






软件构造第三次课程笔记
重点掌握前5部分
广义软件构造过程:设计->编程->debug->测试->构建->release
狭义软件构造过程(build):验证->编译->链接->测试->包装->安装->部署
各阶段子过程如下↓

1.软件开发生命环(SDLC)
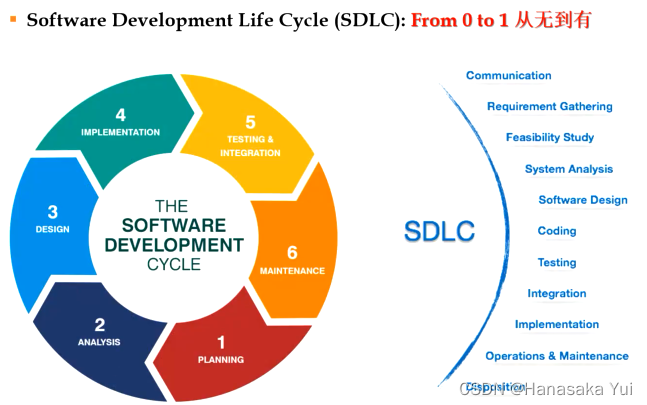
计划->分析->设计->执行->测试&整合->维护
※在实际中实用性不大,只是作为一种概念,因为前面步骤出错会导致后面也出错
软件存在生命周期:兴起-兴盛-消亡
2.传统软件开发模型(瀑布,增量,V 模型,原型化,螺旋型)
0.两个基本模型
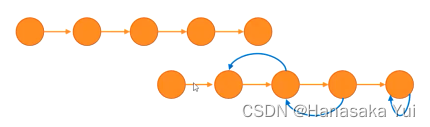
线性过程 :无反馈过程,某一步出错都会导致整体的错误
迭代过程:有反馈过程。执行下一步骤会给上一步骤一个反馈,若有问题则要加以修正
1.瀑布模型
特点:线性推进,无迭代
优点:阶段划分清楚,整体推进,管理简单
缺点:无法保证结果完全正确,无法适应变化
基本只是理论模型,现实中不能用
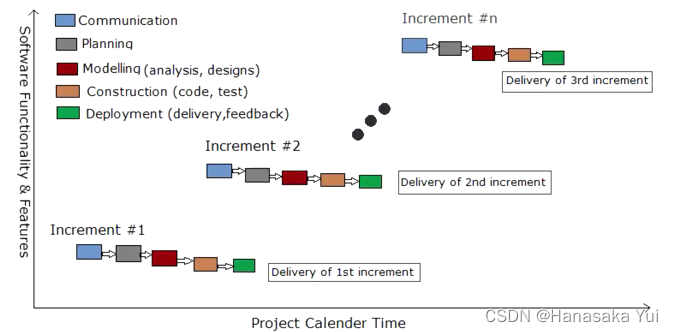
2.增量模型
特点:线性推进,无迭代,增量式(多个瀑布的串行)
优点:比较容易适应需求变化 比如完成第一个子项目了,后面的子项目需求变了对开发过程无影响,因为还没开始后面项目的开发;比如完成第一个项目发现出错也可以重头进行修改,因为将大项目分成若干小项目,小项目用时少,时间上允许重新开发
缺点:无反馈,且需要稳定的整体架构,否则可能会出现各部分均能执行却无法合并到一起
3.V模型
特点:把代码阶段后的步骤进行倒置形成V字形,横纵轴分别代表时间或程序完整性以及抽象阶段
优点:做正确的事、正确地做事
开发过程与验证过程一一对应:
运转概念-----运转与维护
需求与体系结构----系统确定与验证
细节设计----整合,测试,确定
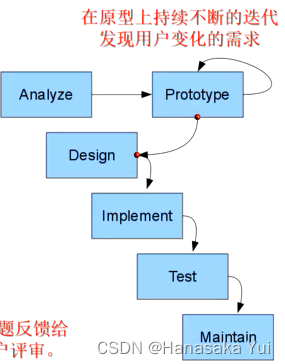
4.原型化开发
特点:先开发出原型程序,在原型上不断迭代发现用户需求变化。具体为开发出来之后由用户试用/评审,发现问题反馈给开发者,开发者修改原有的实现,继续交给用户评审。.循环往复这个过程,直到用户满意为止。
优点:及时从使用者那里得到有价值的反馈
客户可以根据哪一个软件被build,比较软件与软件的规格
允许开发者了解对原始程序准确性的评估,以及是否能够成功达成ddl或里程碑
不足:时间代价高但开发质量也高。
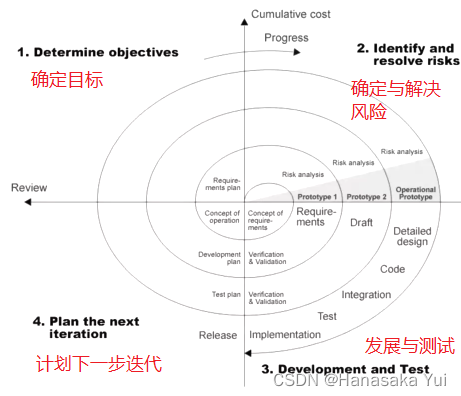
5.螺旋型模型
特点:非常复杂的过程:多轮迭代基本遵循瀑布模式。
每轮迭代有明确的目标,遵循“原型”过程,进行严格的风险分析,方可进入下一轮迭代。
不足:模型很好,但不实用,主要原因是第二象限(风险分析)不知道该怎么办,没有通用的分析思路
3.敏捷开发与极限编程(XP)
1.敏捷开发:通过快速迭代与小规模持续改进,以快速适应变化。变化很大情况下用这种模型
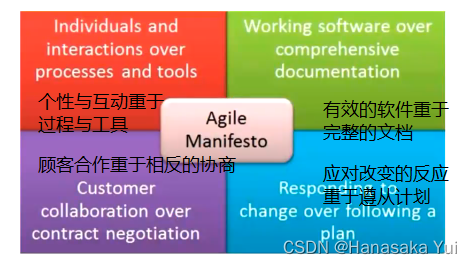
2.敏捷宣言:
3.敏捷开发—>快速的传送
Agile=增量+迭代 每次迭代处理一个小规模增量
1-4周时间开发出一个简易的程序实行部分基本需求。若需求改变,分析需要是已经开发的功能还是未开发的功能,后者无影响,前者可以选择先按此前思路实现该功能提供给用户再优化
计划/反馈循环(不同大小的不同循环)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sEbf90gl-1653835132949)(img/image-20220427194343165.png)]](https://img-blog.csdnimg.cn/53931cb32af345509c4df90a6ff27c7b.png)
4.敏捷开发(随着需求变化,每过段时间发布一个release的程序)与瀑布开发(最终产生一个release的程序的对比
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cARSLvkb-1653835132950)(img/image-20220427194603204.png)]](https://img-blog.csdnimg.cn/245213bdae6841eeba004cd67431cd8c.png)
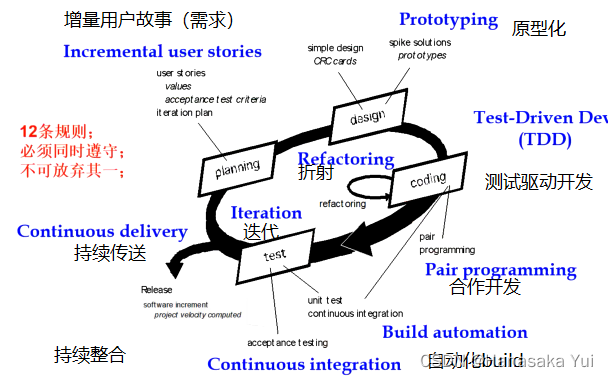
5.极限编程规则
先让用户写需求卡片,
4.软件配置管理(SCM)与版本控制系统(VCS)
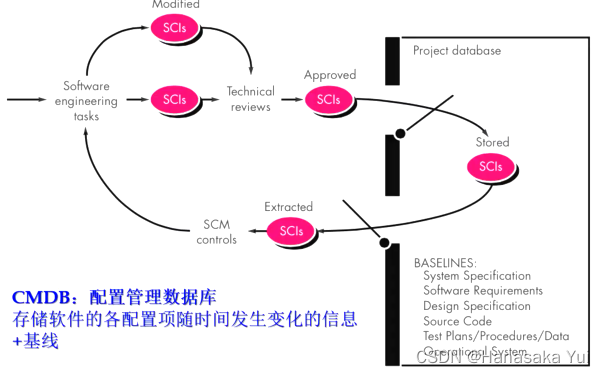
1.软件配置管理:追踪和控制软件变化,包括修订控制、基线建立
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qEBdAVkH-1653835132951)(img/image-20220427200434065.png)]](https://img-blog.csdnimg.cn/9221dc5e12c24c62b7afba3dead1a7a6.png)
2.基线:软件持续变化过程中的稳定时刻(如对外发布的版本)
I)代表多个源代码文件的一组版本。
比如有三个文件,aaa.c、 bbb.c和ccc.h。 可以对这三个文件做一 个基线,每个文件取一个版本,如取aaa.c的版本1.1,取bbb.c的版 本1.3,取c.h的版本1.0,最后形成一个版本的总文件。(1.1,13,1.0)就是一个基线。
II)代表文档的一个稳定状态。
比如有一个项目设计文档,当设计基本完成,开发即将开始的时候,需要把这个文档固定下来,内容不能再频繁改变,否则开发人员就无所适从了,可能导致每个人所参照的文档并不是同一个文档。
一个文档如果经过讨论被通过了,被固定了,就可以说这个文档被“基线化”了,然后所有人就可以在这个“基线”的基础上工作。
文档不可能一成不变,所以当对文档的修改仍然会不断进行,但这种修改并不会随时随地的添加到被“基线化”了的文档中去。因为既然是“基线”,就不能随便动。(比如在1-4周开发中,这个文档就不会变)
到了一定时候,修改积累到一定程度,就需要把很多修改合并到原来的文档中去了,并生成一个新版本的文档作为团队中所有的人的参考标准,并把老的版本淘汰掉。这就叫做“基线提升"
3.配置管理数据库:CMDB
4.版本控制

4.1版本控制的必要性


4.2版本控制相关术语

4.3版本控制系统
A.本地版本控制系统:仓库存储于开发者本地机器,无法共享和协作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x03XeMgG-1653835132954)(img/image-20220427202529506.png)]](https://img-blog.csdnimg.cn/12ced58de7e34495b9ea71aa1fe9cb72.png)
B.集中式版本控制系统:仓库存储于独立的服务器,支持多开发者之间的协作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3ym1py8U-1653835132954)(img/image-20220427202544174.png)]](https://img-blog.csdnimg.cn/f6fefe3176184c8099496cb944b40e2b.png)
C.分布式版本控制系统:仓库存储于独立的服务器+每个开发者的本地机器
server里有每个人的备份,每个人电脑里也有各自备份。
A和B可以互相交流也可以通过server进行交流
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mvKf2Oag-1653835132955)(img/image-20220427202946741.png)]](https://img-blog.csdnimg.cn/a8be171cf9e84b29956cf3def8b86dd9.png)
5.GIT作为软件调试管理工具
1.GIT相关提交下载指令
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Jhd2m0a-1653835132955)(img/image-20220427203051899.png)]](https://img-blog.csdnimg.cn/48953101d12b4f27a1b0c8cae5edbf1f.png)
2.GIT仓库分为3部分:git directory :本地CMDB;工作目录(working directory):本地文件系统;暂存区(staging area):隔离工作目录与GIT仓库
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-icAnFlp2-1653835132955)(img/image-20220427203313124.png)]](https://img-blog.csdnimg.cn/6353a44ed1db41d19dcfca7a5963e085.png)
3.GIT的对象图
我们用Git做的所有操作-克隆,添加,提交,推送,日志合并等都是对图数据结构的操作。
图数据结构在项目中存储所有版本的文件,以及描述这些更改的条目的所有日志。
Git对象图存储在存储库的.git目录中。
从另一台机器/服务器复制git项目意味着复制整个对象图。
4.对象图的结点:commit
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZFrDFrD3-1653835132956)(img/image-20220427203834612.png)]](https://img-blog.csdnimg.cn/da33a01e465d40659b678ffe2c884e1d.png)
HEAD为当前编辑结点。这幅图最底下的为祖先commit
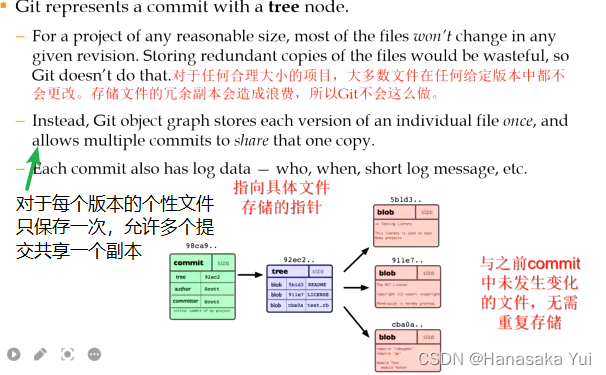
6.GIT的管理变化
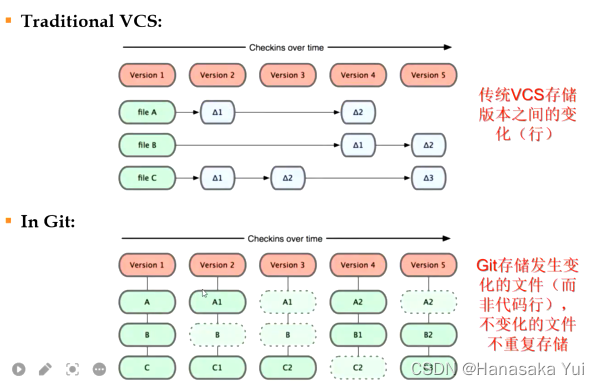
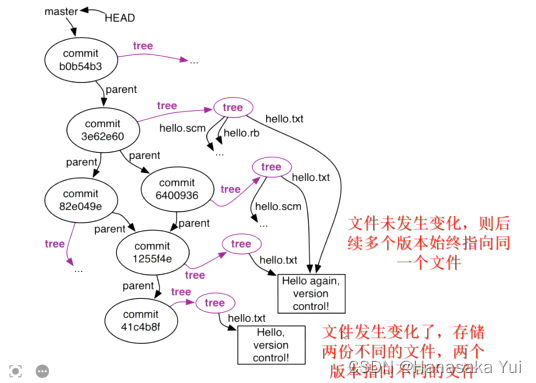
7.分支/合并
分支是处于修订控制下的对象的复制,以便可以沿着两个分支并行修改
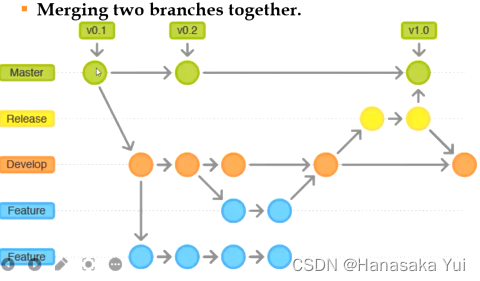
*6.软件开发整体流程
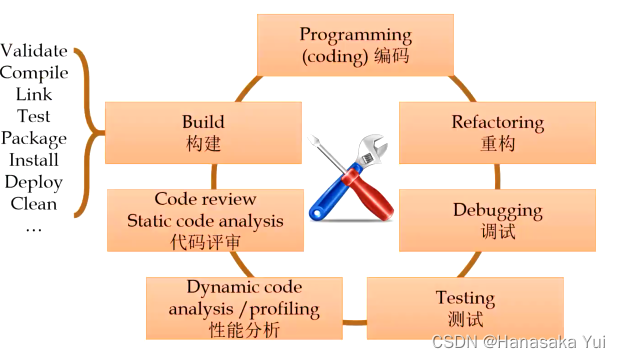
(1)编程
A.语言组成

B.编程工具:

C.建模语言
建模语言是一种人工语言,可用于在由一组一致规则定义的结构中表达信息、知识或系统,其目的是可视化、推理、验证和传达系统的设计。UML即为一种建模语言
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qBbwU83e-1653835132962)(img/image-20220502193412201.png)]](https://img-blog.csdnimg.cn/b744f2136b204458a3f6f040db11c0fb.png)
(2)评审与代码分析
代码评审是对源代码的系统性检查(同行评审)旨在发现在初始开发阶段被忽略的错误,提高整体质量评审以各种形式进行,如结对编程、非正式演练和正式检查。
代码审查实际上有两个目的:
1.改进代码。发现错误,预测可能的错误,检查代码的清晰性,并检查与项目风格标准的一致性。
2.改进程序员。代码评审是程序员相互学习和传授新语言特性、项目设计或其编码标准的变化以及新技术的重要方式。尤其是在开源项目中,有很多对话在代码审查的环境中发生。
代码审查广泛应用于开源项目,比如Apache和Mozilla。
(3)动态代码分析/概况
动态分析:要执行程序并观察现象、收集数据、分析不足
执行目标程序时必须有足够的测试输入,以产生有趣的行为。
使用诸如代码覆盖率之类的软件测试措施有助于确保程序的一组可能行为中有足够的一部分得到了观察。
评测(“程序评测”、“软件评测”)是一种动态程序分析形式,用于测量程序的空间(内存)或时间复杂性、特定指令的使用情况,或函数调用的频率和持续时间.
(4)调试测试
A.测试
软件测试是为了提供利益相关者有关测试产品或服务质量的信息。
测试技术包括执行程序或应用程序的过程,目的是发现软件缺陷(错误或其他缺陷),并验证软件产品是否适合使用。
软件测试涉及软件组件或系统组件的执行,以评估一个或多个感兴趣的属性。
B.调试
调试是识别故障根源的过程并纠正它。
它与测试形成对比,测试是最初检测错误的过程,调试是由于测试成功的结果。
与测试一样,调试不是提高软件质量的方法,而是诊断缺陷的方法。
软件质量必须从一开始就具备。构建高质量产品的最佳方法是仔细地开发需求、良好地设计并使用高质量的编码实践。
调试是最后的手段。
(5)重构
重构是改变软件系统的过程,不会改变系统的外部行为。代码还改进了其内部结构。
重构是:重组(重新排列)代码、在一系列保留语义的小变换中、为了使代码更易于维护和修改
重构不仅仅是任何旧的重组,需要让代码继续工作,需要一些小步骤来保留语义,需要进行单元测试来证明代码是有效的
*7.狭义的软件构建过程(构建)
粗略理解build:build-time-> run-time
借助于工具,将软件构造各阶段的活动“自动化”(编译、打包、静态分析、测试、生成文档、部署、…)
尽可能脱离“手工作业”,提高构造效率
–构建系统:组件和过程–构建变体和构建语言
–构建工具:Make、Ant、Maven、Gradle、Eclipse















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









