






简介:达梦数据复制(DATA REPLICATION)是一个分担系统访问压力、加快异地访问响应速度、提高数据可靠性的解决方案。功能:将一个服务器实例上的数据变更复制到另外的服务器实例。应用场景:可以用于解决大、中型应用中出现的因来自不同地域、不同部门、不同类型的数据访问请求导致数据库服务器超负荷运行、网络阻塞、远程用户的数据响应迟缓的问题。
一.基本概念
1.主服务器
发起复制操作的服务器,称为主服务器。
2.从服务器
接收主服务器发送的数据并进行复制的服务器,称为从服务器。
3.复制服务器(RPS)
在数据复制环境中,负责配置复制环境,定义复制关系的服务器。RPS有且仅有一台,它只负责配置和监控,并不参与到复制过程中。
4.复制节点
涉及到复制的服务器,主服务和从服务的统称。一个节点既可以是主服务器也可以是从服务器。
5.复制关系
复制关系指明主服务器和从服务器以何种方式进行复制。按照复制的方式,复制关系分为同步复制和异步复制。
6.同步复制关系
主服务器数据更新立即复制到从服务器。
7.异步复制关系
主服务器和从服务器在某段时间内数据可能是不同的,主服务器数据更新不会立刻同步到从服务器,而是在经过一段时间后才进行复制。异步复制的同步时机由指定的定时器确定。
8.逻辑日志
记录产生数据变化的逻辑操作的日志。记录的逻辑操作包括INSERT、UPDATE、DELETE、TRUNCATE、ROLLBACK和COMMIT等。
9.复制源对象
主服务器上作为复制数据源的对象,可以是库、模式或表。在该对象上的操作都会被记录成逻辑日志,发送给从服务器进行复制操作。
10.复制目标对象
从服务器上作为复制数据目标的对象。从服务器接收到逻辑日志后,将复制源对象的变化复制到复制目标对象中。
11.复制对象映射
一对复制源对象和复制目标对象构成一个复制对象映射。构成映射的源对象和目标对象必须是同一类型的对象。根据对象的类型,复制映射分为库级、模式级和表级三个级别。其中表级要求源表和目标表结构完全一致,库级和模式级没有要求。库级和模式级复制映射会将其DDL也进行复制。复制映射包括只读模式和非只读模式。对于只读模式的映射,映射的目的表禁止用户更新。
12.复制组
一组逻辑相关的复制关系可以构造成为复制组。通过复制组,可以构造出一对多复制、多对一复制、级联复制、对称复制、循环复制等复杂的逻辑复制环境。
二.规划和配置


dmmal.ini文件(三个服务器一样,放在/home/dmdba/dmdbms/data/DAMENG下)
MAL_CHECK_INTERVAL = 5
MAL_CONN_FAIL_INTERVAL = 5
[MAL_INST1]
MAL_INST_NAME = DM
MAL_HOST = 192.168.100.104
MAL_PORT = 5241
MAL_INST_PORT = 5236
MAL_INST_HOST = 192.168.100.104
[MAL_INST2]
MAL_INST_NAME = DM01
MAL_HOST = 192.168.100.105
MAL_PORT = 5242
MAL_INST_PORT = 5236
MAL_INST_HOST = 192.168.100.105
[MAL_INST3]
MAL_INST_NAME = DM02
MAL_HOST = 192.168.100.106
MAL_PORT = 5243
MAL_INST_PORT = 5236
MAL_INST_HOST = 192.168.100.106
三.创建复制组
1.右键创建数据复制环境
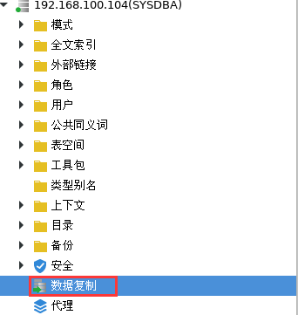
2.右键新建复制组

3.填写名字确定

4.在创建的复制组右键新建复制
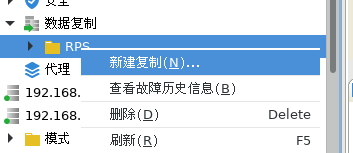
5.填写主从实例名称和归档路径

6.新建复制表映射

7.填写主服务器的模式名表名和从服务器对应的模式名表名,选择只读

8.点击确定后成功创建从192.168.100.105 SYSDBA下TEST1表到192.168.100.106 USER1下TEST2表的复制表映射
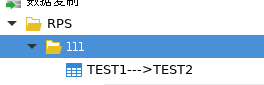
四.只读测试
1.Insert对比
192.168.100.105 SYSDBA下TEST1添加一行数据
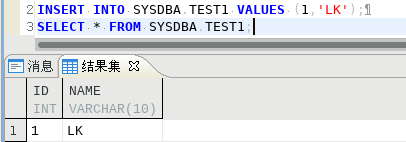
192.168.100.106 USER1下TEST2查询
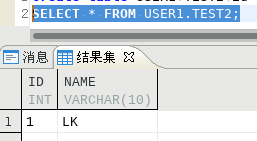
只读模式下TEST2表添加数据报错

192.168.100.105 SYSDBA下TEST1添加4行数据

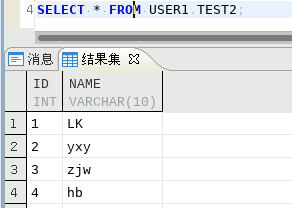
192.168.100.106 USER1下TEST2查询

2.delete对比
192.168.100.105 SYSDBA下TEST1删除1行数据

192.168.100.106 USER1下TEST2查询
只读模式下,TEST2删除数据报错

3.Update对比
192.168.100.105 SYSDBA下TEST1修改一行数据

192.168.100.106 USER1下TEST2查询


总结,只读模式下,从服务器的表能够同步且不能够进行添加,修改,删除操作.
五.非只读测试
在创建复制表映射的时候,只读选择否

1.
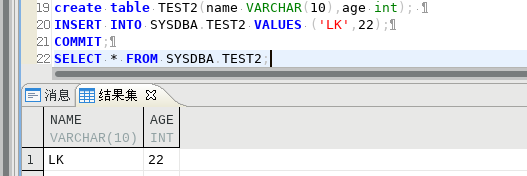
192.168.100.105表TEST2插入一条数据
192.168.100.106表TEST3可以查到
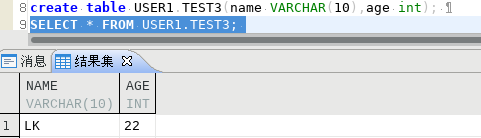
192.168.100.106表TEST3可以自己插入数据

192.168.100.105表TEST2在插入一条数据

192.168.100.106表TEST3查询,数据没有同步第二条数据为自己创建的

192.168.100.105表TEST2重新插入两条数据

192.168.100.106表TEST3查询,然后删后两条数据

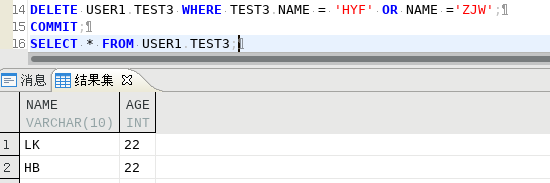
192.168.100.105表TEST2重新插入一条数据

192.168.100.106表TEST3查询

总结,非只读模式下从服务器的表能够进行修改,修改后不能同步,比如从表第一行先添加一条数据,则主表是从第二条开始同步的(第一条数据不会同步),从表添加,修改的那行数据不会同步.
六.命令方式
创建环境
SP_INIT_REP_SYS(1);
创建复制组
call SP_RPS_ADD_GROUP(‘RPS’,’’);
创建复制
call SP_RPS_SET_BEGIN(‘RPS’);
call SP_RPS_ADD_REPLICATION(‘RPS’,‘111’,’’,‘DM01’,‘DM02’,NULL,’/home/dmdba/dmdbms/data/DAMENG/arch’);
call SP_RPS_SET_APPLY();
创建复制表映射
call SP_RPS_SET_BEGIN(‘RPS’);
call SP_RPS_ADD_TAB_MAP(‘111’,‘SYSDBA’,‘TEST1’,‘USER1’,‘TEST2’,1);
call SP_RPS_SET_APPLY();
更多更详细的内容可以到达梦技术社区:https://eco.dameng.com学习.














 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









