







今天打开手机,打开某站,看起了本周的每周必看,一个疑问在我的脑中升起
目前上榜次数最多的up到底是谁!
目前上榜次数最多的up到底是谁!
目前上榜次数最多的up到底是谁!
恰好目前正好有一定的python基础,那就来玩一下吧
提前准备
对于爬取,我们首先需要分析的是他数据的存储格式和返回格式,通过对于某站的网络,我们锁定到下面两个网站
详细期数信息:https://api.xxxxx.com/x/web-interface/popular/series/one?number=XXX
所有期数信息:https://api.xxxxx.com/x/web-interface/popular/series/list

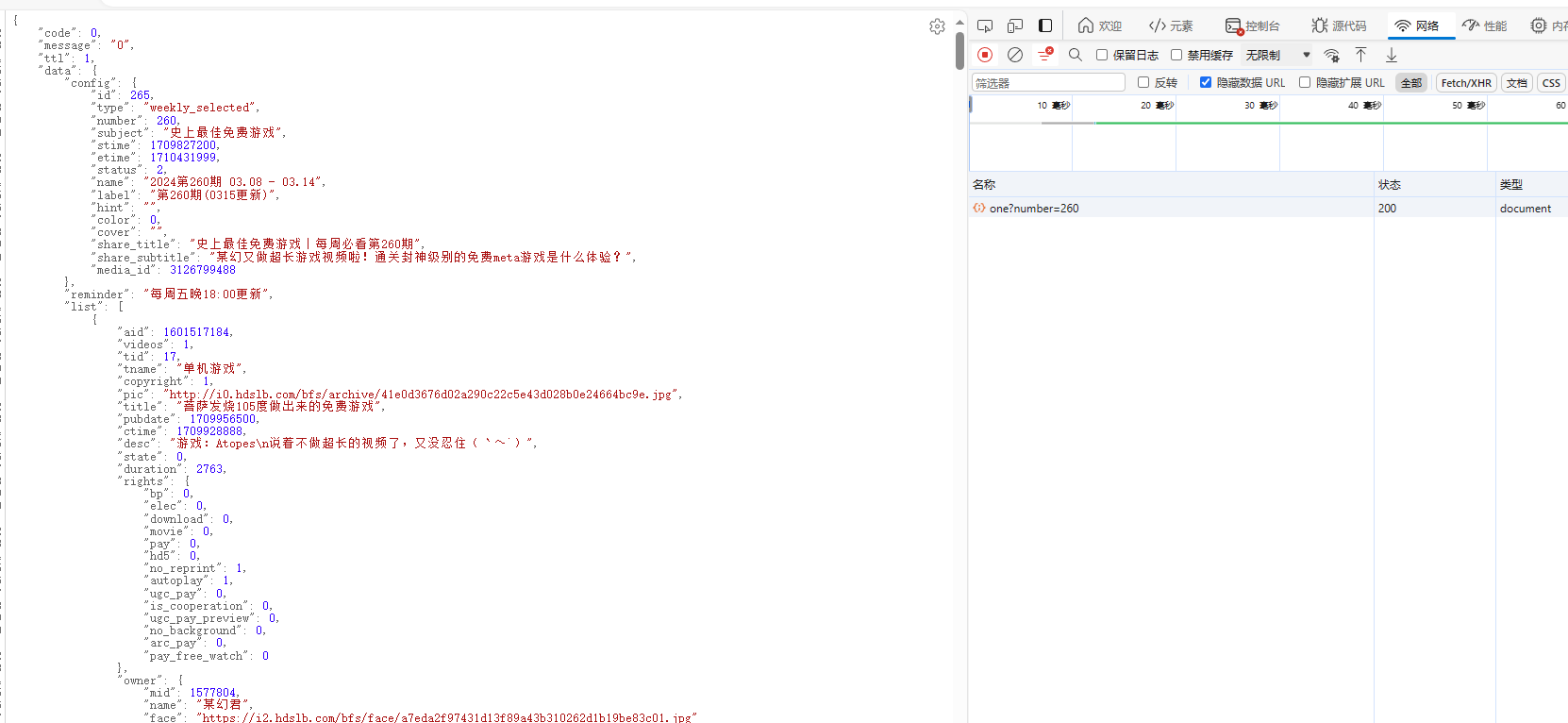
那这拿到信息之后,对于我们操作就很简单了,很明显这就是一个前后端分离的爬取,我们就只要对于对于接口的get请求进行模拟即可,首先我们获取到我们的最大期数,然后通过我们for循环遍历去模拟请求详细界面搞定!
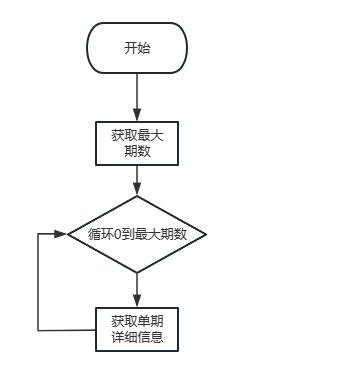
实操开始
import requests
import time
import json
from collections import Counter
headers= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
}
def getmaxweek():
url = "https://api.xxxx.com/x/web-interface/popular/series/list"
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
maxindex = json.loads(response.text)['data']['list'][0]['number']
print(maxindex)
return maxindex
def getlibilibili(url):
names=[]
response = requests.get(url,headers=headers)
week = json.loads(response.text)['data']['list']
for i in range(len(week)):
name=week[i]['owner']['name']
names.append(name)
return names
namesum=[]
urls = "https://api.xxxx.com/x/web-interface/popular/series/one?number="
for i in range(1, getmaxweek()+ 1):
url=urls+str(i)
print(i)
namesum.extend(getlibilibili(url))
name_counter = Counter(namesum)
print(name_counter)
就在我等待爬取完成的时候,这个时候
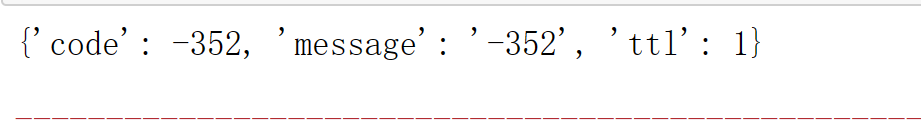
很明显,ip请求次数过多,导致ip被封,首先想到的就是加上time时间等待
不过很遗憾问题还是没有得到解决
还是1min内最多请求100次,超过100会锁IP
这个时候就要使用代理ip了,经过几番寻找找到一个巨好用的ip池,图形界面化的同时,直接把代理ip的API怼我脸上
真的很舒服,设置完成后直接复制就好了,获取方式放在最后
url = "http://xxxxx.user.xiecaiyun.com/api/proxies?action=getJSON&key=xxxxxx&count=200&word=&rand=false&norepeat=true&detail=false<ime=&idshow=false"
response = requests.get(url)
data = response.json()
proxy = []
for proxy_info in data["result"]:
proxy_ip = proxy_info["ip"]
proxy_port = proxy_info["port"]
proxy_url = f"http://{proxy_ip}:{proxy_port}"
proxy.append(proxy_url)
print(proxy)
最后圆满完成任务!
怎么说,和大家预想的有差距吗,好多名字很熟悉但是已经很少活跃了,害
还有什么问题欢迎大家一起讨论!
说说你猜测的是谁呢,嘿嘿





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











