







3.3算数运算与数据对齐
Pandas执行算数运算时,会先按照索引进行对齐,对齐以后再进行相应的运算,没对齐的位置会用NaN进行补齐。其中,series是按行索引对齐的,DataFrame是按行索引、列索引对齐的。
例:
1)
import pandas as pd
obj_one = pd.Series(range(10, 13), index=range(3))
print(obj_one)
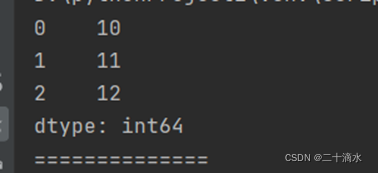
2)
obj_two = pd.Series(range(20, 25), index=range(5))
print(obj_two)
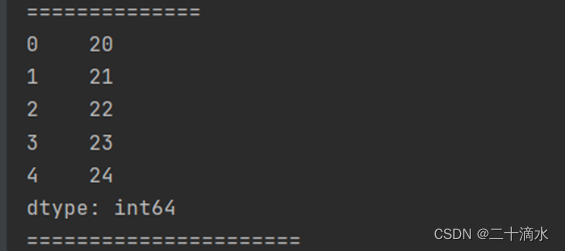
Obj_one与obj_two进行加法运算,则会将它们按照索引进行对齐,对齐的位置进行加法运算,没有对其的位置使用NaN值进行填充
3)执行相加运算
print(obj_one+obj_two)
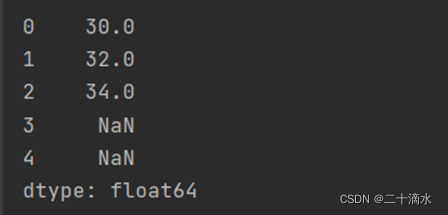
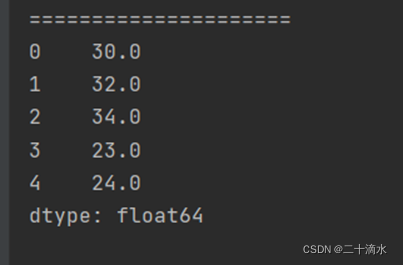
如果希望不使用NaN填充缺失数据,则可以在调用add方法时提供fill_value参数的值,fill_value将会使用对象中存在的数据进行补充
4)执行加法运算,补充缺失值
print(obj_one.add(obj_two, fill_value=0))
3.4数据排序
在数据处理中,数据的排序也是常见的一种操作。由于pandas中存放的是索引和数据的组合,所以它既可以按索引进行排序,也可以按数据进行排序
3.4.1按索引排序
语法格式
sort_index(axis=0, level=None, ascending=True, inplace=False,
kind='quicksort', na_position='last', sort_remaining=True)
常用参数说明
| 参数 | 说明 |
|---|---|
| axis | 轴索引(排序的方向),0表示index(按行),1表示columns(按列) |
| Level | 若不为None,则对指定索引级别的值进行排序 |
| Ascending | 是否升序排序,默认为True,表示升序 |
| Inplace | 默认为Flase,表示对数据表进行排序,不创建新的实例 |
| kind | 选择排序算法 |
默认情况下,pandas对象是按照升序排序,当然也可以通过参数ascending=Flase改为降序排序
例:
1)
import pandas as pd
ser_obj = pd.Series(range(10, 15), index=[5, 3, 1, 3, 2])
print(ser_obj)
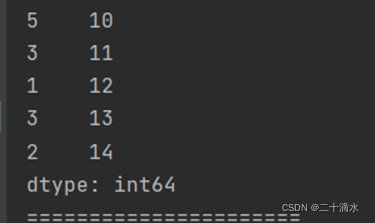
2)按索引进行升序排列
print(ser_obj.sort_index())#按索引进行升序排列

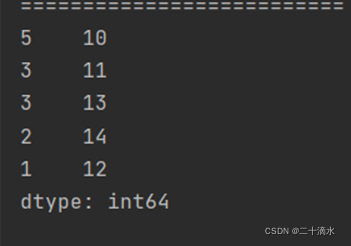
3)按索引进行降序排序
print(ser_obj.sort_index(ascending=False))#按索引进行降序排列
对DataFrame的索引进行排序
例
1)
import pandas as pd
import numpy as np
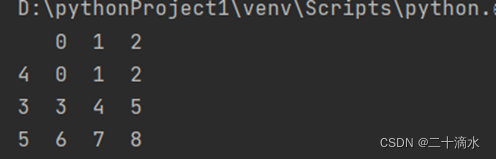
df_obj = pd.DataFrame(np.arange(9).reshape(3, 3), index=[4, 3, 5])
print(df_obj)
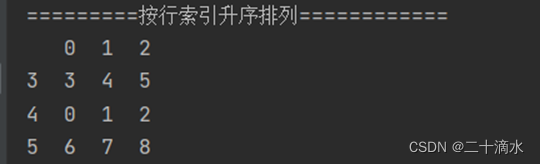
2)按行索引升序排列
print(df_obj.sort_index())#按行索引升序排列
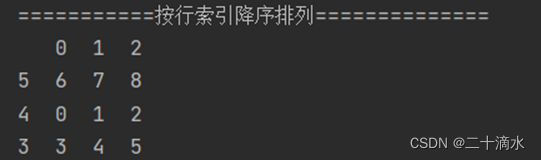
3)按行索引降序排列
print(df_obj.sort_index(ascending=False))#按行索引降序排列
4)按列索引降序排列
print(df_obj.sort_index(axis=1, ascending=False))
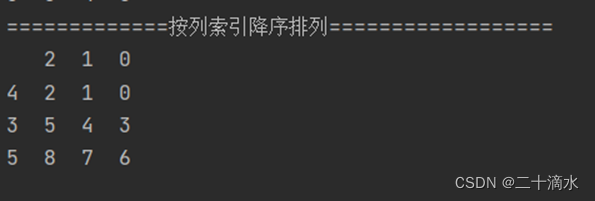
需要注意的是,当对DataFrame进行排序操作时,要注意州的方向。如果没有指定axis参数的值,则默认会按照行索引进行排序;如果指定axis=1,则会按照列索引进行排序
3.4.2按值排序
Pandas中用来按值排序的方法味sort_values()语法格式如下
sort_values(by,axis=0,ascending=True, inplace=False, kind='quicksort',
na_position='last')
其中,by参数表示排序的列,na_position参数只有两个值:first和last,若设为first,则会将NaN值放在开头;若设为Flase,则会将NaN值放在最后。
例:
1)
import pandas as pd
import numpy as np
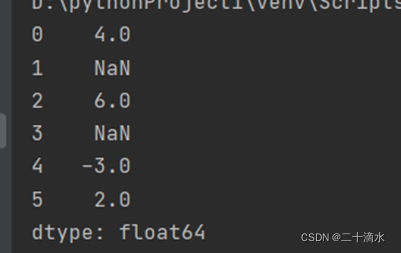
ser_obj = pd.Series([4, np.nan, 6, np.nan, -3, 2])
print(ser_obj)
2)按值升序排列
print(ser_obj.sort_values())
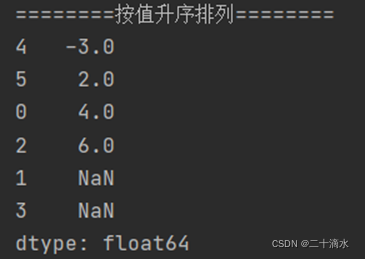
需要注意的是,当series对象调用sort_values()方法按值进行排序时,所有缺失值默认都会放在末尾
再DataFrame中,sort_values()方法可以根据一个或多个列中的值进行排序,但是需要在排序时将一个或多个列的索引传递给by参数才行
例:
1)
import pandas as pd
import numpy as np
df_obj = pd.DataFrame([[0.4, -0.1, -0.3, 0.0],
[0.2, 0.6, -0.1, -0.7],
[0.8, 0.6, -0.5, 0.1]])
print(df_obj)
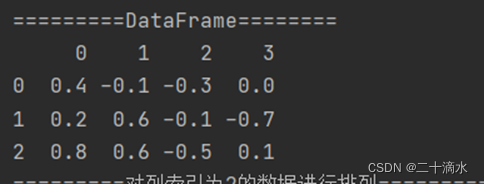
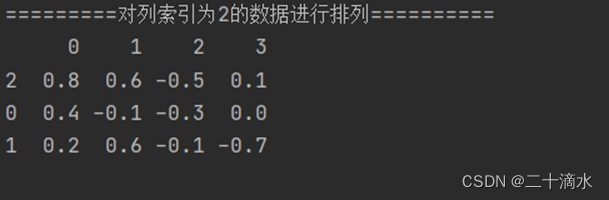
2)对列索引为2的数据进行排序
print(df_obj.sort_values(by=2))















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









