







一般的自注意力:查询−键−值模型
到目前为止,我们只考虑了输入序列只有一个的情况。但是,Transformer架构最初是为机器翻译而开发的,它需要处理两个输入序列:当前正在翻译的源序列(比如“How’s the weather today?”)与需要将其转换成的目标序列(比如“¿Quétiempo hace hoy?”)。Transformer是一种序列到序列(sequence-to-sequence)模型,它的设计目的就是将一个序列转换为另一个序列。本章稍后会深入介绍序列到序列模型。源序列是英语,目标序列是西班牙语,两句话的意思都是“今天天气怎么样”。—译者注现在我们先回到本节主题。自注意力机制的作用如下所示。
outputs = sum(inputs * pairwise_scores(inputs, inputs))
↑ ↑ ↑
C A B
这个表达式的含义是:“对于inputs(A)中的每个词元,计算该词元与inputs(B)中每个词元的相关程度,然后利用这些分数对inputs(C)中的词元进行加权求和。”重要的是,A、B、C不一定是同一个输入序列。一般情况下,你可以使用3个序列,我们分别称其为查询(query)、键(key)和值(value)。这样一来,上述运算的含义就变为:“对于查询中的每个元素,计算该元素与每个键的相关程度,然后利用这些分数对值进行加权求和。”
outputs = sum(values * pairwise_scores(query, keys))
这些术语来自搜索引擎和推荐系统,如图11-7所示。想象一下,你输入“沙滩上的狗”,想从数据库中检索一张图片。在数据库内部,每张照片都由一组关键词所描述—“猫”“狗”“聚会”等。我们将这些关键词称为“键”。搜索引擎会将你的查询和数据库中的键进行对比。“狗”匹配了1个结果,“猫”匹配了0个结果。然后,它会按照匹配度(相关性)对这些键进行排序,并按相关性顺序返回前n张匹配图片。
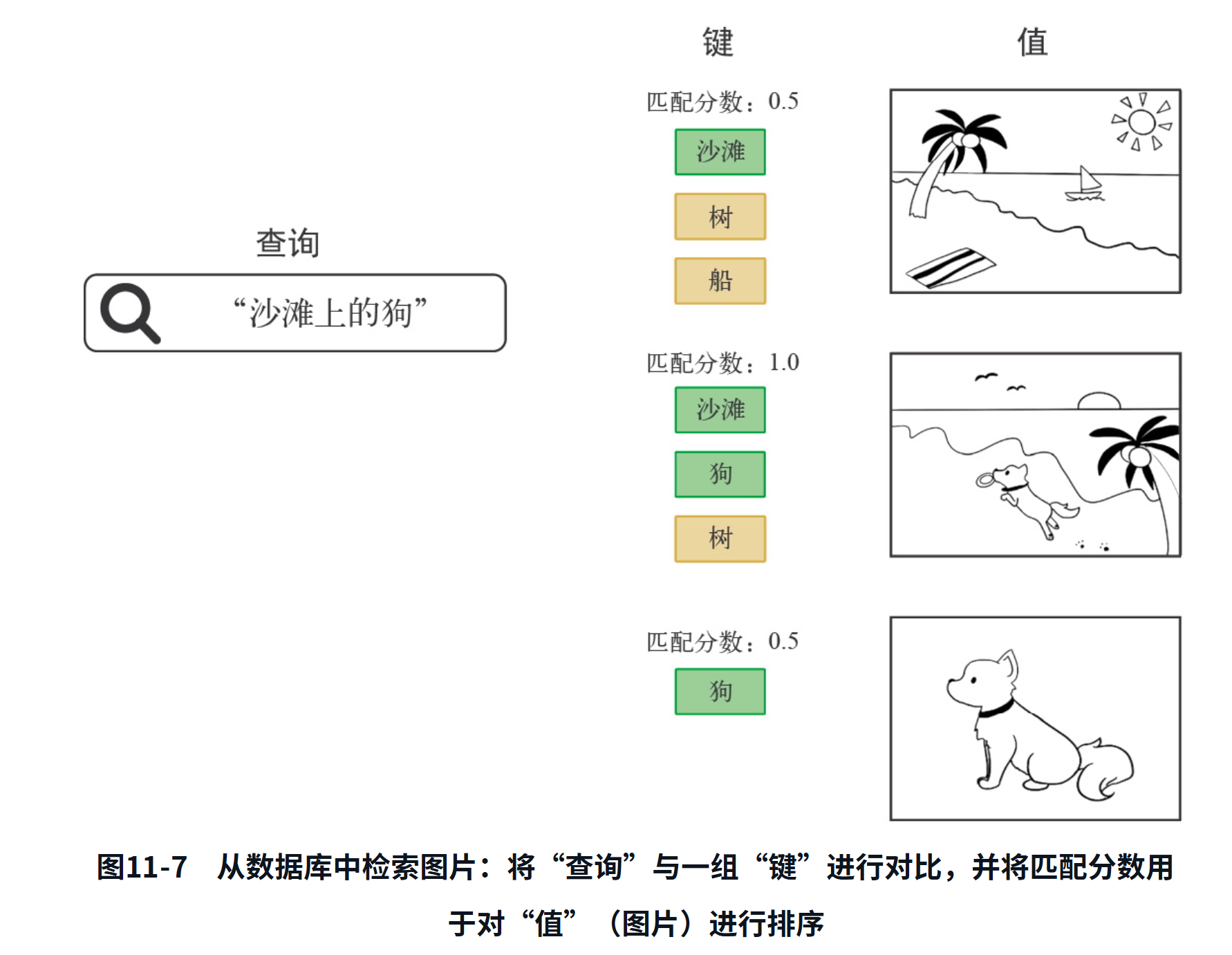
从概念上来说,这就是Transformer注意力所做的事情。你有一个参考序列,用于描述你要查找的内容:查询。你有一个知识体系,并试图从中提取信息:值。每个值都有一个键,用于描述这个值,并可以很容易与查询进行对比。你只需将查询与键进行匹配,然后返回值的加权和。在实践中,键和值通常是同一个序列。比如在机器翻译中,查询是目标序列,键和值则都是源序列:对于目标序列中的每个元素(如“tiempo”),你都希望回到源序列(“How’s the weather today?”),并找到与其相关的元素(“tiempo”和“weather”应该有很强的匹配程度)。当然,如果你只做序列分类,那么查询、键和值这三者是相同的:将一个序列与自身进行对比,用整个序列的上下文来丰富每个词元的表示。这就解释了为什么要向MultiHeadAttention层传递3次inputs。但为什么叫它“多头注意力”呢?
多头注意力
多头注意力”是对自注意力机制的微调,它由“Attention Is All You Need”这篇论文引入。“多头”是指:自注意力层的输出空间被分解为一组独立的子空间,对这些子空间分别进行学习,也就是说,初始的查询、键和值分别通过3组独立的密集投影,生成3个独立的向量。每个向量都通过神经注意力进行处理,然后将多个输出拼接为一个输出序列。每个这样的子空间叫作一个“头”。整体示意图如图11-8所示。
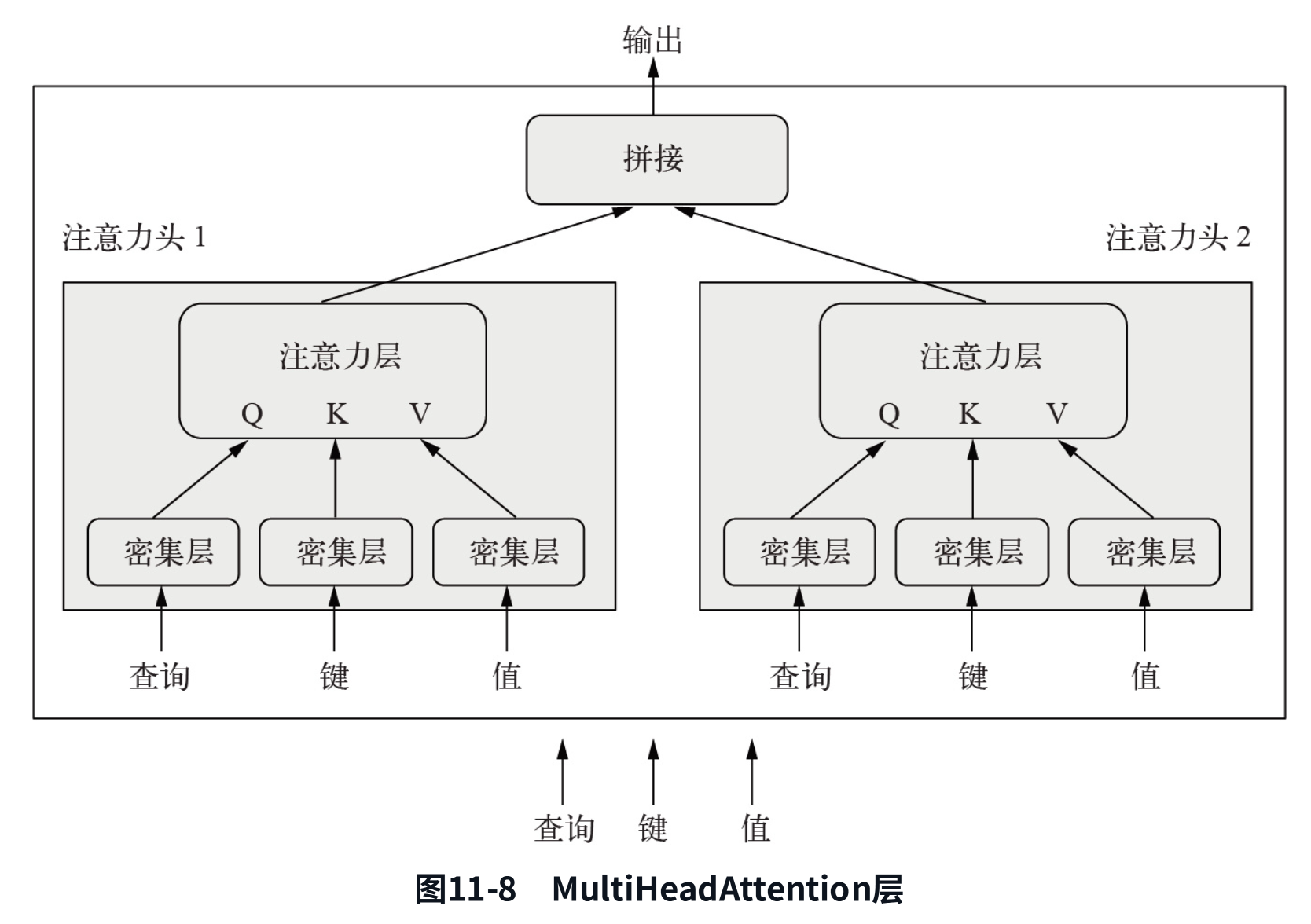
由于存在可学习的密集投影,因此该层能够真正学到一些内容,而不是单纯的无状态变换,后者需要在之前或之后添加额外的层才能发挥作用。此外,独立的头有助于该层为每个词元学习多组特征,其中每一组内的特征彼此相关,但与其他组的特征几乎无关。这在原理上与深度可分离卷积类似:对于深度可分离卷积,卷积的输出空间被分解为多个独立学习的子空间(每个输入通道对应一个子空间)。“Attention Is All You Need”这篇论文发表时,人们发现将特征空间分解为独立子空间的想法对计算机视觉模型有很大好处,无论是深度可分离卷积,还是另一种密切相关的方法,即分组卷积。多头注意力只是将同样的想法应用于自注意力。
Transformer编码器
如果添加密集投影如此有用,那为什么不在注意力机制的输出上也添加一两个呢?实际上这是一个好主意,我们来这样做吧。因为我们的模型已经做了很多工作,所以我们可能想添加残差连接,以确保不会破坏任何有价值的信息—第9章说过,对于任意足够深的架构,残差连接都是必需的。第9章还介绍过,规范化层有助于梯度在反向传播中更好地流动。因此,我们也添加规范化层。这大致就是我所想象的Transformer架构的发明者当时头脑中的思考过程。将输出分解为多个独立空间、添加残差连接、添加规范化层—所有这些都是标准的架构模式,在任何复杂模型中使用这些模式都是明智的。这些模式共同构成了Transformer编码器(Transformer encoder),它是Transformer架构的两个关键组件之一,如图11-9所示。
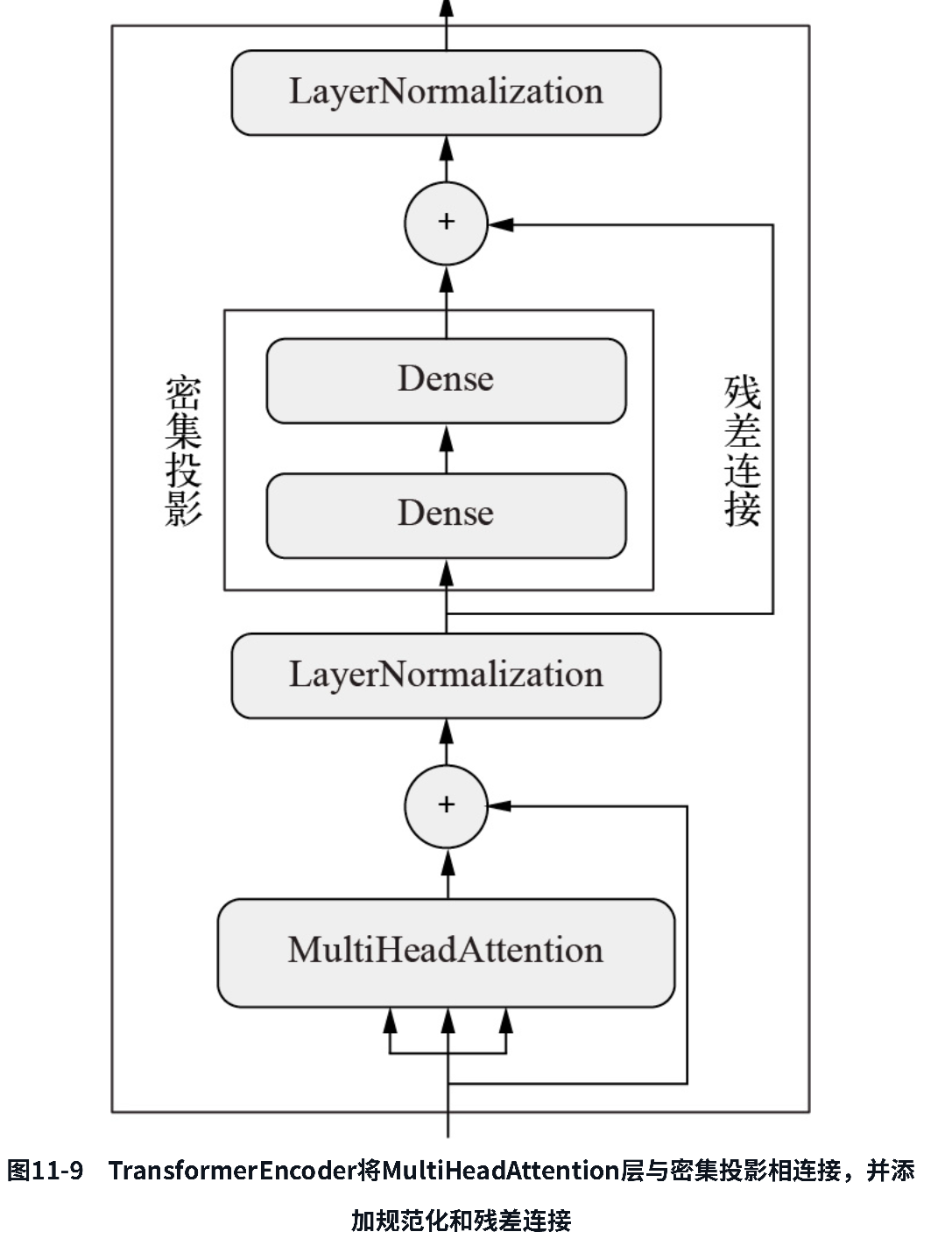
最初的Transformer架构由两部分组成:一个是Transformer编码器,负责处理源序列;另一个是Transformer解码器(Transformer decoder),负责利用源序列生成翻译序列。我们很快会介绍关于解码器的内容。重要的是,编码器可用于文本分类—它是一个非常通用的模块,接收一个序列,并学习将其转换为更有用的表示。我们来实现一个Transformer编码器,并尝试将其应用于影评情感分类任务,如代码清单11-21所示。
代码清单11-21 将Transformer编码器实现为Layer子类
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim ←----输入词元向量的尺寸
self.dense_dim = dense_dim ←----内部密集层的尺寸
self.num_heads = num_heads ←----注意力头的个数
self.attention = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None): ←----在call()中进行计算
if mask is not None: ←---- (本行及以下1行) Embedding层生成的掩码是二维的,但注意力层的输入应该是三维或四维的,所以我们需要增加它的维数
mask = mask[:, tf.newaxis, :]
attention_output = self.attention(
inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self): ←----实现序列化,以便保存模型
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











