






今天浏览网站时遇到了slideshow格式的图片集,如下图,我需要爬取每张图片下面对应的文字说明。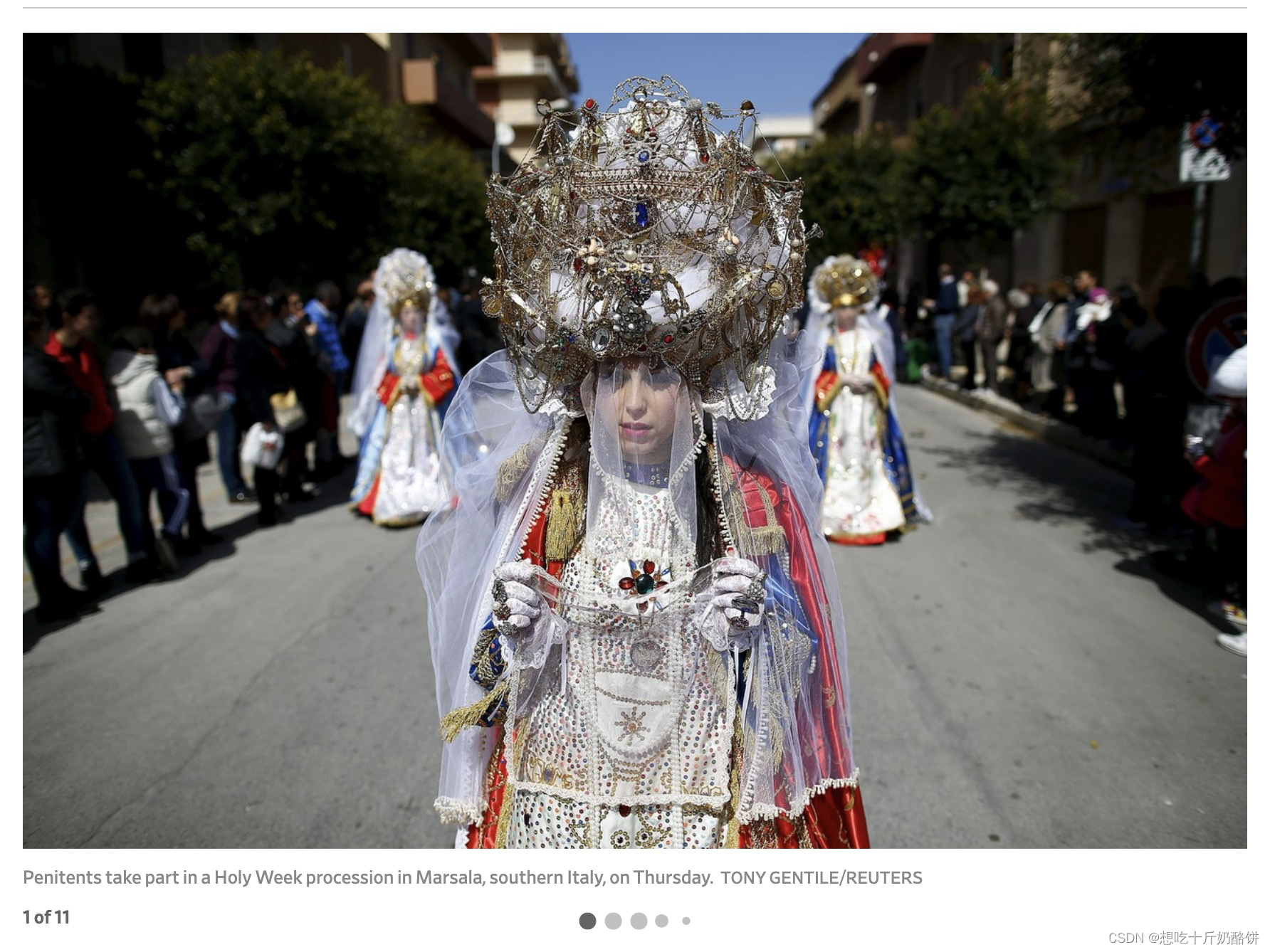
代码如下。
#环境配置+初始化driver
option = webdriver.ChromeOptions()
option.add_argument(r"user-data-dir=/Users/yunjiefei/Library/Application Support/Google/Chrome/Default/tmp2")
driver = webdriver.Chrome(executable_path = '/opt/anaconda3/bin/chromedriver',options=option)
url = 'https://www.wsj.com/articles/photos-of-the-day-april-2-1428006374'
driver.get(url) #用模拟浏览器规避反爬
time.sleep(5)
titlename = driver.find_element(By.XPATH,'//*[@id="main"]/header')
source = driver.page_source #模拟浏览器使用beautifulsoup解析
soup = BeautifulSoup(source, 'html.parser')
idname = soup.find(attrs={'name':'article.id'})['content'] #获取一下idname,可能用到。获取meta数据的方法 attrs={'name':'article.id'})['content']
#titlename = soup.find('div',{'class':'article_header module'})
textlis = []
for image in soup.find_all('img',{'class':'WSJTheme-module--slideshow-img-3g1DH_RVH3q_8Ic61A4cxp'}):
text = image.get('alt','')
textlis.append(text)
article = ' '.join(textlis)
content = titlename.text + '\n' + article















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









