






GPIoT: Tailoring Small Language Models for IoT Program Synthesis and Development
Abstract
大意:
现有的代码大型语言模型(如WizardCoder和CodeLlama)无法较好完成IoT领域的代码生成任务,因为它们主要针对通用编程任务进行训练,IoT相关知识在其训练数据中占比很小。此外,使用云端LLMs(如GPT-4)进行IoT应用开发存在隐私泄露、网络不稳定和高昂的查询成本等问题。
而本文提出的GPIoT由三个本地部署的小型语言模型组成,分别是任务分解SLM(TDSLM)、需求转换SLM(RTSLM)和代码生成SLM(CGSLM)。TDSLM将IoT应用分解为多个子任务,RTSLM将子任务描述转换为结构化的规范,CGSLM根据规范生成代码和文档。(这个论文提出的方法有三个slm组成)
1 INTRODUCTION
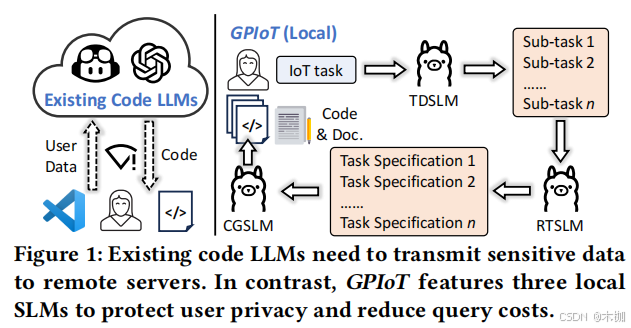
当前出现了许多结合工具的LLM,如图1所示。
通用大模型在训练过程中,因为使用的数据集中IOT占比太少,它会赋予iot相关术语(terminologies)更低的比重导致输出的结果不适用于iot,虽然现在有许多llm+rag的方法出现,但是有挑战:
1.模型本身的能力问题;
2.对RAG的质量要求;
3.hallucinations and unreality of LLMs,Prompt必须保证格式!
GPIOT的优势:
1)本地部署;
2)iot数据集与iot相关性高
3)iot数据集自带格式,避免问题3
GPIOT使用3个SLM(small language Model)来解决这个问题。TDSLM for Task Decomposition, RTSLM for Requirement Transformation, and CGSLM for Code Generation.
这三个模型里只有TDSLM和RTSLM需要微调,而CGSLM只要进行语言加工就好了。
GPIOT的挑战:
1)缺数据集。自行搭建两个数据集。
2)SLMs之间的领域不能对齐。TDSLM分解的任务可能超过了CGSLM的处理范围。we propose a parameter-efficient co-tuning (PECT) paradigm featuring a multi-path Low-Rank Adaptation (LoRA) pipeline.
论文中的PECT使用的是一个共同的base model但使用了不同的adapter,以此来降低不协同并利用共享参数。
3)格式问题。使用COT来提示格式规范。
测评:
在iotbenchmark来进行测评。
2 background & motivation
为了证明定制Llm模型(tailored IoT-related LLMs)的重要性,实施了几个预实验(preliminary experiments)。
2.1 现有模型局限性
现有的LLM在通用和简单的编程任务上表现出色,但在复杂的IoT应用开发中存在不足。因为它们主要针对通用编程任务进行训练,IoT相关知识在其训练数据中占比很小。这导致通用词比专业词在向量空间中有更高的相似度。
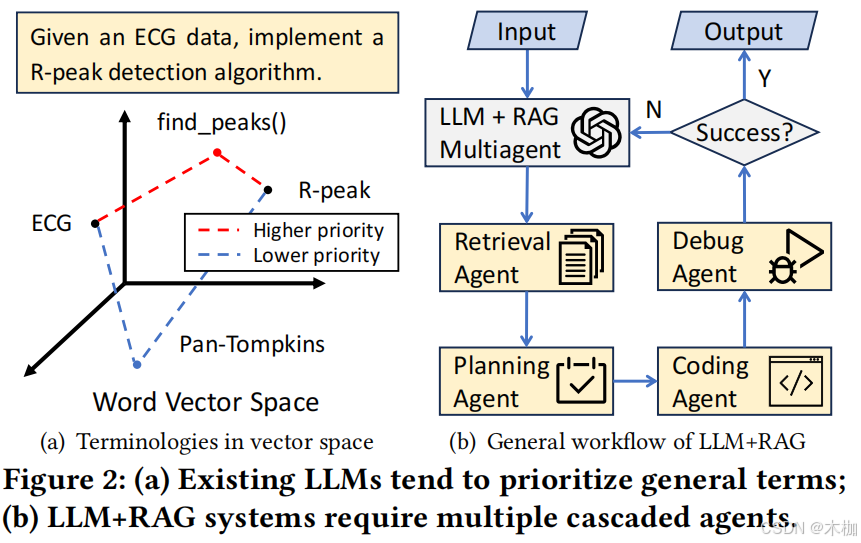
如图2(a) 所示,当提示LLM设计个先点图的r peak detection method,它还是优先设计一个同样的方法,而不是心电图专用的方法,如Pan-Tompkins。
LLMs+RAG
LLMs+RAG的方法通过提供参考和级联的agent设计,来提升正确率,如图2(b)所示。论文使用MapCoder [30]进行测试,发现代码的正确率只有28%。原因:1.需要高精度的rag;2.多级连agents会引入noise and propagates errors;3.LLM在生成内容的过程中不可避免地倾向于生成通用方法。
2.2 预实验
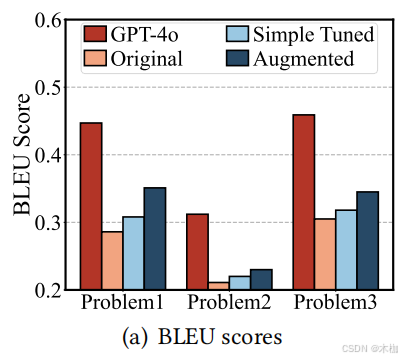
This motivates us to design an IoT-tailored text augmentation method to enhance thequantity, quality, and diversity of the original dataset
GSLM to synthesize corresponding programs for each sub-task. Surprisingly, we find that only 53.4% of the programs can be successfully executed without bugs and only 10.6% of the programs adopt IoT-specialized algorithms for the IoT tasks.
This motivates us to develop a knowledge-sharing strategy between the two SLMs duringtuning so that they can reach a consensus when handling IoT tasks.
This motivates us to develop a method to convert the task descriptions in natural language into well-organized specifications.
3 SYSTEM OVERVIEW
GPIoT系统主要由两个阶段组成:离线调优阶段(Offline Stage)和在线处理阶段(Online Stage)。如图4所示。
offline stage
构建两个专门用于IoT领域的数据集,并微调TDSLM和CGSLM。
为了微调,首先建立一个rag agent,此外从website和paper获取iot data用于构建数据集,然后再使用IoT-oriented augmentation method(§ 4.1)
RAG是在offline stage构建数据集时使用,至于微调两个模型,原文如下:
we fine-tune two SLMs via our PECT paradigm, where certain model parameters are collaboratively tuned through a multiple-path LoRA pipeline with two projection layers
for task decomposition and code generation, respectively
两个模型参数是通过lora加投影层共享协调的。
GPIoT first leverages Task Decomposition SLM (TDSLM) to decompose the IoT application into multiple manageable sub-tasks with detailed descriptions (①~ ② ). Next, through CoT-based prompting techniques, the sub-task descriptions will be gradually transformed into well- structured specifications by Requirement Transformation SLM (RTSLM) (③ ∼ ④ ). Next, for each sub-task, Code Generation SLM (CGSLM) accordingly generates a code snippet with documentation (⑤ ∼ ⑥ ). Users can execute the code sequentially to realize the IoT application based on the instructions from the documentation (⑦ ).
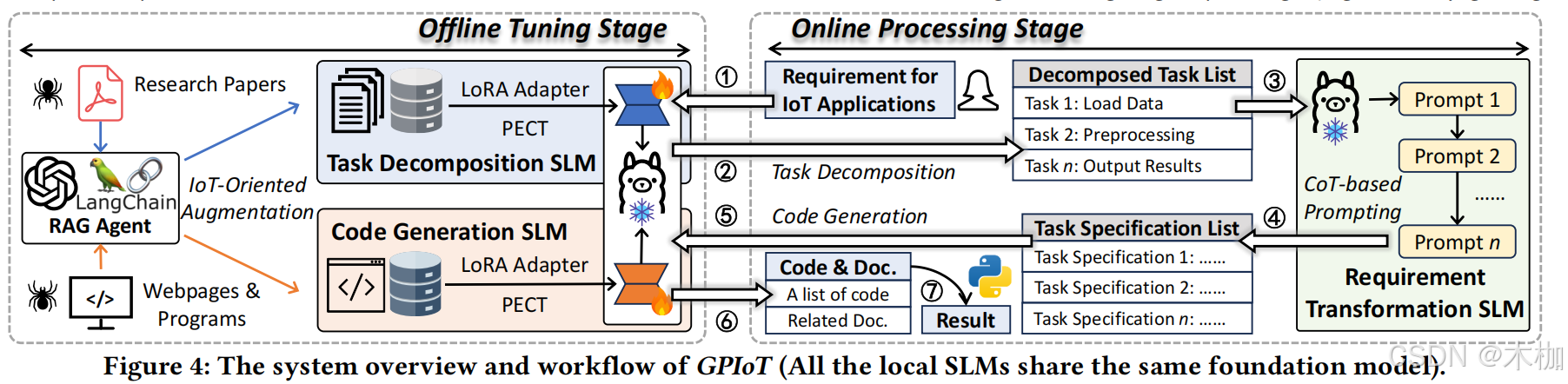
SLM Considerations.(SLM注意事项)
SLM是开源模型可以本地部署,在开销、隐私、独立性上相较于云端模型有优势。
This aligns with the practical constraints of normal users, where local models offer advantages in terms of cost, privacy, and independence from the cloud.
此外,这个微调模型的开销很小很小。
there are three SLMs working simultaneously, they share the same foundation model and differ only in some additional tunable parame ters , which only occupy 1% of all the parameters.
4 SYSTEM DESIGN
4.1 Data Collection & Augmentation
论文首先构建了一个任务分解数据集(TDD)和一个代码生成数据集(CGD)。该数据集包含文本形式的Q&A,这与传统的IoT数据集根本不同,后者通常包含传感器数据和标签对。
4.1.1 Task Decomposition Dataset.
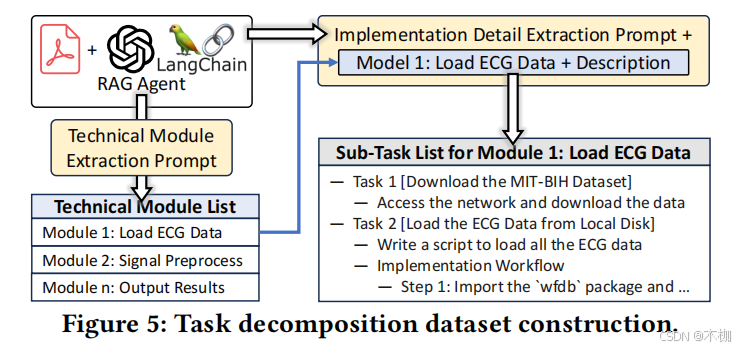

具体构建过程在原文中如下:
we first build a RAG agent by combining the downloaded papers with an LLM (GPT-4o). Based on the provided context documents, we then prompt (Fig. 6(a)) the agent to split the proposed system in the paper into multiple technical modules with detailed descriptions. Next, for each technical module, we prompt (Fig. 6(b)) the agent to further decompose it into several sub-tasks with detailed implementation steps.
如此,我们可以得到每个模块的问题和它对应的sub-task
作为问题对
,如下所示:
![]()
where is the total number of technical modules from all the papers.

图8(a)展示了数据集的一个样本,其中每个子任务由一个空行分隔,以便于解析和进一步处理。

为了达到这个目的我们使用了个search agent去提示gpt-4o产生这样的decomposed任务。并且人工过滤不正确的结果和选择格式。
4.1.2 Code Generation Dataset.

一个网页典型包括两个部分:1) API reference (包括一系列modules的指引信息,我们将这些信息记为)2)Example gallery (使用示例,我们将每个示例记作
)
结合和
,我们得到了raw dataset
。
![]()
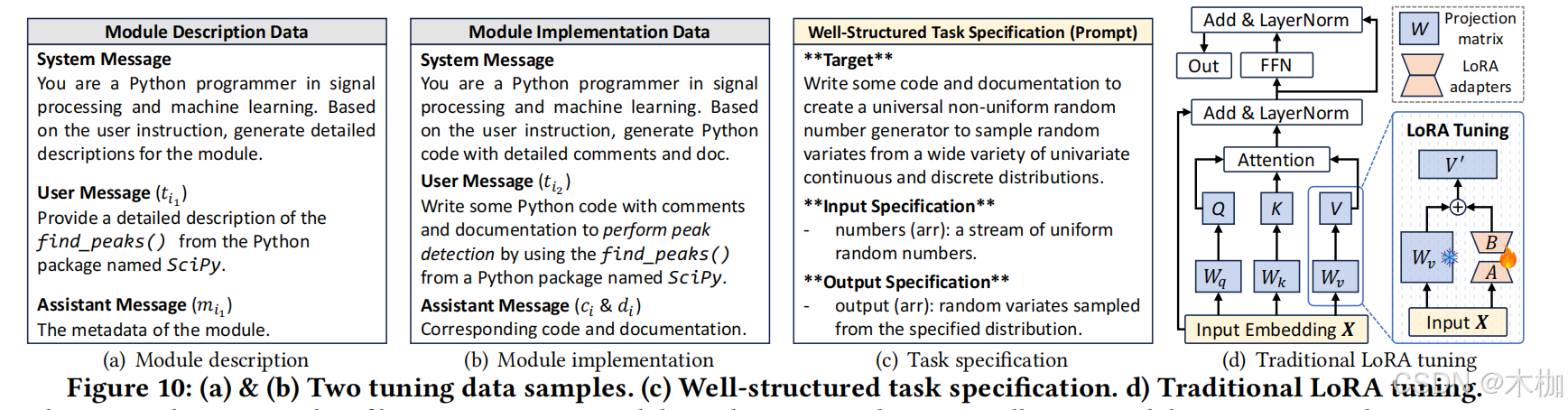
图10(a)展示了模块描述的示例,图10(b)展示了模块实现的示例,图10(c)展示了任务规范的示例。
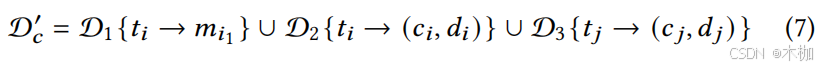
4.1.3 IoTBench.
4.2 Parameter-Efficient Co-Tuning (PECT)
在获得了two augmented datasets (D𝑡 ′ and D𝑐 ′ ),下一步是微调。
4.2.1 LoRA Tuning.
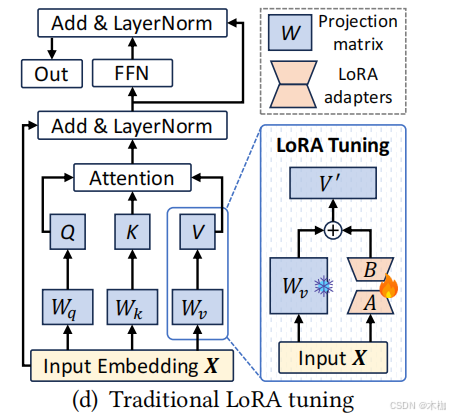
图10(d)所示是传统lora微调过程。
each Transformer block in an LLM contains two main components: a self-attention mechanism and a feed-forward network (FFN), both of which are followed by residual connections and layer normalization.
The self-attention features three tunable weight matrices ( 𝑊 𝑞 , 𝑊 𝑘 , and 𝑊 𝑣 ) to capture contextual relationships between input embeddings, while the FFN processes the outputs from the attention mechanism to refine the feature representations.
LoRA reduces the number of tunable parameters [15 , 18 ], where two low-rank matrices 𝑨 and 𝑩 ( i .e., LoRA adapters) are inserted alongside the weight matrix.(低秩矩阵A和B被插入到权重矩阵中)
Given an input 𝑿, the tuning process can be expressed as:
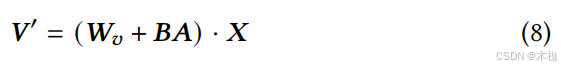
只要更新AB就够了,降低开销。(为什么这个公式里只出现了Wv)
如下是rola的原理图:
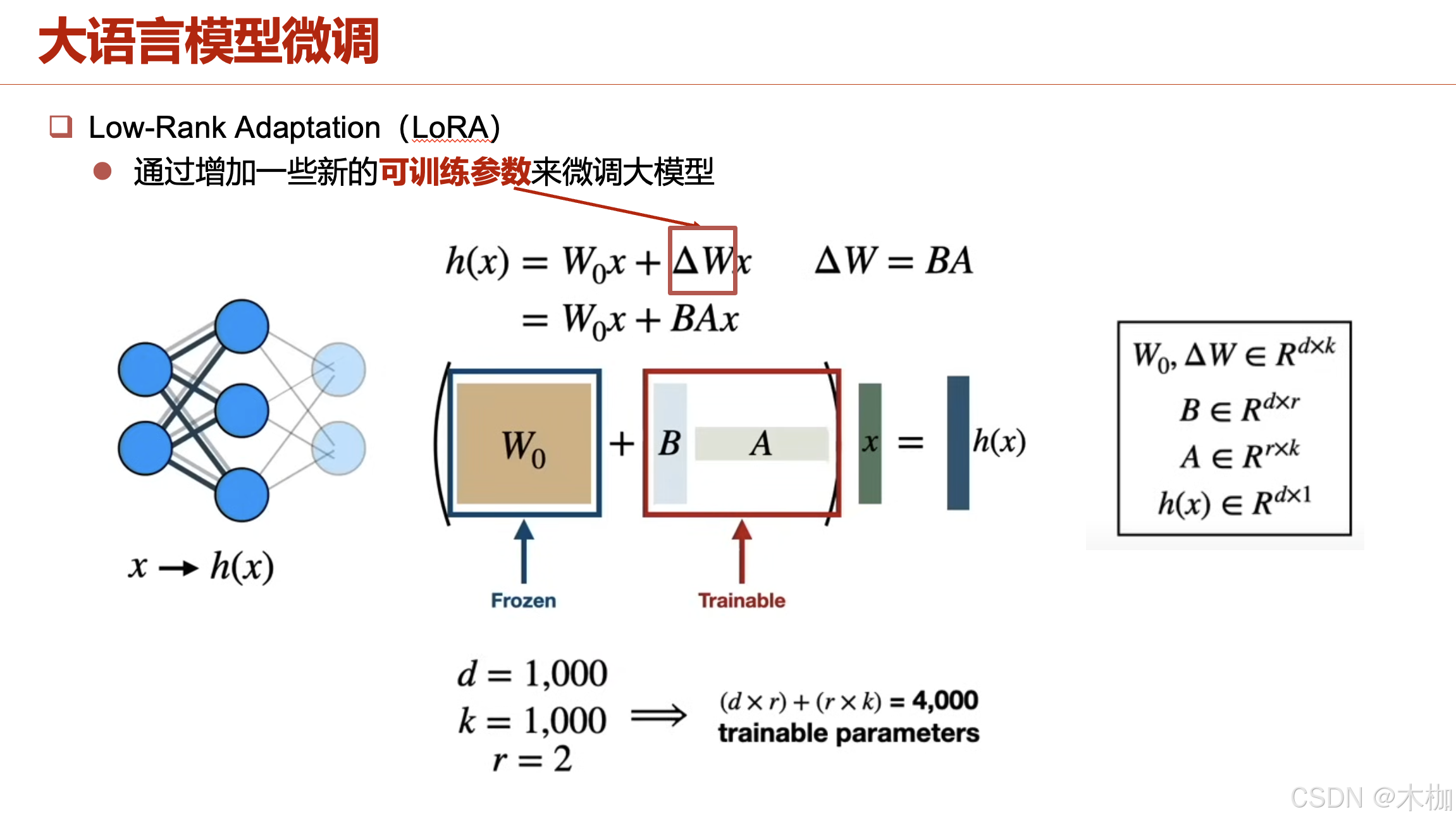
更新的矩阵A和B它们的参数要少,这主要由参数r决定的。
论文的公式没有写全,它其实是用V'表示了Wv的调优,而对于K'和Q'都是一样的。
但由于§ 2.2提到的不对齐问题,在不同数据集上训练的tdslm和cgslm没法很好地协调工作。故提出了parameter-efficient co-tuning (PECT) paradigm。
Un like conventional LoRA tuning that tunes adapters separately, PECT enables collaborative fine-tuning of several SLMs with a shared base model but with different LoRA adapters.
4.2.2 Multi-Path LoRA Pipeline.
we create three pipelines of LoRA adapters in each Transformer block. Two pipelines (the orange one and the green one) are independently tuned by TDSLM and CGSLM with respect to TDD and CGD . The other pipeline (the gray one) is co-tuned on both TDD and CGD.
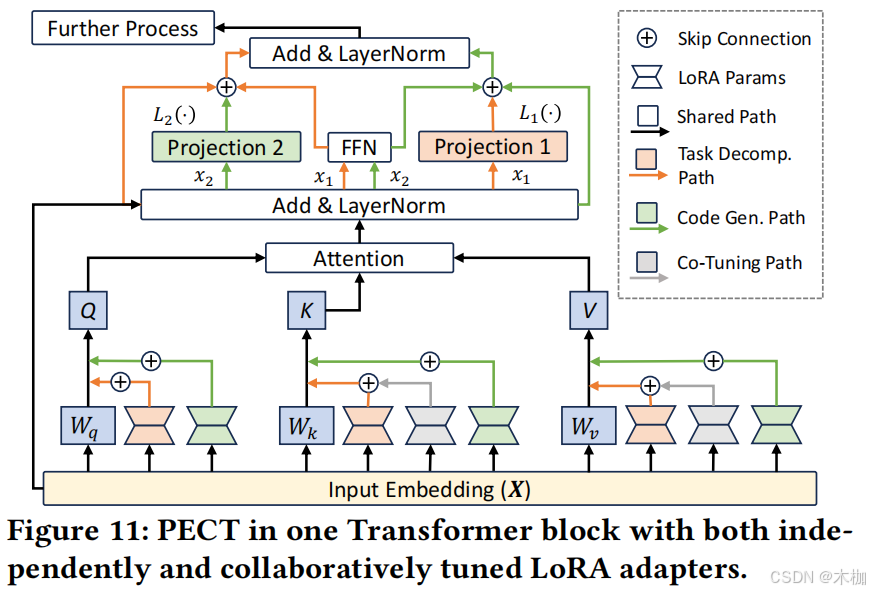
In Fig. 11, we designate the orange line as the task decomposition path (TDP), through which only data from TDD will pass. The green line is the code generation path (CGP), through which only data from CGD will pass. The grey line represents the co-tuning path, through which all data will pass.
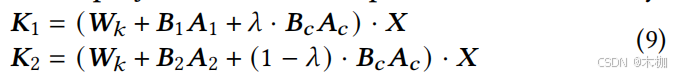
4.2.3 Projection Layers.
作者在transformer block中将two projection与FFN并行。
As such(因此), they can serve as extra FFNs that apply non-linear transformations to theattention representations. (是指self attention层的表示形式吗?)
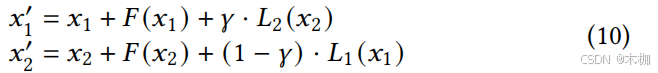
4.3 Requirement Transformation
使用RTSLM进行转换,将task description 转化为well-structured data,考虑到SLM的能力受限,使用RAG辅助。
RAG Construction.
we first transform all the downloaded papers into a text embedding database. Then, armed with such an IoT knowledge database, we build a RAG agent based on RTSLM to retrieve relevant context for reference.
CoT Prompting

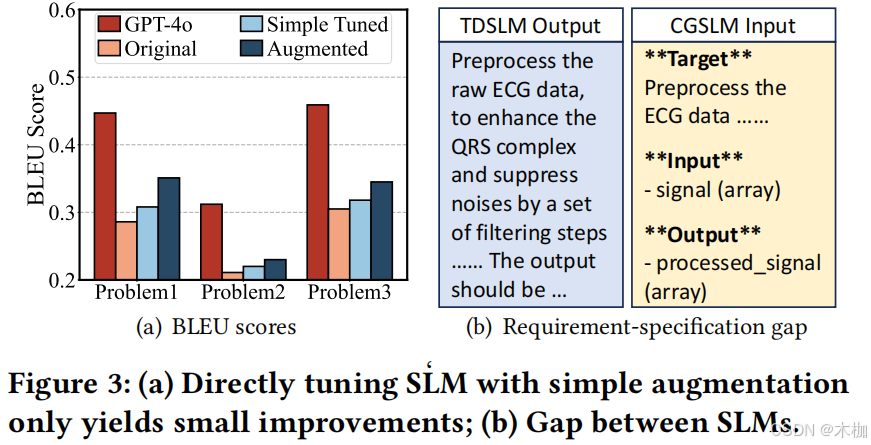
如图10(c)所示,a well-structured task specification for code generation, consisting of three parts: task target, input and output specifications of the expected code.
对每个 decomposed task 𝑡𝑖 generated by TDSLM。
we first prompt (Fig. 12(a)) the agent to summarize a target for the task. Next, we further instruct (Fig. 12(b)) the agent to generate a list of parameter descriptions for the input and output of the expected code.
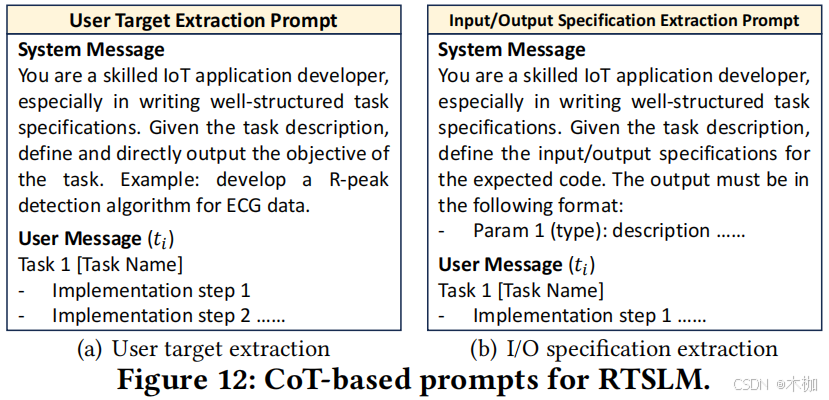
每个单一的参数描述项(parameter description item)都包含参数名称(parameter name)、参数类型(parameter type)和对其含义的简要说明(a brief explanation of its meaning)。例如,“信号(numpy.ndarray):从有噪声的患者那里收集的原始心电图数据。”最后,RTSLM将上述信息重新组织并格式化为一个结构良好的任务规范,CGSLM将进一步处理该规范,以生成相应的代码片段和文档。
5 EXPERIMENT SETUP
5.1 Implementation
System Configurations.
- an RTX 4090 GPU (24 GB)
- use selenium as a web crawler
- an agent based on GPT-4o and LangChain to perform data formatting and augmentation
- an NVIDIA A100 GPU (80 GB) to tune SLM on cloud.
Hyper-parameters.
The tuning process takes around 80 GPU hours. Since TDSLM, RTSLM, and CGSLM share the same foundation model, only about 16 GB of GPU memory is needed for
the whole system
5.2 IoT Applications
6 EVALUATION
6.1 Metrics
6.2 Baselines
6.3 Application Evaluation

With the designed two problem statements (Fig. 13) for the three IoT applications, we input them into GPIoT and the baselines to synthesize 20 different programs for each task.
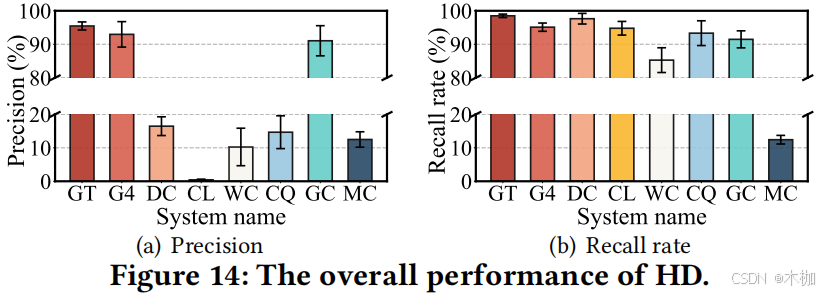
6.3.1 HD.
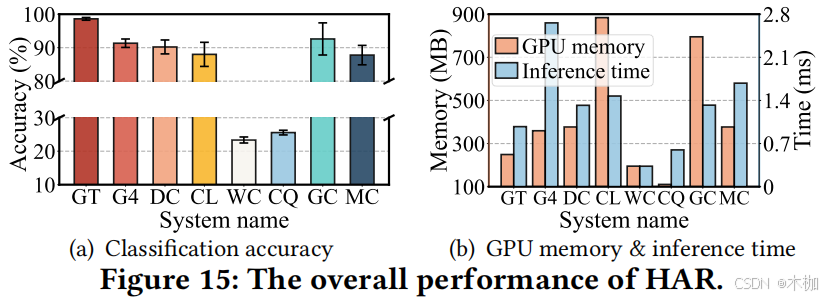
6.3.2 HAR.
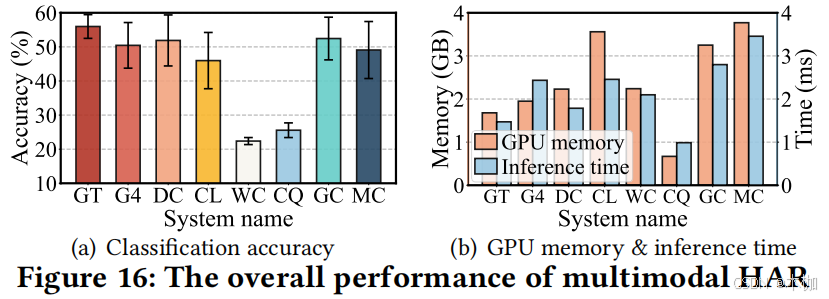
6.3.3 Multimodal HAR.
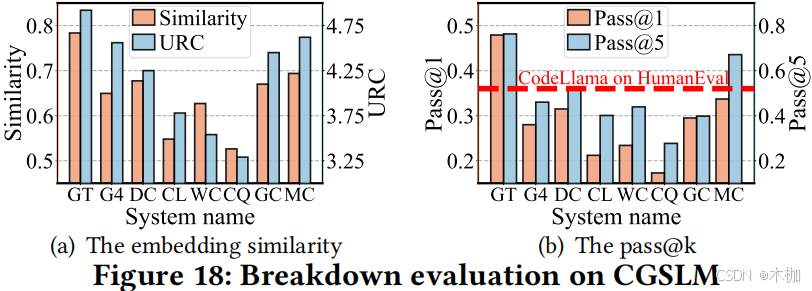
6.4 Breakdown Evaluation
6.4.1 Metrics.
1) BLEU:
2) Format Correctness Rate (FCR):
3) Sub-Task Completeness (STC):
CGSLM.
1) Code embedding similarity:
2) Pass@k:
4) Code quality:
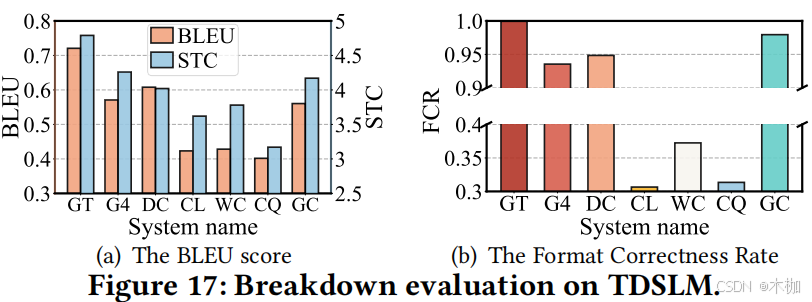
6.4.2 TDSLM.
6.4.3 CGSLM.
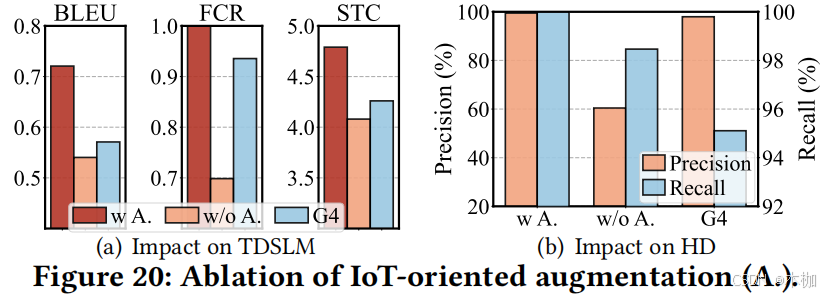
6.5 Ablation Study
6.5.1 IoT-Oriented Data Augmentation.
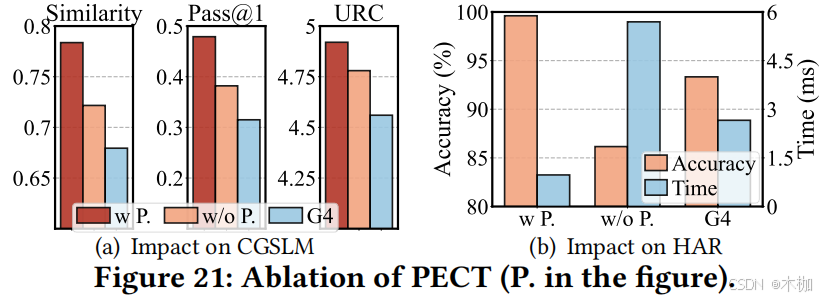
6.5.2 PECT.
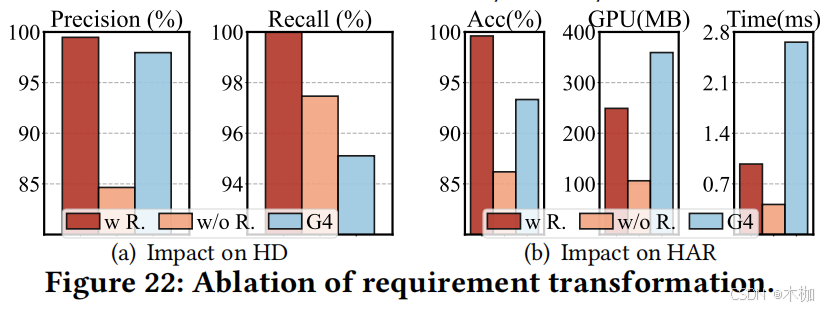
6.5.3 RTSLM.
6.6 User Study
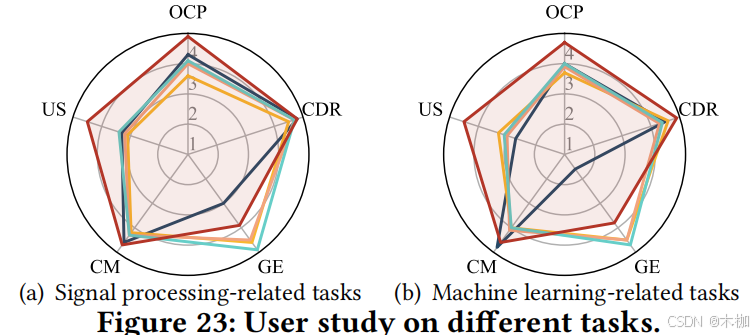
QUESTION
在这篇论文中,作者指出Evol-Instruct微调的TDSLM效果不佳,主要是因为Evol-Instruct专注于增强原始文本数据的语言特性,而未能有效地捕捉物联网(IoT)术语之间复杂的关系。具体来说,Evol-Instruct可能无法充分理解和处理物联网领域特有的术语和概念,导致生成的解决方案与物联网领域的相关性不足。
相比之下,论文提出的Parameter-Efficient Co-Tuning (PECT) 范式通过以下方式克服了这一问题:
-
多路径低秩适应(Multi-Path LoRA Pipeline):PECT采用了一个多路径的低秩适应(LoRA)管道,允许在任务分解和代码生成之间共享知识。通过这种方式,TDSLM和CGSLM可以在一个共享的基础模型上进行协作微调,从而促进知识在两个阶段之间的传递和共享。
-
轻量级投影层(Projection Layers):PECT引入了轻量级的投影层,这些层可以在Transformer块中并行于FFN层,应用非线性变换来增强注意力表示的特征提取能力。这种设计有助于在跨领域任务中增强模型的学习能力,从而更好地理解和处理物联网术语之间的关系。
-
IoT导向的数据增强方法:论文提出了一种针对物联网的数据增强方法,考虑了物联网应用的独特特性,如传感器模态、数据表示和系统资源异质性。这种方法旨在增强数据集的质量和多样性,从而提高SLMs对物联网知识的理解能力。
通过这些技术手段,PECT能够更有效地捕捉和处理物联网领域的复杂关系,从而提高了TDSLM在任务分解方面的表现,并增强了CGSLM在生成相关代码方面的能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









