻塞事务的 ID。
blocking_lock_id:某一事务的锁的 ID,该事务阻塞了另一事务的运行。可以和 INNODB_LOCKS 表 JOIN。
查询条件影响锁规则
where条件:
| 条件 | 说明 | 行锁/表锁 |
|---|---|---|
| 主键 | 主键字段作为查询条件 | 行锁 |
| 索引 | 索引字段作为查询条件 | 行锁 |
| 普通字段 | 普通字段作为查询条件 | 表锁 |
-- id字段为主键
-- age字段创建B-TREE索引
CREATE TABLE stu (
id INT ( 11 ) NOT NULL AUTO_INCREMENT,
name VARCHAR ( 255 ) DEFAULT NULL,
age INT ( 11 ) DEFAULT NULL,
code VARCHAR ( 255 ) DEFAULT NULL,
PRIMARY KEY ( id ),
KEY idx_age ( age ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1570068 DEFAULT CHARSET = utf8;
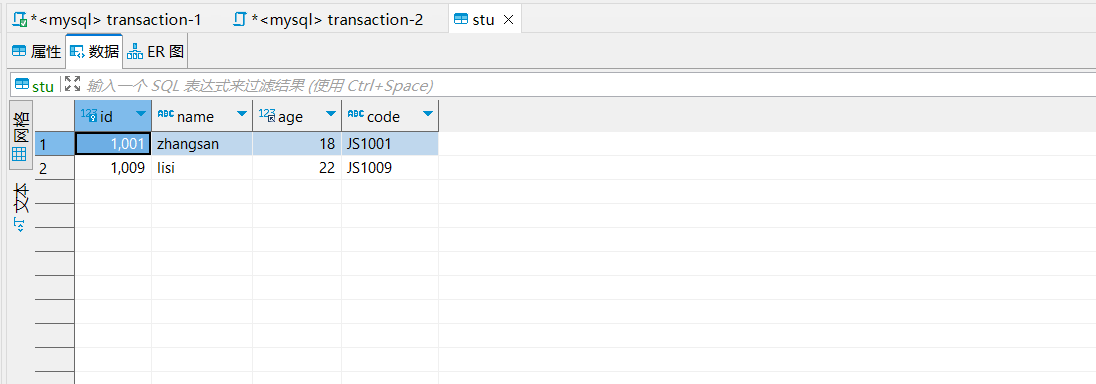
测试1
图1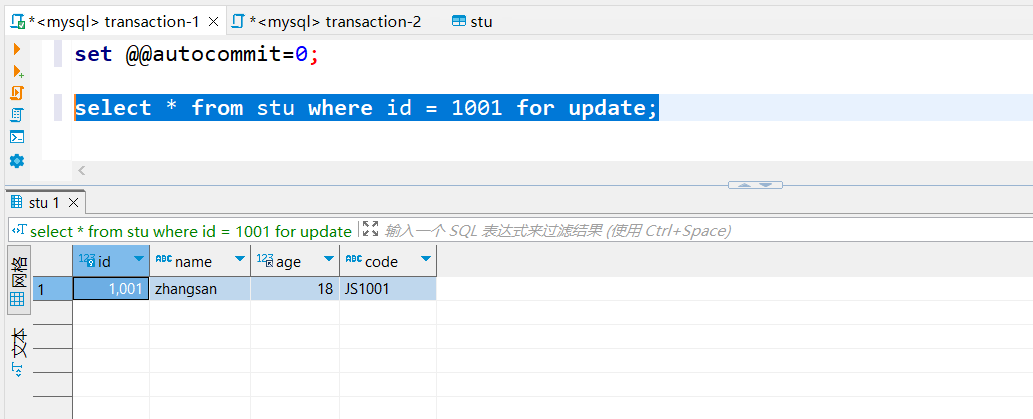
图2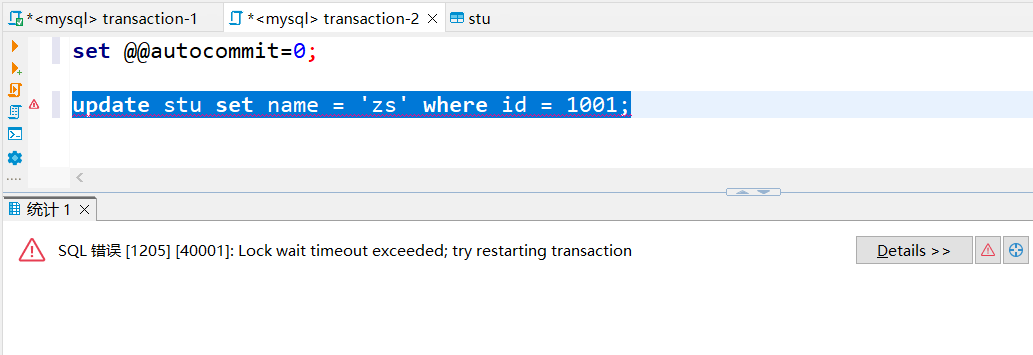
图3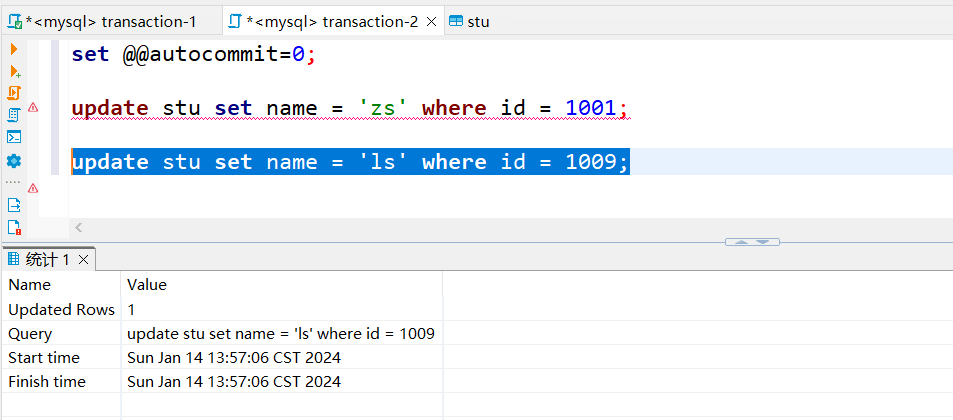
分析:
- 图1:A事务执行select * from stu where id = 1001 for update; 以主键字段作为查询条件
- 图2:B事务执行update stu set name = ‘zs’ where id = 1001; 对id为1001的数据(事务A查询出的数据)进行修改,阻塞等待,最后长时间拿不到锁报错
- 图3:B事务执行update stu set name = ‘ls’ where id = 1009; 对其他数据进行修改,修改成功
总结:
以主键字段作为条件上锁,锁的是行,是表中查询命中的数据
测试2
图1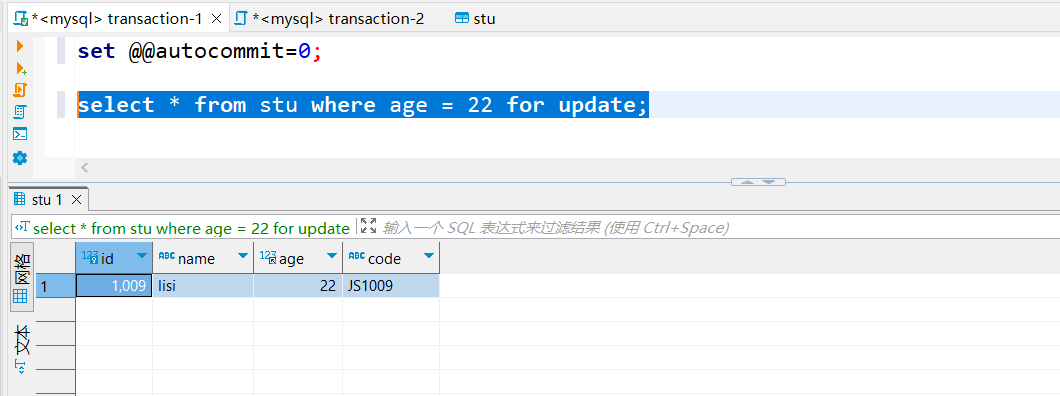
图2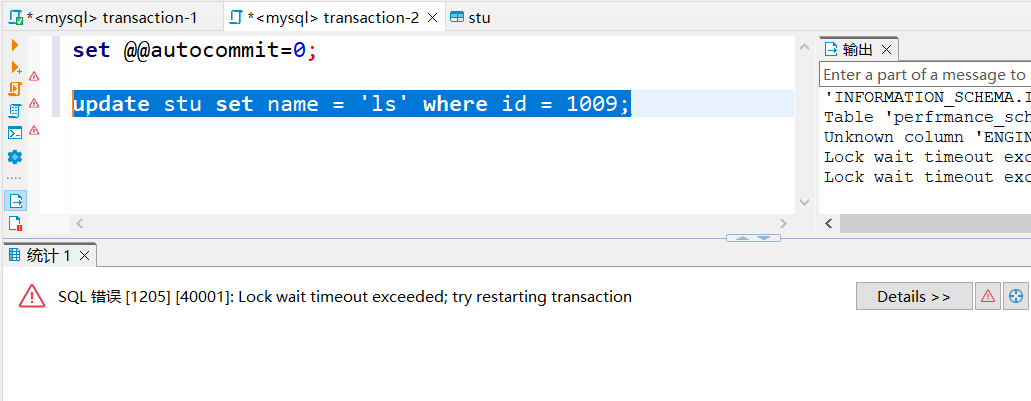
图3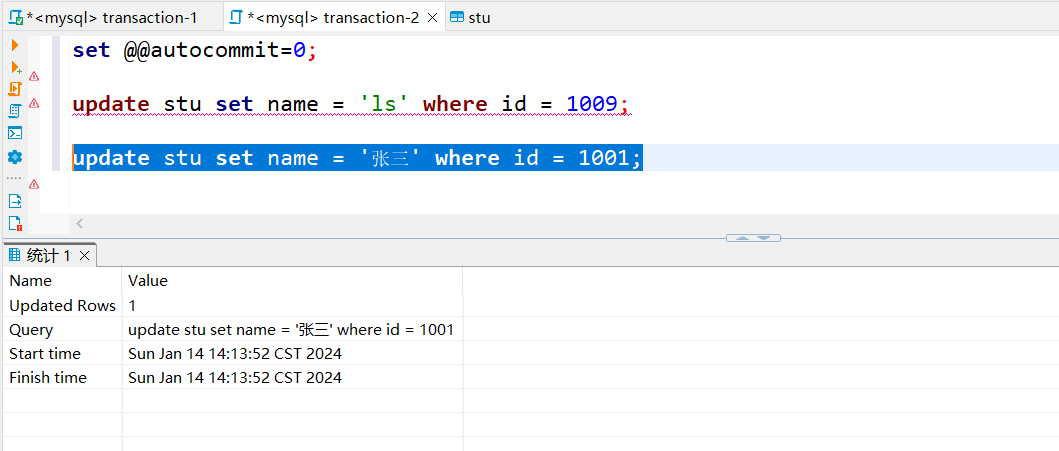
分析:
- 图1:A事务执行select * from stu where age = 22 for update; 以索引字段作为查询条件
- 图2:B事务执行update stu set name = ‘ls’ where id = 1009; 对id为1009的数据(事务A查询出的数据)进行修改,阻塞等待,最后长时间拿不到锁报错
- 图3:B事务执行update stu set name = ‘张三’ where id = 1001; 对其他数据进行修改,修改成功
总结:
以索引字段作为条件上锁,锁的是行,是表中查询命中的数据
测试3
图1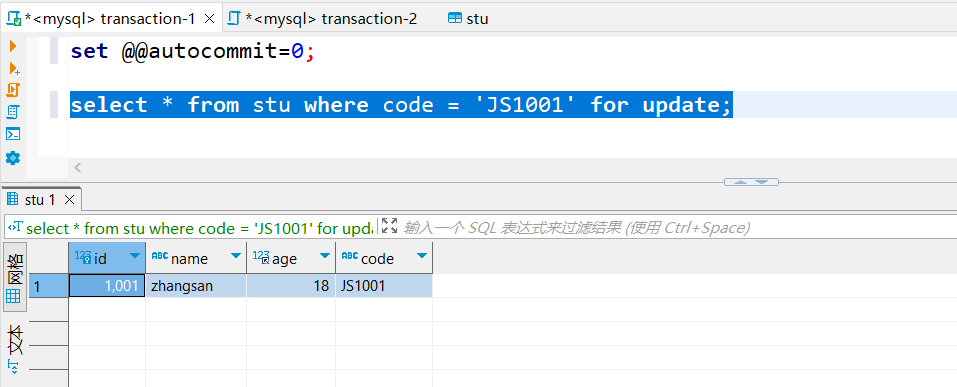
图2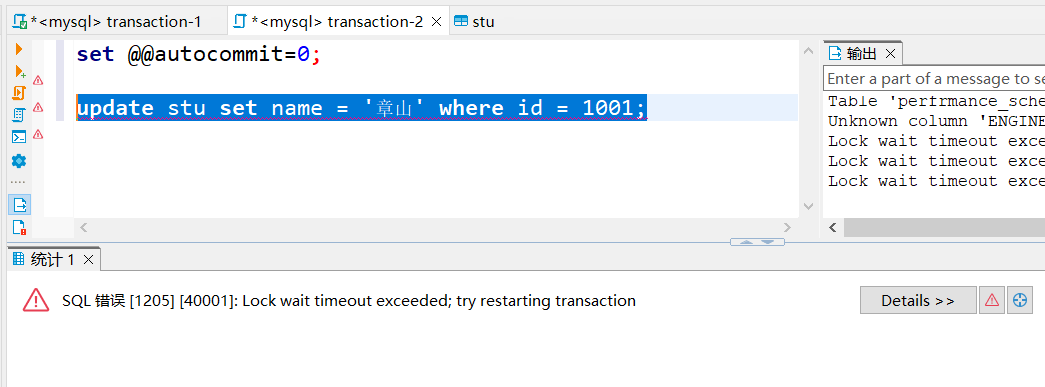
图3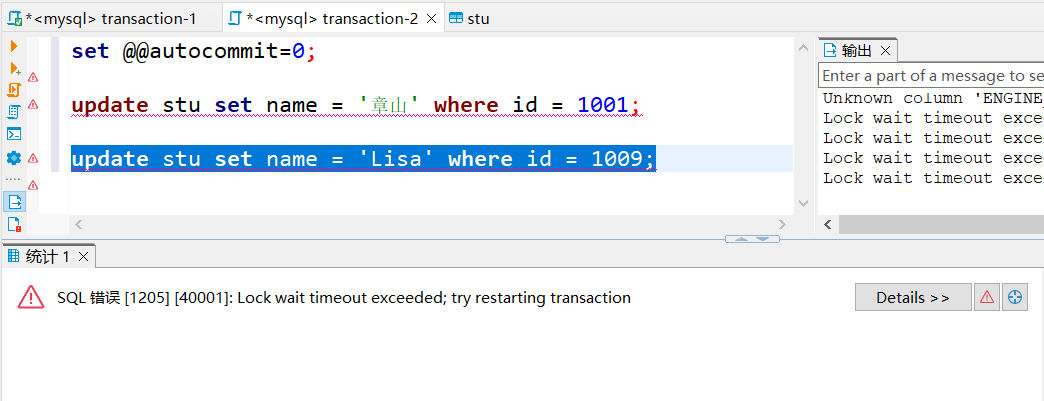
分析:
- 图1:A事务执行select * from stu where code = ‘JS1001’ for update; 以普通字段作为查询条件
- 图2:B事务执行update stu set name = ‘章山’ where id = 1001; 对id为1001的数据(事务A查询出的数据)进行修改,阻塞等待,最后长时间拿不到锁报错
- 图3:B事务执行update stu set name = ‘Lisa’ where id = 1009; 对其他数据进行修改,阻塞等待,最后长时间拿不到锁报错
总结:
以普通字段作为条件上锁,锁的是表,该表的全部数据
组合条件
and组合条件
| 条件 | 行锁/表锁 |
|---|---|
| 主键 and 索引 | 行锁 |
| 主键 and 普通字段 | 行锁 |
| 索引 and 普通字段 | 行锁 |
or组合条件
| 条件 | 行锁/表锁 |
|---|---|
| 主键 or 索引 | 行锁 |
| 主键 or 普通字段 | 表锁 |
| 索引 or 普通字段 | 表锁 |


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











