







主从配置和分库分表
Field 'brand_id' doesn't have a default value
Insert statement does not support sharding table routing to multiple data nodes
QueryWrapper和LambdaQueryWrapper
执行testSave()和findByBrandStatus()测试
Sharding-Sphere组成
Sharding-JDBC 最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为 ShardingSphere,2020年4⽉16⽇正式成为 Apache 软件基⾦会的顶级项⽬。
随着版本的不断更迭 ShardingSphere 的核心功能也变得多元化起来。如图7-1,ShardingSphere生态包含三款开源分布式数据库中间件解决方案,Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar。
Apache ShardingSphere 5.x 版本开始致力于提供可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,而且仍在不断增加中。
| Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar | |
| 数据库 | 任意 | MySQL | MySQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | JAVA | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
Sharding-JDBC
Sharding-JDBC是比较常用的一个组件,它定位的是一个增强版的JDBC驱动,简单来说就是在应用端来完成数据库分库分表相关的路由和分片操作,也是我们本阶段重点去分析的组件。
我们在项目内引入Sharding-JDBC的依赖,我们的业务代码在操作数据库的时候,就会通过Sharding-JDBC的代码连接到数据库。也就是分库分表的一些核心动作,比如SQL解析,路由,执行,结果处理,都是由它来完成的,它工作在客户端。Sharding-JDBC是对原有JDBC驱动的增强,在分库分表的场景中,为应用提供了如图所示的功能。
| 数据分片 | 分布式事务 | 数据库治理 |
| 分库分表 | 标准化事务接口 | 配置动态化 |
| 读写分离 | XA强一致事务 | 编排治理 |
| 分片策略定制化 | 柔性事务 | 数据脱敏 |
| 无中心化分布式主键 | 可视化链路追踪 |
Sharding-Proxy
Sharding-Proxy有点类似于Mycat,它是提供了数据库层面的代理,什么意思呢?简单来说,以前我们的应用是直连数据库,引入了Sharding-Proxy之后,我们的应用是直连Sharding-Proxy,然后Sharding-Proxy通过处理之后再转发到mysql中。
这种方式的好处在于,用户不需要感知到分库分表的存在,相当于正常访问mysql。目前Sharding-Proxy支持Mysql和PostgreSQL两种数据库协议
Sharding-Sidecar(TODO)
看到Sidecar,大家应该就能想到服务网格架构,它主要定位于 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。目前Sharding-Sidecar还处于开发阶段未发布。
Sharding-JDBC表的概念
在Sharding-JDBC中,有一些表的概念,需要给大家普及一下,逻辑表、真实表、分片键、数据节点、动态表、广播表、绑定表。
逻辑表
配置文件中的定义,t_order、t_user等就是逻辑表。 后面的分库db1.t_user或者分表t_user_0等才是真实的表
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..1}

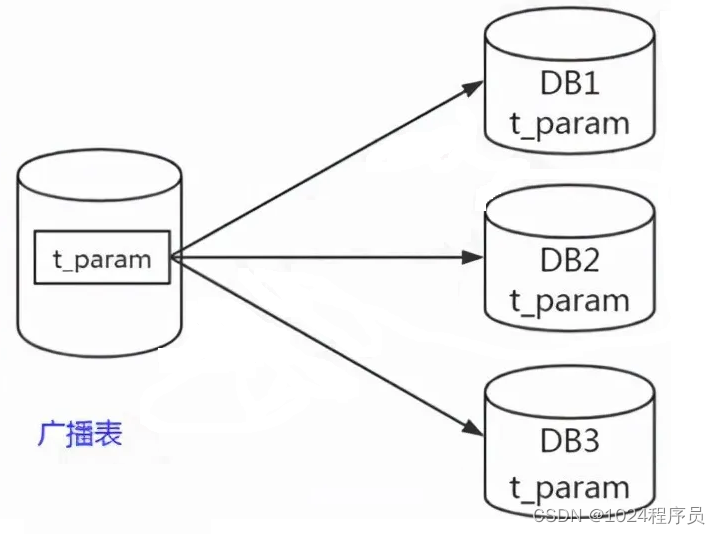
广播表
广播表也叫全局表,也就是它会存在于多个库中冗余,避免跨库查询问题,比如省份、字典等一些基础数据,为了避免分库分表后关联表查询这些基础数据存在跨库问题,所以可以把这些数据同步给每一个数据库节点,这个就叫广播表
配置文件中的定义
# 广播表, 其主节点是ds0
spring.shardingsphere.sharding.broadcast-tables=t_config
spring.shardingsphere.sharding.tables.t_config.actual-data-nodes=ds$->{0}.t_config
绑定表
表的数据是存在逻辑的主外键关系的,比如订单表order_info,存的是汇总的商品数,商品金额;订单明细表order_detail,是每个商品的价格,个数等等。或者叫做从属关系,父表和子表的关系。他们之间会经常有关联查询的操作,如果父表的数据和子表的数据分别存储在不同的数据库,跨库关联查询也比较麻烦。所以我们能不能把父表和数据和从属于父表的数据落到一个节点上呢?比如order_id=1001的数据在node1,它所有的明细数据也放到node1;order_id=1002的数据在node2,它所有的明细数据都放到node2,这样在关联查询的时候依然是在一个数据库

绑定表规则,多组绑定规则使用数组形式配置
spring.shardingsphere.rules.sharding.binding-tables=t_order,t_order_item
如果存在多个绑定表规则,可以用数组的方式声明
# 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[0]= spring.shardingsphere.rules.sharding.binding-tables[1]=
Sharding-JDBC中的分片策略
Sharding-JDBC内置了很多常用的分片策略,这些算法主要针对两个维度
- 数据源分片
- 数据表分片
Sharding-JDBC的分片策略包含了分片键和分片算法;
- 分片键,用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
- 分片算法,就是用来实现分片的计算规则。
Sharding-JDBC提供内置了多种分片算法,包含四种类型分别是
- 自动分片算法
- 标准分片算法
- 复合分片算法
- Hinit分片算法
自动分片算法
自动分片算法,就是根据我们配置的算法表达式完成数据的自动分发功能,在Sharding-JDBC中提供了五种自动分片算法
- 取模分片算法
- 哈希取模分片算法
- 基于分片容量的范围分片算法
- 基于分片边界的范围分片算法
- 自动时间段分片算法
标准分片算法
标准分片策略(StandardShardingStrategy),它只支持对单个分片健(字段)为依据的分库分表,Sharding-JDBC提供了两种算法实现
- 行表达式分片算法
类型:INLINE
使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。 对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的 Java 代码开发,如: t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为 t_user_0 到 t_user_7
配置方法如下。
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2}spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.type=INLINEspring.shardingsphere.rules.sharding.sharding-algorithms.t-order-inline.props.algorithm-expression=t_order_$->{order_id % 2}
- 时间范围分片算法
和前面自动分片算法的自动时间段分片算法类似。
类型:INTERVAL
可配置属性:
| 属性名称 | 数据类型 | 说明 | 默认值 |
| datetime-pattern | String | 分片键的时间戳格式,必须遵循 Java DateTimeFormatter 的格式。例如:yyyy-MM-dd HH:mm:ss | - |
| datetime-lower | String | 时间分片下界值,格式与 datetime-pattern 定义的时间戳格式一致 | - |
| datetime-upper (?) | String | 时间分片上界值,格式与 datetime-pattern 定义的时间戳格式一致 | 当前时间 |
| sharding-suffix-pattern | String | 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM | - |
| datetime-interval-amount (?) | int | 分片键时间间隔,超过该时间间隔将进入下一分片 | 1 |
| datetime-interval-unit (?) | String | 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS |
复合分片算法
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片健操作。
自定义分片算法
除了默认提供了分片算法之外,我们可以根据实际需求自定义分片算法,Sharding-JDBC同样提供了几种类型的扩展实现
- 标准分片算法
- 复合分片算法
- Hinit分片策略
- 不分片策略
分布式序列算法
Sharding-JDBC中默认提供了两种分布式序列算法
- UUID
- 雪花算法
可配置属性:
| 属性名称 | 数据类型 | 说明 | 默认值 |
| worker-id (?) | long | 工作机器唯一标识 | 0 |
| max-vibration-offset (?) | int | 最大抖动上限值,范围[0, 4096)。注:若使用此算法生成值作分片值,建议配置此属性。此算法在不同毫秒内所生成的 key 取模 2^n (2^n一般为分库或分表数) 之后结果总为 0 或 1。为防止上述分片问题,建议将此属性值配置为 (2^n)-1 | 1 |
| max-tolerate-time-difference-milliseconds (?) | long | 最大容忍时钟回退时间,单位:毫秒 |
Sharding-Sphere实战
- 建表语句
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- Table structure for brand_info_0 DROP TABLE IF EXISTS brand_info_0; CREATE TABLE brand_info ( brand_id varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '品牌ID', brand_name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '品牌名称', telephone varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '联系电话', brand_web varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌网络', brand_logo varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌logo URL', brand_desc varchar(150) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌描述', brand_status tinyint(1) NOT NULL DEFAULT 0 COMMENT '品牌状态,0禁用,1启用', brand_order tinyint(4) NOT NULL DEFAULT 0 COMMENT '排序', modified_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间', PRIMARY KEY (brand_id) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '品牌信息表' ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; - 用mybatis plus generator自动生成代码。
- 新建springcloud工程,maven依赖如下
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- <dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</dependency>-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>- 编写测试代码
/**
* @author zhousong
* @ClassName ShardingApplication
* @description: 分库分表测试类
* @datetime 2021年 11月 27日 15:05
* @version: 1.0
*/
@SpringBootTest
public class BrandInfoServiceImplTest {
private static final Logger logger= LoggerFactory.getLogger(BrandInfoServiceImplTest.class);
@Resource
public IBrandInfoService iBrandInfoService;
@Test
public void testSave(){
List<BrandInfo> brandInfos=new ArrayList<BrandInfo>(12);
BrandInfo brandInfo ;
for (int i = 20; i < 42; i++) {
brandInfo = new BrandInfo();
brandInfo.setBrandDesc("toker.zhou品牌测试"+i);
brandInfo.setBrandStatus(i%2);
brandInfo.setBrandLogo("");
brandInfo.setBrandName("toker.zhou品牌测试"+i);
brandInfo.setBrandOrder(1);
if (i<10){
brandInfo.setTelephone("1336757129"+i);
}else{
brandInfo.setTelephone("133675712"+i);
}
brandInfo.setBrandWeb("http://minorcode.cn");
brandInfos.add(brandInfo);
iBrandInfoService.save(brandInfo);
}
logger.info("BrandInfo保存成功");
// iBrandInfoService.saveOrUpdateBatch(brandInfos);
}
}- 首先贴出我之前的错误配置
spring: shardingsphere: # 内存模式,元数据保存在当前进程中 mode: type: Memory datasource: names: master,slave$->{0..1} master: #shardingsphere默认连接池是Hikari type: com.alibaba.druid.pool.DruidDataSource url: jdbc:mysql://192.168.118.121:3306/tokercart?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false username: root password: xxxx slave0: type: com.alibaba.druid.pool.DruidDataSource #shardingsphere默认连接池是Hikari url: jdbc:mysql://192.168.118.120:3306/tokercart?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false username: root password: xxxx slave1: type: com.alibaba.druid.pool.DruidDataSource #shardingsphere默认连接池是Hikari url: jdbc:mysql://192.168.118.122:3306/tokercart?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false username: root password: xxxx rules: readwrite-splitting: data-sources: toker-source: load-balancer-name: round_robin_toker write-data-source-name: master read-data-source-names: slave0,slave1 load-balancers: round_robin_toker: type: ROUND_ROBIN sharding: tables: brand: actual-data-nodes: master.brand_info_copy$->{0..1},slave$->{0..1}.brand_info_copy$->{0..1} #也可以使用${0..n1}的形式,但是会与Spring属性文件占位符冲突,注意不要写成了$->{0,1}我之前就是在这个逗号上栽了跟头 database-strategy: standard: sharding-column: brand_status sharding-algorithm-name: brand_mode table-strategy: standard: sharding-column: brand_id sharding-algorithm-name: brandId_mode sharding-algorithms: brand_mode: type: MOD props: sharding-count: 2 brandId_mode: type: MOD props: sharding-count: 2 key-generator: column: brand_id type: SNOWFLAKE props: sql: show: true实操注意的问题:创建实体类时,默认一个实体类对应一张表,若要对应两张表,需要在properties文件中添加配置(spring.main.allow-bean-definition-overriding=true)
shardingsphere的sql日志无法打印问题
5.x版本以前
spring.shardingsphere.props.sql.show=true
5.x版本以后,sql.show参数调整为sql-show
spring.shardingsphere.props.sql-show=true
所以上面配置文件应该是
props:
sql-show:true配置的雪花算法不生效
- BrandInfo实体类auto生成的id注释
- key-generator属于sharding的子项,而不是tables的,改正如下
// @TableId(value = "brand_id", type = IdType.AUTO)
private String brandId;
.................... ....................
sharding:
tables:
brand_info:
....................
column: brand_id
key-generator-name: Brand_SNOWFLAKE
....................
key-generators:
Brand_SNOWFLAKE:
type: SNOWFLAKEField 'brand_id' doesn't have a default value
### The error may involve com.toker.cloud.platform.sharding.mapper.BrandInfoMapper.insert-Inline
### The error occurred while setting parameters
### SQL: INSERT INTO brand_info ( brand_name, telephone, brand_web, brand_logo, brand_desc, brand_status, brand_order ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
### Cause: java.sql.SQLException: Field 'brand_id' doesn't have a default value
; Field 'brand_id' doesn't have a default value; nested exception is java.sql.SQLException: Field 'brand_id' doesn't have a default value
at org.springframework.jdbc.support.SQLErrorCodeSQLExceptionTranslator.doTranslate(SQLErrorCodeSQLExceptionTranslator.java:251)
at org.springframework.jdbc.support.AbstractFallbackSQLExceptionTranslator.translate(AbstractFallbackSQLExceptionTranslator.java:70)
at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:88)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:440)
........................................................................................................................................................
Caused by: java.sql.SQLException: Field 'brand_id' doesn't have a default value
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:129)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:916)
at com.mysql.cj.jdbc.ClientPreparedStatement.execute(ClientPreparedStatement.java:354)
at com.alibaba.druid.pool.DruidPooledPreparedStatement.execute(DruidPooledPreparedStatement.java:497)
at org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement$2.executeSQL(ShardingSpherePreparedStatement.java:412)
at org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSpherePreparedStatement$2.executeSQL(ShardingSpherePreparedStatement.java:408)
at org.apache.shardingsphere.infra.executor.sql.execute.engine.driver.jdbc.JDBCExecutorCallback.execute(JDBCExecutorCallback.java:86)
at org.apache.shardingsphere.infra.executor.sql.execute.engine.driver.jdbc.JDBCExecutorCallback.execute(JDBCExecutorCallback.java:66)
at org.apache.shardingsphere.infra.executor.kernel.ExecutorEngine.syncExecute(ExecutorEngine.java:135)
at org.apache.shardingsphere.infra.executor.kernel.ExecutorEngine.parallelExecute(ExecutorEngine.java:131)参看开头我贴出错的配置文件
sharding:
tables:
brand: ##错误原因在这里
....................
column: brand_id
key-generator-name: Brand_SNOWFLAKE
....................
key-generators: ####这里从原来的key-generators和tables同属于sharding的子配置项
Brand_SNOWFLAKE:
type: SNOWFLAKE错误原因。我用mybatis生成的实体类brandInfo以及mapper默认的表对应的是brand_info。当shardingsphere执行 INSERT INTO brand_info ( brand_name....这条语句的时候, 由于配置文件没有brand_info这个表对应的分表配置。那么直接放过。这个时候对brand_id配置的雪花算法自然无效。所以这里有两种解决办法
解决办法:第一种办法在实体类上加上@TableName("brand"),第二种办法修改bootstrap.yml这段配置,直接修改为brand_info
sharding:
tables:
brand_info: ####这里从原来的brand直接修改为brand_info
....................
column: brand_id
key-generator-name: Brand_SNOWFLAKE
....................
key-generators: ####这里从原来的key-generators和tables同属于sharding的子配置项
Brand_SNOWFLAKE:
type: SNOWFLAKEInsert statement does not support sharding table routing to multiple data nodes
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
### Error updating database. Cause: java.lang.IllegalStateException: Insert statement does not support sharding table routing to multiple data nodes.
### The error may exist in com/toker/cloud/platform/sharding/mapper/BrandInfoMapper.java (best guess)
### The error may involve com.toker.cloud.platform.sharding.mapper.BrandInfoMapper.insert-Inline
### The error occurred while setting parameters
### SQL: INSERT INTO brand_info ( brand_name, telephone, brand_web, brand_logo, brand_desc, brand_status, brand_order ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
### Cause: java.lang.IllegalStateException: Insert statement does not support sharding table routing to multiple data nodes.
at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:92)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:440)
at com.sun.proxy.$Proxy216.insert(Unknown Source)
at org.mybatis.spring.SqlSessionTemplate.insert(SqlSessionTemplate.java:271)
at com.baomidou.mybatisplus.core.override.MybatisMapperMethod.execute(MybatisMapperMethod.java:60)
at com.baomidou.mybatisplus.core.override.MybatisMapperProxy$PlainMethodInvoker.invoke(MybatisMapperProxy.java:148)
at com.baomidou.mybatisplus.core.override.MybatisMapperProxy.invoke(MybatisMapperProxy.java:89)
at com.sun.proxy.$Proxy217.insert(Unknown Source)解决方案:看错误明显是insert没有路由到的问题。发现sharding-algorithms路径写到了 brand_info下面。它应该属于sharding的子项才对
sharding:
tables:
brand_info:
....................................
sharding-algorithms:
brand_mode:
type: MOD
props:
sharding-count: 2
brandId_mode:
type: MOD
props:
sharding-count: 2No database route info
### SQL: INSERT INTO brand_info ( brand_name, telephone, brand_web, brand_logo, brand_desc, brand_status, brand_order ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
### Cause: java.lang.IllegalStateException: No database route info
at org.mybatis.spring.MyBatisExceptionTranslator.translateExceptionIfPossible(MyBatisExceptionTranslator.java:92)
at org.mybatis.spring.SqlSessionTemplate$SqlSessionInterceptor.invoke(SqlSessionTemplate.java:440)
at com.sun.proxy.$Proxy216.insert(Unknown Source)
at org.mybatis.spring.SqlSessionTemplate.insert(SqlSessionTemplate.java:271)
at com.baomidou.mybatisplus.core.override.MybatisMapperMethod.execute(MybatisMapperMethod.java:60)
at com.baomidou.mybatisplus.core.override.MybatisMapperProxy$PlainMethodInvoker.invoke(MybatisMapperProxy.java:148)
at com.baomidou.mybatisplus.core.override.MybatisMapperProxy.invoke(MybatisMapperProxy.java:89)
at com.sun.proxy.$Proxy217.insert(Unknown Source)正确配置要点
- 主从配置数据源(主库写、从库读)。即readwrite_ds(这个是在spring.shardingsphere.rules.readwrite-splitting.data-sources下自定义的名称)
- 分库分表的的数据源要从前面的主从配置数据源获取即readwrite_ds ,actual-data-nodes: readwrite_ds.brand_info_$->{0..1},这里的$->{0..1}是为了防止和spring的配置文件占位符{0..1}起冲突.
-
切勿网上拷贝的配置,从github找到相应的版本的example核对下配置.比如我是5.1.2的版本。则核对位置;https://github.com/apache/shardingsphere/blob/5.1.2/examples/shardingsphere-jdbc-example/mixed-feature-example/sharding-readwrite-splitting-example/sharding-readwrite-splitting-spring-boot-mybatis-example/src/main/resources/application-sharding-readwrite-splitting.properties
主从分离和分库分表配置(修正后)
spring:
shardingsphere:
# 内存模式,元数据保存在当前进程中
mode:
type: Memory
datasource:
names: master,slave0,slave1
master:
#shardingsphere默认连接池是Hikari
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.118.121:3306/tokercart?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: xxxx
slave0:
type: com.alibaba.druid.pool.DruidDataSource #shardingsphere默认连接池是Hikari
url: jdbc:mysql://192.168.118.120:3306/tokercart?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: xxxx
slave1:
type: com.alibaba.druid.pool.DruidDataSource #shardingsphere默认连接池是Hikari
url: jdbc:mysql://192.168.118.122:3306/tokercart?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: xxxx
rules:
readwrite-splitting:
data-sources:
readwrite_ds:
type: Static
props:
write-data-source-name: master
read-data-source-names: slave0,slave1
load-balancer-name: round_robin_toker
load-balancers:
round_robin_toker:
type: ROUND_ROBIN
sharding:
tables:
brand_info:
actual-data-nodes: readwrite_ds.brand_info_$->{0..1}
# database-strategy:
# standard:
# sharding-column: brand_status
# sharding-algorithm-name: brand_mode
table-strategy:
standard:
sharding-column: brand_status
sharding-algorithm-name: brand_mode
key-generate-strategy:
column: brand_id
key-generator-name: Brand_SNOWFLAKE
sharding-algorithms:
brand_mode:
type: MOD
props:
sharding-count: 2
# brandId_mode:
# type: MOD
# props:
# sharding-count: 2
key-generators:
Brand_SNOWFLAKE:
type: SNOWFLAKE
props:
# sql:
# show: true
sql-show: true
enabled: true
main:
allow-bean-definition-overriding: trueQueryWrapper和LambdaQueryWrapper
在前面的BrandInfoServiceImplTest中再添加一个查询类,结合前面的写入类观测结果
@Test
public void findByBrandStatus(){
QueryWrapper<BrandInfo> queryWrapper = new QueryWrapper<BrandInfo>();
// 面向表字段的查询
queryWrapper.eq("brand_status",0);
Page<BrandInfo> page=new Page<BrandInfo>(1,2);
IPage<BrandInfo> results=iBrandInfoService.page(page,queryWrapper);
logger.info("case1查询出的分页对象为:{}", JSON.toJSON(results));
Page<BrandInfo> page2=new Page<BrandInfo>(2,2);
//面向对象的写法
LambdaQueryWrapper<BrandInfo> lambdaQueryWrapper = new LambdaQueryWrapper<BrandInfo>();
lambdaQueryWrapper.eq(BrandInfo::getBrandStatus,1);
//下面这段方法在mybatis在做属性转换时候值是一段函数。而非从get或者is解析出来的值
// lambdaQueryWrapper.eq((x)->{
// return x.getBrandStatus();
// },1);
IPage<BrandInfo> results2=iBrandInfoService.page(page2,lambdaQueryWrapper);
logger.info("case2查询出的分页对象为:{}", JSON.toJSON(results2));
// queryWrapper.clear();
// queryWrapper.eq("brand_status",1);
// IPage<BrandInfo> results3=iBrandInfoService.page(page,lambdaQueryWrapper);
// logger.info("case3查询出的分页对象为:{}", JSON.toJSON(results3));
}
执行testSave()和findByBrandStatus()测试
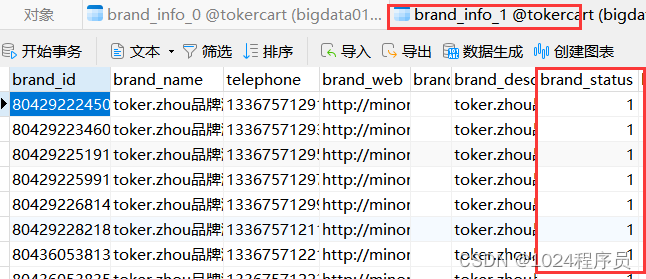
- 先执行BrandInfoServiceImplTest的testSave()方法,观测写库结果,可以看到status为1的和为0的在不同的表里。分表成功。

- 执行findByBrandStatus()的方法。观测实际生成的sql语句和打印的分页的执行结果,可以看到一个是查询的slave0的brand_info_0 ,一个查询的是slave1的brand_info_1表
Actual SQL: slave0 ::: SELECT brand_id,brand_name,telephone,brand_web,brand_logo,brand_desc,brand_status,brand_order,modified_time FROM brand_info_0 WHERE (brand_status = ?) LIMIT ? ::: [0, 2] 2022-11-29 15:21:35.003 INFO 56624 --- [ main] c.t.c.p.s.s.i.BrandInfoServiceImplTest : case1查询出的分页对象为:{"current":1,"total":17,"hitCount":false,"pages":9,"optimizeCountSql":true,"size":2,"records":[{"brandWeb":"http://minorcode.cn","modifiedTime":"2022-11-29T10:10:10","brandName":"toker.zhou品牌测试0","brandDesc":"toker.zhou品牌测试0","brandId":"804289715246202880","telephone":"13367571290","brandStatus":0,"brandLogo":"","brandOrder":1},{"brandWeb":"http://minorcode.cn","modifiedTime":"2022-11-29T10:10:12","brandName":"toker.zhou品牌测试2","brandDesc":"toker.zhou品牌测试2","brandId":"804292230620643328","telephone":"13367571292","brandStatus":0,"brandLogo":"","brandOrder":1}],"searchCount":true,"orders":[]} : Actual SQL: slave1 ::: SELECT brand_id,brand_name,telephone,brand_web,brand_logo,brand_desc,brand_status,brand_order,modified_time FROM brand_info_1 WHERE (brand_status = ?) LIMIT ?,? ::: [1, 2, 2] 2022-11-29 15:21:35.066 INFO 56624 --- [ main] c.t.c.p.s.s.i.BrandInfoServiceImplTest : case2查询出的分页对象为:{"current":2,"total":17,"hitCount":false,"pages":9,"optimizeCountSql":true,"size":2,"records":[{"brandWeb":"http://minorcode.cn","modifiedTime":"2022-11-29T10:10:17","brandName":"toker.zhou品牌测试5","brandDesc":"toker.zhou品牌测试5","brandId":"804292251910930433","telephone":"13367571295","brandStatus":1,"brandLogo":"","brandOrder":1},{"brandWeb":"http://minorcode.cn","modifiedTime":"2022-11-29T10:10:19","brandName":"toker.zhou品牌测试7","brandDesc":"toker.zhou品牌测试7","brandId":"804292259913662465","telephone":"13367571297","brandStatus":1,"brandLogo":"","brandOrder":1}],"searchCount":true,"orders":[]}至此主从+分库分表配置测试成功。 下一步计划将跟踪Debug的源码分析贴出来。
一个小插曲
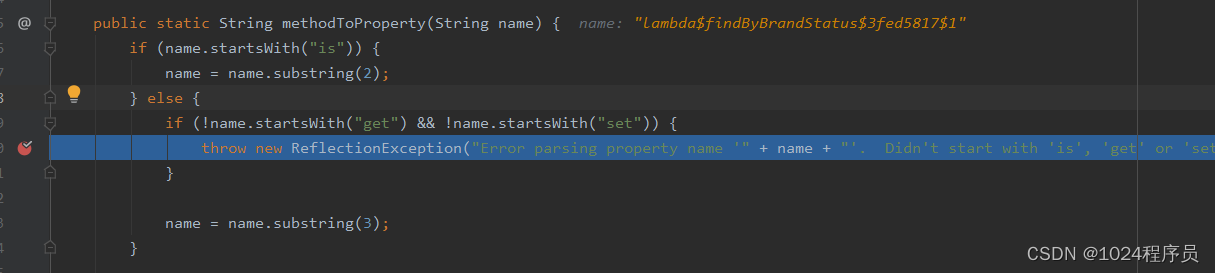
错误写法:lambdaQueryWrapper.eq((x)->{
return x.getBrandStatus();
},1);
正确写法:lambdaQueryWrapper.eq(BrandInfo::getBrandStatus,1);如果用lambda表达式,这个name的值会被判定是一段函数,mybatis在做属性转换的时候直接报错














 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









