







 ELK是Elasticsearch、Logstash和Kibana的组合,提供日志收集和分析。Elasticsearch是实时分布式搜索和分析引擎,Logstash用于数据收集和解析,Kibana则用于数据的可视化分析。ELK支持分布式集群,数据源丰富,能体现数据价值。Elasticsearch的核心概念包括索引、类型、映射、文档、字段、集群、节点、分片和副本等。Kibana提供了数据的可视化界面,便于数据仪表分析。Elasticsearch的Java API支持创建索引、管理索引、搜索功能、分词计算、聚合查询等操作。
ELK是Elasticsearch、Logstash和Kibana的组合,提供日志收集和分析。Elasticsearch是实时分布式搜索和分析引擎,Logstash用于数据收集和解析,Kibana则用于数据的可视化分析。ELK支持分布式集群,数据源丰富,能体现数据价值。Elasticsearch的核心概念包括索引、类型、映射、文档、字段、集群、节点、分片和副本等。Kibana提供了数据的可视化界面,便于数据仪表分析。Elasticsearch的Java API支持创建索引、管理索引、搜索功能、分词计算、聚合查询等操作。
文章目录
ELK介绍
1.什么是ELK
ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash 和 Kibana。
1.1E-ELASTICSEARCH
ElasticSearch简称ES,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
1.2L-LOGSTASH
Logstash是一个具有实时传输能力的数据收集引擎,用来进行数据收集(如:读取文本文件)、解析,并将数据发送给ES。
1.3K-KIBANA
Kibana为 Elasticsearch 提供了分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
2.为什么要使用ELK
2.1分布式集群
- 数据量庞大:PB级别甚至更高
- 搜索需求要求高:快,准,多维度全文搜索
ELASTICSEARCH就支持这种场景,也是目前全文搜索功能使用最多的一种技术.
2.2数据源丰富
- 数据库数据
- 日志数据
- 其他分散存储的数据.
LOGSTASH可以从多数据源采集数据
2.3数据的价值
所谓数据保存的越多,数据提现的价值就越多.前提是需要分析展示数据.
KIBANA就可以提供数据的仪表分析等功能.
所以基于上述的一些问题,开源实时日志分析 ELK 平台能够完美的解决, ELK 由 ElasticSearch 、 Logstash 和 Kiabana 三个开源工具组成。
ELASTICSEARCH概括
1.ES安装和启动
1.1安装
- 下载ES最新版本的安装包
截止到本笔记时间,最新版本是7.10.2,ES的更新速度非常之快,但是我们应该合理运用ES的官方文档帮助我们实现学习和深入.
- 上传到服务器解压安装
上传,并且进行解压.使用的软件是开源免费的finalshell
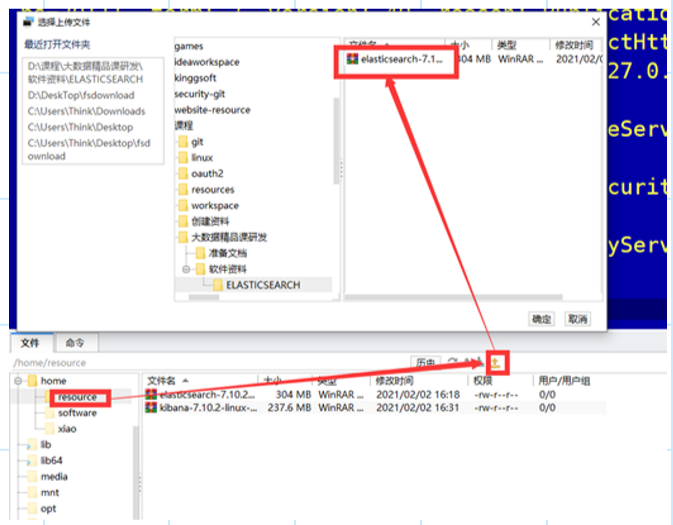
- 调用命令解压:
[root@10-42-17-191 software]# tar -zxvf /home/resource/elasticsearch-7.10.2-linux-x86_64.tar.gz -C /home/software/
- 配置es根目录下的jdk环境
当前版本的es7.10.2,要求最推荐使用jdk11以上的环境,根目录已经准备好了jdk15.
1.2启动
安装完成之后我们可以在服务器启动这个ES软件
- 添加用户用户组
ES拒绝root用户直接启动软件,需要创建新用户,并且赋权启动.
[root@10-9-182-139 config]# groupadd tedu
[root@10-9-182-139 config]# useradd tedu -g tedu
- 赋权
[root@10-42-17-191 config]# chown -R tedu:tedu /home/software/elasticsearch-7.10.2
- 启动ES
[tedu@10-42-17-191 elasticsearch-7.10.2]$ ./bin/elasticsearch
- 测试es进程
发送一个http请求,查看es
tarena@tedu:~/software/elasticsearch-7.10.2$ curl "localhost:9200"
1.3配置集群启动
上述启动的是单节点进程,如果按照默认配置,实际上是多个服务器各自启动一个ES进程,想要将他们添加到同一个集群,需要进行配置.配置文件就是ES目录中的config/elasticsearch.yml文件:
cluster.name: es-cluster
node.name: es01
path.data: /home/software/elasticsearch-7.10.2/data
path.logs: /home/software/elasticsearch-7.10.2/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.42.129", "192.168.42.131","192.168.42.130"]
cluster.initial_master_nodes: ["192.168.42.129"]
http.cors.enabled: true
http.cors.allow-origin: "*"
- cluster.name
集群名称,同一个服务器集群的节点实例的集群名称要一致.
- node.name
节点名称,也就是你启动的每个es的进程的名字.
- path.data
数据路径,指定当前es进程节点的存储数据的文件夹.
注意:如果路径不在启动es用户的权限范围之内,启动会报错
- path.logs
es启动的日志文件夹.
注意:如果路径不在启动es用户的权限范围之内,启动会报错
- bootstrap.memory_lock
锁定物理内容,会造成性能降低,将其关闭.
- bootstrap.system_call_filter
系统调用过滤器主要是防止任意代码攻击漏洞的.将其关闭.
- network.host
es进程绑定的物理ip可以ipv4 可以ipv6,默认是localhost不允许外界访问.
- http.port
es进程绑定占用的http协议访问端口,默认9200.
- transport.tcp.port:
es进程绑定单用的tcp协议访问端口,默认9300
- discovery.seed_hosts
配置主机hosts名单,主要可以使用ip:port的方式来配置.有几个节点,就配置几个节点.
- cluster.initial_master_nodes
集群第一次启动初始化时,想要指定的主机节点是谁,一旦配置,初始主机节点就定了,后续可以将这个配置删除.
- http.cors.enabled
是否支持跨域访问,如果支持,有一些代理软件是可以访问es的比如head插件
- http.cors.allow-origin
当设置了支持跨域后,允许的跨域域名都有哪些,默认是*.
将多个es节点按照需求配置完成所有内容,如下所示.
ES01节点:
cluster.name: es-cluster
node.name: es01
path.data: /home/software/elasticsearch-7.10.2/data
path.logs: /home/software/elasticsearch-7.10.2/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.42.129", "192.168.42.131","192.168.42.130"]
cluster.initial_master_nodes: ["192.168.42.129"]
http.cors.enabled: true
http.cors.allow-origin: "*"
ES02节点:
cluster.name: es-cluster
node.name: es02
path.data: /home/software/elasticsearch-7.10.2/data
path.logs: /home/software/elasticsearch-7.10.2/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.42.129", "192.168.42.131","192.168.42.130"]
cluster.initial_master_nodes: ["192.168.42.129"]
http.cors.enabled: true
http.cors.allow-origin: "*"
ES03节点:
cluster.name: es-cluster
node.name: es03
path.data: /home/software/elasticsearch-7.10.2/data
path.logs: /home/software/elasticsearch-7.10.2/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.42.129", "192.168.42.131","192.168.42.130"]
cluster.initial_master_nodes: ["192.168.42.129"]
http.cors.enabled: true
http.cors.allow-origin: "*"
最后将3个节点挨个启动.一个分布式的集群就搭建好了
1.4测试访问
我们可以连接任意一个节点的9200端口进行集群的测试
http://192.168.42.129:9200 得到返回结果
{
"name" : "es01",
"cluster_name" : "es-cluster",
"cluster_uuid" : "h9ffNy1YRleRuimyJ0AXQA",
"version" : {
"number" : "7.10.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "747e1cc71def077253878a59143c1f785afa92b9",
"build_date" : "2021-01-13T00:42:12.435326Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2.ES的head插件
head插件是一个可以帮助用户代理访问es的,可以图形界面展示数据的插件.我们配置了es的跨域开启,所以为了方便观察,我们可以安装head插件
2.1node.js安装
- 下载
wget https://nodejs.org/dist/v15.0.0/node-v15.0.0-linux-x64.tar.gz
在这里可以手动选择比较新的版本,node的环境也是对应操作系统的,所以这里选择linux系统.
- 解压
[root@localhost resource]# tar -xvf node-v15.0.0-linux-x64.tar.gz -C /home/presoft/
-
环境变量
-
- 打开/etc/profile
-
-
[root@localhost resource]# vim /etc/profile -
- 编辑内容
-
NODE_HOME=/home/presoft/node-15 PATH=$PATH:./:/home/software/elasticsearch-7.10.2/jdk/bin:$NODE_HOME/bin export PATH NODE_HOME 退出编辑内容,使得编辑生效. -
验证node安装
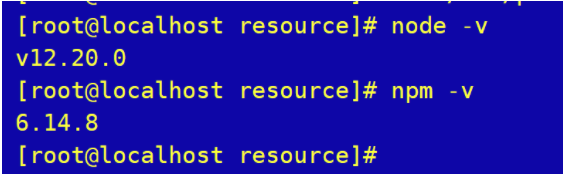
2.2head插件安装和启动
- 下载head插件
我们可以从git上下载head插件.
[root@localhost resource]# yum -y install git
[root@localhost resource]# git clone https://github.com/mobz/elasticsearch-head.git
- npm安装
在head插件文件夹的根目录执行npm安装
[root@localhost elasticsearch-head]#npm install -g grunt
[root@localhost elasticsearch-head]npm install
- 配置head文件(云主机必做)
在GruntFile.js中配置97(有可能版本不同有上下浮动)行内容,添加一个hostname
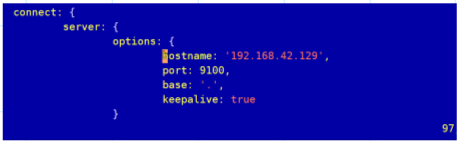
-
启动head(云主机必做)
直接在head根目录运行命令启动,grunt server.

-
访问这个地址
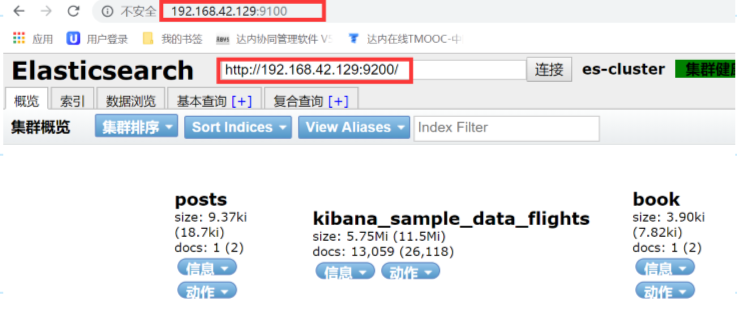
ELASTICSEARCH核心概念
1.ES中的重要概念
1.1索引(index)
类似于关系型数据中的库-database,一个es的集群中可以有多个索引,每个索引都是一批独立的存储数据,按照一定的数据结构保存,方便查询.
1.2类型(type)
类似于关系型数据库中的表格-table,一个索引中可以有多个类型,每个类型中的数据结构是一致的.
注意:6.x中使用类型,但是在7.x版本中,所有索引的类型只有一个叫做_doc,在8.x的版本将会彻底移除类型的概念.目的是提升索引的效率.
1.3映射(mapping)
类似于关系型数据库中定义的结构-schema,主要用来定义我们想要往es索引里存储的数据结构,到底是string还是数字,还是布尔等等.
1.4文档(document)
类似于关系型数据库中的行数据-rows,是es中存储数据的最小数据单元.每个文档都能根据数据的结构,有多个字段field存在.而field的类型,在存储数据时,是由mapping映射决定的.
1.5字段(field)
类似于关系型数据库中的列数据-columns,每个文档都由多个field组成.
1.6集群(cluster)
Es是天生分布式集群的结构,每个es进程都属于一个集群,即使只有一个Es进程在启动,它也是一个集群.不同集群由集群名称分开.
1.7节点(node)
每个ES进程都是一个节点,每个节点都有自己的名字.
1.8分片(shard)
单台机器存储数据量是有限的,es可以将一个index下的数据分为多个shard,存储在不同的机器上,横向扩展,存储更多的数据,而且可以让搜索,分析等操作分步到多个机器上去执行,提升吞吐量和性能。每个shard都是一个lucene index
1.9分片复制(Replica)
每台机器都可能会不可用,此时shard上的数据就可能会丢失。因此可以为每个shard建立多个副本,保证在一个shard不可用时还可以使用副本,且保证数据不丢失,还能提升查询性能。
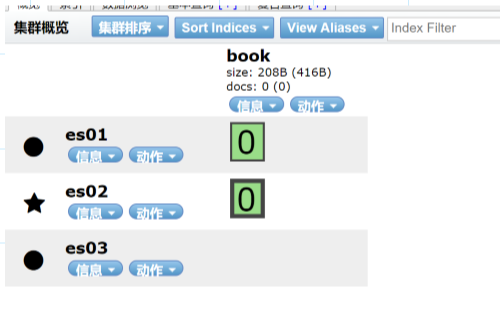
注意:主分片的个数是在建立索引时定下的,不能修改,默认为5个,副本分片,可以随时修改,默认是1个。因为要保证高可用,所以每个分片的的主分片和副本分片不能在一台机器上,所以保证最小高可用配置,需要两台服务器
1.10接近实时(Near Reatime-NRT)
从写入数据到可以被搜索到会有一些延时,大概1秒左右,基于es执行搜索和分析可以达到秒级
ELASTICSEARCH索引数据
1.REST命令
ES支持http协议的REST风格接口访问,所以我们需要一个"东西"帮助我们发送http请求,这个东西可以是插件,软件,比如head,kibana,也可以使用CURL命令完成
1.1CURL
curl命令,是linux系统中的一个命令脚本,支持http协议.它的语法格式为:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>' -H'<headers>'
上述语法中有2个选项-X -d -H还有一些<**>的变量,这是一个最基本的使用语法,我们先来掌握它的使用
- 选项
-X:表示请求方式
-d:请求实体内容,es中的实体内容就是json格式字符串
-H:请求头信息
- 参数:

curl -X PUT "localhost:9200/person/_doc/1?pretty" -H 'Content-Type: application/json' -d
'{
"name": "liulaoshi"
}'
如果严格按照语法中使用协议也可以把"*"中的请求url替换成 http://localhost:9200/person/_doc/1
1.2KIBANA的developer tool
简化用户使用操作es的方便工具.后续我们会一直使用.
2.索引的管理
2.1索引的创建
[root@localhost ~]# curl -XPUT "192.168.42.129:9200/book?pretty"
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "book"
}
2.2插入一个文档
所有数据文档在ES中都是存储的一个json字符串,我们可以在已存在的索引中添加我们的第一条文档数据.
[root@localhost ~]# curl -XPUT "192.168.42.129:9200/book/_doc/1?pretty" -d '{"name":"王翠花"}' -H 'Content-type:application/json'
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
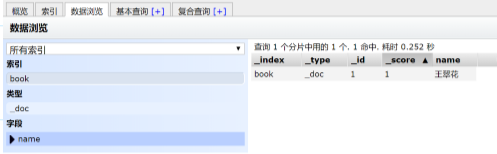
2.3查询一个文档
[root@localhost ~]# curl -XGET "192.168.42.129:9200/book/_doc/1?pretty"
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "王翠花"
}
}
2.4更新一个文档
和新增一样,重新增加一个id相同的文档数据
2.5删除一个文档
[root@localhost ~]# curl -XDELETE "192.168.42.129:9200/book/_doc/1?pretty"
{
"_index" : "book",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
2.6删除一个索引
新创建完索引,也可以查询一下这个索引.
[root@localhost ~]# curl -XDELETE "192.168.42.129:9200/book?pretty"
{
"acknowledged" : true
}
2.7批量索引
如果有许多文档需要索引,可以使用批量API批量提交它们。使用批量来批处理文档操作比单独提交请求要快得多,因为它减少了网络往返。这里可以使用es官方提供的一个数据集合,当然也可以自己准备.
这是一个.json文件,叫做accounts.json放到服务器中.
[root@localhost resource]# curl -H "Content-Type: application/json" -XPUT "192.168.42.129:9200/bank/_bulk?pretty" --data-binary "@json的文件名"
3.搜索功能
ES提供了非常多种的搜索功能.我们可以从多维度搜索我们需要的数据.所有的查询条件在HTTP的REST风格中都是对应的json字符串.
3.1match_all
这是一个最简单的,没有任何查询约束的查询条件,它就是将当前的所有文档数据查询出来.
curl -XGET http://127.0.0.1:9200/bank/_search?pretty -d '{"query":{"match_all":{}}}' -H 'Content-Type:application/json'
这里可以对一个具体的索引bank进行搜索请求,然后携带一个请求数据就是我们json中的查询条件,为了后续展示方便我们只展示这个json格式数据.

3.2 term
term:词项,在文档增加到es的时候进行分词计算的一个单位.是查询过程中一个计算使用的最基本单位.词项的组成结构 field:query
- 分词计算: 将一个文本按照分次计算器的逻辑拆分的过程,就是分词计算,例如当我们把{“name”:“王翠花”}写进es的时候,es会将"王翠花" 计算拆分成 “王”,“翠”,"花"三个词项,当然,文本如何进行拆分也可以指定拆分逻辑,以方便我们更好的查询和组织查询逻辑.es默认计算分词的逻辑是将英文按照词语拆分,将中文按照字拆分.
所以词项term查询,返回的文档是包含查询
提供的确切词项进行的,如果文档没包含这个词项,那么就不会在查询结果中展示.

上述查询条件中,使用term查询,会返回文档中 address字段包含"lane"的所有数据,还可以在term查询中添加附加条件属性.
由于多添加了boost属性,使得每个查询结果的文档评分最终会以相乘boost的结果返回.所以value属性必须添加.
注意:由于分词计算的存在,避免使用term查询做全文的文本检索,例如

这样的搜索是查不到数据的,因为不存在一个在address字段中的词项叫做"929 Eldert Lane".要使用全文文本检索,请使用match查询
3.3range
返回一个范围内的所包含的文档,这个范围有上限和下限.

该查询定义了balance的一个范围 [19000,20000].范围定义可以使用的四个值是
- gt:大于
- lt:小于
- gte:大于等于
- lte:小于等于
3.4exits
返回的是包含某些指定查询的字段,包含则返回不包含则不返回

这里表示,文档的字段不能存在的原因可以有以下几个:
- 写入的索引字段值在json中是null或者[]
- 字段设置了"index":false的映射导致不会写入到索引中
- 字段设置了ignore_above,当超出长度不会写入索引
3.5match
**匹配查询(match)**会返回我们提供的查询条件文本,日期,布尔,数字相匹配的文档数据,与term查询不同的是,match查询会在查询之前对我们提供的数据先进行分词计算,默认使用的分词计算器就是查询的索引中的分词器,我们也可以使用自定义分词器.
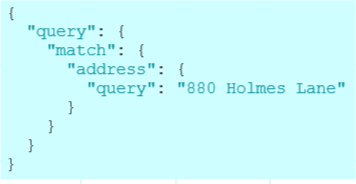
这里的结构和term一样,match下的第一级字段就是我们想要查询的文档字段,里面包含了一个属性query就是我们要查询的文本,这时,es会接收到请求,根据"880 Holmes Lane"文本进行解析 “880” “Holmes” “Lane” ,只要包含这3个词项的都会返回,默认情况下我们的查询文本最长会使用解析出来的50个分词.我们还可以指定词项之间的逻辑关系,默认是OR也就是三个词项查询的并集,我们还可以查询交集AND,只要在match查询条件中附加更多的属性.
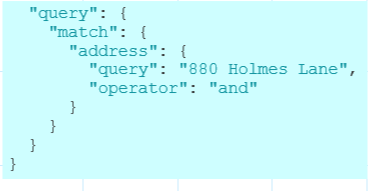
3.6bool
由多个子查询组成的布尔查询,可以定义多个子查询对最终结果的影响逻辑关系.

这个布尔查询中,就只有一个子条件match,所以和单独使用match查询结果是一样的.must表示布尔查询结果必须是这个子条件的子集(子集概念要清楚,全部算子集,一部分算子集,空集也算子集).

这里有2个子条件,都是must逻辑关系,所以最终查询结果是两个match的交集.既要address中有lane也要state是MD.
布尔查询中有4中逻辑关系值,我们见到了一个must
- must: 布尔结果必须是must子条件的查询子集
- must_not: 布尔结果必须不是must_not子条件的子集
- should: 查询结果可能是也可能不是这个条件的子集,should和must同时使用,should的唯一作用就是影响最终相关性的评分计算.会让计算考虑多一个条件.

- filter:查询结果必须是该条件子集,但是满足filter子条件的结果要忽略评分,也就是其他子条件的查询评分不会应为filter的存在而变化

ELASTICSEARCH索引的映射和设置
1.MAPPING
映射(MAPPING)就是es中一个决定了文档如何存储,如何生成索引,字段各种类型定义的过程.类似于我们在关系型数据库中创建一个表格数据之前先定义表格有哪些字段,每个字段是什么类型,然后数据会按照这个配置写入表格,ES中同样是这个过程,它由两种映射组成.一个是动态映射(dynamic mapping)一个是静态映射(explicit mapping).各自都具备各自的长处和短处,比如动态映射使得我们索引数据的时候很方便,静态映射是当我们想特指一些特殊的,或者需求需要的结构时使用.
注意:从7.0开始,es中将逐渐删除type类型的概念,所以和7.0之前的版本设置mapping有区别,不在添加自定义类型,到了8.0就会彻底消失.
1.1Dynamic Mapping(动态映射)
动态映射允许您在刚刚开始时就对数据进行试验和研究。Elasticsearch通过索引文档自动添加新字段。您可以向顶级映射、内部对象和嵌套字段添加字段。
总的来讲,使用dynamic mapping你不需要做任何修改和操作,都是默认的.
- 查询一个mapping
当我们创建一个索引之后,在索引中随意添加一个数据,都会自动生成mapping映射.
[root@localhost ~]# curl -XPUT http://192.168.42.129:9200/index02?pretty -H 'Content-Type:application/json'
创建完这个索引我们来查看一下mapping.
[root@localhost ~]# curl -XGET http://192.168.42.129:9200/index02/_mappings?pretty -H 'Content-Type:application/json'
其返回结果如下,看起来是个空的配置.

- 新增一个索引文档
当我们新增一个文档数据的时候,就会因为默认的mapping,动态生成对应结构.
[root@localhost ~]# curl -XPUT http://192.168.42.129:9200/index02/_doc/1?pretty -H 'Content-Type:application/json' -d '{"name":"王翠花","address":"北京市大兴区亦庄开发区科创十三街28号","sorted":false,"employed_time":"2020-01-05","location":{"lat":41.12,"lon":-71.34},"salary":20000.0,"ip":"10.9.42.129","age":19}'
其中包含的数据json如下:
{
"name": "王翠花",
"address": "北京市大兴区亦庄开发区科创十三街28号",
"sorted": false,
"employed_time": "2020-01-05",
"location": {
"lat": 41.12,
"lon": -71.34
},
"salary": 20000.0,
"ip": "10.9.42.129",
"age": 19
}
在这个案例中,我们由数据字符串name,address,有日期 employed_time,有地理位置location 有浮点数salary 有ip地址 ip,还有整数一些常用的类型数据都包含在内.
- 查看动态生成的mapping
[root@localhost ~]# curl -XGET http://192.168.42.129:9200/index02/_mappings?pretty -H 'Content-Type:application/json'
得到的返回结果如下,这些都是动态mapping映射生成的结构.

这个JSON的基本格式是这样的:

我们可以分字段来讨论这些结构
- 字符串类型
在数据中我们字符串类型有name,address和ip,他们动态映射结构是一致的

address表示字段名称,后面的{}内容就是描述这个字段在映射中的结构.
- type:表示字段类型,每一个字段都必须包含一个类型的属性,字符串字段会添加一个text类型
- fields:可选的一个属性,它表示给当前字段扩展的属性,扩展了一个类型keyword,这样一来,当前字符串address就既具备text类型的特点,也具备keyword类型的特点.
- text和keyword类型区别:都可以表示字符串,但是text类型会被分词器计算,默认使用索引的分词器,而keyword不会被计算分词,例如:名字,邮箱,id值,url地址这些文本计算分词是没有意义的.我们可以使用分词计算词项查询该字段,也可以在字段上添加*.keyword使用keyword类型查询数据的整体内容,ignore_above表示当我这个字段的长度大于256时,keyword扩展类型消失
- 整数类型

age字段,类型是long,所以整数默认映射是long,还可以是integer
- 浮点数类型

salary字段,类型float,默认浮点数类型float,还可以时double
- 日期类型

employed_time字段,日期类型,默人date yyyy-MM-dd
- 对象类型

location字段,在写入索引文档时,location字段对应的是**{}结构**,所以在动态映射中对应它指定了对象类型,对于这个json里包含的lat,和lon继续按照默认配置指定了浮点数float类型
1.2EXPLICIT MAPPING(静态映射)
我们自己肯定比ES更了解我们的数据,如果需要我们可以在创建索引时就指定mapping或者在一个已存在的索引中添加mapping.
- 创建索引时添加mapping
[root@localhost ~]# curl -XPUT http://192.168.42.129:9200/index03?pretty -H 'Content-Type:application/json' -d '{"mappings":{"properties":{"email":{"type":"keyword"}}}}'
在这个命令汇总我们添加了一个索引并且指定了一个mappings.

这个mapping定义了email这个字段只有文本的keyword属性,并且不会被索引,也就是存储在索引中不能使用该字段搜索.
- 在已存在的索引中添加mapping
[root@localhost ~]# curl -XPUT http://192.168.42.129:9200/index03/_mapping?pretty -H 'Content-Type:application/json' -d '{"properties":{"id":{"type":"keyword"}}}'
这里我们新增了一个字段的mapping.
{
“properties”: {
“id”: {
“type”: “keyword”
}
}
}
- 更新索引的映射
正常情况下,我们不能更新一个已存在的索引mapping,这会导致索引数据的无效.
- 查看一个索引mapping
[root@localhost ~]# curl -XGET http://192.168.42.129:9200/index03/_mapping?pretty
- 查看一个索引字段的mapping
可以一次只查看一个或几个字段的mapping映射.
[root@localhost ~]# curl -XGET http://192.168.42.129:9200/index03/_mapping/field/id?pretty
它的返回值是:

也可以一次查询多个字段,只要在字段位置使用逗号隔开多个字段即可
[root@localhost ~]# curl -XGET http://192.168.42.129:9200/index03/_mapping/field/id,email,name?pretty
2.SETTING设置
每一个索引都有一个settings属性,这里就是对该索引的一些设置值.也有动态和静态之分,静态索引创建后不可修改的值,动态是索引在使用时也可以修改,比如分片和副本
2.1分片
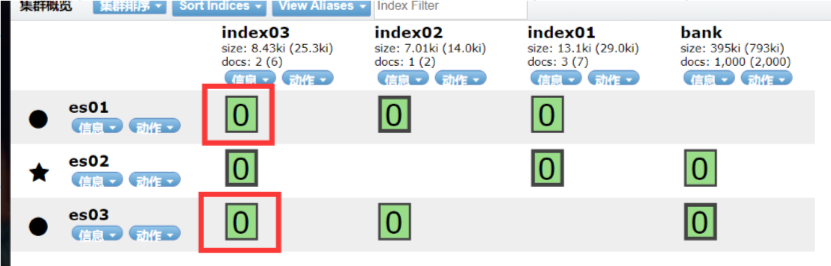
为了让一个索引文件行程并行读写,提升效率,每一个索引都有一个设置的属性叫做分片,在7.10.2版本中,索引的分片默认是1,这也就是为什么我们在搭建es之后通过head插件能够看到一个索引有一个分片.可以修改number_of_shards来决定分片个数.
curl -XPUT "http://10.42.60.224:9200/index07" -H 'Content-Type: application/json' -d'{ "settings": { "number_of_shards": 5 }}'
2.2副本
为了让一个索引的每一个分片都是高可用的,不会因为部分分片不可用导致整个索引丢失数据,可以引入副本的配置,每一个分片默认都是有一个副本的,副本的设置是动态的,所以我们可以对一个正在使用的索引修改他的副本数量,属性名称 index.number_of_replicas
[root@localhost ~]# curl -XPUT http://192.168.42.129:9200/index03/_settings?pretty -H 'Content-Type:application/json' -d '{"index":{"number_of_replicas":2}}'
ELASTICSEARCH分词计算和热词更新
1.分词
ES中为了方便查询,提供多维度的查询功能,对存储在索引中的文档进行分词计算,但是文本内容不同,类型不同,语言不同分词计算逻辑就不会一样.
1.1概括
文本分析使Elasticsearch能够执行全文搜索,其中搜索返回所有相关结果,而不仅仅
是精确匹配.
如果您搜索"王者荣耀",您可能希望包含"王者","荣耀"和"王者荣耀"的文档,还可能希望包含相关"王"或"者"的文档。
- Tokenization
该过程将文本拆分成一小块一小块,这一小块内容称之为token,大多数情况下一个token代表着一个词语;
- Normalization
词条化允许在单个术语上进行匹配,但是每个标记仍然是字面上匹配的。这就意味着:
- 搜索"Quick"不会匹配"quick",即使你觉得或希望这样
- 虽然"fox"和"foxes"有着相同的词根,但是对于fox的搜索并不匹配foxes,反之亦然。
- 搜索"jumps"不会匹配"leaps",他们不同根,但是同义.
这些问题可以通过Normalizatin解决,将词条规范化标记.这就允许你不仅能使用精确的匹配搜索,还可以使用相关性查询.
1.2分词器
应对不同的分词计算逻辑,ES中使用了底层的分词器.
- standard analyzer
这是一个标准分词器,它可以应对多种不同的语言文本环境,是es的默认分词器.默认分词器,如果未指定,则使用该分词器。按词切分,支持多语言.小写处理,它删除大多数标点符号、小写术语,并支持删除停止词
[root@localhost ~]# curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"text":"王者荣耀","analyzer":"standard"}'
这个命令是打算使用standard对王者荣耀进行分词计算.它的返回结果是:
{
"tokens": [
{
"token": "王",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "者",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "荣",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "耀",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
- simple analyzer
按照非字母切分,简单分词器在遇到不是字母的字符时将文本分解为term小写处理,所有条款都是小写的。
- Whitespace Analyzer
空白字符作为分隔符,当遇到任何空白字符,空白分词器将文本分成term。
- Stop Analyzer
类似于Simple Analyzer,但相比Simple Analyzer,支持删除停止字.停用词指语气助词等修饰性词语,如the, an, 等
1.3IK分词器
内置的分词器可以处理一下通用场景,对于中文来讲常用的是IK分词器,ES也支持IK分词器的插件,IK分词器是基于词典的分词器,这让我们可以自行扩展分词的词语.
- 安装下载IK分词器插件
首先我们可以下载IK插件,这个版本是和ES严格对应的.
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v710.2/elasticsearch-analysis-ik-7.10.2.zip
上传到服务器中,然后我们解压它到ES的plugins目录中即可.
注意: 多个ES节点的集群中,所有节点都需要配置IK分词器,否则计算会报错
- 重启ES测试IK分词器
需要将ES重新启动以加载IK分词器插件.
[root@localhost ~]# curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'{"text":"王者荣耀","analyzer":"ik_max_word"}'
这里可以选择2个不同名称的分词器,一个是ik_smart 一个是ik_max_word
前者是粗粒度分词,后者是细粒度分词计算.测试返回结果如下.
{
"tokens" : [
{
"token" : "王者",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "荣耀",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
可以看到相对es内置的分词器,IK可以对中文做比较基本的词语分词计算,但是这不能是永远不变的.
- IK词典的配置
在我们解压的ik分词器的文件夹中**/plugins/ik/config有一个xml配置文件可以指定词典使用.
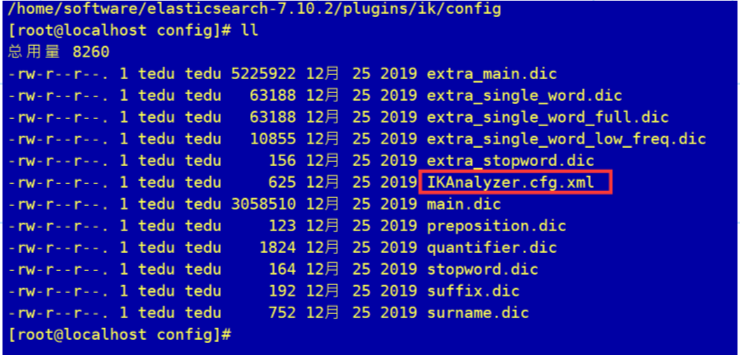
这可配置文件可以指定本地词典和远程词典

无论是远程还是本地,都可以有2种词典,一种是扩展,一种是扩展停用词典.扩展词典就是我们根据词典的配置填写准备我们想要让ik切分出来的词语,而停用词典就是停止计算一些无意义或少意义的词语,例如"这个"“哪些”“还是”"一个"等等类似于英文中的 a the an this that等
- 注意:使用本次词典,配置文件需要指定相对路径,一般我们都将词典和配置xml放到同一个目录中.
- 本地词典扩展词典和停用词典
我们可以配置2个词典,一个叫做ext.dic一个叫做stop.dic.并且在IKAnalyzer.cfg.xml中配置2个词典
ext.dic
王者荣耀
stop.dic
王者
IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stop.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!--<entry key="remote_ext_dict">http://192.168.42.130:8080/hot.dic</entry>-->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
这样依赖,ik分词器在计算"王者荣耀"分词时,会根据加载的配置文件完成计算.
{
"tokens" : [
{
"token" : "王者荣耀",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "荣耀",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
}
]
}
- 远程词典热词更新
我们可以在任意一个远程的web服务器资源中配置这些词典,从而使IK分词器可以通过网络访问这些频繁变动的资源.
这里我们选择使用tomcat服务器 设置一个远程词典测试 http://192.168.42.130:8080/hot.dic 作为远程热词资源.并且在其中我们添加一个测试词语 “王者荣”
然后我们在每一个IK分词器的配置xml中指定远程扩展词典
IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stop.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.42.130:8080/hot.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es测试访问ik分词器.得到“王者荣”的词语
{
"tokens" : [
{
"token" : "王者荣耀",
"start_offset" : 0,
"end_off 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









