






PS:主要补充在http服务器发送请求后,匹配的规则是按照正则表达式来的。
众所周知,
HTTP的请求报文格式如下所示:
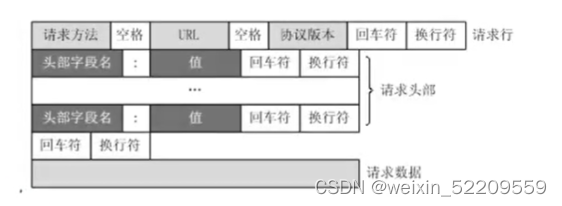
在发送http请求时,用正则表达式去匹配请求行和请求头部。
下面进入正题,关于正则表达式符号:
^ 匹配字符串的开始或行开头(在集合字符里[^a]表示非(不匹配)的意思
$ 匹配字符串的结束或行结尾
* 匹配前面的表达式0个或多个。
· 匹配除换行符 \n 之外的任何单字符
() 为了提取匹配字符串的,表达式中有几个()就有几个相应的匹配字符串。
[] 定义匹配的单个字符的范围,比如[a-zA-Z0-9]表示相应位置的字符要匹配英文字符或数字。
{} 用来匹配的长度,格式为{n}、{n,m}、{n,}。(ab){0,12}? 表示匹配0到12次但尽可能少。
? 重复0次或1次,等价于:{0,1}
请求行:
//正则表达式匹配:对应http报文的 GET / HTTP/1.1
regex patten("^([^ ]*) ([^ ]*) HTTP/([^ ]*)$");//匹配规则
HTTP请求方法有很多,比如GET、POST、HEAD、TRACE、OPTIONS、CONNECT、DELETE等,其中常见的是GET和POST,这二者的区别不再赘述。
根据请求报文的格式,依次是 请求方法 空格 URL 空格,从[^ ]开始表示开始匹配字符串,而([^ ])对应匹配多个字符,代表了请求方法,同样的第二个([^ ])匹配了URL,接着HTTP/后面的协议号也对应上了([^ ]*),最后$表示字符串匹配结束。
请求头:
//正则表达式:对应键对值kv
regex patten("^([^:]*): ?(.*)$");
同样的,^表示开始匹配字符串,([^:]*) 表示匹配key值,?表示至少一个value,(.*)表示任意字符出现零次或多次,匹配可能出现的多个值value,最后$结束。















 3061
3061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









