







文章目录
并行及分布式框架
并行计算常用技术
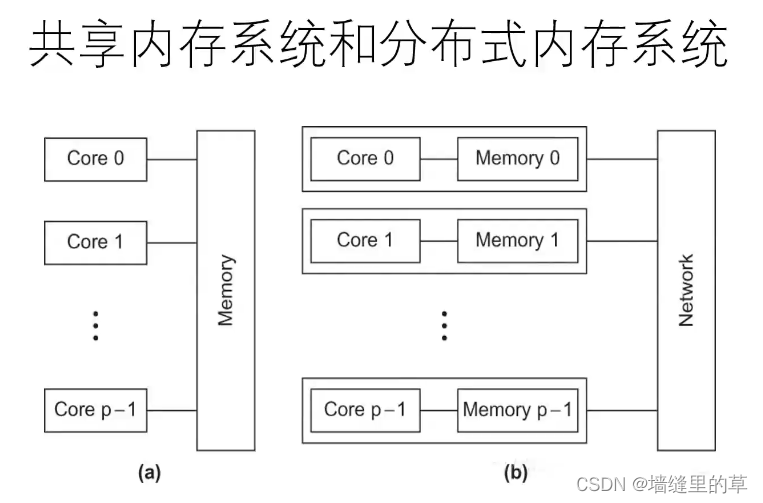
共享内存系统和分布式内存系统概述
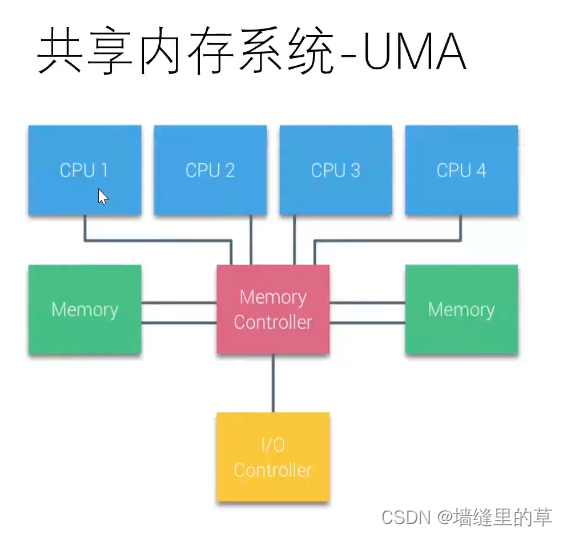
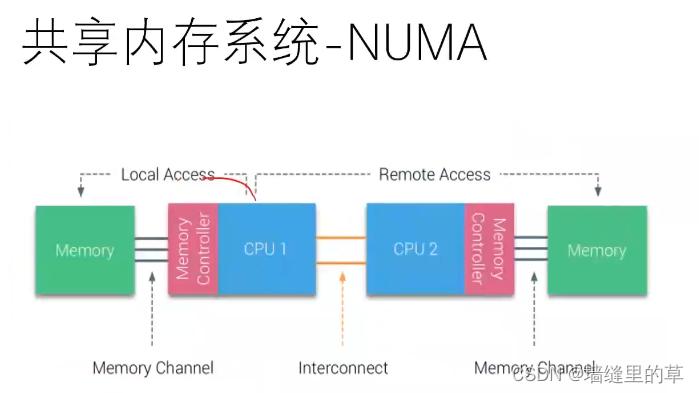
统一内存访问(UMA)系统或对称多处理器(smp)
在numa内多核cpu根据cpu的主频不一样其亲和性也会不一样,主频高的亲和性越高,低的功耗越小。
OPENMP技术
(Open Multi-Processing,开放多处理)
主要是为共享式存储计算机上的并行程序设计使用,支持多平台共享存储器多处理器编程的C/C++和Fortran语言的规范和API。
OPENMP提供对于并行描述的高层抽象,降低了并行百年城的难度和复杂度。
OpenMP编程模型
采取传统的fork-join模式,并行执行的控制流之间共享存储器。
OpenMP程序单线程执行开始,在parallel伪指令调用处,主线程产生多个子线程
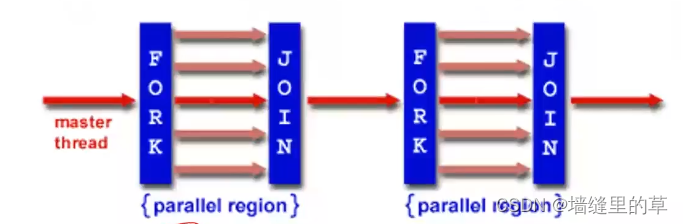
缺点:不适合需要复杂的线程间通信。
不是很好在非共享内存系统上使用。
OPENMP API构成
编译伪指令
Pragma伪指令:通过通过标识引导编译器对相应代码段做处理,编译器根据指令自动将程序并行化,并加入同步互斥等手段。
eg:#pragma omp parallel
运行时函数
eg:int omp_get_num_threads();
环境变量
eg: export OMP_THREAD_LIMIT=8
OpenMP常用指令
prallel,用在一个代码段之前,表示这段代码将被多个线程并行执行
for,用于for循环之前, 将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。
prallfor,parallel 和for语句的结合,也是用在一个for循环之前,表示for循环的代码将被多个线程并行执行。
sections, 用在可能会被并行执行的代码段之前
pallel sctions, parallel和sections两 个语句的结合
citical,, 用在一段代码临界区之前
singe,用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
brrier,用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才续往下执行。
atomic,用于指定一块内存区域被制动更新
master,用于指定一段代码块由主线程执行
ordered,用于指定并行区域的循环按顺序执行
thedpivate,用于指定一个变量是线程私有的。
OpenMP常用函数
omp_ get_ num_ procs,返回运行本线程的多处理机的处理器个数。
omp get_ num_ threads,返回当前并行区域中的活动线程个数。
omp get. thread_ num, 返回线程号
omp_ set. nugn threads,设置并行执行代码时的线程个数
omp_ init Jock, 初始化一-个简单锁
omp_ set_ lock ,上锁操作
omp_ unset_ lock,解锁操作,要和omp_ set_ lock 函数配对使用。
omp_ destroy_ lock ,omp_ init_ _lock函数的配对操作函数,关闭一个锁
OpenMP 环境变量
●OMP NUM_ THREADS:指定执行并行区域时使用的默认线程数量。
●OMP_ PROC_ BIND:决定了是否允许线程迁移到其他的处理器上执行。设置为True时,运行时不会在处理器间迁移线程。
●OMP THREAD_ LIMIT:指定 了系统能够创建的OpenMP线程的最大值。
●OMP NESTED:决定了是否支持嵌套线程,True时支持。
MPI技术
●MPI是一个跨语言的通讯协议。支持点对点和广播。
●MPI是- -个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。
●MPI的目标是高性能,大规模性,和可移植性。
●与OpenMP并行程序不同,MPI是一种基于信息传递的并行编程技术。MPI标准定义了一组具有可移植性的编程接口。
MPI消息传递
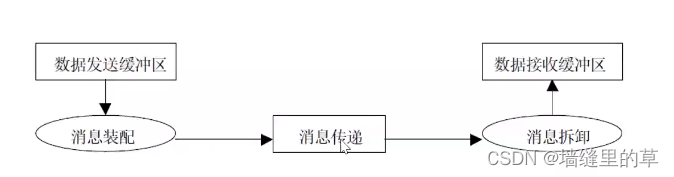
MPI消息传递规程三个阶段:
1.消息装配将发送数据从发送缓冲区中取出加上消息信封等形成一个完整的消息
2.消息传递将装配好的消息从发送端传递到接收端
3.消息拆卸从接收到的消息中取出数据送入接收缓冲区
通信器
●通讯器定义了←组能够互相发消息的进程。在这组进程中,每个进程会被分配大个序号,称作秩(rank)-六进程间显性地通过指定秩来进行通信。
●通信的基础建立在不同进程间发送和接收操作。J–个进程可以通.过指定另一-个进程的秩以及一个独一无二的消息标签(tag) 来发送消息给另一个进程。接受者可以发送一个接收特定标签标记的消息的请求(或者也可以完全不管标签,接收任何消息),然后依次处理接收到的数据。类似这样的涉及一个发送者以及一个接受者的通信被称作,点对点(point-to-point) 通信。
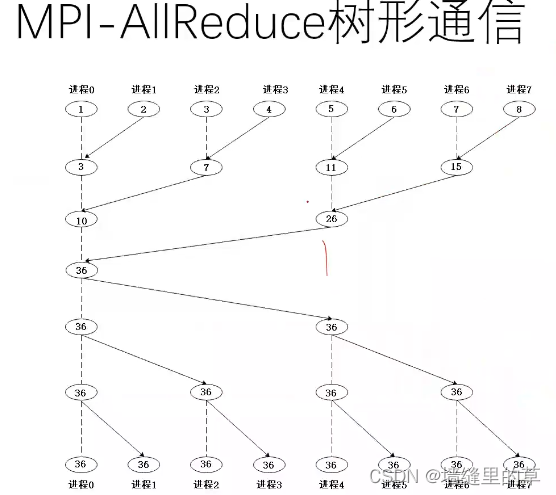
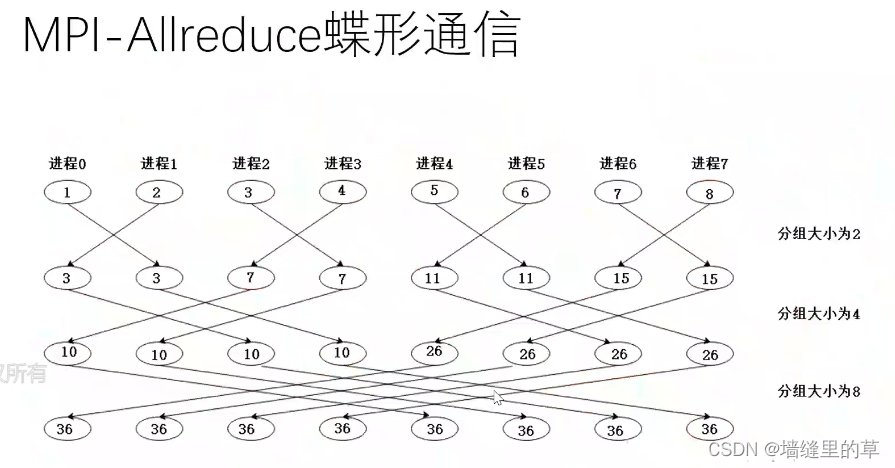
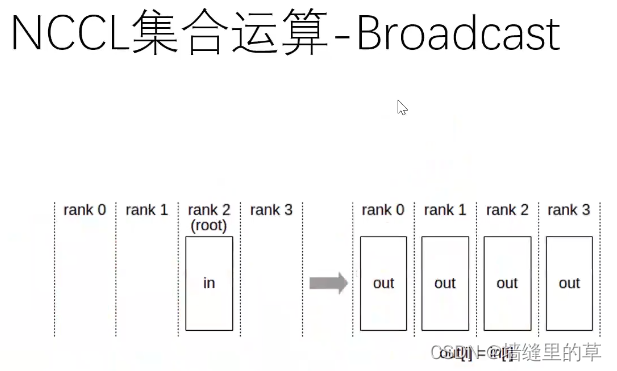
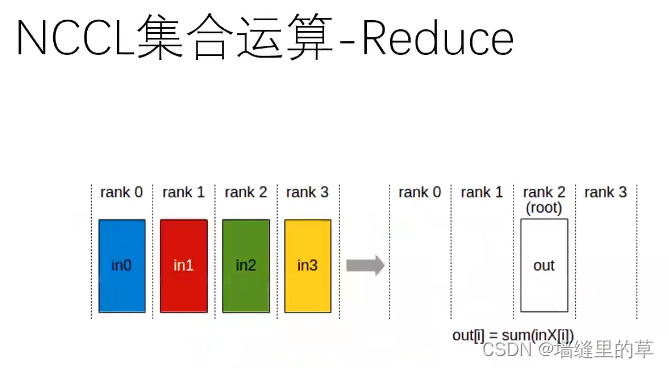
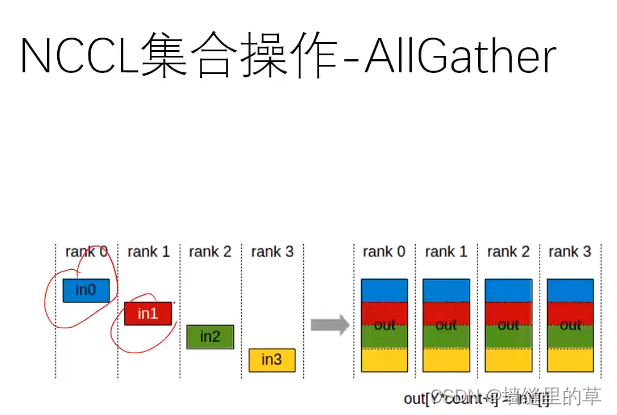
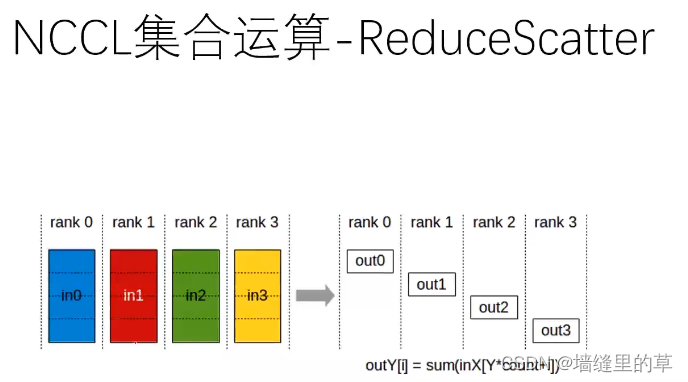
Nvidia NCCL技术
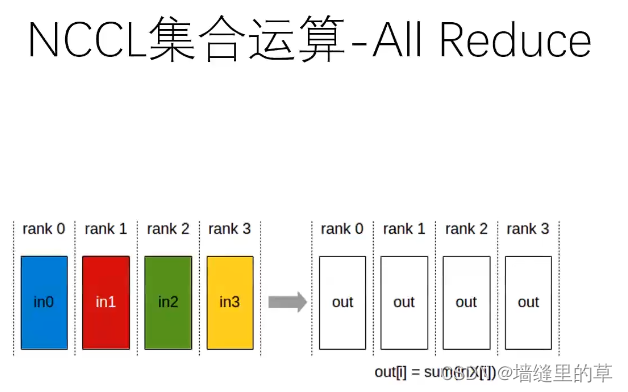
●NCCL是Nvidia Collective multi-GPU Communication Library的简称,它是一个实现多GPU的collective communication通信(all-gather, reduce, broadcast)库,Nvidia做 了很多优化,以在PCle、Nvlink、 InfiniBand. 上实现较高的通信速度。














 290
290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









