







OpenHands LM:一个开源的代码生成模型
1. 背景与目标
OpenHands LM 是一个开源的代码生成模型,旨在解决软件开发任务中的实际问题。与依赖专有模型的编码代理不同,OpenHands LM 提供了一个完全开源的解决方案,允许用户在本地运行模型,而无需依赖外部服务。它的目标是为软件开发人员提供一个高效、灵活且可扩展的工具,以自动化代码生成和问题解决。
2. 核心特点
开源与本地部署:OpenHands LM 在 Hugging Face 上开放,用户可以下载并在本地运行。它支持在单个 3090 GPU 等硬件上运行,降低了硬件要求。
模型规模与性能:模型大小为 32B 参数,具有 128K 令牌上下文窗口,适合处理大型代码库和长期软件工程任务。
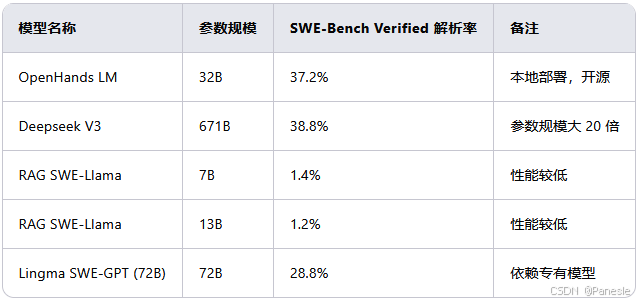
SWE-Bench Verified 性能:在 SWE-Bench Verified 基准测试中,OpenHands LM 达到了 37.2% 的解析率,与参数规模大 20 倍的模型(如 671B 参数的 Deepseek V3)性能相当(38.8%)。
基于 RL 的微调:OpenHands LM 基于 Qwen Coder 2.5 Instruct 32B 构建,通过基于强化学习(RL)的框架进行微调,使用 OpenHands 生成的训练数据进行优化。
3. 性能对比
下表展示了 OpenHands LM 与其他开源模型的性能对比:
4. 使用方法
下载模型:从 Hugging Face 下载 OpenHands LM 模型。
模型服务框架:使用模型服务框架创建与 OpenAI 兼容的终端节点,以获得最佳性能。
集成到 OpenHands:将 OpenHands 代理指向新模型,并按照说明使用与 OpenAI 兼容的终端节点。
5. 训练与优化
训练数据:OpenHands LM 使用 SWE-Gym 提供的训练数据进行微调。SWE-Gym 是一个包含 2,438 个真实世界 Python 任务的训练环境,每个任务都包含代码库、可执行运行时环境、单元测试和自然语言任务描述。
RL 框架:通过基于 RL 的框架,OpenHands LM 使用现有代理生成的训练数据进行微调,从而提高性能。
Verifier 模型:OpenHands LM 还支持推理时扩展,通过训练 Verifier 模型(基于任务执行上下文的奖励模型)来选择最佳解决方案。Verifier 模型可以显著提高解析率,例如在 SWE-Bench Verified 上从 20.6% 提升到 32.0%。
6. 实验结果
训练时间扩展:随着训练轨迹数量的增加,模型性能持续提升,表明 SWE-Gym 的规模和多样性尚未成为性能瓶颈。
推理时间扩展:通过 Verifier 模型,推理时采样多个解决方案并选择最佳解决方案,解析率显著提高。
Pass@K:从 20.6% 提升到 42.8%(K=16)。
Best@K:从 20.6% 提升到 32.0%(K=16)。
7. 未来计划
社区反馈:OpenHands LM 是一个研究预览版本,团队计划根据社区反馈和研究进展继续优化模型。
紧凑模型版本:开发更小的模型版本(如 7B 参数变体),以支持计算资源有限的用户。
解决限制:当前版本在解决 GitHub 问题任务上表现较好,但在更多种类的软件工程任务上表现不佳,有时会生成重复步骤,并且对量化敏感。团队计划在下一个版本中解决这些问题。
8. 应用场景
OpenHands LM 可以应用于以下场景:
自动化代码生成:自动生成代码解决方案以解决 GitHub 问题。
代码审查:帮助开发人员审查代码并提供改进建议。
代码优化:优化现有代码以提高性能和可读性。
教育与培训:作为教育工具,帮助初学者学习编程。
9. 总结
OpenHands LM 是一个具有里程碑意义的开源代码生成模型,它不仅在性能上接近更大的专有模型,还提供了本地部署的灵活性和开源的透明性。通过 SWE-Gym 的支持,OpenHands LM 在真实世界的软件工程任务中表现出色,并且具有良好的扩展性。团队的未来计划将进一步提升模型的性能和适用性,使其成为软件开发人员的得力助手。
10. 相关资源
Hugging Face 模型页面:https://huggingface.co/all-hands/openhands-lm-32b-v0.1
SWE-Gym 论文:Training Software Engineering Agents and Verifiers with SWE-Gym
OpenHands 项目页面:OpenHands GitHub


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









