







文章目录
- 一:Elasticsearch前言
- 二:在win10安装Elasticsearch
- 三:Elasticsearch入门
- 四:Elasticsearch的基础分布式架构
- 五:Elasticsearch入门(第二章)
- 六:Elasticsearch进阶
- 6.1排序(文本排序)
- 6.1TF/IDF算法(非常重要)
- 6.1document数据的写入
- 6.3 term
- 6.4 terms
- 6.5mush & must_not & should
- 6.6range
- 6.7 match
- 6.8 boost
- 6.9 negative
- 6.10dis_max
- 6.11 multi_match
- 6.12 best_fields、most_fields、cross_fields策略
- 6.13 match_phrase
- 6.14 混合使用实现 召回率 精准度的平衡
- 6.14 前缀搜索
- 6.15 通配符搜索
- 6.16 正则表达式
- 6.17 推荐搜索
- 6.18 理论
- 6.19 fuzzy
- 6.20 ik分词器
- 6.21 bucket与metric
- 6.21.1 统计最高销量
- 6.21.2 统计最高销量 and 计算平均值
- 6.21.3 统计最高销量 and 电视型号 and 计算平均值
- 6.21.4 最大值&最小值&平均值
- 6.21.5 统计范围区间
- 6.21.6 按照日期统计
- 6.21.6 按照日期统计每个季度的品牌营业额
- 6.21.7 统计指定品牌下的营业额
- 6.21.7 统计指定品牌下的营业额与总营业额
- 6.21.8 过滤&聚合
- 6.21.9 统计指定品牌的最近一个月总额度
- 6.21.10 统计颜色的平均价格然后排序
- 6.21.11 统计颜色的平均价格和品牌的平均价格然后排序
- 6.21.12季度品牌祛重
- 6.21.12 cardinality性能优化
- 6.21.13 百分比算法
- 6.21.13 聚合分析的实现原理
- 6.21.14 分词field+fielddata
- 6.21.14 集合操作最终章 优化
- 6.22 es数据模型
- 6.23 (高手进阶) 高亮显示
- 6.24(高手进阶) search temolate
- 6.25 (高手进阶) completion suggest
- 6.25 (高手进阶) 地理位置(gen point)
- 七:JAVA代码 操作Elasticsearch
- 八 虚拟机安装es
文档
所需资料
1c5v
Elasticsearch,分布式,高性能,高可用,可伸缩的搜索和分析系统
需要了解:
1.什么是搜索?
2.如果用数据库做搜索会怎么样?
3.什么是全文搜索和Lucene?
4.什么是Elasticsearch?
一:Elasticsearch前言
1.1:什么是搜索?
百度:比如我们想找寻任何信息的时候,就回去百度上搜索一下,比如找一部自己喜欢的电影,或者找一本喜欢的书,或者搜寻一条新闻(提到搜索的第一印象)
但是 ,百度!=搜索
垂直搜索(站内搜索)
互联网的搜索:电商网站,招聘网站,新闻网站,各种APP
IT系统的搜索:OA软件,办公自动化软件,会议管理,员工搜索等,假设有个电商的后台管理,卖家搜索牙膏,会搜索出牙膏相关的订单
简而言之:就是在任何场景下,寻找你想要的数据,这个时候,你输入一段搜索的关键词, 期望找到关键词有关的信息
1.2:如果用数据库做搜索会怎么样?
做软件开发的话,或者对IT,计算机有一定的了解,就会明白数据是存储在数据库里面,比如说电商网站的招聘信息,招聘网站的职位信息,新闻网站的职位信息,等等。
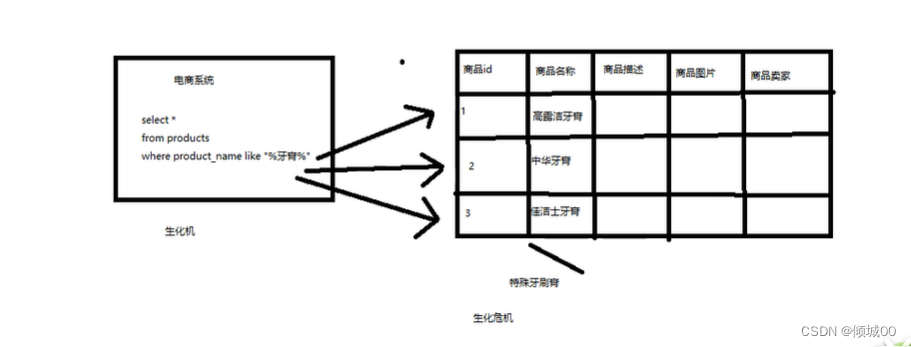
如上图可以看到,这是一个商品表,不考虑索引等元素,我们去执行sql语句去查找,效率非常的慢
1.如果说商品描述对这个字段的的长度,有长达数千个数万个字符的时候,我们每次都要对条记录的文本去扫描,在简单就说,你这个数据里面包不包含“牙膏”这个关键词
2:不能将搜索词条拆分开来,尽可能的更多去搜索你期望的结果,比如存入的数据是“生化危机”,我们输入的是“生化危”就搜索不出来数据,
3.我们通常百度的时候搜索Elasticseara,注意看这个单词,这是个错误拼写的单词,但是我们还是会搜到Elasticsearch这个正确的,这个在数据库是无法实现的,名词(自动矫正)
总结:用数据库来实现搜索,是不太靠谱的,性能会很差
1.3:什么是全文搜索和Lucene?
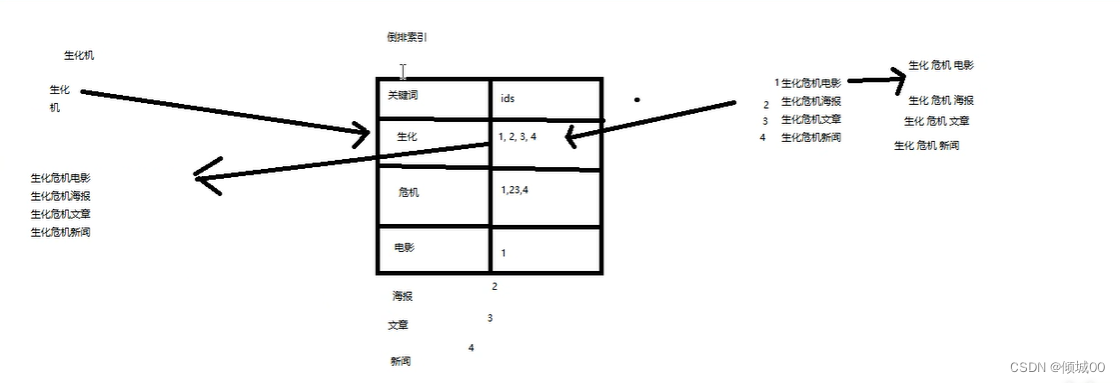
1.3.1:全文检索
如上图,我们有4条数据
id为1 内容为生化危机电影
id为2 内容为生化危机海报
id为3 内容为生化危机文章
id为4 内容为生化危机新闻
我们将每一个数据去进行一个拆分,拆分出来的数据是
id为1 内容为生化危机电影 ------------>拆分为 生化-危机-电影,这三个词
id为2 内容为生化危机海报 ------------>拆分为 生化-危机-海报,这三个词
id为3 内容为生化危机文章 ------------>拆分为 生化-危机-文章,这三个词
id为4 内容为生化危机新闻 ------------>拆分为 生化-危机-新闻,这三个词
然后将他们放入到索引之中
我们下面是一个表关键字 -------id
生化---------1,2,3,4
危机---------1,2,3,4
电影---------1
海报---------2
文章---------3
新闻---------4这个索引表被称之倒排索引,我们想要搜索的内容是“生化机”这三个字,会进行拆分
生化机--------->拆分成 生化-机,这两个词
我们去倒排索引中去寻找发现生化这个词语,对应的id是1,2,3,4,我们通过这个id就可以拿到 ,生化危机电影,生化危机海报,生化危机文章,生化危机新闻,我们就可以拿到了数据
上述过程叫做全文检索
数据库里的数据,一共有100万条,按照之前的思路,需要扫描100万次,而且每次扫描到,都需要匹文本所有的字符,确保是否搜索的关键词,而且不能将搜索词拆开进行检索
利用倒排索引,就行搜索的话,假设有100万条数据,拆分出来的词语,假设有1000个词语,我们可能不需要检索1000万次,,有可能在搜索到第一次的时候就找到了对应的数据,也可能是第100次或者1000次
1.3.2:Lucene
Lucene就是一个jar包,里面包含封装好的各种建立倒排索引,以及进行搜索的代码,包括各种算法,我们用Lucene开发的时候,引入Lucene.jar,然后基于Lucene去进行开发,使用Lucene我们就可以将已有的数据去建立索引,Lucene会在本地磁盘上给我们组织索引的数据结构,另外,我们可以使用Lucene提供的API来针对磁盘上的索引数据,进行搜索。
1.4:什么是Elasticsearch?
我们用Lucene去封装了搜索引擎的功能,部署在单台服务器上的,假设磁盘空间是500个g的空间
假设我们有1T 的数据,数据量很大,我们一台机器是放不下的,我们肯定要搞2台,上面都有Lucene,那么我们整个系统就是分布式,散落在多态服务器。前端的一个电商网站进行搜索,我们肯定要考虑和哪台机器进行通信,跟多台机器通信的过程会很麻烦
我们想要实现数据不丢失和系统的高可用,每个Lucene放了500个g,假设一个Lucene宕机了,这500g的数据突然就没了,如果说数据量很大,超过了单台机器承受的范围,就必须用多条机器去进行存储的搜索,很麻烦
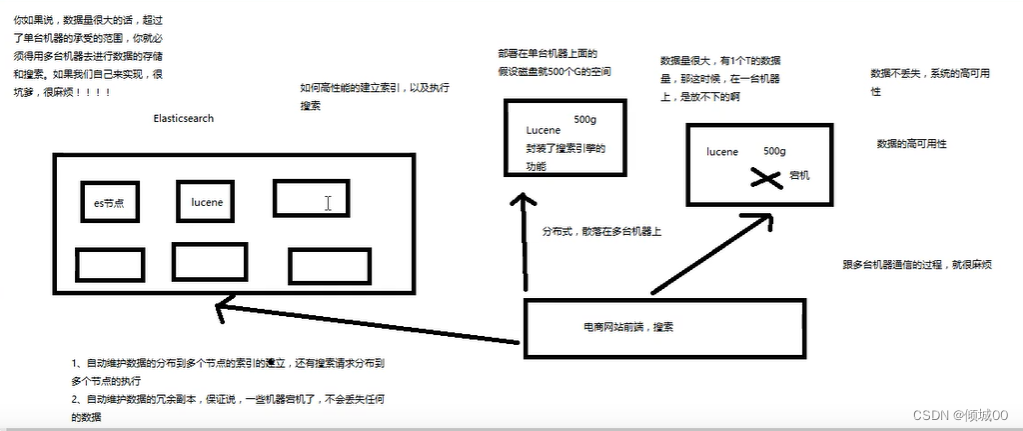
于是在这种环境下Elasticsearch就诞生了,Elasticsearch会建立很多的节点,可以去建立Elasticsearch的集群,每一个Elasticsearch的节点都封装了Lucene,数据的存储到了Elasticsearch集群中,他会自己管理说如何去分散到多个节点上去,当一个搜索过来的时候 会进行一个透明的处理,怎么把这个请求分布在各个节点上去,最后将结果汇总,封装起来统一的返回,这样就避免了和多台机器的通信,第二点es中会有很多副本 扩容的机制,部分机器宕机之后,保证数据不会丢失
es的特点和优点
1.自动维护数据的分布到多个节点的索引建立,还有搜索请求到多个节点去执行
2.自动维护数据的副本,保证一个机器宕机了,数据不会丢失
3.封装了更多高级的功能,给我们提供了更多高级的技术支持,让我们快速的开发应用 ,开发更加复杂的应用复杂的搜索功能,聚合分析的功能,基于地理位置的搜索(距离我当前位置1公里的烤肉店)
1.4.1Elasticsearch的功能
(1)分布式的搜索引擎和数据分析
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近7天牙膏销量排名前100的商家有哪些;新闻网站,最近1个月的访问排名前三的板块
分布式,搜索,数据分析
(2)全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称含有牙膏的商品:select * from products where p_name like “%牙膏%”
结构化搜索:我想搜索商品分类为日用的数据有哪些:select * from products where category_id=“日用”
数据分析:分析每一个商品id下有多少个商品:select category_id,count(*) from products groub by category_id
还有部分匹配,自动完成,搜索纠错,搜索推荐等等
(3)对海量数据记性近实时处理
分布式:es自动可以将海量数据分散到多台服务器上去存储和检索
海量数据的处理:分布式以后,就可以采用大量的服务器去存储的检索数据,就可以实现海量数据的处理
近实时:检索数据要花一个小时(这不是近实时),在秒级别对数据进行操作和分析
1.4.2Elasticsearch的特点
(1)可以作为一个大型分布式集群,(数百台服务器)技术,处理PB级数据,服务大公司,也可以运行在单击上,服务小公司
(2)Elasticsearc并不是全新的技术,它是将全文检索,数据分析,以及分布式分布式技术,结合在了一起,才形成一个独一无二的Elasticsearc
(3)对于用户而言,是开箱即用的非常简单,作为中小型的应用,直接3分钟部署一下es,就可以作为生产环境来使用了,数据量不大,操作不复杂,
(4)数据库的功能面对很多的领域是不够用的(事务,还有各种联机事务的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,海量数据的实时处理,Elasticsearc作为传统数据库的一个补充,提供了数据库所不能提供的很多功能
1.4.3Elasticsearch和Lucene的前世今生
Lucene是最先进,功能最强大的数据库,直接基于Lucene开发,非常的复杂,api复杂(实现一些简单的功能需要写大量的代码),需要深入理解其原理(各种索引结构)
Elasticsearc是基于Lucene开发的,隐藏其复杂性,提供简单易用的restfui,api接口,java api接口(还有其他语言的api接口)
(1)分布式的文档存储引擎
(2)分布式的搜索引擎和分析引擎
(3)分布式,支持PB级数据
开箱即用,优秀的默认参数,不需要任何额外的设置,完全开源
关于Elasticsearch的故事:
有一个程序员失业了,陪着自己的老婆去英国伦敦去学习厨师课程,程序员在失业期间想给自己的老婆写一个菜谱的搜索引擎,觉得Lucene太复杂了,就开发了一个封装了Lucene的开源项目,compass,后来程序员找到了工作,是做分布式高性能项目的,觉得compass不够,就写了Elasticsearch,让Lucene变成分布式的项目
1.4.3Elasticsearch的核心概念
(1)Near Realtime (NRT)近实时,两个意思,从写入数据到数据被搜索有一个延迟,大概1s,基于es执行搜索的分析可以达到秒级
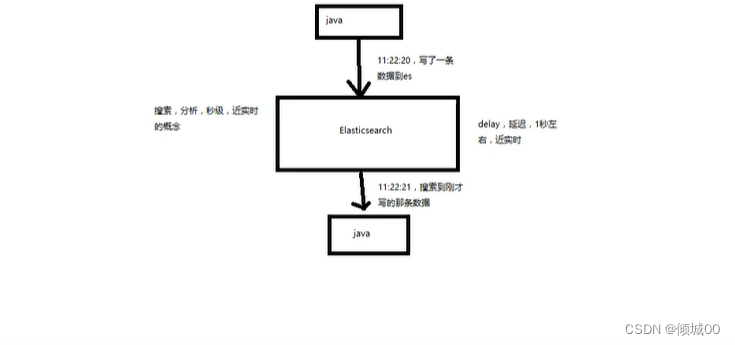
(2)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是Elasticsearc)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node:节点,集群中的一个节点,节点也有一个名称,(默认是随机分配的)节点名称很重要,(在执行运维管理操作的时候)。默认会去加入一个名称为Elasticsearc的集群,如果直接启动一堆节点,那么他们会自动组成一个Elasticsearc集群
(4)Document&fieid:文档,es中最小存储单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用json数据结构表示,每个index下的type都可以去存储多个document,一个docunemt里面有多个field,每个field就是一个数据字段
(5)index :索引,包含一堆有相思结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引都有一个名称,一个index包含了很多的document,一个index代表了一类类似的或者相同的document
(6)Type:类型,每个索引里都可以有一个或者多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field
(7)shard:单台机器无法存储大量的数据,es可以将一个索引的数据分为多个shard,分布在多态服务器上存储,有个shard可以横向扩展,存储更多的数据,让搜索和分析等操作到多台服务器上去执行,提升吞吐量和性能
我们下面是一个Elasticsearc集群,集群里面有多个节点,假设有一条index,需要占用3T,都放在一个节点上肯定不显示,那么就将每一个节点上均分开来,每一个节点上1T,每一个节点就是一个shard,如果数据量上涨了,增加到了4T,我们只需要在添加一个shard即可,再者说,我们的一个服务器吞吐量是2000/s,那么我们将数据均匀的分散到多个服务器,一个2000,4个就是8000/s,吞吐量也会有所提升
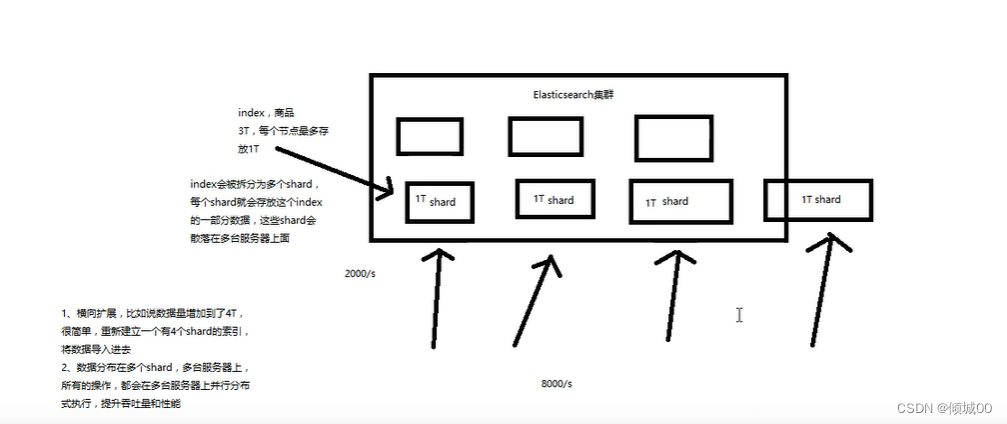
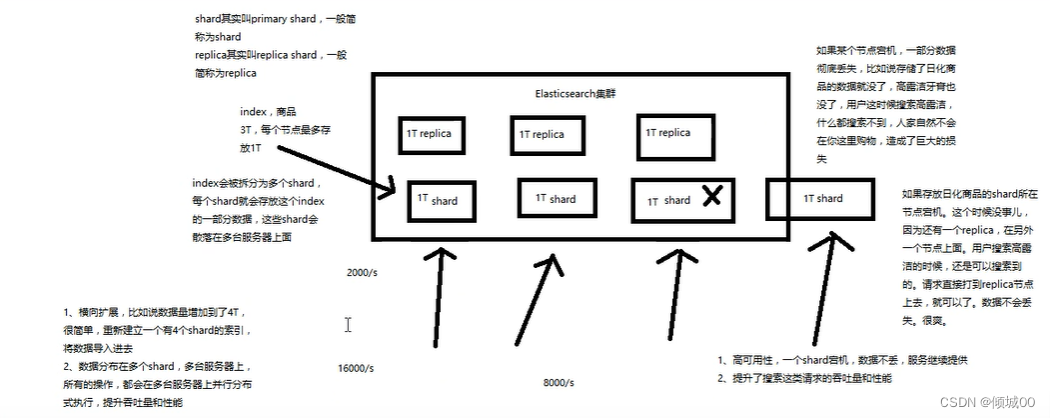
(8)replica。任何一个服务器随时可能故障或者宕机,此时shard可能会丢失,因此可以为每个shard创建多个replica副本,replica可以再shard故障的时候提供备用服务,保证数据不会丢失,多个replica会提高搜索操作的吞吐量和性能,primary shard
(简历索引时一次修改,默认5个),replica shard(随时修改,默认1个)
二:在win10安装Elasticsearch
1.安装JDK,1.8版本以上,因为我们演示用的Elasticsearc版本用的是7.8,已经内置了JDK,就不需要去安装了
2.下载和解压缩Elasticsearc安装包,
3.启动Elasticsearch:bin\elasticsearch.bat
4.检查es是否启动成功
5.下载和解压缩Kibana安装包
6.启动Kibana:bin\Kibana.bat
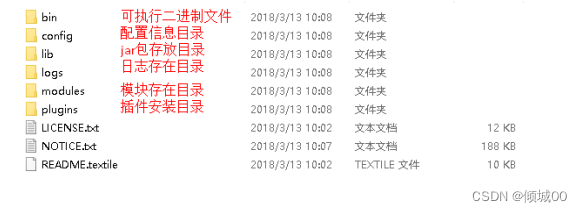
2.1Elasticsearch的目录结构
打开lib介意仔细的看到,有很多的jar包,主要是依赖Lucene
2.1启动Elasticsearch
手动启动,进入到bin目录下找到elasticsearch.bat,双击即可启动,es的本身特点之一就是开箱即用,如果是中小型应用,数据量少,操作不是很复杂直接就可以用了
检查是否启动成功:在浏览器上输入http://127.0.0.1:9200/ 如果看到如下网页,说明启动成功
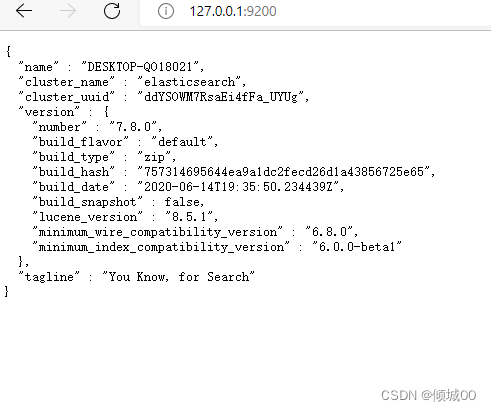
以下是返回的数据
{
“name” : “DESKTOP-QO18021”, ---------------------node名称
“cluster_name” : “elasticsearch”,------------------------集群名称(默认的集群名称就是elasticsearch)
“cluster_uuid” : “ddYSOWM7RsaEi4fFa_UYUg”,
“version” : {
“number” : “7.8.0”, ------------------------------版本号
“build_flavor” : “default”,
“build_type” : “zip”,
“build_hash” : “757314695644ea9a1dc2fecd26d1a43856725e65”,
“build_date” : “2020-06-14T19:35:50.234439Z”,
“build_snapshot” : false,
“lucene_version” : “8.5.1”,
“minimum_wire_compatibility_version” : “6.8.0”,
“minimum_index_compatibility_version” : “6.0.0-beta1”
},
“tagline” : “You Know, for Search”
}
2.3安装kibana
把压缩包解压缩,进入bin目录去执行kibana.bat文件即可启动成功,kibana这个可以理解为一个可视化图形界面,更便捷的去操作数据,浏览器输入http://127.0.0.1:5601/ ,展示如下页面即成功
三:Elasticsearch入门
浏览网址输入http://127.0.0.1:5601/ 点击右下角控制台
这就是咱们打“代码”的地方

3.1查看索引
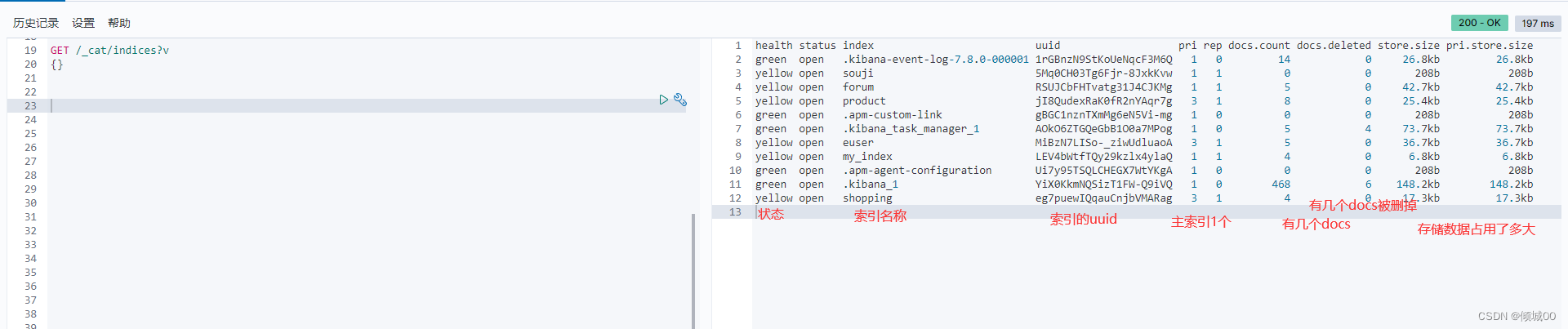
get请求,了解RestFul基础的应该知道get 意为查看
查看所有的索引:GET /_cat/indices?v
3.2创建索引
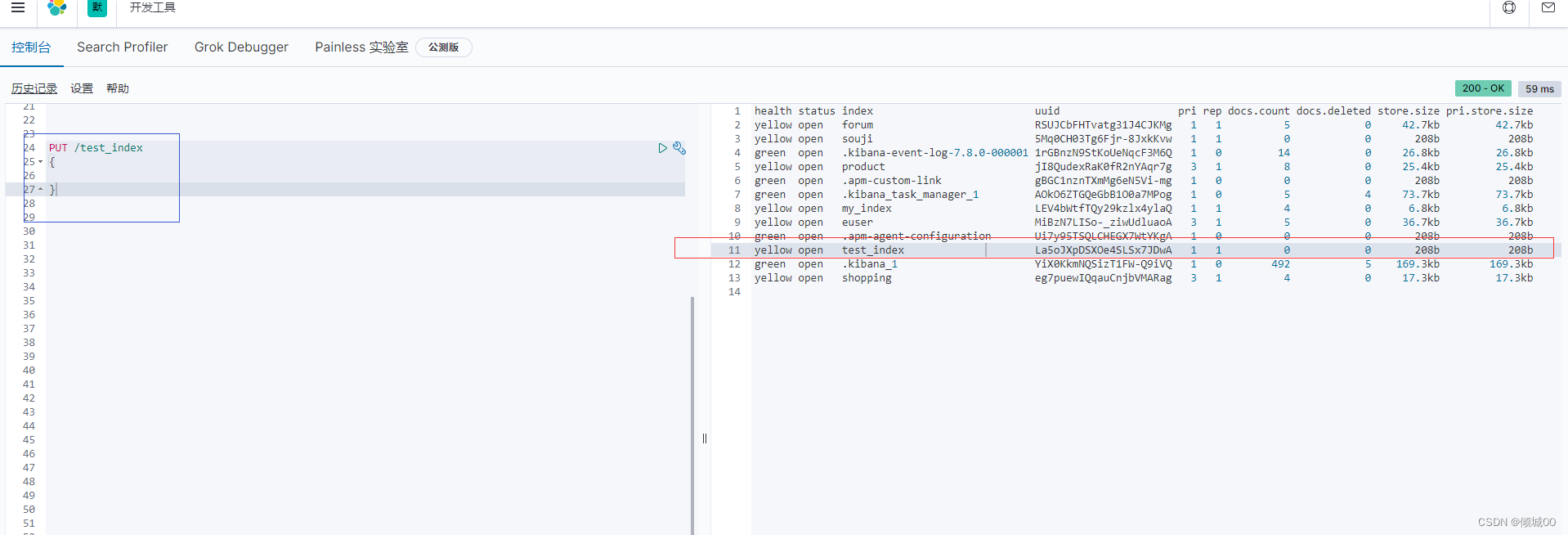
put是创建,以下为创建一个test_index的索引
PUT /test_index{}
3.3删除索引
运用delete请求就可以把索引删掉
DELETE /test_index{},再次查看就会发现test_index这条索引不见了

3.4添加数据
添加数据之前要添加索引,数据就是一个document,把n+个document存入到索引中,可以理解为在java中,List<Map<String ,object>>一个list是一个index,一个map是一个document,map中存入的一个个的数据是field。
(1)添加索引PUT /ecommerce{}
(2)在索引中添加数据
post请求为添加数据,后面/是将数据装入到哪个索引中/_create是添加数据,可以理解为mysql的insert into ,添加了_create才会有添加数据的功能/1是id,每个document都有一个唯一的id,可以通过id对每一个数据进行CRUD的操作,
ps:使用拼音 为了降低入门门槛,后面会用到中文,分词等等
POST /ecommerce/_create/1
{
“name”:“gaolujie yagao”,
“desc”:“gaoxiao meibai”,
“price”:30,
“producer”:“gaolujie producer”,
“tags”:[“meibai”,“fangzhu”]
}
添加3行数据,数据都是以json的格式进行发送,反之接受也是json格式进行接受

#需要用到的数据
POST /ecommerce/_create/1
{
"name":"gaolujie yagao",
"desc":"gaoxiao meibai",
"price":30,
"producer":"gaolujie producer",
"tags":["meibai","fangzhu"]
}
POST /ecommerce/_create/2
{
"name":"jiajieshi yagao",
"desc":"youxiao meibai",
"price":25,
"producer":"jiajieshi producer",
"tags":["fangzhu"]
}
POST /ecommerce/_create/3
{
"name":"zhonghua yagao",
"desc":"caoben meibai",
"price":40,
"producer":"zhonghua producer",
"tags":["qingxin"]
}
3.5查询一条数据
使用get方式请求,/索引名称/_doc/1,搜索出id为1的数据,我们上面添加的时候,已经指明每个数据都有一个对应的id,
GET /ecommerce/_doc/1

3.6更新数据
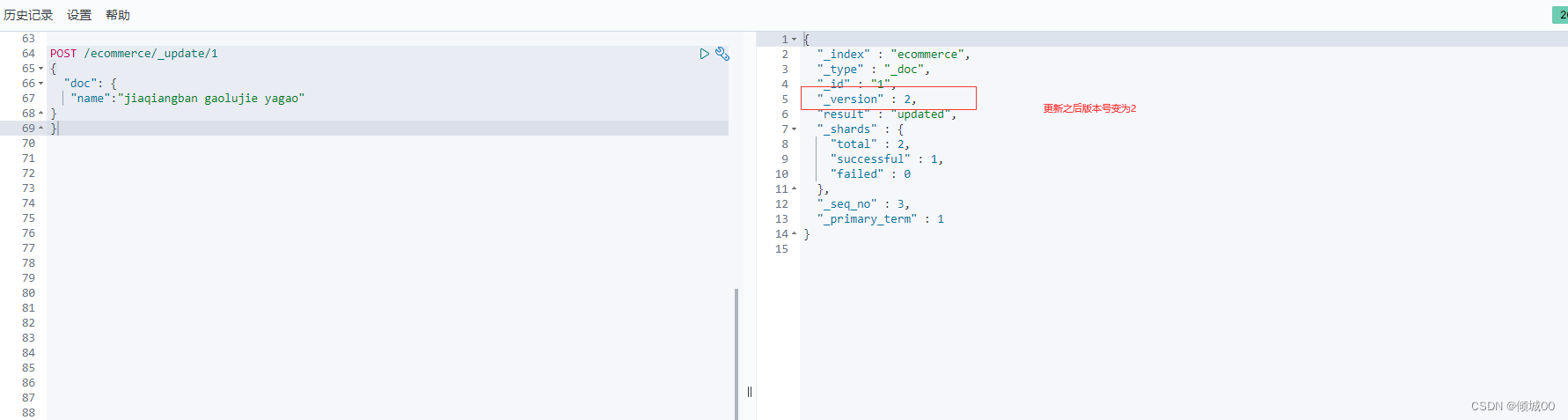
POST /ecommerce/_update/1
{
“doc”: {
“name”:“jiaqiangban gaolujie yagao”
}
}
使用post请求,/_update指明是更新,后面是需要更新的id,json体里面需要用doc进行一个包裹,更新之后变为2
3.7删除数据
DELETE /ecommerce/_doc/1{} 用delete请求,后面跟上id是删除,把delete变为get是查询,查询之后发现数据已经没有了
3.8查询全部
GET /ecommerce/_search{}使用_search用来查询
返回的数据:
took:耗费了几秒钟
time_out:是否超时
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是一个document对于一个search的相关匹配度的打分,越匹配分数就越高
hits.hits:里面包含的了document的详细数据
hits.hits._index:是每个document的id
3.8queryDSL
DSL:Domain Specified language:特定领域的语言
通俗点,就是es的语法
3.8.1查询全部(match_all)
query是查询 match_all是查询全部
GET /ecommerce/_search
{
"query": { "match_all": {}}
}
3.8.2 查询(match)&排序(sort)
查询name中包含yagao的数据,将最终的结果进行Desc排序
GET /ecommerce/_search
{
"query": {
"match": {"name": "yagao"}
},
"sort": [
{"price": {"order": "desc"}}
]
}
3.8.3查询&分页
查询name中包含yagao的数据 ,from是哪一个页,size是显示多少页
GET /ecommerce/_search
{
"query": {
"match": { "name": "yagao" }
},
"from": 1,
"size": 2
}
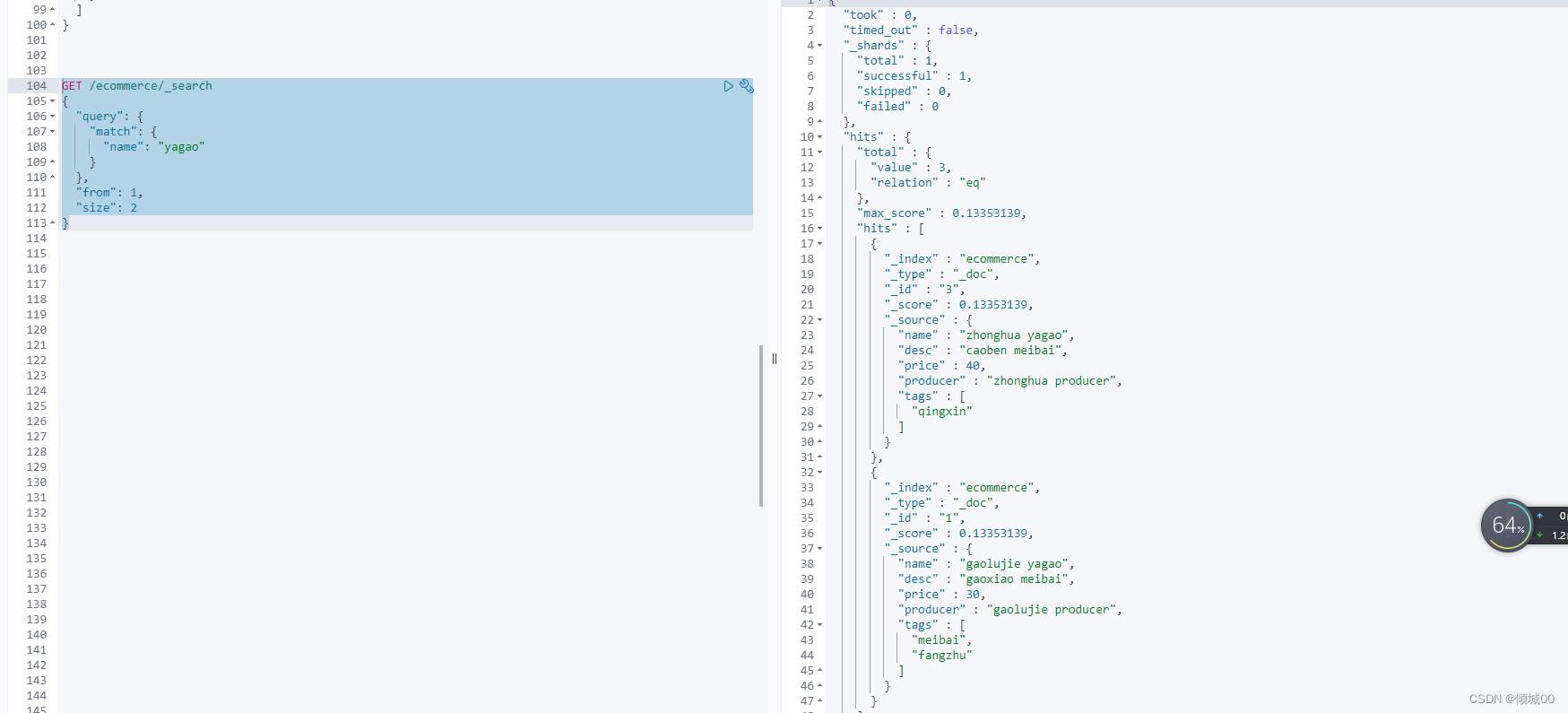
3.8.4查询&分页&展示部分数据
查询name中包含yagao的数据 ,from是哪一个页,size是显示多少页,但是只显示priceh和name,其他的不显示
GET /ecommerce/_search
{
"query": {
"match": { "name": "yagao" }
},
"from": 1,
"size": 2,
"_source":["price","name"]
}
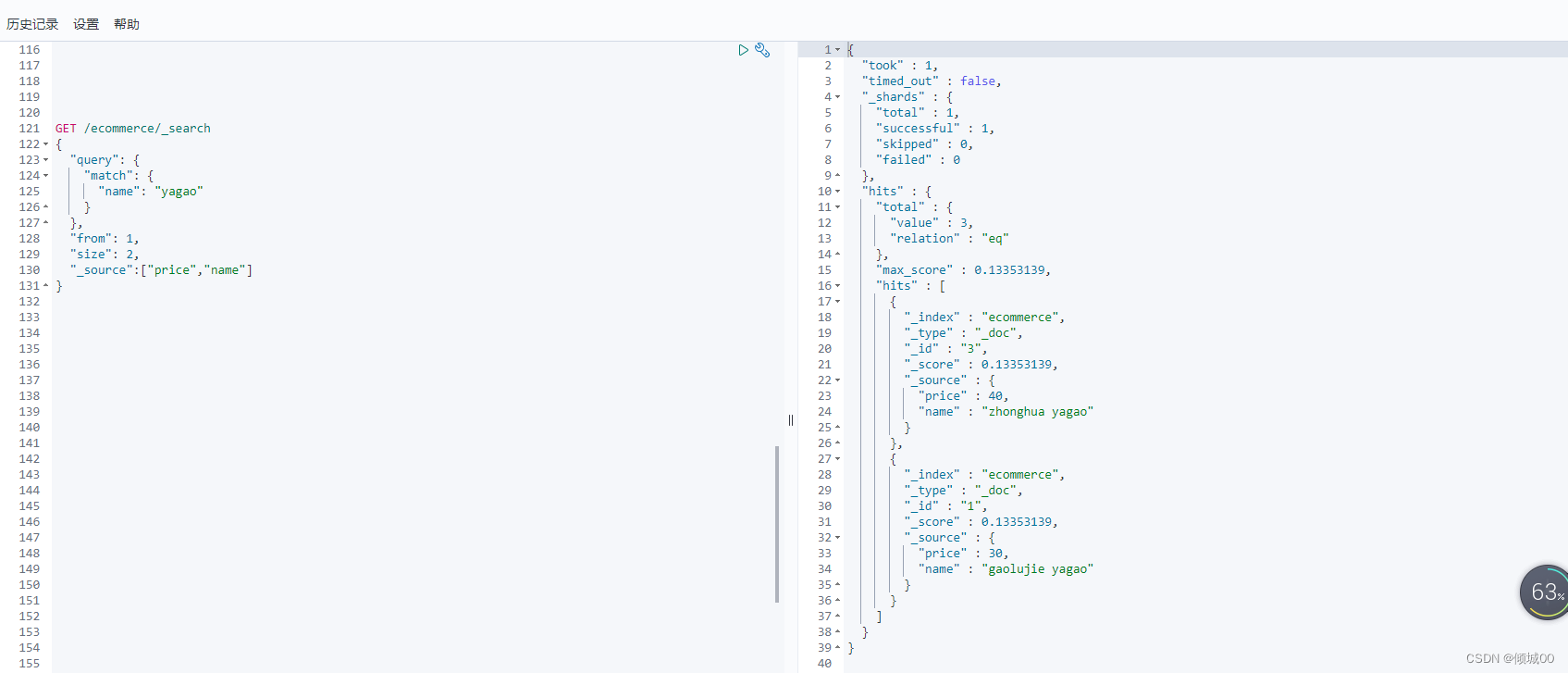
3.8.4过滤条件(filter)&must
查询name包含yagao的且price小于29的数据
对于price小于29的数据进行筛选就是filter
query里面套bool,must的意思是必须完全匹配,下图只有一个条件就是name=yagao,如果还有一个条件,数据必须完全匹配2个条件才可以展示出来,这是must的作用,
filter:过滤,range:过滤范围 后面跟过滤条件 ge是小于 就是过滤price小于29的数据
GET /ecommerce/_search
{
"query": {
"bool": {
"must": [ { "match": { "name": "yagao" } } ],
"filter": [ { "range": { "price": { "gt": 29 } } } ]
}
}
}
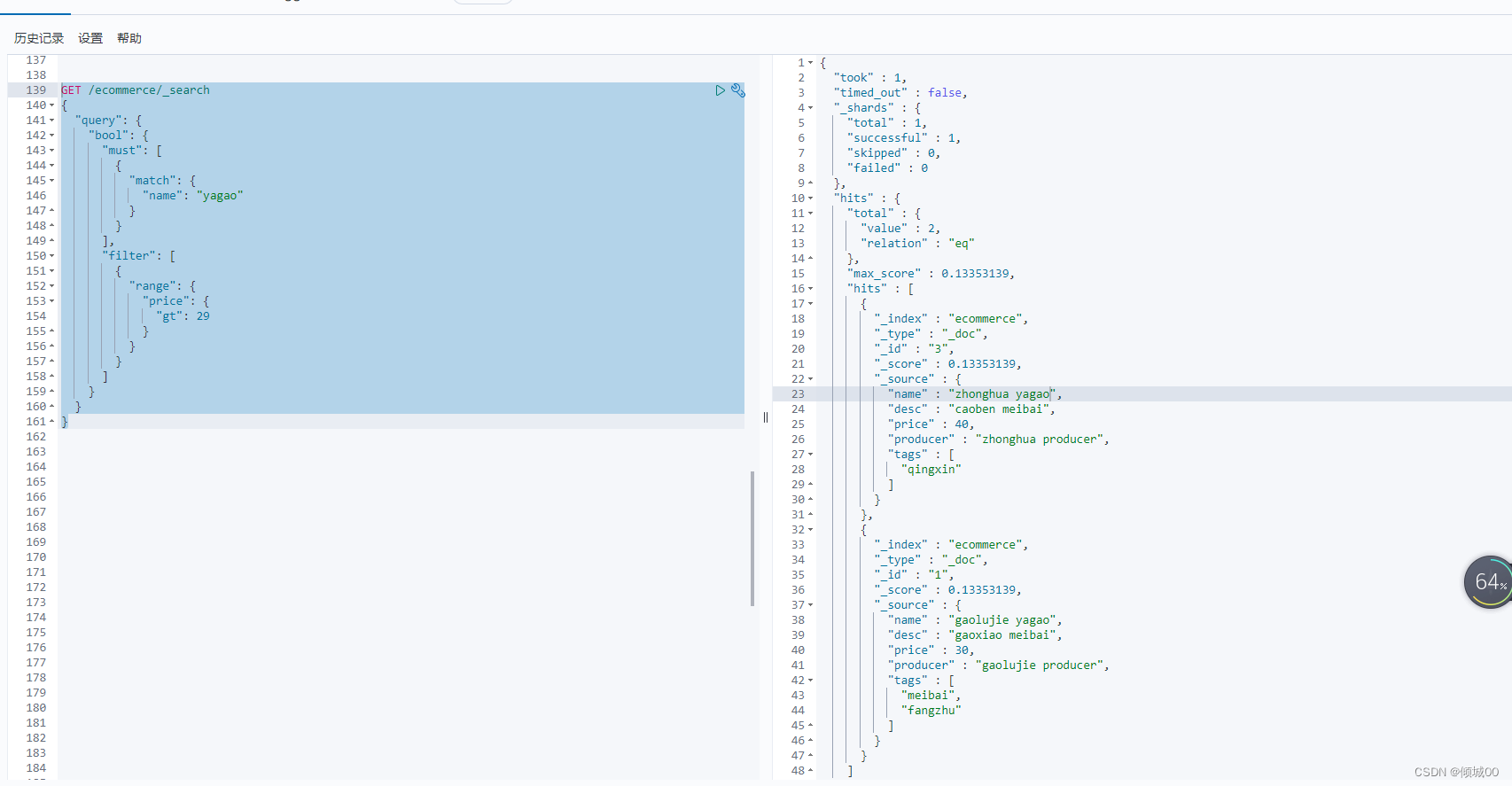
3.8.5全文检索
#先添加数据
POST /ecommerce/_create/4
{
"name":"special yagao ",
"desc":"special meibai",
"price":50,
"producer":"special yagao producer",
"tags":["meibai"]
}
#执行查询
GET /ecommerce/_search
{
"query": {
"match": {
"producer": "yagao producer"
}
}
}
我们执行语句去进行查询 “producer”: “yagao producer”
我们可以看到新添加的数据分数是1.15,其他的是0.11分数
这个分数后面会有详细的讲解。原理就是越匹配他的分数就越高,为什么新添加的分数这么高
我们试着拆解一下
id =4 special yagao producer
id = 2 jiajieshi producer
id =3 zhonghua producer
id =1 gaolujie producer
这是我们的4条数据我们将其拆解
关键字-------------id
special-------------4
yagao --------------4
producer-----------4,2,3,1
jiajieshi -------------2
zhonghua ---------3
gaolujie ------------1
将其装入到倒排索引中
我们搜索的是yagao producer 会自动拆解成yagao producer两个词
去代拍索引中寻找,yagao 对应的是4 producer对应的四1,2,3,4,
我们发现,4占的有2分,索引id=4的这个数据就会分数高,优先显示出来

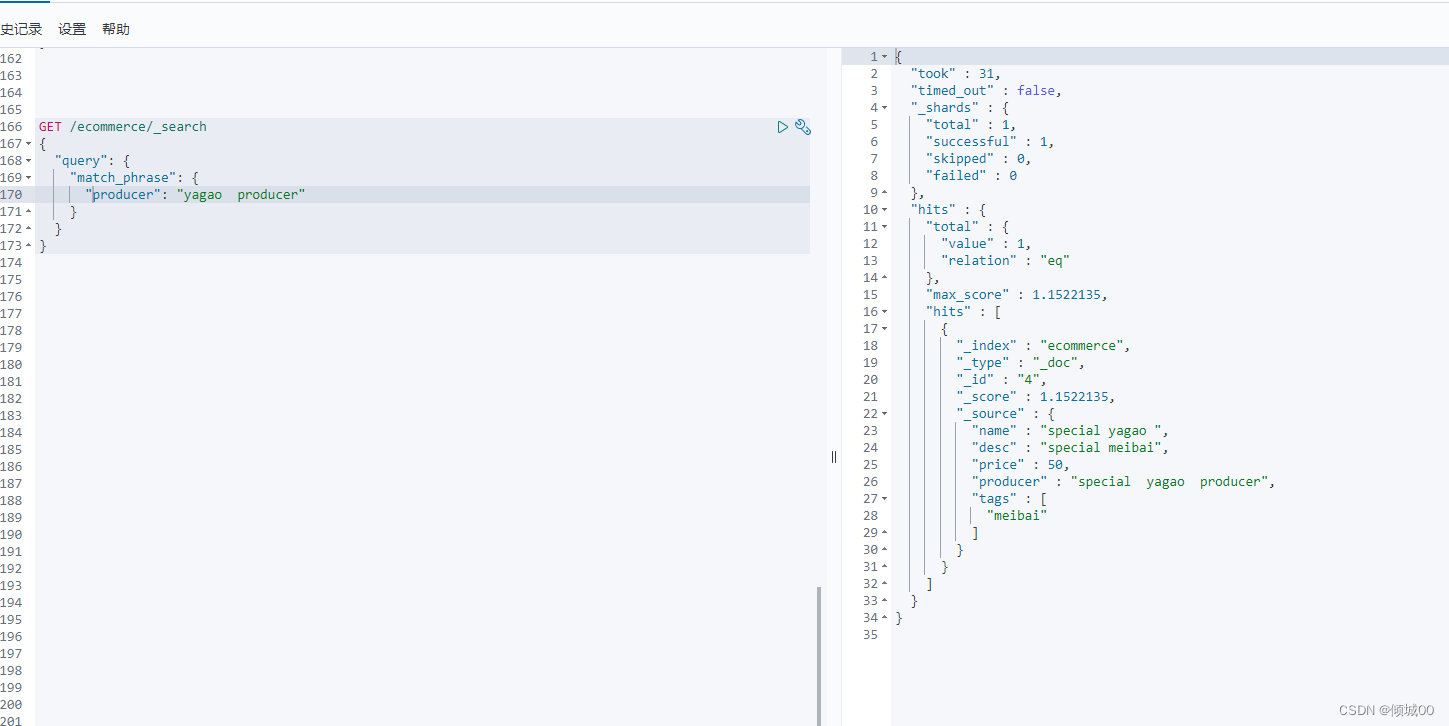
3.8.6短语搜索(match_phrase)
跟全文检索相反,全文检索是会将搜索串拆分出来,去倒排索引中一一匹配,只要有一个单词匹配成功就会作为结果进行返回,match_phrase要求指定的搜索串,必须在指定的文本字段中,才可以算匹配,才能算作结果去返回
GET /ecommerce/_search
{
"query": {
"match_phrase": {
"producer": "yagao producer"
}
}
}
3.8.6高亮显示(highlight)
百度搜索关键词会标红显示,这就是高亮显示
GET /ecommerce/_search
{
"query": {
"match": {
"producer": "producer"
}
},
"highlight": {
"fields": {
"producer": {}
}
}
}
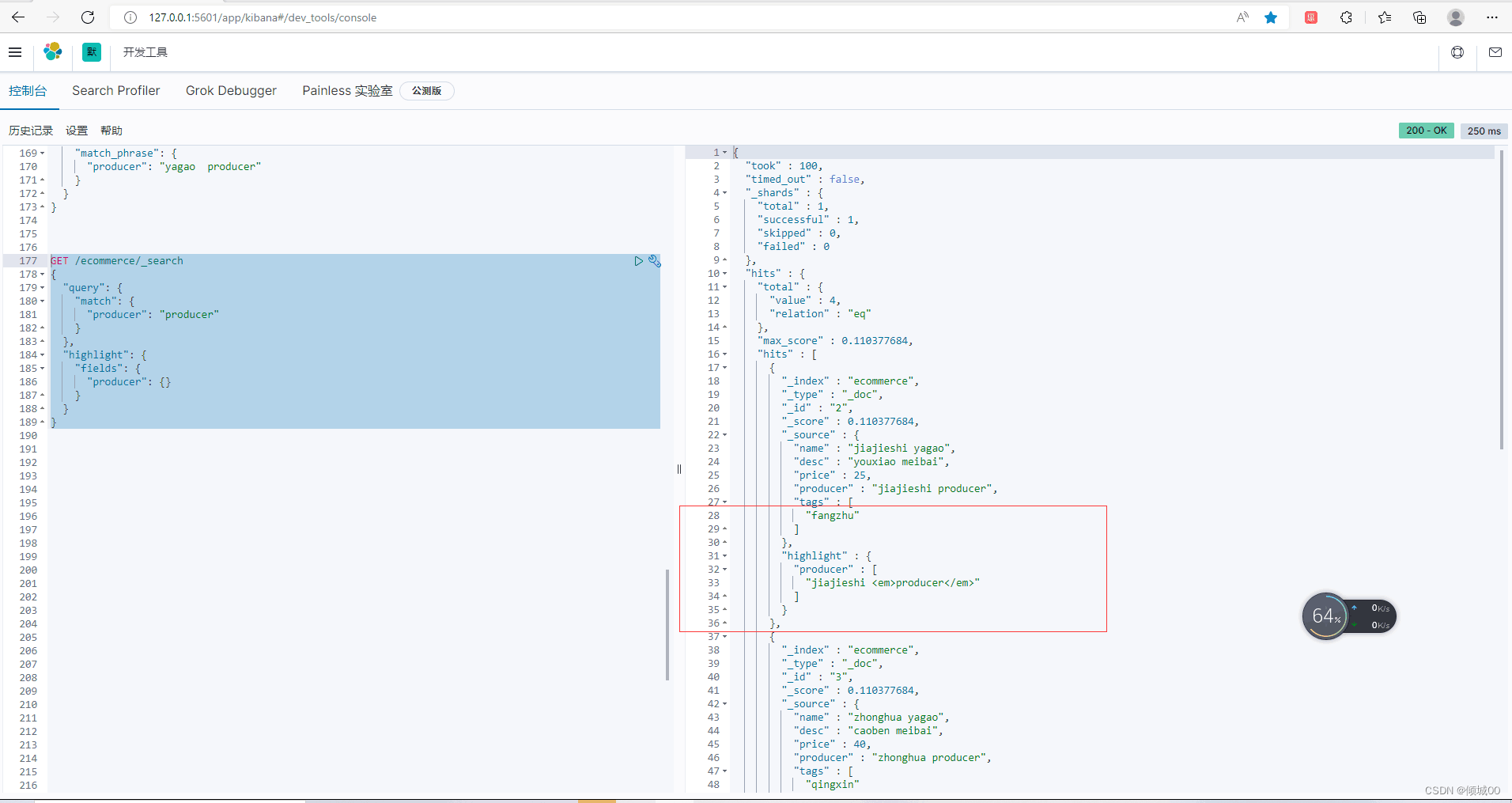
3.8.7聚合函数
计算tage下的商品数量
我们用到aggs,后面跟自定义名字,后面跟terms,至于里面为什么要放tags.keyword
因为我们maping中tags的type是text,是默认分词的,解决办法修改mapping或者加上.keyword让其不分词,后面根据mapping会有讲解
GET /ecommerce/_search
{
"aggs": {
"grob_by": {
"terms": { "field": "tags.keyword"} }
}
}

3.8.7.1聚合函数练习1
对名称中包含yagao的商品计算tag下的商品数量
掌握先搜索然后再聚合,size是显示多少,我们不想显示原始数据,将size设置为0即可
GET /ecommerce/_search
{
"query": {
"match": {
"name": "yagao"
}
},
"size": 0,
"aggs": {
"grob_by": {
"terms": {
"field": "tags.keyword"
}
}
}
}
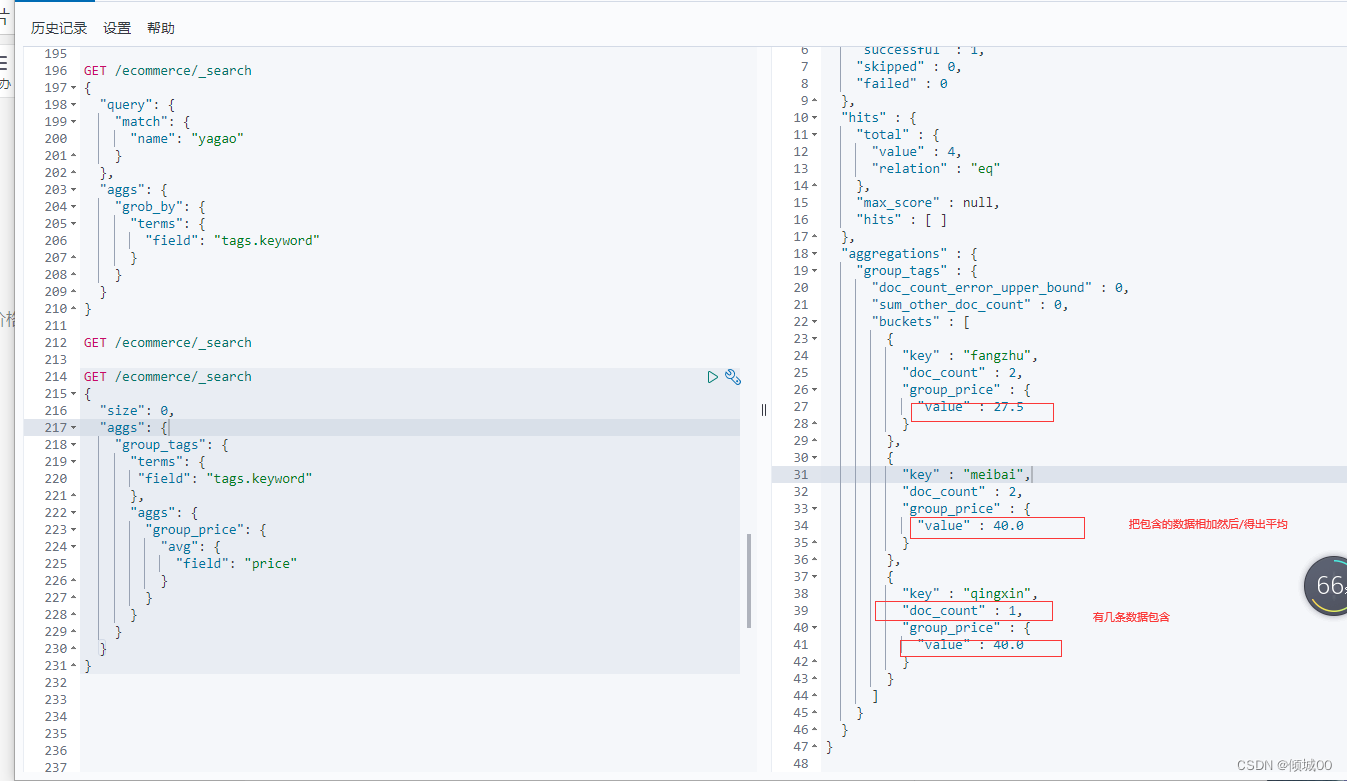
3.8.7.2聚合函数练习2
聚合分析需求:先分组,然后计算tag下商品的平均价格
这里使用的嵌套,先对tag进行分组,使用avg去进行一个平均数的查询
GET /ecommerce/_search
{
"size": 0,
"aggs": {
"group_tags": {
"terms": {
"field": "tags.keyword"
},
"aggs": {
"group_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
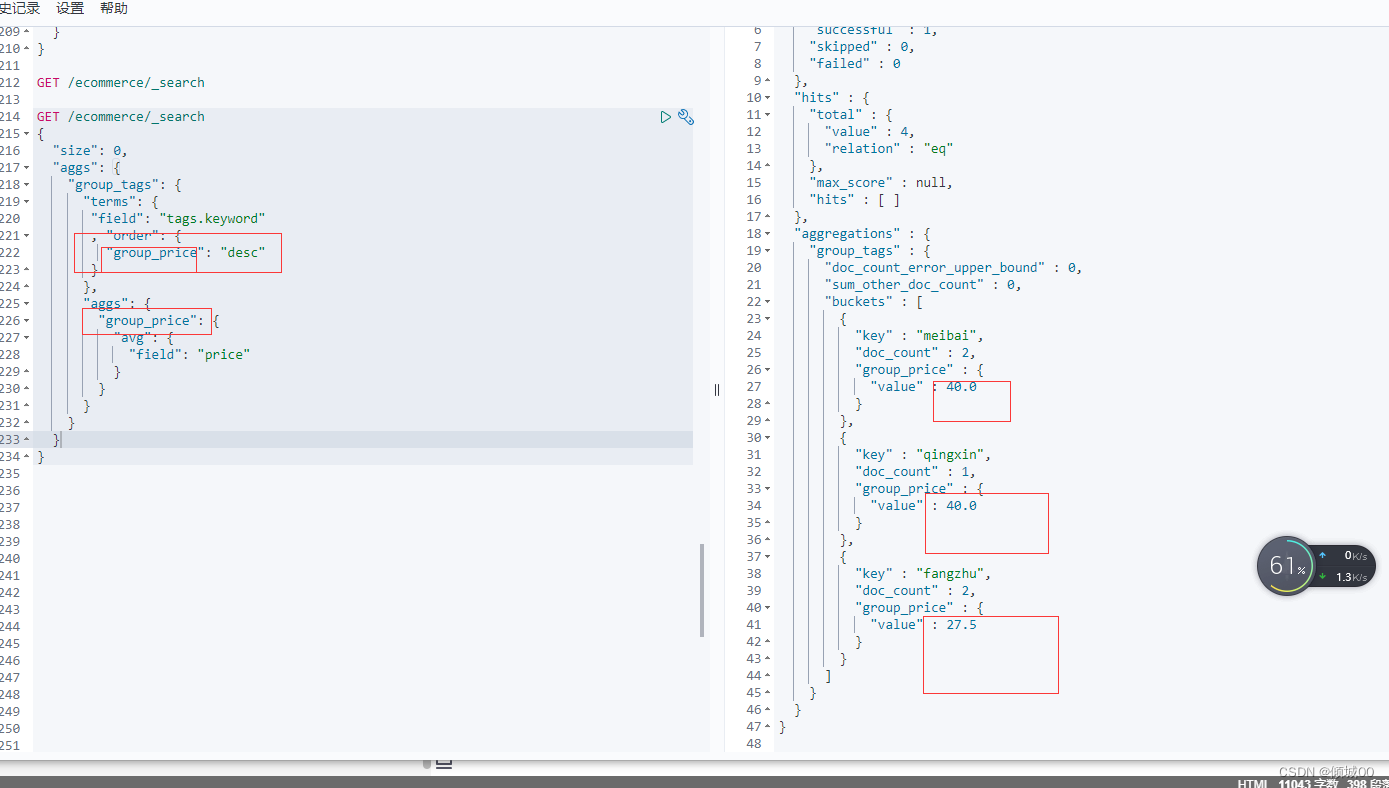
3.8.7.3聚合函数练习3
聚合分析需求:先分组,然后计算tag下商品的平均价格,然后将其倒叙输出,我们使用的是order,后面跟,需要对哪个进行分组,我们把下面的结果集group_price扔过来, 让其他进行排序
GET /ecommerce/_search
{
"size": 0,
"aggs": {
"group_tags": {
"terms": {
"field": "tags.keyword"
, "order": {
"group_price": "desc"
}
},
"aggs": {
"group_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
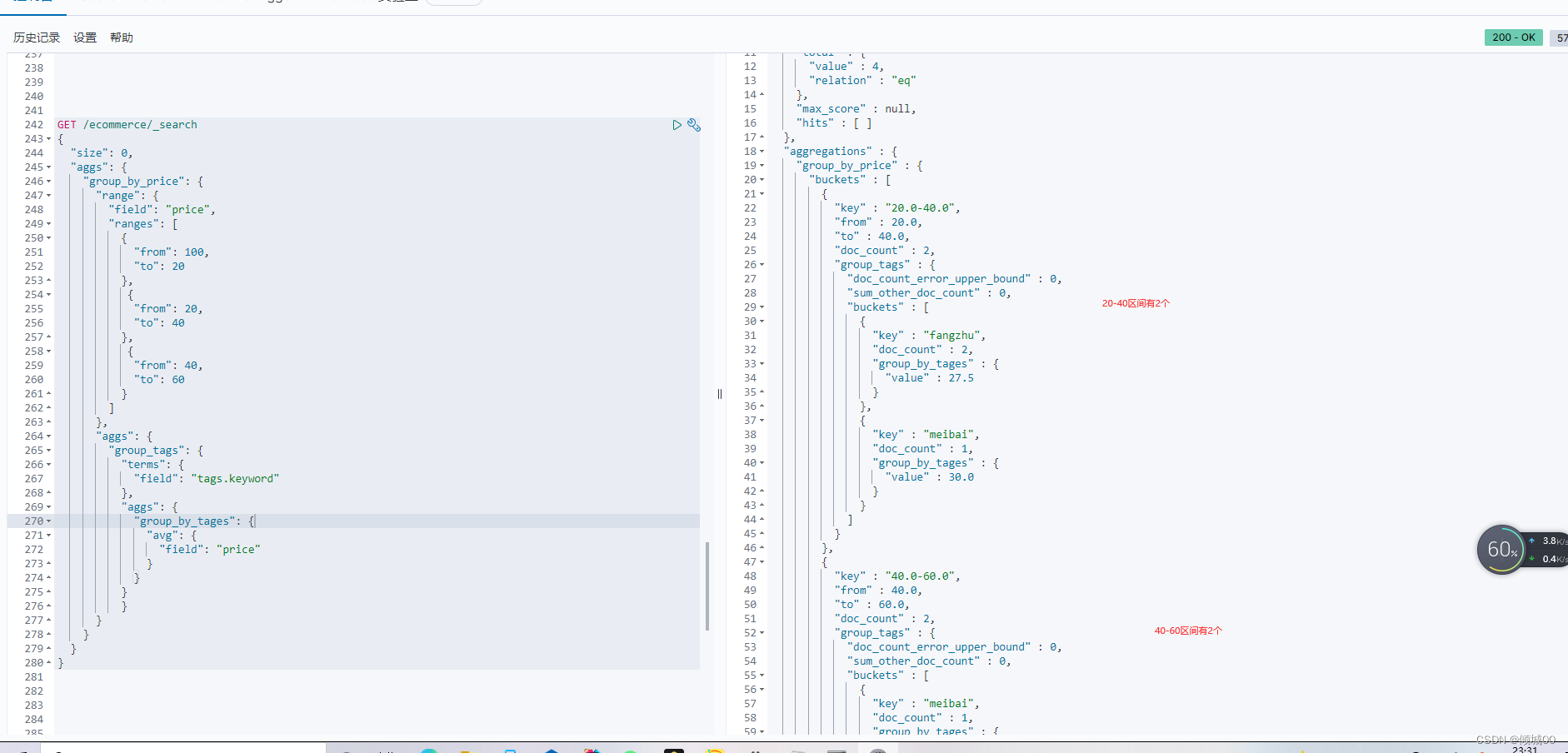
3.8.7.4聚合函数练习4
按照指定的价格的区间进行分组,然后再每组中按照tag进行分组,然后再计算平均的价格
GET /ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 100,
"to": 20
},
{
"from": 20,
"to": 40
},
{
"from": 40,
"to": 60
}
]
},
"aggs": {
"group_tags": {
"terms": {
"field": "tags.keyword"
},
"aggs": {
"group_by_tages": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
3.8.7.5聚合函数练习4
这里我们分组,然后找出每组的最大值,累死的的还有很多的函数,后续还会在讲解
GET /ecommerce/_search
{
"size": 0,
"aggs": {
"group_price": {
"terms": {
"field": "tags.keyword"
},
"aggs": {
"group_max": {
"max": {
"field": "price"
}
}
}
}
}
}
四:Elasticsearch的基础分布式架构
4.1Elasticsearch的扩容
扩容方案:
假设有6台服务器,每台容纳1T的数据,马上数据量就要新增到8T,解决方案:
(1)垂直扩容:
重新购买2台服务器,每台服务器的容量是2T,将老的1T的2台服务器给替换掉,那么现在6台的总容量就是41T+22T=8T
(2)水平扩容
新购置2台服务器,每台服务器的容量是1T,加入到集群中,那么现在服务器的总容量就是8*1T=8T
一半是采用水平扩容的方案
4.2windows上的集群部署
推荐看完练习完 三:Elasticsearch入门的基础在来配置集群,不然会看不懂或者范蒙
步骤一删除es的data目录和logs文件之中的数据,刚安装是没有内容的,这是es在运行期间产生的,我们之前运行过,所以是会有数据的
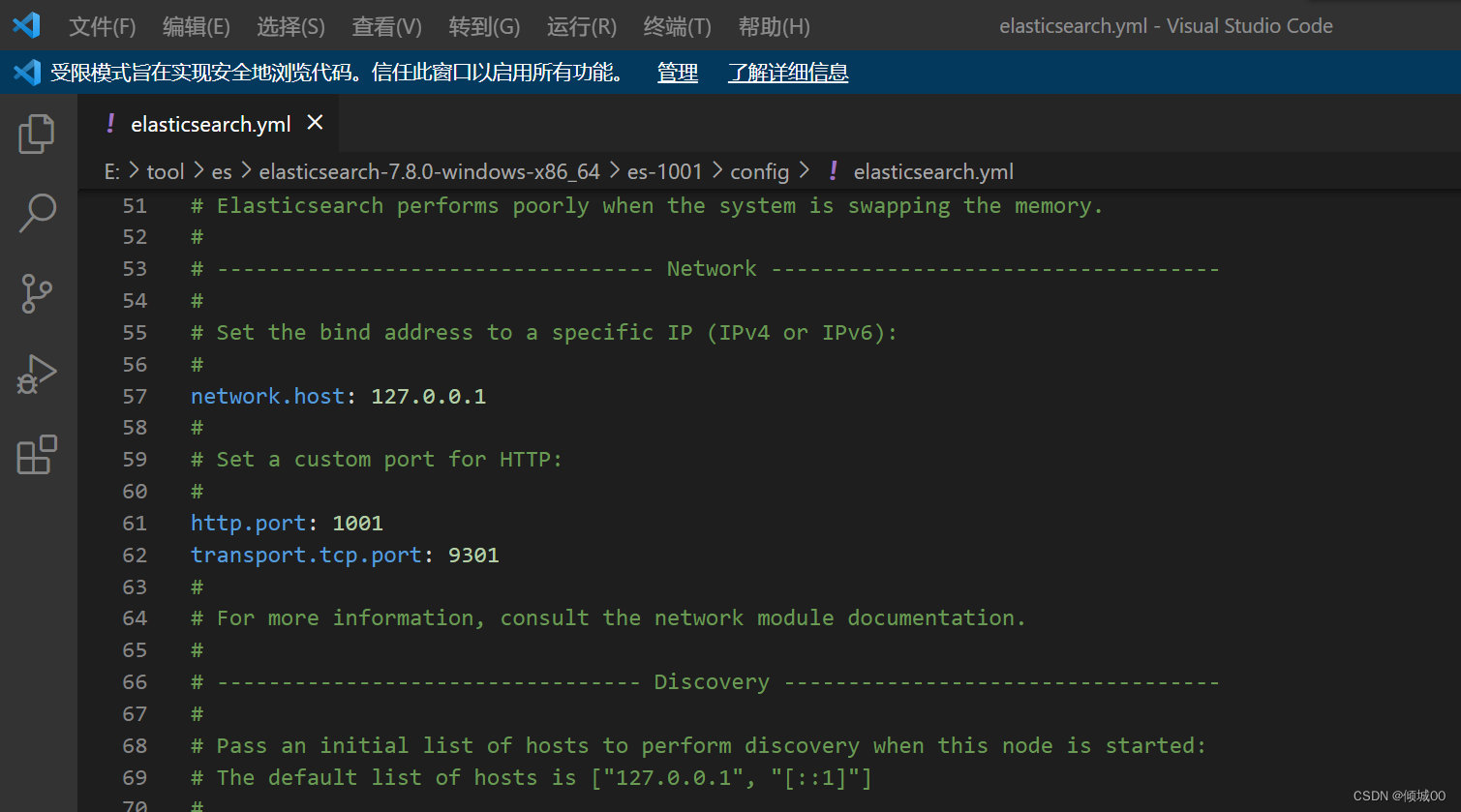
步骤2,配置config文件,打开config,进入到elasticsearch.yml文件中 ,刚打来发现全部都注释了,我们进行如下操作
(1)cluster.name: my-application ------------>集群名称,我们想要对个节点,他们的集群必须要相同
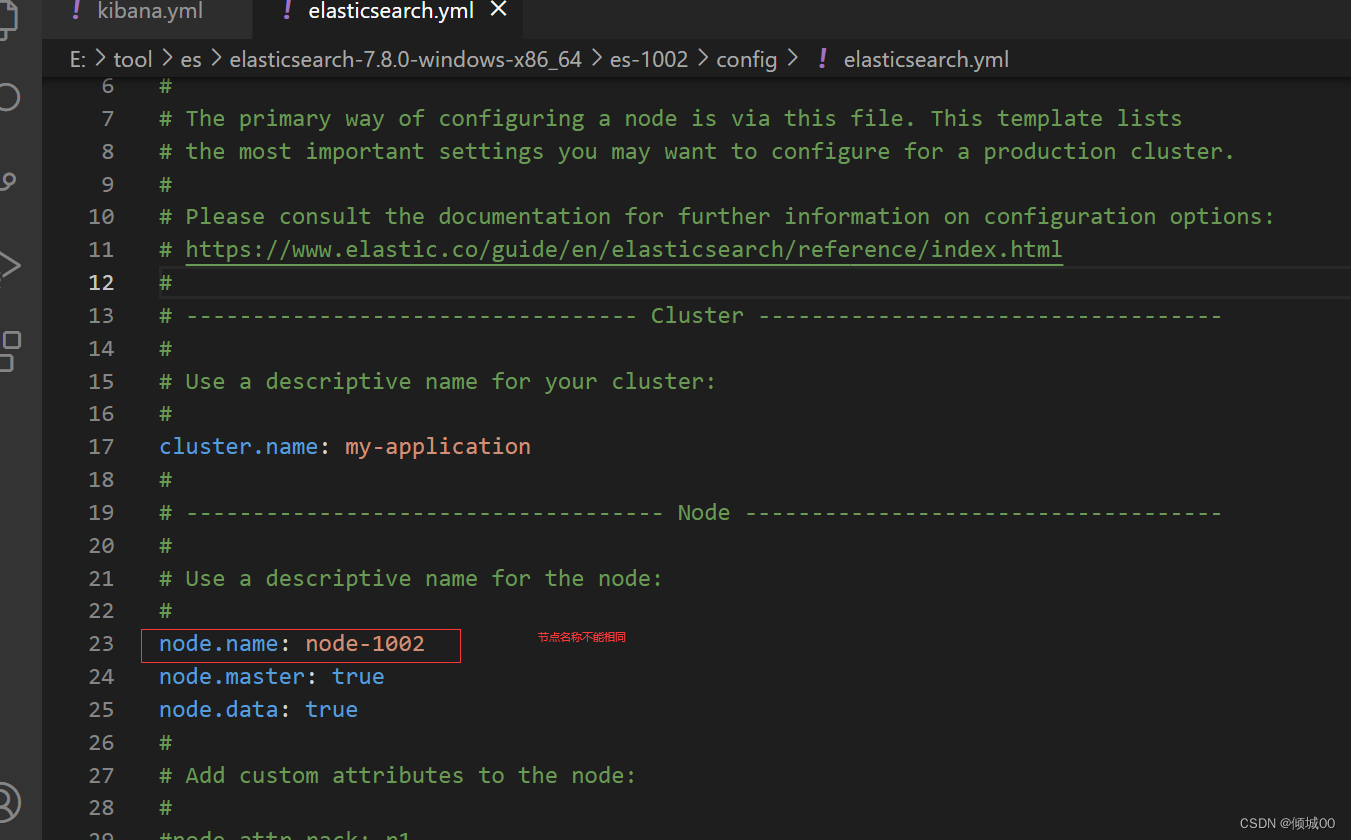
(2)node.name: node-1001----------------->每个节点要有自己的名字,他的名字是不能重复的
node.master: true
node.data: true
(3)network.host: 127.0.0.1---------------->主机名称,这里写本地
(4)http.port: 1001-------------->端口号
(5)transport.tcp.port: 9301------------>通信端口
(6)http.cors.enabled: true---------------->跨域设置
http.cors.allow-origin: “*”

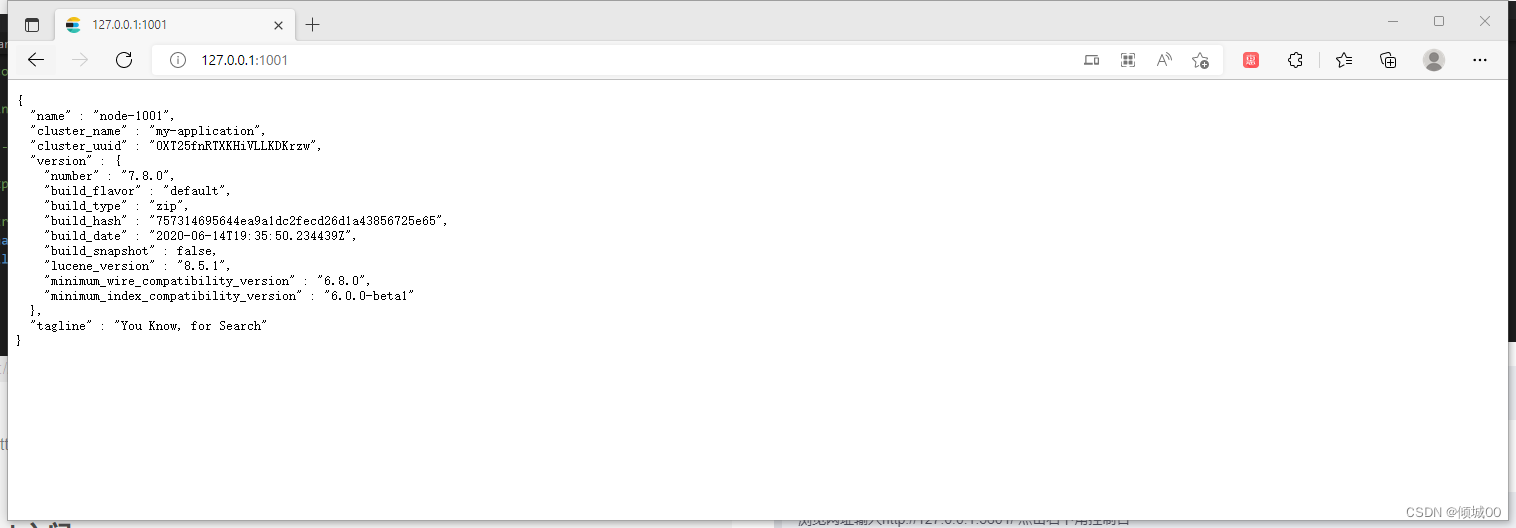
然后保存启动浏览器输入http://127.0.0.1:1001/
返回如下数据证明成功
步骤3:配置kibana ,打来config目录,打来kibana.yml文件,在大概28行打开更改elasticsearch.hosts: [“http://127.0.0.1:1001/”]
因为我们上面配置的端口是1001,主机地址是127.0.0.1,如果不更改会启动不起来,更改之后启动即可,启动之后我们打开控制台
步骤4:控制台输入GET /_cluster/health 查看集群状况
接下来我们启动第二个,把第一个复制一份,改名叫1002,然后1002删除data文件夹和logs文件夹里面的数据,打开config文件夹的elasticsearch.yml文件进行配置
discovery.seed_hosts: [“127.0.0.1:9301”]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
然后浏览器输入http://127.0.0.1:1002/,如下是启动成功
我们在控制台重新查询,得到的结果是2个,证明咱们的2台搭建成功,然后我们去配置第三台,相同的操作,

接下来我们启动第三个,把第一个复制一份,改名叫1003,然后1003删除data文件夹和logs文件夹里面的数据,打开config文件夹的elasticsearch.yml文件进行配置
discovery.seed_hosts: [“127.0.0.1:9301”,“127.0.0.1:9301”]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
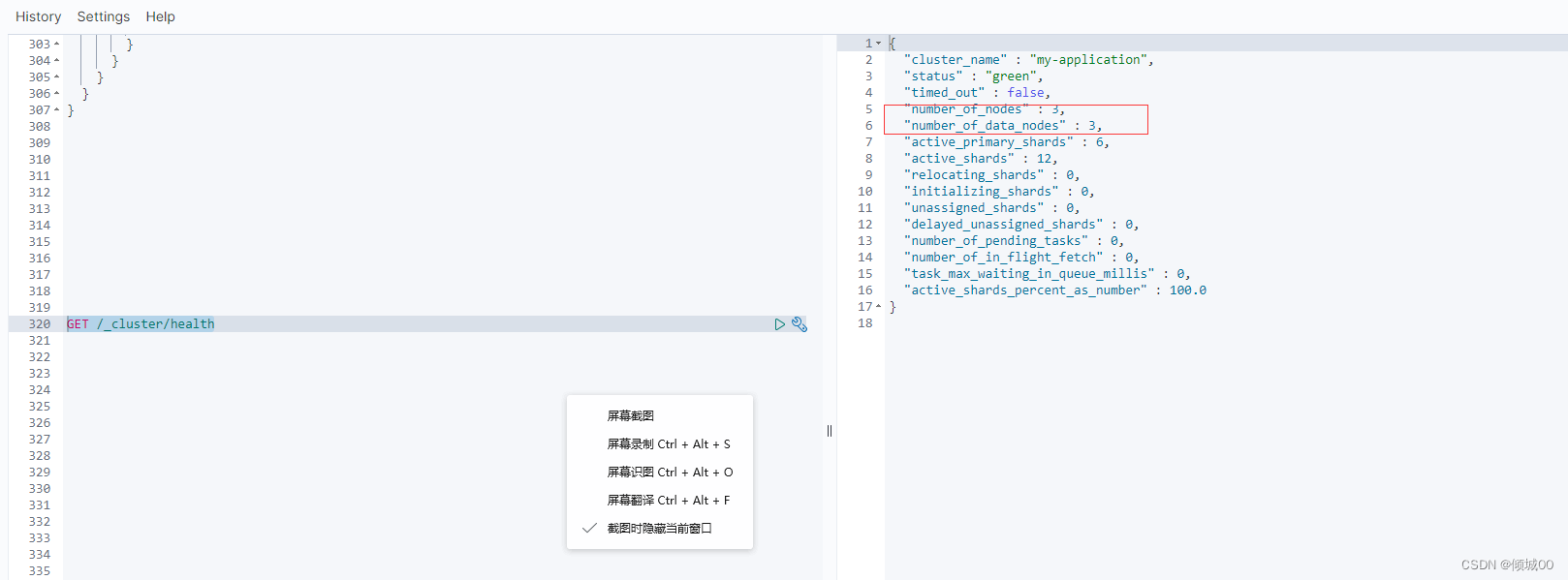
我们在控制台重新查询,得到的结果是3个,证明咱们的集群搭建完成

4.3核心概念(进阶)
4.3.1分片(shards)
一个索引可以存储超出单节点硬件限制的大型数据,比如,一个具有10亿文档数据的索引占据1TB的磁盘空间,,而任一节点都可能没有这样大的磁盘空间,或者单个节点处理搜索请求,响应太慢,为了解决这个问题,Elasticearch提供了将搜因划分成多份的能力,每一个就称之为分片,当你创建一个索引的时候,你可以指定你想要的分片数量,每个分片本身也是一个功能完善,并且独立的“索引”,这个“索引”可以被放置到集群的任何节点上
1)分片很重要,主要有方面允许你水平分割/扩展你的内容容量
2)允许你再分片之上进行分布式。并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,他的文档怎样聚合和搜索请求,是由Elasticsearch来管理的,对于用户来说,这都是透明的,无需过多关心
4.3.2副本(Replicas)
在一个网络云的环境里,失败可以能随时都发生,在某个分片/节点,不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用是强烈推荐的,为此Elasticsearch允许你创建一份或者多份的拷贝,这些拷贝就是副本,
复制分片之所以重要,有两个原因:
1)在分片/节点失败的情况下,提高了可用性,因为这个原因,注意到复制分片从不与原/主要(original/Primary)分片置于同一节点上是非常重要的
2)扩展你的搜索/吞吐量,因为搜索可以再所有的副本上并行运行
4.3.3 分配(Allocation)
将分片分配给某个节点的过程,包括分配主分片或者副本还包含主分片复制数据的过程,这个过程由master节点完成的
4.3.4系统架构

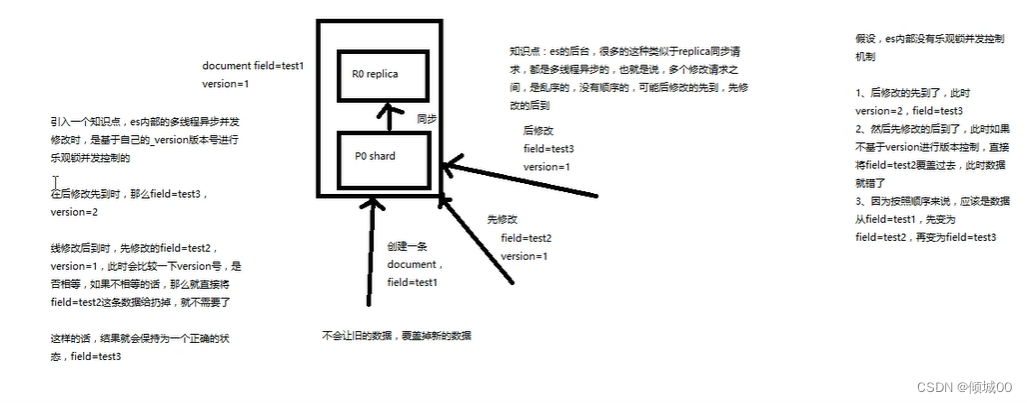
看图,我们的es有多个节点,我们会在多个节点中选举出一个主节点叫master,为什么要选举这个master,以为这个master要管理这整个集群,我们的负载均衡都是由master来调度,我们的集群的管理是和master有关系的,删除索引和删除索引都是和master有关的 ,我们每个节点是可以存储我们的索引的,而索引中的数据是有副本的概念和分片的概念,我们的p0,p1,p2是我们的分片一个完整的索引切成几片,R0,R1,R2是我们的副本防止数据丢失 我们的P0和R0是不能在一台副本上的,如果这个节点出了问题,整个就全挂了,这个时候数据就会不安全
4.3.5master节点
master节点管理es集群的元数据,比如说索引的创建和删除,维护索引的元数据,节点的增加和移除,维护集群的元数据
默认情况下会自动选举出一台节点作为master节点
master节点不会承载所有的请求,所以不会是一个单点瓶颈
4.4分布式集群(进阶)
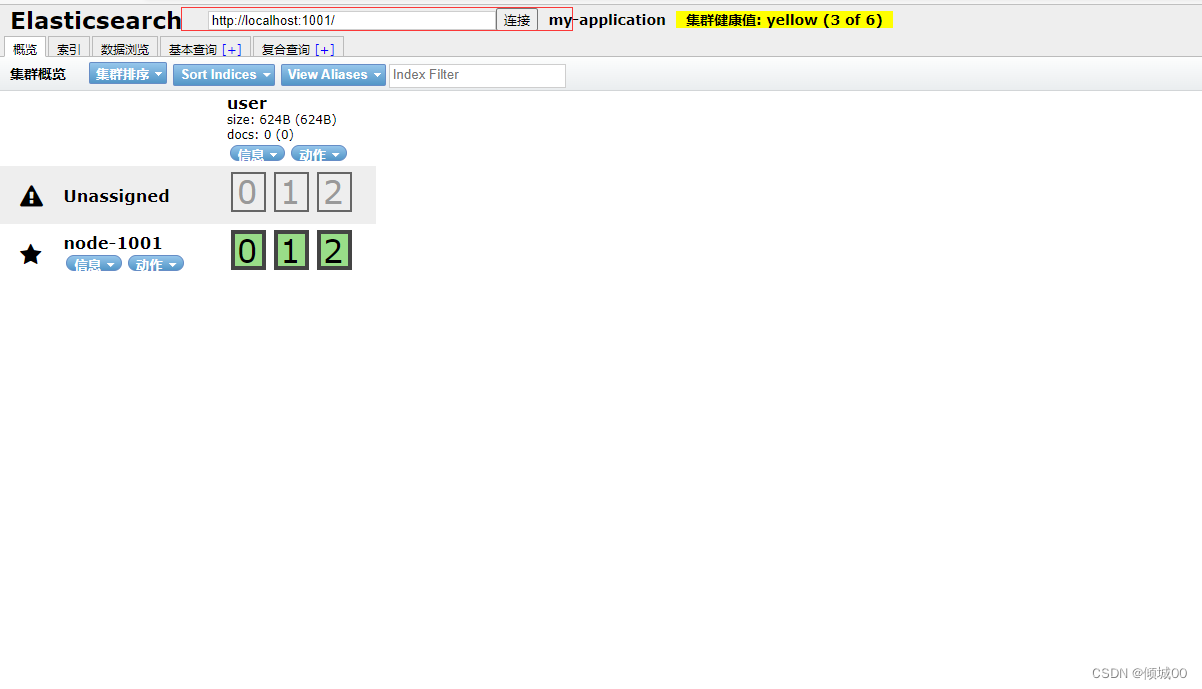
4.4.1单节点集群
整个集群只有一个节点就是单节点集群,我们创建一个user的索引,给他的主分片为3,副本为1的
我们只需要启动一个1001即可
PUT /user
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 3
}
}
这边需要下载一个扩展包,我放在最上文的连接中了elasticsearch-head-chrome-plugin
然后打开我们的浏览器。

加载好了之后我们下滑,打开,然后我们就可以看到和图一样的效果了
点进去之后输入地址就会和我看到的效果是一样的
- 为什么副本没有进行分配呢?为什么所有的主要分片都在一起,因为本次演示的是单节点,就是一台机器所以没有进行负载均衡,现在我们的主分片咋运行,但是没有副本,我们上面设置的副本为1,的意思就是每一个分片都有一个副本
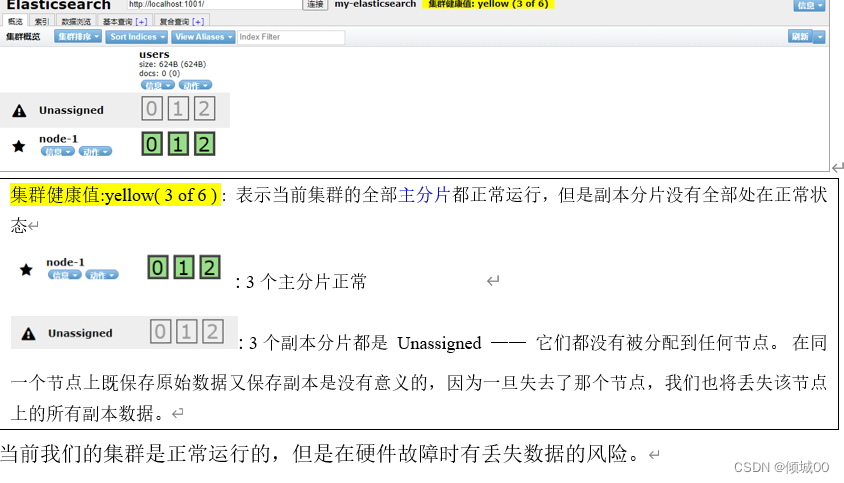
2.我们启动第二个,启动1002
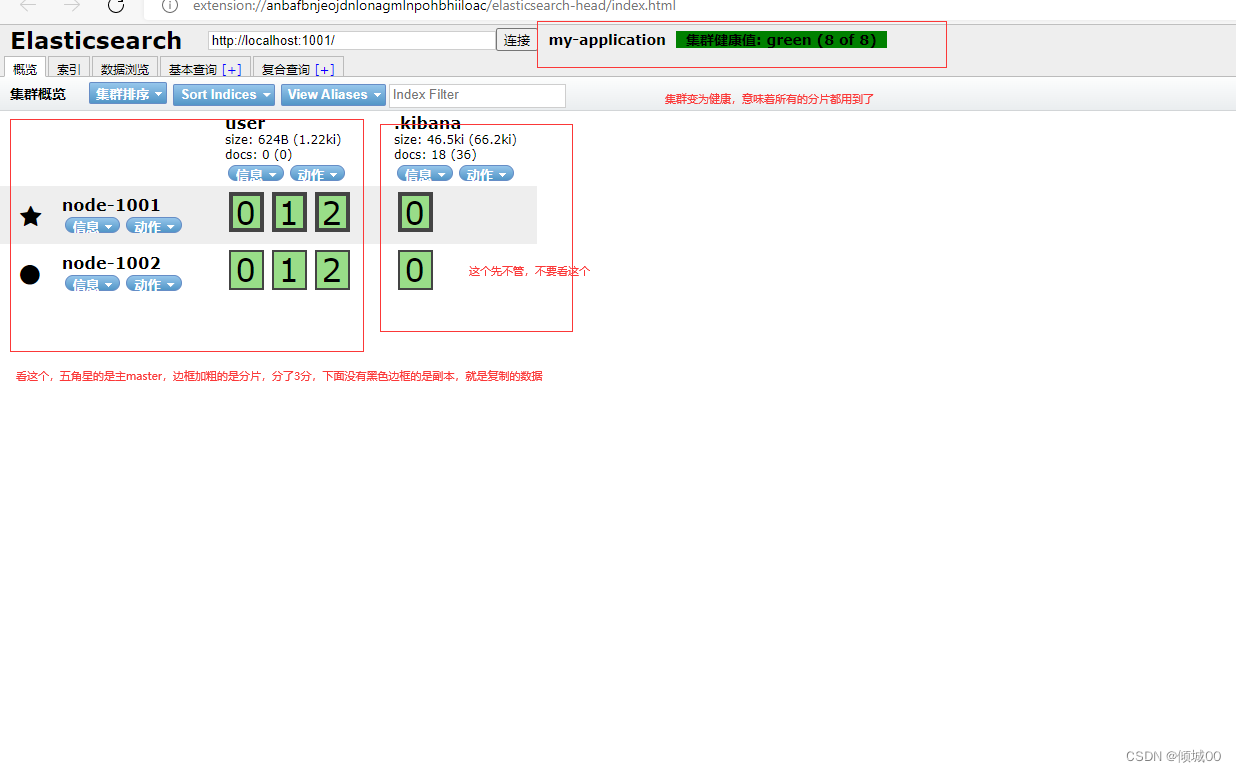
4.4.2水平扩容实践
一直说水平扩容的概念可能看不懂,直接实战来一手,我们现在是2个节点(1001和1002)我们也可以看到所有的主分片和副本分片都正常,已经没有多余的位置了,但是,当我们启动第三个(1003)的时候后,他的分片会转移到不同的节点上去
3.1)好处:负载均衡,增加吞吐量,可以理解为,一个骆驼,背着100g的粮食,我们在来一个骆驼就一个骆驼50g,那么第一个骆驼就不那么累了。
Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有2个分片,而不是之前的3个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片的性能将会得到提升。

4.4.3头脑风暴
我们想扩容超过6T应该怎么办,我们的主分片在开始创建的时候已经设置了为3,但是在创建完成之后,主分片是不能更改的,那么我们想实现应该怎么办?
我们设置副本分片是2个就可以,副本分片是2个,吞吐量又进一层,可能不理解这个吞吐量是什么意思,比方说我们的项目在nginx上发布项目,开3个tomcat,让用户访问的时候在tomcat上轮训的聚在均衡,但是数据量非常的大,想扩容怎么办,最简单的办法,在加几台tomcat,当人这是举的一个例子,当然实际开发是不能这么干的,机器顶不住,大白话来说就是减轻单个的压力
PUT user/_settings
{
"index": {
"number_of_replicas" : 2
}
}

users索引现在拥有9个分片:3个主分片和6个副本分片。 这意味着我们可以将集群扩容到9个节点,每个节点上一个分片。相比原来3个节点时,集群搜索性能可以提升 3 倍。
当然,如果只是在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每个分片从节点上获得的资源会变少。 你需要增加更多的硬件资源来提升吞吐量。
但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去2个节点的情况下不丢失任何数据。
4.3.4 应对故障
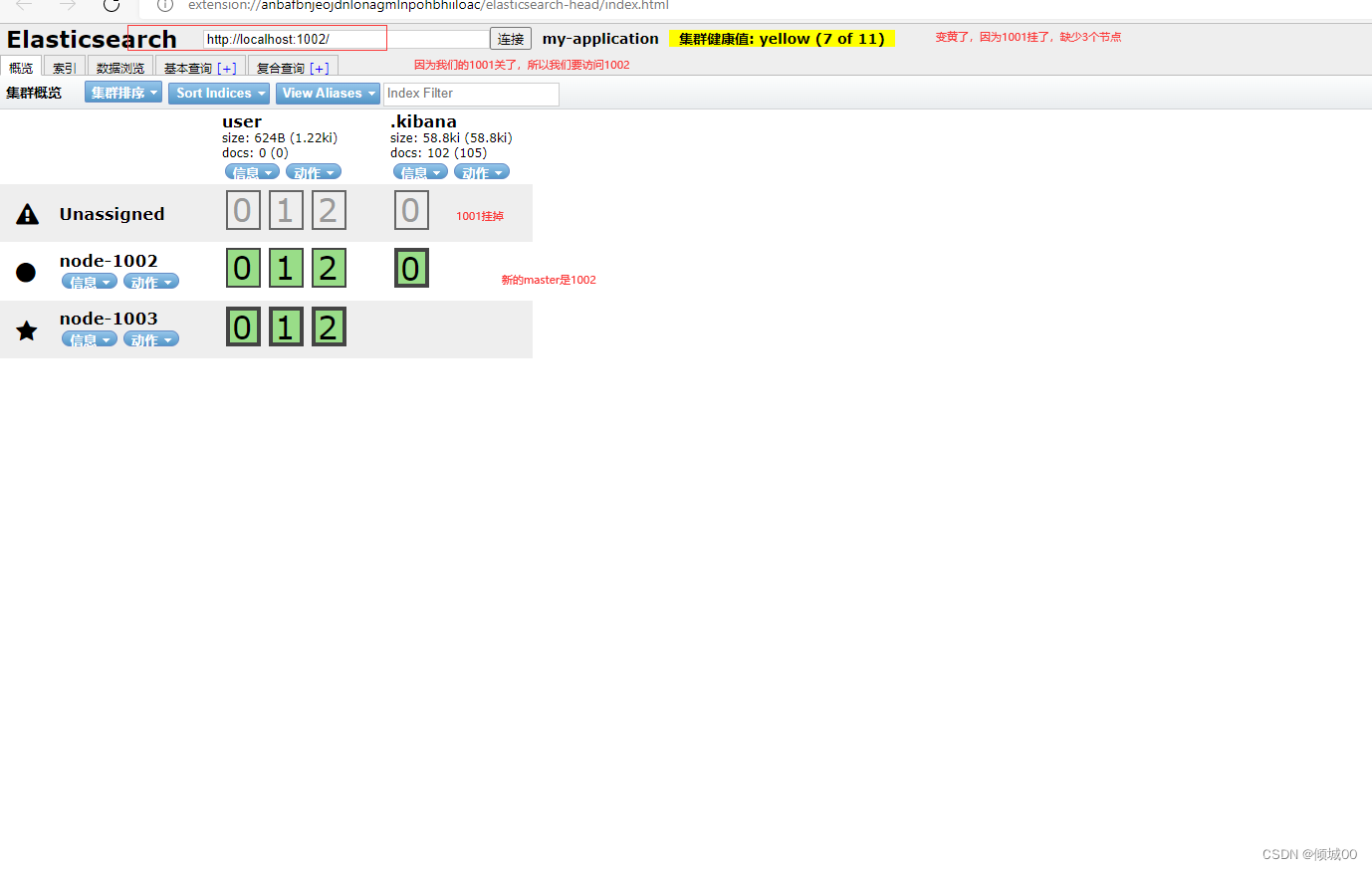
我们的master是1001,如果我们的1001因为故障,挂了,会发生什么情况,我们试验一下,把master关掉
ps:下面的图片我标错了,应该是1003是master,带五角星的是master,(懒得在关掉在改了)
我们把1001重新执行一下
在1001的配置文件中添加discovery.seed_hosts: [“127.0.0.1:9301”,“127.0.0.1:9302”]
因为我们之前以1001为master,但是现在1001挂了,我们就要去连接新的master,不然启动不成功
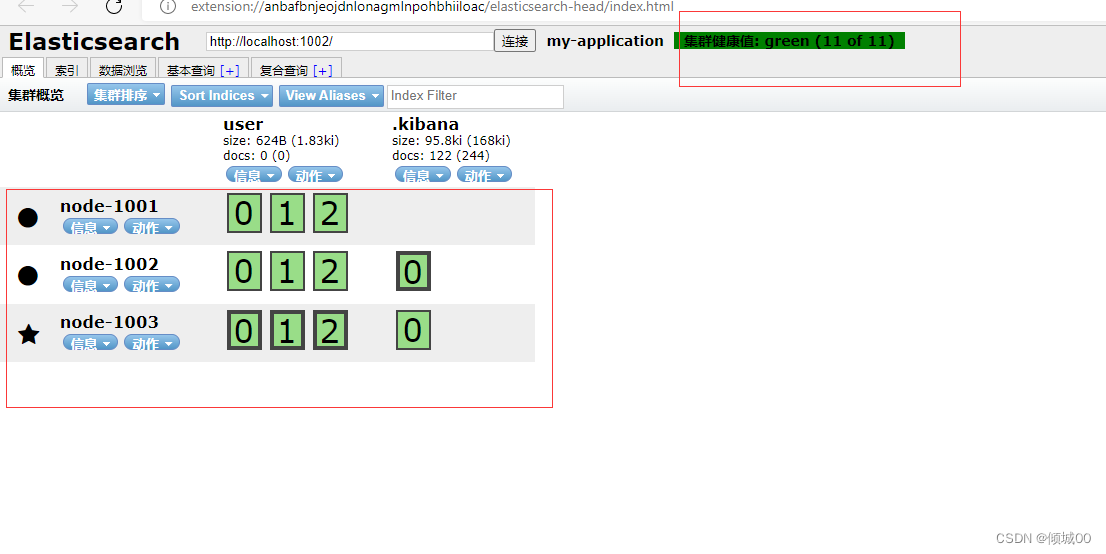
大功告成
4.3.5 master选举
当我们的主master下线了是如何重新选举新的master呢?
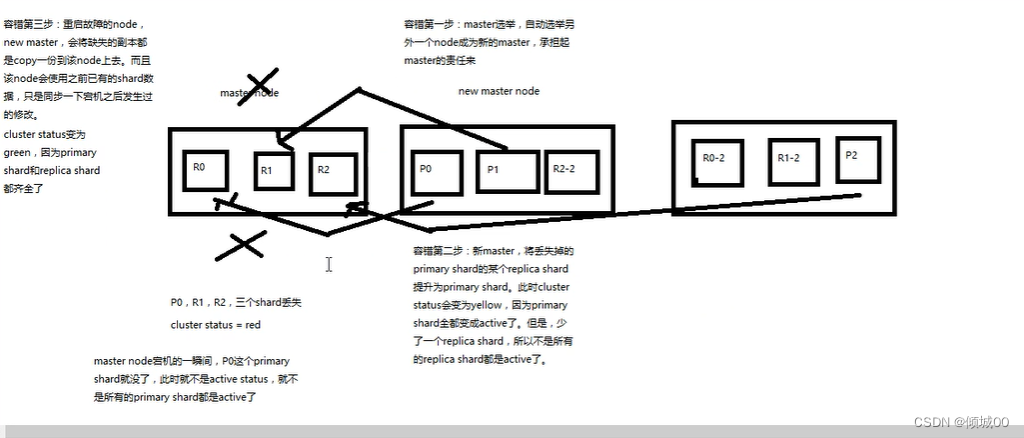
4.3.6 路由计算&分片控制
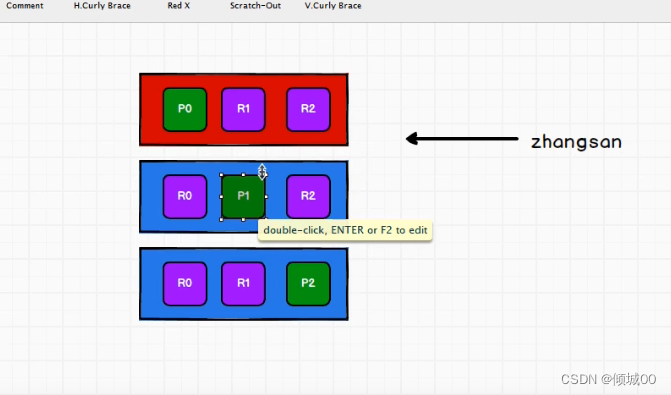
我们看图来想这样的一个问题,这是3个节点1001,1002,1003然后1个主分片,2个副本分片,我们的zhangsan这个数据是怎么存进去的?
1)首先我们的数据是存再主分片的,副本是用来备份的,我们去保存数据,肯定要在主分片上,可是如何知道数据是保存在哪个主分片上的
1.1)随便给一个,假设我们把数据给p2了,我们取数据,在p1取肯定是取不到的,这种肯定是行不通的
2)那么增加数据和查询数据等操作他肯定是有一个规则的,我们把这种规则叫做路由计算
3)路由计算的小共识:hash(id)%主分片数量=【0,1,2】,我们的计算结果到底是0呢还是1呢还是2呢,我们的数据从哪里放在哪里取都要靠这个路由计算
4)我们取数据的话用户其实可以访问任何一个节点,因为如图2的话,任何一个节点上都有数据,但是也不能一直访问一个,是有轮询的规则的
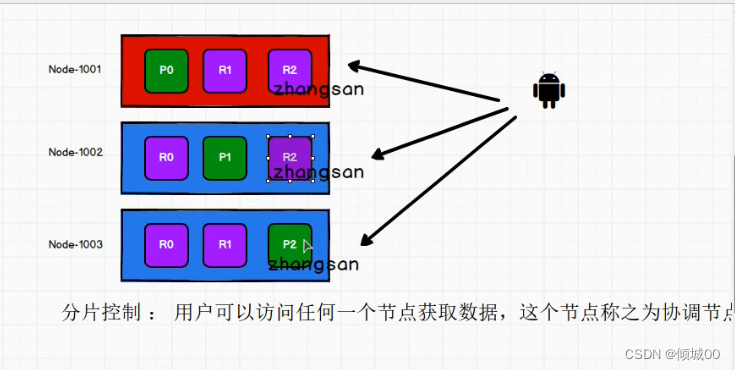
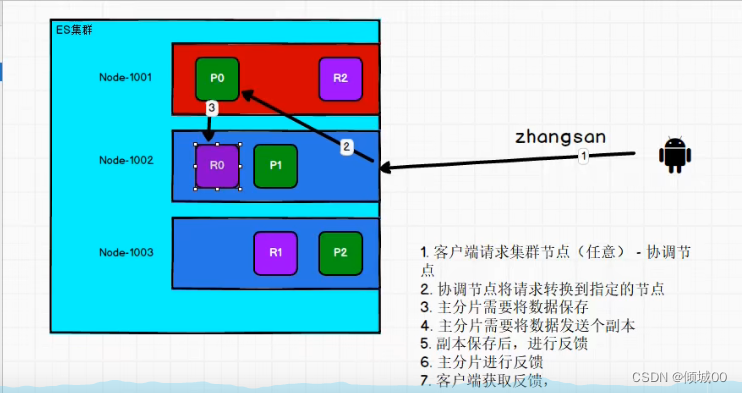
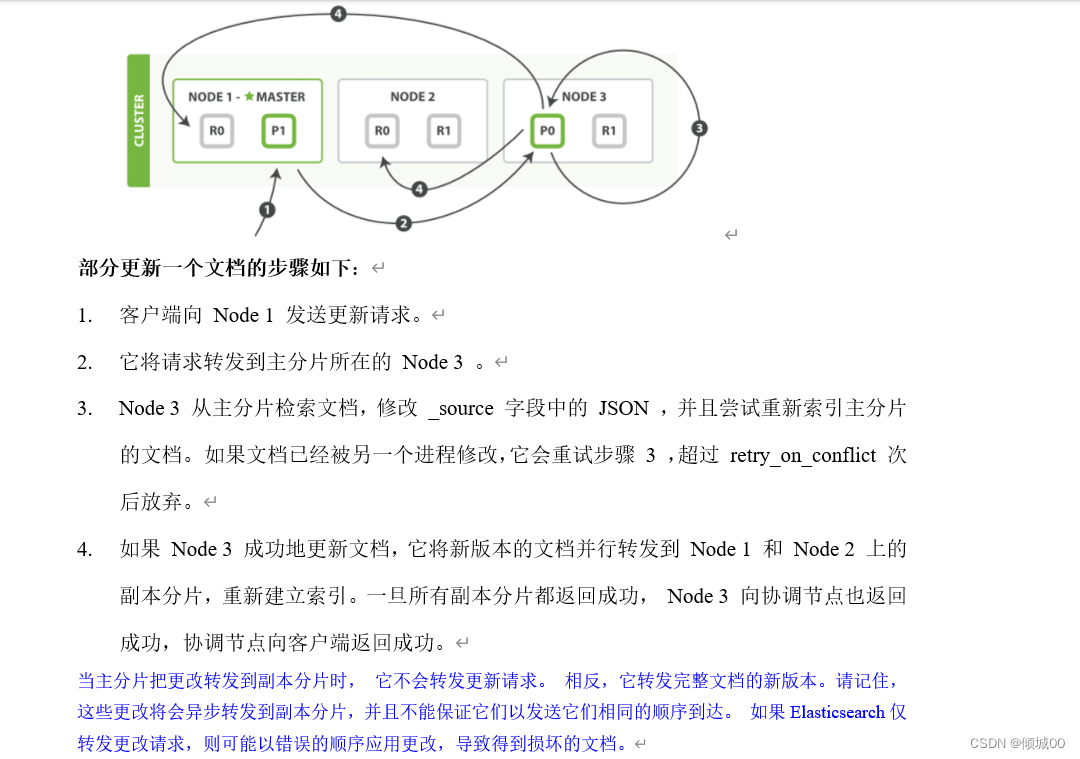
4.3.7 数据的写入
用户想要写入数据,写入zhangsan,他是连接哪台机器的,用户是不知道存在哪里的,是到了集群中才知道的,数据到了集群,算出id啊hash值啊以及取运算之后的位置,发现是我们的1,可能我们连接的是1002,但是经过计算之后我们发现我们的数据应该去p0之中,就会将数据发送到P0之中去,当我们把数据写入到p0中,副本也需要写数据,写完了之后副本会告诉p0我写完了,p0再去告诉我们的客户端说我写完了
4.3.8数据的读取
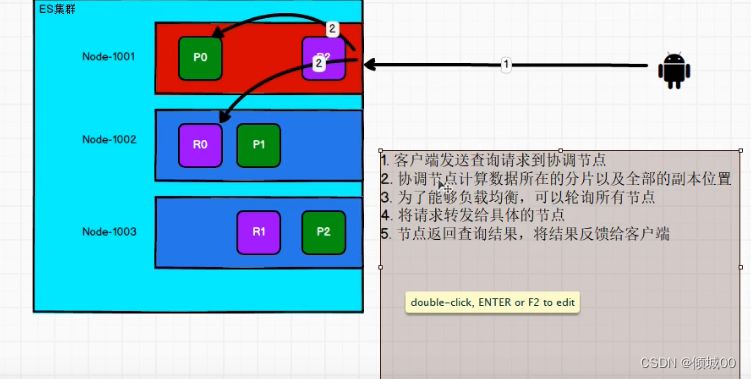
我们的数据进行查询,是怎么查询的呢?
加入说我们连接的是1001,整好我们想查询p0,但是就直接从p0查询?
并不是这个样子的他会进行一个po和r0的轮训查询
4.8.9更新流程
4.8.10文档搜索&合并&刷新&刷写&分析&控制(未写)
五:Elasticsearch入门(第二章)
5.1_id的手动生成与自动生成
1.手动指定id
根据应用情况来说是否满足手动指定document id的前提
一般来说,是从某些其他的系统中,导入一些数据到es中,会采取这种方式,就是使用数据库中已有的数据唯一标识,作为es中document 的id,例如:开发一个电商网站,做搜索的功能,或者是oA系统,做员工检索功能,这个时候,数据首先会在网站系统内部的数据库中,这时我们肯定会有一个数据库的主键id,我们将数据导入到es中,此时就比较适合采用数据在书库中已有的主键
POST /user/_create/1
{
"name":"zhagnsan"
}
如果说,我们在做一个系统,这个系统主要是数据存储,就是es的一种,也就是说数据生产之后,可能没有id,直接就放es的一个存储,name这个时候可能就不太适合手动指明id了,因为你也不知道id是什
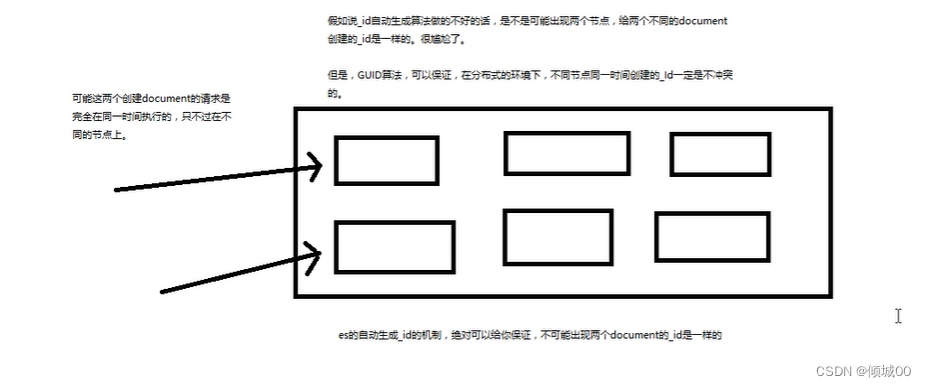
2.自动生成id
POST /user/_doc
{
"name":"lisi"
}
自动生成的id,长度为20个字符,URL编码,base64编码,GDID,分布式系统并行生成时不会发生冲突.
5.2_score元数据
{
“_index” : “user”,
“_type” : “1”,
“_id” : “1”,
“_score” : 1.0,
“_source” : {
“name” : “zhagnsan”
}
}
_source元数据,也就是说,我们在创建一个document的时候,使用的那个放在request boby中的json字符串,默认情况下,在get的时候,会原封不动的给我们返回回来,如果我们想返回部分数据应该怎么解决
GET /user/_search
{
"_source": ["name"]
}
以为我们的user只有一个field,如果想返回多个fiield的话,在‘“[ ]“”中用逗号隔开即可
5.3document的变量与替换
POST /user/_doc/1
{
“name”:“lisi”
}.
我们指定了id为1的数据添加lisi,如果id为1的数据存在会进行替换
通过查看版本号,第一个创建时1,这里我现实4是因为已经修改过3次了。
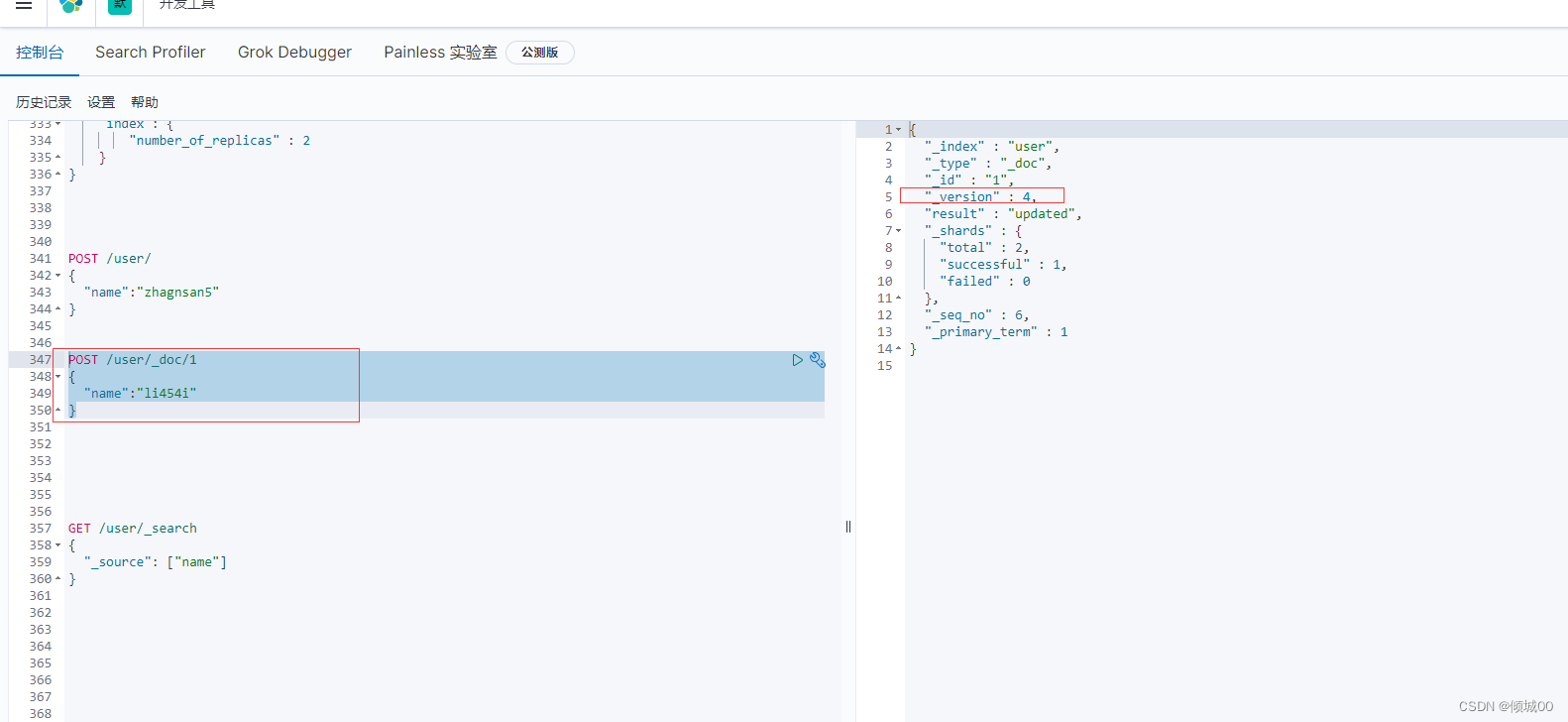
替换的原理:我们原来的数据是id=1 name =list 我们将这条数据称为doc_1
然后我们发送一个修改替换的请求,id=1 name=lisi555;我们将这条数据称为doc_2
我们进行发送数据,doc_1的状态是delete状态,我们去查询数据的时候发现id=1,我们就去查询doc_2,因为doc1的状态是delete状态,但是还没有删除。
当我们的es数据越来越多,es会在后台将标记称delete的数据都给物理的删除掉,以释放空间
5.4document的删除
我们删除一个document的时候,同理会将数据标记为delete状态,查询是查询不到的,我们的es数据越来越多,es会在后台将标记称delete的数据都给物理的删除掉,以释放空间
5.5Elasticsearch的数据并发问题
并发是一个很常见的问题,下图例:购买牙膏,2个线程,线程A和线程B,线程A-B读取的数据都是100件,线程A去购买然后返回结果是99件,线程B当时读的数据还是100件,去修改数据,返回结果还是99件,很显然这个结果不止我们想要的,我们想要的结果是,线程A去操作变成99,线程B去操作,变为98。我们如何结局呢?请继续从下看,悲观锁和乐观锁

5.5.1悲观锁
悲观锁,顾名思义就是每次执行都上锁,我们牙膏还是100件,我们的线程1去读数据,读取的数据是100,然后线程B去读,但是读不到数据,因为悲观锁的缘故,上锁了,我们线程1拿着100件牙膏去操作,操作完成返回数据是99件,然后线程B就可以读取到数据了,读到的数据是线程A修改之后的数据99件,然后线程B拿着99去操作,返回结果是98件,悲观锁,就是悲观的,每次都上锁,这样保障了线程的安全

5.5.2乐观锁
乐观锁 顾名思义就是很乐观,每次都不加锁,es默认是使用饿的乐观锁去保证数据安全的
既然每次都不加锁是如何保证数据的安全呢,es中有一个版本号也就是version的概念,初始化的version=1,然后2个线程去读这100件商品,都拿到的是100,version都=1,然后线程A去拿着这100去操作,返回的数据是99,去修改,判断version是不是和我的version一样,一看我的version是1,,完全一样,然后重新赋值,库存变为99,同时修改版本号,版本号变为version=2,然后咱们的线程B既然读到的数据也是100,线程B也是拿这100去进行操作,操作完返回数据变为99,然后去判断version是不是等于1,发现version由于线程A已经修改了,已经变为2了,此时就不去更新,重新读取version2的信息,然后拿着重新读取的version2的信息,库存等于99去操作,对这99-1变为98,然后去修改。同时version变为3,这样即可保证数据的安全问题
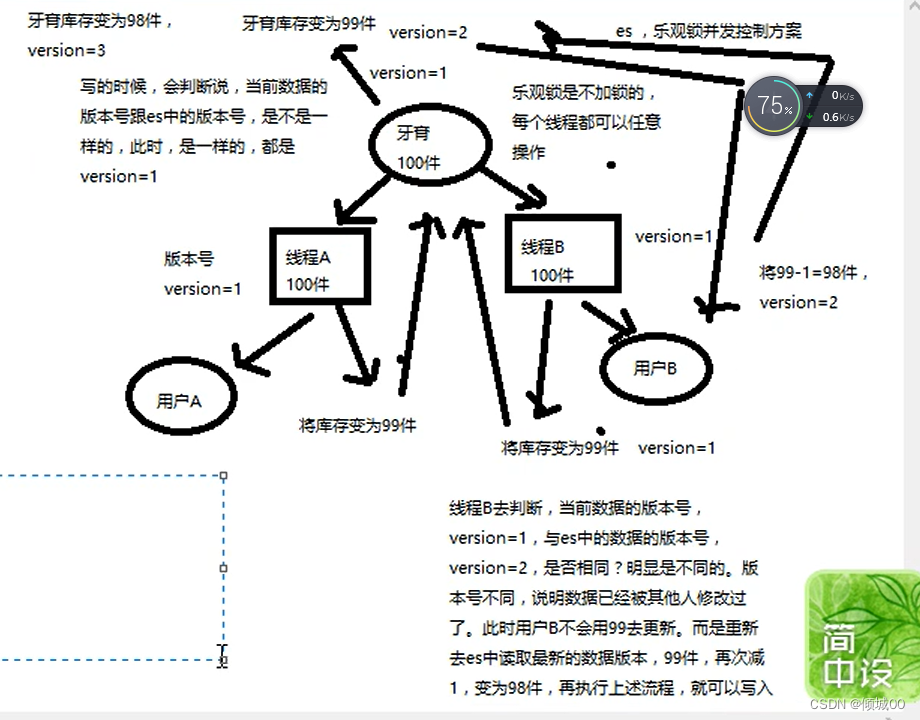
5.5.3悲观锁&乐观锁
悲观锁的优点是直接加锁,对于应用程序来说,透明,不需要做额外的操作,缺点:并发能力低,一次只能一个线程去操作
乐观锁的优点是并发能力高,不给数据加锁,大量数据并发,缺点:麻烦,每次数据更新的时候都要先比对版本号,然后需要重新加载数据,再次修改,在写,这个过程,可能重复好几次
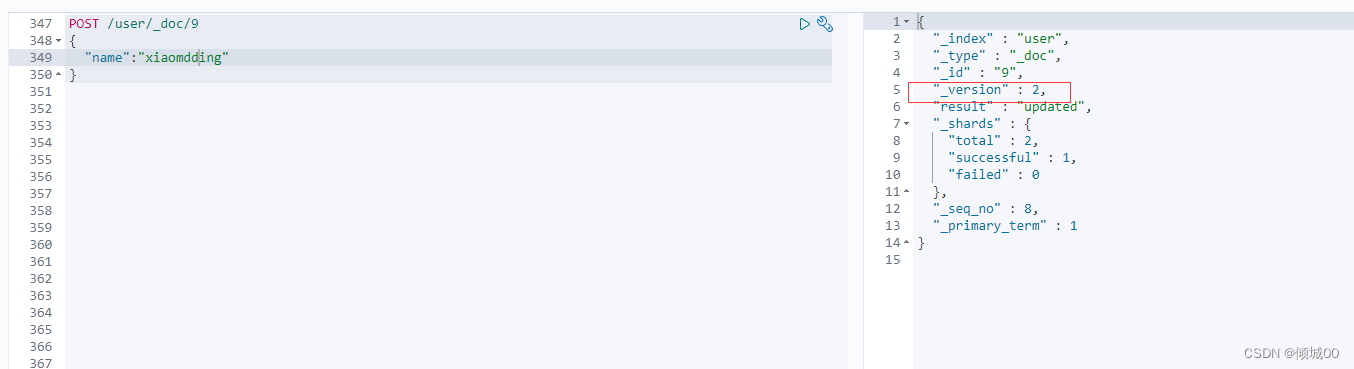
5.5.4Version补充
我们第一张图创建一个document的时候,他的version是1
第二张图是修改替换,他的version是2
第三张图是删除,他的version是3
第四章图是在重新创建,因为已经删除了查不到数据,所以重新创建,出现了一个问题:为什么他的versin是4,而不是重头开始是1,这就印证了我前面写的,删除一条数据,是把数据标记为delete状态,等着es去自动的物理删除,所以我们删除之后查询不到数据,但是他并没有直接去删除,当我们创建一个id一样的,这条数据就又回来了



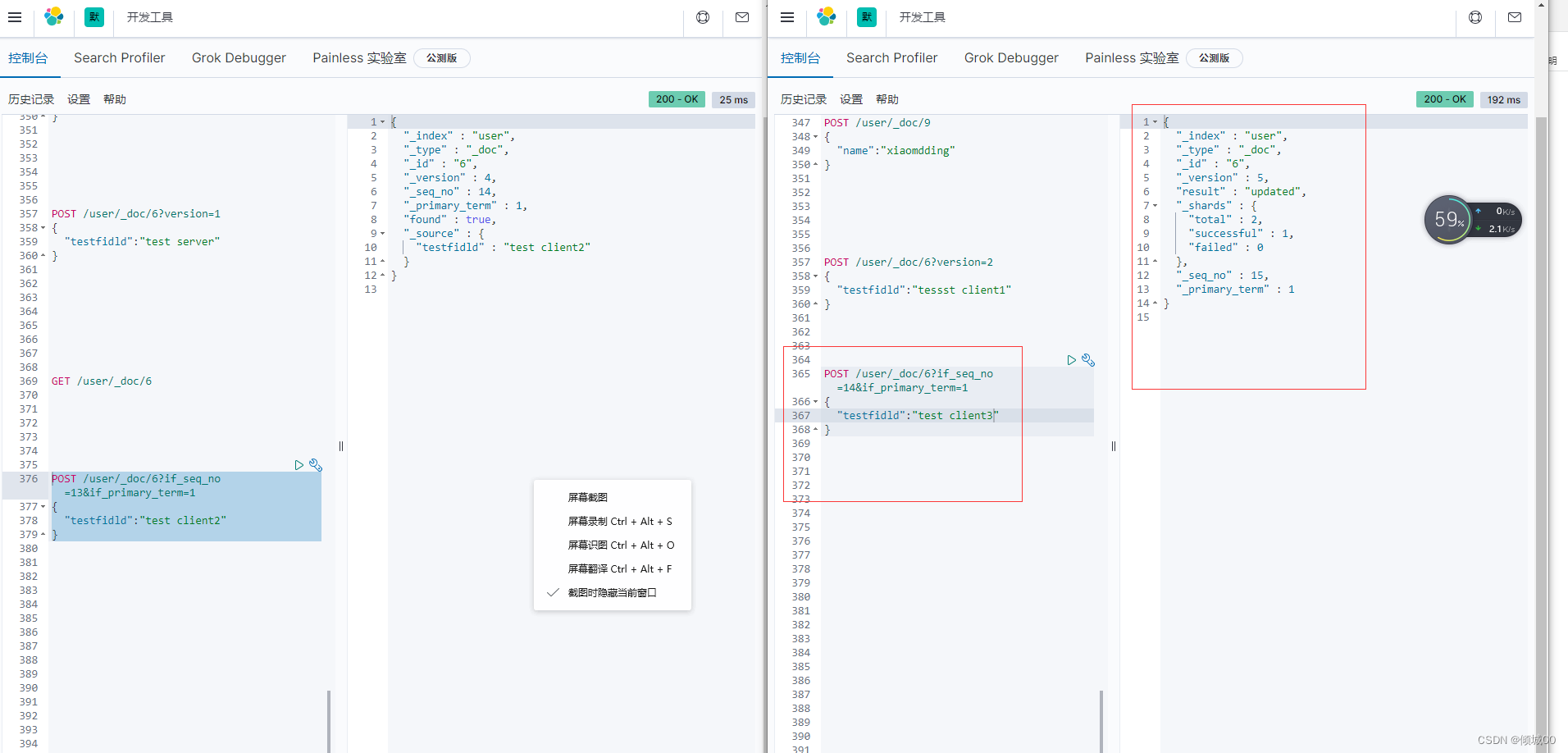
5.54动手演练实现乐观锁保证数据安全
前言:提前说明改一下,咱们目前的版本是不支持?version进行乐观锁进行试验的
替换成了_seq_no和_primary_term,不过和version的实现原理是一样的
1.开2个控制台,直接把uri复制一份即可
2.创建数据,创建完成之后版本号是1
POST /user/_doc/6
{
“testfidld”:“test server”
}
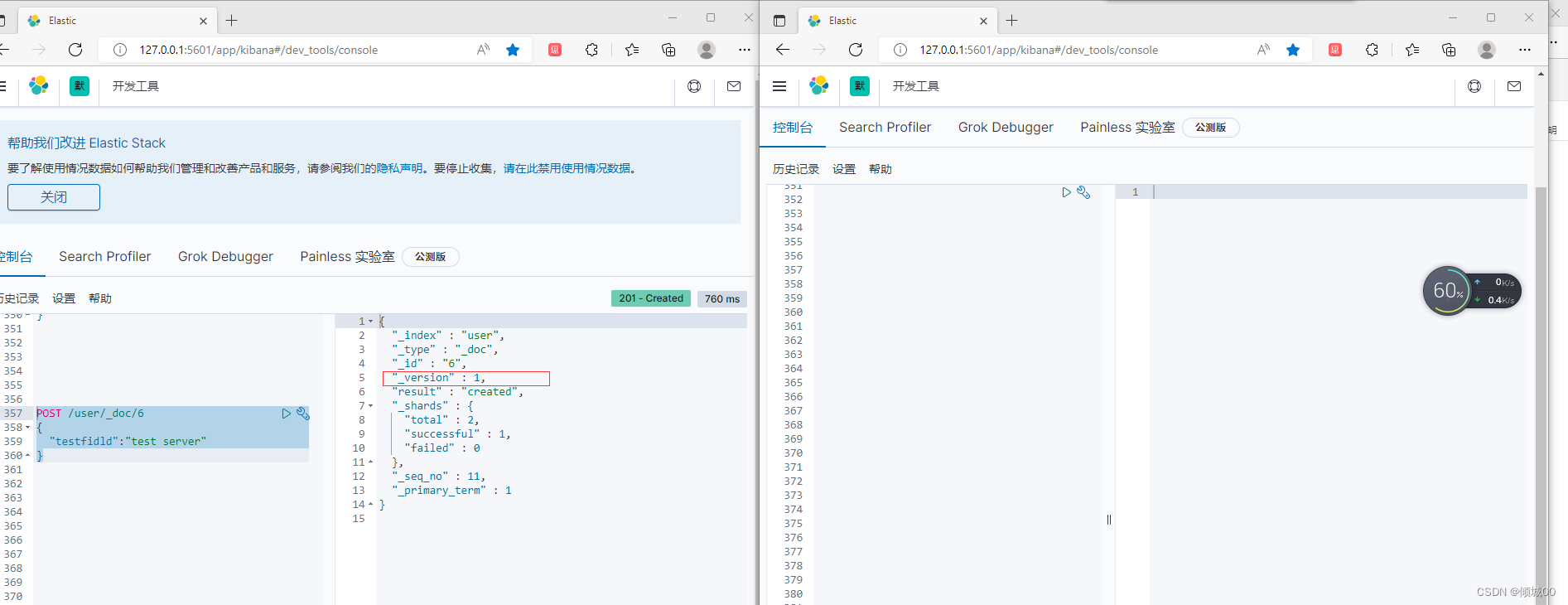
2台查询的全部一样
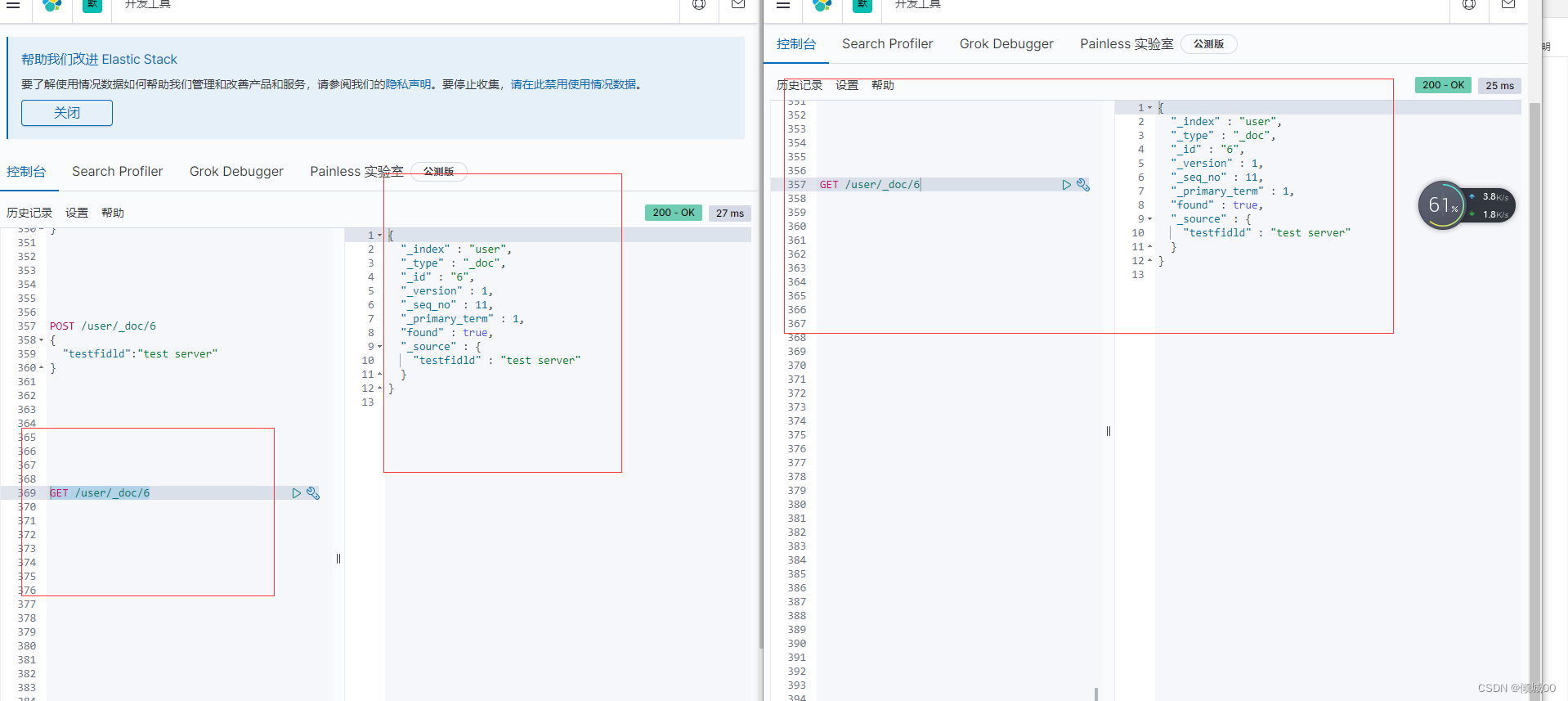
一些老的版本es使用version,但是新版本不支持了,会提示我们用if_seq_no和if_primary_term
我们是7.5版本的应该看这里,对其进行修改

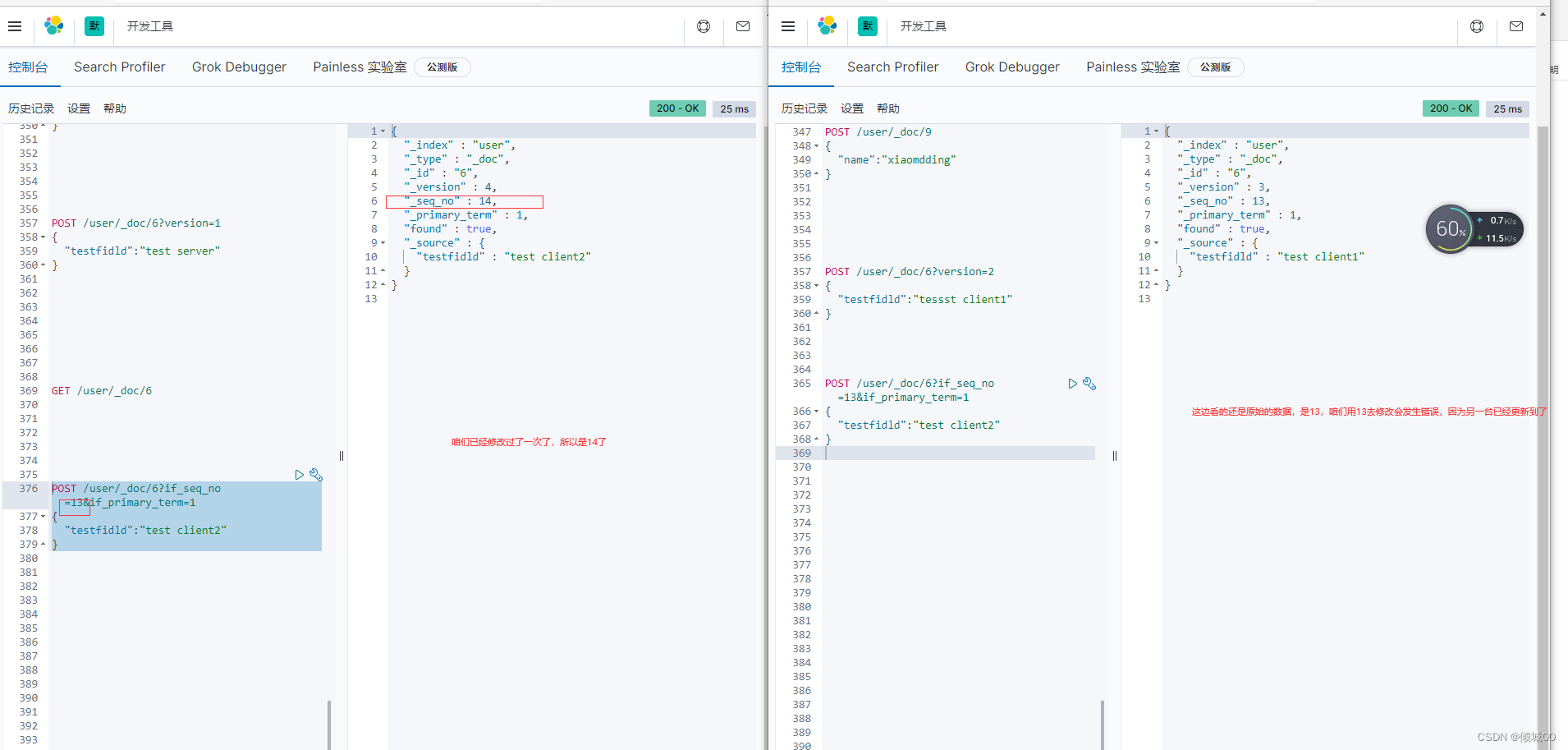
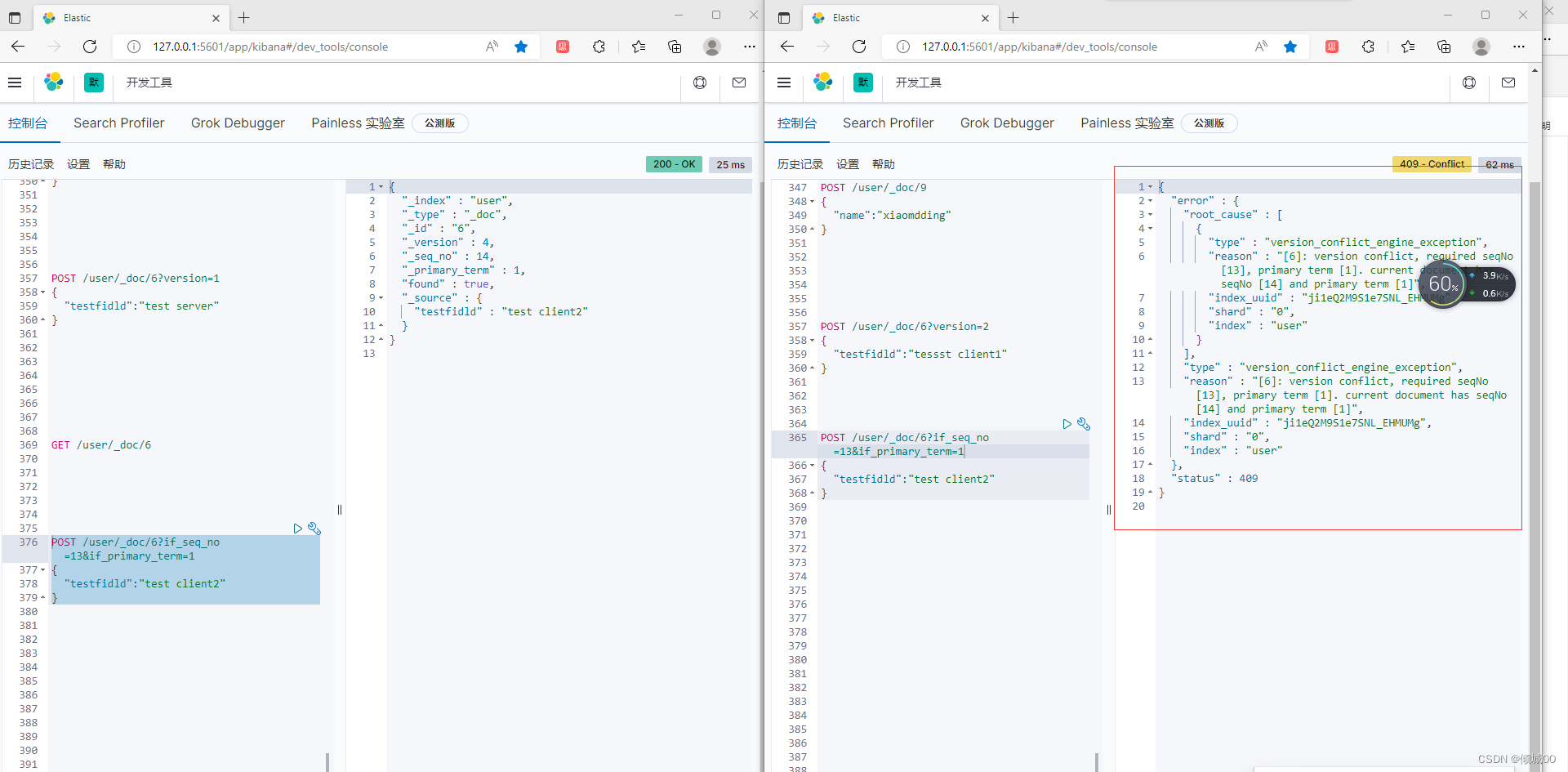
如上,会发生错误,咱们附带正确的去修改即可修改成功
POST /user/_doc/6?if_seq_no=14&if_primary_term=1
{
“testfidld”:“test client3”
}
5.6深度分页问题(Deep paging)
从10万名高考生中查询成绩为的10001-10100位的100名考生的信息。
假设10万名考生的考试信息被存放在一个exam_info索引中,由于索引数据在写入是并无法判断在执行业务查询时的具体排序规则,因此排序是随机的。而由于ES的分片和数据分配策略为了提高数据在检索时的准确度,会把数据尽可能均匀的分布在不同的分片。假设此时我们有五个分片,每个分片中承载2万条有效数据。按照需求我们需要去除成绩在10001到10100的一百名考生的信息,就要先按照成绩进行倒序排列。然后按照page_size: 100&page_index: 101进行查询。即查询按照成绩排序,第101页的100位学员信息。
单机数据库的查询逻辑很简单,先按照把10万学生成绩排序,然后从前10100条数据数据中取出第10001-10100条。即按照100为一页的第101页数据。
但是分布式数据库不同于单机数据库,学员成绩是被分散保存在每个分片中的,你无法保证要查询的这一百位学员的成绩一定都在某一个分片中,结果很有可能是存在于每个分片。换句话说,你从任意一个分片中取出的前10100位学员的成绩,都不一定是>总成绩的前10100。更不幸的是,唯一的解决办法是从每个分片中取出当前分片的前10100名学员成绩,然后汇总成50500条数据>再次排序,然后从排序后的这50500个成绩中查询前10100的成绩,此时才能保证一定是整个索引中的成绩的前10100名。
5.7 mapping(核心知识)
创建我们需要的数据
PUT website
POST website/_create/1
{
"post_data":"2017-01-01",
"title":"my first-article",
"content":"this is my first article in this website",
"author_id":11400
}
POST website/_create/2
{
"post_data":"2017-01-02",
"title":"my second article",
"content":"this is my second article in this website",
"author_id":11400
}
POST website/_create/3
{
"post_data":"2017-01-03",
"title":"my third article",
"content":"this is my third article in this website",
"author_id":11400
}
我们搜索一下 “post_data”: "2017-01-01"和 “post_data”: "2017"发现结果都是一样的,这是为什么呢
GET website/_search
{
"query": {
"match": {
"post_data": "2017-01-01"}}
}
GET website/_search
{
"query": {
"match": {
"post_data": "2017"
}
}
}
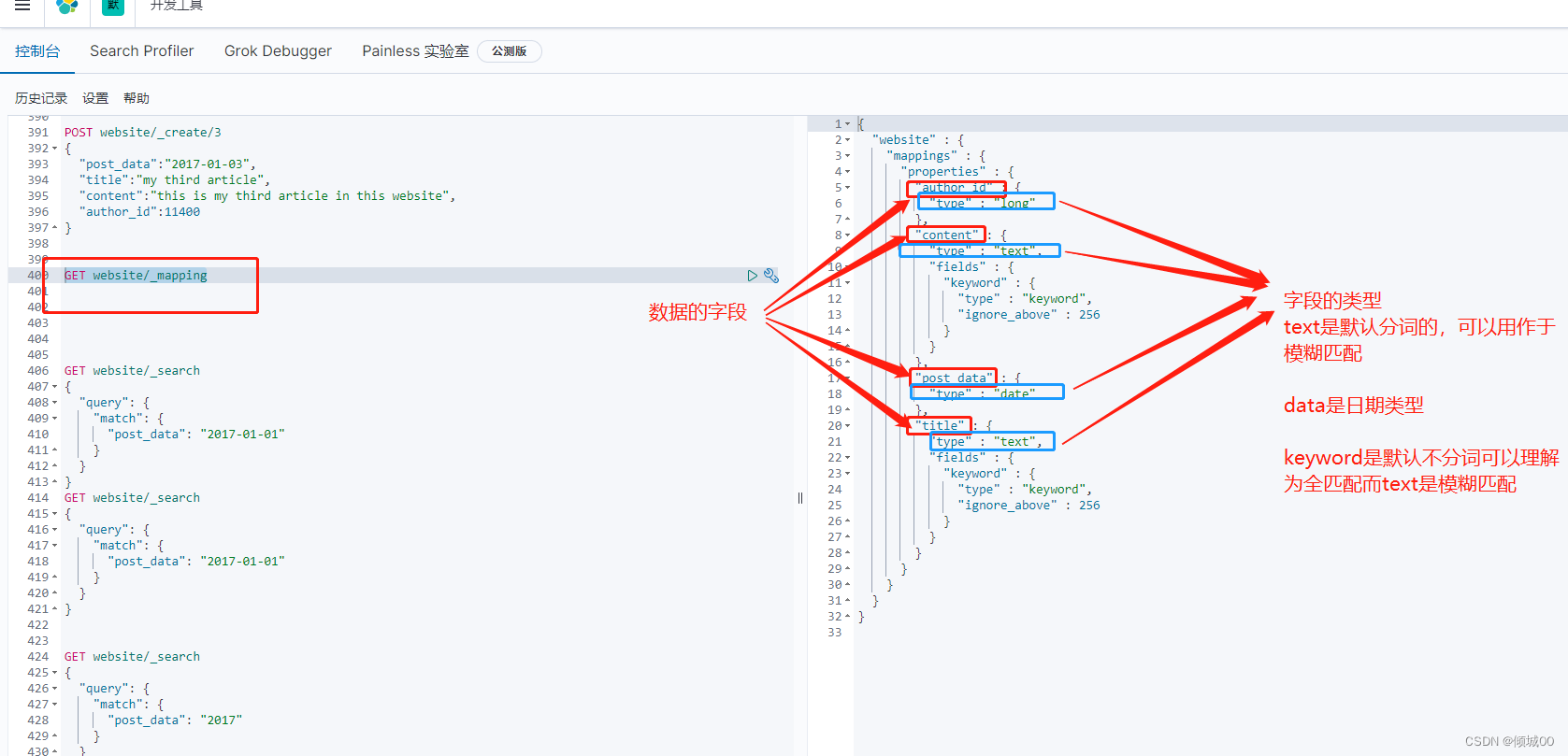
我们去创建一条索引的时候,es会主动根据存入的数据进行分配数据类型,
GET website/_mapping 用本条命令去查看索引
我们看如下图,猛的一看可能看不懂,总结的说一下,es会分配数据类型常用的
text是默认的,是分词的
keywoed是不分词的
daa是日期的
我们带着疑问继续从下看,一点一点说
5.7.1精准匹配与全文搜索
1)exate value
我们有一条数据 2017-01-01 exate value,搜索的时候,必须输入2017-01-01才能搜索出来,如果只数据01搜索不出来,这就是我上面说的默认不分词(不分词)
2)full text
我们有一条数据 2017-01-01,es会将其拆分为2017 01 01 我们搜索2017你呢搜索出来数据,我们搜索01页可以搜索出来数据,就不是说单纯的去匹配一个值,而是对值进行拆分后(分词)进行匹配
我们有数据:china,搜索chin也可以搜索出数据(分词)
我们有数据:China,搜索chin可以搜索出数据(大小写)
我们有like ,搜索love,也可以搜索出来(同义词)
5.7.2 倒排索引的核心原理
假设我们给出2行数据
doc1:I liked dogs
doc2:I dont liked dogs (以上两句话是我自由发挥的)
接下来我们进行分析,装入倒排索引中
数据- - - - doc1 – – – doc2
I – – – ---- * -----------------*
liked--------* ------------------*
dogs------- * ----------------- *
dont ---------------------------*
我这个有点丑,但是能看懂就行,我们进行分词
我们去匹配“ my like dog”但是不会匹配到数据
搜索不出来我们想要的结果,在我们看来,liked和like有区别吗?都是喜欢的意思,dog和dogs有区别吗?都是狗,不过一个是单数,一个数复数
normalization
1)es在创建索引的时候,会执行这个操作也就是对拆分的单词进行处理,以提升后面搜索的时候能够搜索出响应的的文档的概率
2)normalization用于时态的转换,单复数的转换,同义词的转换,大小写的转换
3)如何进行转换的
liked可以转成like
dogs 可以转成dog
我们重新去建立倒排索引给他增加一个normalization的过程
数据- - - - doc1 – – – doc2
I – – – ---- * -----------------*
liked--------* ------------------* liked–>like
dogs------- * ----------------- * dogs–>dog
dont ---------------------------*
我们去匹配“ my like dog” 结果是doc1和doc2都可以匹配到,我抽象的描述了一下,就是es执行了normalization进行一提高搜索概率
看不懂的戳:给大家网上找了一篇容易看懂的
5.7.2 分词器
什么是分词器
切分短语,normalization(提升召回率)
给你一段句子,然后将句子拆分为一个一个的单词,对每个单词进行normalization(时态转换,单复数转换等)
召回率:搜索的时候增加能够搜索到结果的数量
character filter:在一段文本进行分词之前会进行预处理,常见的有过滤html标签,(< span> helllo </ span> —>hello ),(I&you -->I and you )
tokenizer:分词,hello you and me .,拆分为hello ,you,and,me
token filter:进行时态转换,单复数转换等(Ser–>ser)(dogs–<dog)等
一个分词器很重要,将一段文本进行各种处理最后处理好的结果才拿去倒排索引
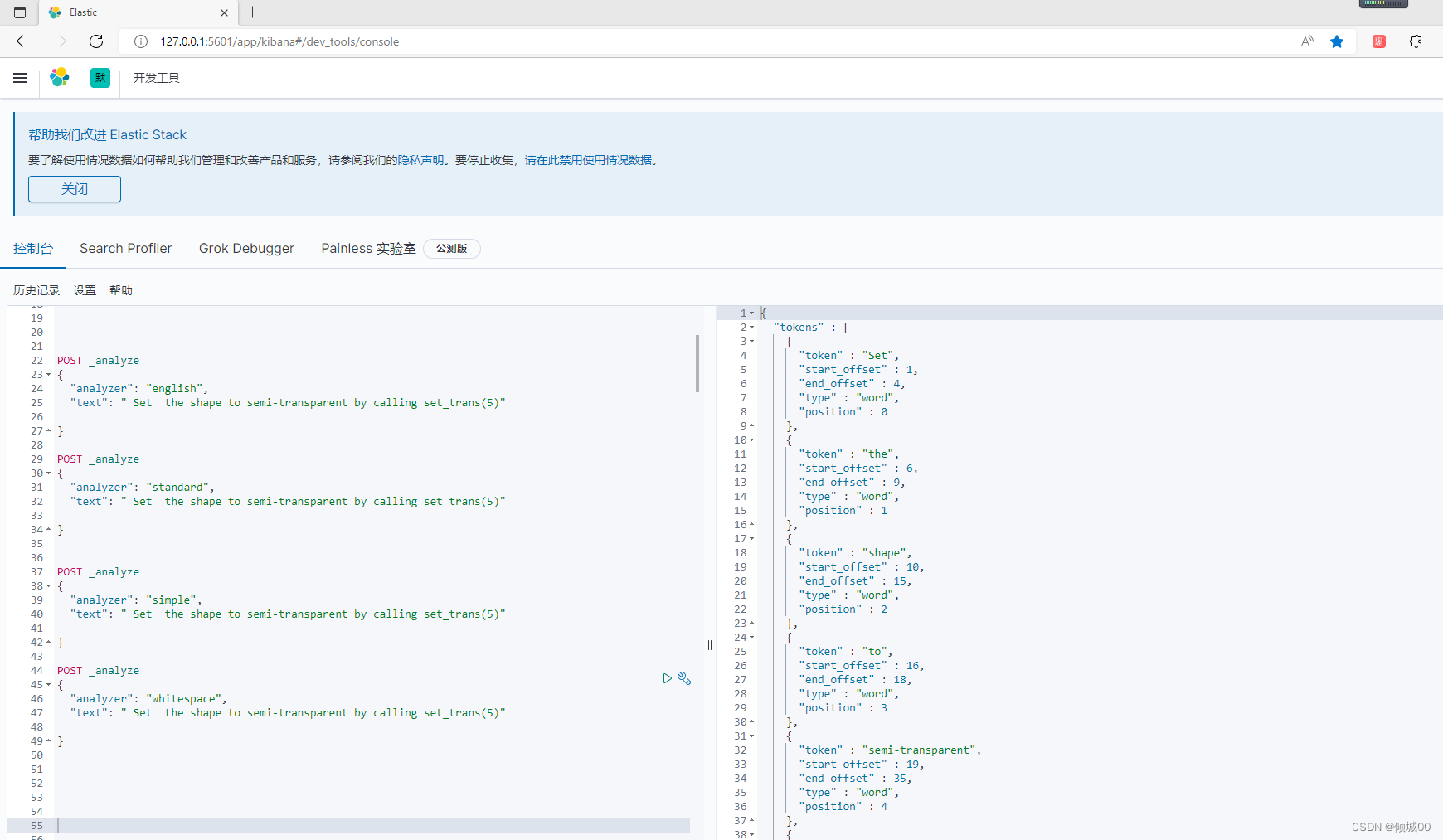
es的内置分词器:
Set the shape to semi-transparent by calling set_trans(5)
第一种:
1)standard analyzer:set ,the shape ,to ,semi,transparent,by,calling ,set_trans,5(我们可以看到按空格拆分,将- ( ) 进行一个过滤,大小写转换等操作)
2)simple analyzer:set ,the shape ,to ,semi,transparent,by,calling ,set,trans(我们可以看到按空格拆分,将- ( ) 进行一个过滤,大小写转换等操作,将_拆分)
3)whitespace analyzer:Set ,the shape ,to ,semi-transparent,by,calling ,set_trans,(5)(只根据空格拆分)
4)language analyzer:(特定语言的分词器,english;英语分词器) set shape,semi.transpar,call,set _trans,5(把一些停用词干干掉了,按照-分词,空格分词,大小写转换)
推荐动手实战一下
POST _analyze
{
"analyzer": "english",
"text": " Set the shape to semi-transparent by calling set_trans(5)"
}
#standard
#simple
#whitespace
5.7.2 mapping
- 在es里面直接插入数据,es会自动建立索引,同时建立对应的type和mappping
- mapping中定义了每个filed的数据类型
- 不同的数据类型(比如说text和data)可能有的是exact value,有的是full text
- exact value,在建立倒排索引的时候,分词的时候,是将整个值一起作为一个关键词建立到到倒排索引中,full text 会经历各种各样的出来,分词,normalization(时态转换,同义词转换,大小写转换),才会建立在倒排索引中
- 同时呢,exact values和full text 类型的field就决定了一个搜索过来的时候,对exact values或full text搜索的结果也是不一样的,会跟建立倒排索引的行为保持一致;比如exact value搜索的时候,就直接按照整个值进行匹配,full text也会进行分词和normalization再去倒排索引中搜索
- 可以让es自动的建立mapping,让其自动建立mapping,包括自动建立数据类型,也可以提前手动创建index和mapping,自己对field进行设置,包括数据类型包括索引行为,分词器,等等
基本数据类型
true && false -->boolean
123–>long
123.45–>double
2017-01-01–>data
“hello woed” -->text
查看mapping,
get 索引名/_mapping
5.7.2 .1自己手动创建索引之指定mapping
DELETE website 创建之前先删除索引
我们下面创建的索引,自己指定mapping
author_id类型long
title 类型text(分词),分词用的是english,默认设置text的分词是standard
contentl类型(分词)
post_data类型(data)
publisher_id类型keyword (不分词,全匹配才能匹配到数据)
PUT website
{
"mappings": {
"properties": {
"author_id" :{
"type": "long"
},
"title":{
"type": "text"
, "analyzer": "english"
},
"content":{
"type": "text"
} ,
"post_data" : {
"type" : "date"
},
"publisher_id":{
"type": "keyword"
}
}
}
}
5.7.2 .2自己手动创建索引之添加mapping
PUT website/_mapping
{
“properties”: {
“tags”:{
“type”:“text”
}
}
}
GET website/_mapping 去查看一下mapping

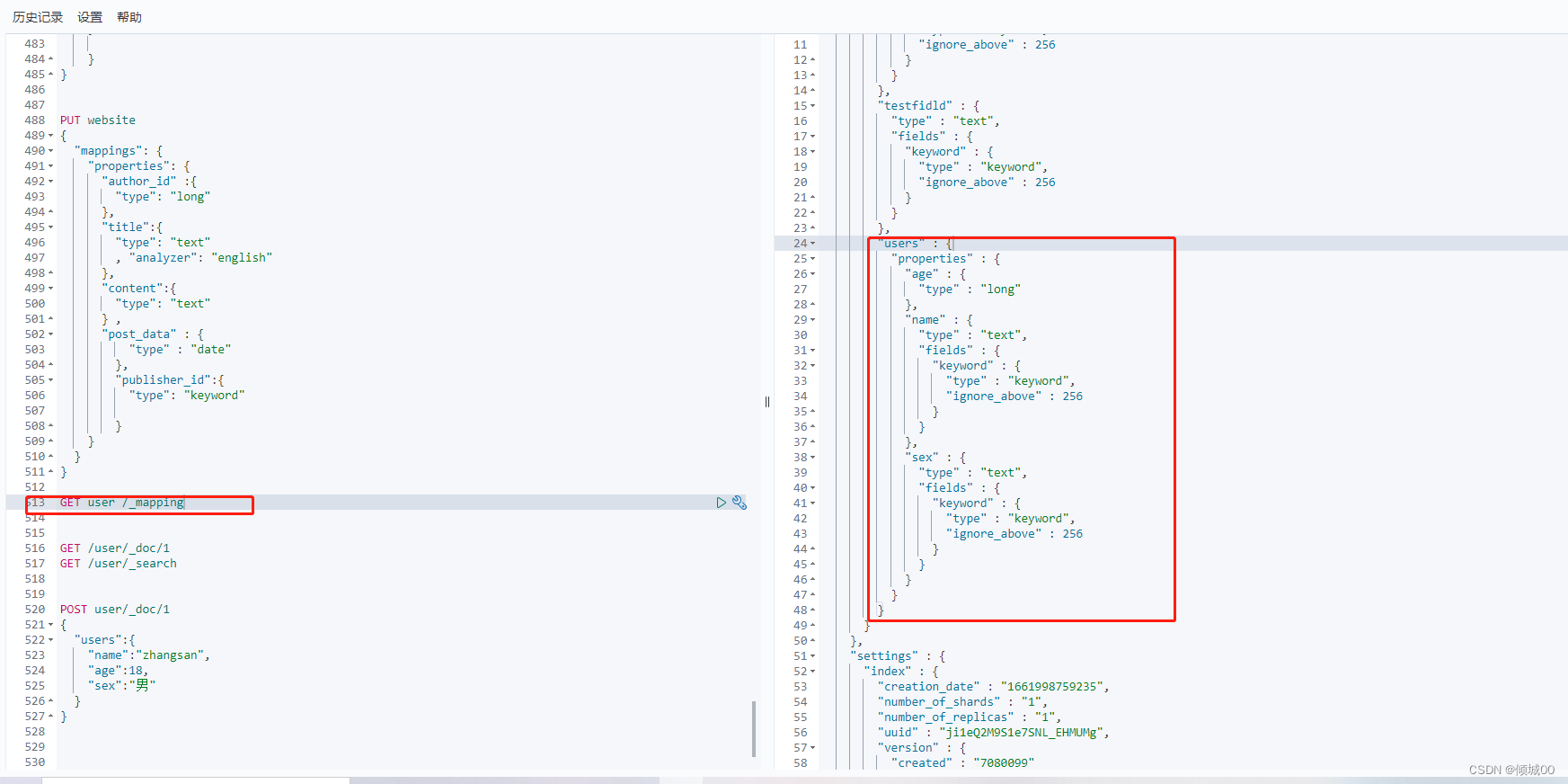
5.7.2 .2自己手动创建索引之mapping的object类型
我们如下的去添加数据,就是object数据类型的
POST user/_doc/1
{
“users”:{
“name”:“zhangsan”,
“age”:18,
“sex”:“男”
}
}
六:Elasticsearch进阶
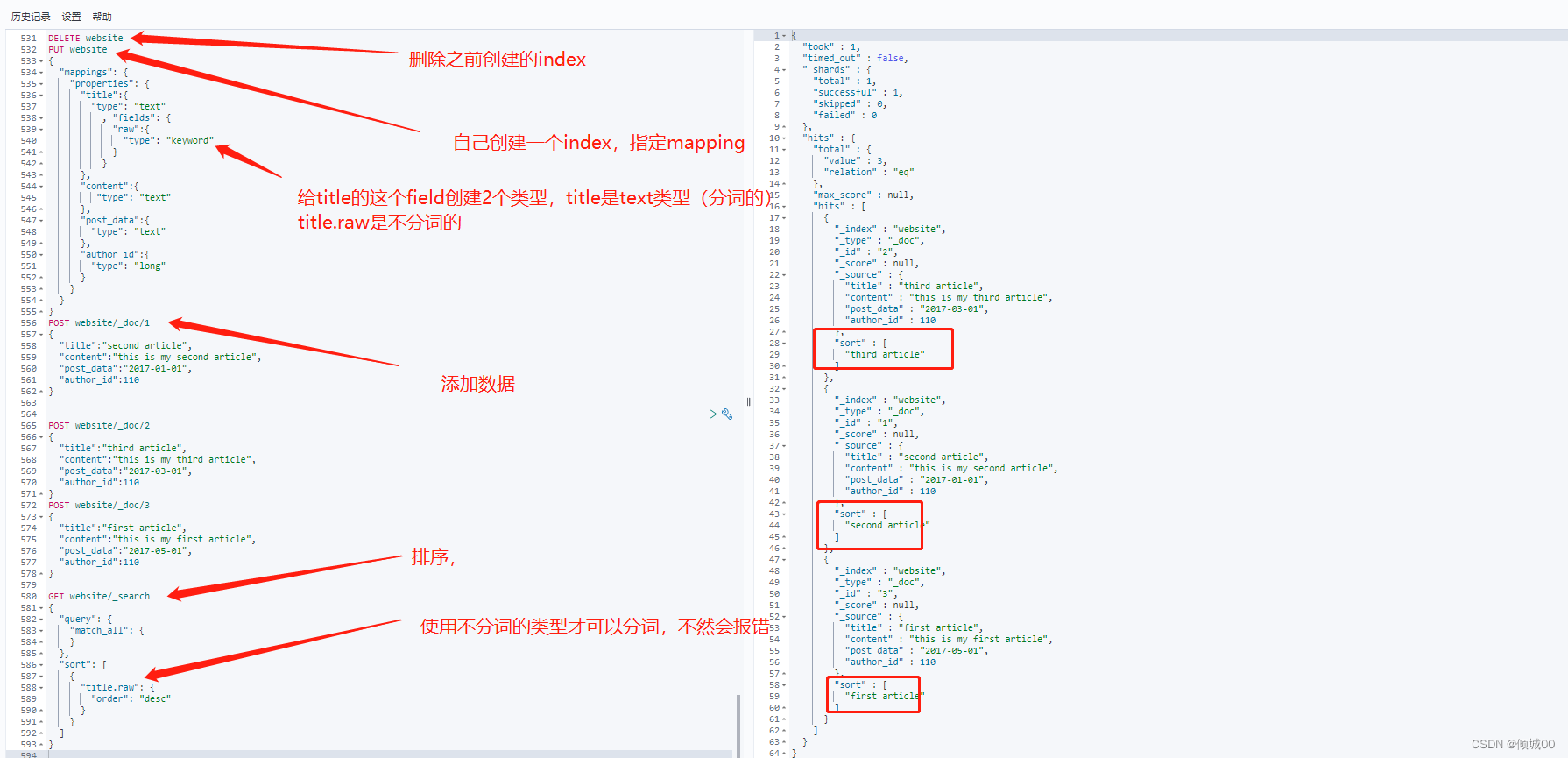
6.1排序(文本排序)
我们的日期,数字可以进行排序,那么我们的文本类型是不是可以排序,是可以的
DELETE website
PUT website
{
"mappings": {
"properties": {
"title":{
"type": "text"
, "fields": {
"raw":{
"type": "keyword"
}
}
},
"content":{
"type": "text"
},
"post_data":{
"type": "text"
},
"author_id":{
"type": "long"
}
}
}
}
POST website/_doc/1
{
"title":"second article",
"content":"this is my second article",
"post_data":"2017-01-01",
"author_id":110
}
POST website/_doc/2
{
"title":"third article",
"content":"this is my third article",
"post_data":"2017-03-01",
"author_id":110
}
POST website/_doc/3
{
"title":"first article",
"content":"this is my first article",
"post_data":"2017-05-01",
"author_id":110
}
GET website/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"title.raw": {
"order": "desc"
}
}
]
}
6.1TF/IDF算法(非常重要)
-
es使用的是 term frequency / inverse document frequency算法,简称TF/IDF算法
-
term frequency搜索文本中的各个词条在field文本中出现了多少次,出现的次数越多就越相关
ps:搜索请求是hello word
doc1:hello you and word is you very good
doc2: hello hao are you
doc1是最为匹配的,因为在doc1中既出现了hello ,也出现了word,所以搜索出的结果doc1排在了doc2前面 -
inverse document frequency搜索文本中的各个词条在整个索引文档中出现了多少次,出现的次数越多,就越不相关
ps:搜索请求是hello word
doc1:hello is you
doc2:hello are you
doc3:word is book
hello 在这三个doc中出现了2次,word在这三个doc中出现了1次,doc3更加相关 -
Field-length norm:field长度,field越长,相关度就越弱
ps:搜索请求是hello word
doc1:hello is you 1千个单词
doc2:hello are you 1千个单词 is man
hello在doc1和doc2出现的次数是一样的,但是,doc1是最为匹配的,因为doc1field短,它的相关度就越高
ps:相关度是什么,我们查询出来的数据是有_score分数的,分数越高证明就越相关,它就会优先展示
es里面有算法将以上3中综合的分数就是我们在页面看到展示的数据

的算法很复杂,不能说百分百对,但是核心的知识相差无疑
6.1document数据的写入
- 数据写到buffer中
- es会有一个commit提交的过程
- buffer中的数据写入到新的index segment
- 等待在os cache中的index segment被fsync强制刷到磁盘上
- 新的index segment被打开,供search使用
- buffer被清空
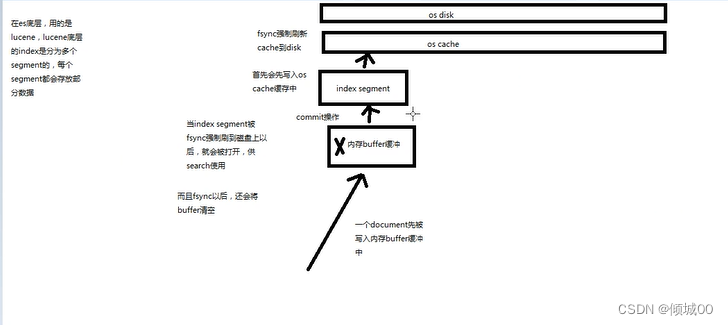
数据被写到document中,会先将数据写入到buffer中,每隔多少时间,或者说内存满了,es会执行一个commit的操作,执行这个commit操作的时候,es会将数据写到一个新的index segment中,先写入到os cache缓存中,然后fsync强制刷新cache到disk ,这样数据就会被强制的刷到磁盘上去,当index segment被fsync强制刷新到磁盘上去,就会被打开,供search使用。刷新之后会将内存buffer清空
##6.2进阶所有需数据
GET forum/_search
POST forum/_doc/1
{
"userID":1,
"hidden":false,
"articleID":"XHDK-A-1293-#FJ3",
"postDate":"2017-01-01"
}
POST forum/_doc/2
{
"userID":1,
"hidden":false,
"articleID":"KDKE-B-9947-#KL5",
"postDate":"2017-01-02"
}
POST forum/_doc/3
{
"userID":2,
"hidden":false,
"articleID":"JODL-X-1937-#pv7",
"postDate":"2017-01-01"
}
POST forum/_doc/4
{
"userID":2,
"hidden":true,
"articleID":"QQPX-R-3956-#aD8",
"postDate":"2017-01-02"
}
6.3 term
shiyong trem进行不分词的查询,直接拿到倒排索引,你搜索的是什么他就匹配什么,因为刚才创建的默认是分词的,所以需要用 .keyword 来让其不分词
POST forum/_search
{
"query": {
"term": {
"articleID.keyword": {
"value": "XHDK-A-1293-#FJ3"
}
}
}
}
6.4 terms
查询多个里面可以匹配多个值
POST forum/_search
{
"query": {
"terms": {
"articleID.keyword": [
"XHDK-A-1293-#FJ3",
"KDKE-B-9947-#KL5"
]
}
}
}
6.5mush & must_not & should
- mush是条件完全匹配 可以理解为and
- must_not 是完全不匹配可以理解为!=
- should是匹配其一即可可以理解为and
6.5.1mush
查询articleID是XHDK-A-1293-#FJ3的和hidden是true的数据,must是必须匹配,没有符合条件的数据,所以匹配不到
POST forum/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"articleID.keyword": {
"value": "XHDK-A-1293-#FJ3"
}
}
},
{
"term": {
"hidden": {
"value": true
}
}
}
]
}
}
}
6.5.2should
查询articleID是XHDK-A-1293-#FJ3的或hidden是true的数据,should是有一个匹配即可,可以查询出来2条数据
POST forum/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"articleID.keyword": {
"value": "XHDK-A-1293-#FJ3"
}
}
},
{
"term": {
"hidden": {
"value": true
}
}
}
]
}
}
}
6.5.3must_not
查询articleID不是XHDK-A-1293-#FJ3的和hidden不是true的数据,must_not是不匹配这两种相等的数据,可以查询出来另外2条数据
POST forum/_search
{
"query": {
"bool": {
"must_not": [
{
"term": {
"articleID.keyword": {
"value": "XHDK-A-1293-#FJ3"
}
}
},
{
"term": {
"hidden": {
"value": true
}
}
}
]
}
}
}
6.5.4练习
查询出articleID是 “XHDK-A-1293-#FJ3” 或者postDate是2017-01-01的但postDate不能是2017-01-02的数据
POST forum/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"articleID.keyword": {
"value": "XHDK-A-1293-#FJ3"
}
}
},{
"term": {
"postDate": {
"value": "2017-01-01"
}
}
}
],
"must_not": [
{
"term": {
"postDate": {
"value": "2017-01-02"
}
}
}
]
}
}
}
6.5.5 嵌套练习
查询 postDate必须是2017-01-02,查询articleID可能是XHDK-A-1293-#FJ3"
或者是 “KDKE-B-9947-#KL5”
POST forum/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"postDate": {
"value": "2017-01-02"
}
}
},
{
"bool": {
"should": [
{
"term": {
"articleID.keyword": {
"value": "XHDK-A-1293-#FJ3"
}
}
},
{
"term": {
"articleID.keyword": {
"value": "KDKE-B-9947-#KL5"
}
}
}
]
}
}
]
}
}
}
6.6range
range 范围查询 查询日期在2017年1月20日之前的数据
POST forum/_search
{
"query": {
"range": {
"postDate": {
"gte": "2017-01-20||-20d"
}
}
}
}
6.7 match
6.7.1 新增数据
POST forum/_update/1
{
"doc": {
"title" : "this is java and elasticsearch blog"
}
}
POST forum/_update/2
{
"doc": {
"title" : "this is elasticsearch blog"
}
}
POST forum/_update/3
{
"doc": {
"title" : "this is java blog"
}
}
POST forum/_update/4
{
"doc": {
"title" : "this is java, elasticsearch, hadoop blog"
}
}
6.7.1 match & operator
查询title有java 或包含elasticsearch的数据(or)
operator中默认为or,不写就是执行默认的or
POST forum/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "or"
}
}
}
}
-常规写法
POST forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "java "
}
},
{
"match": {
"title": "elasticsearch "
}
}
]
}
}
}
6.7.1 match & operator
查询title有java 和elasticsearch的数据(and)
operator中默认为or,不写就是执行默认的or,可以原则修改为and
POST forum/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
}
-常规写法
POST forum/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "java "
}
},
{
"match": {
"title": "elasticsearch "
}
}
]
}
}
}
6.7.3 match & minimum_should_match
查询出最少匹配多少个
:“java elasticsearch hadoop spark”, 查询出最少包含3个的数据
POST forum/_search
{
"query": {
"match": {
"title": {
"query":"java elasticsearch hadoop spark",
"minimum_should_match": 3
}
}
}
}
- bool查询,没有上面的minimum_should_match查询效果好
POST forum/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "java "
}
},
{
"match": {
"title": "elasticsearch "
}
}
],
"should": [
{
"match": {
"title": "hadoop "
}
},
{
"match": {
"title": "spark "
}
}
]
}
}
}
- bool查询,+minimum_should_match 查询效果比上面好
POST forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "hadoop "
}
},
{
"match": {
"title": "spark "
}
},
{
"match": {
"title": "java "
}
},
{
"match": {
"title": "elasticsearch "
}
}
]
, "minimum_should_match": 3
}
}
}
ps:小结论:minimum_should_match 除了后面可以跟1,2,…还可以跟75%,50%…等,
“minimum_should_match”: “75%” 效果和minimum_should_match3 是一样的
6.8 boost
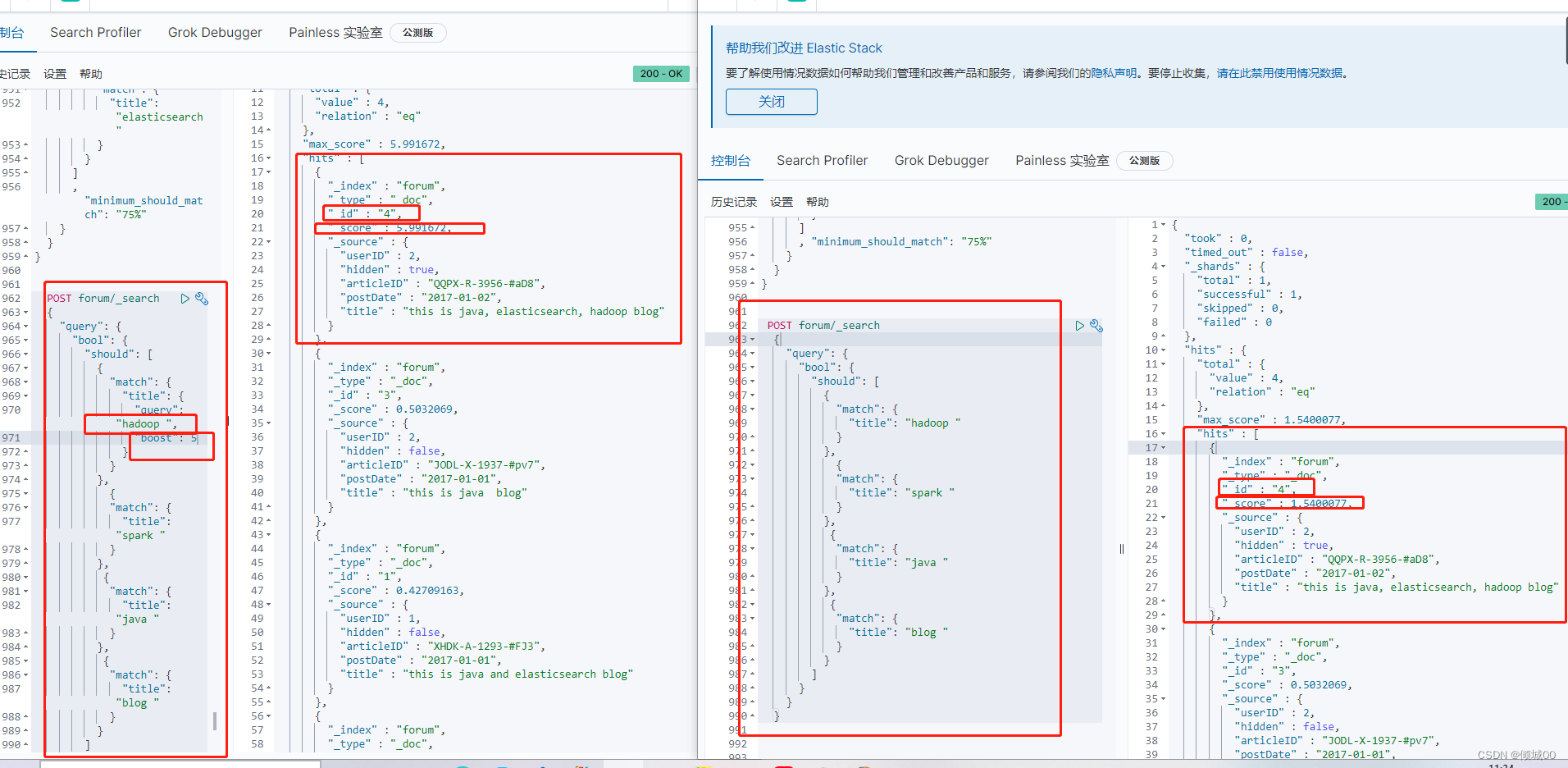
什么是权重:指某一因素或指标相对于某一事物的重要程度,通俗来讲,权重大就优先展示
想包含hadoop的数据优先显示,需要在其后面追加boost 意思是让包含boost的优先显示,后面的值越大就越展示的越靠前
我们想搜索出包含hadoop 或spark 或java 或blog 的数据,但是让包含hadoop的数据优先展示,我们通过下图可以看到,常规的搜索分数是1.5,但是我们加了权重之后,就是让包含hadoop 的优先展示,权重提高,所对应的的分数就会提高,就会优先显示
POST forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "hadoop ",
"boost": 5
}
}
},
{
"match": {
"title": "spark "
}
},
{
"match": {
"title": "java "
}
},
{
"match": {
"title": "blog "
}
}
]
}
}
}
6.9 negative
我们想搜索包含java,但是不包含elasticsearch的数据
POST forum/_search
{
"query": {
"bool": {
"must": [
{"match": {
"title": "java"
}}
],
"must_not": [
{
"match": {
"title": "elasticsearch"
}
}
]
}
}
}
我们想搜索包含java,但是不包含elasticsearch的doc 。使用must_not会显得很死板,我们转念一想,我们搜索包含java,但是包含elasticsearch让其从后排,可以搜索出来但是不让其优先展示,negative为反搜索,包含spark的让其*0.2,分数就会低的很多
POST forum/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "java"
}
},
"negative": {
"match": {
"title": "elasticsearch"
}
},
"negative_boost": 0.2
}
}
}
6.10dis_max
6.10.1 添加数据
POST forum/_update/1
{
"doc": {
"content" : "i like to write best elasticsearch article"
}
}
POST forum/_update/2
{
"doc": {
"content" : "i think java is the best programming language"
}
}
POST forum/_update/3
{
"doc": {
"content" : "i am only an elasticsearch beginner"
}
}
POST forum/_update/4
{
"doc": {
"content" : " elasticsearch and hadoop are all very good solution ,i am a beginner"
}
}
POST forum/_doc/5
{
"userID":1,
"hidden":false,
"articleID":"GFTH-A-1293-#FJ3",
"postDate":"2017-01-01",
"title" : " this is spark blog",
"content" : " spark is best big data solution based on scala ,an programming language similar to java "
}
POST forum/_update/4
{
"doc": {
"content" : "spark elasticsearch and hadoop are all very good solution ,i am a beginner"
}
}
6.10.2dis_max
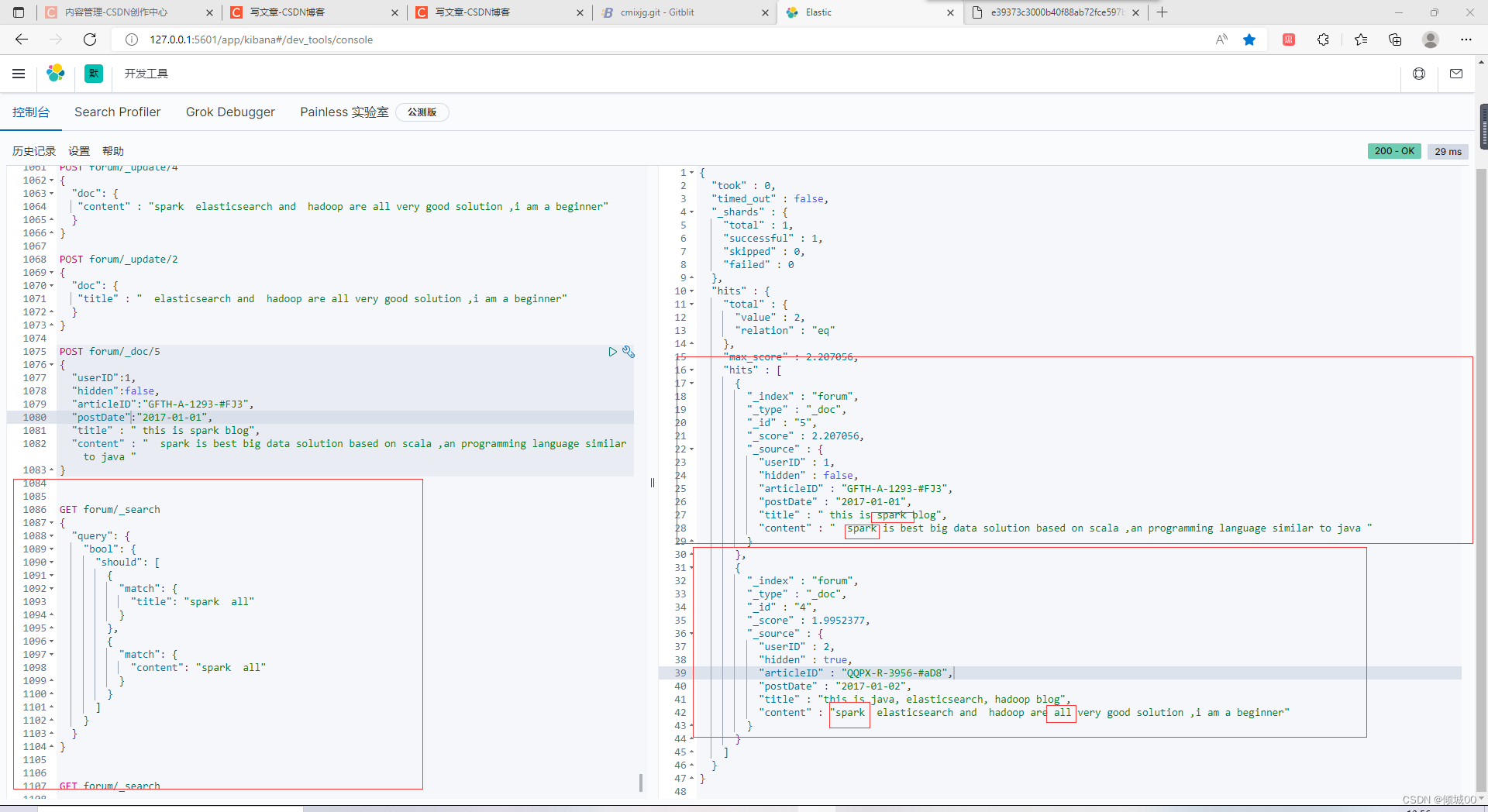
我们想要搜索title中包含spark all 的数据和 content中包含spark all 的数据,正常的来说,应该是第二条的相关度会更高,因为,content中spark all 全出现了,我们想优先展示这一条数据。
GET forum/_search
{
"query": {
"dis_max": {
"queries": [
{"match": {
"title": "spark all"
}},
{
"match": {
"content": "spark all"
}
}
]
}
}
}
dis_max,只是取分数最高的那个 query 的分数。
如何去理解?
我们去搜索
title中包含spark all
content中包含spark all
doc1这条数据匹配到的是title是spark ,content匹配到的数spark
doc2这条数据匹配到的是title没有匹配到,content匹配到的数spark all
is_max,只是取分数最高的那个 query 的分数 所以doc2会比doc1会优先显示
ps:dis_max,只是取分数最高的那个 query 的分数 ,完全不考虑其他 query 的分数。
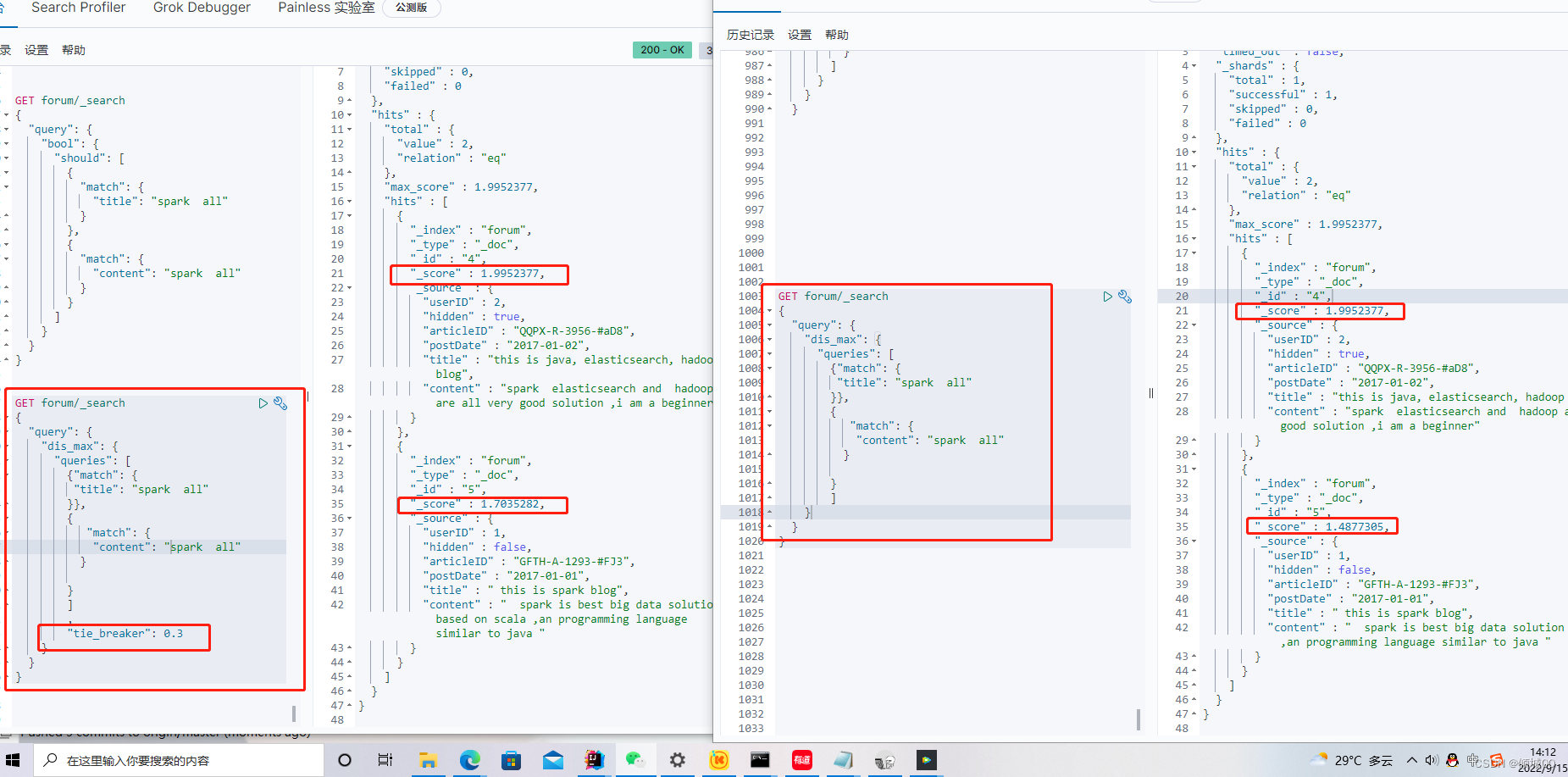
6.10.3 tie_breaker
tie_breaker 参数的意义就是将其他的query分数,*tie_breaker的 值,然后综合分数最高的query去一同作比较,除了考虑最大值,还会考虑其他的query,tie_breaker的值在0-1之间是一个小数
我们可以看下图,用上了tie_breaker和没用上tie_breaker的分数是不一样的,用上了tie_breaker会考虑其他的query分数,会有明显上升,但是最匹配的还是在上面
GET forum/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.3,
"queries": [
{"match": {
"title": "spark all"
}},
{
"match": {
"content": "spark all"
}
}
]
}
}
}
6.11 multi_match
multi_match是实现多个fidld去匹配,这个就是用于多term多匹配
例下:title和content2个去匹配spark all这两个关键字
GET forum/_search
{
"query": {
"multi_match": {
"query": "spark all",
"fields": ["title","content"]
}
}
}
可以搭配 minimum_should_match 混合搜索,提升搜索的精准难度
GET forum/_search
{
"query": {
"multi_match": {
"minimum_should_match": 2,
"query": "spark all",
"fields": ["title","content"]
}
}
}
6.12 best_fields、most_fields、cross_fields策略
6.12.1 most-fields策略
best-fields策略是将某一个fields匹配尽可能多的关键词的doc优先返回回来
most-fields策略是尽可能返回更多的fields匹配到某个关键的doc优先返回回来
1…先去修改一下她的mapping ,让其默认使用english ,然后再创建一个子fields,子fields用的是standard,说一下为什么
1.1假设我们要搜索的
learning more courses
learned a lot of course 这两个数据
给出的匹配字是learning 和courses
但是有可能出现的结果是learned a lot of course 这条数据比learning more courses这条数据要优先展示,这不是我们想要的结
说一下为什么会出现这种情况,假如使用的是english进行分词的话,learning 和courses 这两个匹配字段,会变成learn和cours
段就会造成上述的情况
那么使用standard进行分词就不会出现上面的情况,那么,如果一起使用,会让standard分词得到的数据正式我们想要的会优先
显示,那么english的数据也不能舍弃,在简介的说,使用english得到的数据会匹配,但是standard得到的数据会更匹配
以上是我自己本人的理解,这个本来就有点绕,打字去描述这个事情,有点不太好理解。
@添加mapping,使用english进行分词
然后添加一个子fields让其用 standard进行分词
POST /forum/_mapping
{
"properties":{
"sub_title":{
"type":"text",
"analyzer":"english",
"fields":{
"std":{
"type":"text",
"analyzer":"standard"
}
}
}
}
}
#添加测试数据
POST /forum/_update/1
{
"doc":{
"sub_title":"learning more courses"
}
}
POST /forum/_update/2
{
"doc":{
"sub_title":"learned a lot of course"
}
}
POST /forum/_update/3
{
"doc":{
"sub_title":"we have a lot of fun"
}
}
POST /forum/_update/4
{
"doc":{
"sub_title":"botn of then are good"
}
}
POST /forum/_update/5
{
"doc":{
"sub_title":"haha, hello world"
}
}
我们去进行搜索,会发现两条数据分数一样,明明第一条更加匹配,但是分数还是一样,原因就是我们使用的默认是english的分词器,可以去查看mapping就可以得知
GET /forum/_mapping
GET /forum/_search
{
"query": {
"match": {
"sub_title": "learning courses"
}
}
}

接下来使用我们创建的子分词器,结果正时候我们想要的
GET /forum/_search
{
"query": {
"match": {
"sub_title.std": "learning courses"
}
}
}

但是我们结合一下,让更匹配的分数高,让不太匹配的分数低点,就是我们想要的数据了,我们将2个分词器都使用上了
GET /forum/_search
{
"query": {
"multi_match": {
"query": "learning courses",
"fields": ["sub_title","sub_title.std"]
}
}
}

6.12.2 cross_field策略
POST /forum/_update/1
{
"doc": {
"author_first_name":"Peter",
"auhor_last_name":"Smith"
}
}
POST /forum/_update/2
{
"doc": {
"author_first_name":"Smith",
"auhor_last_name":"Williams"
}
}
POST /forum/_update/3
{
"doc": {
"author_first_name":"Jack",
"auhor_last_name":"Na"
}
}
POST /forum/_update/4
{
"doc": {
"author_first_name":"Robbin",
"auhor_last_name":"Li"
}
}
POST /forum/_update/5
{
"doc": {
"author_first_name":"Tonny",
"auhor_last_name":"Peter Smith"
}
}
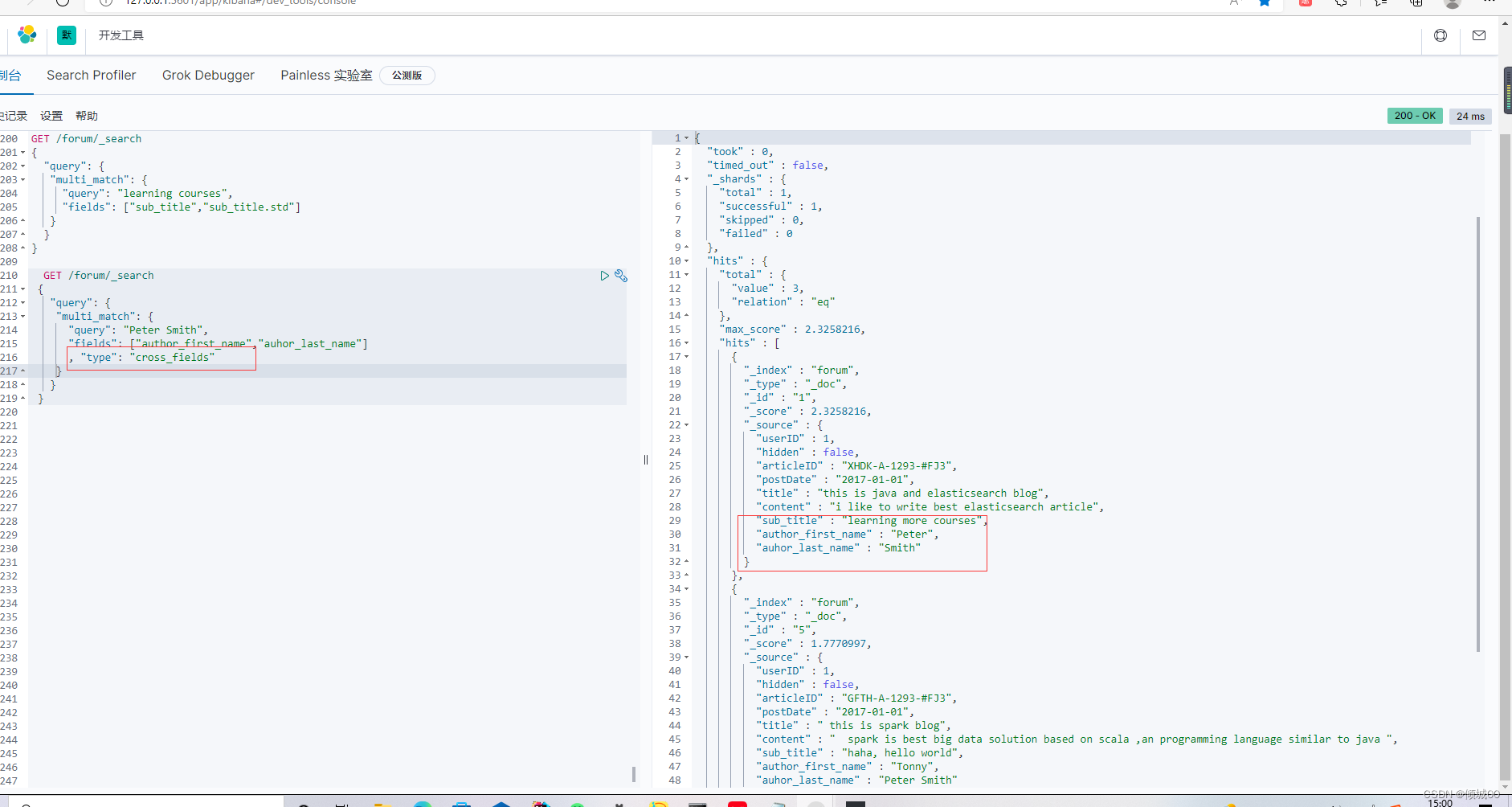
新添加的2行数据,author_first_name,auhor_last_name这两个field去匹配Peter和Smith,这是2个字段,使用most_fields,best_fields这两种去搜索,搜索出来的数据,并不理想,因为想搜索的这是个人名,如果把他拆开去评判,得到的结果远不是我们想要的
cross_fields:一个唯一标识,跨了多个field,可以理解成,多个field去看做一个整合去进行条件的搜索
推荐文章:
使用copy_t来解决:推荐文章:copy_t
或者如下文使用"type": "cross_fields"来解决这个

-
总结
-
best_fields 策略,为什么没说,因为我们之前用的就是best_fields策略
-
best-fields策略是将某一个fields匹配尽可能多的关键词的doc优先返回回来

-
most-fields策略是尽可能返回更多的fields匹配到某个关键的doc优先返回回来

-
cross_fields策略,看上面的例子
6.13 match_phrase
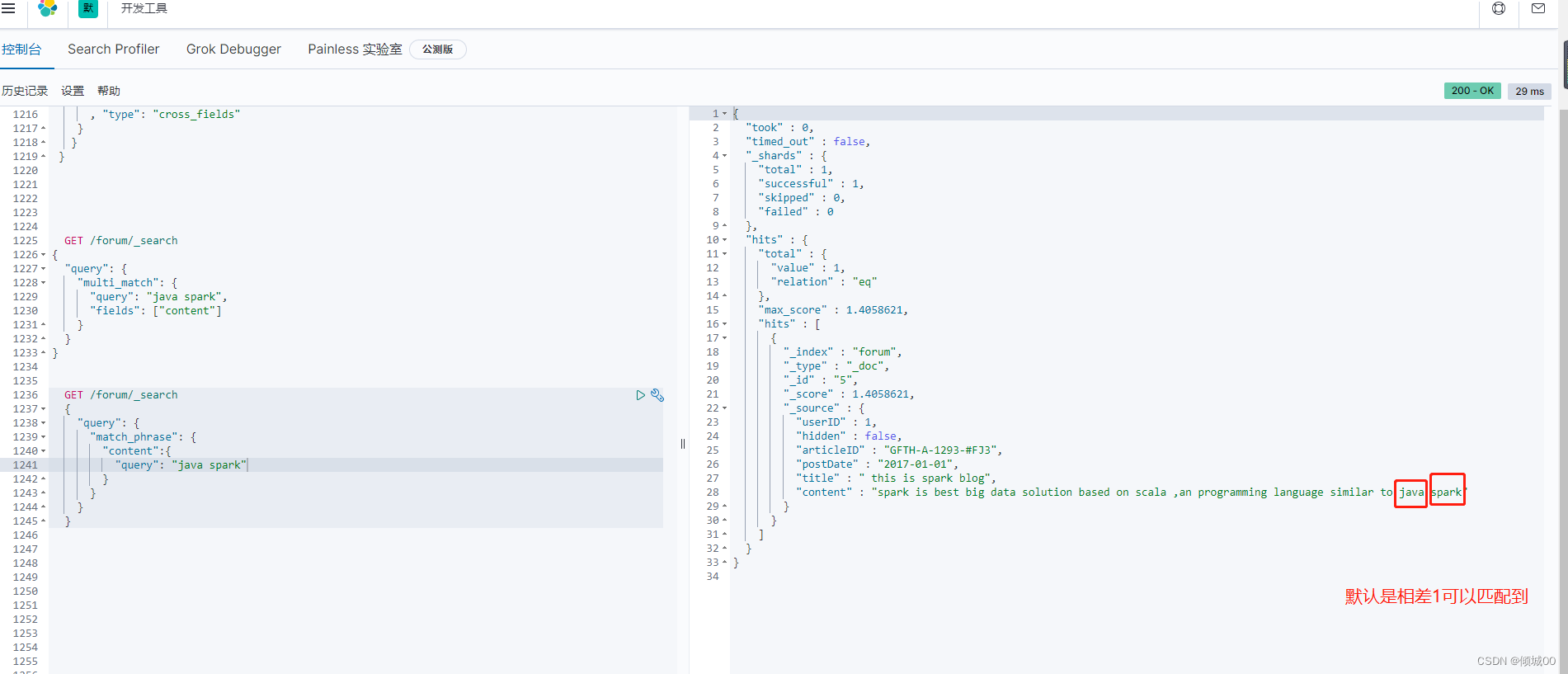
spark is best big data solution based on scala ,an programming language similar to java spark
i think java is the best programming language
这有2条语句,我们想搜索java spark 搜索出来的是这两条语句,语句一中包含,语句二中只包含java,我们想把java spark看>成是一个整体去判断,用普通的match是查询不出来的,使用match_phrase也就是近似匹配去查询,查询出来的语句是只有第一条
默认的情况下java spark 相隔1个能匹配上多了和少了都不能匹配上
#修改数据
POST forum/_update/5
{
"doc": {
"content" :"spark is best big data solution based on scala ,an programming language similar to java spark"
}
}
#执行代码
GET /forum/_search
{
"query": {
"match_phrase": {
"content":"java spark"
}
}
}
6.13.1 slop
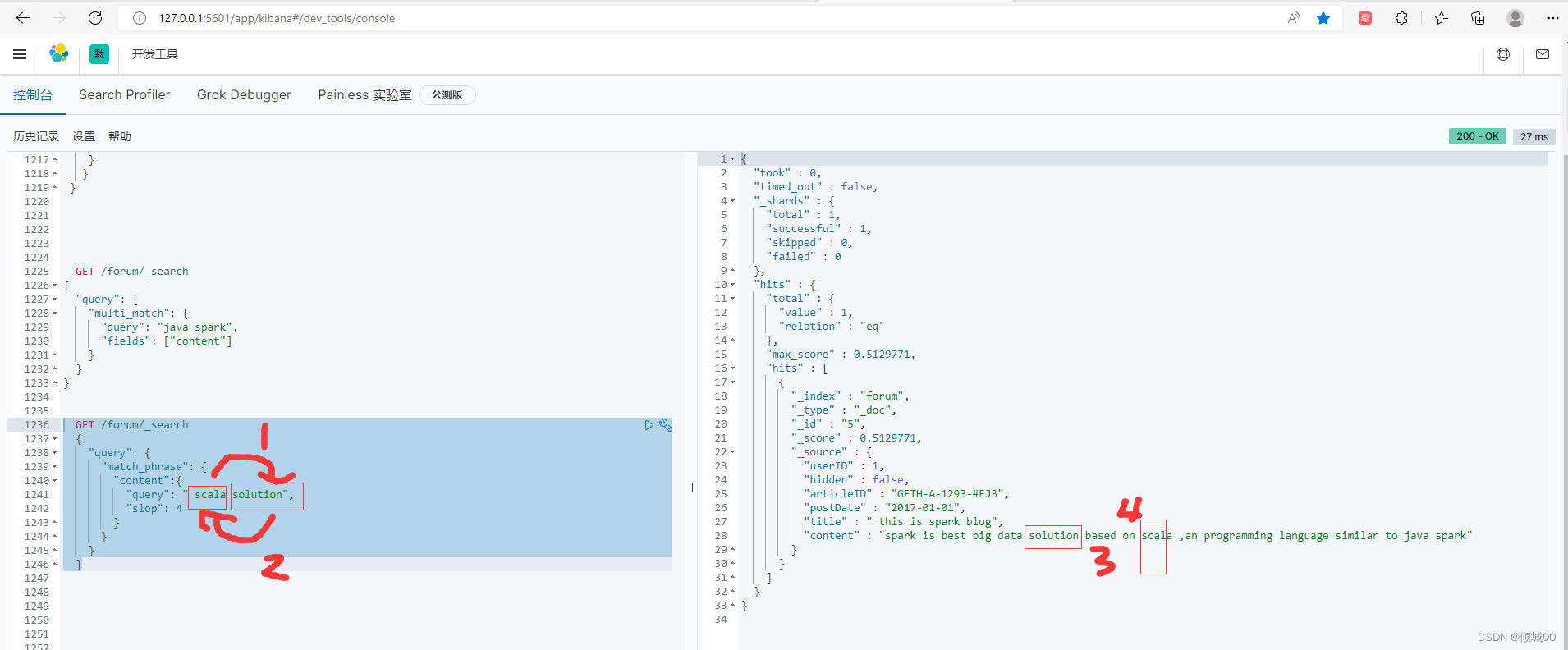
slop的用法,例如下面的语句
spark is best big data solution based on scala ,an programming language similar to java spark
我们正常的match_phrase 进行普通查询,查询 data scala ,是查询不出来的,因为字段在doc中距离>1
距离:data scala 我们通过对比上面的语句,发现data 和scala 中间相隔了3个词,这个3距离就是slop的参数
简单来说就是,这个term的两个单词的间隔>3可以匹配上,才可以,匹配不上是搜索不出来条件的
第二个例子:
scala data我们来搜索这个用3是搜索不到的,需要把slop设置成5.为什么呢,
scala data
第一步 scala data 把scala 左边移
第二部 data scala 把data左边移动,这样的几所是不是就和上面一样了,然后再加上上面说的3,通过"slop": 5 就可以拿到结果
补充讲解:如果有2个doc,靠的近,会被优先搜索出来,队形的分数也会越多。
match_phrase是近似匹配,slop可以对其设定距离,靠的近,会被优先搜索出来如下图搜索不出来数据,我们将范围调整大

调大,调到2如下图可以张看好匹配到

我们反过来搜索 先交换数据然后搜索
GET /forum/_search
{
"query": {
"match_phrase": {
"content":{
"query": " scala solution",
"slop": 4
}
}
}
}
6.14 混合使用实现 召回率 精准度的平衡
- 召回率:比如去搜索1个 java spark 总共100个doc 能返回多少个作为结果,就是召回率
- 精准度:比如去搜索1个 java spark 能不能让包含 java spark的排在最前面,或者是java spark离着最近的排在最前面
GET forum/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"content":{
"query": "data best"
}
}
}
],
"should": [
{
"match_phrase": {
"content":{
"query":"data best",
"slop": 10
}
}
}
]
}
}
}
6.14 前缀搜索
前缀搜索是不计算分数的,只是说是把前缀带有的给过滤出来,前缀越短,匹配的doc也就越多,性能反而就越差,尽可能用长前缀搜索
前缀搜索,通配搜索,正则,这几个性能很差,不如match,因为他们都是默认是会扫描到整个索引,能不用尽量别】
- 搜搜articleID的内容是以XHDK开头的数据
GET /forum/_search
{
"query": {
"prefix": {
"articleID.keyword": {
"value": "XHDK"
}
}
}
}
6.15 通配符搜索
运用通配符进行搜索可以实现复杂的查询
以下的例子是以k开头后面任意字符J后面跟任意多个字符,最后以7结尾
?=任意字符,*=任意多个字符
- 以下是搜索articleID 以X开头后面跟任意字符,D后面跟任意N个字符最后以3结尾
GET /forum/_search
{
"query": {
"wildcard": {
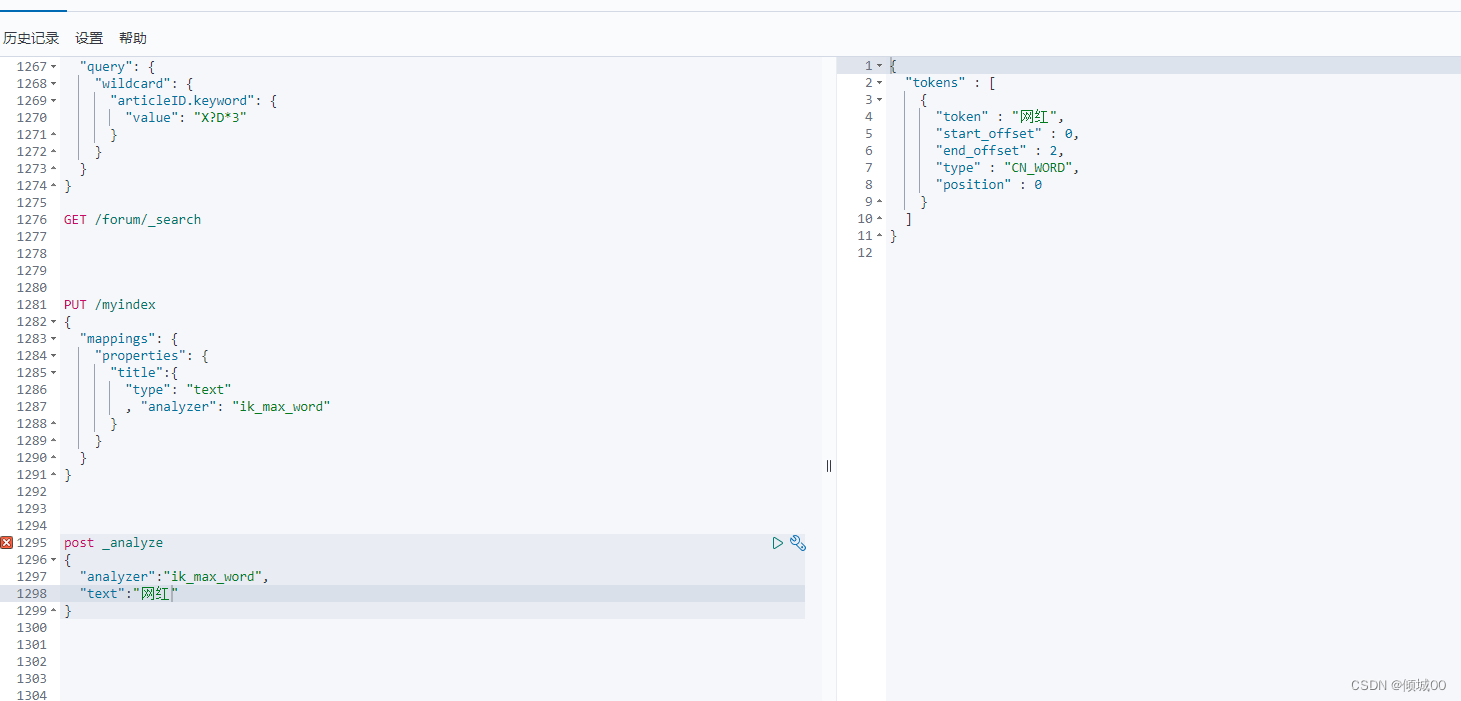
"articleID.keyword": {
"value": "X?D*3"
}
}
}
}
6.16 正则表达式
正则表达式
[0-9]:指定范围内出现的数字
[a-z]:指定范围内出现的字母
.:一个字符
+:前面的正则表达式可以出现一次或多次
GET /forum/_search
{
"query": {
"regexp": {
"articleID.keyword": "K[A-Z].+"
}
}
}
6.17 推荐搜索
推荐搜索:相当于百度去搜索一个东西,搜索java j 会弹出jsvs jdk 和java jre等等,这个是推荐搜索
有如下数据 hello word hello index hello wind helli wo 输入hello w 去搜索,把w作为前缀去搜索,搜索出包含w的前缀doc,性能很差,也是扫描全部索引,性能会很差
6.17.1 match_phrase_prefix
GET forum/_search
{
"query": {
"match_phrase_prefix": {
"content": "java s"
}
}
}
6.18 理论
6.18.1 booleanmodel
类似于and的这种操作符,先过滤出对应的term的doc
query :"hello word " 进行过滤,结果可能是hello /word 或者hello &woed
或者说bool里面跟了must/ust not/should,会进行过滤,过滤出包含什么或者不包含什么或者可能包含的,会进行过滤把相关的doc会过滤出来,是不打分数的,得出的结果true/false,为了减少后续要计算的doc数量提升性能
6.18.2 TF/IDF
query:“hello word”
TF :term frequency
找到hello在doc中出现了几次,根据出现的次数给定分数
一个trem在一个doc中,出现的次数越高,给定的评分就越高IDF:inversed document frequency
找到hello 在所有的doc出现的次数
一个term在所有的doc中出现的次数越高,相关的评分度就越低length norm ->hello搜索的那个field的长度,field的长度越长,给出的相关评分就越低,field的长度越短,给出的相关评分就越高
最后会将hello这个term,对doc1的分数,综合TF,IDF ,length norm.计算出一个综合性的分数
6.18.3分数优化
01:boost增加权重,分数会相应的发生变动
02.上面说底层原理的时候,should里面圈套了4个term,这样他们的权重比都是4分之1,name想要更改权重,需要在term里面在嵌套一个bool,
03.使用negative,上面有讲过
04.使用constant_score
6.19 fuzzy
如果我么想去搜索countent中elasticsearch的这个关键词,但是不小心拼错了fuzzy是用来帮助错误纠正的
elasticseerc 想去匹配elasticsearch但是发现其中有个单词拼写错误,fuzzy会进行一个自动的纠正,l里面有个参数
fuzziness为错误纠正的次数,比如我们想搜索keoopo这个但是不小心写成了keeop 把e变成o是一次,随后的末尾添加一个o也是一次,这就是2次,如果设置了2次还没匹配就小扩大纠正的次数
GET forum/_search
{
"query": {
"fuzzy": {
"content": {
"value": "elasticseerc",
"fuzziness": 3
}
}
}
}
GET /forum/_search #在开发的时候一半都是嵌套在match中去写,将fuzziness设置为AUTO
{
"query": {
"match": {
"content": {
"query": "elasticsear",
"fuzziness": "AUTO"
}
}
}
}
6.20 ik分词器
将ik分词器加压到目录下,然后启动就可以了,ik分词器对中文是非常友好的
-ik_max_word:会将文本做最细粒度的拆分,比如将中华人民共和国国歌,拆分成,中华人民共和国,中华人民,中华,华人,人民,人,共和国等等,会有很难多种组合
6.20.1 检验证ik分词器是否使用成功
post _analyze
{
"analyzer":"ik_max_word",
"text":"我是中国公民"
}

6.20.2 添加扩展词典
接下来我们不想让ik分词器去分词 “欧尼酱”,欧尼酱这个词咱们不想拆开,比如这个欧尼酱这个词是最近非常流行的词语,比如网红啊什么的,ik分词库里面都没有,我们可以自己手动添加,打开配置文件
添加扩展词典,如果目录里面没有这个文件就创建一个
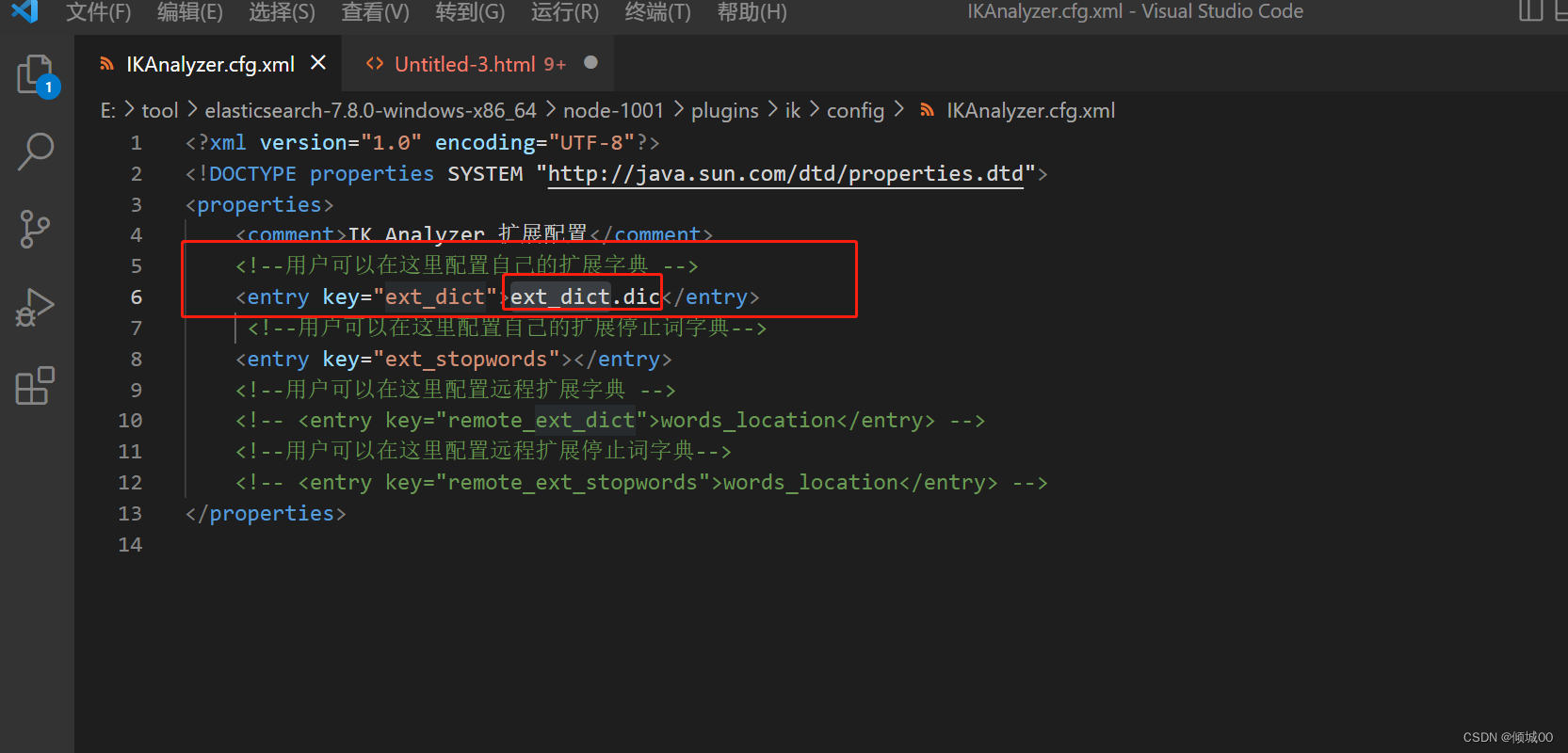
创建完成文件以后去填写扩展词,保存,重新启动即可
我们重新在分词,会发现我们配置的词库已经生效了,es已经看成是一个整体了
6.20.3 添加停用词
停用词就是将词语停用不会对搜索产生影响
创建停用词文件
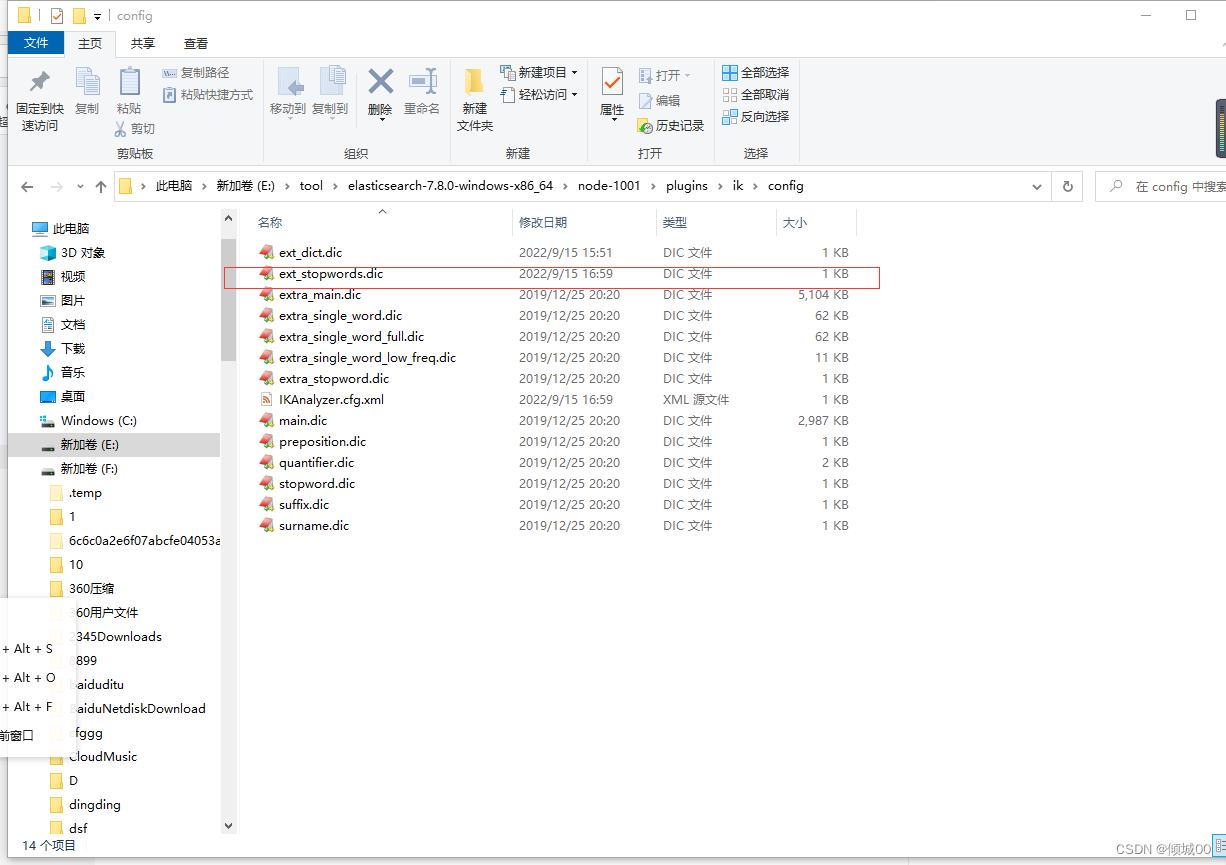
添加停用词
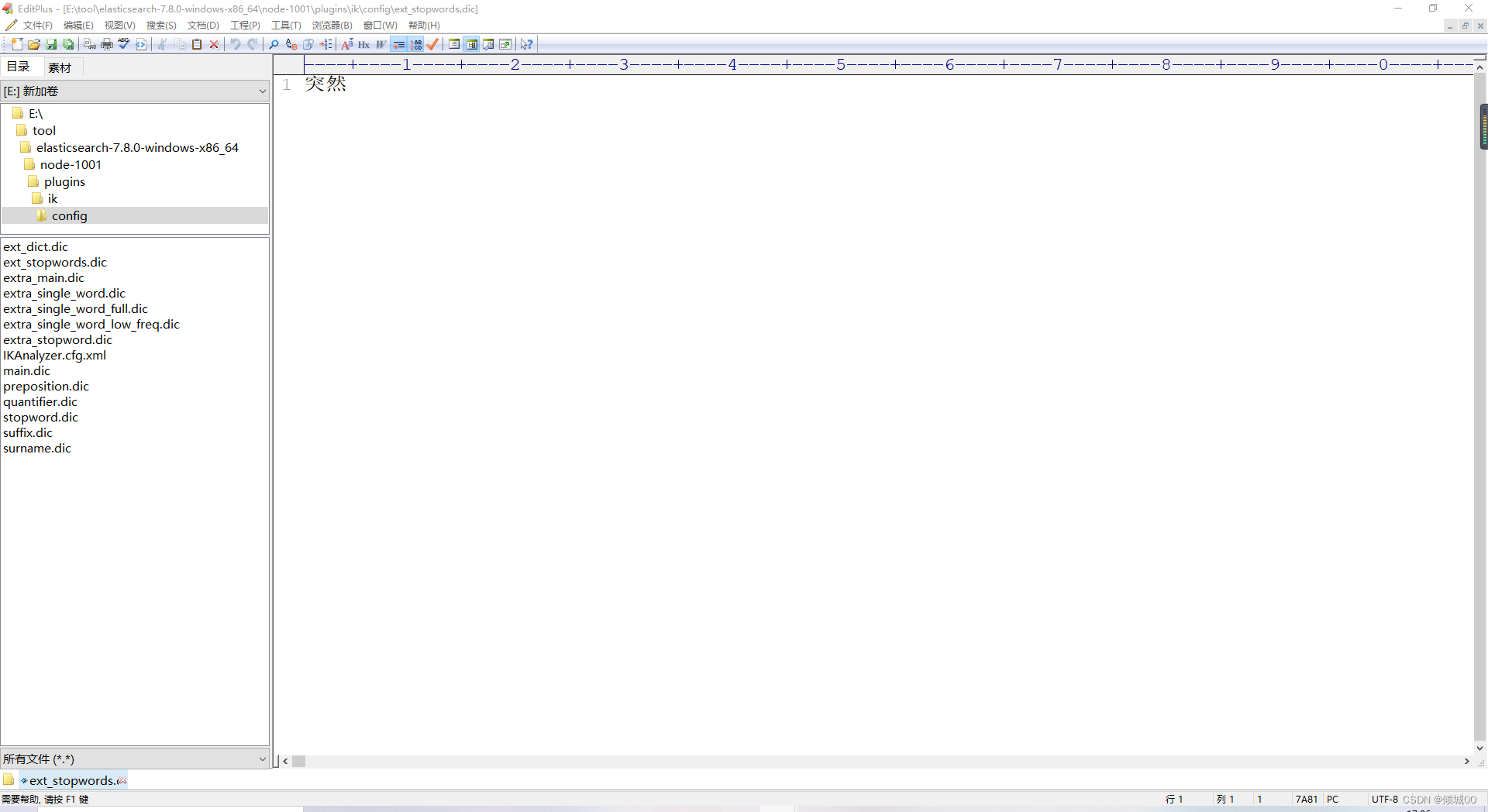
在IKAnalyzer.cfg.xml中将停用词去配置
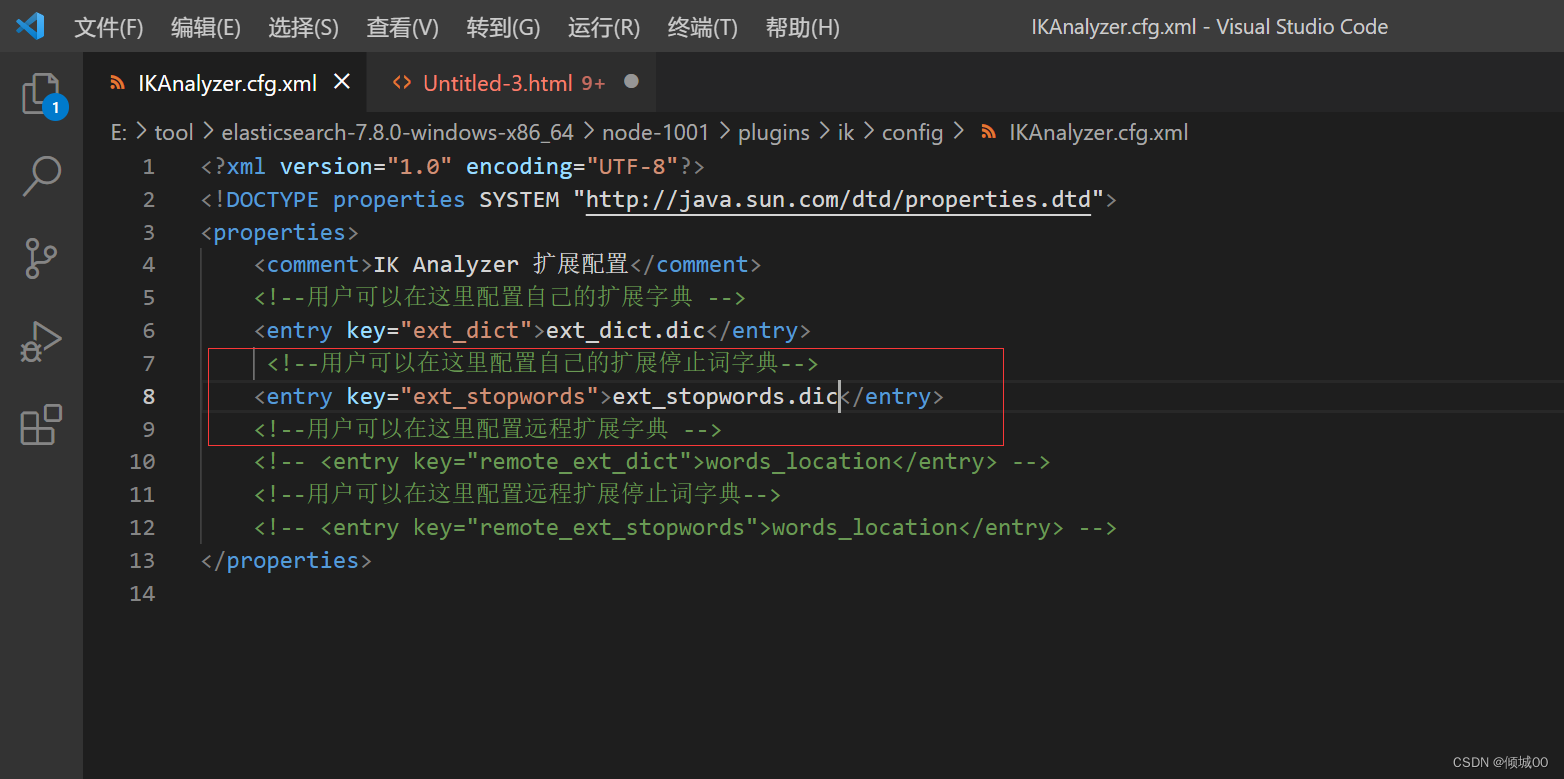
重启es,测试,发现停用词生效

6.21 bucket与metric
-
bucket对数据进行分组,假设我们有如下数据
city – name
北京 小王
北京 小刘
上海 小孟
上海 小天
上海 小爱 -
基于city去划分出来bucket
-
划分出两个bucket,一个是北京bucket,一个是上海bucket
-
上海bucket 里面有小天,小爱,小孟
-
北京bucket 里面有小王,小刘
-
按照某个字段进行划分,字段相同的会划分到一个bucket中
-
metric:对一个数据进行分组之后的统计
-
当我们有了一堆bucket之后就可以对每个bucket进行聚合分词了,比如计算最大值,最小值等等
-
PS:有mysql基础应该容易理解 bucket就是分组 对于分组的数据进行聚合操作就是metric avg啊,count(*)啊等等
添加数据
PUT /tvs
{
"mappings": {
"properties": {
"price":{
"type": "long"
},
"color":{
"type": "keyword"
},
"brand":{
"type": "keyword"
},
"sold_data":{
"type": "date"
}
}
}
}
GET tvs/_search
POST tvs/_doc/1
{
"price":1000,
"color":"红色",
"brand":"长虹",
"sold_data":"2017-10-28"
}
POST tvs/_doc/2
{
"price":2000,
"color":"红色",
"brand":"长虹",
"sold_data":"2017-11-05"
}
POST tvs/_doc/3
{
"price":3000,
"color":"绿色",
"brand":"小米",
"sold_data":"2017-05-18"
}
POST tvs/_doc/4
{
"price":1500,
"color":"蓝色",
"brand":"TCL",
"sold_data":"2017-07-02"
}
POST tvs/_doc/5
{
"price":1200,
"color":"绿色",
"brand":"TCL",
"sold_data":"2017-08-19"
}
POST tvs/_doc/6
{
"price":2000,
"color":"红色",
"brand":"长虹",
"sold_data":"2017-11-05"
}
POST tvs/_doc/7
{
"price":800,
"color":"红色",
"brand":"三星",
"sold_data":"2017-01-01"
}
POST tvs/_doc/8
{
"price":2500,
"color":"蓝色",
"brand":"小米",
"sold_data":"2017-02-12"
}
6.21.1 统计最高销量
“size”: 0, 不显示原始数据
aggs,要对一份数据进行聚合操作
popo_clolor:对每个分组起一个名字,名字是随机的起什么都可以”
terms:根据字段进行分组
field:对什么字段进行分组
ps:最上面有相关的聚合练习,推荐重温一遍
GET tvs/_search
{
"size": 0,
"aggs": {
"popo_clolor": {
"terms": {
"field": "color"
}
}
}
}
6.21.2 统计最高销量 and 计算平均值
统计最高销量 and 计算平均值 ,统计完颜色的分组之后,在分组里面在套aggs进行聚合操作
GET tvs/_search
{
"size": 0,
"aggs": {
"popo_clolor": {
"terms": {
"field": "color"
},
"aggs": {
"popo_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
6.21.3 统计最高销量 and 电视型号 and 计算平均值
统计颜色的销量,计算颜色的平均值,然后在划分品牌,然后再计算品牌的平均值
GET tvs/_search
{
"size": 0,
"aggs": {
"popo_clolor": {
"terms": {
"field": "color"
},
"aggs": {
"popo_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"popo_price": {
"avg": {
"field": "price"
}
}
}
}
,
"groub_by_proce":{
"avg": {
"field": "price"
}
}
}
}
}
}
6.21.4 最大值&最小值&平均值
统计最大值,最小值和平均值
GET tvs/_search
{
"size": 0,
"aggs": {
"popo_clolor": {
"terms": {
"field": "color"
},
"aggs": {
"popo_value": {
"avg": {
"field": "price"
}
},
"popo_max":{
"max": {
"field": "price"
}
},
"popo_min":{
"min": {
"field": "price"
}
}
}
}
}
}
6.21.5 统计范围区间
histogram 对价格进行分组,以800分组会划分为800-1600 1600-2400 等等
以下对价格划分区间然后对区间的品牌进行分组,查询品牌中的销售额
GET tvs/_search
{
"size":0,
"aggs": {
"groub_by_price": {
"histogram": {
"field": "price",
"interval": 800
},
"aggs": {
"groub_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"groub_by_sum": {
"sum": {
"field": "price"
}
}
}
}
}
}
}
}
6.21.6 按照日期统计
date_histogram 按照日期划分
field 对什么划分
interval 按照field对月划分
extended_bounds里面的个参数
min 最小值,从哪里开始
max 最大值,在哪里结束
GET /tvs/_search
{
"size":0,
"aggs": {
"group_by_data": {
"date_histogram": {
"field": "sold_data",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2017-01-01",
"max": "2017-12-31"
}
}
}
}
}
按照季度划分 “interval”: “quarter”,
GET /tvs/_search
{
"size":0,
"aggs": {
"group_by_data": {
"date_histogram": {
"field": "sold_data",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2017-01-01",
"max": "2017-12-31"
}
}
}
}
}
6.21.6 按照日期统计每个季度的品牌营业额
按照季度去划分,获得每个季度的营业额,然后对每个季度的品牌分组聚合求出每个品牌的营业额
GET /tvs/_search
{
"size":0,
"aggs": {
"group_by_data": {
"date_histogram": {
"field": "sold_data",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2017-01-01",
"max": "2017-12-31"
}
},
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"groub_by_price": {
"sum": {
"field": "price"
}
}
}
},
"group_by_values":{
"sum": {
"field": "price"
}
}
}
}
}
}
6.21.7 统计指定品牌下的营业额
统计小米牌子的营业额
GET tvs/_search
{
"query": {
"match": {
"brand": "小米"
}
},
"aggs": {
"groub_by_brand": {
"sum": {
"field": "price"
}
}
}
}
6.21.7 统计指定品牌下的营业额与总营业额
我们上面的例子是对指定的品牌获得总营业额,然后我们还得获得所有的营业额与指定的营业额做比较
“global”: {}的意思是获得所有的数据,然后后面在跟aggs进行对所有的数据进行聚合操作
GET tvs/_search
{
"query": {
"match": {
"brand": "小米"
}
},
"aggs": {
"groub_by_brand": {
"sum": {
"field": "price"
}
},
"all":{
"global": {}
, "aggs": {
"groub_by_all": {
"sum": {
"field": "price"
}
}
}
}
}
}
6.21.8 过滤&聚合
统计价格大于1200的电视平均价格
GET tvs/_search
{
"query": {
"range": {
"price": {
"gte": 1200
}
}
},
"aggs": {
"grouy_by_avg": {
"avg": {
"field": "price"
}
}
}
}
6.21.9 统计指定品牌的最近一个月总额度
GET /tvs/_search
{
"query": {
"term": {
"brand": {
"value": "小米"
}
}
},
"aggs": {
"grroub_data": {
"filter": {
"range": {
"sold_data": {
"gte": "2017-02-22||-10d"
}
}
},
"aggs": {
"groub_clo": {
"terms": {
"field": "color"
}
},
"groub_sum":{
"sum": {
"field": "price"
}
}
}
}
}
}
6.21.10 统计颜色的平均价格然后排序
GET /tvs/_search
{
"size":0,
"aggs": {
"geoub_by_cloer": {
"terms": {
"field": "color",
"order": {
"_key": "asc"
}
},
"aggs": {
"groub_by_avg": {
"avg": {
"field": "price"
}
}
}
}
}
}
6.21.11 统计颜色的平均价格和品牌的平均价格然后排序
GET /tvs/_search
{
"size":0,
"aggs": {
"geoub_by_cloer": {
"terms": {
"field": "color",
"order": {
"_key": "asc"
}
},
"aggs": {
"groub_by_avg": {
"avg": {
"field": "price"
}
},
"groub_by_brand":{
"terms": {
"field": "brand",
"order": {
"_key": "asc"
}
},
"aggs": {
"groub_by_brand_avg": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
6.21.12季度品牌祛重
GET tvs/_search
{
"size":0,
"aggs": {
"group_by_data": {
"date_histogram": {
"field": "sold_data",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2017-01-01",
"max": "2017-12-31"
}
},
"aggs": {
"groub_by_dis": {
"cardinality": {
"field": "brand"
}
}
}
}
}
}
6.21.12 cardinality性能优化
cardinality,count(distinct)是有5%的错误率的,性能在100ms左右
- precision_threshold优化准确率和内存开销
- 如果brand的value 在100个以内,小米,三星,长虹,等等。可以保证100%的精确
- cardinality 算法会占用precision_threshold 8 byte的内存消耗 1008=800个字节
- 占用内存很小。。。而且values如果如果的确在值以内,可以确保100%的精准
- precision_threshold=1000的值设置的越大,占用的内存越大,1000*8=8000/1000=8kb可以确保更多values
- 根据es官方的统计,如果把precision_threshold设置为100对数百万的values进行祛重,错误率在5%以内
GET tvs/_search
{
"size": 0,
"aggs": {
"groub": {
"terms": {
"field": "brand"
},
"aggs": {
"dis": {
"cardinality": {
"field": "brand",
"precision_threshold": 100
}
}
}
}
}
}
6.21.13 百分比算法
需求:有一个网站,记录了每次请求访问的耗时,需要统计tp50,tp90,tp99
tp50:50%的请求耗时是多长时间
tp90:90%的请求耗时是多长时间
tp99:99%的请求耗时是多长时间
添加所需数据
PUT/ website
POST website/_doc/1
{
"latency":105,
"province":"江苏",
"timestamp":"2016-10-28"
}
POST website/_doc/2
{
"latency":83,
"province":"江苏",
"timestamp":"2016-10-29"
}
POST website/_doc/3
{
"latency":92,
"province":"江苏",
"timestamp":"2016-10-29"
}
POST website/_doc/4
{
"latency":112,
"province":"江苏",
"timestamp":"2016-10-28"
}
POST website/_doc/5
{
"latency":68,
"province":"江苏",
"timestamp":"2016-10-28"
}
POST website/_doc/6
{
"latency":76,
"province":"江苏",
"timestamp":"2016-10-29"
}
POST website/_doc/7
{
"latency":101,
"province":"新疆",
"timestamp":"2016-10-28"
}
POST website/_doc/8
{
"latency":275,
"province":"新疆",
"timestamp":"2016-10-29"
}
POST website/_doc/9
{
"latency":166,
"province":"新疆",
"timestamp":"2016-10-29"
}
POST website/_doc/10
{
"latency":654,
"province":"新疆",
"timestamp":"2016-10-28"
}
POST website/_doc/11
{
"latency":389,
"province":"新疆",
"timestamp":"2016-10-28"
}
POST website/_doc/12
{
"latency":302,
"province":"新疆",
"timestamp":"2016-10-29"
}
6.21.13 聚合分析的实现原理
聚合分析的实现原理不是倒排索引+搜索,这样的性能太低了
es是通过doc value 就是正排索引
如果是搜索倒排索引的话,必须遍历完整个倒排索引才可以
因为可能你要搜索的field的值是分词的,比如说是hello word my name ->一个doc的聚合field的值 可能在倒排索引中对应多个value
所以说,当你在倒排索引中找到一个值,发现它是属于某个doc的时候,还不能停,必须遍历完整个倒排索引,才能确保每个doc对应的所有的terms然后进行分组聚合
正排队索引推荐文章
我们如果有100w个数据,我们没有必要搜完成整个倒排索引,我们可能搜索到1w5000个就能找到然后就可以执行分组聚合操作了
- (1)doc value的原理
- 我们在post/put的时候就会生成doc value的数据,也就是正排索引
- (2)核心原理与正派索引类似
- 正排索引也会写入到磁盘文件中,然后os cache 先进行缓存,以提升doc value的性能 ,如os cache的内存不足以整个倒排索引,就会将doc value写入到磁盘文件中
- (3)性能建议:给jvm少量内存,64g服务器,给jvm最多16g
- es官方是建议,es大量是基于os cache来进行缓存来提升性能的,不建议用jvm内存来进行缓存,那样会导致一定的gc开销和oom问题
- 给jvm更小的内存,给os cache更大的内存
- 64g服务器给jvm最多16g,几十g的内存给os cache
- os cache可以提升doc value和倒排索引的缓存和查询效率
- 2.column压缩
- (2.1)所有值相同,直接保留单位
- (2.2)少于256个值,使用table encoding模式,一种压缩方式
- (2.3)大于256个值,看看有没有最大公约数,有就处于最大公约数,然后保留这个最大公约数
- (2.4)如果没有最大公约数,采用offset结合压缩的方式
- 3.如果不 使用doc value可以对其进行禁用,减少磁盘占用空间
PUT myindexs
{
"mappings": {
"properties": {
"mufiles":{
"type": "keyword",
"doc_values": false
}
}
}
}
6.21.14 分词field+fielddata
我们使用text类型的field进行分组会报错
- 对分词的field,直接进行聚合的操作,会报错,大概的报错信息是你必须要先打开fielddata,然后将正排索引数据加载到内存中,才可以对的field执行聚合操作,而且会小号非常大的内存
PUT textsmy
POST textsmy/_doc/1
{
"title":"daada"
}
GET textsmy/_search
{
"aggs": {
"groub_by": {
"terms": {
"field": "title"
}
}
}
}
加上.keyword就不会产生错误了
GET textsmy/_search
{
"aggs": {
"groub_by": {
"terms": {
"field": "title.keyword"
}
}
}
}
如果想要实现英文聚合应该将 “fielddata”:true即可
POST textsmy/_mapping
{
"properties":{
"title":{
"type":"text",
"fielddata":true
}
}
}
GET textsmy/_search
{
"aggs": {
"groub_by": {
"terms": {
"field": "title"
}
}
}
}
- 分词field+fielddata的工作原理
doc value–>不分词的所有field,可以执行聚合操作,如果你的某个field不分词,那么在创建索引的时候,就会自动生成doc value,针对与这些不分词的field执行聚合操作的时候,自动会用doc value
分词field是没有doc value的,在创建索引的时候,因为某个field是分词的,就不会给他建立doc value正排索引,因为分词后,占用的空间太大,所以是不支持分词的field进行聚合的
分词field是默认没有doc value所以执行聚合会报错
对于分词的field,必须打开和使用fieldata,完全存在于纯内存中,结构和doc vaue类似,如果是大量的trems那必将占用大量的内存
如果一定要对分词的field进行聚合操作,那么必须将fielddata=true然后es在执行聚合的时候,现场将field对应的数据,现场建立一份正派索引,fielddata建立的正排索引结构是和doc value是相似的
为什么fielddata必须在内存?大家思考一下,分词的字符串,需要按照trems进行聚合,需要执行更加复杂的算法和操作,如果基于磁盘和os cache那么性能会很差
6.21.14 集合操作最终章 优化
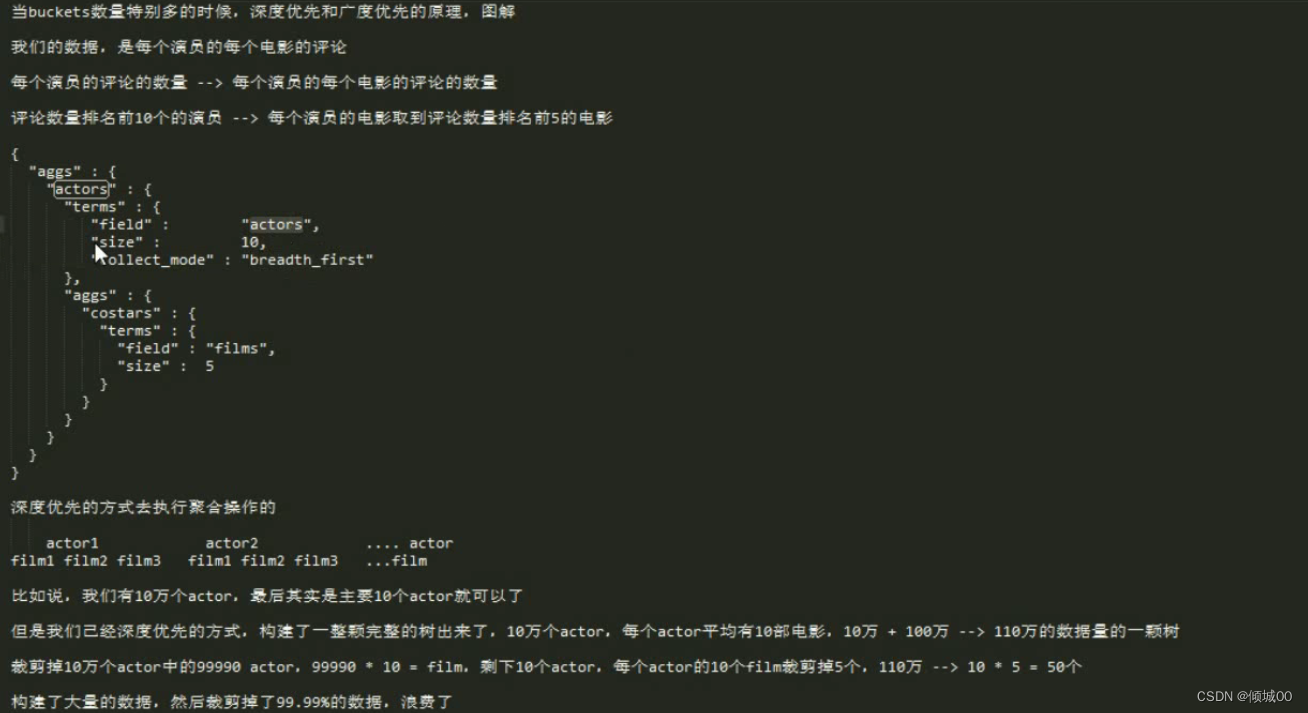

6.22 es数据模型
- es更加类似于面向对象的数据模型,将所有右关联关系的数据,放在一个doc json类型的数据中,整个数据的关系,还有完整的数据,都放在了一起
public class stu{
private iint id;
private int age;
peivate String sex;
private String name;
private Classes classses
}
private class Classes{
private int sid;
private classname;
private List<stu> students
}
- 在es中是如下格式
{
"sid ":1
" classname":"5号教室",
"students":[
{
"id:"001";
"age":'44",
"sex":"男",
"name":"张三"
},
{
"id:"002";
"age":'23",
"sex":"女",
"name":"小莉"
}
]
}
PS: 附加constant_score
6.22.1 es数据模型通过应用层实现数据建模
背景:博客网站,
- 创建数据
PUT websiteuser
POST websiteuser/_doc/1
{
"name":"小鱼儿",
"emaill":"xiaoyuer@163.com",
"birthday":"2013-06-05"
}
PUT websitblogs
POST websitblogs/_doc/1
{
"title":"我的第一篇博客",
"content":"这是我的第一篇博客",
"userId":1
}
- 我们进行如下搜索,可以搜索出一对多的数据
GET websiteuser/_search
{
"query": {
"term": {
"name.keyword": {
"value": "小鱼儿"
}
}
}
}
GET websitblogs/_search
{
"query": {
"constant_score": { ----constant_score 查询出的数据是不算入分数的
"filter": {
"term": {
"userId": 1
}
}
}
}
}
- 优点和缺点:
- 优点:数据不拢余,维护起来方便
- 缺点:应用层join,如果关联的数据太多,导致查询慢,性能会很差
6.22.2 top_hits 简单获取数据 & _source 显示数据
我们对数据进行分组之后,想展示数据,需要使用top_hits
我们对数据进行分组之后想显示一部分,使用_source
具体如何实现请看下方
6.22.2 es数据模型通过数据冗余,实现用户关联
- 所需数据
POST websiteuser/_doc/2
{
"name":"黄药师",
"emaill":"huangyaoshi@163.com",
"birthday":"2017-06-05"
}
POST websiteuser/_doc/3
{
"name":"杨过",
"emaill":"yangguo @163.com",
"birthday":"2016-06-05"
}
POST websitblogs/_doc/2
{
"title":"我是黄药师",
"content":"这是我的第一篇博客,我是黄药师",
"userinfor":{
"userid":2,
"username":"黄药师"
}
}
POST websitblogs/_doc/3
{
"title":"我是杨过",
"content":"这是我的第一篇博客,我是杨过",
"userinfor":{
"userid":3,
"username":"杨过"
}
}
- 查询代码
对数据进行分组,然后展示部分数据
GET websitblogs/_search
{
"size":0
, "aggs": {
"grouby_user": {
"terms": {
"field": "userinfor.username.keyword"
},
"aggs": {
"groub_by_value": {
"top_hits": {
"_source": {
"includes": ["title","content"]
}
,"size": 5
}
}
}
}
}
}
6.22.3 nestedbject数据存储
先构建数据
PUT netobject
POST netobject/_doc/1
{
"title":"花无缺发表了一篇帖子",
"content":"我是花无缺,大家要不要考虑一下投资房产和买股票的的事情啊?",
"comments":[
{
"name":"小鱼儿",
"comment":"什么股票,推荐一下",
"age":48,
"start":4,
"date":"2022-09-20"
},
{
"name":"黄药师",
"comment":"我喜欢投资房产,风险大,收益也大",
"age":31,
"start":2,
"date":"2020-9-20"
}
]
我们想查询,name=黄药师和年龄是48的数据,理论上是查不到数据的,我们看下面的查询代码,可以查询到数据
GET netobject/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "黄药师"
}
},
{
"match": {
"comments.age": 48
}
}
]
}
}
}
创建的数据是object类型的底层存储,数据在底层是这样的,如下图,所以我们name=黄药师,age=48可以查到(图片个个别数据与代码有略微不同)
所以咱们直接命中了这个document

- 解决办法:引入nestedbject 来解决object底层的问题
对mapping 进行修改将comments的值从object的值,修改为nestedbject
- 修改mapping ,添加数据,搜索
DELETE netobject
PUT netobject
{
"mappings": {
"properties": {
"title":{
"type": "text"
},
"content":{
"type": "text"
},
"comments":{
"type": "nested",
"properties": {
"name":{
"type": "text"
},
"comment":{
"type": "text"
},
"age":{
"type":"long"
},
"start":{
"type":"long"
}
}
}
}
}
}
POST netobject/_doc/1
{
"title":"花无缺发表了一篇帖子",
"content":"我是花无缺,大家要不要考虑一下投资房产和买股票的的事情啊?",
"comments":[
{
"name":"小鱼儿",
"comment":"什么股票,推荐一下",
"age":48,
"start":4,
"date":"2022-09-20"
},
{
"name":"黄药师",
"comment":"我喜欢投资房产,风险大,收益也大",
"age":31,
"start":2,
"date":"2020-09-20"
}
]
}
GET netobject/_search
{
"query": {
"bool": {
"must": [
{"match_all": {}}
,
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "黄药师"
}
},
{
"match": {
"comments.age": 48
}
}
]
}
}
}
}
]
}
}
}
- 咱们修改完整mapping 将object替换成nestedbject的底层存储,咱们在进行搜索,如果搜索不对是搜索不出来数据的

6.22.4 基于nestedbject 实现aggs对年龄区间分组
GET netobject/_search
{
"aggs": {
"groub_by_snet": {
"nested": {
"path": "comments"
},
"aggs": {
"groub_by_": {
"histogram": {
"field": "comments.age",
"interval": 10
},
"aggs": {
"groub_his": {
"top_hits": {
"size": 10
}
}
}
}
}
}
}
}
6.22.5 基于nestedbject 实现季度分组
GET netobject/_search
{
"aggs": {
"groub_by_snet": {
"nested": {
"path": "comments"
},
"aggs": {
"group_date": {
"date_histogram": {
"field": "comments.date",
"interval": "quarter",
"format": "yyyy-MM"
},
"aggs": {
"group_top_his": {
"top_hits": {
"size": 10
,
"_source": ["comments.name" ,"comments.comment"]
}
}
}
}
}
}
}
}
6.22.6 父子关系分层
在mysql中,可以使用join来实现表与表之间的数据连接,在es中如何实现这个问题?
更改mapping 映射,让其设置为父子关系,
“my_join_field”:{
“type”: “join”,
“relations”:{
“father”:“son”
}
如果是父,指定其为father,反之,指定为son, 字段是自己自定义的
PUT cina
{
"mappings": {
"properties": {
"city":{
"type": "keyword"
},
"title":{
"type": "keyword"
},
"my_join_field":{
"type": "join",
"relations":{
"father":"son"
}
}
}
}
}
POST cina/_doc/1?refresh
{
"city":"北京",
"my_join_field":{
"name":"father"
}
}
POST cina/_doc/2?refresh
{
"city":"河北",
"my_join_field":{
"name":"father"
}
}
POST cina/_doc/3?refresh
{
"city":"山西",
"my_join_field":{
"name":"father"
}
}
GET cina/_search
POST cina/_doc/5?routing=1&refresh
{
"title":"香蕉",
"my_join_field":{
"name":"son",
"parent": "1"
}
}
POST cina/_doc/6?routing=1&refresh
{
"title":"苹果",
"my_join_field":{
"name":"son",
"parent": "1"
}
}
POST cina/_doc/7?routing=2&refresh
{
"title":"橘子",
"my_join_field":{
"name":"son",
"parent": "2"
}
}
POST cina/_doc/8?routing=2&refresh
{
"title":"苹果",
"my_join_field":{
"name":"son",
"parent": "2"
}
}
POST cina/_doc/9?routing=3&refresh
{
"title":"石榴",
"my_join_field":{
"name":"son",
"parent": "3"
}
}
POST cina/_doc/10?routing=3&refresh
{
"title":"苹果",
"my_join_field":{
"name":"son",
"parent": "3"
}
}
- 查询父数据
GET cina/_search
{
"query": {
"has_child": {
"type": "son",
"query": {
"match_all": {}
}
}
}
}
- 条件查询父数据
GET cina/_search
{
"query": {
"has_child": {
"type": "son",
"query": {
"match": {
"title": "石榴"
}
}
}
}
}
- 通过父id查询子数据
GET cina/_search
{
"query": {
"parent_id":{
"type":"son",
"id":"3"
}
}
}
- 查询子数据
GET cina/_search
{
"query": {
"has_parent": {
"parent_type": "father",
"query": {
"match_all": {
}
}
}
}
}
- 条件查询子数据
GET cina/_search
{
"query": {
"has_parent": {
"parent_type": "father",
"query": {
"match": {
"city": "北京"
}
}
}
}
}
- 分组
GET cina/_search
{
"size": 0,
"aggs": {
"groub_by": {
"terms": {
"field": "city"
},
"aggs": {
"groub_by_childer": {
"children": {
"type": "son"
},
"aggs": {
"groub_tremnt": {
"terms": {
"field": "title"
}
}
}
}
}
}
}
}
- 再次深入练习
PUT china
{
"mappings": {
"properties": {
"city":{
"type": "keyword"
},
"title":{
"type": "keyword"
},
"my_join_field":{
"type": "join",
"relations":{
"father":"son"
}
}
}
}
}
POST china/_doc/1?refresh
{
"city":"北京",
"my_join_field":{
"name":"father"
}
}
POST china/_doc/2?refresh
{
"city":"上海",
"my_join_field":{
"name":"father"
}
}
POST china/_doc/3?routing=1&refresh
{
"title":"香蕉",
"valu":55,
"my_join_field":{
"name":"son",
"parent": "1"
}
}
POST china/_doc/4?routing=1&refresh
{
"title":"榴莲",
"valu":59,
"my_join_field":{
"name":"son",
"parent": "1"
}
}
POST china/_doc/5?routing=1&refresh
{
"title":"西红柿",
"valu":5,
"my_join_field":{
"name":"son",
"parent": "1"
}
}
POST china/_doc/6?routing=2&refresh
{
"title":"苹果",
"valu":25,
"my_join_field":{
"name":"son",
"parent": "2"
}
}
POST china/_doc/7?routing=2&refresh
{
"title":"橙子",
"valu":250,
"my_join_field":{
"name":"son",
"parent": "2"
}
}
POST china/_doc/8?routing=2&refresh
{
"title":"柚子",
"valu":55,
"my_join_field":{
"name":"son",
"parent": "2"
}
}
#查询所有父类
GET china/_search
{
"query": {
"has_child": {
"type": "son",
"query": {
"match_all": {}
}
}
}
}
#查询所有子父类
GET china/_search
{
"query": {
"has_parent": {
"parent_type": "father",
"query": {
"match_all": {}
}
}
}
}
#查询某个父类的所有子类
GET china/_search
{
"query": {
"has_parent": {
"parent_type": "father",
"query": {
"match": {
"city": "北京"
}
}
}
}
}
# 查询父类(条件:子类的valu>250)
GET china/_search
{
"query": {
"has_child": {
"type": "son",
"query": {
"range": {
"valu": {
"gte": 250
}
}
}
}
}
}
- 聚合查询
GET china/_search
{
"query": {
"has_parent": {
"parent_type": "father",
"query": {
"match_all": {}
}
}
},
"aggs": {
"groub_by_val": {
"stats": {
"field": "valu"
}
}
}
}
```**
GET china/_search
{
"query": {
"has_child": {
"type": "son",
"min_children": 2, #最少包含2个
"query": {
"match_all": {}
}
}
}
}**
6.23 (高手进阶) 高亮显示
添加数据
PUT blog_website
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST blog_website/_doc/1
{
"title":"我的第一篇博客",
"content":"大家好,这是我写的第一篇博客,非常喜欢这个博客网站"
}
我们进行搜索,可以搜索到数据,
GET blog_website/_search
{
"query": {
"match": {
"title": "博客"
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
我们想搜索title和content都高亮那就必须条件查询两个都进行查询才可以显示出来,这是相互对应的
highlight的field必须和query的field是一一对应的
GET blog_website/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "博客"
}
},
{
"match": {
"content": "博客"
}
}
]
}
},
"highlight": {
"fields": {
"title": {},
"content": {}
}
}
}
6.23.1 高亮显示 :三种highlight的介绍
plain highlight ,lucene highlight 是默认的
posting highlight ,index_options=offsets
- 性能比plain highlight要高,因为不需要重新对高亮文本进行分词
- 对磁盘消耗少
- 将文本切割为句子,并且对句子高亮,效果好
DELETE blog_website
PUT blog_website
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
, "index_options": "offsets"
}
}
}
}
POST blog_website/_doc/1
{
"title":"我的第一篇博客",
"content":"大家好,这是我写的第一篇博客,非常喜欢这个博客网站"
}
GET blog_website/_search
{
"query": {
"match": {
"content": "博客"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
- fast vector highlight
- index-time trem vector 设置在mapping中,就会用fast verctor highlight
- 对于大field值(大于1mb)性能更多
PUT blog_website
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
, "term_vector": "with_positions_offsets"
}
}
}
}
- 强制使用某种highlight
GET blog_website/_search
{
"query": {
"match": {
"content": "博客"
}
},
"highlight": {
"fields": {
"content": {
"type":"plain"
}
}
}
}
ps:根据实际情况考虑,一半情况下用默认的plain highlight ,不需要做其他额外的设置
如果对高亮性能高,可以尝试用posting highlight
如果field的值河很大,可以尝试用 fast vector highlight
6.23.2 高亮显示 :自定义显示标签
GET blog_website/_search
{
"query": {
"match": {
"content": "博客"
}
},
"highlight": {
"pre_tags": ["<span>"],
"post_tags": ["</span>"],
"fields": {
"content": {
"type":"plain"
}
}
}
}
6.23.3 高亮显示 :参数设置
- fragment_size ,你的一个field的值,如果长度是1w,但是你不可能在页面上显示这么长,设置要显示出来的fragment文本判断长度,默认是100
- number_of_fragments,你可能高亮的文本片段有多个片段,你可以指定显示几个片段
- no_match_size :如果说,对于那些你的query没有匹配到的doc,你的高亮可以显示多少个字符文本
POST blog_website/_doc/2
{
"title":"我的第二篇博客",
"content":"大家好,这是我写的第一篇博客,非常喜欢这个博客网,里面的家人对我非常的号好,我每天都可以里面学习到很多新的知识,也会去分享自己所掌握的知识,我爱博客网,我爱大家"
}
GET blog_website/_search
{
"query": {
"match": {
"content": "博客"
}
},
"highlight": {
"fields": {
"content": {
"fragment_size":20,
"number_of_fragments": 3
, "no_match_size": 10
}
}
}
}
6.24(高手进阶) search temolate
模板搜索,我们将搜索进行模板化,每次执行调用模板,传入参数就可以了
- 可以理解为mysql的?占位
GET blog_website/_search/template
{
"inline":{
"query":{
"match":{
"{{value}}":"{{field}}"
}
}
},
"params": {
"value":"title",
"field":"博客"
}
}
- 上面方法已经被淘汰了,我们试着下面代码
- #! Deprecation: [search_template][2:12] Deprecated field [inline] used, expected [source] instead
GET blog_website/_search/template
{
"source": {
"query": {
"match": {
"title": "{{kw}}"
}
}
},
"params": {
"kw": "博客"
}
}
6.24.1 toJson方式传递参数
- #toJson不要随便改,是一个关键字
GET blog_website/_search/template
{
"source": """{ "query": { "match": {{#toJson}}parameter{{/toJson}} }}"""
,
"params": {
"parameter":{
"title": "博客"
}
}
}
6.24.2 join方式传递参数
GET blog_website/_search/template
{
"source": {
"query": {
"match": {
"content": "{{#join delimiter=','}}kw{{/join delimiter=','}}"
}
}
},
"params": {
"kw": [
"博客",
"网站"
]
}
}
6.24.3 default value
-默认值,我们下面的代码,如果给end赋值就赋值,如果没有就是走默认值
修改数据
POST blog_website/_update/1
{
"doc": {
"views":5
}
}
GET blog_website/_search/template
{
"source": {
"query":{
"range":{
"views":{
"gte":"{{start}}",
"lte":"{{end}}{{^end}}20{{/end}}"
}
}
}
},
"params": {
"start": "1"
}
}
6.25 (高手进阶) completion suggest
suggest ,completion suggest 自动完成,搜索推荐,搜索提示
比如我们百度搜索大话西游,会自动提示“”大话西游电影”,大话西游小说”,“大话西游游戏”等
不需要把你所有想输入的都搜索完,搜索引擎会自动去进行提示
- completion es实现的时候,是有很高的性能的,会构建不是倒排索引,也不是正排索引,就是纯用于前缀搜索的一种特殊的数据结构,而且是全放在内存中,所以搜索性能是非常高的
PUT new_website
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"suggest":{
"type": "completion",
"analyzer": "ik_max_word"
}
}
}
}
}
}
POST new_website/_doc/1
{
"title":"大话西游游戏"
}
POST new_website/_doc/2
{
"title":"大话西游小说"
}
POST new_website/_doc/3
{
"title":"大话西游电影"
}
GET new_website/_search
{
"suggest": {
"search_title": {
"prefix":"大话西游",
"completion": {
"field":"title.suggest"
}
}
}
}
6.25 (高手进阶) 地理位置(gen point)
地理位置
es基于地理位置的搜索,做聚合分析
例如:我们在上海某个大厦附近,我们搜索吉利我们2公里以内的5星酒店,就可以用es
- 修改mapping
PUT mypoint
{
"mappings": {
"properties": {
"location":{
"type": "geo_point"
}
}
}
}
- 添加数据,数据是我在百度开放平台拾取的经纬度坐标,一个北京开放平台,一个廊坊站
POST mypoint/_doc/1
{
"text":"北京天安门",
"location":{
"lon":"116.403838",
"lat":"39.91488"
}
}
POST mypoint/_doc/2
{
"text":"廊坊站",
"location":{
"lon":"116.717203",
"lat":"39.514215"
}
}
6.25.1 geo_bounding_box
- 查询范围内的坐标 两个点缺点一个矩形
geo_bounding_box涉及的参数如下 - top_left: 左上角的矩形起始点经纬度;
- bottom_right: 右下角的矩形结束点经纬度
GET mypoint/_search
{
"query": {
"geo_bounding_box":{
"location":{
"top_left":{
"lon":"116.23316",
"lat":"39.997551"
},
"bottom_right":{
"lon":"116.487273",
"lat":"39.847927"
}
}
}
}
}
top_left 左上角的方位
bottom_right 右下角的方位
蓝色的圈圈是我们取的2个位置,一个北京天安门,一个廊坊车站,我们的top_left 设置的是北京的左上方,bottom_right 设置的是北京的右下方,然后会在左上角和右下角形成一个矩形,矩形里面的数据是我们想查询的范围,天安门属于北京,但是廊坊不属于,所以可以查询出来北京,廊坊不在范围之内
6.25.2 geo_polygon
- 根据范围内的多个点,确定一个范围,去查询范围内的数据
添加数据
PUT hotel_app
{
"mappings": {
"properties": {
"pin":{
"properties": {
"location":{
"type":"geo_point"
}
}
}
}
}
}
POST hotel_app/_doc/1
{
"name":"北京-喜来乐酒店",
"pin":{
"location":{
"lon":"116.403119",
"lat":"39.914492"
}
}
}
POST hotel_app/_doc/3
{
"name":"廊坊-白灯酒店",
"pin":{
"location":{
"lon":"116.717203",
"lat":"39.514215"
}
}
}
POST hotel_app/_doc/2
{
"name":"北京-宜家酒店",
"pin":{
"location":{
"lon":"116.43862",
"lat":"39.950233"
}
}
}
#根据2个点进行矩形查询
GET hotel_app/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_bounding_box":{
"pin.location": {
"top_left":{
"lon":"116.23316",
"lat":"39.997551"
},
"bottom_right":{
"lon":"116.487273",
"lat":"39.847927"
}
}
}
}
]
}
}
}
#多个点查询,具体的范围可以看图片
GET hotel_app/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_polygon":{
"pin.location": {
"points":[
{ "lat":"40.969836","lon":"117.969872"},
{ "lat":"40.784805","lon":"114.892924"},
{"lat":"38.314068","lon":"116.852236"}
]
}
}
}
]
}
}
}
6.25.3 geo_distance
- 查询自己多少公里以内的范围

GET hotel_app/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_distance": {
"distance": "1km",
"pin.location": {
"lat":"39.947882","lon":"116.439662"
}
}
}
]
}
}
}
6.25.4聚合排序
- 聚合排序,统计自己300m以内的酒店,并且显示又多远
GET hotel_app/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_distance": {
"distance": "300m",
"pin.location": {
"lat":"39.947882","lon":"116.439662"
}
}
}
]
}
},
"sort": [
{
"_geo_distance": {
"pin.location": {
"lat":"39.947882","lon":"116.439662"
},
"order": "asc"
}
}
]
}
6.25.5聚合统计区间数据
- 我们统计100-300 100以内,300以上的酒店,就可以统计出来,运用聚合
GET hotel_app/_search
{
"query": {
"match_all": {}
},
"aggs": {
"rings_around_amsterdam": {
"geo_distance": {
"field": "pin.location",
"unit": "m",
"distance_type": "plane",
"origin": {
"lat": 39.947882,
"lon": 116.439662
},
"ranges": [
{
"to": 300
, "from": 100
},
{
"from": 300
},
{
"to": 100
}
]
},
"aggs": {
"top_his": {
"top_hits": {
"size": 10
}
}
}
}
},
"sort": [
{
"_geo_distance": {
"pin.location": {
"lat":"39.947882","lon":"116.439662"
},
"order": "asc"
}
}
]
}
6.25.6 技术提升
- 查询全部数据,然后对数据进行分组,然后过滤出5km以内的数据,然后排序输出,然后继续将范围缩小到一公里去查询
GET hotel_app/_search
{
"query": {
"match_all": {}
},
"aggs": {
"rings_around_amsterdam": {
"geo_distance": {
"field": "pin.location",
"unit": "m",
"distance_type": "plane",
"origin": {
"lat": 39.947882,
"lon": 116.439662
},
"ranges": [
{
"to": 300
, "from": 100
},
{
"from": 300
},
{
"to": 100
}
]
},
"aggs": {
"top_his": {
"top_hits": {
"size": 10
}
}
}
}
},
"sort": [
{
"_geo_distance": {
"pin.location": {
"lat":"39.947882","lon":"116.439662"
},
"order": "asc"
}
}
]
}
GET hotel_app/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{"geo_distance": {
"distance": "5km"
, "pin.location": {
"lat": 39.947882,
"lon": 116.439662
}
}}
]
}
},
"aggs": {
"groub_km": {
"geo_distance": {
"field": "pin.location",
"unit": "m",
"origin": {
"lat": 39.947882,
"lon": 116.439662
},
"ranges": [
{
"from": 100,
"to": 300
},
{
"from": 300
}
]
},
"aggs": {
"roub_top": {
"top_hits": {
"size": 10
}
}
}
}
}
,
"sort": [
{
"_geo_distance": {
"pin.location": {
"lat": 39.947882,
"lon": 116.439662
}
}
}
],
"post_filter": {
"geo_distance": {
"distance": "1km",
"pin.location": {
"lat": 39.947882,
"lon": 116.439662
}
}
}
}
6.25.7 额外补充
PS:geo-polygon-多边形查询(过时)
在 es7.12 中已经过时了,推荐使用 geo_shape来实现
2.我们"distance_type": “plane”, 参数是可选的
sloppy_arc (默认)
arc(精准的,速度慢)
plane(速度很快,不是很精准)
6.25.8 地理位置进阶 geo_shape
Elasticsearch支持两种类型的地理数据:
geo_point:是一个(lon,lat) 经度/纬度 点
geo_shape: 是对geo_point不足之处的拓展.支持点、线、圆、多边形、多多边形.
-
很多初次接触的童鞋,不理解geo_shape. 想象一下,一个学校在地理坐标中怎么表示? geo_point只是一个点位,无法表示一片区域, 所以这个时候就需要可以表示区域的数据结构,这就是geo_shape
-
.geo_point的搜索
先不说怎么搜索,先来聊聊这个point,点顾名思义就是一个经纬度点. 也就是我们的es中存储的每条数据有一个字段存储的是一个经纬度的点. 对于数据中的经纬度点,我们能想到的就是查询的时候提供一个范围,然后判断目标索引中数据的经纬度是否在我提供的范围内, 或者我提供一个点,然后查找目标索引中距离我提供的点在一定距离内. 事实上es确实也是这么做的.
创建mapping
PUT gensope
{
"mappings": {
"properties": {
"location":{
"type": "geo_shape"
}
}
}
}
添加数据
- 一个点
POST gensope/_doc/1
{
"name":"故宫博物院",
"location" : "POINT (116.40368 39.923574)"
}

- 多个点
POST gensope/_doc/2
{
"name":"故宫博物院&北京天安门",
"location" : "MULTIPOINT (116.40368 39.923574,116.404003 39.91508)"
}
- 一条线
POST gensope/_doc/3
{
"name":"北二环-->北京站",
"location" : "LINESTRING (116.422041 39.955522,116.434115 39.909047)"
}

- 多条线
POST gensope/_doc/4
{
"name":"北二环-->北京站-->西城区-->什刹海公园",
"location" : "MULTILINESTRING ((116.422041 39.955522,116.434115 39.909047),(116.366562 39.906834,116.377773 39.954637))"
}
- 任意多边形,意思就是一个面. 一个多边形是由一系列的point 数组定义的。 point数组中的第一个点和最后一个点必须相同(多边形必须是闭合的)
POST gensope/_doc/5
{
"name":"北二环 &&白塔公园 &&天安门&&北二环",
"location" : "POLYGON((116.422329 39.955301,116.449925 39.921665,116.404506 39.915024, 116.422329 39.955301))"
}
- 添加多个面
POST gensope/_doc/6
{
"name":"北二环 &&白塔公园 &&天安门&&朝阳公园&&北二环 and 东城区&北京站&6号线 and 北京动物园 &欢乐谷&朝阳公园,北京动物园 ",
"location" : "MULTIPOLYGON (((116.422329 39.955301,116.449925 39.921665,116.404506 39.915024, 116.422329 39.955301)),((116.424844 39.934446,116.43433 39.910763,116.459914 39.929578, 116.424844 39.934446)),((116.344068 39.948165,116.501883 39.874448,116.488947 39.950378, 116.344068 39.948165)))"
}

ps:图片和我的数据有点不符合,主要是点有点不好找,凑合看
我们的数据都存好了,我们如何使用呢
intersects(相交)、disjoint(相离)、within(内含)、contains(包含) 我们要进行如下操作
GET gensope/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
116.355567,39.956351
],
[
116.446978,39.901686
]
]
},
"relation": "intersects"
}
}
}
]
}
}
}
七:JAVA代码 操作Elasticsearch
- 本次例子:Springboot项目,下图是对应版本
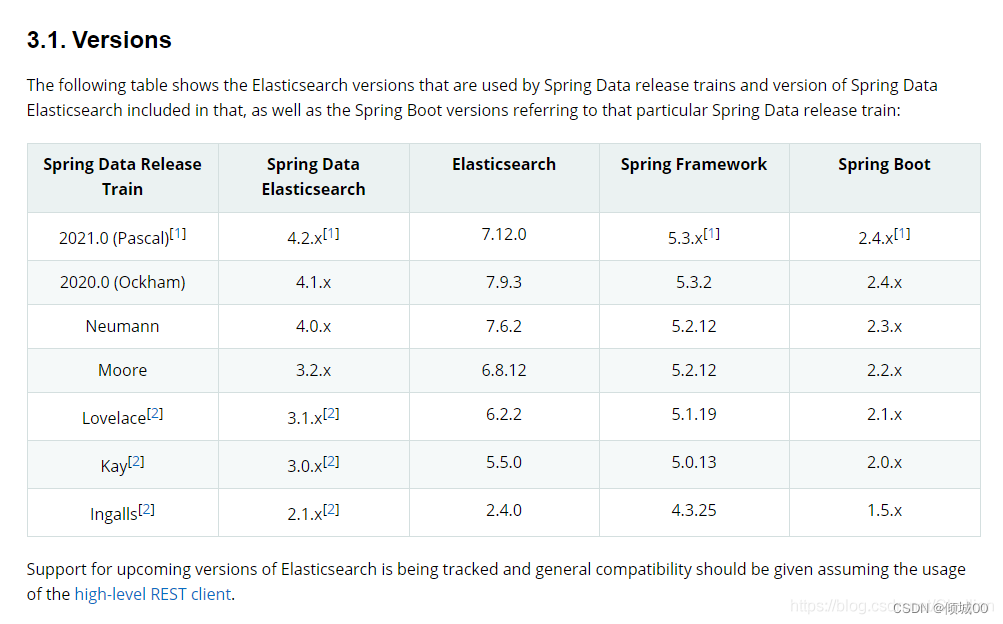
前言:Springboot整合elasticsearch实现简单查询,高级查询等,简单查询在dao层通过继承ElasticsearchRepository复杂查询需要用到ElasticsearchRestTemplate模板类,请看操作,配图文解析lasticsearchRestTemplate模板类复杂查询
7.1配置环境
配置pom文件
注:elasticsearch的版本和Springboot的版本要匹配(不是版本匹配),是兼容问题,如果es用的是7.8但是springboot用的低版本会出现莫名的错误(踩坑注意)
?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bj.ft</groupId>
<artifactId>es7</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.6.RELEASE</version>
<relativePath/>
</parent>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
</dependency>
</dependencies>
</project>
配置实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "student", shards = 3, replicas = 1)
public class Student {
@Id
private String id;//商品唯一标识
private String name;
private String sex;
private int age;
}
配置配置文件
@Configuration
public class esConfig extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost("127.0.0.1", 1001));
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);
return restHighLevelClient;
}
}
配置DAO层
@Repository
public interface StuDao extends ElasticsearchRepository<Student, String > {
}
启动类
@SpringBootApplication
public class APP {
public static void main(String[] args) {
SpringApplication.run(APP.class,args);
}
}
Test
@RunWith(SpringRunner.class)
@SpringBootTest
public class StuTest {
@Autowired
ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
StuDao dao;
//创建索引
@Test
public void creatindex(){
System.out.println("创建索引");
}
@Test //添加一条数据
public void savaStu(){
Student student = new Student();
student.setName("小明");
student.setAge(18);
student.setSex("男");
dao.save(student);
}
}
-
我们执行test测试类,然后打开es去查询,
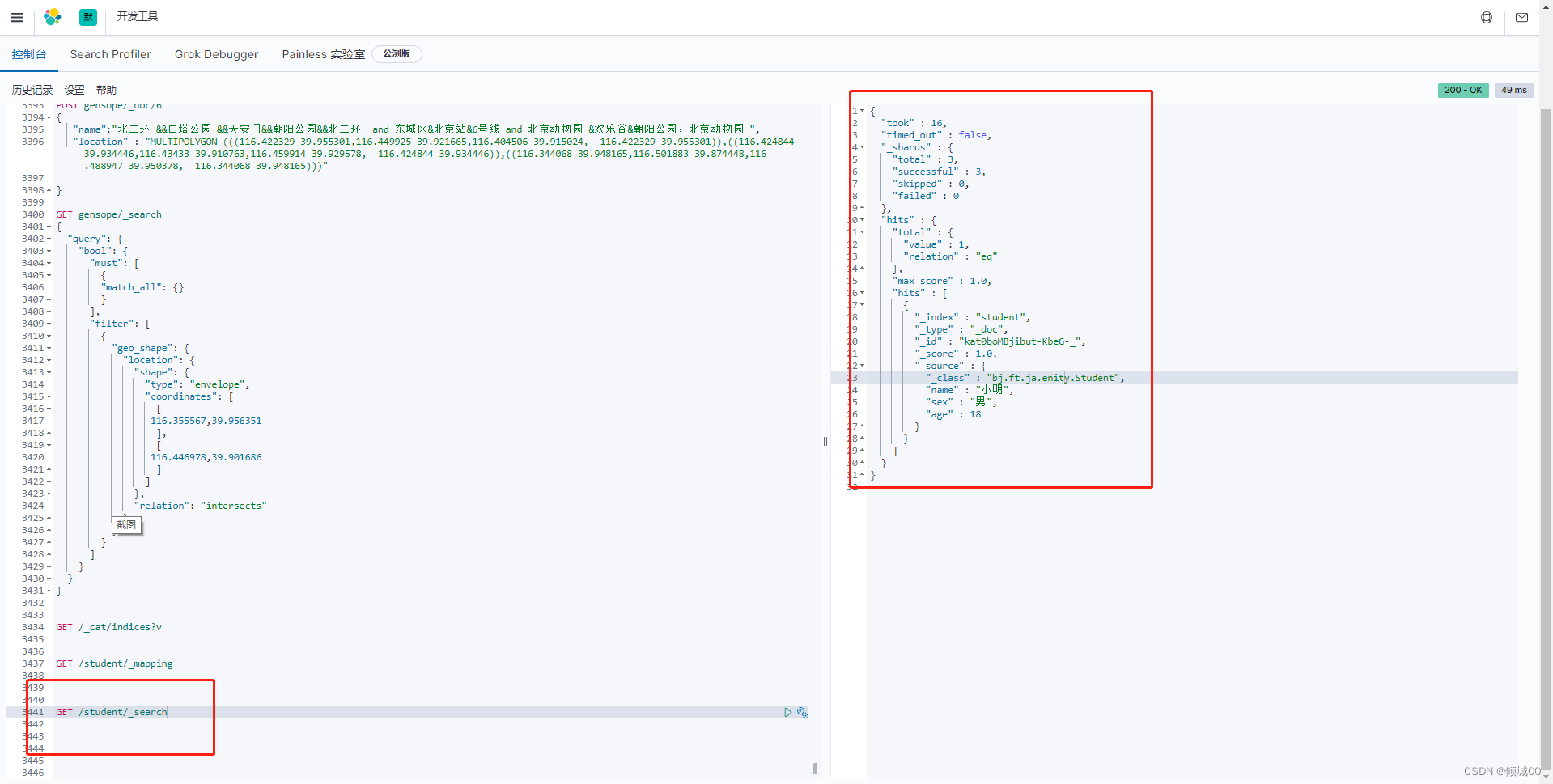
-
数据已经存储进来了,配置成功
-实体类的@Id注解,这个是es的主键表示,我们几乎的操纵座都和id有关系也就是唯一的标识 -
额外补充 SpringData对ES的封装ElasticsearchRestTemplate类,可直接使用,此类在ElasticsearchRestTemplate基础上进行性一定程度的封装,使用起来更方便灵活,拓展性更强。ElasticsearchRepository可以被继承操作ES,是SpringBoot对ES的高度封装,操作最为方便,但牺牲了灵活性。
7.2 删除索引
@Test
public void deleteIndex() {
boolean flg = elasticsearchRestTemplate.deleteIndex(Student.class);
System.out.println("删除索引 = " + flg);
}
7.3 添加一条数据
@Test //添加一条数据
public void savaStu(){
Student student = new Student();
student.setName("小明");
student.setAge(18);
student.setSex("男");
dao.save(student);
}
7.4 批量添加
@Test
public void savaall(){
Student student=new Student();
student.setSex("男");
student.setName("杨过");
student.setAge(28);
Student stu=new Student();
stu.setName("小龙女");
stu.setAge(26);
stu.setSex("女");
List<Student>list=new ArrayList<>();
list.add(stu);
list.add(student);
dao.saveAll(list);
}
7.5 查询全部
@Test
public void finall(){
Iterable<Student> all = dao.findAll();
for (Student student : all) {
System.out.println(student);
}
}
7.6 查询一条
@Test
public void findById(){
Optional<Student> byId = dao.findById("FautboMBjibut-KbaHUj");
System.out.println(byId);
}
7.7 删除一条
@Test
public void delete(){
Student student=new Student();
student.setId("FautboMBjibut-KbaHUj");
dao.delete(student);
}
7.8 删除全部数据
@Test
public void deleteall(){
dao.deleteAll();
}
7.9 修改数据
@Test
public void update(){
Student student = new Student();
student.setId("OKulboMBjibut-Kb8nTD");
student.setName("小龙女");
student.setSex("女");
student.setAge(66);
dao.save(student);
}
7.10 运用模板类进行复杂查询
7.10.1 查询分组
GET /student/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{"range": {
"age": {
"gte": 30
}
}}
]
}
}
}
- 上下两个代码相等
- NativeSearchQueryBuilder 类,可以理解为最外层的query,然后对比着es语句,在里面进行嵌套
@Test
public void query(){
//查询所有 ,并且过滤出20岁
NativeSearchQueryBuilder builder=new NativeSearchQueryBuilder(); //==queyr
builder.withQuery(QueryBuilders.boolQuery() //=====boool
.must(QueryBuilders.matchAllQuery()) // must{
// matchAll()
// }
.filter(QueryBuilders.rangeQuery("age").gte(30)) // 条件查询,查询>30的数据
);
SearchHits<Student> search = elasticsearchRestTemplate.search(builder.build(), Student.class);
for (SearchHit<Student> studentSearchHit : search) {
System.out.println(studentSearchHit);
}
}
7.11 使用 RestHighLevelClient完成复杂查询
配置application.properties文件
server.port=8088
spring.elasticsearch.rest.uris=127.0.0.1:1001
在test类中自动装配
@Autowired
RestHighLevelClient client;
7.11.1 size+条件查询
@Test
public void squery() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //可以理解为最外层的{}
searchSourceBuilder.size(1); //{size=1}
searchSourceBuilder.query(QueryBuilders.boolQuery() //{size=0,query{bool{}}}
.must(QueryBuilders.matchAllQuery())
);
SearchRequest request = new SearchRequest("student");
request.source(searchSourceBuilder);
SearchResponse response = client.search(request,RequestOptions.DEFAULT);
org.elasticsearch.search.SearchHits hits = response.getHits(); //获得his
for (org.elasticsearch.search.SearchHit hit : hits) { //迭代每个元素
System.out.println(hit);
Map<String, Object> sourceAsMap = hit.getSourceAsMap(); //获得map数据源
System.out.println(sourceAsMap);
}
}
7.11.2 geo_distance代码查询
GET hotel_app/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_distance": {
"distance": "300m",
"pin.location": {
"lat":"39.947882","lon":"116.439662"
}
}
}
]
}
}
}
@Test
public void hotel_app() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.boolQuery()
.filter(QueryBuilders.geoDistanceQuery("pin.location").distance("300m").point(39.947882,116.439662))
.must(QueryBuilders.matchAllQuery()));
SearchRequest request = new SearchRequest("hotel_app");
request.source(searchSourceBuilder);
SearchResponse response = client.search(request,RequestOptions.DEFAULT);
org.elasticsearch.search.SearchHits hits = response.getHits(); //获得his
for (org.elasticsearch.search.SearchHit hit : hits) { //迭代每个元素
System.out.println(hit);
}
}
7.11.3 分组,解析分组数据
GET tvs/_search
{
"size": 0,
"aggs": {
"groub_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"top_his": {
"top_hits": {
"size": 10
}
}
}
}
}
}
@Test //解析分组数据
public void groub_by() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.terms("groub_by_color")
.field("color")
.subAggregation(AggregationBuilders.topHits("top_his").size(5))
);
//上述是分组一次然后里面在套一个分组
SearchRequest request = new SearchRequest("tvs");
request.source(searchSourceBuilder);
SearchResponse response = client.search(request,RequestOptions.DEFAULT);
Map<String, Aggregation> stringAggregationMap = response.getAggregations().asMap(); //开始解析数据,获得map
Terms stringTerms= (Terms ) stringAggregationMap.get("groub_by_color"); //我们获得第一次解析的分组名字是groub_by_color
List<? extends Terms.Bucket> buckets = stringTerms.getBuckets(); //将其变成list气门即可取出第一层数据
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKey() +"---"+bucket.getDocCount()); //getKey 获取kex getDocCount获取values
Map<String, Aggregation> stringAggregationMap1 = bucket.getAggregations().asMap(); //解析第二层的数据
ParsedTopHits parsedTopHits=(ParsedTopHits) stringAggregationMap1.get("top_his"); //获得第二层的分组名字
org.elasticsearch.search.SearchHits hits = parsedTopHits.getHits(); //githits
for (org.elasticsearch.search.SearchHit hit : hits) { //迭代
Map<String, Object> sourceAsMap = hit.getSourceAsMap(); //获得map
System.out.println(sourceAsMap);
}
}
}
7.11.4
查询1km之内的数据
public void geo_distance() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.boolQuery()
.filter(QueryBuilders.geoDistanceQuery("pin.location").distance("1km").point(39.947882,116.439662))
.must(QueryBuilders.matchAllQuery()));
SearchRequest request = new SearchRequest("hotel_app");
request.source(searchSourceBuilder);
SearchResponse response = client.search(request,RequestOptions.DEFAULT);
org.elasticsearch.search.SearchHits hits = response.getHits(); //获得his
for (org.elasticsearch.search.SearchHit hit : hits) { //迭代每个元素
System.out.println(hit);
}
八 虚拟机安装es
我本机是ubuntu安装的es
1.将elasticsearch-7.8.0-linux-x86_64.tar.gz 文件拷贝到文件夹中,(放在网盘连接了)
2.解压即可,通过./直接运行
虚拟机安装kibana
观看连接下载,解压bin 文件运行
1.踩坑知识点,不能用root用户启动
2.如果你的虚拟机有java环境,确保java环境配置正确,不然es启动不了(咱们的版本ed有内置的java,但是如果本机没有把本机的java变量配置好也是启动不起来)
3. 将es和kibana的所有文件设置777权限,没权限无法启动















 3488
3488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









