







我决定了要成为海贼王便要为此而战,我必须变的更强。———路飞
阶段1目标:
基本了解C语言语法,站在全局,避去晦涩难懂,鲜明梳理C语言基本概念,为算法竞赛等计算机专业比赛铺好道路。传统功夫讲究点到为止,此阶段仅点明语法知识,后续阶段再进一步精进学习。

目录
1.一维数组的创建和初始化
1.1什么是数组
数组是一组相同类型元素的集合。
1.2数组的创建
数组的创建方式:
type_t arr_name [const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小素组创建的实例:
//代码1
int arr1[10];
//代码2
int count = 10;
int arr2[count];//数组是否可以正常创建?
//代码3
char arr3[10];
float arr4[1];
double arr5[20];代码2解释:
代码2称为变长数组,C99之前不允许这样在数组中放变量,C99以后可以使用变长数组。
注意:数组创建, [ ] 中要给一个常量才可以,不能使用变量。
1.3数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
下面给出代码,不一定正确,先来思考这几个初始化代码的区别:
int arr1[20] = { 1,2,3 };
int arr2[] = { 1,2,3 };
int arr3[3] = { 1,2,3,4,5 };
char arr4[] = { 'a','b','c' };
char arr5[] = "abc";
char arr6[] = { 'a',98,'c' };#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
int arr1[20] = { 1,2,3 };//不完全初始化,剩余的默认初始化都是0
int arr2[] = { 1,2,3 };//可以继续续写数组内容
int arr3[3] = { 1,2,3,4,5 };//报错,超出数组元素范围
char arr4[] = { 'a','b','c' };//只存3个字符abc
char arr5[] = "abc";//有abc\0
char arr6[] = { 'a',98,'c' };//默认会把98当成char类型的,即:‘b’
return 0;
}数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
但是对于下面的代码要区分,内存中如何分配。
char arr4[] = { 'a','b','c' };
char arr5[] = "abc";2.一维数组的使用
对于数组的使用我们之前介绍了一个操作符: [ ] ,下标引用操作符。它其实就数组访问的操作符。 我们来看代码:
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
int arr[10] = { 0 };//数组的不完全初始化
//计算数组的元素个数
int sz = sizeof(arr) / sizeof(arr[0]);
//对数组内容赋值,数组是使用下标来访问的,下标从0开始。所以:
int i = 0;//做下标
for (i = 0; i < 10; i++)//这里写10,好不好?肯定不好,代码不够灵活,应该换成sz
{
arr[i] = i;
}
//输出数组的内容
for (i = 0; i < 10; ++i)
{
printf("%d ", arr[i]);
}
return 0;
}总结:
- 数组是使用下标来访问的,下标是从0开始。
- 数组的大小可以通过计算得到。( int sz = sizeof(arr) / sizeof(arr[0]); )
3.一维数组在内存中的存储
我们来讲解数组在内存中的存储,先上代码,思考输出结果并试想一下,为何会出现这种输出结果?
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//计算数组的元素个数
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
//输出数组元素的地址
for (i = 0; i < sz; ++i)
{
printf("%p\n", &arr[i]);
}
return 0;
}
我们看到,arr数组的地址,CC—>D0—>D4—>...我们可以明确的看到,数组中的每个地址之间都是差4【内存是16进制】【地址仅仅是编号而已,和 地址本身没有关系】

地址之间差4,说明,第一个数据的地址和第二个数据的地址之间,差4,即:该数据占4个字节
说明:
- 数组在内存中是连续存放的。
- 数据随着下标增长,地址是由低到高的。
4.二维数组的创建和初始化
4.1二维数组的创建
//数组创建
int arr[3][5];
char arr[3][5];
double arr[3][5];4.2二维数组的初始化
//数组初始化
int arr[3][5] = {1,2,3,4,5,6,7,8,9,10,11};
int arr[3][5] = {{1,2},{3,4},{5,6}};
int arr[][5] = {{1,2},{3,4},{5,6}};从狭义来看,二维数组可以理解为几行几列的数组,也可以理解为几行一维数组组合而成,即:


注意:
- 二维数组可以理解为xx行一维数组组合而成的数组。
- 二维数组中行数可以省略,列数不可以省略。
- 二维数组中,列数不足的空自动补0。(各种数据类型都一样)
那再来看看char类型的
char arr1[4][6] = { 'a','b','c' };
char arr2[4][6] = { {'a'},{'b'} };
char arr3[4][6] = { "abc","def","qwe" };
图解:
arr2[4][6]图解画错了,感谢弦鱼要上岸指正~
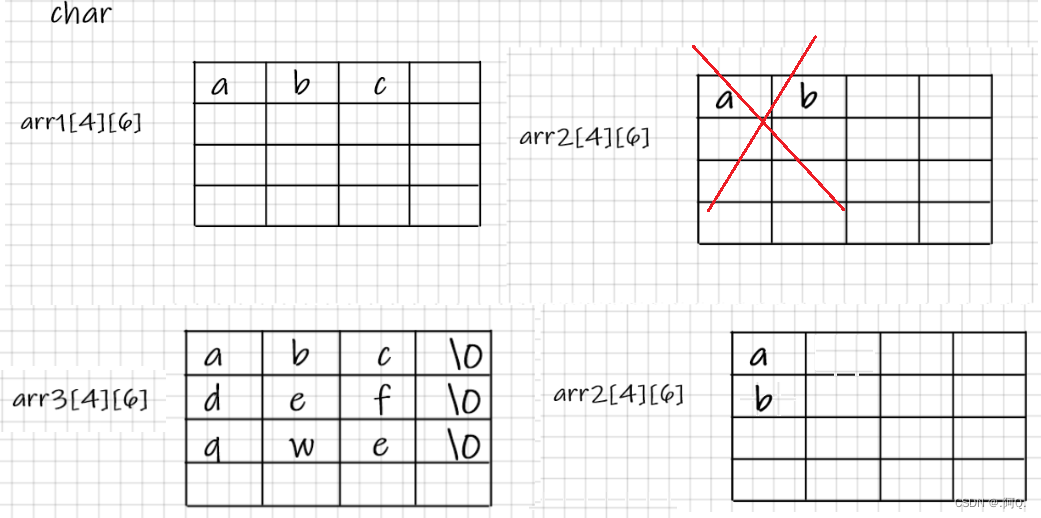
解释
图解中的空格子,可以理解为放了0,或者\0(此数据类型是char),【‘0’—>48,‘\0’—>0,0—>0】
5.二维数组的使用
二维数组的使用也是通过下标访问的方式来进行的。见代码:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main() {
int arr[3][5] = { {1,2,3},{4,5},{6,7,8,9} };
int i = 0;//行
for (i = 0; i < 3; i++) {
int j = 0;//列
for (j = 0; j < 5; j++) {
printf("arr[%d][%d]=%d ", i, j, arr[i][j]);
}
printf("\n");
}
return 0;
}6.二维数组在内存中的存储
我们尝试打印一下二维数组的每个元素的地址。
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main() {
int arr[3][5] = { {1,2,3},{4,5},{6,7,8,9} };
int i = 0;//行
for (i = 0; i < 3; i++) {
int j = 0;//列
for (j = 0; j < 5; j++) {
printf("arr[%d][%d]=%p\n", i, j, &arr[i][j]);
}
}
return 0;
}
我们看出,打印的地址之间都是差值是4,就算是不同行的数组元素之间地址差值也是4,那么我们可能会想了,二维数组不是xx行yy列的吗?
一行中数组元素之间差值是4我能理解,那跨行处的地址差值也是4该怎么解释呢??难道说,二维数组不是xx行yy列的形式存储的??
没错,我们可以把二维数组想象成的xx行yy列,方便我们理解和计算等,但是实际上二维数组在内存中的存储形式,却是连续存储的,比如:

这样的话,我们也能够反向的说明,二维数组中的行数为啥可以省略,列数不能省略的原因了:
本质上的二维数组是连续存放的,即:默认二维数组就是一行来存储,所以可以不说行数;而如果不指明列数,那么存放的数据到哪结束,然后继续填下一个呢?
实际上我们还可以这样理解:
(1)arr[3][5]可以理解为:二维数组arr有3个元素,每个元素是一个一维数组.

(2)arr[3][5]是一个含有15个元素的很长的一维数组【脑回路清奇,也未尝不可(dog.jpg)】

上代码深刻理解:
先来举出一维数组地址访问元素的代码
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main() {
int arr[5] = { 1,2,3,4,5 };
int* p = arr;//首元素地址
int i = 0;
for (i = 0; i < 5; i++) {
printf("%d\n", *p);//*p等价于arr[i]
p++;
}
return 0;
}同样的,二维数组可以理解成一段很长的一维数组,同样可以使用这种方式来验证一下是否二维数组是在内存中连续存放的。
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main() {
int arr[3][5] = { {1,2,3},{4,5},{6,7,8,9} };
int* p = &arr[0][0];//首元素地址
int i = 0;
for (i = 0; i < 15; i++) {
printf("%d ", *p);
p++;
}
return 0;
}
由运行结果可以看出,我们可以把二维数组理解成很长的一维数组,通过下标来访问每个元素。
7.数组作为函数参数
往往我们在写代码的时候,会将数组作为参数传给函数,比如:我要实现一个冒泡排序(这里要讲算法思想)函数将一个整形数组排序。 那我们将会这样使用该函数:
7.1冒泡排序函数的错误设计:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
void Sort(int arr[]) {
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;//冒泡排序的趟数
for (i = 0; i <= sz - 1; i++) {
int j = 0;//一趟冒泡排序的过程
for (j = 0; j <sz-1-i ; j++) {
if (arr[j] > arr[j + 1]) {
int temp = 0;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main() {
int arr[] = { 1,4,2,6,3,8,10,9,5,7,6 };
Sort(arr);//用于排序(实现升序)
//Print(arr);//用于打印
return 0;
}调试监视一下发现:

我们可以发现,sz的值变成了1,????我们传的是数组,应该sz会是数组元素的个数10个啊,为啥会变成1了呢??
解释:
在数组传参的时候,数组会退化成指针,即:
//本质上是void Sort(int* arr),只不过,我们想着用数组传递,也用数组接受,方便初学者看,所以才写成这样,最后误导了自己
void Sort(int arr[])
而
int sz = sizeof(arr) / sizeof(arr[0]);中的sizeof(arr)是对指针类型int* arr进行计算长度,而不是数组arr,所以sizeof(arr)计算出来就是4,则sizeof(arr) / sizeof(arr[0])=4/4,即:sz=1
【32位平台下指针所占4个字节,64为平台下指针所占8个字节】
那么该如何书写正确的计算代码呢?
7.2冒泡排序函数的正确设计:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
void Sort(int* arr,int sz) {
int i = 0;
//冒泡排序的趟数
for (i = 0; i < sz - 1; i++) {
int j = 0;
//一趟冒泡排序的过程
for (j = 0; j < sz - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
//交换
int temp = 0;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
void Print(int* arr,int sz) {
int i = 0;
for (i = 0; i < sz; i++) {
//printf("%d ", arr[i]);方法1
printf("%d ", *arr);//方法2
arr++;
}
}
int main() {
int arr[] = { 1,4,2,6,3,8,10,9,5,7};
int sz = sizeof(arr) / sizeof(arr[0]);
Sort(arr,sz);//用于排序(实现升序)
Print(arr,sz);//用于打印
return 0;
}说明:将int sz = sizeof(arr) / sizeof(arr[0]);放在main函数中,再用sz作为参数传过去

总结:
- 数组名在传参的时候,数组会降级变成首元素的地址,即:指针。 (在数组传参的时候,数组会退化成指针)
- 在刚刚的main函数中,数组名单独放在sizeof内部的话,如:sizeof(arr),这里的arr表示整个数组,不是首元素地址
- 在刚刚的Sort函数的错误设计中,sizeof(arr),这里的arr表示的是指针
拓展:
我们再细想一下,其实我们的排序算法效率并不高,就拿一个原本就是升序的一列数来说:1,2,3,4,5,6,7,8,9,10,进入Sort函数以后第一趟发现没有任何交换,那么就没有必要继续进行下一轮的比较了,直接跳出Sort函数即可,节省了大量时间,提高了效率!!
所以我们可以这样精进优化代码:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
void Sort(int* arr,int sz) {
int i = 0;
//冒泡排序的趟数
for (i = 0; i < sz - 1; i++) {
int j = 0;
int flag = 1;
//一趟冒泡排序的过程
for (j = 0; j < sz - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
//交换
int temp = 0;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = 0;
}
}
if (flag == 1) {
break;
}
}
}
void Print(int* arr,int sz) {
int i = 0;
for (i = 0; i < sz; i++) {
//printf("%d ", arr[i]);方法1
printf("%d ", *arr);//方法2
arr++;
}
}
int main() {
int arr[] = { 1,4,2,6,3,8,10,9,5,7};
int sz = sizeof(arr) / sizeof(arr[0]);
Sort(arr,sz);//用于排序(实现升序)
Print(arr,sz);//用于打印
return 0;
}小总结
一般情况下,数组名就是首元素的地址,但是也有2个例外:
- sizeof(数组名),这里的数组名表示整个数组,sizeof(数组名)计算的是整个数组的大小。
- &数组名,这里的数组名表示整个数组,取出的是数组的地址。
仔细比对如下的代码:
printf("%p\n", arr);//代码1
printf("%p\n", &arr[0]);//代码2
printf("%p\n", &arr);//代码3代码1,代码2表示数组首元素的地址,代码3表示数组的地址。两者大不一样!!!


















 2196
2196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











