







 本文介绍了数据流分析的基础,包括迭代算法的理论、不动点的概念、偏序和上下界的定义,以及如何通过Lattice和单调性理论分析数据流。文章还讨论了may/must分析、MOP的精度和常量传播,并提到了Worklist算法优化迭代计算的方法。
本文介绍了数据流分析的基础,包括迭代算法的理论、不动点的概念、偏序和上下界的定义,以及如何通过Lattice和单调性理论分析数据流。文章还讨论了may/must分析、MOP的精度和常量传播,并提到了Worklist算法优化迭代计算的方法。
参考:
【课程笔记】南大软件分析课程4——数据流分析基础(课时5/6) - 简书
---------------------------------------------------------------------------
1. 迭代算法
本质:常见的数据流迭代算法,目的是通过迭代计算,最终得到一个稳定的不变的解。
(1)理论
定义1:给定有 k 个节点(基本块)的 CFG,迭代算法就是在每次迭代时,更新每个节点 n 的OUT[n]。
定义2:设数据流分析的值域是 V,可定义一个 k - 元组:![]() ,作为集合
,作为集合![]() (记为
(记为![]() )的一个元素,表示每次迭代后 k 个节点的值。
)的一个元素,表示每次迭代后 k 个节点的值。
定义3:每一次迭代可看作是![]() 映射到新的
映射到新的![]() ,通过 转换规则 和 控制流 来映射,记作函数
,通过 转换规则 和 控制流 来映射,记作函数![]() 。
。
迭代算法本质:通过不断迭代,直到相邻两次迭代的 k - 元组值一样,算法结束。
(2)图示

不动点:当Xi = F(Xi)时,就是不动点。
问题:
- 迭代算法是否一定会停止(到达不动点)?
- 迭代算法如果会终止,会得到几个解(几个不动点)?
- 迭代几次会得到解(到达不动点)?
2. 偏序(Partial Order)
定义:给定偏序集(P, ![]() ),
),![]() 是集合 P 上的二元关系,若满足以下性质则为偏序集:
是集合 P 上的二元关系,若满足以下性质则为偏序集:
- ∀x∈P, x⊑x(自反性 Reflexivity)
- ∀x,y∈P, x⊑y∧y⊑x ⇒ x=y(对称性 Antisymmetry)
- ∀x,y∈P, x⊑y∧y⊑z ⇒ x⊑z(传递性 Transitivity)
例子:
- P 是整数集,
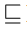 表示
表示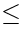 ,是偏序集;若表示 <,则显然不是偏序集。
,是偏序集;若表示 <,则显然不是偏序集。 - P 是英文单词集合,表示子串关系,是偏序集(可以存在两个元素不具有偏序关系,不可比性)。
3. 上下界(Upper and Lower Bounds)
(1)定义
定义:给定偏序集(P, ![]() ),且有 P 的子集 S ⊆ P:
),且有 P 的子集 S ⊆ P:
- ∀x∈S, x⊑u, 其中 u∈P,则 u 是子集 S 的上界 (注意,u并不一定属于S集)
- ∀x∈S, l⊑x, 其中 l∈P,则 l 是 S 的下界
最小上界:least upper bound(lub 或者称为 join),用 ⊔S 表示。
定义:对于子集 S 的任何一个上界 u,均有 ⊔S⊑u。
最大下界:greatest lower bound(glb 或者称为 meet),用 ⊓S 表示。
定义:对于子集 S 的任何一个下界 l,均有 l⊑⊓S。
(2)示例
若 S 只包含两个元素 a、b(S = {a, b}),那么上确界可以表示为 a⊔b,下确界可以表示为 a⊓b。

(3)特性
并非每个偏序集都有上下确界。

如果存在上下确界,则是唯一的。(利用传递性和反证法即可证明)
4. 格(Lattice),(半格)Semilattice,全格,格点积(Complete and Product Lattice)
都是基于上下确界来定义的。
(1)格
定义:给定一个偏序集 (P, ⊑),∀a, b∈P,如果存在 a⊔b 和 a⊓b,那么就称该偏序集为格。(偏序集中的任意两个元素构成的集合均存在最小上界和最大下界,那么该偏序集就是格)
例子:
- (S, ⊑) 中 S 是整数子集,⊑是,(S, ⊑)是格;
- (S, ⊑) 中 S 是英文单词集,⊑表示子串关系,(S, ⊑)不是格,因为单词 pin 和 sin 就没有上确界;
- (S, ⊑) 中 S 是 {a, b, c} 的幂集,⊑表示子集
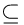 ,(S, ⊑)是格。
,(S, ⊑)是格。
(2)半格
定义:给定一个偏序集 (P, ⊑),∀a, b∈P:
当且仅当 a⊔b 存在(上确界),该偏序集叫做 join semilatice;
当且仅当 a⊓b 存在(下确界),该偏序集叫做 meet semilatice。
(3)全格
定义:对于格 (S, ⊑) 的任意子集 S,⊔S 上确界和 ⊓S 下确界都存在,则为全格(complete lattice)。
例子:
- P 是整数集,⊑是,P 不是全格,因为 P 的子集正整数集没有上确界。
- (S, ⊑) 中 S 是 {a, b, c} 的幂集,⊑表示子集,(S, ⊑) 是全格。
性质:
1. 有穷的格点必然是全格。
2. 全格一定有穷吗? 不一定,如实数界 [0, 1]。
(4)格点积

5. 数据流分析框架 via Lattice
数据流分析框架 (D, L, F) :
- D — 方向
- L — 格点(值域 V)
- F — 转换规则 V
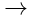 V。
V。
数据流分析可以看做是迭代算法对格点利用转换规则和 meet/join 操作。
6. 单调性与不动点定理(Monotonicity and Fixed Point Theorem)
目标问题:迭代算法一定会停止(到达不动点)吗?
(1)单调性
定义:函数f: L → L,满足 ∀x, y∈L,x⊑y ⇒ f(x)⊑f(y),则为单调的。
(2)不动点理论
定义:给定一个完全格 (L, ⊑),如果f: L → L是单调的,并且L有限,
那么我们能得到最小不动点,通过迭代:![]() 直到找到最小的一个不动点;
直到找到最小的一个不动点;
同理,我们能得到最大不动点,通过迭代:![]() 直到找到最大的一个不动点。
直到找到最大的一个不动点。
7. 迭代算法转化为不动点理论
问题:我们如何在理论上证明迭代算法有解、有最优解、何时到达不动点?
那就是将迭代算法转化为不动点理论。因为不动点理论已经证明了,单调、有限的完全格,存在不动点,且从 ⊤ 开始能找到最大不动点,从 ⊥ 开始能找到最小不动点。
目标:证明迭代算法是一个完全格 (L, ⊑),是有限的,单调的。

(1)证明迭代算法是一个完全格
根据第5小节,迭代算法每个节点(基本块)的值域相当于一个 lattice,每次迭代的 k 个基本块的值域就是一个 k - 元组。k - 元组可看作格点积。根据格点积性质:若![]() 中每一个 lattice 都是完全(有限)的,则
中每一个 lattice 都是完全(有限)的,则![]() 也是完全(有限)的。
也是完全(有限)的。
(2)L是有限的
迭代算法中,值域是 0/1,是有限的,则 lattice 有限,则![]() 也有限。
也有限。
(3)F是单调的
函数F:BB 中 转换函数 fi:L → L 与 BB 分支之间的控制流 影响(汇聚是join ⊔ / meet ⊓ 操作,分叉是拷贝操作)。
- 转换函数:BB 的 gen、kill 是固定的,值域一旦变成 1,就不会变回 0,显然单调。
- join/meet 操作:L × L → L 。证明:∀x, y, z∈L,且有 x⊑y 需要证明 x⊔z⊑y⊔z。
总结:迭代算法是完全 lattice,且是有限、单调的,所以一定有解、有最优解。
(4)算法何时到达不动点?
定义:lattice 高度 — 从 lattice 的 top 到 bottom 之间最长的路径。

最坏情况迭代次数:设有 n 个块,每次迭代只有 1 个 BB 的 OUT/IN 值的其中 1 位发生变化,则最多迭 (n × h) 次。(可以看成每个块的值在上图向上爬,每个块要爬 h 次)
8. 从 lattice 的角度看 may/must 分析
说明:may 和 must 分析算法都是从不安全到安全(是否安全取决于 safe-aprroximate 过程),从准确到不准确。

(1)may分析
以 Reaching Definitions 分析为例:
-
从
 开始,表示所有定义都不可达,是不安全的结果(因为这个分析的应用目的是为了查错,查看变量是否需要初始化,并对每个值为 1 的 definition 进行初始化。表示不需要对任何变量进行初始化,这是不安全的,可能导致未初始化错误)。
开始,表示所有定义都不可达,是不安全的结果(因为这个分析的应用目的是为了查错,查看变量是否需要初始化,并对每个值为 1 的 definition 进行初始化。表示不需要对任何变量进行初始化,这是不安全的,可能导致未初始化错误)。 -
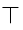 表示需要对每个变量都进行初始化,非常安全!但是这句话没有用,我都要初始化的话还做这个分析干嘛?
表示需要对每个变量都进行初始化,非常安全!但是这句话没有用,我都要初始化的话还做这个分析干嘛? -
Truth:表明最准确的验证结果,假设 {a, c} 是 truth,那么包括其以上的都是 safe 的,以下的都是 unsafe。

从![]() 到
到![]() ,得到的最小不动点最准确,离Truth最近。上面还有多个不动点,越往上越不准。
,得到的最小不动点最准确,离Truth最近。上面还有多个不动点,越往上越不准。
(2)must分析
以 available expressions 分析为例:
- 从开始,表示所有表达式可用。如果用在表达式计算优化中,那么有很多已经被重定义的表达式也被优化了(实际上不能被优化),那么该优化就是错误的,不安全!
- 表示没有表达式可用,都不需要优化,很安全!但没有用。
- 从到,就是从不安全到安全,存在一个 Truth,代表准确的结果。
- 从到,达到一个最大不动点,离 truth 最近的最优解。
迭代算法转化到 lattice 上,may/must 分析分别初始化为最小值![]() 和最大值
和最大值![]() ,最后求最小上界/最大下界。
,最后求最小上界/最大下界。
9. 分配性(Distributivity)和MOP
目的:MOP(meet-over-all-paths)衡量迭代算法的精度。
(1)概念
定义:分别得出每条路径的 OUT,最终将所有路径的 OUT 一起来进行 join/meet 操作,本质求这些值的最小上界 / 最大下界。
路径 P = 在 cfg 图上从 entry 到基本块 si 的一条路径(P = Entry → s1 → s2 → ... → si )。
路径 P 上的转移函数 Fp:该路径上所有语句的转移函数的组合fs1,fs2,... ,fsi-1。

MOP准确性:有些路径原本不会被执行而被计算,所以不准确;若路径包含循环,或者路径爆炸,所以实操性不高,只能作为理论的一种衡量方式。
(2)MOP vs 迭代算法

证明:
-
根据最小上界的定义,有 x⊑x⊔y 和 y⊑x⊔y。
-
由于转换函数是单调的,则有 F(x)⊑F(x⊔y) 和 F(y)⊑F(x⊔y),所以 F(x⊔y) 就是 F(x) 和 F(y) 的上界。
-
根据定义,F(x)⊔F(y) 是 F(x) 和 F(y) 的最小上界。
-
所以 F(x)⊔F(y)⊑F(x⊔y)。
结论:所以,MOP更准确。若 F 满足分配律,则迭代算法和 MOP 精确度一样 F(x⊔y) = F(x)⊔F(y)。一般,对于控制流的 join/meet,是进行集合的交或并操作,满足分配律。
10. 常量传播 (constant propagation)
问题描述:在程序点 p 处的变量 x,判断 x 是否一定指向常量值。
类别:must分析。
表示:CFG 每个节点的 OUT 是 pair(x, v)的集合,表示变量 x 是否指向常数 v。
(1)数据流分析框架(D, L, F)
(1)D:forward
(2)L:lattice

变量值域:所有实数。
meet 操作:
- NAC ⊓ v = NAC(非常量)
- UNDEF ⊓ v = v(未初始化的变量不是我们分析的目标)
- c ⊓ v = ?
- c ⊓ c = c
- c1 ⊓ c2 = NAC
不满足分配律。
(2)F 转换函数
OUT[s] = gen U (IN[s] - {(x, _)})
对所有的赋值语句进行分析(不是赋值语句则不管,用 val(x) 表示 x 指向的值):

(3)性质
不满足分配律

可以发现,MOP更准确。
11. Worklist算法
本质:对迭代算法进行优化,采用队列来存储需要处理的基本块,减少大量的冗余的计算。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









