







MYSQL索引详解
索引概述
索引就是类似书的目录,就是为了查的快,索引即数据,索引本身就是数据
优缺点
优点:
- 当然是快,检索快
缺点
- 索引是数据结构,是会占用内存的
- 更新的时候,需要改变索引的结构
对于第二点,你可能会有点疑惑,我们打个比喻,一本书目录是完好的,你突然要加内容进去,你是不是得修改目录的位置,添加一行新的内容目录进去,更新的时候也是同理
InnoDB索引的推演
索引之前的查询
此时没有索引
在一个页面中查询
在一个页面中的查询是按照主键自增id来查询的,此时我们为了避免全表查询,可以使用二分法来查,定位到一个比较精确的范围,在进行查询,在底层的数据结构就是找到那个页的开头然后开始循环链表查
在多个页进行查询
先定位到记录所在页,然后再在一个页中进行查询
索引的数据结构的推演
我们先来看索引的数据结构
先创建一个表
mysql> CREATE TABLE index_demo(
-> c1 INT,
-> c2 INT,
-> c3 CHAR(1),
-> PRIMARY KEY(c1)
-> ) ROW_FORMAT = Compact;
这个表就三个列 c1 c2 c3
c1是主键
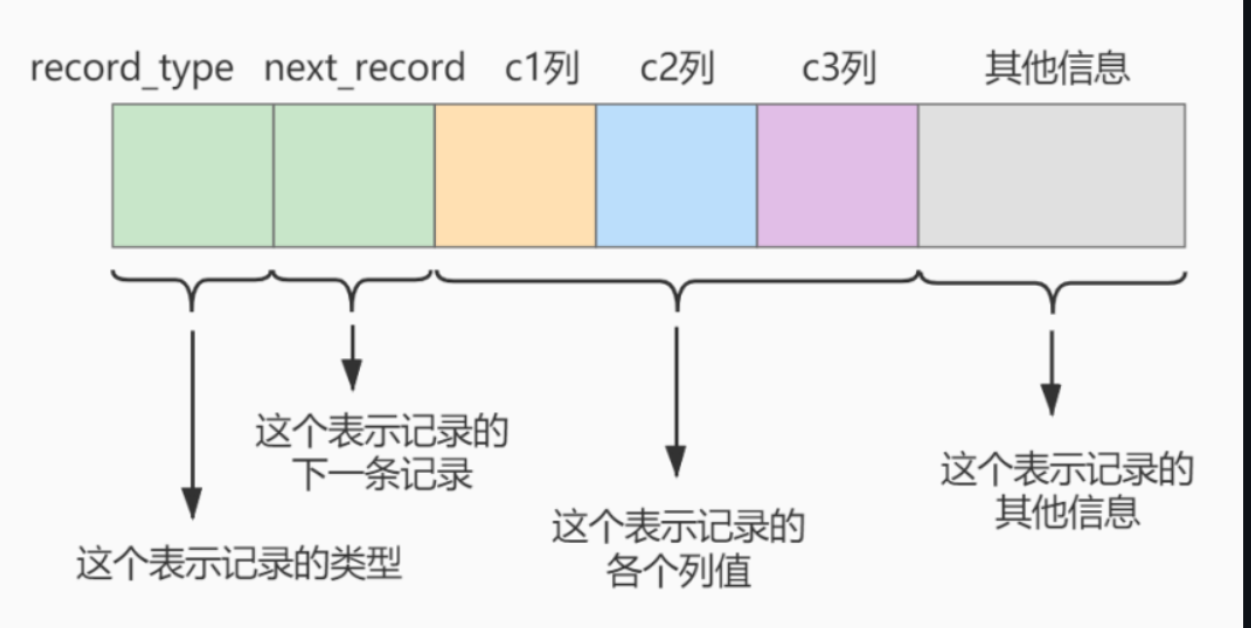
我们来看索引的结构
record type: 记录头的属性,表示这个记录是什么类型的,比如 0 就是普通的记录,2表示最小的记录,3表示最大的记录,1表示目录项的作用
这里的record type,你可以先不搞懂什么意思,待会我们看图的时候就能搞懂为啥要这个东西.
next_record: 下一个记录的地址,因为底层是链表,所以需要下一个地址
然后是三个列
最后是其他的信息
我们来看举例
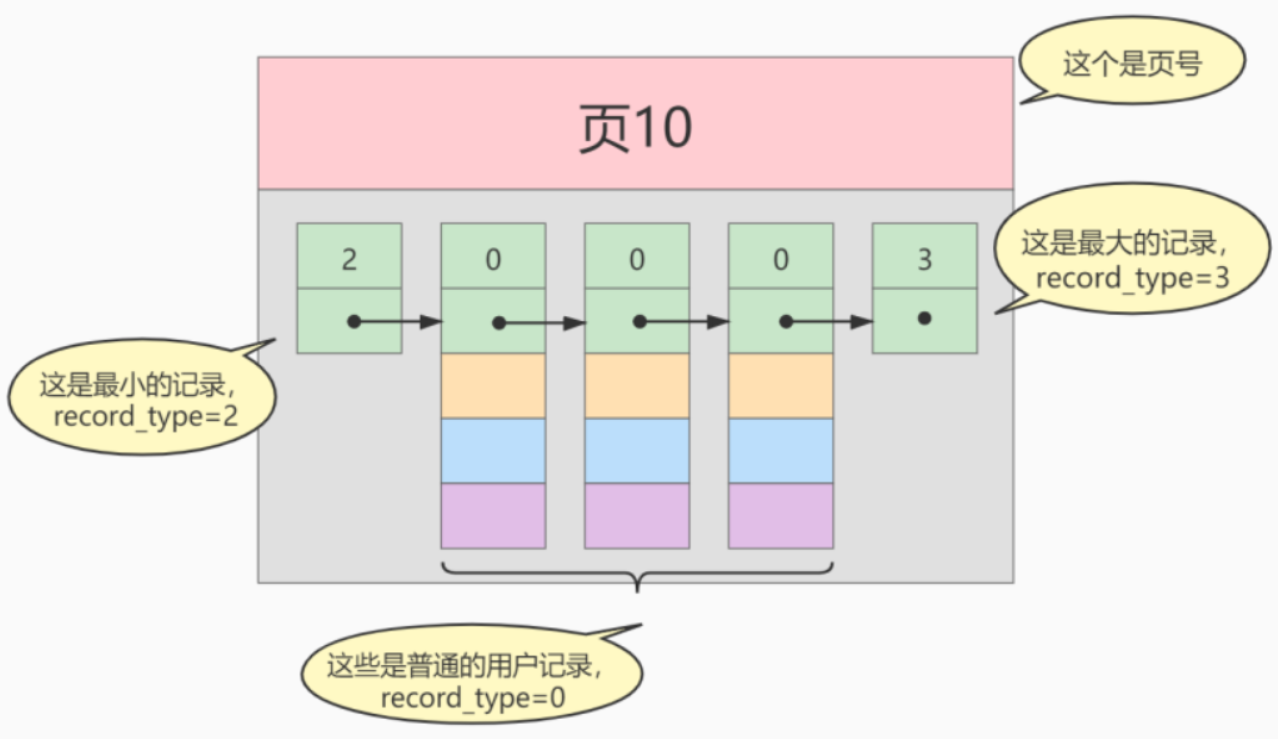
第一个record_type是2,意味着它是最小的记录,同样的意思是,它是一个虚拟的头节点,这样更为洽淡
最后一个record_type是3,意味着它是最大的记录,同样的意思是,它是一个虚拟的尾节点
中间的记录record_type是0,代表着它是普通的记录
对于record_type是1的,会在后边出现
一些简单的索引设计方案
我们假设页10已经有了以下的记录

这些记录是顺序的
此时我们要插入,4,4,‘a’
我们假设一个页中,我们只放3条记录
此时要插入的化,肯定是新开一个页,假设叫作页28

如果我们把新的记录放在这,就不合适了,因为没有保证整体的有序性
1 3 5 4这样的顺序是错误的,所以此时我们得交换 5 和 4 的记录
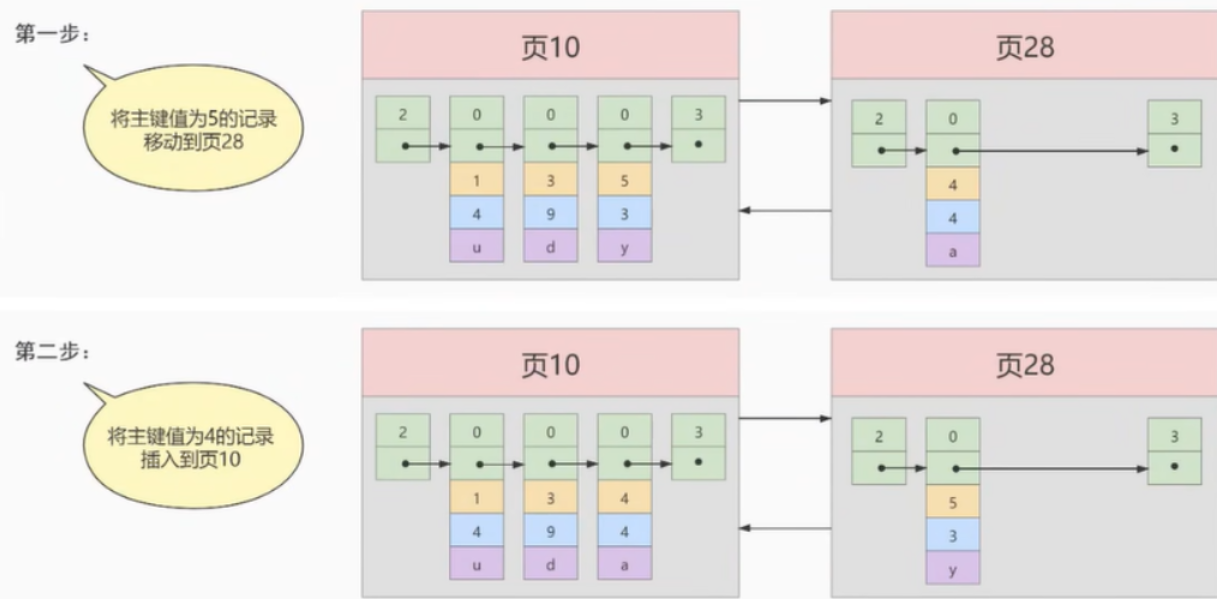
下一个页中的数据的主键必须大于上一个页中的主键,这个过程叫做页分裂
整体做好了状态的维护,然后我们要做目录项的分配
你可能会好奇,为什么要有目录项,当然是为了快
你想想,一本书,有很多章,你把所有章的目录都写了出来,这样不好查阅,你把相同内容的章节合成一个大章节,然后给大章节一个目录地址,这样我们检索的时候,就可以快速定位到我们需要的目录的开头,然后再去做检索.
总的来说,就是再加一层,给记录加上目录
而这个目录项,它的record_type就是1,每一个目录包括两个部分
- 页的最小主键值
- 页号
看图就懂了
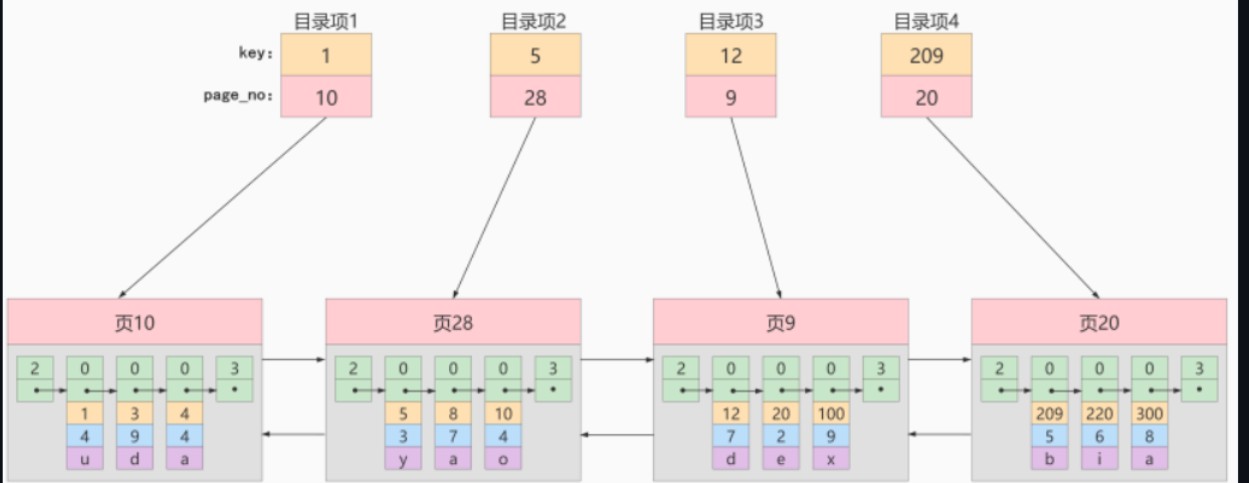
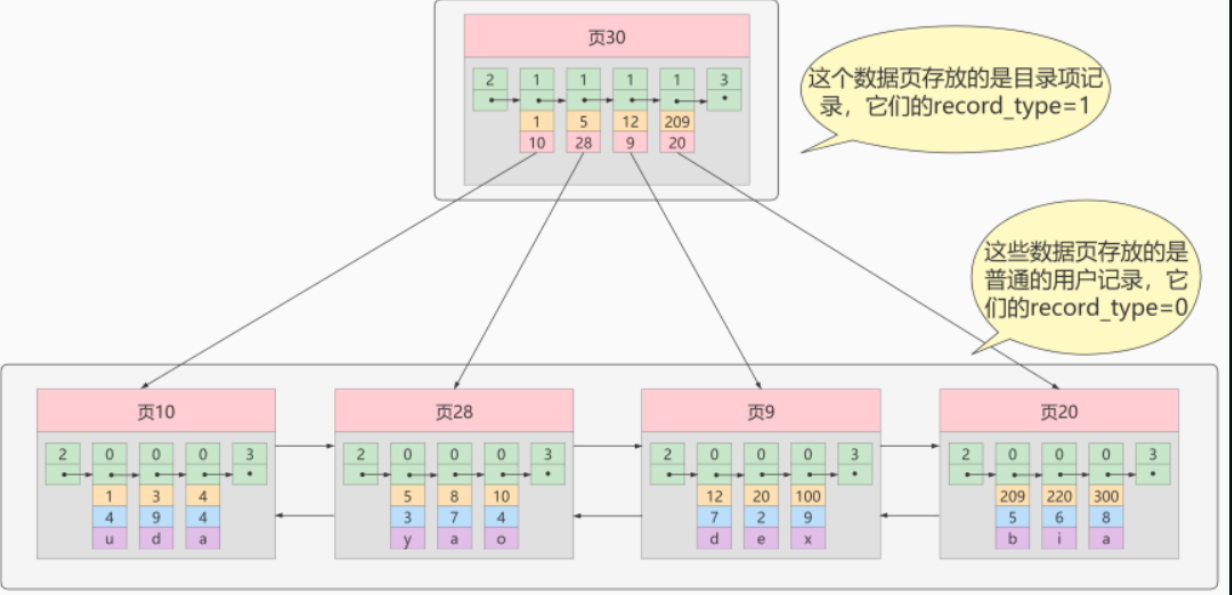
假设我们要查询20,我们就先去查询目录
1 10 1 < 20 有可能在页10上
5 28 5 < 20 那么有可能在页28上,但是不可能在页10上了
12 9 12 < 20 那么可能在页9上,但是不可能在页28上
209 20 209 > 20 那么不可能在页20上,所以,只可能在页9上
所有,目录项的出现,就是为了,我们快速的找到数据所在页的地方,然后再去页中进行查找
我们总体来看,主要的设计就是它的数据结构,是页结构,一个页里边是一个链表,有着头,有着尾,然后是实际的记录,并且是按照主键顺序的记录
InnoDB中的索引
先有上边的粗略的了解,我们来推出一个整体的索引的结构
我们先打个预防针,索引的结构会是树结构,并且是B+Tree。
第一次迭代
最下边这层是实际的数据项,也就是不同的页
倒数第二层是目录项
他们的区别,我上边也说过了,目录项,就是大体的范围的地址,也是为了加快查询,为了快速定位到你想要的范围
迭代两次,多个目录项记录的页
目录项多了,就会有多个目录项的页
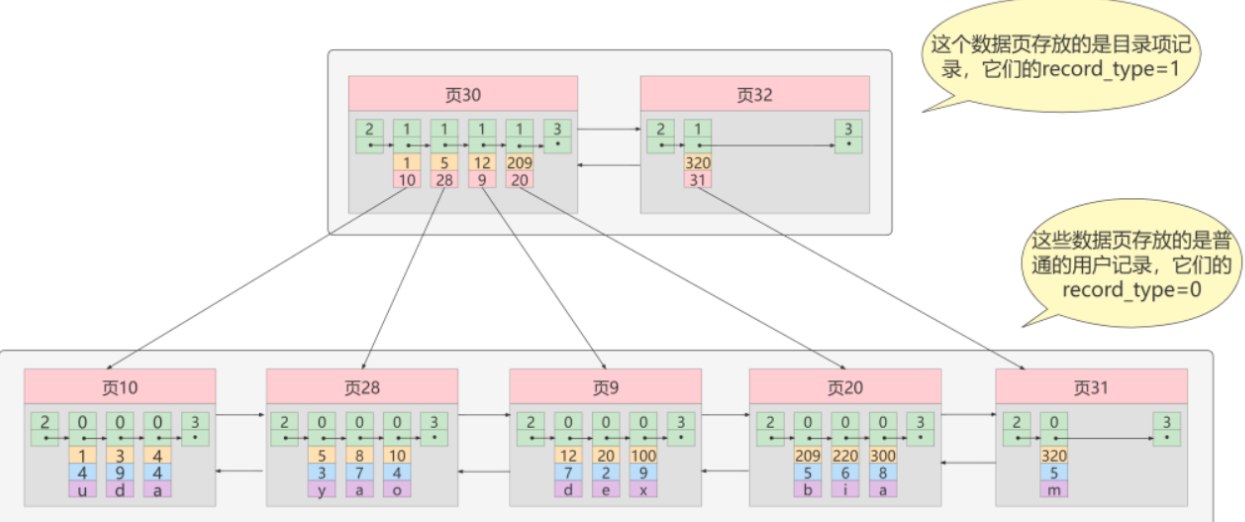
迭代三次,多个目录记录的页的目录
给目录加目录的意思,多加了一层
也就是大目录嵌套着小目录
最后抽象称为的结构就是这样的
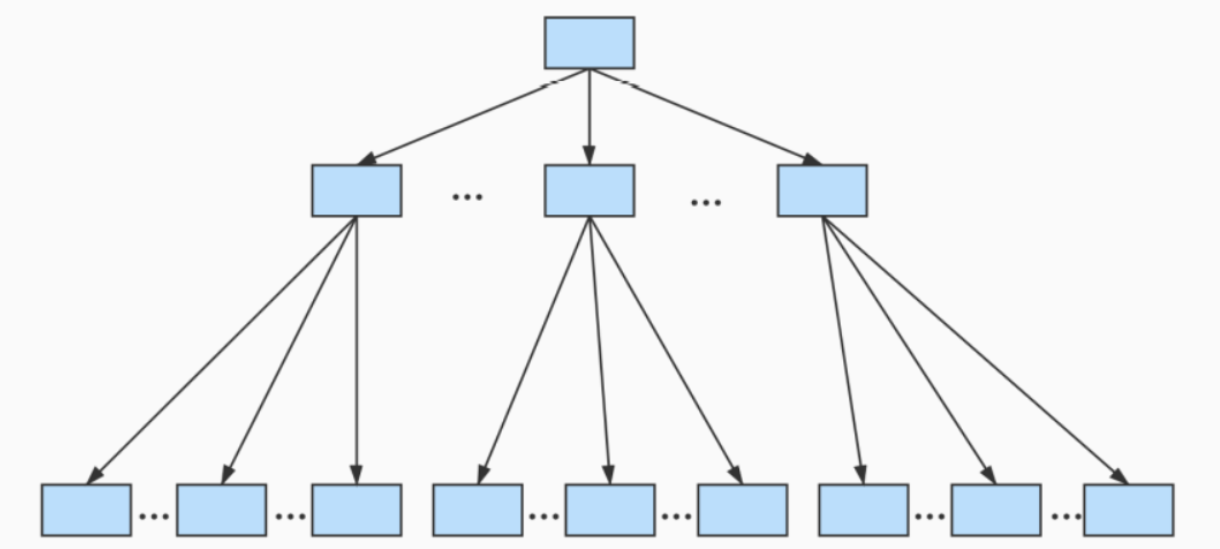
B+Tree
这个就是B+树
一个B+树的节点可以分为很多层,规定最下边那层是第0层
一般来说,B+树的高度是3层
为什么说B+树的高度一般是3层呢?
这里我们论证一下
我们假设一个叶子节点可以存100条记录,一个目录项可以存1000条记录
我们假设一个叶子节点可以存放100条用户记录,一个目录项可以存放1000条目录项记录
- 只有一层,也就是只有一个用户记录页,
最多存放100条记录 - 两层,
最多存放1000 * 100 = 10,000条记录 - 三层,
最多存放1000 * 1000 * 100 = 1,0000,0000条记录 - 四层,最多存放1000 * 1000 * 1000 * 100 = 1000,0000,0000条记录!
总结
所以总结来看,一般来说,io操作最多4次,4层的B+树,那个数据是海量的了.
InnoDB中B+树索引的注意事项
跟位置万年不动
为了演示方便,上边的迭代过程,我们是从叶子节点从下往上形成的B+Tree,但是实际情况是从上往下形成的B+树
实际的B+树的形成过程
- 创建表的时候,默认会创建一个聚簇索引,没数据,对应着的是一个空的根节点的页面
- 随后插入数据,会先存储到根节点
- 当根节点的位置不够的时候,此时就会将根节点的数据复制到一个
页a上,对这个新的页a进行分裂,然后根节点,进化成一个目录项页
一个页最少存2条数据
只存一条和直接查没区别
索引类型总结
按照物理存储类型分
聚簇索引:
索引和数据在一起的索引,一般就是指主键 + 所有的列
Innodb中的主键就是聚簇索引,这也是为什么说,索引即数据,因为数据和索引都绑在一起了
非聚簇索引: 索引和数据分开存储的索引,一般就是指主键的地址 + 部分的列 索引加到哪去了呢,就是给这些部分列加的索引
如果我们需要完整的数据,就会涉及到回表的操作,因为本身不是完整的数据,我们就要通过主键的地址,找到聚簇索引,然后读取完整的数据
非聚簇索引也叫做二级索引
按照应用维度来分
主键索引: 也就是给主键加的索引,不能加null
普通索引: 就是加速而已
唯一索引: 列值唯一,可以有null
覆盖索引: 一个索引包含所有需要查询的字段的值
联合索引: 多个列形成的索引
全文索引: 对全文内容进行索引,不常用
MySQL8.xx新的索引
隐藏索引:
也叫做不可见索引,对查询优化器不可见,相当于索引失效,但是可以重新设置索引
隐藏索引的意义,一句话,就是为了备份,我们去删除一个索引,如果它是隐藏索引,那么这里就类似逻辑删除.
但是需要注意的是,隐藏索引就算被隐藏了,也是要维护更新的,所以隐藏索引不用的化,应该删除,不然会有损性能
降序索引
从4.0开始,我们就支持desc,降序,但是它的底层实际上是升序索引,也就是不管怎样,都是从小到大开始查,8.0的时候,才有降序索引
MYISAM的索引方案
MyISAM的索引是和数据分开的,也就是都是非聚簇索引
底层的文件是
.MYD 数据文件
.MYI 索引文件
索引原理
MyISAM索引的叶子节点存的是主键值 + 地址
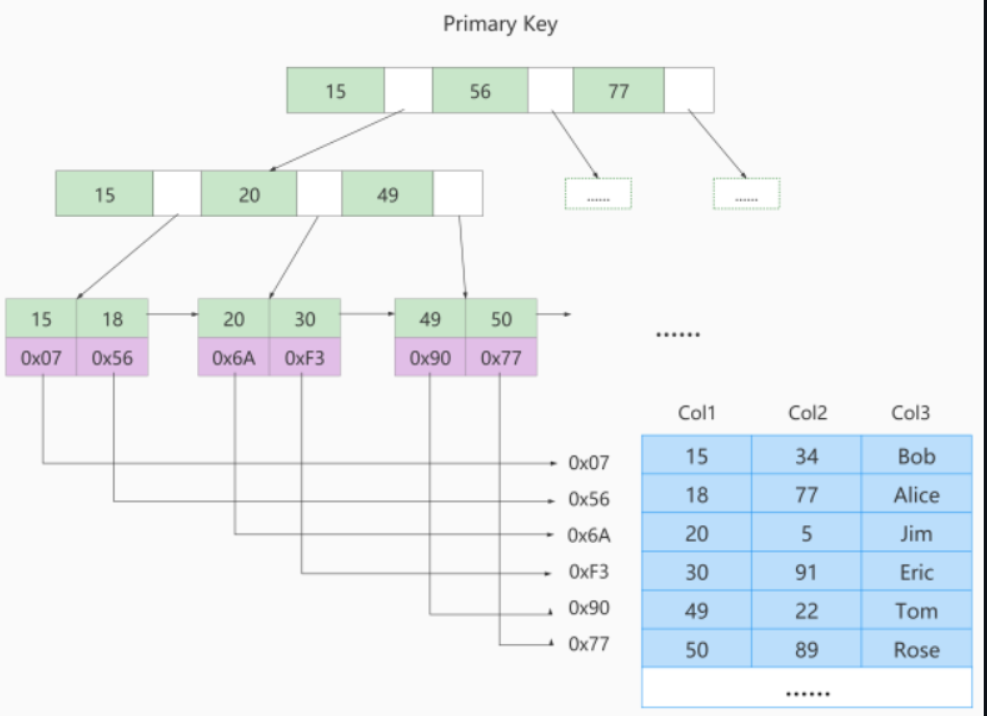
MyISAM和InnoDB对比
MyISAM的索引都是非聚簇索引,Innodb的索引一定包含一个聚簇索引
- Innodb中,查主键,只有一次聚簇索引,不是主键,有可能会有两次,因为第一个是非聚簇索引,加回表操作,回表操作就是去查聚簇索引,MyISAM不管什么都只用查一次
- Innodb数据 索引在一起,MyISAM分开的
- MyISAM回表会快,因为只用回表一次,而Innodb会慢一点
- Innodb必须有主键,如果没有指定,会自动指定一个非空且唯一的列作为主键,如果这样的列都没有,会自动创建一个隐含的字段,这个字段的长度尾6个字节,类型为长整型
覆盖索引和联合索引
覆盖索引
覆盖索引,覆盖索引就是二级索引上的一个现象
我们要知道,对于二级索引来,也就是非聚簇索引,它存储的一般是主键 + 部分列
一般来说,我们要查询的列要是不再这些列中的化,我们要去回表操作,也就是去聚簇索引中查完整的列
但是如果我们要查的列,就在二级索引上,那就不用回表操作了,直接就拿到数据了,这样就少了一次回表操作,我们需要知道回表操作是一个随机的过程,所以也是会损耗性能的
联合索引
联合索引的定义很简单,就是几个列一起的索引
比较重要的是一个原则,最左前缀原则
最左前缀原则
我们要从左边 匹配到右边
这个是顺序匹配的,要是左边不匹配,后边也不会匹配
最左前缀原则遇到 < >范围查询会停止匹配
遇到 <= >= between like 不会停止匹配
索引下推
索引下推,针对的就是二级索引,联合索引
举个例子就能懂
联合索引(A,B,C),A索引成功,B,C索引失效,此时就要回表操作,但是因为后边的回表操作代价太大了,此时就先在二级索引上,用上B,C的索引,过滤掉不满足的列,然后再去回表,这样就可以减少回表的成本
索引下推的意思,你要补偿索引失效回表的成本















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











