






目录
一.Shell文件介绍
Linux中.sh文件是脚本文件,一般都是bash脚本。文件后缀名为.sh,其中包含一系列要由操作系统的命令解释器执行的命令。在 Unix 和类 Unix 操作系统中,通常使用 Bourne Shell(sh)或其衍生的 Shell(如 Bash、Zsh)来执行这些脚本,本文叙述的都是Bash Shell脚本。
二.运行方式
可以使用bash运行,source运行和./ 运行。
bash运行:bash name.sh或者使用sh name.sh,该方法会创建子进程执行shell脚本,不影响当前环境。
source运行:source name.sh,该方式不创建子进程执行,会影响当前环境。
./ 运行:./name.sh。这个运行方式脚本的首行必须要有#!/bin/bash并且需要给脚本添加执行权限chmod +x name.sh,然后进入脚本所在的目录才能直接运行。该方式同bash运行会创建子进程执行shell脚本,不影响当前环境。如图:
![]()
![]()
三.举例说明
1.shell文档
这里以Android12源码中/build/make/banchanHelsp.sh文件为例来进行一些基本的语法讲解:
#!/bin/bash
# locate some directories
cd "$(dirname $0)"
SCRIPT_DIR="${PWD}"
cd ../..
TOP="${PWD}"
message='usage: banchan <module> ... [<product>|arm|x86|arm64|x86_64] [eng|userdebug|user]
banchan selects individual APEX modules to be built by the Android build system.
Like "tapas", "banchan" does not request the building of images for a device but
instead configures it for an unbundled build of the given modules, suitable for
installing on any api-compatible device.
The difference from "tapas" is that "banchan" sets the appropriate products etc
for building APEX modules rather than apps (APKs).
The module names should match apex{} modules in Android.bp files, typically
starting with "com.android.".
The product argument should be a product name ending in "_<arch>", where <arch>
is one of arm, x86, arm64, x86_64. It can also be just an arch, in which case
the standard product for building modules with that architecture is used, i.e.
module_<arch>.
The usage of the other arguments matches that of the rest of the platform
build system and can be found by running `m help`'
echo "$message"2.内容解释
(1)在Unix和Linux系统中,bash shell脚本文件的第一行用于指定解释该脚本的程序。通常都是#!/bin/bash,也有第一行为#!/bin/sh的。
#!:这是一个特殊的标记,它告诉系统接下来的路径是一个解释器的路径,这个解释器是用来执行该脚本的。
/bin/bash:/bin/bash是bash shell在大多数Linux系统上的默认安装路径。但在有的系统上它可能位于/usr/bin/bash等其他目录,在这种情况下,要把第一行更改为正确的路径。
(2)# locate some directories是注释,一般sh文件没有多行注释,通常使用单行注释,即在语句前加#,语句后添加注释则是空格加上#来撰写单行注释,如果想使用多行注释可以使用以下技巧:
A. 使用:命令,:是一个空命令,表示啥也不做,虽然什么也不会做,但是在:后面的这些行也会被解析,如果这些内容没有实际的命令或者语法上的错误,对sh脚本来说不会产生任何效果。
:'这是一个多行注释
请注意,这不是真正的多行注释
这只是一个不执行任何操作的命令'
B.使用:<<'END' END
:
这是一个多行注释
请注意,但不是真正的多行注释
END
(3)cd "$(dirname $0)":bash命令,将当前工作目录更改为脚本所在的目录
$0:特殊的shell变量,代表当前脚本的名称,该名称包含脚本所在的路径
dirname:后面加路径,用于提取该路径的目录部分
$:sh脚本中用来引用变量名的,$+变量名可以引用变量的内容
(4)SCRIPT_DIR="${PWD}":bash命令,PWD变量是特殊的shell变量,代表当前工作目录的完整路径,=将PWD变量赋值给SCRIPT_DIR变量,由于运行了第3点,所以此时SCRIPT_DIR变量是脚本所在的目录路径。
(5)cd ../..:非常标准的Linux常用命令,从当前所在的目录往上级目录退回两级,举个例子:

(6)TOP="${PWD}",bash命令,和第二行类似,这行代码将当前工作目录(经过 cd ../.. 命令更改后)的完整路径赋给 TOP 变量。因此,TOP 变量将包含脚本所在目录的上级目录的上级目录的路径。
这些脚本的主要目的是确定脚本所在的目录(保存在 SCRIPT_DIR 变量中)和该目录的上上级目录(保存在 TOP 变量中)。这在许多脚本中都是有用的,因为脚本可能需要在不同的目录间导航以访问资源或执行其他任务。
(7)message='':将该脚本文件的用法说明(一大串字符串)赋值给变量message。
(8)echo "$message":将message这个字符串打印到终端上
echo $"变量名" 这种用法通常与已本地化的字符串(翻译过的字符串)相关。
在 bash 中,当变量名被双引号括起来并前面有 $ 时,bash 会检查该字符串是否是一个有效的消息目录条目。如果是,并且已设置了适当的本地化环境(如 LANG, LANGUAGE, LC_ALL, LC_MESSAGES 等),bash 将尝试查找并返回该条目的翻译。
四.如何写一个Shell脚本
1.基本规范
(1)文件名使用.sh结尾
(2)Shell文件中可以通过分号组合多条命令,但一般都使用一行对应一条命令
cd /home/ ; ls ; cd ../
#或者使用以下代码,效果是一致的
cd /home/
ls
cd ../2.使用符号
2.1常用符号
#表示一个注释。
;命令分隔符。同一行上写多个命令时,命令之间用;分隔。
\转义字符。转义后面的字符,使其具有特殊的意义或去除其特殊意义。例如,\n 代表换行符,\" 用于在双引号字符串中包含双引号字符。
"双引号。用于定义字符串。但某些特殊字符(如$, `, \, ")会保留其特殊意义。
`反引号,旧式的命令替换,它用于执行命令并替换为命令的输出
'单引号。用于定义字符串。单引号内的内容会原样保留,不会进行任何 shell 解释或变量替换。
:空语句
\n换行符,不是所有echo都支持转义字符,使用-e选项会让echo解释转义符号\t制表符也同理。
\r回车符。
\t制表符。通常用于缩进或对齐文本。
$变量前缀。在 shell 脚本中,$ 用于引用变量的值。例如,echo $HOME 会输出当前用户的主目录。
举例如下:
#!/bin/bash
#这是一个注释
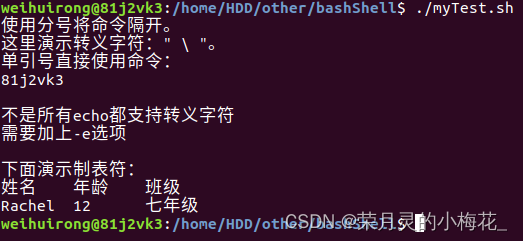
echo "使用分号将命令隔开。";echo "这里演示转义字符:\" \\ \"。"
echo "单引号直接使用命令:"
echo `hostname`
echo -e "\n不是所有echo都支持转义字符\n需要加上-e选项\n"
echo "下面演示制表符:"
echo -e "姓名\t年龄\t班级\nRachel\t12\t七年级" 运行结果为:
2.2运算符
(1)赋值运算符号
=赋值运算符,用于算术赋值和字符串赋值
(2)算数运算符号
+-*/%分别是加减乘除和取余,在bash4.0及以上版本中**是幂运算,++是递增,--是递减。
$(( ))和$[]都是算术扩展符号,但$[]的用法较老兼容性较差。
expr和let都是数学运算命令:
expr是命令行工具,用于求值后返回结果,通常用于整数计算,运算符前后需要加空格,并且*需要使用转义符号,否则会报错,因为*在shell脚本中有通配符的特殊含义。
let命令是shell的内置命令,用于进行算术运算后将结果存储在变量中。
举例:
#!/bin/bash
a=4
b=5
c=$a+$b
echo $c
echo $((4+5))
echo $((a+b))
echo $[a+b]
echo `expr 4 \* 5`
let d=a+b
echo $d运行结果为:
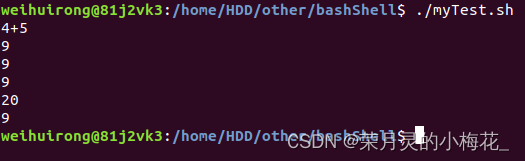
注意:c=4+5或者是c=$a+$b,输出c的结果都是4+5,而如果c=a+b,则echo c的结果为a+b,由此可见是否使用$(())符号结果是不一样的。
(3)比较运算符
-eq和==是等于,可用于比较字符串,==用于某些版本的[[......]]条件测试中
-ne和!=是不等于,可用于比较字符串,!=用于某些版本的[[......]]条件测试中
-gt和>大于
-lt和
-ge大于或等于
-le小于或等于
(4)逻辑运算符:-a和&&是与,-o和||是或,!是非
(5)位运算符(bash 4.0及更高版本中)
位运算符不常用,但是在执行低级位操作时是有用的:
&位于,|位或,^位异或,~位非,>右移
(6)字符串运算符
-z字符串为空字符串
-n字符串长度不为0
${#string}获取字符串的长度
${#string:position:length}从字符串的第几个位置提取长度为length的子串,注意是从0开始的。
(7)文字测试运算符
-e文件存在
-d文件是目录
-r文件可读
-w文件可写
-x文件可执行
-f文件是常规文件,不是目录也不是特殊文件
-s文件的有大小,不是非零文件
-perm文件权限与指定权限匹配
-nt用于文件的比较,文件是最新的,比比较的文件新
-ot文件比比较的文件旧
这里用简单的if语句(if语句的语法见四.4)对上述运算符的使用进行举例:
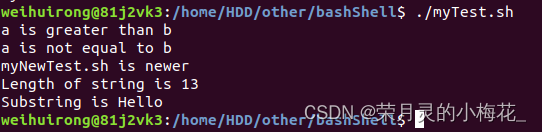
#!/bin/bash
a=5
b=3
if [ $a > $b ]; then
echo "a is greater than b"
fi
if [ $a -gt $b ] || [ $a -lt $b ]; then
echo "a is not equal to b"
fi
file1="/home/HDD/other/bashShell/myTest.sh"
file2="/home/HDD/other/bashShell/myNewTest.sh"
if [ $file1 -nt $file2 ]; then
echo "myNewTest.sh is newer"
fi
string="Hello, World!"
echo "Length of string is ${#string}"
echo "Substring is ${string:0:5}"运行结果为:
2.3重定向符
主要用于改变命令的输入和输出方向。
(1)输出重定向符
>:将命令的标准输出重定向到文件。如果文件已存在,它会被覆盖。如果文件不存在,它会被创建。
>>:将命令的标准输出追加到文件。如果文件已存在,新的输出会被添加到文件的末尾。如果文件不存在,它会被创建。
(2)输入重定向符
<:将文件的内容作为命令的标准输入
<<:用于将多行文本重定向到命令的标准输入。通常与一个标识符(如 EOF、END 等)一起使用,以标记输入文本的结束,以下是一个示例:
cat > /home/fileconfig/myNewTest.sh << EOF
echo "hello world"
EOF运行结果如下:
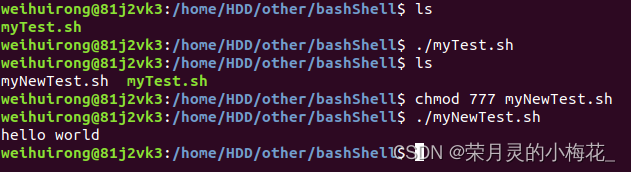
这段代码是把echo "hello world"这个语句写到了/home/fileconfig/myTest.sh文件中,可以看到一开始这个文件是不存在的,运行命令后创建了myNewTest.sh文件,然后赋予权限使用./方式运行myNewTest.sh文件,于是就看到终端打印了hello world。
(3)错误重定向
2>:将命令的标准错误输出重定向到文件。与 > 类似,如果文件已存在,它会被覆盖。
2>>:将命令的标准错误输出追加到文件。与 >> 类似,新的输出会被添加到文件的末尾。
(4)同时重定向标准输出和标准错误
&> 或 >&:将命令的标准输出和标准错误都重定向到同一个文件。
2>&1:首先正常地重定向标准输出(可能是到文件,也可能是其他命令),然后将标准错误重定向到标准输出所指向的地方。
/dev/null:特殊的设备文件,它会丢弃所有写入它的数据。通常用于丢弃不需要的输出。例如,command > /dev/null 会丢弃 command 的所有输出
3.使用变量
3.1变量的分类
(1)用户自定义变量
由用户自行定义。在3.2-3.4中有对如何定义及使用自定义变量的简单叙述。
(2)环境变量
主要用于定义系统级别的配置和状态信息,常见的环境变量有HOME,PATH,USER和SHELL等。可以通过export命令将用户自定义变量设置为环境变量。
(3)系统变量
由shell脚本程序自定义,用于存储脚本程序运行时的相关信息。常见的系统变量有:$0当前脚本名称,$#传递给脚本的参数个数,$*所有参数列表,$?上一条命令的退出状态(0表示成功非0表示失败)
除了上述变量还有一些只读变量,未知参数变量等。
3.2基本使用方式
定义变量并赋值格式:变量名=变量;使用unset 变量名取消变量,使用$符号取变量值,$变量的效果与${变量}的效果一致。
注意:变量名字不可以用数字开头,不能使用特殊符号,区分大小写,且等号两边不使用空格,同样,+-*/这些运算符号与变量之间不能使用空格符号。
例如:
#!/bin/bash
A = 1
a=1
b=string
echo a;echo b
echo $a;echo $b;echo ${b}
unset a;unset b
echo $a;echo $b运行结果为:
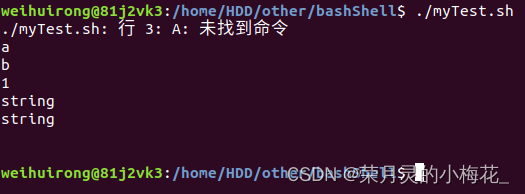
可以看到如果=前后有空格则会直接报错,如果不加$符号,那么会直接输出a,而不是a的值,$变量 的输出结果与${变量}的输出结果一致。
3.3交互式定义变量
交互式定义变量是指通过如命令行或者图形界面等来定义和设置变量的值。Bash shell脚本中一般使用read命令来实现。
举例:
#!/bin/bash
read name
read -p age
read -s password
echo $name
echo $password这个命令会让用户输入值,并且把值赋值给read命令后的变量。
read命令可以支持一些选项和参数,用于控制输入的方式和格式,比如-p用于指定提示信息,-s用于隐藏输入内容,一般在输入密码时使用。上述命令执行过程如下:
第一行需要输入name,但终端不会显示任何提示性的东西:

输入Agen,敲回车,终端出现age,提示我输入的内容是年龄:

当然为了终端输出更好看,也可以将第四行代码改为read -p "请输入您的年龄: " age。则会显示:

继续以上述代码为例,键入年龄后回车,接下来我输入123456,输入的这串内容终端不可见,再敲击回车,我输入的name和password会输出到终端:
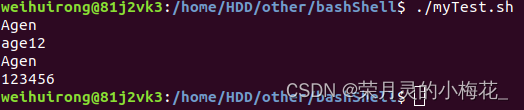
3.4将命令的结果赋值给变量
使用``以及$()符号可以将命令的结果赋值给变量。
#!/bin/bash
name=`hostname`
date=$(date +%F)
echo $name
echo $date
运行结果为:

4.if语句
(1)基本格式
if [ 条件 ]
then
# 如果条件为真,执行这里的代码
# ...
else
# 如果条件为假,执行这里的代码(可选)
# ...
fi(2)注意事项
条件必须放在方括号[]中;方括号[]和条件之间以及条件和then之间都需要有空格;fi是if语句的结束标志。具体示例可以在本文使用运算符中查看。
(3)case语句
基本格式:
case 变量 in
模式1)
# 如果变量匹配模式1,则执行这里的命令
;;
模式2)
# 如果变量匹配模式2,则执行这里的命令
;;
...
*)
# 如果变量不匹配任何模式,则执行这里的命令(默认情况)
;;
esac以下是对上述格式的解释:
- case 变量 in:开始一个case语句,并指定要匹配的变量。
- 模式1)、模式2)等:这些要与变量值进行比较的模式。每个模式后面都跟着一个)和一组命令,这组命令在变量与模式匹配时执行。
- ;;:表示命令块的结束。每个case分支都以;;结束。
- *):这是一个通配符模式,用于捕获所有不匹配前面任何模式的值。它通常作为case语句的最后一个分支,以处理所有未明确指定的值。
- esac:表示case语句的结束。
举例如下:
#!/bin/bash
# 读取用户输入
read -p "请输入一个数字 (1-3): " num
# 使用case语句判断输入的数字
case $num in
1)
echo "你输入了 1"
;;
2)
echo "你输入了 2"
;;
3)
echo "你输入了 3"
;;
*)
echo "输入无效,请输入1到3之间的数字"
;;
esac运行结果为:
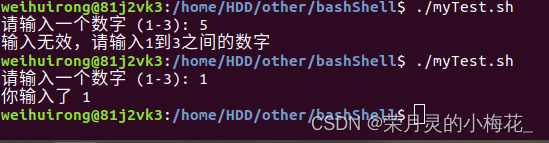
5.循环语句
5.1 for循环语句
for循环用于遍历一系列的值,并对每个值执行相同的操作。
基本格式是:
for 变量 in 列表
do
# 执行命令
done举例如下
#!/bin/bash
for i in {1..5}
do
echo "当前数字是 $i"
done{1..5} 是一个序列扩展的特性,这个特性允许生成一个从1到5的整数序列。
上述脚本运行结果为:

5.2 while循环语句
while循环在条件为真时执行命令块,直到条件不再满足为止。
基本格式:
while [ 条件 ]
do
# 执行命令
done举例:
#!/bin/bash
counter=1
while [ $counter -le 5 ]
do
echo "当前计数器值是 $counter"
counter=$((counter+1))
done运行结果为:
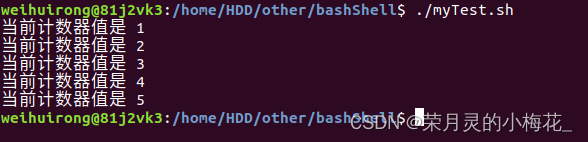
5.3 until 循环语句
until循环与while循环相反,它在条件为假时执行命令块,直到条件变为真为止。
基本格式:
until [ 条件 ]
do
# 执行命令
done举例:
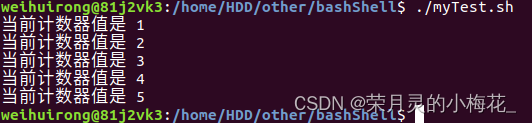
#!/bin/bash
counter=1
until [ $counter -gt 5 ]
do
echo "当前计数器值是 $counter"
counter=$((counter+1))
done运行结果为:
5.4 break和continue语句
break命令用于立即退出当前循环,而continue命令用于跳过当前循环的剩余部分,并开始下一次迭代。
(1)break 命令
break命令用于在循环中立即退出循环。当break被执行时,它将结束最近的循环(例如,最近的for、while或until循环)。
示例:
#!/bin/bash
for i in {1..5}
do
if [ $i -eq 3 ];
then
break
fi
echo "当前数字是 $i"
done
echo "循环已结束"运行结果为:
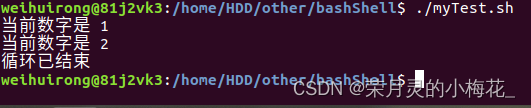
当$i的值等于3时,break命令会被执行,循环将立即结束。所以只有数字1和2被打印出来。
(2)continue 命令
continue命令用于跳过当前循环迭代的剩余部分,并立即开始下一次迭代。当continue被执行时,它将跳过当前迭代中continue之后的所有命令。
示例:
#!/bin/bash
for i in {1..5}
do
if [ $((i % 2)) -eq 0 ]; then
continue
fi
echo "当前数字是 $i(奇数)"
done运行结果为

举例是检查每个数字是否是偶数。如果是偶数(即$((i % 2))等于0),则执行continue命令,跳过当前迭代,不打印任何内容。所以只有1、3和5这三个奇数被打印,并且下一句echo命令也会执行。
6.数组
(1)定义数组
通过直接为数组的元素分配值来定义数组。数组元素可以使用索引来引用,索引从0开始。
# 定义并初始化数组
array_name=(value1 value2 value3 ...)
# 也可以逐个为数组元素赋值
array_name[0]="value1"
array_name[1]="value2"
array_name[2]="value3"
# ...(2)访问数组元素
使用${array_name[index]}的语法来访问数组中的特定元素。
# 访问第一个元素
echo ${array_name[0]}
# 访问第二个元素
echo ${array_name[1]} (3)获取数组长度
用${#array_name[@]}或${#array_name[*]}来获取数组的长度。
# 获取数组长度
length=${#array_name[@]} (4)遍历数组
使用循环来遍历数组的所有元素。
# 使用for循环遍历数组
for element in "${array_name[@]}"
do
echo "$element"
done注意:在循环中,我们使用"${array_name[@]}"而不是$array_name或"${array_name[*]}",因为"${array_name[@]}"可以保留数组中的空格和特殊字符,而"${array_name[*]}"会将所有元素作为单个字符串处理,其中元素之间由空格分隔。
(5)修改数组元素
通过重新为数组元素赋值来修改。
# 修改第一个元素的值
array_name[0]="new_value1"(6)删除数组元素
Shell脚本中没有直接删除数组元素,但可以通过重新分配数组来“删除”元素,或者将元素的值设置为空。
# "删除"第二个元素(实际上将其设置为空字符串)
array_name[1]=""举例:
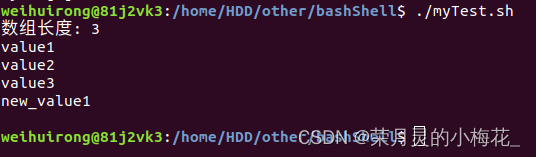
#!/bin/bash
array_name[0]="value1"
array_name[1]="value2"
array_name[2]="value3"
length=${#array_name[@]}
echo "数组长度: $length"
# 使用for循环遍历数组
for element in "${array_name[@]}"
do
echo "$element"
done
# 修改第一个元素的值
array_name[0]="new_value1"
echo ${array_name[0]}
array_name[1]=""
echo ${array_name[1]}运行结果为:
7.函数
建议在脚本的顶部定义函数,然后在需要时调用。这可以使脚本的结构更清晰。
命名时需要注意:
- 使用小写字母和下划线(snake_case)来命名函数,如 my_function_name。
- 避免使用大写字母,因为大写字母通常用于环境变量和特殊变量。
- 避免使用与shell内置命令、关键字或特殊字符相同的名称。
下文是有关函数的一些简单介绍。
(1)定义函数
可以直接使用函数名(){}的格式定义,也可以加上function关键字来定义函数。大括号{}之间的是函数体。
# 使用function关键字定义函数
function my_function() {
echo "Hello from my_function!"
}
# 不使用function关键字定义函数
my_other_function() {
echo "Hello from my_other_function!"
}(2)调用函数
定义函数后,可以在脚本的任何位置调用,只需键入函数名即可,且在调用函数时不需要在函数名后添加括号或参数。
# 调用函数
my_function
my_other_function举例如下:
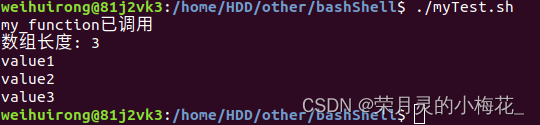
#!/bin/bash
array_name[0]="value1"
array_name[1]="value2"
array_name[2]="value3"
function my_function() {
length=${#array_name[@]}
echo "my_function已调用"
echo "数组长度: $length"
for element in "${array_name[@]}"
do
echo "$element"
done
}
my_function运行结果为:
(3)函数参数
shell脚本中函数可以接受参数,就像脚本可以接受命令行参数一样。在函数内部使用$1、$2、$3等来引用传递给函数的参数,$#表示传递给函数的参数数量,$@和$*表示所有参数。
举例:
#!/bin/bash
read -p "请输入你的姓名:" name
read -p "请输入你的年龄:" age
function use_date(){
echo "刚才输入的姓名是:$1"
echo "刚才输入的年龄是:$2"
}
use_date "$name"
use_date "$name" "$age"运行结果为:
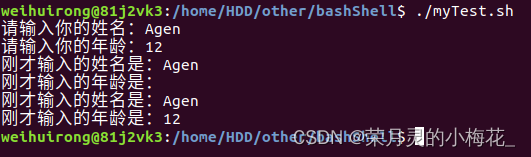
由于第一次调用时没有传入$2参数,所以第一次调用函数时并不会打印$2,但第二次传入了两个参数,所以两个参数都成功打印。
只有一个参数就使用$1,第二个参数使用$2,第三个$3,以此类推。固定就是这么写的,不要交换顺序,也不要写错,否则是会报错的。
(4)返回值
默认没有返回值,一般是返回退出状态码,通常是上一个执行的命令的退出状态码。但可以使用echo语句打印输出,并使用命令替换$(...)来捕获这些输出,并在需要时将其用作返回值。
sum_numbers() {
local num1=$1
local num2=$2
echo $((num1 + num2))
}
# 调用函数并捕获输出
result=$(sum_numbers 3 5)
echo "The sum is: $result"运行结果为:

(5)内的局部变量
如果在函数外部定义了一个变量,并且没有在函数内部使用local关键字声明同名变量,那么函数将能够访问并修改这个全局变量。为了保持函数的独立性和可重用性,最好在函数内部使用局部变量。
(6)函数库
函数定义在一个单独的文件中可被称为“函数库”,在其他脚本中使用source或.命令来加载它。这样可以在多个脚本之间共享函数定义。
举例如下:
在/home/HDD/other/bashShell/myTest.sh文件中写入以下代码:
#!/bin/bash
sum_numbers() {
echo "正在调用函数库中的函数..."
echo -e "生成信息:\n姓名\t年龄\t班级\t\n$1\t$2\t$3"
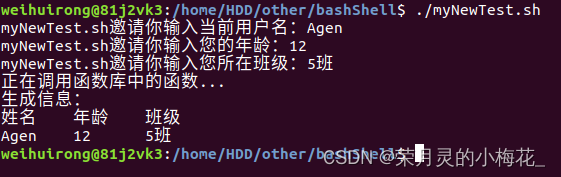
} 在 myNewTest.sh中写入以下代码:
#!/bin/bash
source /home/HDD/other/bashShell/myTest.sh
read -p "myNewTest.sh邀请你输入当前用户名:" name
read -p "myNewTest.sh邀请你输入您的年龄:" age
read -p "myNewTest.sh邀请你输入您所在班级:" class
sum_numbers "$name" "$age" "$class"运行 myNewTest.sh结果为:
以上就是关于Shell文件的简单介绍,如有错误烦请在评论区指出。















 2619
2619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









