








刚接触实时数据的时候,那时候比较时兴叫“流式数据”。我就非常怀疑实时数据的应用场景极其有限。别的不说,单说 Join 这个非常常用的数据操作,你说咋实现?
Join 是咋回事?
在关系型数据库中,两个表的 Join 原理其实还是比较容易理解的。我们用最朴素的方式方法去理解,就是这个样子:
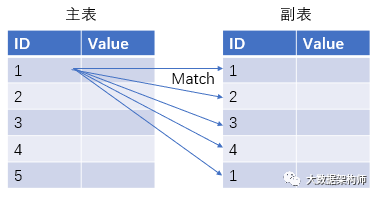
主表和副表进行 Join ,其实就是拿主表的每一条记录跟副表的每一条记录进行查询、匹配。有人说了,匹配上一条是不是就可以了?当然不行了,因为可能会存在多对多的关系,所以必须要每一条进行匹配。
匹配结束后,把匹配的结果进行合并,然后输出结果,这就是全表 Join 的原理了。不过这种方式简单且容易理解,但是这开销也太大了吧!相当于 N 个全表扫描了。
这种情况在一般的场景不多见,因为有经验的数据工程师会用第二种方法:
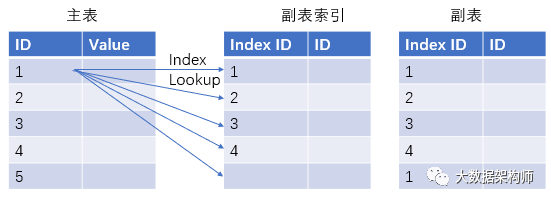
其实就是在副表的关联字段上建一个索引。这样,主表在去找数据的时候,就不用做全表扫描了,索
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6235
6235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









