







函数式API的强大之处:获取层的连接方式
函数式模型是一种图数据结构。这便于我们查看层与层之间是如何连接的,并重复使用之前的图节点(层输出)作为新模型的一部分。它也很适合作为大多数研究人员在思考深度神经网络时使用的“思维模型”:由层构成的图。它有两个重要的用处:模型可视化与特征提取。我们来可视化上述模型的连接方式(模型的拓扑结构)。你可以用plot_model()将函数式模型绘制成图。
keras.utils.plot_model(model, "ticket_classifier.png")
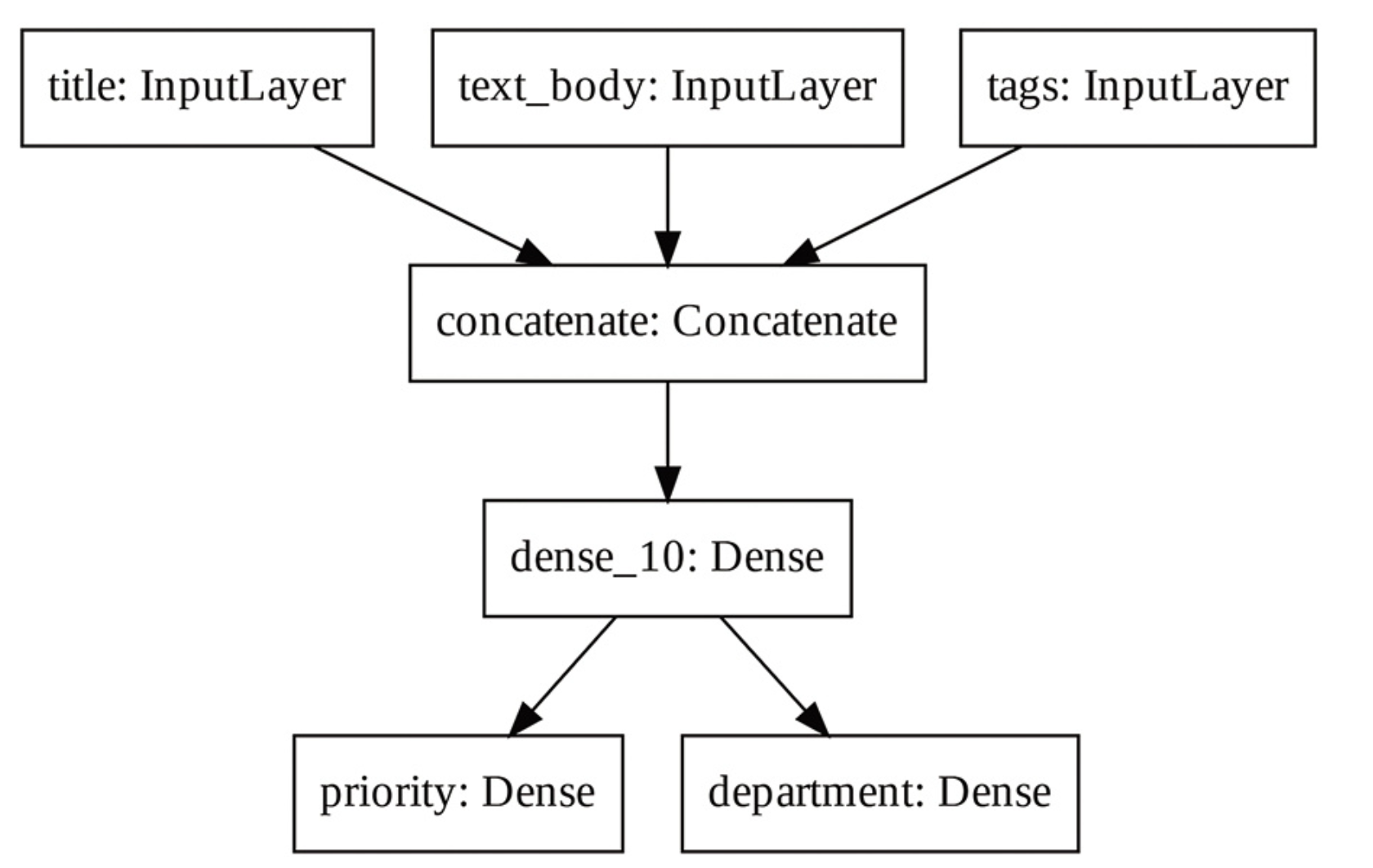
你可以将模型每一层的输入形状和输出形状添加到图中,这对调试很有帮助
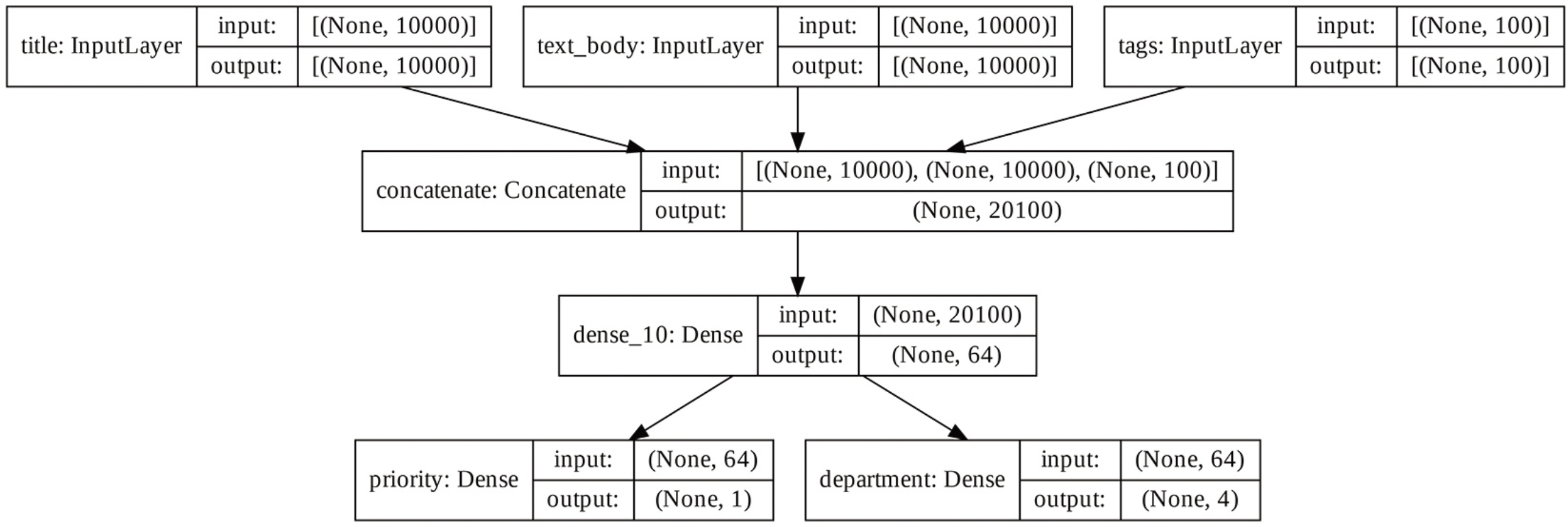
张量形状中的None表示批量大小,也就是说,该模型接收任意大小的批量。获取层的连接方式,意味着你可以查看并重复使用图中的节点(层调用)。模型属性model.layers给出了构成模型的层的列表。对于每一层,你都可以查询layer.input和layer. output。
>>> model.layers
[<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d358>,
<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d2e8>,
<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d470>,
<tensorflow.python.keras.layers.merge.Concatenate at 0x7fa963f9d860>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa964074390>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa963f9d898>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa963f95470>]
>>> model.layers[3].input
[<tf.Tensor "title:0" shape=(None, 10000) dtype=float32>,
<tf.Tensor "text_body:0" shape=(None, 10000) dtype=float32>,
<tf.Tensor "tags:0" shape=(None, 100) dtype=float32>]
>>> model.layers[3].output
<tf.Tensor "concatenate/concat:0" shape=(None, 20100) dtype=float32>
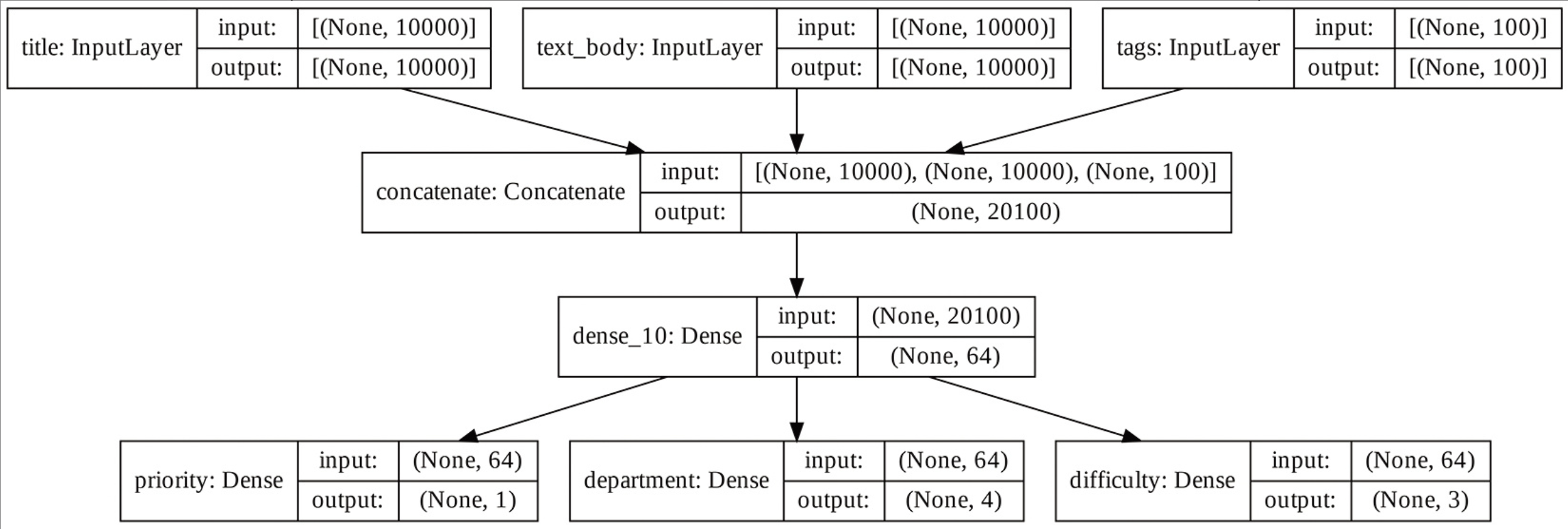
这样一来,我们就可以进行特征提取,重复使用模型的中间特征来创建新模型。假设你想对前一个模型增加一个输出—估算某个问题工单的解决时长,这是一种难度评分。实现方法是利用包含3个类别的分类层,这3个类别分别是“快速”“中等”和“困难”。你无须从头开始重新创建和训练模型。你可以从前一个模型的中间特征开始(这些中间特征是可以访问的。
代码清单 重复使用中间层的输出,创建一个新模型
features = model.layers[4].output # layers[4]是中间的Dense层
difficulty = layers.Dense(3, activation="softmax", name="difficulty")(features)
new_model = keras.Model(
inputs=[title, text_body, tags],
outputs=[priority, department, difficulty])
我们来绘制新模型的图。
keras.utils.plot_model(
new_model, "updated_ticket_classifier.png", show_shapes=True)
模型子类化
最后一种构建模型的方法是最高级的方法:模型子类化,也就是将Model类子类化。前面介绍过如何通过将Layer类子类化来创建自定义层,将Model类子类化的方法与其非常相似:在__init__()方法中,定义模型将使用的层;在call()方法中,定义模型的前向传播,重复使用之前创建的层;将子类实例化,并在数据上调用,从而创建权重。
将前一个例子重新实现为Model子类我们看一个简单的例子:使用Model子类重新实现客户支持工单管理模型。
代码清单 简单的子类化模型
class CustomerTicketModel(keras.Model):
def __init__(self, num_departments):
super().__init__() #不要忘记调用super()构造函数!
self.concat_layer = layers.Concatenate() #(本行及以下3行)在构造函数中定义子层
self.mixing_layer = layers.Dense(64, activation="relu")
self.priority_scorer = layers.Dense(1, activation="sigmoid")
self.department_classifier = layers.Dense(
num_departments, activation="softmax")
def call(self, inputs): #在call()方法中定义前向传播
title = inputs["title"]
text_body = inputs["text_body"]
tags = inputs["tags"]
features = self.concat_layer([title, text_body, tags])
features = self.mixing_layer(features)
priority = self.priority_scorer(features)
department = self.department_classifier(features)
return priority, department
定义好模型之后,就可以将模型实例化。请注意,只有第一次在数据上调用模型时,模型才会创建权重,就像Layer子类一样。
model = CustomerTicketModel(num_departments=4)
priority, department = model(
{"title": title_data, "text_body": text_body_data, "tags": tags_data})
到目前为止,一切看起来都与Layer子类化非常相似。那么,Layer子类和Model子类之间有什么区别呢?答案很简单:“层”是用来创建模型的组件,而“模型”是高阶对象,用于训练、导出进行推理等。简而言之,Model有fit()、evaluate()和predict()等方法,而Layer则没有。除此之外,这两个类几乎相同。(另一个区别是,你可以将模型保存为文件)你可以编译和训练Model子类,就像序贯模型或函数式模型一样。
model.compile(optimizer="rmsprop",
loss=["mean_squared_error", "categorical_crossentropy"], #(本行及以下1行)参数loss和metrics的结构必须与call()返回的内容完全匹配——这里是两个元素组成的列表
metrics=[["mean_absolute_error"], ["accuracy"]])
model.fit({"title": title_data, #(本行及以下2行)输入数据的结构必须与call()方法的输入完全匹配——这里是一个字典,字典的键是title、text_body和tags
"text_body": text_body_data,
"tags": tags_data},
[priority_data, department_data], #目标数据的结构必须与call()方法返回的内容完全匹配——这里是两个元素组成的列表
epochs=1)
model.evaluate({"title": title_data,
"text_body": text_body_data,
"tags": tags_data},
[priority_data, department_data])
priority_preds, department_preds = model.predict({"title": title_data,
"text_body": text_body_data,
"tags": tags_data})
模型子类化是最灵活的模型构建方法。它可以构建那些无法表示为层的有向无环图的模型,比如这样一个模型,其call()方法在for循环中使用层,甚至递归调用这些层。一切皆有可能,你说了算。注意:子类化模型不能做什么。这种自由是有代价的:对于子类化模型,你需要负责更多的模型逻辑,也就是说,你犯错的可能性会更大。因此,你需要做更多的调试工作。你开发的是一个新的Python对象,而不仅仅是将乐高积木拼在一起。函数式模型和子类化模型在本质上有很大区别。函数式模型是一种数据结构—它是由层构成的图,你可以查看、检查和修改它。子类化模型是一段字节码—它是带有call()方法的Python类,其中包含原始代码。这是子类化工作流程具有灵活性的原因—你可以编写任何想要的功能,但它引入了新的限制。举例来说,由于层与层之间的连接方式隐藏在call()方法中,因此你无法获取这些信息。调用summary()无法显示层的连接方式,利用plot_model()也无法绘制模型拓扑结构。同样,对于子类化模型,你也不能通过访问图的节点来做特征提取,因为根本就没有图。将模型实例化之后,前向传播就完全变成了黑盒子。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











