







Python爬虫系列
网络爬虫也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。在大数据时代,信息的采集是一项重要的工作,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。
本节讲述Python爬虫中requests模块的使用!并在上一篇的基础下实现爬虫代码,获取一定的数据。
前言
首先,Python的Requests模块是一个广泛应用的网络请求库,它提供了简单而优雅的HTTP方法,使得与Web接口交互变得非常容易。使用Requests,我们可以执行各种HTTP请求,包括GET、POST、PUT、DELETE等,同时还可以添加头文件、Cookie信息和其他参数。通过网络爬虫,我们可以快速高效地获取特定网站上的数据,并将其保存在本地进行分析和处理。简而言之,Requests模块是实现网络爬虫的必备工具之一,本篇文章将帮助您快速掌握使用它编写网络爬虫的基本步骤和技巧。但请注意,在爬取数据时,请遵循道德及法律规定,不要违反任何相关法律法规。
一、Requests模块作用介绍
Requests是一个Python第三方库,用于发送HTTP/1.1请求。它能够发送各种类型的HTTP请求,并且能且自动管理连接池和重试功能,支持国际化URL和数据编码、使用Cookie等常见的HTTP功能。
在Python中使用Requests模块可以轻松获取网页内容、搜索API、下载二进制文件等等,它还提供了丰富的请求方法(如GET、POST、PUT、DELETE等)、钩子函数(如响应返回回调、请求预处理)、Session会话以及Cookie、头部信息等一系列优秀的特性。
同时,Requests还受到全球范围内Python开发者的大力推崇,深受欢迎成为众多开发者首选的网络请求库之一。
除此之外,基于Requests还有非常著名的Scrapy、BeautifulSoup等python库,它们都在不同的领域中应用广泛,无论是爬虫还是Web开发都能够让我们少走很多弯路。
二、使用前的准备工作
1 requests模块的安装
requests模块是一个第三方模块,需要在你的python(虚拟)环境中额外安装
在终端命令如下:
pip/pip3 install requests
如果是linux系统安装时报权限的错,请加上sudo命令如下:
sudo pip/pip3 install requests
2 requests模块导入
要在Python中使用requests模块,需要先进行导入操作,requests模块和其他模块相同。
- 一般情况下,可以使用以下代码进行导入:
import requests
- 如果想给导入的requests模块指定一个别名(alias),可以使用以下代码:
import requests as rq
这样就可以使用rq来代替requests了。
- 如果只需要使用requests模块中的某个函数或属性,可以通过如下方式进行导入:
from requests import get, post
这里以get和post两个函数为例进行导入,这样就可以直接调用它们,而不需要使用"requests."前缀。
- 除此之外,还可以通过类似于如下代码的方式进行导入:
from requests import *这种方式可以一次性导入所有请求方法、异常、响应码等信息,但不推荐这种做法,因为容易产生命名冲突和代码可读性差等问题。
三、requests模块的使用
1 使用requests模块发送get请求
语法调用规则如下:
import requests
url='目标链接(url)'
requests.get(url)
简单的实例操作:
- 需求:通过requests向百度首页发送请求,获取该页面的源码
- 运行下面的代码,观察打印输出的结果
# 3.1.1-简单的代码实现
import requests
# 目标url百度网页
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
返回信息如下:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>ç™¾åº¦ä¸€ä¸‹ï¼Œä½ å°±çŸ¥é“</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ–°é—»</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产å“</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å
³äºŽç™¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度å‰å¿
读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ„è§å馈</a> 京ICPè¯030173å· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
观察上方获取的源码,你会发现以上获取的数据大部分是乱码,而且并不完整!这是因为编解码使用的字符集不同早造成的;我们尝试使用下边的办法来解决中文乱码问题:
方法一:
# 手动设置编码格式
response.encoding = 'utf8'
方法二:
# response.content是存储的bytes类型的响应源码,可以进行decode操作
response.content.decode()
结合上方代码一个完整获取的方式如下:
# 3.1.2-response.content
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
# response.encoding = 'utf8'
# print(response.text)
print(response.content.decode()) # 注意这里!
注意:
- response.text是requests模块按照chardet模块推测出的编码字符集进行解码的结果
- 网络传输的字符串都是bytes类型的,
所以response.text =response.content.decode(‘推测出的编码字符集’)- 我们可以在网页源码中搜索
charset,尝试参考该编码字符集,注意存在不准确的情况
1.1 response.text 和response.content的区别
- response.text
- 类型:str
- 解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- response.content
- 类型:bytes
- 解码类型: 没有指定
1.2 通过对response.content进行decode,来解决中文乱码
response.content.decode("GBK")response.content.decode()默认utf-8- 常见的编码字符集
- Utf-8
- Gbk
- ASCII(美国信息交换标准代码)
- Gb2312
- iso-8859-1
1.3 response响应对象的其它常用属性或方法
response = requests.get(url)中response是发送请求获取的响应对象;response响应对象中除了text、content获取响应内容以外还有其它常用的属性或方法:
| 属性/方法 | 意义 |
|---|---|
response.url | 响应的url;有时候响应的url和请求的url并不一致 |
response.status_code | 响应状态码 |
response.request.headers | 响应对应的请求头 |
response.headers | 响应头 |
response.request._cookies | 响应对应请求的cookie;返回cookieJar类型 |
response.cookies | 响应的cookie(经过了set-cookie动作;返回cookieJar类型 |
response.json() | 自动将json字符串类型的响应内容转换为python对象(dict or list) |
示例:
# 3.1.3-response其它常用属性
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
# print(response.text)
# print(response.content.decode()) # 注意这里!
print(response.url) # 打印响应的url
print(response.status_code) # 打印响应的状态码
print(response.request.headers) # 打印响应对象的请求头
print(response.headers) # 打印响应头
print(response.request._cookies) # 打印请求携带的cookies
print(response.cookies) # 打印响应中携带的cookies
2 requests模块发送请求
2.1 发送带header的请求
我们先写一个获取百度首页的代码,并返回请求头
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.content.decode())
# 打印响应对应请求的请求头信息
print(response.request.headers)
- 对比浏览器上百度首页的网页源码和代码中的百度首页的源码,你会发现有很多不同的地方
- 查看网页源码的方法:
- 右键-查看网页源代码 或 右键-检查
- 对比对应url的响应内容和代码中的百度首页的源码,有什么不同?
- 查看对应url的响应内容的方法:
1. 右键-检查
2. 点击Net work
3. 勾选Preserve log
4. 刷新页面
5. 查看Name一栏下和浏览器地址栏相同的url的Response
- 代码中的百度首页的源码非常少是因为什么?
- 需要我们带上请求头信息
- 请求头中有很多字段,其中User-Agent字段必不可少,表示客户端的操作系统以及浏览器的信息
下面将通过加入User-Agent来实现数据的获取
2.1.1 携带请求头发送请求的方法
requests.get(url, headers=headers)
- headers参数接收字典形式的请求头
- 请求头字段名作为key,字段对应的值作为value
从浏览器中复制User-Agent(获取方法上一篇文章已经讲过,这里不再多说),构造headers字典;完成下面的代码后,运行代码查看结果,具体代码如下:
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
print(response.content)
# 打印请求头信息
print(response.request.headers)
2.1.2 携带参数的请求方式
在百度首页搜索框搜索python,观察上方的url如下:
https://www.baidu.com/s?wd=python&rsv_spt=1&rsv_iqid=0xcdf0972a000f48b6&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf8&rqlang=cn&tn=baiduhome_pg&rsv_dl=tb&rsv_enter=1&oq=%25E7%2588%25AC%25E8%2599%25AB&rsv_btype=t&inputT=7401&rsv_t=1c62bHLorj83pbHxf4nHEtoBmryb9us56X8OPsom60kviHBR768%2FxzuoCbEYmqf3NenL&rsv_sug3=43&rsv_sug1=17&rsv_sug7=100&rsv_pq=d259428f0005d194&rsv_sug2=0&rsv_sug4=10940
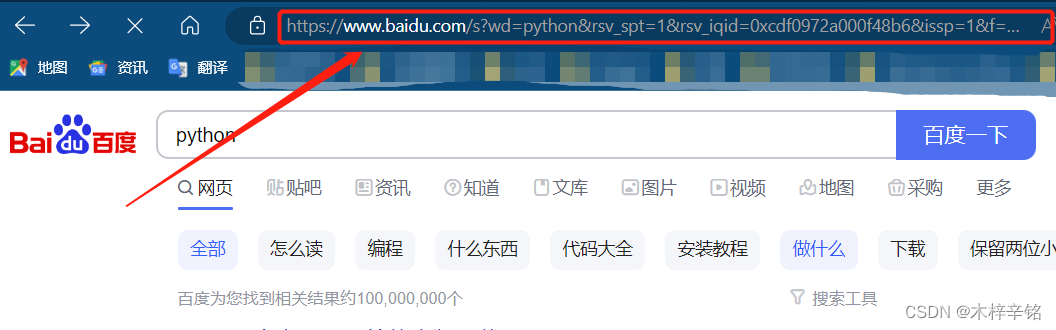
你会发现url后面有很多不知道的代码,并且网页中有很多不重要的数据,我们可以尝试删除一部分进行访问看能不能拿到自己想拿到的东西。
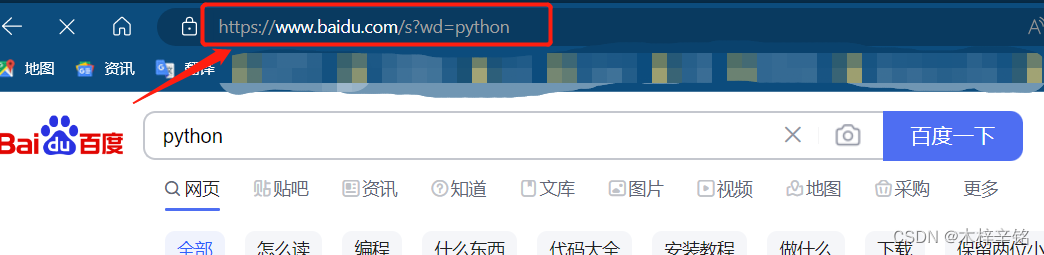
经过删减后,我们可以看到如上图所示,保留关键字wd=python就可以获取到你想要的信息!
url地址中会有一个?,那么该问号后边的就是请求参数,又叫做查询字符串
携带参数请求的两种方式:
- 第一种:
通过直接对携带参数的url发起请求,如下:
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
response = requests.get(url, headers=headers)
- 第二种:
- 带上请求头参数访问,构建请求头参数字典
- 向接口发送请求的时候带上参数字典,参数字典设置给params,代码如下:
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'
# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?'
# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
print(response.content)
小Tips:
什么是params:
params是requests模块中用于指定GET请求参数的一个关键字参数,用于传递自定义请求参数。它可以接收一个字典类型的对象作为参数,并将其转换为查询字符串(query string)的形式,添加到URL末尾。
具体来说,当我们向某个网站发送GET请求时,有时需要在URL中带上一些额外的参数,如翻页参数、搜索关键词等。这时就可以使用params参数来构建查询字符串,例如:import requests url = 'https://www.example.com/search' payload = {'q': 'python', 'page': 2} response = requests.get(url, params=payload)在上述代码中,payload表示要传递的参数,其中’q’对应的是搜索关键词,‘page’对应的是页码。requests会将它们拼接成查询字符串’q=python&page=2’,并将其附加到url的结尾处,最终形成完整的请求URL https://www.example.com/search?q=python&page=2。
需要注意的是,params参数只能用于GET请求,而不能用于POST等其他请求方法。另外,如果传递的参数中包含恶意信息,可能会引起对方服务器的误解,进而导致安全问题,因此在发送请求时应该尽量合理地选择和组织参数。
2.2 在headers参数中携带cookie
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。
我们以github登陆为例:
2.2.1 github登陆抓包分析
- 打开浏览器,右键-检查,点击Net work,勾选Preserve log
- 访问github登陆的url地址
https://github.com/login - 输入账号密码点击登陆后,访问一个需要登陆后才能获取正确内容的url,比如点击右上角的Your profile访问
https://github.com/USER_NAME - 确定url之后,再确定发送该请求所需要的请求头信息中的User-Agent和Cookie
2.2.2 完成代码
- 从浏览器中复制User-Agent和Cookie
- 浏览器中的请求头字段和值与headers参数中必须一致
- headers请求参数字典中的Cookie键对应的值是字符串
import requests
url = 'https://github.com/USER_NAME'
# 构造请求头字典
headers = {
# 从浏览器中复制过来的User-Agent
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
# 从浏览器中复制过来的Cookie
'Cookie': '这里是复制过来的cookie字符串'
}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers)
print(resp.text)
2.2.3 运行代码验证结果
在打印的输出结果中搜索title,html中的标题文本内容如果是你的github账号,则成功利用headers参数携带cookie,获取登陆后才能访问的页面
小结
ok!本文先讲到这里,主要讲述了python爬虫requests模块的使用,并熟练掌握下面的知识
- headers参数的使用
- 发送带参数的请求
- headers中携带cookie
下节讲述:
- cookies参数的使用
- cookieJar的转换方法
- 超时参数timeout的使用
最后,文章持续更新中,希望所有有缘的读者都有所收获,祝你们有所成!感觉有用就支持一下吧!点赞加关注,知识不迷路!!!
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











